文章目录
- 一、运行时配置
- [二、MapReduce 并行执行](#二、MapReduce 并行执行)
-
- [2.1 Send对象](#2.1 Send对象)
- [2.2 编写路由逻辑](#2.2 编写路由逻辑)
- [2.2 Demo](#2.2 Demo)
本文介绍了LangGraph中的运行时配置和MapReduce并行执行机制。运行时配置允许动态切换模型、个性化Prompt和环境参数,通过RunnableConfig实现模型切换(如GPT-4/3.5)。MapReduce模式包含三步:
- Map阶段通过路由器节点动态生成Send对象分配子任务;
- Worker节点并行处理;
- Reduce阶段聚合结果。
文中提供了代码示例,展示了如何定义状态、节点函数,以及通过Send对象实现动态任务分发。该机制支持运行时根据状态决定并行任务数量和输入数据,适用于需要
一、运行时配置
简单来说,就是用同一套工作流应对不同的场景,无需重新定义和编译整个 Graph
比如:
-
根据任务类型动态切换模型(如复杂推理用 GPT-4,简单对话用 GPT-3.5)。
-
为不同用户提供个性化的系统 Prompt。
-
在不同环境中(开发/生产)使用不同的 API 密钥或数据库连接。
动态切换模型
以下是一个很简单的节点的Demo,动态选择是deepseek的模型,还是其他模型
我们来看这个节点的定义
接收的是一个RunnableConfig的配置文件
python
# 1. 定义state,确定节点间通讯的消息格式
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
# 2. 定义节点,一般而言,节点就是一个函数,接收State值的传入
def _call_model(state:AgentState, config: RunnableConfig) -> AgentState:
model_name = config.get("model_name", "deepseek")
model = models[model_name]
response = model.invoke(state["messages"])
return {"messages": [response]}完整Demo如下:
python
# -*- encoding: utf-8 -*-
'''
Date :2026/04/28 16:54:15
Author :xuhaijun
file :6.精细控制之模型配置.py
Description:
'''
import operator
from pathlib import Path
import sys
from typing import Annotated, TypedDict, Sequence
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.runnables.config import RunnableConfig
from langgraph.graph import START, END, StateGraph
from llm.llm import get_deepseek_llm, get_mega_llm
from IPython.display import display, Image
ds_llm = get_deepseek_llm()
mega_llm = get_mega_llm()
models = {
"deepseek": ds_llm,
"mega": mega_llm,
}
# 1. 定义state,确定节点间通讯的消息格式
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
# 2. 定义节点,一般而言,节点就是一个函数,接收State值的传入
def _call_model(state:AgentState, config: RunnableConfig) -> AgentState:
model_name = config.get("model_name", "deepseek") # 有model_name取model_name,没有默认deepseek
model = models[model_name]
response = model.invoke(state["messages"])
return {"messages": [response]}
graph = StateGraph(AgentState)
graph.add_node("model", _call_model)
graph.add_edge(START, "model")
graph.add_edge("model", END)
app = graph.compile()
result = app.invoke({"messages": [HumanMessage("你好,我是张三")]}, config={"model_name": "deepseek"})
print(result)
result = app.invoke({"messages": [HumanMessage("你好,我是张三")]}, config={"model_name": "mega"})
print(result)
graph_image = app.get_graph().draw_mermaid_png()
im = Image(graph_image)
with open('精细控制之模型配置.png', 'wb') as f:
f.write(im.data)二、MapReduce 并行执行
可以将 Send API 驱动的 Map-Reduce 抽象为一个"拆解-归总"的模型,其核心流程由三步构成:
-
Map 阶段(映射,即"扇出"):在一个节点(如路由器节点)的函数中,分析当前状态。根据分析结果,动态地创建并返回一个或多个 Send 对象。每个 Send 对象将一个具体的子任务和它独立的输入状态"包裹"起来,并指明由哪个"工人"(Worker)节点来处理。
-
并行处理:LangGraph 的运行时环境会接收路由函数返回的所有 Send 对象,并将它们作为触发信号,并行地、相互隔离地启动指定 Worker 节点的独立实例。每个 Worker 实例都只处理自己收到的输入状态,互不干扰。
-
Reduce 阶段(归约):所有并行 Worker 节点的执行结果会通过图的状态定义进行汇聚。这是通过在状态定义中为结果字段指定一个累加器(Reducer) 来实现的。最终,汇聚后的完整结果会传递给一个可选的"聚合器"节点进行最终处理。
生成多个Send对象
生成多个Send对象
生成多个Send对象
Update State
Update State
Update State
Preprocess(可选)
Router
Worker 1
Worker 2
... Worker N
Reducer
End(可选)
2.1 Send对象
Send 是一种能在工作流运行时,动态地、并行地将任务分发给指定节点的机制,让你能打破预定义的静态图结构.
单来说,你的工作流运行时能自动判断:
- 现在要创建 1个 还是 100个 并行任务?
- 给第 1 个任务的初始数据是 A,给第 2 个则是 B?
- 这些任务都应该发送到 Worker节点 来处理?
