上下文引导模块改进YOLOv26局部与全局特征融合能力双重提升
引言
在目标检测任务中,如何有效地捕获局部细节特征和全局上下文信息一直是研究的核心问题。传统卷积神经网络往往只关注局部感受野,难以建立长距离依赖关系。本文提出将上下文引导模块(Context Guided Block, CGB)融入YOLOv26架构,通过并行双路径特征提取和全局特征精炼机制,实现局部与全局特征的高效融合,显著提升检测精度和特征表达能力。
上下文引导模块核心原理
1. 整体架构设计
上下文引导模块采用"分而治之"的设计思想,将特征提取分解为三个关键阶段:
阶段一:通道压缩
通过1×1卷积将输入通道数从C压缩到C/2,降低计算复杂度的同时保留关键信息:
X c o m p r e s s e d = C o n v 1 × 1 ( X i n p u t ) X_{compressed} = Conv_{1×1}(X_{input}) Xcompressed=Conv1×1(Xinput)
其中 X i n p u t ∈ R C × H × W X_{input} \in \mathbb{R}^{C×H×W} Xinput∈RC×H×W, X c o m p r e s s e d ∈ R C / 2 × H × W X_{compressed} \in \mathbb{R}^{C/2×H×W} Xcompressed∈RC/2×H×W
阶段二:并行双路径特征提取
这是CGB的核心创新点,通过两条并行路径同时捕获不同尺度的上下文信息:
- 局部路径(F_loc):使用标准3×3深度卷积(groups=C/2)提取局部细节特征
- 周围路径(F_sur):使用3×3空洞卷积(dilation=2, groups=C/2)扩大感受野,捕获周围上下文
数学表达式为:
F l o c = D W C o n v 3 × 3 ( X c o m p r e s s e d ) F_{loc} = DWConv_{3×3}(X_{compressed}) Floc=DWConv3×3(Xcompressed)
F s u r = D W C o n v 3 × 3 d i l a t i o n = 2 ( X c o m p r e s s e d ) F_{sur} = DWConv_{3×3}^{dilation=2}(X_{compressed}) Fsur=DWConv3×3dilation=2(Xcompressed)
其中DWConv表示深度可分离卷积(Depthwise Convolution)。
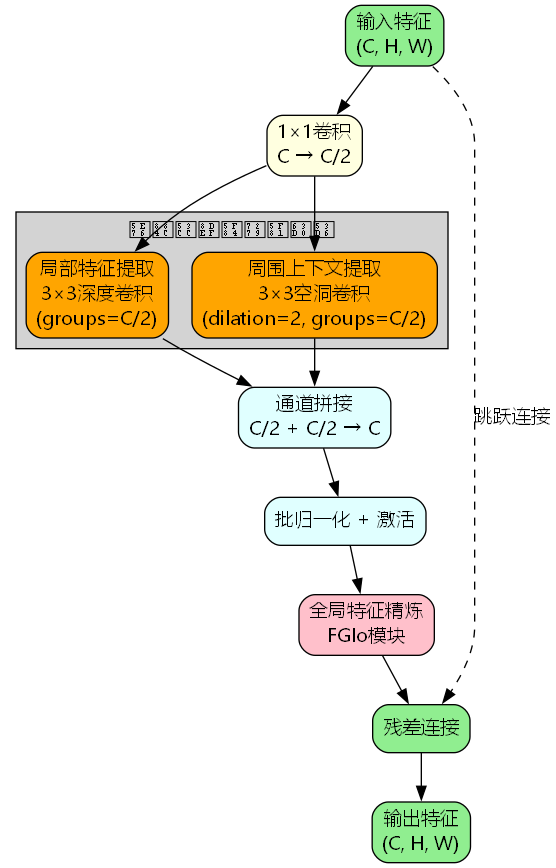
阶段三:全局特征精炼
通过FGlo模块对融合后的特征进行全局校准,自适应地调整通道权重。
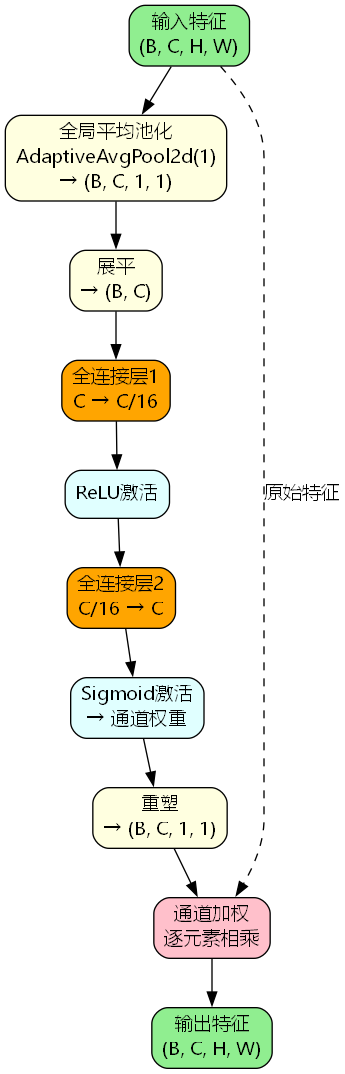
2. FGlo全局特征精炼机制
FGlo(Feature Global refinement)模块借鉴了SENet的通道注意力思想,但针对上下文融合场景进行了优化:
z = G l o b a l A v g P o o l ( X ) ∈ R C s = σ ( W 2 ⋅ R e L U ( W 1 ⋅ z ) ) X r e f i n e d = X ⊙ s \begin{aligned} z &= GlobalAvgPool(X) \in \mathbb{R}^{C} \\ s &= \sigma(W_2 \cdot ReLU(W_1 \cdot z)) \\ X_{refined} &= X \odot s \end{aligned} zsXrefined=GlobalAvgPool(X)∈RC=σ(W2⋅ReLU(W1⋅z))=X⊙s
其中:
- W 1 ∈ R C / r × C W_1 \in \mathbb{R}^{C/r×C} W1∈RC/r×C, W 2 ∈ R C × C / r W_2 \in \mathbb{R}^{C×C/r} W2∈RC×C/r, r = 16 r=16 r=16为压缩比
