零、多数据源管理方案
1、核心是使用Spring提供的AbstractRoutingDataSource抽象类,注入多个数据源。
2、使用MyBatis注册多个SqlSessionFactory
3、dynamic-datasource是MyBaits-plus作者设计的一个多数据源开源方案。使用这个框架需要引入对应的pom依赖
一、分库分表、读写分离
- 对于前端的重复点击造成的订单问题?
前端进入确认订单界面的时候,就先生成一个订单号ID。在订单点击提交的时候,订单号和商品一起提交,提交的按钮就置灰,防止重复点击。
由于网络的不可靠,后端通过前端提交的订单号校验是否重复提交是非常有必要的。可以用布隆过滤器校验。
-
对于订单的ABA问题,使用版本号解决。
-
对于分库分表来说,能不分就不分。如果单表数据量太大,就分表;如果并发请求量高,就分库。阿里给出参考建议:对于单表在短期内会超过500万,做分表处理。或者所有表加起来超过2GB,则考虑分库。
分表一般取2的幂次方,关联的信息表绑定同步的分片表,比如订单分表1对应订单详情分表1。
在之后做数据的迁移归档,我们总是在MySQL中保留3个⽉的订单数据,超过三个⽉的数据则迁出。假设预估每⽉订单2000W,⼀张订单下的商品平均为10个,如果只保留3个⽉的数据,则订单详情数为6亿,分布到32 个表中,每个表容纳的记录数刚好在2000W左右,那分库分表将订单表就设定为32个。
订单的分片键要如何划分?------》订单可以根据订单号+用户ID的后两位做组合,取模。这样同一个用户的数据不用跨表,在一个表内就可以完成根据订单号查询订单详情,或者根据用户查询订单信息的需求。比如在后续的对账过程中,根据用户下的订单金额和银行的流水金额是否匹配。
-
对于读多写少的要做读写分离,提高数据库的并发能力。读写分离分数据库层面和应用层面,数据库层面做主从备份的机制。在应用层面要做路由控制,主节点写,从节点读,减轻数据库的压力。
-
读写分离的数据不一致问题?
主从同步延迟带来的读写不一致问题,尽量规避更新数据后立即去从库查询刚刚更新的数据。如果一定要查,这两个步骤可以放到一个数据库事务中,同一个事务中的查询操作也会被路由到主库,这样就可以规避主从不一致的问题了,还有一种解决方式则是对查询部分单独指定进行主库查询。
常规做法是增加了一个支付完成页面,这个页面其实没有任何新的有效信息,就是告诉你支付成功的信息。如果想再查看一下刚刚支付完成的订单,需要手动选择,这样就能很好地规避主从同步延迟的问题。
- 如何在代码中实现读写分离和分库分表呢?
使用像Sharding-JDBC 这些组件集成在应用程序内,用于代理应用程序的所有数据库请求,并把请 求自动路由到对应的数据库实例上。
- 当每个月的订单超过2000w,数据量太大,严重影响数据库的性能,我们就要对它进行拆。其实 分库分表很多的时候并不是⾸选的⽅案,应该先考虑归档历史数据。
银行更关注近一个月的数据查询,电商参考京东,关注近3个月的数据。
所以,把超过关注时间的数据迁移到别的数据库或者别的存储系统(mangoDB,Hive,click house,ES等)。
进一个月/三个月的数据放到拆分的表里面,基本上只有查询统计类的功能会查到历史订单,这些都需要稍微做些调整。按照查询条件中的时间范围,选择去订单表还是历史订单中查询就可以了。
应该尽量选择在闲时迁移⽽且每次数据库操作的记录数不宜太多。按照⼀般的经验,对MySQL 的操作的记录条数每次控制在10000⼀下是⽐较合适,迁移前一定会做备份以免误删。
迁移的流程:
逐表批次删除,对于每张订单表,先从MySQL从获得指定批量的数据,写⼊ MongoDB,再从MySQL中删除已写⼊MongoDB的部分。这⾥并不需要分布式事务,解决的关键在于写⼊订单数据到MongoDB 时,我们要记住同时写⼊当前迁⼊数据的最大订单ID,让这两个操作执⾏在同⼀个事务之中。
定时迁移------》XXL Job。
停止迁移以及恢复迁移的问题------》只要记录了当前迁入数据的最大订单ID,下一次从MySQL获取数据,就从最大的订单ID开始,就不会漏数据。
