前言
在我们刚开始接触AI的时候,会觉得特别复杂、门槛很高。
因为一提到AI,就会有各种专业名词:LLM、Agent、RAG、向量数据库、MCP、Skill....,还有以后会出现的各种新概念,这种信息过载,就会让我们产生理解焦虑,是不是需要把这些东西都弄明白,才能掌握AI。
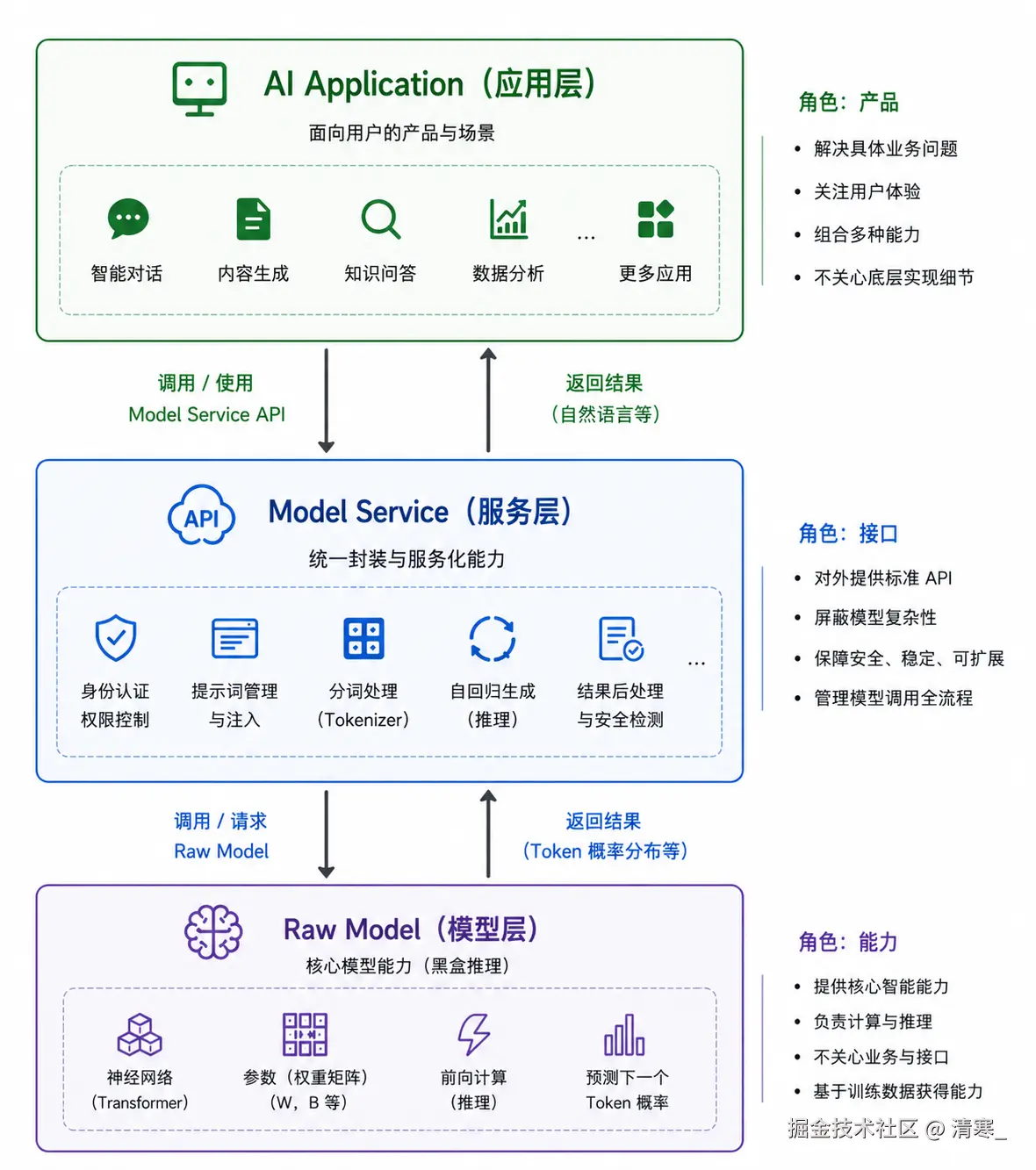
早在计算机网络中,为了把复杂的问题简单化,就出现了五层网络模型,每一层对上一层的数据进行包装,在传给下一层,只负责自己的职责,不用关心其他层。
在AI架构中,也有相似的分层,用来简化复杂问题的处理:
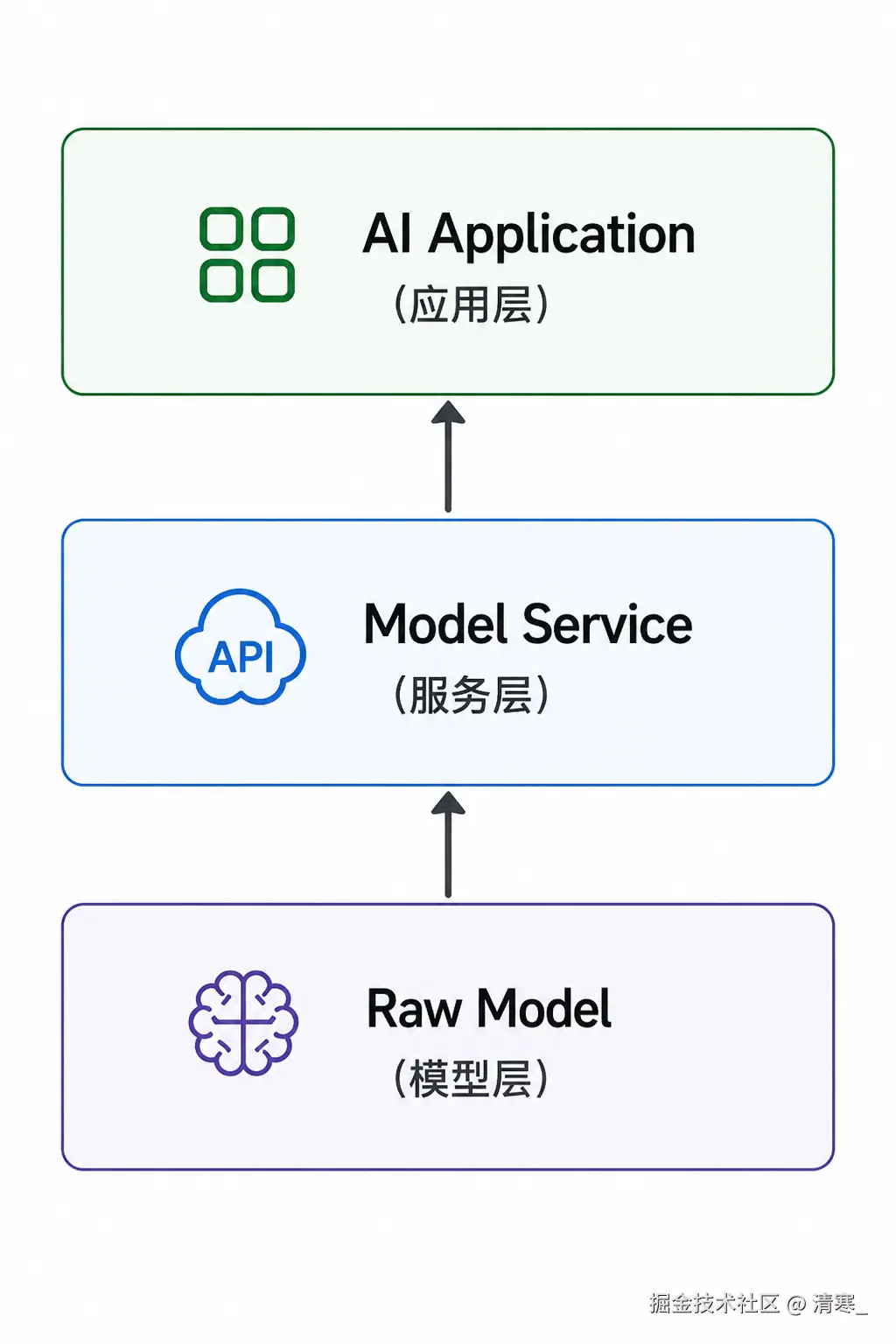
