作者:洛水石
前言
"K8s 的核心组件是什么?"
"一个 Pod 挂了,K8s 是怎么把它拉起来的?"
"你们生产环境用的什么网络方案?"
如果你在简历上写了"了解 K8s"或"熟悉微服务",这些问题是必问的。但大多数候选人只能说出"Kubectl 是个命令行工具",然后就卡住了。
今天一文讲透 K8s 核心架构,从组件原理到 Deployment 实战,面试能直接用。
1. 先搞懂 Kubernetes 是什么
Kubernetes(K8s)是 Google 内部 Borg 系统的开源版本,是一个**容器编排平台**。
它的核心职责:
-
**调度**:把容器调度到合适的节点
-
**自愈**:容器挂了自动重启
-
**扩缩容**:根据负载自动增减副本
-
**服务发现**:容器IP会变,K8s 提供稳定的访问入口
记住这句话面试能加10分:**K8s 不运行容器,它运行的是 Pod,Pod 才是 K8s 的最小调度单位。**
2. K8s 核心组件详解
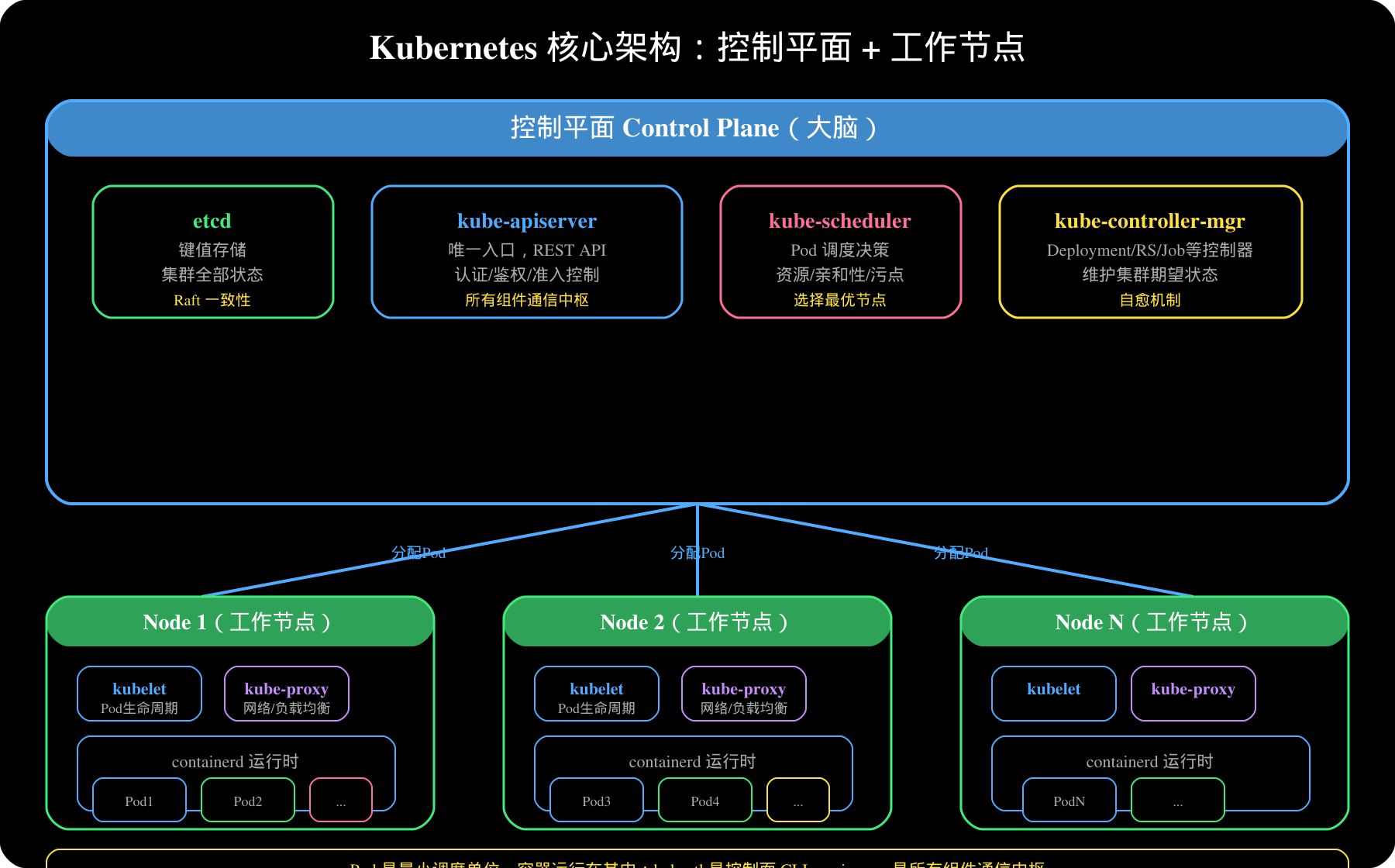
2.1 控制平面(Control Plane)--- 大脑
```
┌─────────────────────────────────────────────────────┐
│ 控制平面 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ kube- │ │ kube- │ │ kube- │ │
│ │ apiserver│ │ scheduler│ │ controller│ │
│ │ (网关) │ │ (调度器) │ │ manager │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ └──────────────┼──────────────┘ │
│ ┌──────────────────┴──────────────────┐ │
│ │ etcd(配置存储) │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
```
**kube-apiserver**:K8s 唯一入口,所有组件和用户都通过它通信。
```bash
举例:kubectl get pods 背后发生了什么
kubectl get pods
↓
kube-apiserver(验证请求,读取etcd,返回结果)
↓
```
