文章目录
- [1. 概述](#1. 概述)
- [2. API 概述](#2. API 概述)
-
- [2.1 VectorStoreRetriever 接口](#2.1 VectorStoreRetriever 接口)
- [2.2 VectorStore 接口](#2.2 VectorStore 接口)
- [2.3 SearchRequest 构建器](#2.3 SearchRequest 构建器)
- [3. 集成 Milvus 向量数据库](#3. 集成 Milvus 向量数据库)
-
- [3.1 Milvus 简介](#3.1 Milvus 简介)
- [3.2 Docker Compose 部署](#3.2 Docker Compose 部署)
- [3.3 自动配置(推荐)](#3.3 自动配置(推荐))
-
- [3.3.1 依赖引入](#3.3.1 依赖引入)
- [3.3.2 YAML 配置](#3.3.2 YAML 配置)
- [3.3.3 完整配置参数](#3.3.3 完整配置参数)
- [3.3.4 MilvusVectorStoreAutoConfiguration](#3.3.4 MilvusVectorStoreAutoConfiguration)
- [3.4 业务方法](#3.4 业务方法)
1. 概述
向量数据库是面向 AI 原生场景设计的专用数据库系统,核心用于高维向量存储、向量索引构建、海量相似度检索。
与传统关系型数据库、文档数据库存在本质差异:
- 传统数据库:依赖关键词、字段的精确匹配完成查询,无法理解数据间的语义关联;
- 向量数据库 :依托高维空间几何运算与近似最近邻索引算法(
ANN),以向量相似度计算为核心能力,实现语义级模糊检索、特征聚类、内容匹配等高级能力。
向量数据库是实现检索增强生成 (RAG)的核心基础设施,解决 AI 模型无法直接访问私有数据、知识滞后的问题,核心流程如下:
- 数据预处理与入库:将私有文档、知识库数据转换为高维向量,存储到向量数据库中,并关联元数据;
- 用户提问向量化 :用户输入的问题通过
Embedding模型转换为查询向量; - 相似度检索:向量数据库基于查询向量进行相似度搜索,召回与问题语义最相关的文档片段;
- 上下文拼接与生成:将召回的文档片段作为上下文,与用户问题一同发送给大语言模型,生成基于私有数据的精准回答。
2026 年主流向量数据库对比(按热度与生态成熟度排序):
| 名称 | 来源 | 核心优势 | 适用场景 |
|---|---|---|---|
| Milvus | 中国Zilliz(星爵科技)研发,LF AI & Data基金会毕业项目 | 全球最活跃的企业级开源向量库,分布式、云原生架构,支持千亿级向量,国内生态完善,与Spring AI、LangChain、LlamaIndex深度集成 | 企业级私有化部署、大规模RAG生产落地、分布式向量检索 |
| Pinecone | 美国Pinecone Inc.(2019年成立) | 全托管SaaS向量库开创者,零运维、全球多区域部署,自动扩缩容,OpenAI/Anthropic官方推荐 | 快速原型开发、企业级全托管场景、全球化AI应用 |
| Qdrant | 俄罗斯Qdrant Solutions GmbH,Rust开发 | 极致性能(p50延迟约4ms,多项基准测试领先),轻量二进制部署,过滤能力强,社区增长极快 | 高并发低延迟场景、高性能向量检索、轻量部署 |
| Weaviate | 荷兰Weaviate B.V.(2019年开源) | 向量+知识图谱(RDF)混合引擎,语义理解能力强,内置RAG、多模态与混合搜索(向量+BM25)能力成熟 | 知识图谱场景、多模态语义检索、金融/医疗复杂语义场景 |
| pgvector | 开源项目,由Andrew Kane主导开发,PostgreSQL扩展 | 无需新增组件,直接在现有PostgreSQL上扩展向量能力,完整支持ACID事务与SQL,数据一致性强 | 中小规模混合检索、现有PostgreSQL生态复用、结构化+向量混合数据场景 |
| Chroma | 美国Chroma Inc.,Python开源项目 | 极简轻量,开箱即用,一行代码启动,专为LLM原型设计,被称为"AI应用的SQLite",与LangChain/LlamaIndex默认集成 | 本地开发、原型验证、轻量RAG应用 |
| FAISS | Meta(Facebook)AI研究院开源 | 工业级向量算法库,支持HNSW、IVF、PQ、GPU加速等最全索引算法,是多数向量数据库的底层依赖,与PyTorch/TensorFlow无缝集成 | 科研/训练场景、自定义向量引擎开发、GPU加速的大规模向量计算 |