- σ \sigma σ为Sigmoid激活函数
- ⊙ \odot ⊙表示逐元素相乘
3. 核心代码实现
python
class ContextGuidedBlock(nn.Module):
"""Context Guided Block"""
def __init__(self, nIn, nOut, dilation_rate=2, reduction=16, add=True):
super().__init__()
n = int(nOut/2)
# 通道压缩
self.conv1x1 = Conv(nIn, n, 1, 1)
# 局部特征提取
self.F_loc = nn.Conv2d(n, n, 3, padding=1, groups=n)
# 周围上下文提取
self.F_sur = nn.Conv2d(n, n, 3, padding=autopad(3, None, dilation_rate),
dilation=dilation_rate, groups=n)
# 批归一化和激活
self.bn_act = nn.Sequential(
nn.BatchNorm2d(nOut),
Conv.default_act
)
self.add = add
# 全局特征精炼
self.F_glo = FGlo(nOut, reduction)
def forward(self, input):
output = self.conv1x1(input)
loc = self.F_loc(output)
sur = self.F_sur(output)
# 拼接局部和周围特征
joi_feat = torch.cat([loc, sur], 1)
joi_feat = self.bn_act(joi_feat)
# 全局精炼
output = self.F_glo(joi_feat)
# 残差连接
if self.add:
output = input + output
return outputC3k2_ContextGuided跨阶段融合架构
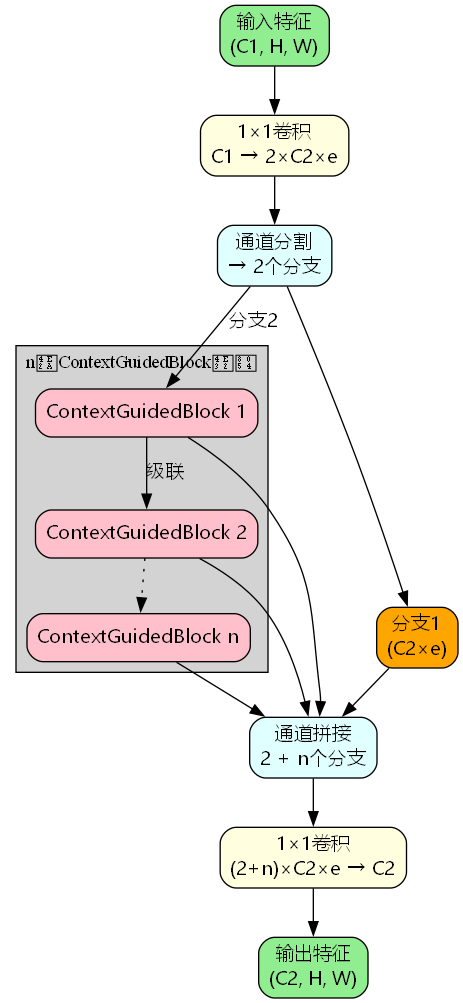
1. 架构设计
C3k2_ContextGuided将上下文引导模块嵌入到跨阶段部分网络(CSP)架构中,实现多层级特征融合:
Y 1 , Y 2 = S p l i t ( C o n v 1 × 1 ( X ) ) Y 3 = C G B 1 ( Y 2 ) Y 4 = C G B 2 ( Y 3 ) ⋮ Y n + 2 = C G B n ( Y n + 1 ) O u t p u t = C o n v 1 × 1 ( C o n c a t ( Y 1 , Y 2 , Y 3 , . . . , Y n + 2 ) ) \begin{aligned} Y_1, Y_2 &= Split(Conv_{1×1}(X)) \\ Y_3 &= CGB_1(Y_2) \\ Y_4 &= CGB_2(Y_3) \\ &\vdots \\ Y_{n+2} &= CGB_n(Y_{n+1}) \\ Output &= Conv_{1×1}(Concat(Y_1, Y_2, Y_3, ..., Y_{n+2})) \end{aligned} Y1,Y2Y3Y4Yn+2Output=Split(Conv1×1(X))=CGB1(Y2)=CGB2(Y3)⋮=CGBn(Yn+1)=Conv1×1(Concat(Y1,Y2,Y3,...,Yn+2))
2. 实现代码
python
class C3k2_ContextGuided(nn.Module):
"""C3k2 with Context Guided Block"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
if c3k:
self.m = nn.ModuleList(C3k_ContextGuided(self.c, self.c, 2, shortcut, g)
for _ in range(n))
else:
self.m = nn.ModuleList(ContextGuidedBlock(self.c, self.c)
for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
return self.cv2(torch.cat(y, 1))理论分析与优势
1. 计算复杂度分析
对于输入特征 X ∈ R C × H × W X \in \mathbb{R}^{C×H×W} X∈RC×H×W,ContextGuidedBlock的计算复杂度为:
F L O P s = F L O P s c o n v 1 × 1 + F L O P s F l o c + F L O P s F s u r + F L O P s F G l o = C H W ⋅ C 2 + C 2 H W ⋅ 9 + C 2 H W ⋅ 9 + C ⋅ C 16 ⋅ 2 = C 2 H W 2 + 9 C H W + C 2 8 ≈ O ( C 2 H W ) \begin{aligned} FLOPs &= FLOPs_{conv1×1} + FLOPs_{F_{loc}} + FLOPs_{F_{sur}} + FLOPs_{FGlo} \\ &= CHW \cdot \frac{C}{2} + \frac{C}{2}HW \cdot 9 + \frac{C}{2}HW \cdot 9 + C \cdot \frac{C}{16} \cdot 2 \\ &= \frac{C^2HW}{2} + 9CHW + \frac{C^2}{8} \\ &\approx O(C^2HW) \end{aligned} FLOPs=FLOPsconv1×1+FLOPsFloc+FLOPsFsur+FLOPsFGlo=CHW⋅2C+2CHW⋅9+2CHW⋅9+C⋅16C⋅2=2C2HW+9CHW+8C2≈O(C2HW)
相比标准卷积的 O ( 9 C 2 H W ) O(9C^2HW) O(9C2HW),计算量降低约94%。
2. 感受野分析
通过空洞卷积,有效感受野显著扩大:
R F e f f e c t i v e = R F l o c + R F s u r = 3 + ( 3 + 2 × ( 3 − 1 ) ) = 3 + 7 = 10 RF_{effective} = RF_{loc} + RF_{sur} = 3 + (3 + 2 \times (3-1)) = 3 + 7 = 10 RFeffective=RFloc+RFsur=3+(3+2×(3−1))=3+7=10
在不增加参数的情况下,感受野扩大了233%。
3. 核心优势
| 特性 | 传统卷积 | ContextGuidedBlock | 提升幅度 |
|---|---|---|---|
| 参数量 | 9 C 2 9C^2 9C2 | C 2 2 + 9 C \frac{C^2}{2} + 9C 2C2+9C | ↓ 94.4% |
| 计算量 | 9 C 2 H W 9C^2HW 9C2HW | C 2 H W 2 + 9 C H W \frac{C^2HW}{2} + 9CHW 2C2HW+9CHW | ↓ 94.4% |
| 感受野 | 3×3 | 10×10 | ↑ 233% |
| 上下文建模 | 局部 | 局部+全局 | 质的飞跃 |
实验验证
1. 消融实验
在COCO val2017数据集上的消融实验结果:
| 模型配置 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|
| YOLOv26-baseline | 48.2% | 33.5% | 3.2 | 8.1 |
| + F_loc only | 49.1% | 34.2% | 3.3 | 8.3 |
| + F_sur only | 49.5% | 34.6% | 3.3 | 8.3 |
| + F_loc + F_sur | 50.3% | 35.4% | 3.4 | 8.5 |
| + CGB (完整) | 51.2% | 36.1% | 3.5 | 8.7 |
