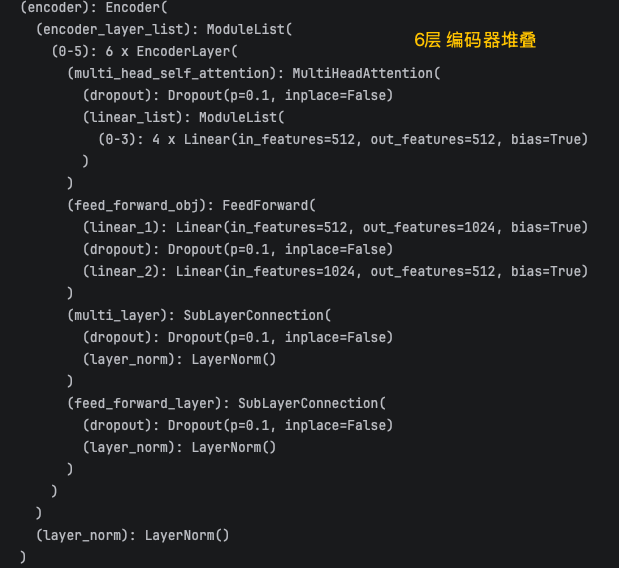
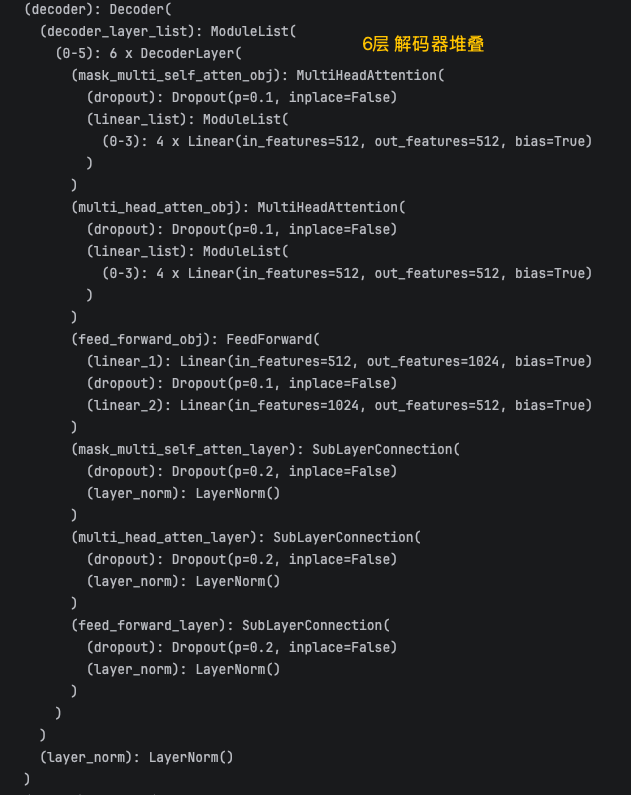
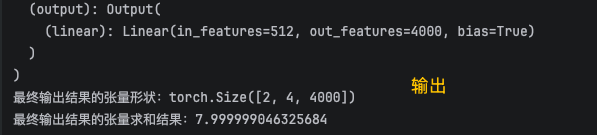
本篇是结合前面几篇把,Transformer 最终整个框架封装好直接拿来使用实例代码。
目录
[Transformer 原理](#Transformer 原理)
[2.Transformer对象 前向传播](#2.Transformer对象 前向传播)
[3. Transformer 实例对象使用](#3. Transformer 实例对象使用)
Transformer 原理
链接:https://blog.csdn.net/i_k_o_x_s/article/details/161060029
整体Transformer框架回顾
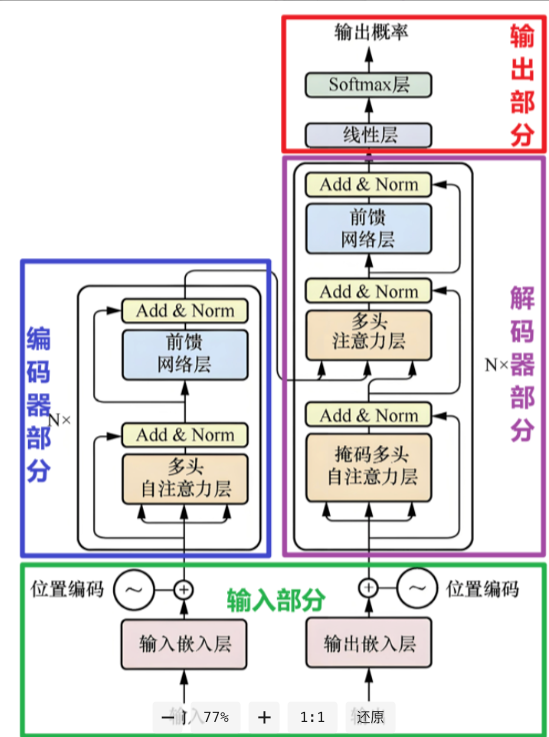
各个部分Transformer手写底层代码剖析
- Transformer 底层源码剖析(输入部分)
https://blog.csdn.net/i_k_o_x_s/article/details/161065795?spm=1001.2014.3001.5502
- Transformer底层代码剖析(通用部分)
https://blog.csdn.net/i_k_o_x_s/article/details/161096897?spm=1001.2014.3001.5502
- Transformer底层源码剖析(编码器部分)
https://blog.csdn.net/i_k_o_x_s/article/details/161173312?spm=1001.2014.3001.5502
4.Transformer底层源码剖析(解码器部分+输出)
https://blog.csdn.net/i_k_o_x_s/article/details/161176836?spm=1001.2014.3001.5502
使用Transformer框架
1.定义Transformer类
(编码输入部分、解码输入部分、编码器、解码器、输出)
2.Transformer对象 前向传播
(编码输入数据、解码输入数据、掩码)
python
class SelfTransformer(nn.Module):
def __init__(self, encoder_input, decoder_input, encoder, decoder:Encoder, output):
super().__init__()
self.encoder_input = encoder_input
self.decoder_input = decoder_input
self.encoder = encoder
self.decoder = decoder
self.output = output
def forward(self, encoder_input_data, decoder_input_data, mask):
# 1. 编码器 输入部分得到的数据
en_embd_data = self.encoder_input(encoder_input_data)
# 2. 编码器层得到的数据
encoder_output = self.encoder(en_embd_data)
# 3. 解码器 输入样本数据
de_embd_data = self.decoder_input(decoder_input_data)
# 4. 解码器的 N层 解码层处理
decoder_data = self.decoder(data=de_embd_data, mask=mask, encoder_output=encoder_output)
# 5. 输出部分
return self.output(decoder_data)
3. Transformer 实例对象使用
python
def get_self_transformer():
# 设置常量
d_model = 512
dropout_p = 0.1
en_vocab_size = 1000
de_vocab_size = 4000
en_max_len = 50
de_max_len = 60
num_heads = 8
output_dim_size = 1024
# ============== 编码器部分 ===============
en_ebd = Embedding(vocab_size=en_vocab_size,d_model=d_model)
en_pos = PositionalEncoding(d_model=d_model, dropout_p=dropout_p, max_len=en_max_len)