这些都无法预先编码,必须在图(Graph)运行时,根据状态(State)来动态决定。而 Send 的设计目标正是解决这些问题。
2.2 编写路由逻辑
关键点是,路由器节点不再返回状态更新,而是返回一个 Send 对象的列表。这个列表的长度,就决定了动态创建的任务数量。
python
from langgraph.types import Send
class OverallState(TypedDict):
topics: list[str] # 假设这个列表的运行时长度是未知的
results: Annotated[list[str], operator.add]
# 路由器节点:为每个topics生成一个Send指令
def distribute_topics(state: OverallState):
# 注意!这里state.subjects的长度在编码时无法确定
return [Send("summarize", {"topic": t}) for t in state["topics"]]2.2 Demo
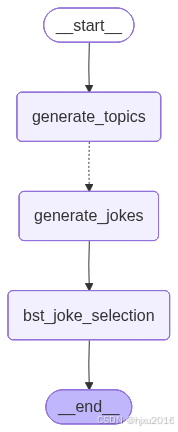
给定一个来自用户的一般主题,生成相关主题列表,为每个主题生成一个笑话,并从结果列表中选择最佳笑话。 节点数量不变,但是让llm生成指定的格式,然后节点内部通过循环等方式,发送多个Send对象
python
import operator
from pathlib import Path
import sys
from typing import Annotated, TypedDict, Sequence
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.runnables.config import RunnableConfig
from langgraph.graph import START, END, StateGraph
from langgraph.types import Send
from pydantic import BaseModel, Field
from llm.llm import get_deepseek_llm, get_mega_llm, get_qwen_llm
from IPython.display import display, Image
# 模型和提示词
# 定义我们将使用的模型和提示词
subject_prompt = """生成一个用逗号分割列表,包含2到5个与以下主题相关的例子:{topic}。"""
joke_prompt = """生成2到4个关于{subject}的短笑话(字符串列表)。"""
best_joke_prompt = """以下是一些关于{topic}的笑话,请选择一个最好的一个!返回最佳笑话的ID.{jokes}"""
# BaseModel 是 Pydantic 库提供的核心基类,用于声明数据模型。它的主要作用是让你的类具备自动类型校验、数据转换、序列化等能力,从而写出更安全、更简洁的代码。
# State继承BaseModel让State具有类型安全和自动校验,避免运行时类型错误
class Subjects(BaseModel):
subjects: list[str]
class Jokes(BaseModel):
jokes: str
# Field 是 Pydantic 中用于对模型字段进行精细配置的工具函数。它让你能针对单个字段声明额外的验证规则、约束、描述或别名等元数据,超越了普通类型注解的能力。
class BestJoke(BaseModel):
best_joke_id: int = Field(description="最佳笑话的索引,从0开始", ge=0)
# 推理模型:用 structured_invoke_reasoning,不要用 with_structured_output
# mega_llm = get_mega_llm()
mega_llm = get_qwen_llm()
# 这将是图的整体状态
# 它将包含一个主题(我们期望用户提供)
# 然后将生成一个主题列表,并为每个主题生成一个笑话
class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: str
# 状态,用于生成笑话
class JokeState(TypedDict):
subject: str
_MAX_MAP_TASKS = 16
def _normalize_subjects(raw) -> list[str]:
"""
Map 节点对每个元素发一条 Send。若 ``subjects`` 误为 str(例如模型返回一整句逗号分隔),
Python 会按「字符」迭代,产生成百上千条并行任务,看起来像死循环。
"""
if raw is None:
return []
if isinstance(raw, str):
return [x.strip() for x in raw.split(",") if x.strip()]
if isinstance(raw, (list, tuple)):
out: list[str] = []
for item in raw:
if isinstance(item, str) and item.strip():
out.append(item.strip())
return out
return [str(raw).strip()] if str(raw).strip() else []
# 用来生成笑话主题的函数
def generate_topics(state: OverallState) -> OverallState:
topic = state["topic"]
prompt = subject_prompt.format(topic=topic)
response = mega_llm.with_structured_output(Subjects).invoke([HumanMessage(prompt)])
subjects = _normalize_subjects(response.subjects)
if not subjects:
subjects = [topic]
return {"subjects": subjects}
# 这里我们根据给定的主题,生成笑话
def generate_jokes(state: JokeState) -> JokeState:
subject = state["subject"]
prompt = joke_prompt.format(subject=subject)
response = mega_llm.with_structured_output(Jokes).invoke([HumanMessage(prompt)])
return {"jokes": [response.jokes]}
# 我们定义映射到生成的主题上的逻辑
# 我们将在途中使用这个作为边
def continue_to_jokes(state: OverallState):
# 将返回一个Send对象列表
# 每个Send对象包含途中节点的名称
# 以及要发送到该节点的状态
subjects = _normalize_subjects(state.get("subjects"))
subjects = subjects[:_MAX_MAP_TASKS]
if not subjects:
return []
return [Send("generate_jokes", {"subject": s}) for s in subjects]
# 这里我们将评判最佳笑话
def bst_joke_selection(state: OverallState):
jokes = "\n\n".join(str(j) for j in state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = mega_llm.with_structured_output(BestJoke).invoke([HumanMessage(prompt)])
return {"best_selected_joke": state["jokes"][response.best_joke_id]}
graph = StateGraph(OverallState)
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_jokes", generate_jokes)
graph.add_node("bst_joke_selection", bst_joke_selection)
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_jokes"])
graph.add_edge("generate_jokes", "bst_joke_selection")
graph.add_edge("bst_joke_selection", END)
graph_build = graph.compile()
for s in graph_build.stream({"topic": "动物"}):
print(s)
# print("----------- ------------------------------")
result = graph_build.invoke({"topic": "动物"})
print(result)
graph_image = graph_build.get_graph().draw_mermaid_png()
im = Image(graph_image)
with open('精细控制之MapReduce.png', 'wb') as f:
f.write(im.data)