**kube-scheduler**:负责 Pod 调度,根据资源需求和调度策略选择最优节点。
调度决策因素:
-
资源需求(CPU/内存请求值 vs 限制值)
-
亲和性/反亲和性(Affinity)
-
Taints(污点)和 Tolerations(容忍)
-
拓扑分布(Topology Spread)
```yaml
Pod 调度策略示例
spec:
containers:
- name: myapp
resources:
requests: # 调度依据
memory: "128Mi"
cpu: "250m"
limits: # 硬限制
memory: "256Mi"
cpu: "500m"
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: zone
operator: In
values: "beijing"
```
**kube-controller-manager**:运行所有控制器,维护集群期望状态。
关键控制器:
| 控制器 | 职责 |
|---|---|
| Deployment Controller | 维护 Deployment 期望副本数 |
| ReplicaSet Controller | 维护 Pod 副本数 |
| StatefulSet Controller | 管理有状态应用 |
| DaemonSet Controller | 每个节点运行一个 Pod |
| Job/CronJob Controller | 批处理任务调度 |
| Node Controller | 节点心跳检测 |
| Service Controller | 管理 Service 和负载均衡 |
**etcd**:高可用的键值存储,保存 K8s 集群所有状态数据(Pod定义、Service、ConfigMap等)。
面试高频题:**etcd 用 Raft 一致性算法保证数据一致性**,所有写入必须过半数节点确认。
2.2 工作节点(Node)--- 执行者
```
┌──────────────────────────────────────┐
│ Node │
│ ┌────────────┐ ┌────────────────┐ │
│ │ kubelet │ │ kube-proxy │ │
│ │ (节点代理) │ │ (网络代理) │ │
│ └─────┬──────┘ └──────┬─────────┘ │
│ │ │ │
