你的 GPU 为什么在摸鱼?------存储金字塔、带宽瓶颈与 Roofline 模型
"Data movement is the enemy." ------ Bill Dally,NVIDIA 首席科学家
你有没有遇到过这种情况:花了大价钱租了一台 A100 服务器,跑起训练后打开 nvtop 一看,GPU 利用率在 30%~70% 之间反复横跳,就是上不去。
你检查了模型结构,没问题。你检查了 batch size,也没问题。但 GPU 就是在摸鱼。
这章就来解释这个现象的根本原因------你的 GPU 大部分时间在等数据,而不是在算数据。
1.1 存储金字塔:数据住在哪里
在算法课上,我们把内存抽象成一个随机访问的数组,读任何一个元素的代价都是 O(1)。这个抽象非常好用,让我们可以专注于算法本身。
但在物理世界里,这是个谎言。
计算机的存储系统是一个严格的层次结构------越靠近处理器核心,速度越快,造价越贵,容量也越小。
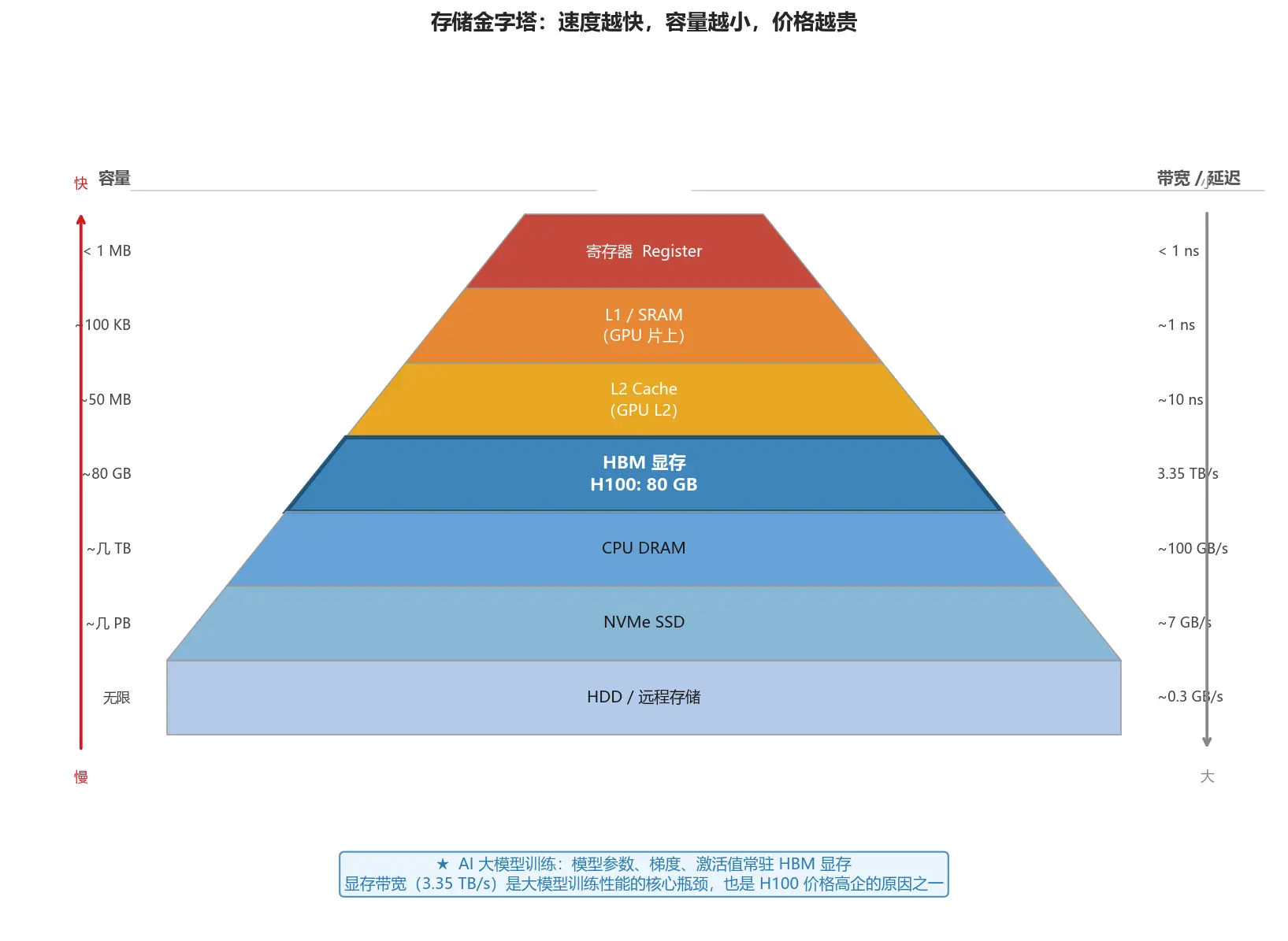
图:从上到下,速度依次降低,容量依次增大。AI 训练主要在 HBM(GPU 显存)这一层发生。
下面逐层拆解,重点放你在 AI 工作中真正会碰到的部分。
寄存器(Register File)
金字塔最顶端是处理器核心内部的寄存器------CPU/GPU 直接操作的存储单元,和算力核心处于同一片芯片,访问延迟不到 1 纳秒,带宽超过 10 TB/s。
但它极度稀缺。GPU 每个 SM(流多处理器)约有 256 KB 寄存器空间,每个线程能分到的寥寥无几。寄存器用超了,变量就会被"溢出"(Register Spill)到 L2 甚至 HBM,性能骤降。这是编写高性能 CUDA Kernel 时必须精细管控的资源之一。
L1/L2/L3 Cache 与 GPU Shared Memory(片上内存)
Cache 是 CPU/GPU 核心旁边的"随身小仓库",用 SRAM(静态随机存储器)制造。SRAM 的每个 bit 需要 6 个晶体管,造价昂贵,但存取速度极快。
在 GPU 上,对应的概念是 Shared Memory(共享内存)------每个 SM 约 100 KB 的片上 SRAM,由同一 Block 内的所有线程共享,访问延迟约 5 个时钟周期,是 HBM 的百倍以上。把数据先加载到 Shared Memory、反复复用,然后再写回 HBM,是绝大多数 GPU 性能优化的核心套路。FlashAttention 就是把这套思路发挥到极致的典型案例(详见第 13 章)。
