引言:企业级AI落地的必经之路------RAG架构
在当前大模型(LLM)技术快速发展的浪潮中,企业要想将其核心知识(文档、手册、代码库)与LLM的强大生成能力相结合,面临着"幻觉(Hallucination)"、知识更新滞后、私有数据安全等核心挑战。
检索增强生成(Retrieval-Augmented Generation, RAG) 架构已成为应对这些挑战的 **"最优工程实践"** 。其核心思想是:首先, 将私有知识库转化为可检索的形式(通常是向量化);其次, 在回答问题时,先从中"回忆"最相关的知识片段;**最后,** 将这些片段作为精确的上下文,提供给LLM生成答案。
第一章:RAG架构核心逻辑与Spring AI的价值定位
1.1 RAG架构四层解剖图
一个完整的企业级RAG架构可以清晰地分为四个层次,每一层都有其明确的职责:
- **应用层 (Application Layer):** 接收用户的自然语言查询,可以是API调用、Web界面交互或消息机器人。它是用户与系统的交互入口。
- 检索层 (Retrieval Layer): 系统最核心的大脑 。它将用户的查询文本通过嵌入模型 (Embedding Model) 转化为"向量"(一种数字表示),并与向量数据库中存储的知识向量 进行相似度计算(如余弦相似度),召回前K个最相关的文档片段。**检索的精准度和效率,直接决定了最终答案的质量和响应速度。**
- **大模型层 (LLM Layer):** 收到来自检索层的"参考材料"(上下文)和用户的原始问题。在此指导下,LLM(如GPT-4、通义千问等)生成更可靠、更精准的回答。该层支持动态切换不同模型,满足成本、性能与功能的平衡。
- 数据层 (Data Layer): RAG系统的记忆仓库 。包含原始知识库 (原始文档)和向量数据库(将文档向量化后的索引存储)。负责数据接入、清洗、切分、向量化和持久化存储。
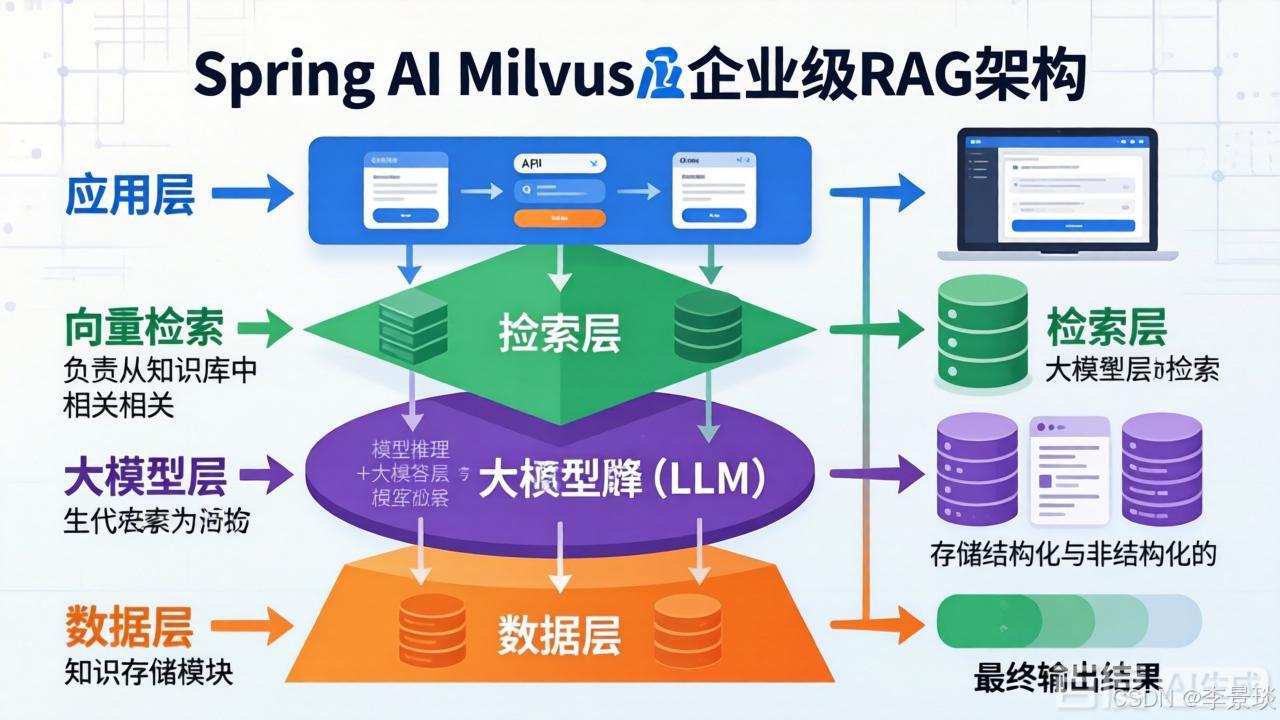
向量数据库正是连接"数据层"与"检索层"的关键组件,其高性能、高扩展的特性是企业级RAG的基石。
1.2 Spring AI的"抽象"之美:简化复杂集成
Spring AI的核心价值在于标准化和抽象。它通过一系列高层次的接口和模板,将复杂的AI组件操作(向量化、检索、大模型调用)简化成熟悉的Spring风格配置和编程模型。对于开发者而言,这意味着:
- 统一API: 无需学习和编写不同向量数据库或LLM厂商的SDK。
- 即插即用 : 通过声明式配置(如
application.yml)快速切换底层组件。 - 生态融合: 与Spring Boot, Spring Cloud等已有架构无缝集成,支持依赖注入、AOP、事务管理等企业级特性。
简单来说,**Spring AI让开发者从"管道工"变成"架构师"**,能更专注于业务逻辑的实现。
第二章:关键组件深度剖析------向量数据库选型与Milvus优势
**2.1 企业为何需要专业的向量数据库?**
相比传统的搜索引擎(Elasticsearch在特定版本后也支持向量)或关系型数据库,专业的向量数据库具备显著优势:
- 极致性能: 针对高维向量相似度搜索进行了深度优化,可实现亚毫秒级的检索响应,满足高并发场景。
- 海量数据: 支持亿级乃至百亿级向量的高效存储和检索。
- 专门算法: 内置HNSW, IVF-Flat等先进的近似最近邻(ANN)搜索算法,能在精度和速度间取得最佳平衡。
- 云原生与可扩展: 设计之初就考虑了分布式部署、动态扩容和运维监控。
2.2 主流向量数据库横向对比与企业选型指南
| 数据库 | 类型 | 核心优势 | 主要劣势 | 推荐指数与场景 |
|---|---|---|---|---|
| Milvus | 开源 | 性能标杆、分布式架构、亿级向量支持、毫秒级检索、社区与生态完善、Spring AI原生支持最好 | 自运维带来一定部署和运维成本 | ★★★★★ 生产级、高并发、大型知识库首选 |
| Pinecone | 全托管云服务 | 开箱即用,零运维;API简单,快速原型 | 费用较高;数据需上云,对网络敏感 | ★★★☆☆ 小型团队、项目早期验证、非核心应用 |
| Chroma | 轻量级开源 | 极简、易部署、学习成本低 | 性能有限,不支持大规模数据;功能相对单一 | ★★☆☆☆ 本地开发、概念验证、快速体验 |
| **ES (w/Vector Plugin)** | 开源搜索 | 混合检索能力强(全文+向量);可复用现有集群和生态 | 纯向量检索性能不如专业向量库;功能稍显冗余 | ★★★★☆ 已有ES生态且搜索需求复杂的场景 |
结论: 对于追求可控性、高性能和成本效益的生产环境,Milvus是一个平衡性极佳的选择。其开源属性和活跃的社区能保障长期技术演进,而Spring AI的完美适配又极大地降低了开发门槛。
**第三章:实战 ------ 从零构建企业级RAG应用(Spring AI + Milvus)**
创建一个能上传文档(PDF/Word/TXT)并提供智能问答的RAG Web服务。
3.1 前置环境准备