2. API 概述
Spring AI 提供了一套抽象化 API,通过 VectorStore 接口(读写)和 VectorStoreRetriever 接口(只读)与向量数据库交互。
2.1 VectorStoreRetriever 接口
Spring AI 提供了只读接口 VectorStoreRetriever,仅暴露文档检索能力:
java
@FunctionalInterface
public interface VectorStoreRetriever {
List<Document> similaritySearch(SearchRequest request);
default List<Document> similaritySearch(String query) {
return this.similaritySearch(SearchRequest.builder().query(query).build());
}
}该函数式接口专为仅需检索、无需修改数据 的场景设计,遵循最小权限原则,仅暴露必要的检索功能。
similaritySearch 方法支持通过以下参数精细化控制检索结果:
k: 整数类型,指定返回的最大相似文档数量 ,即Top K检索(K 近邻算法KNN)。threshold:0~1之间的浮点数,数值越接近 1 表示相似度要求越高。 例:设置阈值0.75,仅返回相似度高于0.75的文档。Filter.Expression:流式DSL领域特定语言,作用等价于SQL的WHERE条件,仅对文档元数据生效。filterExpression:基于ANTLR4的外部DSL,支持字符串格式的过滤表达式。示例,country == 'UK' && year >= 2020 && isActive == true
2.2 VectorStore 接口
VectorStore 继承自 VectorStoreRetriever,并新增了数据修改能力:
java
public interface VectorStore extends DocumentWriter, VectorStoreRetriever {
default String getName() {
return this.getClass().getSimpleName();
}
void add(List<Document> documents);
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... }
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}VectorStore 整合了读写操作 ,支持向向量数据库添加、删除、检索文档。
向量数据库插入数据时,需将数据封装为 Document 对象:
Document:封装PDF/Word等数据源的文本内容 + 键值对元数据(如文件名);- 数据入库时,会通过嵌入模型 (
EmbeddingModel)将文本转为数值数组 ,即向量嵌入 (vector embeddings); - 常用嵌入模型:
Word2Vec、GLoVE、BERT、OpenAItext-embedding-ada-002; - 向量数据库只负责存储和检索 ,不生成向量嵌入,嵌入工作由
EmbeddingModel完成。
以下是 VectorStore 接口的所有可用实现:
Azure Vector Search:Azure向量数据库Apache Cassandra:Apache Cassandra向量数据库Chroma Vector Store:Chroma向量数据库Elasticsearch Vector Store:Elasticsearch向量数据库GemFire Vector Store:GemFire向量数据库MariaDB Vector Store:MariaDB向量数据库Milvus Vector Store:Milvus向量数据库MongoDB Atlas Vector Store:MongoDB Atlas向量数据库Neo4j Vector Store:Neo4j向量数据库OpenSearch Vector Store:OpenSearch向量数据库Oracle Vector Store:Oracle数据库向量数据库PgVector Store:PostgreSQL/PGVector向量数据库Pinecone Vector Store:Pinecone向量数据库Qdrant Vector Store:Qdrant向量数据库Redis Vector Store:Redis向量数据库SAP Hana Vector Store:SAP HANA向量数据库Typesense Vector Store:Typesense向量数据库Weaviate Vector Store:Weaviate向量数据库SimpleVectorStore:简易向量存储实现,仅用于测试