关键概念是 Cache Hit(命中) 和 Cache Miss(未命中):
- Cache Hit:CPU 需要的数据恰好在 Cache 里,直接取走,只要 1~4 个时钟周期。
- Cache Miss:数据不在 Cache 里,CPU 必须停下来,去更慢的存储层取,等待几十到几百个周期。
对 AI 来说最直接的影响是:矩阵乘法为什么要做 Tiling(分块)?就是为了让小块矩阵能塞进 L1/L2 Cache 或 GPU Shared Memory,反复复用,而不是每次计算都跑去 HBM 取数据。
HBM(高带宽内存)------大模型的命门
HBM(High Bandwidth Memory) 是高端 GPU 专用的显存,是整个大模型训练生态里最核心的硬件瓶颈。
HBM 和普通 DRAM 的物理结构不同:它把多个 DRAM 芯片通过 TSV(硅穿孔)技术垂直堆叠,就像在一小块基板上盖了一栋"内存大楼",然后用极宽的总线连接到 GPU 核心。
这带来了惊人的带宽:
- 普通 DDR5 内存:~100 GB/s
- NVIDIA H100 HBM3:~3.35 TB/s,是普通内存的 30 多倍
科普:HBM 占高端 GPU 制造成本的很大比例,这也是为什么 A100/H100 那么贵。买的不是算力,相当程度上买的是带宽。
SSD / HDD
训练过程中尽量别频繁读写磁盘,除了 DataLoader 预取阶段。即便是最快的 NVMe SSD,和内存相比也差了 3 个数量级。
一张表看清楚
把各层关键参数汇总,方便日后参考:
| 存储层 | 典型容量(H100) | 峰值带宽 | 访问延迟 |
|---|---|---|---|
| 寄存器 Register | < 1 MB/SM | > 10 TB/s | < 1 ns |
| Shared Memory / L1 | ~100 KB/SM | ~10 TB/s | ~1 ns |
| L2 Cache | ~50 MB | ~5 TB/s | ~10 ns |
| HBM 显存 | 80 GB | 3.35 TB/s | ~200 ns |
| CPU DRAM | 几 TB | ~100 GB/s | ~100 ns |
| NVMe SSD | 几 TB~PB | ~7 GB/s | ~100 μs |
| HDD | 无限 | ~0.3 GB/s | ~10 ms |
常见误区:带宽大不等于延迟低。HBM 带宽高达 3.35 TB/s,但延迟仍有 200 ns,比 Shared Memory 慢 200 倍。GPU 用"跑足够多的并发线程"来掩盖这个延迟,而不是靠加速单次访问。