如何防止mysql和mangoDB的数据对不上的问题。------》同上
如何批量删除⼤量数据。------》根据主键删除。

由于条件变成了主键⽐较,⽽在MySQL的InnoDB存储引擎中,表数据结构就是按照主键 组织的⼀棵B+树,同时B+树本身就是有序的,因此优化后不仅查找变得⾮常快,⽽且也不需要再进⾏额外的排序操 作了。 按ID排序后,每批删除的记录基本上都是ID连续的⼀批记录,由于B+树的 有序性,这些ID相近的记录,在磁盘的物理⽂件上,⼤致也是存放在⼀起的,这样删除效率会⽐较⾼,也便于 MySQL回收⻚。 关于⼤批量删除数据,还有⼀个点需要注意⼀下,执⾏删除语句后,最好能停顿⼀⼩会,因为删除后肯定会牵涉 到⼤量的B+树⻚⾯分裂和合并,这个时候MySQL的本身的负载就不⼩了,停顿⼀⼩会,可以让MySQL的负载更加 均衡。
- 使用RocketMQ的事务消息对消息状态进行不断的确认,优化订单超时取消流程。回查间隔可以通过参数 transactionCheckInterval 定制。并基于业务做对应的正向或者反向通知,最后采取定时任务做兜底批量回退超时的订单。。
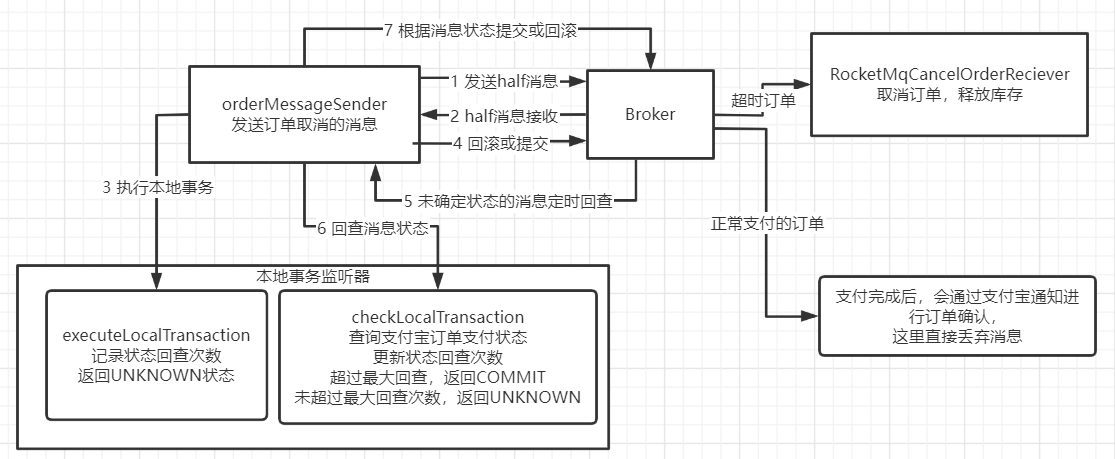
核心代码流程:
1、支付宝预下单时发送事务消息。 OmsPortalOrderController#tradeQrCode: 使用 orderMessageSender.sendCreateOrderMsg(orderId,memberId); 发送消息,这个消息实际上是用来通知 下游服务进行订单取消的。
2、发送消息后,就会先执行本地事务。 TransactionListenerImpl#executeLocalTransaction方法。在这个 方法中会将订单ID放到Redis中,这样可以在后续进行支付状态检查时,快速找到对应的业务信息。只要下单 成功,就会返回UNKOWN状态,这样RocketMQ会在之后进行状态回查。
3、然后在事务状态回查时,会执行 TransactionListenerImpl#checkLocalTransaction方法。在这个方法里 会自行记录回查次数,超过最大次数就直接取消订单。 注意,这里最大回查次数需要根据业务要求进行定制。 如果没有超过最大次数,就可以去支付宝中查询订单支付状态。 如果已经支付完成,则返回ROLLBACK状态,消息取消,后续就不会再进行本地订单取消了。 如果未支付,则记录回查次数后,返回UNKNOWN状态,等待下次回查。
4、如果事务消息最终发送出去,也就是订单已经超时,就会将消息发送到RocketMQ的 ${rocketmq.tulingmall.asyncOrderTopic}这个Topic下。下游的消费者RocketMqCancelOrderReciever就 会完成取消本地订单,释放库存等操作。
通过事务消息通知下游服务订单取消,这其实就是一 种反向通知的方式。
使用正向通知,即通过事务消息通知下游服务进行订单支付 确认,这样这个下单的消息就容易扩展更多的下游消费者。
订单下单确认是用户完成支付 后,支付宝发起的通知来确认的。这时,如果订单确认的下游服务实现了幂等控制,就完全可以将事务消息 机制改为正向通知。即在事务消息回查过程中,确认用户已经完成了支付,就发送消息通知下游服务订单支 付成功。这样也可以防止支付宝通知丢失造成的订单状态缺失。 而用户订单超时判断,则可以在事务消息的checkLocalTransaction状态回查过程中,通过记录回查次数 判断。如果已经超时,则返回Rollback。同时启动另外一个消息生产者,往下游服务发送一个订单取消的消 息,这样也是可以的。
二、分布式事务
三、全局唯一性ID
分库分表之后,数据库的自增 ID 已经无法满足需求,需要有一个唯一 ID 来标识一条数据或消息。此时一个能够生成全局唯一 ID 的系统是非常必要的。