│ ┌─────▼─────────────────▼────────┐ │
│ │ Container Runtime │ │
│ │ (containerd) │ │
│ └───────────────┬─────────────────┘ │
│ ┌───────────────▼─────────────────┐ │
│ │ Pod (myapp) Pod (redis) │ │
│ │ nginx redis-server │ │
│ └──────────────────────────────────┘ │
└──────────────────────────────────────┘
```
**kubelet**:节点上的 Agent,负责:
-
向 apiserver 注册节点
-
汇报节点状态(资源使用、健康状况)
-
根据期望状态创建/销毁 Pod
-
绑定存储卷(Volume)
**kube-proxy**:维护节点上的网络规则,实现 Service 的负载均衡。
-
iptables 模式(早期默认):每个 Service 创建 iptables 规则
-
IPVS 模式(推荐):用 Linux 内核 IPVS 做负载均衡,性能更高
**Container Runtime**:实际运行容器,常见选项:
-
**containerd**(K8s 默认,Docker剥离后独立项目)
-
CRI-O(轻量,专为 K8s 设计)
-
Docker(K8s 1.24 前支持,现已废弃)
3. Pod 的生命周期与健康检查
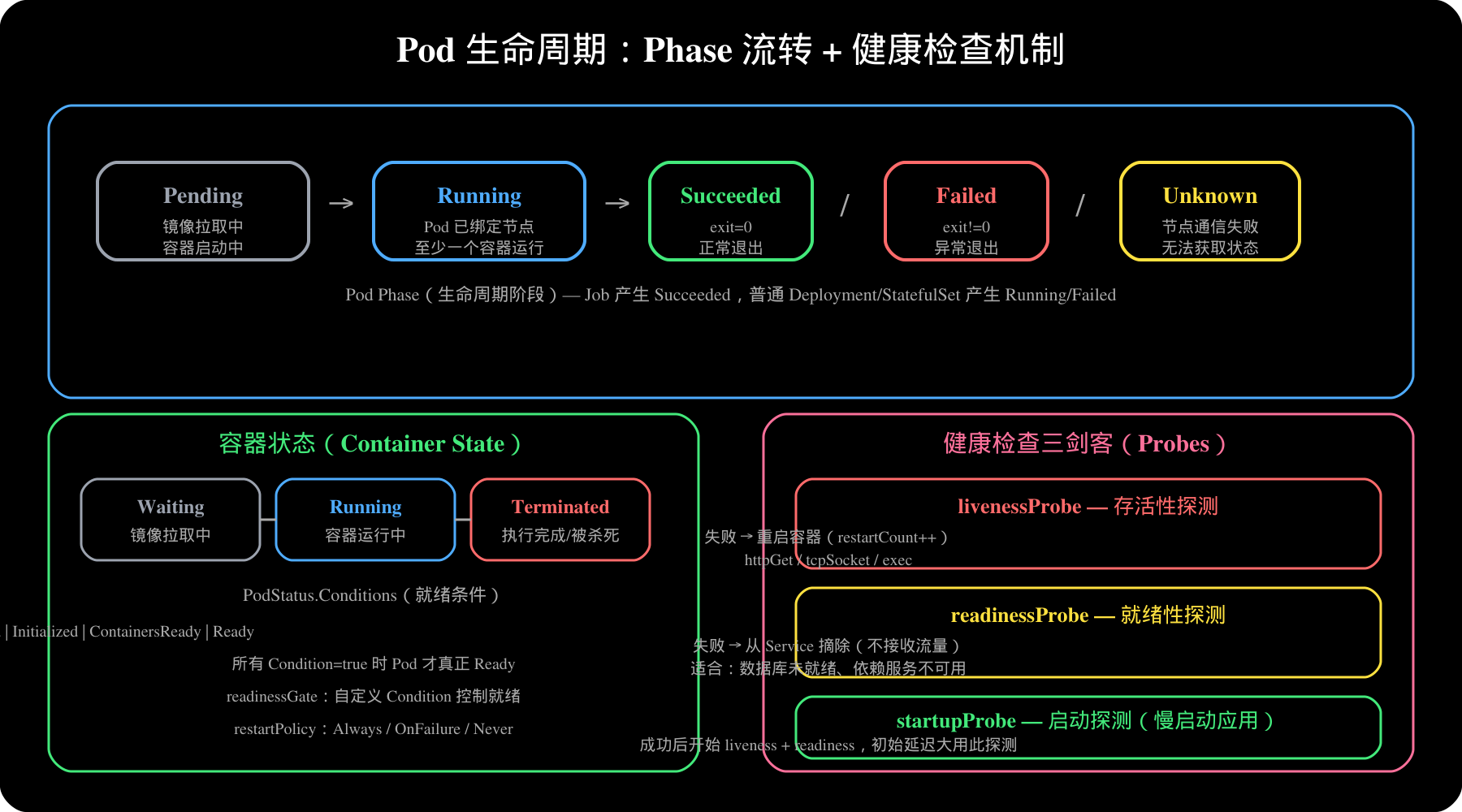
3.1 Pod 的生命周期阶段(Phase)
```
Pending → Running → Succeeded/Failed/Unknown
```
-
**Pending**:Pod 已被 K8s 系统接受,但镜像未拉取或容器未启动
-
**Running**:Pod 已绑定到节点,所有容器已创建,至少有一个在运行
-
**Succeeded**:所有容器正常退出(exit=0),不会重启
-
**Failed**:容器异常退出(exit≠0),超过重启策略限制
-
**Unknown**:节点通信失败,无法获取 Pod 状态
3.2 健康检查(Probes)
```yaml
spec:
containers:
- name: myapp
livenessProbe: # 存活性探测(容器活着吗?)