1.2 延迟 vs 带宽:不要混淆这两个概念
这是两个经常被一起提起但含义截然不同的词:
- 延迟(Latency) :从发出请求到收到第一个字节的时间。水管有多长。
- 带宽(Bandwidth) :单位时间内能传输的数据总量。水管有多粗。
用一个不那么学术的比喻:
| 延迟 | 带宽 | |
|---|---|---|
| 法拉利跑车送 U 盘 | 极低 | 极低(一次就几 GB) |
| 满载卡车跑高速 | 很高(得等装卸) | 极高(一次几十吨) |
GPU 就是那辆卡车:它容忍高延迟,但极其依赖高带宽。
GPU 的设计哲学是用并发掩盖延迟------当一批线程在等内存数据时,调度器立刻切换到另一批已经准备好数据的线程继续计算。这就是为什么 GPU 要同时跑成千上万个线程,而不是追求单线程的极速响应。
1.3 数据搬运的代价
冯·诺依曼瓶颈
在冯·诺依曼架构里,计算单元和存储单元是分离的,数据必须通过总线来回传输。
现代 GPU 的算力和带宽数字放一起,差距触目惊心:
| H100 SXM | |
|---|---|
| BF16 算力 | ~989 TFLOPS( ≈1015 次/秒) |
| HBM3 带宽 | ~3.35 TB/s( ≈3.35×1012 字节/秒) |
换算一下:GPU 每秒能算的次数,是它能搬运字节数的大约 295 倍。
这意味着如果你的算法每次运算都需要重新从显存读一次数据,那 GPU 的算力单元有 99% 的时间在空转等数据。这就是所谓的 Memory-Bound(带宽受限)。
CPU → GPU:PCIe 传输瓶颈
除了 GPU 内部的 HBM 瓶颈,还有一道常被忽视的关口:数据从 CPU 内存搬到 GPU 显存,要经过 PCIe 总线。
| 链路 | 双向峰值带宽 |
|---|---|
| PCIe 4.0 × 16 | ~64 GB/s |
| PCIe 5.0 × 16 | ~128 GB/s |
| NVLink 4(H100 GPU 间) | ~900 GB/s |
PCIe 4.0 x16 双向带宽(64 GB/s)只有 HBM 的约 1/50。一旦 DataLoader 来不及把数据提前送进显存,GPU 训练完一个 batch 就得干等,利用率直接垮掉。
这正是第 11 章 DataLoader 优化里 pin_memory=True 和 num_workers 如此关键的原因:pin_memory 让 CPU 内存页面物理地址固定,GPU DMA 引擎可以绕过 CPU 直接搬运(比普通拷贝快 20%~50%);num_workers 让数据在后台异步准备,GPU 永远有下一个 batch 随时可取。