en_multi_self_attn = MultiHeadAttention(d_model=d_model, num_heads=num_heads, dropout_p=dropout_p)
en_ffn = FeedForward(d_model=d_model, output_dim=output_dim_size, dropout_p=dropout_p)
#组装编码器
encoder_layer = EncoderLayer(
d_model=d_model,
multi_head_self_attention=en_multi_self_attn,
feed_forward_obj=en_ffn,
dropout_p=dropout_p
)
#编码器
encoder = Encoder(encoder_layer, N=6)
# ============= 解码器部分 ================
de_edb = Embedding(vocab_size=de_vocab_size,d_model=d_model)
de_pos = PositionalEncoding(d_model=d_model, dropout_p=dropout_p, max_len=de_max_len)
mask_multi_self_att = MultiHeadAttention(d_model=d_model, num_heads=num_heads, dropout_p=dropout_p)
multi_att = MultiHeadAttention(d_model=d_model, num_heads=num_heads, dropout_p=dropout_p)
de_ffn = FeedForward(d_model=d_model, output_dim=output_dim_size, dropout_p=dropout_p)
# ============= 组装解码器 =================
decoder_layer = DecoderLayer(
d_model=d_model,
mask_multi_self_atten_obj=mask_multi_self_att,
multi_head_atten_obj=multi_att,
feed_forward_obj=de_ffn,
)
decoder = Decoder(decoder_layer)
# 输出层
output = Output(d_model=d_model,vocab_size=de_vocab_size)
# ============= 组装 Transformer 框架 ===================
self_transformer = SelfTransformer(
encoder_input=nn.Sequential(en_ebd, en_pos),
encoder=encoder,
decoder_input=nn.Sequential(de_edb, de_pos),
decoder=decoder,
output=output
)
print(f'架构结构信息:{self_transformer}')
return self_transformer4.测试框架
python
def use_self_transformer():
# 1. 拿到transformes乱讲
self_transformer = get_self_transformer()
# 2. 数据级 编码器端输入
en_intput_data = torch.tensor([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
#3 # 数据集 解码器端 输入
de_intput_data = torch.tensor(
[[222, 2344, 456, 356],
[2456, 131, 456, 67]]
)
# 4. 解码器的掩码
"""
torch.triu(..., diagonal=0)
triu = Upper Triangle 上三角
保留对角线及以上的 1,对角线以下全部变成 0
"""
mask = torch.triu(torch.ones([8, 4, 4]), diagonal=0)
# 5. 调用框架
result = self_transformer(
en_intput_data,
de_intput_data,
mask
)
print(f"最终输出结果的张量形状:{result.shape}")
print(f"最终输出结果的张量求和结果:{result.sum()}")
if __name__ == "__main__":
use_self_transformer()5.打印Transformer框架信息