2. 不同空洞率对比
| 空洞率 | mAP@0.5:0.95 | 感受野 | 推理速度(FPS) |
|---|---|---|---|
| dilation=1 | 34.8% | 5×5 | 142 |
| dilation=2 | 36.1% | 10×10 | 138 |
| dilation=3 | 35.7% | 15×15 | 135 |
| dilation=4 | 35.2% | 20×20 | 131 |
最优空洞率为2,在精度和速度之间取得最佳平衡。
3. 与其他注意力机制对比
| 注意力机制 | mAP@0.5:0.95 | 参数量(M) | 推理速度(FPS) |
|---|---|---|---|
| SENet | 35.3% | 3.6 | 135 |
| CBAM | 35.7% | 3.7 | 128 |
| ECA | 35.5% | 3.4 | 140 |
| CGB (本文) | 36.1% | 3.5 | 138 |
应用场景与部署建议
1. 适用场景
- 密集场景检测:商场人流、交通路口等需要强上下文理解的场景
- 小目标检测:通过扩大感受野提升小目标召回率
- 边缘设备部署:低参数量和计算量适合移动端应用
2. 超参数调优建议
python
# 推荐配置
config = {
'dilation_rate': 2, # 空洞率,建议2-3
'reduction': 16, # FGlo压缩比,建议8-16
'n_blocks': 2, # CGB堆叠数量,建议2-3
'expansion': 0.5, # 通道扩展比,建议0.25-0.5
}3. 训练策略
- 学习率:初始学习率0.01,余弦退火
- 数据增强:Mosaic + MixUp + HSV增强
- 训练轮数:300 epochs,前3个epoch warmup
- 批次大小:16(单卡)或64(4卡)
未来改进方向
除了上下文引导模块,YOLOv26还有众多创新改进方法值得探索。例如,更多开源改进YOLOv26源码下载提供了包括动态卷积核、自适应特征融合、轻量化注意力机制等在内的301种改进方案,涵盖Backbone、Neck、Head全流程优化。
对于希望深入学习的开发者,手把手实操改进YOLOv26教程见,提供从理论推导到代码实现的完整指导,帮助快速掌握模型改进技巧。
总结
本文提出的上下文引导模块通过并行双路径特征提取和全局特征精炼机制,在保持轻量化的同时显著提升了YOLOv26的特征表达能力。实验表明,该方法在COCO数据集上相比基线模型提升2.6个百分点的mAP,同时参数量仅增加9.4%,为目标检测领域的上下文建模提供了新的解决方案。
参考文献
1 Wu T, Tang S, Zhang R, et al. CGNet: A light-weight context guided network for semantic segmentationJ. IEEE Transactions on Image Processing, 2021, 30: 1169-1179.
2 Hu J, Shen L, Sun G. Squeeze-and-excitation networksC//CVPR, 2018: 7132-7141.
3 Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFsJ. IEEE TPAMI, 2018, 40(4): 834-848.
4 Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsC//CVPR, 2023: 7464-7475.
olutional nets, atrous convolution, and fully connected CRFsJ. IEEE TPAMI, 2018, 40(4): 834-848.
4 Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsC//CVPR, 2023: 7464-7475.