核心结论:数据搬运有两道关口------GPU 内部的 HBM 瓶颈,以及 CPU→GPU 的 PCIe 瓶颈。绝大多数训练性能问题都出在这两处,而不是算力不够。
算术强度
为了量化"一段代码到底是在算还是在搬",引入 算术强度(Arithmetic Intensity) ,记作 I:
I=显存读写字节数(Bytes)浮点运算次数(FLOPs)
单位是 FLOP/Byte,直白理解就是:每搬一字节数据,能顺带做多少次计算。
两个经典例子对比:
例一:向量加法 c=a+b( N 个 float16 元素)
- 计算量: N 次加法 → N FLOPs
- 访存量:读 a( 2N B)+ 读 b( 2N B)+ 写 c( 2N B)= 6N 字节
- I=N/6N≈0.17 FLOP/Byte
例二:矩阵乘法 C=AB( N×N 方阵,float16)
- 计算量: 2N3 FLOPs
- 访存量: 3N2×2 字节 =6N2 字节
- I=2N3/6N2=N/3 FLOP/Byte
随着 N 增大,矩阵乘法的算术强度线性增长。这就是深度学习如此依赖矩阵乘法的物理原因------它天然是 Compute-Bound,能把 GPU 的算力充分利用起来。
Roofline 模型
把上面的逻辑画成图,就是性能分析里最著名的 Roofline 模型:
可达算力=min(峰值算力, 峰值带宽×I)
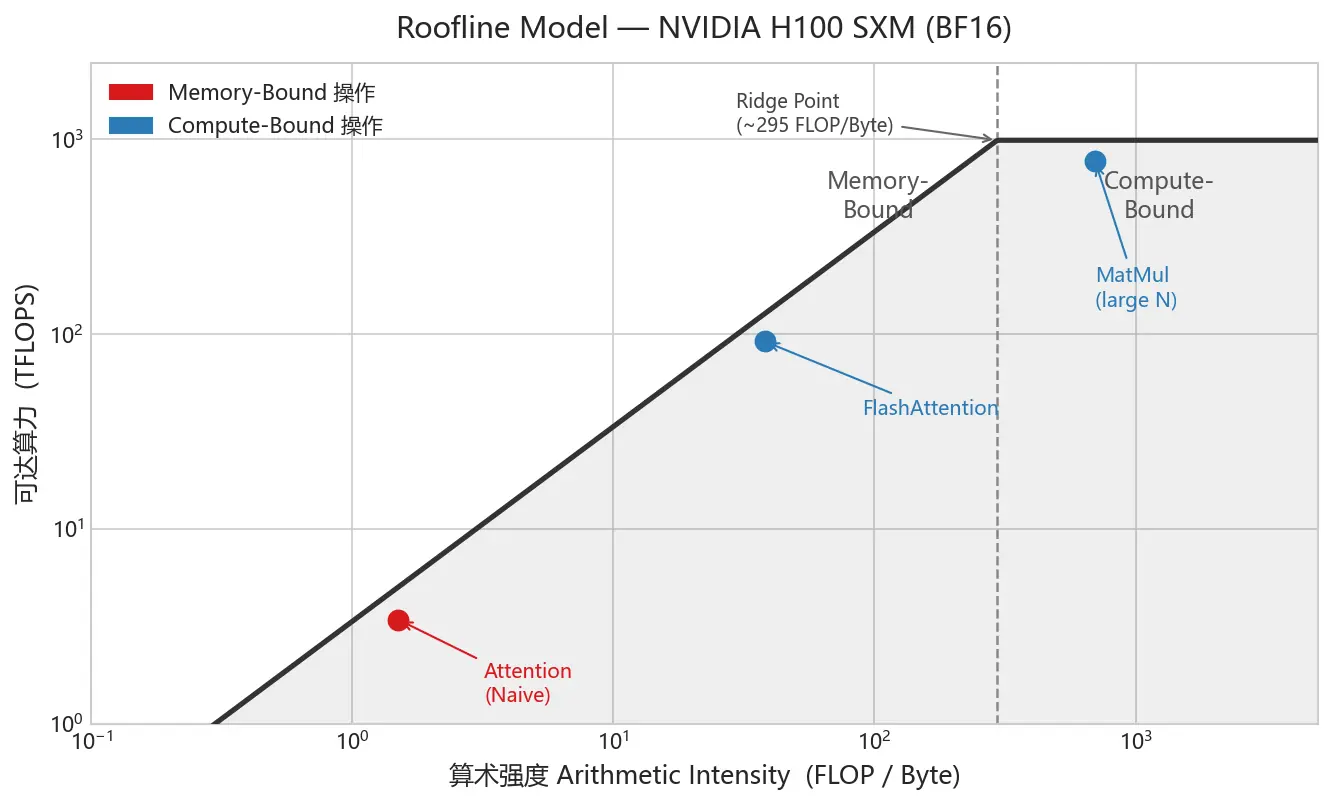
图:H100 BF16 的 Roofline 图。横轴是算术强度,纵轴是可达算力(TFLOPS,对数坐标)。左侧斜坡区是带宽限制区,右侧平顶区是算力限制区,两者交汇处是 Ridge Point(~295 FLOP/Byte)。
读图的方式很直接:
- 落在斜坡区(左侧)的操作:Memory-Bound,即便加再多算力核心也没用,瓶颈在带宽。向量加法、ElementWise 操作都在这里。
- 落在平顶区(右侧)的操作:Compute-Bound,带宽已经够用了,瓶颈是算力核心忙不过来。大矩阵乘法在这里。
- Naive Attention 在斜坡区很深的位置:这是问题所在,下一节详细说。
动手试试:想知道你的模型哪个算子是瓶颈?