**全局唯一性:**不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求。
**趋势递增、单调递增:**保证下一个 ID 一定大于上一个 ID。无序性可能会引起数据位置频繁变动,严重影响性能。
**信息安全:**如果 ID 是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们 一天的单量。所以在一些应用场景下,会需要 ID 无规则、不规则。
常见方法介绍:
- UUID
优点: 性能非常高:本地生成,没有网络消耗。
缺点:
不易于存储:UUID 太长,16 字节 128 位,通常以 36 长度的字符串表示, 很多场景不适用。
信息不安全:基于 MAC 地址生成 UUID 的算法可能会造成MAC 地址泄露, 这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID 就非常不适用:
① MySQL官方有明确的建议主键要尽量越短越好4,36个字符长度的UUID 不符合要求。
② 对 MySQL 索引不利 :如果作为数据库主键,在 InnoDB 引擎下,UUID 的 无序性可能会引起数据位置频繁变动,严重影响性能。在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据, 在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 雪花算法及其衍生
长度64-bit刚好表示一个long类型的数字。
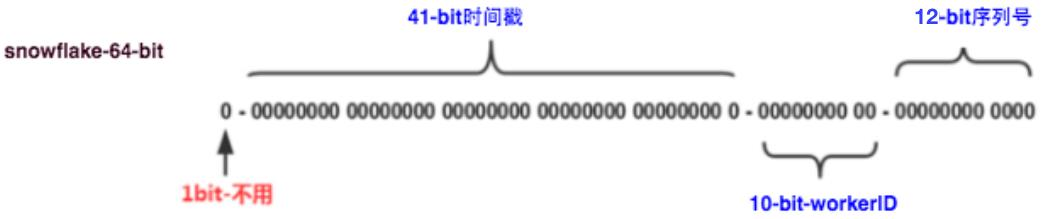
第 0 位: 符号位(标识正负),始终为 0,没有用,不用管。
第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)。
(时间戳就是64-bit,如何压缩到42位?------》当前时间减去一个时间的起点位)
第 42~52 位 :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表 示机器 ID(实际项目中可以根据实际情况调整),这样就可以区分不同集群/机 房的节点,这样就可以表示 32 个 IDC,每个 IDC 下可以有 32 台机器。
第 53~64 位 :一共 12 位,用来表示序列号。 序列号为自增值,代表单 台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最 多可以生成 4096 个 唯一 ID。
优点: 毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的。 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成 ID 的性能也是非常高的。 可以根据自身业务特性分配 bit 位,非常灵活。
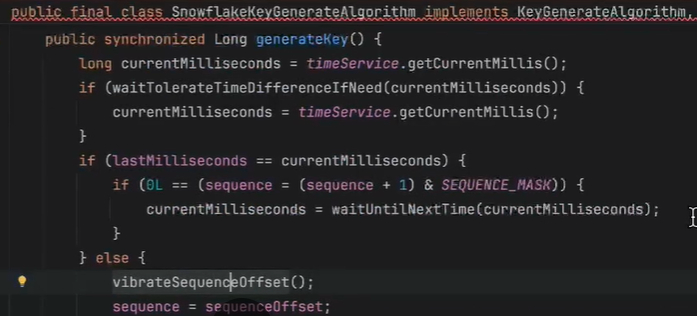
缺点: 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
时钟回拨问题?------》如果当前时间小于之前的时间,就休眠一段时间,再去获取。也可以抛异常,之后再获取。
时间相同,则sequence自增。
时间往前正常走,但是sequence为0,在分库分表,数据取模会导致数据分布不均,如何解决?------》加一个震荡方法,这样取模会自增,让数据分片分表更友好。
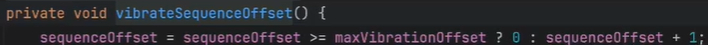
- 数据库生成
MySQL
redis
- 分布式 ID 微服务------》美团 Leaf 方案实现
Leaf 分别在 MySQL 和雪花上做了相应的优化,实现了 Leaf-segment 和 Leaf-snowflake 方案。
1)Leaf-segment数据库方案
每个业务每次根据step取一批数据。

数据库表设计如下: 重要字段说明:biz_tag 用来区分业务,max_id 表示该 biz_tag 目前所被分配 的 ID 号段的最大值,step 表示每次分配的号段长度。