注意:
SimpleVectorStore不适用于生产环境,仅用于测试/演示。
2.3 SearchRequest 构建器
SearchRequest 用于封装检索请求参数,核心代码如下:
java
public class SearchRequest {
public static final double SIMILARITY_THRESHOLD_ACCEPT_ALL = 0.0;
public static final int DEFAULT_TOP_K = 4;
private String query = "";
private int topK = DEFAULT_TOP_K;
private double similarityThreshold = SIMILARITY_THRESHOLD_ACCEPT_ALL;
@Nullable
private Filter.Expression filterExpression;
// 构建器 + getter 方法省略
}核心参数:
query:检索查询文本topK:返回最相似的文档数量(默认4)similarityThreshold:相似度阈值(0~1,默认0不过滤)filterExpression:元数据过滤表达式
3. 集成 Milvus 向量数据库
提示 :基于上篇嵌入模型相关代码!!!因为 MilvusVectorStore 依赖于 EmbeddingModel ,所以需要先集成嵌入模型
3.1 Milvus 简介
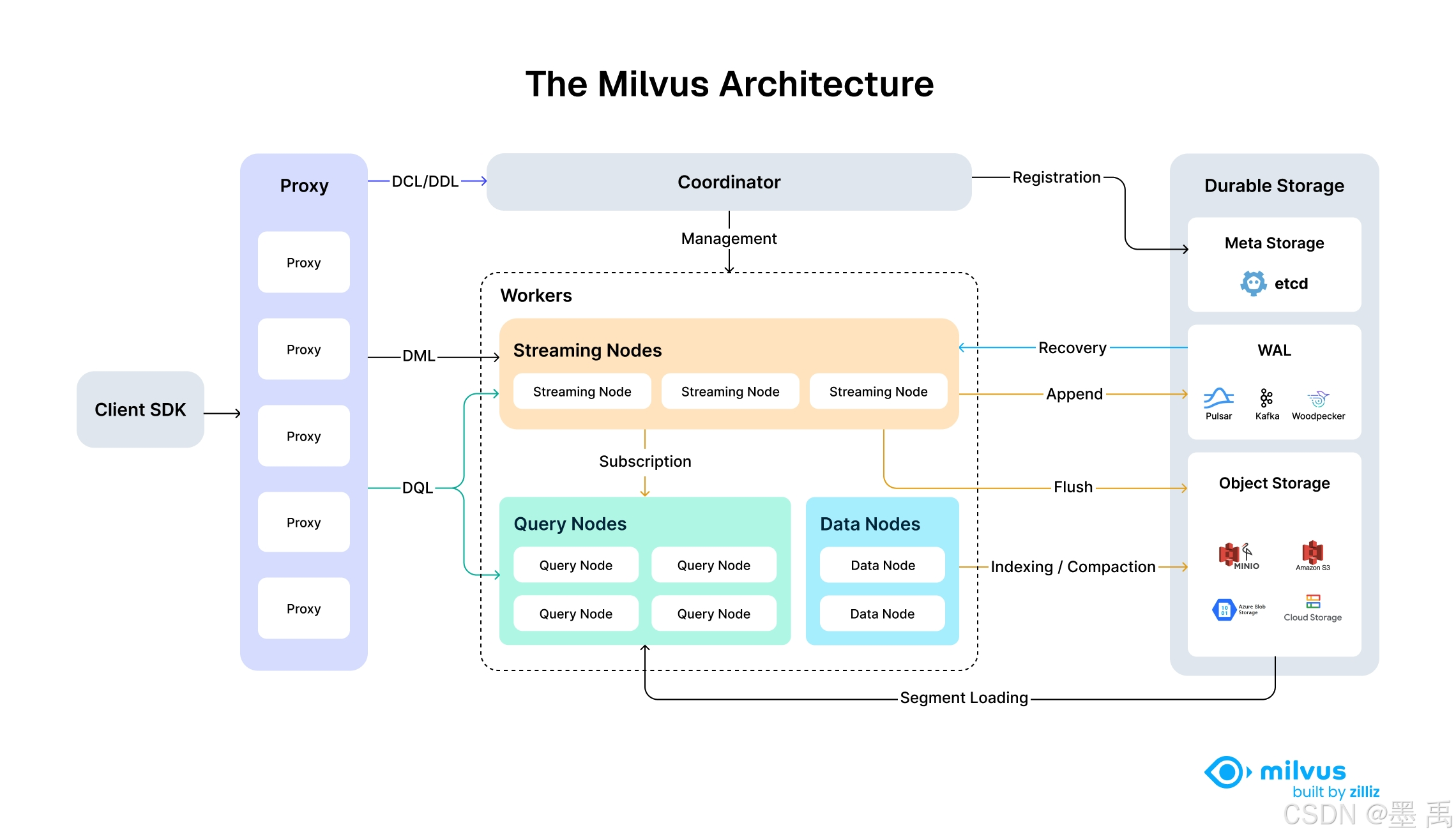
Milvus 是由中国 Zilliz(星爵科技) 主导开发、LF AI & Data 基金会毕业的开源企业级分布式向量数据库 ,也是目前全球企业级落地最广泛的向量数据库之一,国内私有化 RAG 场景的首选方案。
核心优势:
- 分布式云原生架构 :支持分片集群、动态扩容,可稳定承载千亿级向量数据,适配大规模业务场景;
- 高效检索能力 :内置
HNSW、IVF系列、FLAT等多种向量索引,支持CPU/GPU混合加速,亿级数据上实现毫秒级语义召回; - 企业级混合检索:原生支持「向量语义检索 + 结构化条件过滤」,可结合时间、标签、权限等业务字段做精准筛选;
- 丰富生态兼容 :与
LangChain、LlamaIndex、Spring AI等主流AI框架深度集成,提供Python/Java/Go等多语言SDK,私有化部署友好; - 开源可商用 :基于
Apache 2.0协议开源,无商用限制,国内社区与技术支持完善。
典型应用场景:
- 企业级私有化
RAG知识库 - 大规模多模态检索(文本/图像/视频/音频)
- 推荐系统与用户行为向量分析
- 内容风控、违规内容相似度匹配
3.2 Docker Compose 部署
Milvus 主要支持的部署方式:
- 单机版:支持
Docker、Operator、Helm、DEB/RPM、Docker Compose部署 - 集群版:支持
Operator、Helm部署
要使用 Docker Compose 安装 Milvus,只需运行:
bash
wget https://github.com/milvus-io/milvus/releases/download/v2.6.15/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo docker compose up -d
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done可以加上 Milvus 可视化管理工具 Attu :
java
attu:
container_name: milvus-attu
image: zilliz/attu:v2.4
environment:
MILVUS_URL: milvus-standalone:19530
ports:
- "9021:3000"
depends_on:
- "standalone"访问 http://{ip}:9021/ 控制台:
3.3 自动配置(推荐)
3.3.1 依赖引入
Maven 依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>包含以下子依赖:

3.3.2 YAML 配置
在 application.yml 中配置 Milvus 连接参数:
yaml
spring:
ai:
# 通过 spring.ai.vectorstore.type 选择向量存储类型
# - simple: 内存向量存储 (默认,适合开发测试,重启数据丢失)
# - milvus: Milvus 向量数据库 (生产环境推荐,支持大规模向量检索)
vectorstore:
type: milvus # 当前使用内存存储,切换到 Milvus 改为: milvus
# Milvus 配置 (仅当 type=milvus 时生效)
# Milvus 是开源向量数据库,支持多种索引类型和度量方式
milvus:
client:
host: 192.168.1.111 # Milvus 服务地址
port: 19530 # Milvus gRPC 端口
username: root # 用户名
password: milvus # 密码
database-name: default # 数据库名称
collection-name: vector_store # Collection 名称 (类似表名)
embedding-dimension: 1024 # 向量维度 (OpenAI:1536, 智谱:1024)
index-type: IVF_FLAT # 索引类型: FLAT, IVF_FLAT, IVF_SQ8, IVF_PQ, HNSW, DISKANN
metric-type: COSINE # 度量类型: L2(欧氏距离), IP(内积), COSINE(余弦相似度)
initialize-schema: true # 自动创建 Collection 和索引3.3.3 完整配置参数
Milvus 客户端连接配置前缀 spring.ai.vectorstore.milvus.client :
| 配置属性 | 中文说明 | 默认值 | 备注 |
|---|---|---|---|
| secure | 是否启用 TLS 安全连接 | false | 为 true 时才生效各类 SSL 证书配置 |
| host | Milvus 服务地址 | localhost | 服务域名/IP |
| port | Milvus 服务端口 | 19530 | 取值范围 1~65535 |
| uri | Milvus 实例连接地址 | 空 | 可替代 host+port 方式连接 |
| token | 身份认证令牌 | 空 | 用于接口鉴权 |
| connectTimeoutMs | 客户端连接超时时间(毫秒) | 10000 | 必须大于0 |
| keepAliveTimeMs | 通道保活时间(毫秒) | 55000 | 必须大于0 |
| keepAliveTimeoutMs | 保活超时时间(毫秒) | 20000 | 必须大于0 |
| rpcDeadlineMs | RPC 请求响应超时时间(毫秒) | 0 | 0 表示禁用超时限制 |
| clientKeyPath | TLS 双向认证客户端私钥路径 | 空 | 仅 secure=true 生效 |
| clientPemPath | TLS 双向认证客户端证书路径 | 空 | 仅 secure=true 生效 |
| caPemPath | TLS 根证书路径 | 空 | 仅 secure=true 生效 |
| serverPemPath | TLS 单向认证服务端证书路径 | 空 | 仅 secure=true 生效 |
| serverName | SSL 主机名校验覆盖名称 | 空 | 透传给 grpc.ssl_target_name_override |
| idleTimeoutMs | 连接通道空闲超时时间(毫秒) | 24小时 | 超时自动释放空闲连接 |
| username | 登录用户名 | root | Milvus 默认账号 |
| password | 登录密码 | milvus | Milvus 默认密码 |
Milvus 向量存储业务配置前缀 spring.ai.vectorstore.milvus :
| 配置属性 | 中文说明 | 默认值 | 备注 |
|---|---|---|---|
| databaseName | Milvus 数据库名称 | default | 不可为空 |
| collectionName | 向量集合名称 | vector_store | 不可为空 |
| embeddingDimension | 向量嵌入维度 | 1536 | 适配 OpenAI 默认维度,必须大于0 |
| indexType | 向量索引类型 | IVF_FLAT | 枚举类型,见下文 |
| metricType | 向量相似度度量类型 | COSINE | 枚举类型,见下文 |
| indexParameters | 索引自定义参数 JSON | {"nlist":1024} |