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
readinessProbe: # 就绪性探测(容器能接收流量吗?)
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
startupProbe: # 启动探测(慢启动容器专用)
httpGet:
path: /started
port: 8080
failureThreshold: 30
periodSeconds: 10
```
| 探测类型 | 作用 | 失败后果 |
|---|---|---|
| livenessProbe | 容器存活检测 | 重启容器 |
| readinessProbe | 流量接入检测 | 从 Service 摘除 |
| startupProbe | 启动完成检测 | 期间不执行其他探针 |
4. Deployment 实战
 4.1 Deployment 的核心职责
4.1 Deployment 的核心职责
Deployment 是 K8s 最常用的 workload 资源,核心职责:
-
管理 ReplicaSet(RS)
-
滚动更新(Rolling Update)
-
回滚(Rollback)
-
扩缩容(Scale)
```
Deployment → ReplicaSet → Pod(×N)
```
核心理解:**Deployment 不直接管理 Pod,它通过 ReplicaSet 间接管理 Pod**。
4.2 完整的 Deployment YAML
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: myapp
version: v1
spec:
replicas: 3
selector: # 必须,与 template.metadata.labels 匹配
matchLabels:
app: myapp
strategy: # 更新策略
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 最多可超出期望副本数
maxUnavailable: 0 # 更新过程中至少保持 N 个可用
minReadySeconds: 10 # 新Pod就绪后等待N秒才认为可用
revisionHistoryLimit: 3 # 保留多少历史版本
paused: false # 暂停更新
template:
metadata:
labels:
app: myapp
version: v1
spec:
containers:
- name: myapp
image: myapp:1.0.0
ports:
- containerPort: 8080
name: http
env:
- name: SPRING_PROFILES_ACTIVE
value: "prod"
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: myapp-config
key: db.host
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: myapp-secret
key: db.password
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 60
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
lifecycle:
preStop:
exec:
command: "/bin/sh", "-c", "sleep 10" # 优雅下线
terminationGracePeriodSeconds: 30 # SIGTERM等待时间
```
4.3 滚动更新 vs 重建策略
```yaml
滚动更新(默认),逐步替换Pod,线上推荐
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 最多额外启动1个Pod
maxUnavailable: 0 # 旧Pod全部更新前不能有任何不可用
重建策略:先删旧Pod再创建新Pod,有服务中断