这种模式有以下优缺点:
优点:
- Leaf 服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID 号码是趋势递增的 8byte 的 64 位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 Leaf 仍能正 常对外提供服务。
- 可以自定义 max_id 的大小,非常方便业务从原有的 ID 方式上迁移过来。
缺点:
- ID 号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999 数据波动大,当号段使用完之后还是会在获取新号段时在更新数据库 的 I/O 依然会存在着等待,tg999 数据会出现偶尔的尖刺。
- DB 宕机会造成整个系统不可用。
问题1:
我们会一次性插入一条订单记录和多条订单详情记录, 如果对于订单详情记录的 ID 每次都从唯一 ID 服务取,这个无疑会对性能有影响。
解决办法有两个:
1、订单详情记录的 ID 不保证全局唯一,依然使用数据库的自增主键;
2、订单详情记录的 ID 需要全局唯一,但并不每次从唯一 ID 服务,而是在生成订单时,一次性从唯一 ID 服务获得。
问题2:
针对第二个缺点做双 buffer 优化。
采用双 buffer 的方式,Leaf 服务内部有两个号段缓存区 segment。当前号段 已下发 10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。
当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前 segment 接着下发,循环往复。 通常推荐 segment 长度设置为服务高峰期发号 QPS 的 600 倍(10 分钟), 这样即使 DB 宕机,Leaf 仍能持续发号 10-20 分钟不受影响。
每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
2)Leaf-snowflake 方案
启动 Leaf-snowflake 服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点)。 如果有注册过直接取回自己的 workerID(zk顺序节点生成的 int 类型 ID 号), 启动服务。 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取 回顺序号当做自己的 workerID 号,启动服务。
弱依赖 ZooKeeper
除了每次会去 ZK 拿数据以外,也会在本机文件系统上缓存一个 workerID 文 件。当 ZooKeeper 出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。
时钟回拨的问题:(我们采取第二点)
美团建议有三种解决方案,一是可以直接关闭 NTP 同步;二是在时钟回拨的时候直接不提供服务直接返回 ERROR_CODE,等时钟追上即可,三是做一层重试,然后上报报警系统,更或者是发现有时钟回拨之 后自动摘除本身节点并报警。
四、分布式Session
五、分布式链路跟踪
六、日志收集与展示
七、商品搜索
八、分布式锁
九、服务降级/限流/熔断/隔离
十、页面静态化
十一、分布式任务调度
十二、数据迁移方案
十三、数据同步方案
十四、多级缓存、缓存预热
十五、高并发秒杀系统实现(秒杀系统的商详页静态化、秒杀系统的隔离、秒杀的削峰和限流等等)
十六、互联网思维
-
自定义实现MyBatis-Plus逆向工程
-
使用Freemarker模板引擎实现一键开发模式
springboot可以结合freemarker,根据一个表生成对应的controller,service,dao,mapper,pojo,以及统一的前端界面。
- 结合CBoard报表工具实现拖拽式报表开发