不可为 null |
| idFieldName | 集合主键字段名 | doc_id | 自定义主键字段标识 |
| auto-id | 是否开启自动生成主键 | false | 开启后无需手动指定 ID |
| contentFieldName | 文本内容字段名 | content | 存储原始文档文本 |
| metadataFieldName | 元数据字段名 | metadata | 存储文档扩展属性 |
| embeddingFieldName | 向量嵌入字段名 | embedding | 存储高维向量数据 |
| initialize-schema | 是否自动初始化集合结构 | false | 新版 Spring AI 默认关闭,需手动开启 |
相似度度量枚举 MilvusMetricType :
| 枚举值 | 中文名称 | 适用场景 |
|---|---|---|
| INVALID | 无效类型 | 内部占位,不使用 |
| L2 | 欧式距离 | 关注向量绝对距离 |
| IP | 内积 | 向量归一化后等价余弦相似度 |
| COSINE | 余弦相似度 | 语义相似度、文本检索首选 |
| HAMMING | 汉明距离 | 二进制向量相似度计算 |
| JACCARD | 杰卡德距离 | 集合相似度、稀疏特征匹配 |
向量索引类型枚举 MilvusIndexType :
| 枚举值 | 索引类型 | 特点 |
|---|---|---|
| FLAT | 暴力全量检索 | 精度100%,海量数据慢 |
| IVF_FLAT | 倒排暴力索引 | 均衡性能与精度 |
| IVF_SQ8 | 倒排量化索引 | 存储空间低,精度轻微损耗 |
| IVF_PQ | 乘积量化索引 | 高压缩、适合超大规模向量 |
| HNSW | 多层近邻图索引 | 检索速度快、召回率高,生产常用 |
| DISKANN | 磁盘索引 | 适配亿级超大向量、节省内存 |
| AUTOINDEX | 自动索引 | Milvus 自动择优选择索引 |
| SCANN / GPU_IVF_FLAT / GPU_IVF_PQ | GPU 加速索引 | 显卡算力加速检索 |
| BIN_FLAT / BIN_IVF_FLAT | 二进制向量索引 | 专为二值向量优化 |
| TRIE / STL_SORT | 结构化排序索引 | 非向量字段排序场景 |
3.3.4 MilvusVectorStoreAutoConfiguration
Spring AI 集成 Milvus 向量数据库的官方自动配置 Bean:
| Bean 名称 | Bean 类型 | 核心作用 | 创建条件 | 备注 |
|---|---|---|---|---|
| milvusServiceClientConnectionDetails | MilvusServiceClientConnectionDetails |
封装 Milvus 连接地址(host/port),对接配置文件参数 | 缺失 MilvusServiceClientConnectionDetails 类型 Bean |
实现类:PropertiesMilvusServiceClientConnectionDetails |
| milvusBatchingStrategy | BatchingStrategy |
文档向量嵌入批处理策略,防止大文档导致性能问题 | 缺失 BatchingStrategy 类型 Bean |
默认实现:TokenCountBatchingStrategy |
| vectorStore | MilvusVectorStore |
核心业务Bean,提供向量增删改查、相似度检索、混合过滤能力 | 缺失 MilvusVectorStore 类型 Bean |
Spring AI 标准 VectorStore 接口实现 |
| milvusClient | MilvusServiceClient |
底层通信Bean,Milvus 官方客户端,负责与服务端建立连接、执行指令 | 缺失 MilvusServiceClient 类型 Bean |
基于配置自动构建 TLS、认证、超时参数 |
3.4 业务方法
VectorStore 对外暴露的核心业务方法:
| 方法名 | 返回值 | 入参 | 核心功能 |
|---|---|---|---|
| add | void | List | 批量添加文档(自动生成向量并存储) |
| delete | void | List | 根据文档 ID 批量删除数据 |
| delete | void | Filter.Expression | 根据元数据过滤条件删除文档 |