Raw Model(模型层)
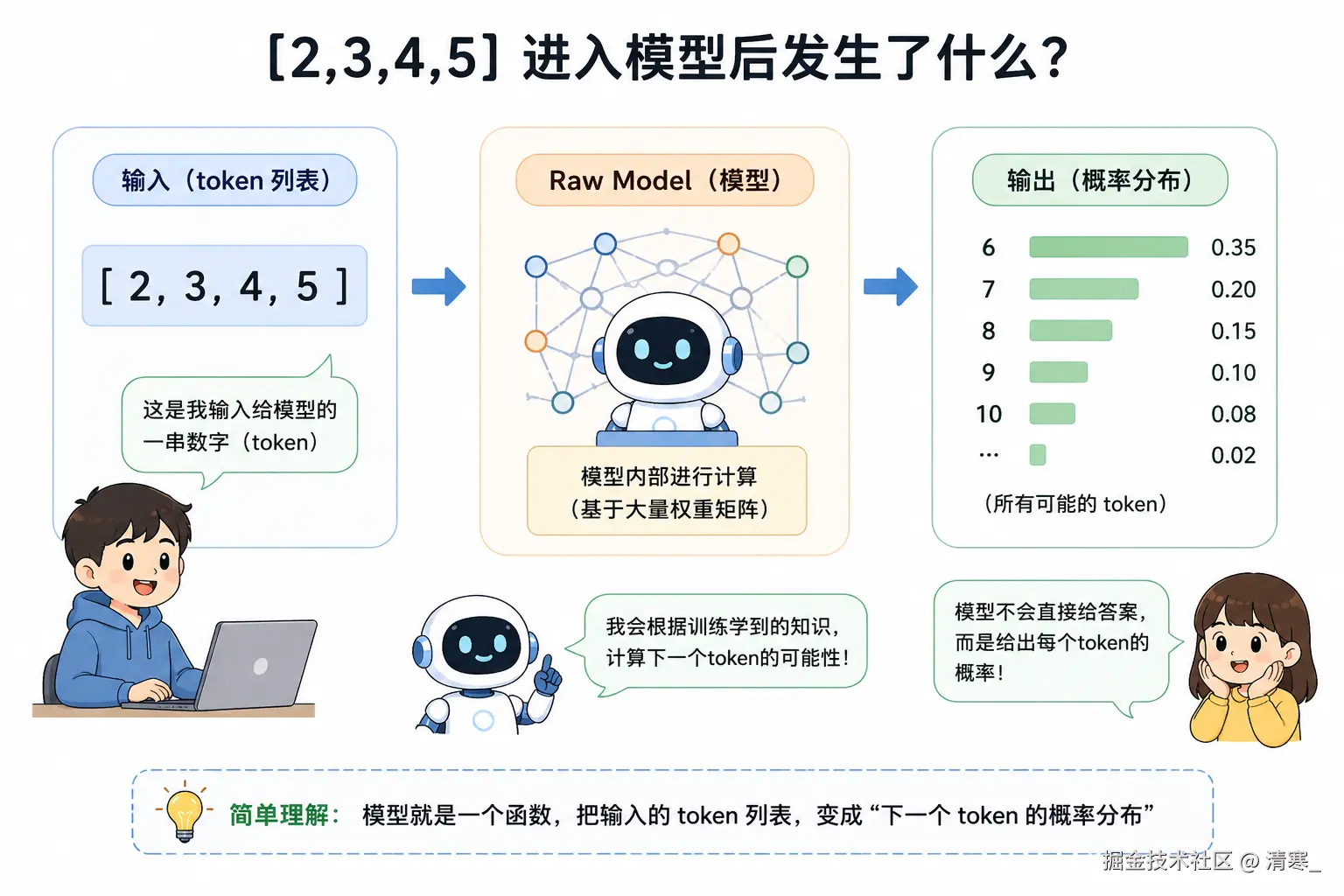
Raw Model 可以简单理解为一个"函数":
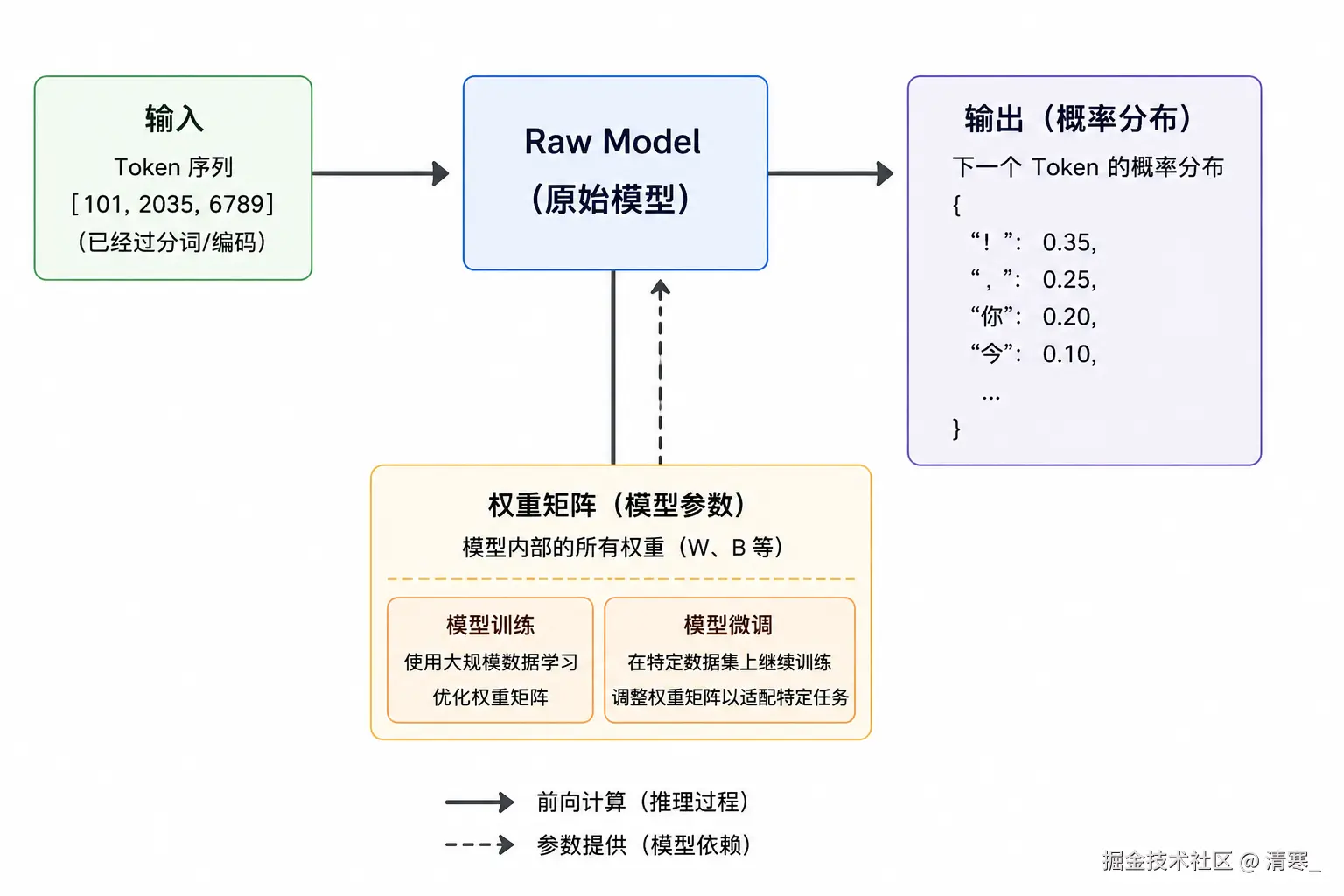
输入与输出
- 输入: token序列(文本被编码后的数字)
- 输出: 概率分布(预测下一个token的可能性)
模型并不是直接"生成答案",而是:
每一步都在"预测下一个最可能的token"
权重矩阵
Raw Model 的核心是:大量权重矩阵(Weights)
矩阵本质就是一堆按行列排好的数字,比如:
csharp
W = [
[0.2, 0.8],