-
**启动Milvus(通过Docker)**:
bash# 拉取最新稳定版镜像 docker pull milvusdb/milvus:v2.4.5 # 运行容器,映射必要端口 docker run -d --name milvus \ -p 19530:19530 -p 9091:9091 \ milvusdb/milvus:v2.4.5可通过
http://localhost:9091访问Milvus Web UI,确认服务启动。 -
获取模型API Key:
- 访问阿里云,开通通义大模型服务,获取您的API Key。
-
项目环境:
- JDK 17+
- Maven 3.8+
- Spring Boot 3.3.0 项目
**3.2 Maven依赖配置 (pom.xml)**
配置Spring AI以及Milvus的依赖。
XML
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
</dependency>
<!-- Spring AI for Milvus -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus</artifactId>
</dependency>
<!-- Spring AI for 通义千问 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tongyi</artifactId>
</dependency>
<!-- 文档解析支持 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
</dependency>**3.3 应用配置文件 (application.yml)**
配置向量数据库连接和AI模型参数。
XML
spring:
ai:
tongyi:
api-key: YOUR_TONGYI_API_KEY # 请替换为您的真实API Key
milvus:
host: localhost
port: 19530
collection-name: rag_docs # 用于存储文档向量的集合名
dimension: 1536 # 必须与嵌入模型的向量维度一致
index-type: IVF_FLAT # 平衡精度与性能的索引
metric-type: COSINE # 使用余弦相似度计算
main:
banner-mode: off配置要点:
dimension必须与向量化模型(通义千问embedding-v1模型)的输出维度(1536)严格匹配。collection-name指定的集合会在首次操作时自动创建。
3.4 核心业务代码实现
A. 文档向量化服务 (DocumentVectorService)
负责解析用户上传的文档,将其分块并转换为向量存储到Milvus。
java
import org.springframework.ai.document.Document;
import org.springframework.ai.milvus.MilvusVectorStore;
import org.springframework.ai.parser.TikaDocumentParser;
import org.springframework.ai.transformer.TextSplitter;
import org.springframework.ai.transformer.TokenTextSplitter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DocumentVectorService {
@Autowired
private MilvusVectorStore milvusVectorStore;
private final TikaDocumentParser parser = new TikaDocumentParser();
private final TextSplitter textSplitter = new TokenTextSplitter(); // 可按需求调整块大小和重叠
public void processAndStoreDocument(Resource fileResource) throws Exception {
// 1. 文档解析(Tika支持PDF, DOCX, PPTX, TXT等)
Document document = parser.parse(fileResource);
// 2. 文本分块(避免单个文档过长,影响检索精度和上下文长度)
List<Document> documentChunks = textSplitter.split(document);
// 3. 向量化并存储(Spring AI底层自动调用EmbeddingClient)
milvusVectorStore.add(documentChunks);
System.out.println("文档处理成功,存储"+ documentChunks.size() + "个文本块。");