| similaritySearch | List | SearchRequest | 相似度检索(支持过滤、TopK、阈值) |
| getNativeClient | Optional | 无 | 获取 Milvus 原生客户端,使用高级特性 |
3.4.1 添加文档
将数据加载到向量数据库的常规用法通常在批处理任务中完成:
- 首先将数据加载到
Spring AI的Document类中 - 然后调用
VectorStore接口的add方法
add(List<Document>) - 批量添加文档:
java
@SpringBootTest
public class MilvusVectorStoreCoreTest {
@Autowired
private VectorStore vectorStore;
// 测试文档ID(固定ID,方便删除验证)
private static final String TEST_DOC_ID = "test_doc_001";
private static final String TEST_CONTENT = "Spring AI 集成 Milvus 向量数据库,实现智能文本检索";
private static final String TEST_QUERY = "Spring AI 向量检索";
// -------------------------------------------------------------------------
// 1. 测试:add(List<Document>) - 批量添加文档
// -------------------------------------------------------------------------
@Test
@DisplayName("测试1:批量添加文档到Milvus")
public void testAddDocuments() {
// 1. 构建测试文档(带ID+元数据)
Document document = Document.builder()
.id(TEST_DOC_ID)
.text(TEST_CONTENT)
.metadata(Map.of("author", "spring-ai", "type", "test"))
.build();
List<Document> documents = List.of(document);
// 2. 执行添加(无异常则成功)
Assertions.assertDoesNotThrow(() -> {
vectorStore.add(documents);
});
System.out.println("✅ 测试1:文档添加成功");
}
}
3.4.2 删除文档
VectorStore 接口提供多种删除方法,支持按文档ID 或过滤表达式删除数据。
- 传入文档
ID列表:该方法会删除所有ID匹配的文档,列表中不存在的ID会被自动忽略。 - 按过滤表达式删除:对于更复杂的删除条件,你可以使用过滤表达式 ,该方法接收一个
Filter.Expression对象,用于定义需要删除的文档匹配规则。
删除文档的性能考量:
- 当你明确知道要删除的文档ID时,按ID列表删除通常速度更快;
- 基于过滤器的删除可能需要扫描索引以匹配文档,具体逻辑取决于向量数据库的实现;
- 大规模删除操作应分批执行,避免系统负载过高;
- 基于文档属性删除时,建议使用过滤表达式,无需先收集文档
ID。
所有删除方法在发生错误时都可能抛出异常,可以将删除操作包裹在 try-catch 代码块中:
java
try {
vectorStore.delete("country == '保加利亚'");
} catch (Exception e) {
logger.error("过滤表达式无效", e);
}delete(List<String>) - 根据文档 ID 批量删除:
java
@Test
@DisplayName("测试3:根据文档ID删除")
public void testDeleteByIdList() {
// 1. 执行删除
List<String> deleteIds = List.of(TEST_DOC_ID);
Assertions.assertDoesNotThrow(() -> {
vectorStore.delete(deleteIds);
});
// 2. 验证删除后检索不到数据
MilvusSearchRequest searchRequest = MilvusSearchRequest.milvusBuilder()
.query(TEST_QUERY)
.topK(5)
