2026年4月23日,OpenAI 发布 GPT-5.5。上下文扩展到 1M tokens,Terminal-Bench 2.0 得分 82.7% 领先 Claude Opus 4.7 超过 13 个百分点。但在 SWE-Bench Pro(代码能力)上,Claude 以 64.3% vs 58.6% 胜出。本文整理接入代码和场景选型建议。
一、模型参数
| 参数 | GPT-5.5 |
|---|---|
| 上下文窗口 | 1,000,000 tokens |
| 多模态 | 文本 + 视觉(输入) |
| 推理模式 | 显式 CoT |
| 标准定价 | 5 / 30 per M(输入/输出) |
| Pro 定价 | 30 / 180 per M |
| 缓存输入 | $0.50 per M |
| Batch 折扣 | 50% |
二、Benchmark 对比
| 评测 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | --- |
| ARC-AGI-2 | 85.0% | 75.8% | 77.1% |
| SWE-Bench Pro | 58.6% | 64.3% | --- |
| FrontierMath T4 | 39.6% | 22.9% | --- |
| GPQA Diamond | ~93.5% | 94.2% | 94.3% |
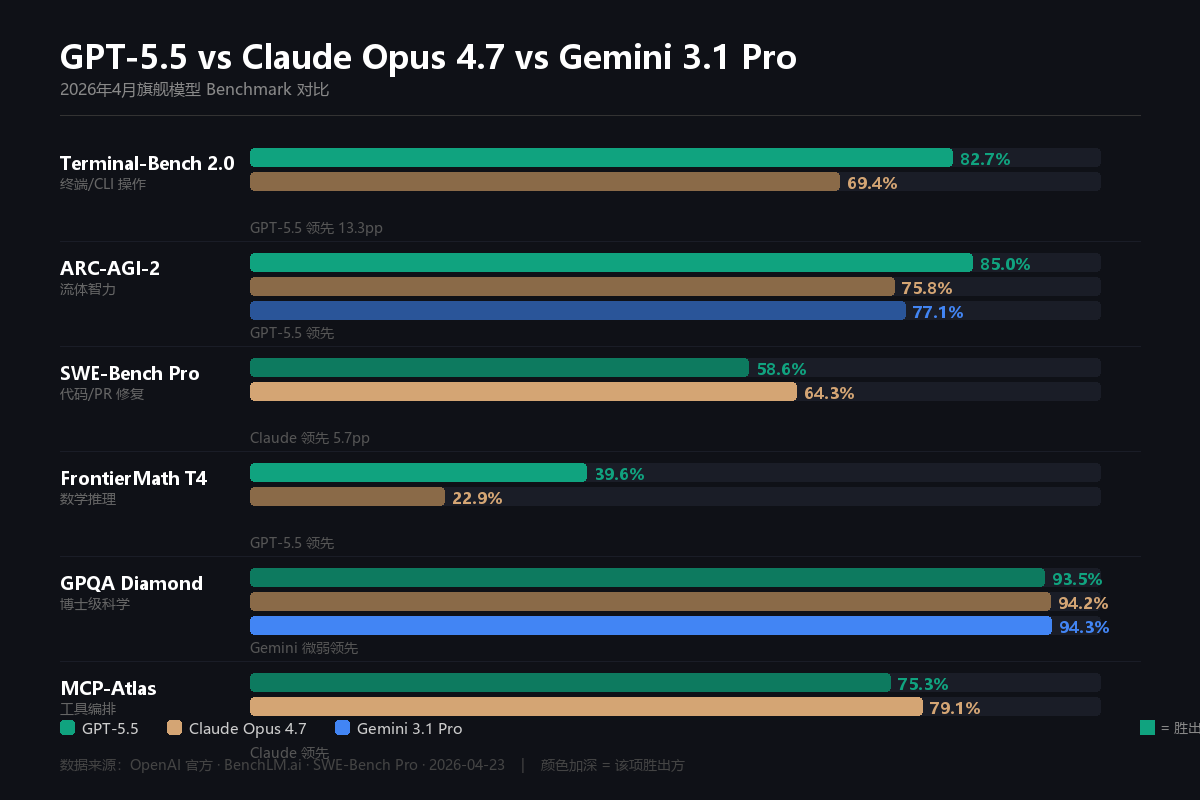
要点: Agent/终端任务选 GPT-5.5;复杂代码任务选 Claude Opus 4.7;高频低成本调用选 Gemini 3.1 Pro。三款模型各有所长。
三、接入代码(数眼智能海外站)
python
from openai import OpenAI
# 数眼智能海外站接入配置
client = OpenAI(
api_key="sk-xxx", # dataeyes.ai 后台获取
base_url="https://cloud.dataeyes.ai/v1"
)
# 基础对话
def chat(prompt: str) -> str:
resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": prompt}],
max_tokens=8192
)
return resp.choices[0].message.content
# 终端命令分析示例
result = chat("分析以下 nginx 错误日志,找出根本原因:\n[粘贴日志内容]")
print(result)四、长上下文用法
python
# 1M 上下文:整个项目一次性扔进去
import os
code_files = []
for root, dirs, files in os.walk("./src"):
for f in files:
if f.endswith((".py", ".js", ".ts")):
path = os.path.join(root, f)
with open(path, "r") as fh:
code_files.append(f"--- {path} ---\n{fh.read()}")
all_code = "\n\n".join(code_files)
resp = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "user", "content": f"以下是整个项目代码,请做全局架构分析:\n\n{all_code}"}
],
max_tokens=16384
)
print(resp.choices[0].message.content)注意:超过 272K tokens 时会触发长上下文附加费(输入 2×,输出 1.5×),控制好输入长度。
五、从 GPT-5.4 迁移
python
# 改前
model="gpt-5.4"
# 改后
model="gpt-5.5"迁移注意:
- 输出价格从 15 涨到 30 per M,翻倍
- 16K--64K 区间表现略弱于 GPT-5.4
- 如果不需要 1M 上下文和 Agent 增强,可继续使用 GPT-5.4 节省成本
六、价格对比
| 模型 | 输入($/ M tokens) | 输出($/ M tokens) |
|---|---|---|
| GPT-5.5 | $5 | $30 |
| GPT-5.5(Batch) | $2.50 | $15 |
| Claude Opus 4.7 | $5 | $25 |
| Gemini 3.1 Pro | $2 | $12 |
GPT-5.5 是目前标准旗舰中定价较高的。成本敏感场景可以用 Batch API(半价)或选 Gemini 3.1 Pro。
七、FAQ
Q:GPT-5.5 和 Claude Opus 4.7 怎么选?
终端自动化/Agent 任务选 GPT-5.5(Terminal-Bench 领先 13 个百分点);多文件代码重构选 Claude(SWE-Bench Pro 领先 5.7 个百分点)。
Q:1M 上下文实用吗?
512K--1M 区间的召回准确率从 GPT-5.4 的 36.6% 提升到 74.0%,已经比较可用了。但 >272K 有附加费,建议先评估是否真需要这么长的输入。
Q:幻觉问题严重吗?
第三方评测显示幻觉率约 86%,高于 Claude Opus 4.7 的约 36%。对事实准确性要求高的场景建议增加验证环节。
API Key 申请:数眼智能海外站