strategy:
type: Recreate
```
4.4 回滚操作
```bash
查看历史版本
kubectl rollout history deployment/myapp-deployment
回滚到上一个版本
kubectl rollout undo deployment/myapp-deployment
回滚到指定版本
kubectl rollout undo deployment/myapp-deployment --to-revision=2
暂停滚动更新(分批发布)
kubectl rollout pause deployment/myapp-deployment
kubectl rollout resume deployment/myapp-deployment
```
4.5 HPA(水平自动扩缩容)
```bash
创建 HPA,CPU>70% 时扩缩
kubectl autoscale deployment myapp-deployment \
--cpu-percent=70 \
--min=2 --max=10
查看 HPA 状态
kubectl get hpa
```
```yaml
高级 HPA(基于自定义指标,Prometheus + KEDA)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior: # 高级行为控制
scaleDown:
stabilizationWindowSeconds: 300 # 缩容冷却5分钟
policies:
- type: Percent
value: 10
periodSeconds: 60
```
5. Service 与网络
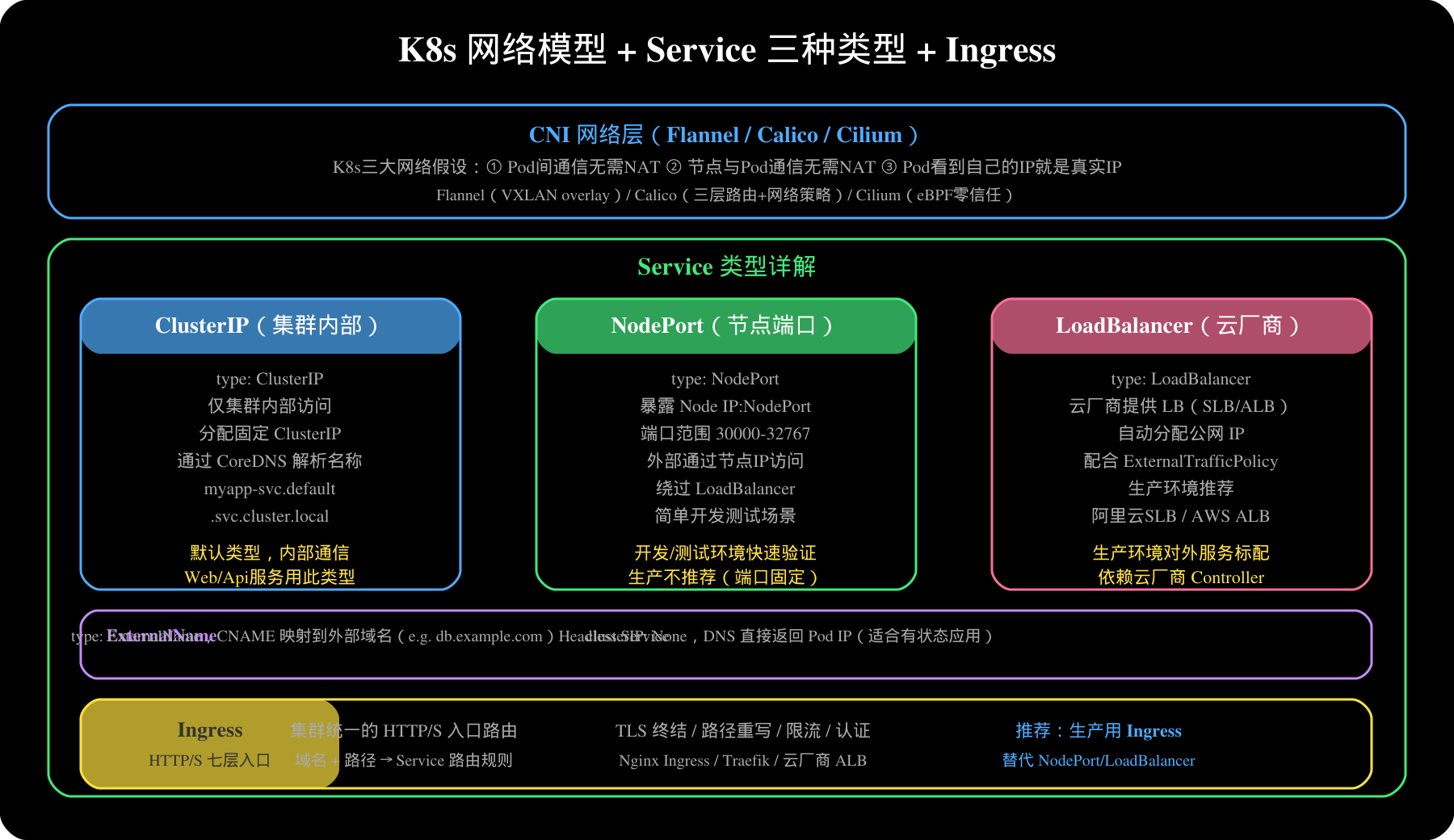
5.1 Service 的四种类型
```yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
spec:
type: ClusterIP # 类型:ClusterIP / NodePort / LoadBalancer / ExternalName
selector:
app: myapp
ports:
- name: http
port: 80 # Service 暴露端口
targetPort: 8080 # 容器端口
protocol: TCP
ClusterIP:集群内部访问(默认)
NodePort:节点端口,外部可通过 <NodeIP>:<NodePort> 访问
LoadBalancer:云厂商负载均衡器(AWS ALB / 阿里SLB)
ExternalName:CNAME 映射到外部域名
```
5.2 Ingress(集群入口)
```yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: myapp.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: myapp-api-svc
port:
number: 80
- path: /
pathType: Prefix
backend:
service:
name: myapp-web-svc
port:
number: 80
```
6. ConfigMap 与 Secret
```bash
从文件创建 ConfigMap
kubectl create configmap myapp-config \
--from-file=application.yml \
--from-literal=server.port=8080
从 env 文件创建 Secret(Base64编码,非加密)
kubectl create secret generic myapp-secret \
--from-literal=db.password=MySecret123 \
--type=Opaque
```
⚠️ **重要**:Secret 只是 Base64 编码,不是加密!生产环境必须配合 EncryptionConfiguration 或 Vault/KMS 方案做加密存储。
7. 面试高频问题汇总
Q1:Pod 挂了,K8s 怎么把它拉起来的?