[0.5, 0.1]
]这些权重来自:
- 模型训练(大量数据学习)
- 模型微调(针对特定任务优化)
权重矩阵用来控制计算、影响结果
- 哪些信息更重要
- 哪些词之间更相关
- 模型怎么"理解"输入
Context Window(上下文窗口)
表示模型一次最多能处理的token数量,决定了:
- 能"记住"多长的上下文
- 能处理多长的输入内容
例如GPT-5.5模型能处理 272k context window,约等于20多万中文
 模型不是产品,它只是能力
模型不是产品,它只是能力
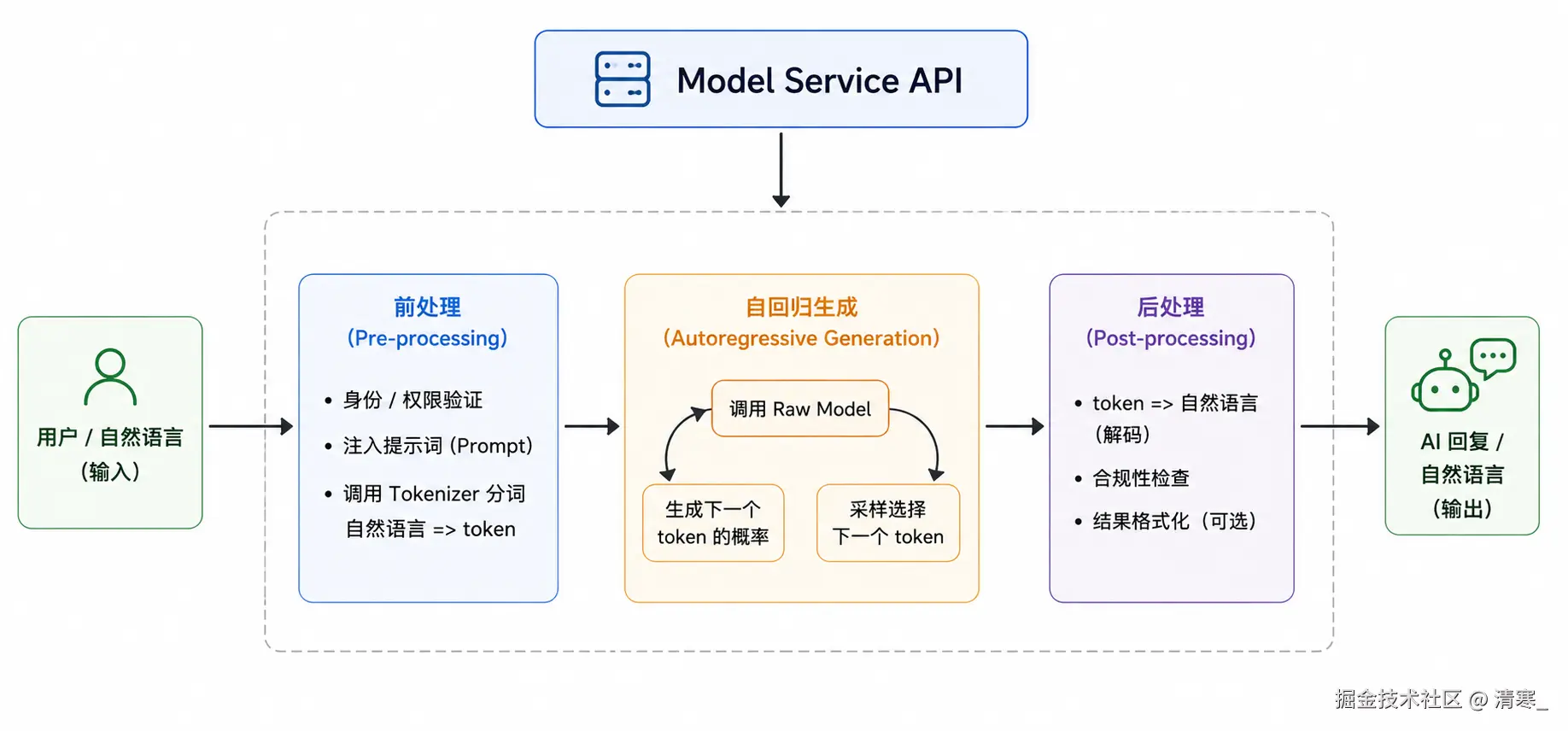
Model Service(服务层)