.build();
List<Document> resultList = vectorStore.similaritySearch(searchRequest);
Assertions.assertTrue(resultList.isEmpty(), "文档未删除成功");
System.out.println("✅ 测试3:根据ID删除文档成功");
}delete(Filter.Expression) - 根据过滤条件删除:
java
@Test
@Order(4)
@DisplayName("测试4:根据元数据过滤条件删除")
public void testDeleteByFilter() {
// 0. 先重新添加测试数据
vectorStore.add(List.of(
Document.builder().id("test_002").text("测试过滤删除").metadata(Map.of("author", "test-user")).build()
));
// 1. 构建过滤表达式:author = 'test-user'
FilterExpressionBuilder filterBuilder = new FilterExpressionBuilder();
var filterExpression = filterBuilder.eq("author", "test-user").build();
// 2. 执行过滤删除
Assertions.assertDoesNotThrow(() -> {
vectorStore.delete(filterExpression);
});
System.out.println("✅ 测试4:根据过滤条件删除文档成功");
}3.4.3 相似度检索
构建检索请求
MilvusSearchRequest 链式构建通用搜索参数(继承自 SearchRequest,所有向量库通用):
| 构建方法 | 参数类型 | 核心功能 | 使用示例 | 备注/默认值 |
|---|---|---|---|---|
query(String query) |
String | 搜索查询文本(会自动向量化) | .query("什么是大模型") |
必选参数,用于生成搜索向量 |
topK(int topK) |
int | 返回最相似的向量结果数量 | .topK(10) |
默认值:10 |
similarityThreshold(double threshold) |
double | 相似度过滤阈值(仅返回大于等于该值的结果) | .similarityThreshold(0.75) |
取值范围:0.0 ~ 1.0;默认:0.0(不过滤) |
similarityThresholdAll() |
- | 取消相似度阈值限制,返回所有匹配结果 | .similarityThresholdAll() |
无参数,重置阈值为不限制 |
filterExpression(String textExpression) |
String | 通用过滤表达式(Spring AI 标准DSL语法) | .filterExpression("country == '中国'") |
跨向量库通用,自动转译为数据库语法 |
filterExpression(Filter.Expression expression) |
Filter.Expression | 编程式构建过滤表达式 | .filterExpression(Filter.eq("age", 18)) |
类型安全的过滤方式,避免字符串语法错误 |
Milvus 专属参数(仅 Milvus 向量库生效):
| 构建方法 | 参数类型 | 核心功能 | 使用示例 | 备注/默认值 |
|---|---|---|---|---|
nativeExpression(String nativeExpression) |
String | Milvus 原生过滤表达式(直接使用 Milvus 原生语法) | .nativeExpression("city LIKE '上海%' AND price > 100") |
优先级高于通用过滤表达式;支持 Milvus 所有原生运算符 |
searchParamsJson(String searchParamsJson) |
String | Milvus 向量索引搜索参数(JSON格式) | .searchParamsJson("{\"nprobe\":256, \"ef\":100}") |
用于优化向量搜索性能/精度;不同索引类型参数不同 |
完整参数使用示例:
java
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