bash# 用 PyTorch Profiler 快速分析 python -c " import torch from torch.profiler import profile, ProfilerActivity # ... 把你的模型前向传播放在这里 ... with profile(activities=[ProfilerActivity.CUDA]) as prof: output = model(x) print(prof.key_averages().table(sort_by='cuda_time_total', row_limit=10)) "
1.4 案例:为什么 Attention 是 Memory-Bound?
Transformer 的核心计算:
Attention(Q,K,V)=softmax(dk QK⊤)V
标准实现的流程是这样的:
- 计算 S=QK⊤,得到 N×N 的矩阵( N 是序列长度)
- 把 S 写回 HBM
- 从 HBM 读出 S,做 Softmax
- 把 Softmax 结果写回 HBM
- 从 HBM 读出结果,乘以 V
注意步骤 2~4:一个 N×N 的中间矩阵被完整地写进显存、再完整地读出来 。当 N=8192(长文本),float16 精度下,这个矩阵占 128 MB。每个 Attention 层来回搬运一次,效率极低。
算术强度大约只有 1~2 FLOP/Byte,远低于 H100 的 Ridge Point(295 FLOP/Byte)。从 Roofline 图上看,它深陷在斜坡区底部,99% 的时间在等显存 I/O,真正用于矩阵乘法的时间很少。
FlashAttention 的解法是:不把 N×N 的矩阵写回 HBM。它把 Q,K,V 分成小块(Tiling),每块加载到 GPU 的片上 SRAM(Shared Memory),在 SRAM 里一口气算完这块的 Softmax 和加权求和,然后把最终结果写回 HBM。整个过程只读写一次 HBM,中间矩阵从未落地。
这就是为什么 FlashAttention 在 Roofline 图上从斜坡区跳到了更靠右的位置------它本质上不是通过减少计算量,而是通过减少显存读写次数来提速的。
核心结论 :在 AI 系统优化中,减少 HBM 访问次数 往往比减少 FLOPs更重要。很多"优化"操作(算子融合、FlashAttention、Paged Attention)的本质都是在节省显存 I/O,而不是在减少计算量。
常见误区:很多人看到 GPU 利用率低就直觉地认为"算力不够",实际上大概率是 Memory-Bound------显存带宽已经跑满了,而算力核心大部分时间在空等。用 Roofline 模型定性分析一下,方向就对了。