模型服务商提供API,封装好的Sdk,把底层模型能力封装成可调用的API服务
比如:
- OpenAI API : developers.openai.com/api/docs
主要功能:
- API接口(HTTP / SDK)
- 鉴权(API Key)
- 限流 / 计费
- 日志 / 监控
- 稳定性保障
注入提示词:
模型服务商想要给模型提前注入的一些内容,当用户询问时,可以按照服务商给的提示去回答内容。
user: 你是什么模型?
system: 当用户询问你是什么模型时,你是XX大模型
模拟运行代码
js
const input = [....] // token序列
const output = []
while (true) {
const prob = raw_model(input) // 预测下一个token概率
const token = pickToken(prob, options) // 采样策略选token
if (结束条件) break
input.push(token)
output.push(token)
}AI Application(应用层)
基于AI能力构建的用户产品
主要内容:
- 用户界面(Web / App)
- 业务逻辑
- Prompt设计
- 数据处理
比如:
- ChatGPT
- AI客服
- AI编程工具
Model Service和AI Application的边界比较模糊,有些事情可以在Model Service做,也可以在AI Application做
比如说: Tools、Function Calling、MCP、Skill
无论在哪里去做,或者再出现什么新的概念,都是在Model Service和AI Application层做处理,我们只需要知道他们都是在做以下的事情:
- 输入什么给模型
- 如何处理模型的输出
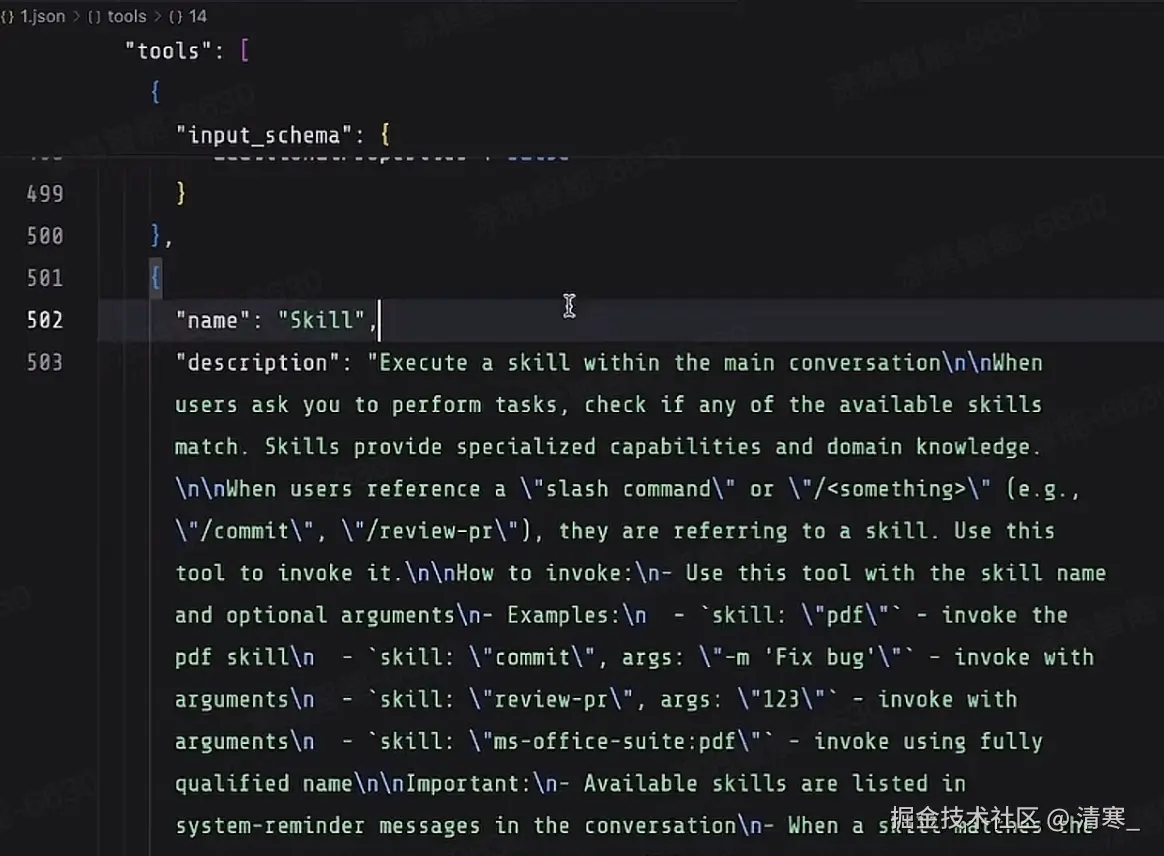
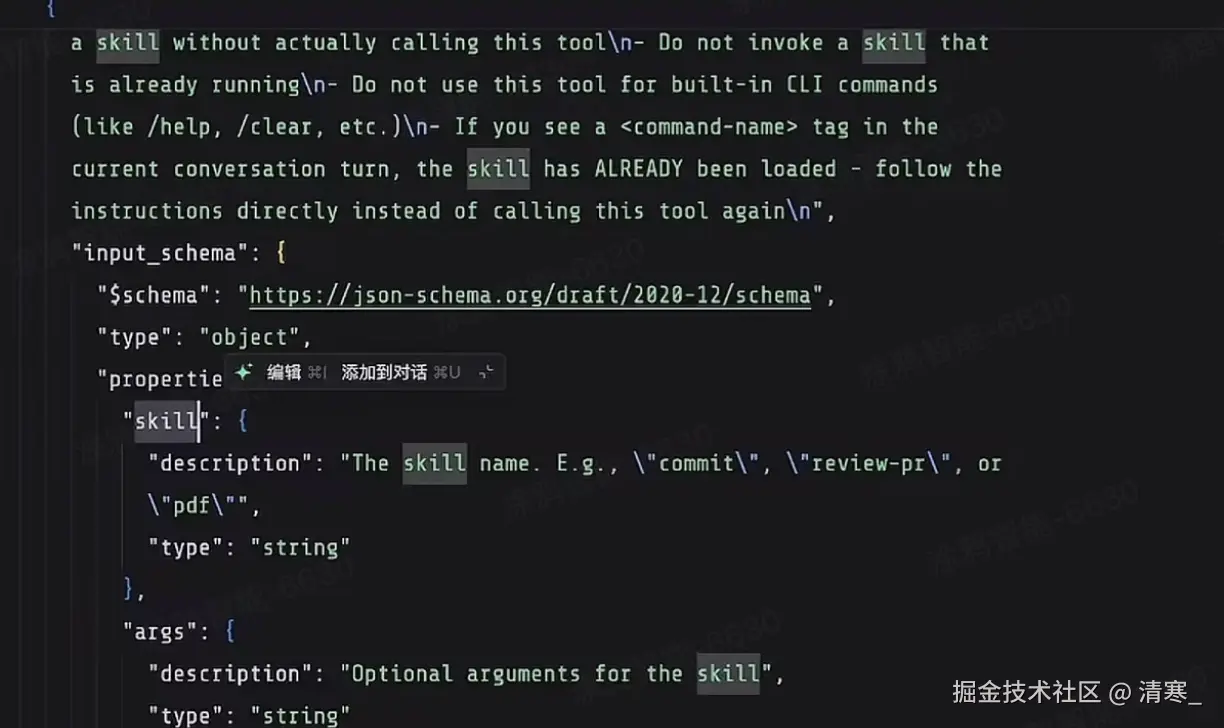
比如我们常说的Skill,看Claude Code中Skill是如何工作的