```
Pod异常 → kubelet上报 → Controller Manager检测到RS副本数不足
→ Deployment Controller 创建/更新 ReplicaSet
→ 调度器选择节点 → kubelet 创建容器 → Pod Running
```
Q2:K8s 是如何实现服务发现的?
-
**集群内部**:每个 Service 被分配一个固定 ClusterIP,通过 CoreDNS 解析 Service 名称
-
DNS 解析:`myapp-svc.namespace.svc.cluster.local`
-
**环境变量**:kubelet 在 Pod 启动时注入所有 Service 的环境变量(`{SVC_NAME}_SERVICE_HOST`)
Q3:如何实现 Pod 的滚动更新不中断服务?
```yaml
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 最多多1个新Pod
maxUnavailable: 0 # 旧Pod必须全部存活
readinessProbe: # 必须配置就绪探针
```
配合 `preStop` 钩子做优雅下线,确保旧 Pod 处理完已有请求后才终止。
Q4:K8s 的网络模型是怎样的?
K8s 要求满足三个网络假设:
-
**Pod间通信无需NAT**:不同 Pod 可以直接通信
-
**节点与Pod通信无需NAT**:节点可直接访问 Pod
-
**Pod看到自己的IP就是真实IP**:不经过 NAT
主流网络插件(CNI):
-
Flannel(VXLAN 封包,overlay网络)
-
Calico(纯三层路由,性能好,支持网络策略)
-
Cilium(基于 eBPF,零信任安全,Linux 5.x+)
Q5:污点(Taint)和容忍(Toleration)是什么?
```bash
为节点打污点:不允许普通Pod调度到此节点
kubectl taint nodes node1 key=value:NoSchedule
Pod 添加容忍:允许调度到有对应污点的节点
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
```
典型使用场景:Master 节点有 NoSchedule 污点,普通 Pod 不能调度到 Master;专用 GPU 节点打污点,只允许 AI 任务调度。
Q6:DaemonSet 是什么?什么场景用?
每个节点运行一个 Pod,节点加入集群时自动在新节点启动,节点移除时自动清理。
使用场景:
-
日志收集(Filebeat、Fluentd)
-
监控代理(Prometheus Node Exporter)
-
网络插件(CNI:如 Calico、Flannel)
8. 总结:K8s 知识图谱
```
Kubernetes 架构
├── 控制平面(Control Plane)
│ ├── kube-apiserver ← 唯一入口,REST API
│ ├── kube-scheduler ← Pod 调度决策
│ ├── kube-controller-manager ← 维护集群期望状态
│ └── etcd ← 状态存储,Raft 一致性
│
├── 工作节点(Node)
│ ├── kubelet ← Pod 创建/管理/汇报
│ ├── kube-proxy ← Service 网络代理
│ └── containerd ← 容器运行时
│
├── Workload 资源
│ ├── Deployment ← 无状态应用(最常用)
│ ├── StatefulSet ← 有状态应用(有序部署)
│ ├── DaemonSet ← 节点守护(每节点1个)
│ ├── Job/CronJob ← 批处理/定时任务
│ └── ReplicaSet ← Deployment 的底层控制器
│
├── 网络
│ ├── Service ← ClusterIP / NodePort / LB
│ ├── Ingress ← HTTP/S 入口
│ └── CNI(Flannel/Calico) ← Pod 网络
│
└── 配置
├── ConfigMap ← 非敏感配置
└── Secret ← 敏感信息(Base64)
```
觉得有用?关注更多硬核技术文章每周更新。