// 通用必选参数
.query("推荐高性能的向量数据库")
// 通用可选参数
.topK(8)
.similarityThreshold(0.8)
.filterExpression("type == '分布式'")
// Milvus专属可选参数
.nativeExpression("brand == 'Milvus' AND version >= 2.4")
.searchParamsJson("{\"nprobe\": 256, \"ef\": 200}")
.build();当前测试类使用示例:
java
@Test
@Order(2)
@DisplayName("测试2:文本相似度检索")
public void testSimilaritySearch() {
// 1. 构建检索请求
MilvusSearchRequest searchRequest = MilvusSearchRequest.milvusBuilder()
.query(TEST_QUERY)
.topK(5)
.similarityThreshold(0.5)
.build();
// 2. 执行检索
List<Document> resultList = vectorStore.similaritySearch(searchRequest);
// 3. 断言:结果不为空,且包含目标文档
Assertions.assertFalse(resultList.isEmpty(), "检索结果为空");
Assertions.assertEquals(TEST_DOC_ID, resultList.get(0).getId(), "文档ID不匹配");
System.out.println("✅ 测试2:相似度检索成功,匹配文档:" + resultList.get(0).getText());
}元数据过滤
支持通用可移植的元数据过滤,两种写法等价:
文本表达式:
java
vectorStore.similaritySearch(
SearchRequest.builder()
.query("The World")
.topK(5)
.similarityThreshold(0.7)
.filterExpression("author in ['john', 'jill'] && article_type == 'blog'")
.build()
);编程式 DSL :
java
FilterExpressionBuilder b = new FilterExpressionBuilder();
vectorStore.similaritySearch(
SearchRequest.builder()
.query("The World")
.topK(5)
.similarityThreshold(0.7)
.filterExpression(b.and(
b.in("author", "john", "jill"),
b.eq("article_type", "blog")
).build())
.build()
);专属搜索请求
MilvusSearchRequest 继承 SearchRequest,支持 Milvus 原生参数,灵活性更强。
基础用法:
java
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
.query("sample query")
.topK(5)
.similarityThreshold(0.7)
.nativeExpression("metadata[\"age\"] > 30") // 原生表达式(优先级高于 filterExpression)
.searchParamsJson("{\"nprobe\":128}") // 索引参数
.build();
List<Document> results = vectorStore.similaritySearch(request);3.4.3 原生客户端访问
通过 getNativeClient() 获取 Milvus 原生客户端,使用高级特性:
java
MilvusVectorStore vectorStore = context.getBean(MilvusVectorStore.class);
Optional<MilvusServiceClient> nativeClient = vectorStore.getNativeClient();
if (nativeClient.isPresent()) {
MilvusServiceClient client = nativeClient.get();
// 执行 Milvus 原生操作
}