当启动Claude Code时,就会向模型发送一些初始化的消息,就包括关于Skill的内容,用来告诉模型:
- Skill是什么?Skill的概念
- 如果需要使用技能,需要模型返回什么内容
当用户向Claude Code发送: review UX
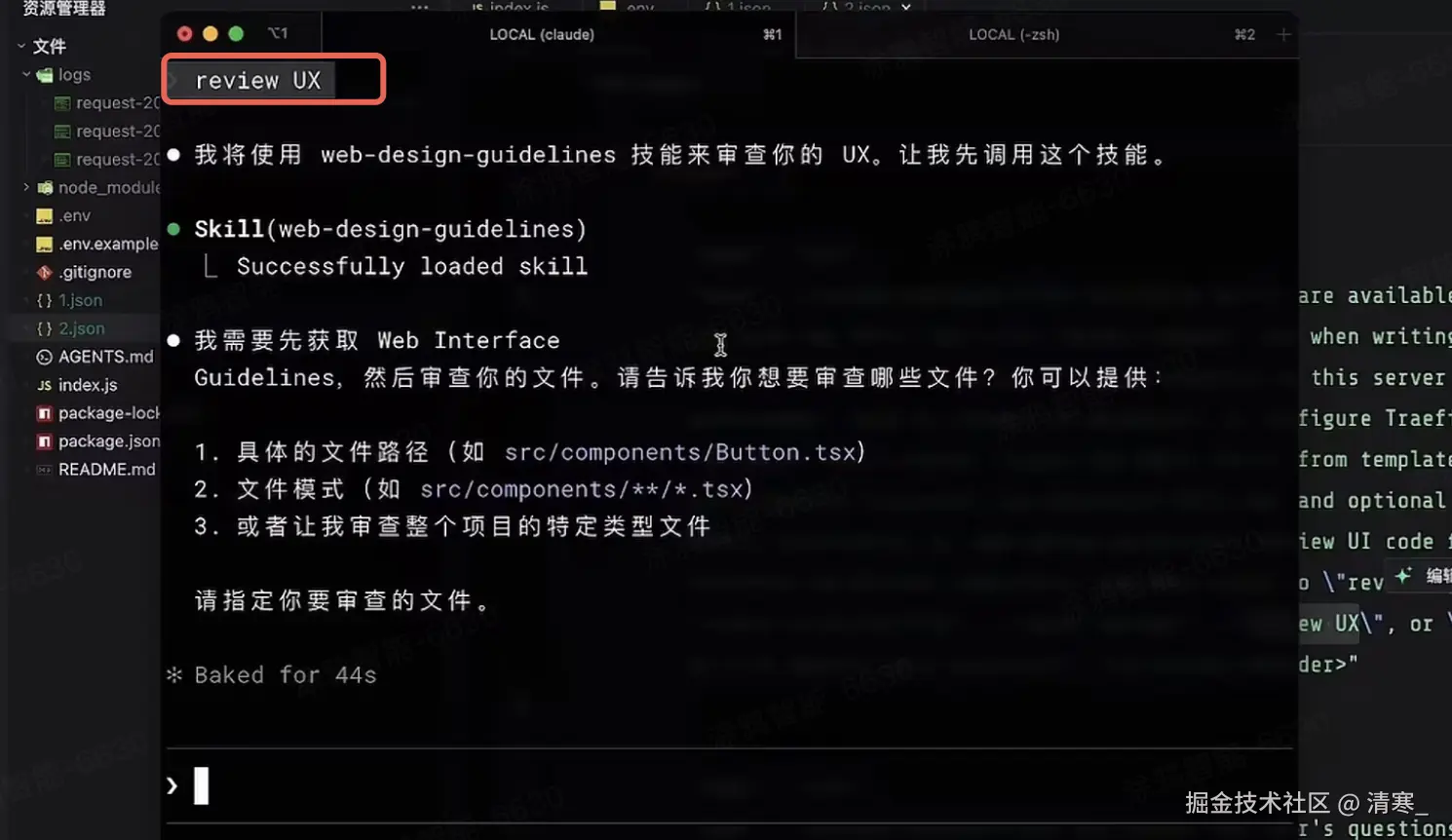
Claude Code向模型发送的:
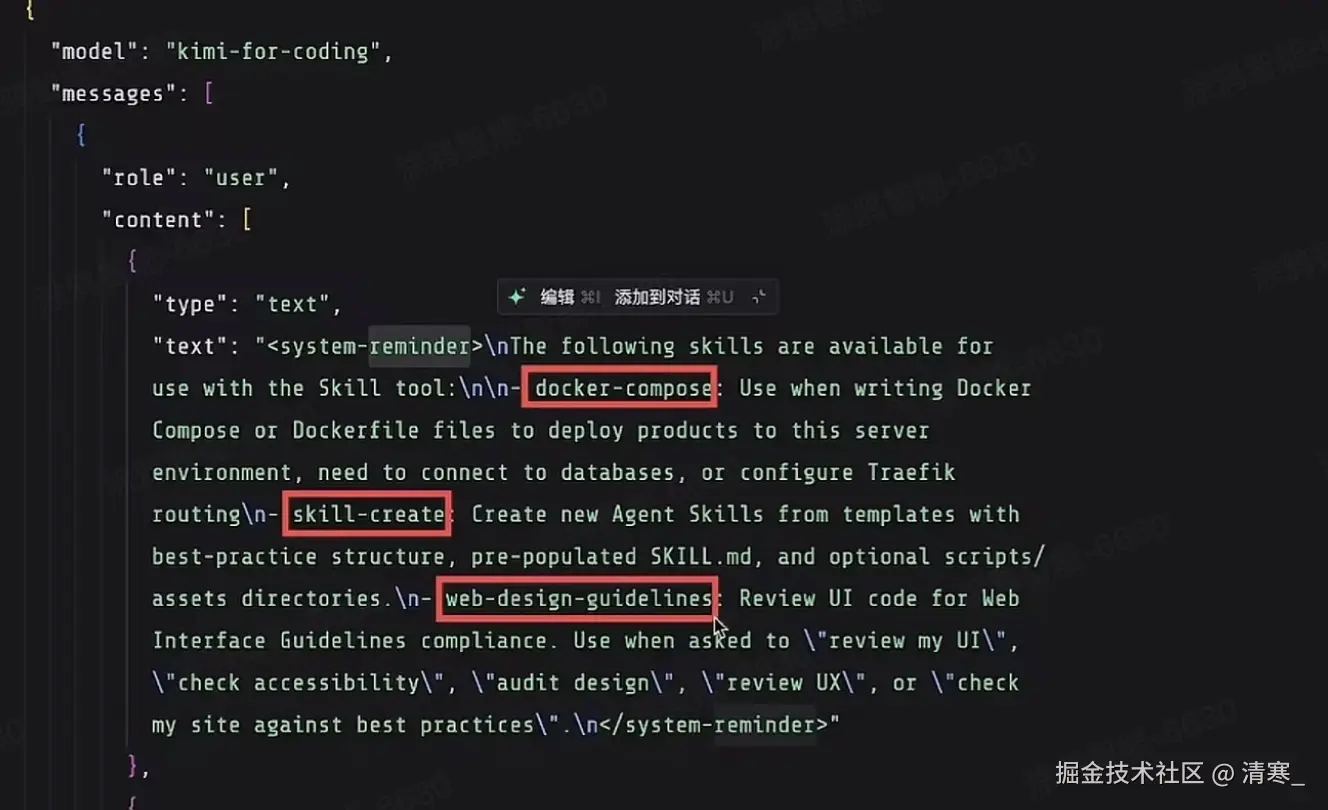
把用户的prompt发送给模型,还告诉了模型,有哪些Skill,Skill的触发词是什么

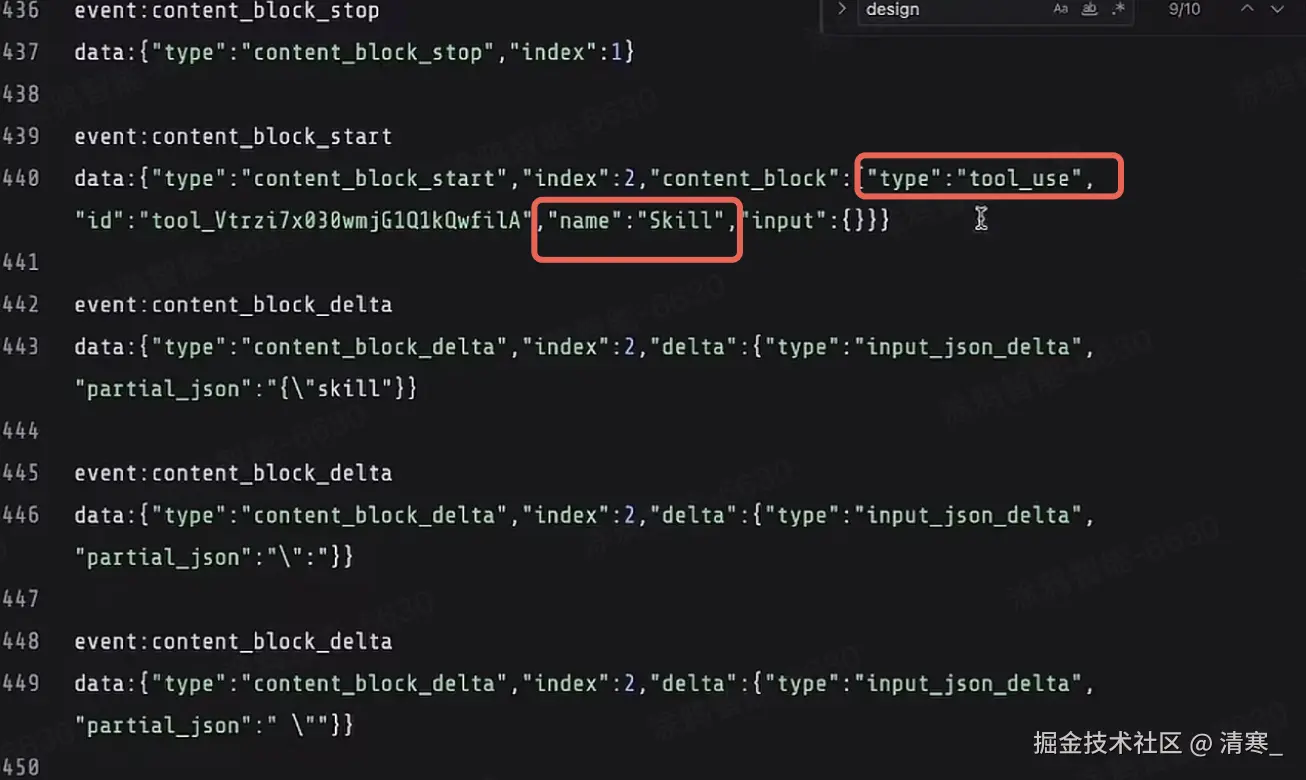
模型向Claude Code返回(SSE格式 流式传输):
通知Claude Code使用工具,工具是Skill,Skill的name是 web-design-guidelines
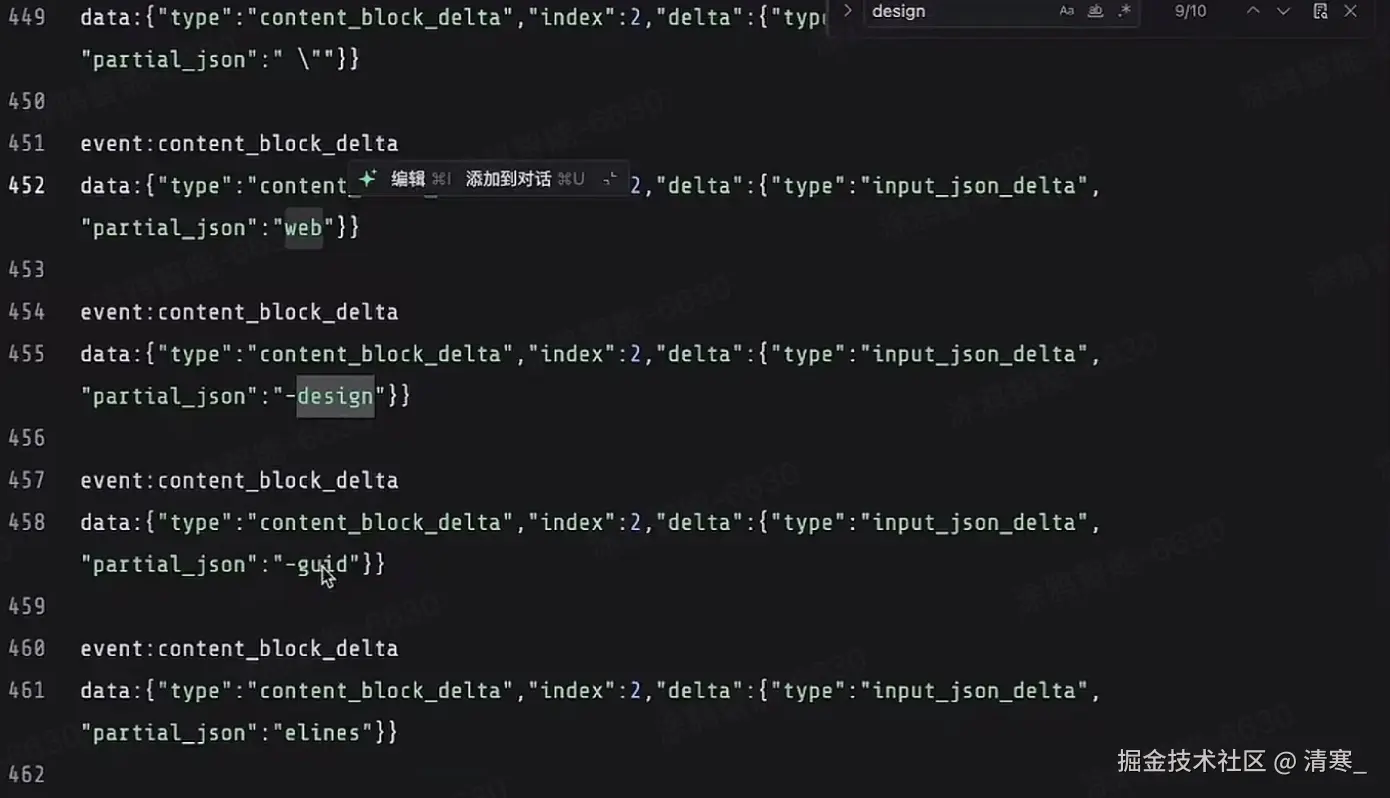
- Claude Code拿到模型的返回,确定要使用Skill
- Claude Code会去读取Skill的完整文档传给模型,
- 模型再去处理后,返回给Claude Code
- Claude Code在返回给用户
具体流程: 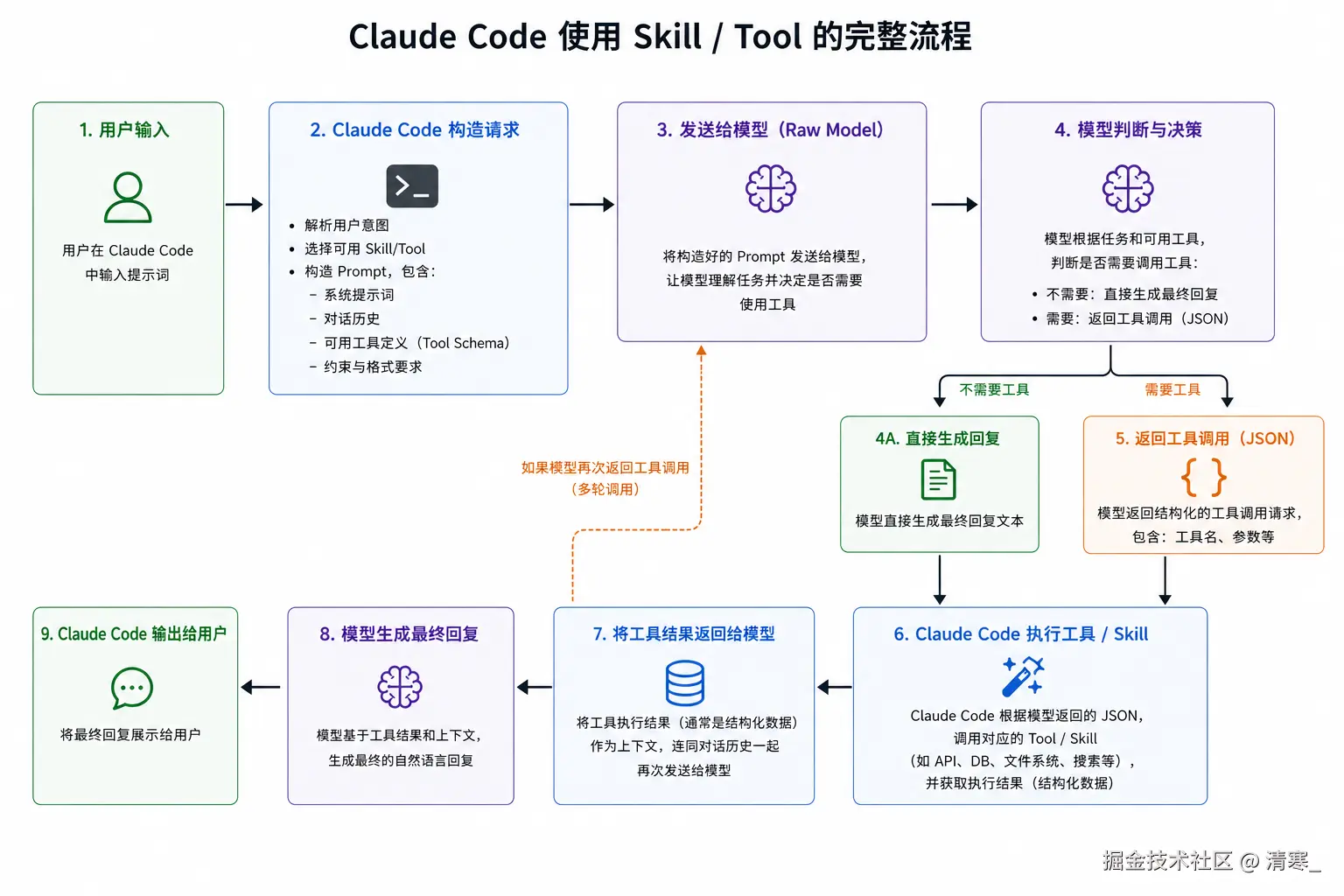
AI Application = 用AI解决问题的产品
一张图总结