}
}B. RAG检索增强问答服务 (RagService)
这是系统的核心,执行"检索 - 构建提示 - 生成"的完整RAG流程。
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.milvus.MilvusVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Service
public class RagService {
@Autowired
private ChatClient chatClient;
@Autowired
private MilvusVectorStore milvusVectorStore;
// RAG生成的核心方法
public String generateAnswer(String userQuery) {
// 1. 向量相似度检索:从Milvus中查找最相关的文档块(例如Top 5)
List<Document> relevantDocs = milvusVectorStore.similaritySearch(userQuery, 5);
if (relevantDocs.isEmpty()) {
return "抱歉,在知识库中未找到相关信息。";
}
// 2. 构建带上下文的Prompt模板
// 注意:这是一个简单的模板,可以设计更复杂的Prompt工程
String contextString = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("\n---\n"));
String systemPrompt = """
你是一个专业的AI助手,请严格根据以下给定的上下文来回答问题。
上下文信息:
%s
要求:
- 回答必须只基于给定的上下文信息。
- 如果上下文信息不足以回答,请直接说明"根据现有信息无法准确回答"。
- 确保回答清晰、准确、有用。
问题:%s
""".formatted(contextString, userQuery);
// 3. 调用大模型生成最终答案
Prompt prompt = new Prompt(systemPrompt);
return chatClient.call(prompt)
.getResult()
.getOutput()
.getContent();
}
}C. 提供REST API接口 (RagController)
暴露简单易用的HTTP接口,供前端或其他服务调用。
java
import org.springframework.ai.milvus.MilvusVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.FileSystemResource;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
@RestController
@RequestMapping("/api/rag")
public class RagController {
@Autowired
private DocumentVectorService docService;
@Autowired
private RagService ragService;
// 文件上传与向量化
@PostMapping("/upload")
public String uploadDocument(@RequestParam("file") MultipartFile file) throws Exception {
// 处理文件上传和向量化逻辑
// ... (保存文件、调用 docService.processAndStoreDocument)
return "文档已成功处理并存入知识库。";
}
// 智能问答
@GetMapping("/ask")
public String askQuestion(@RequestParam("q") String question) {
return ragService.generateAnswer(question);
}
}第四章:企业级优化与进阶思考
为了让RAG系统真正具备"企业级"能力,仅完成基础功能是远远不够的,必须从以下维度进行加固:
-
检索性能调优:
- 索引策略 :对于千万级以上的向量数据,将
IVF_FLAT索引升级为HNSW索引,并精细调参(如M,efConstruction)。 - 混合检索 (Hybrid Search) :结合基于BM25的关键词检索和向量检索,能更全面地召回信息。可考虑在Milvus中集成,或在应用层做结果融合。
- 索引策略 :对于千万级以上的向量数据,将
-
增强Prompt工程:
- 根据业务领域优化Prompt模板,例如加入角色设定、输出格式规范、推理步骤引导等。
-
数据管理与同步:
- 增量索引:实现知识的实时或准实时更新,避免使用定期全量重建。
- **元数据过滤 (Metadata Filtering)**:在相似度检索的基础上,增加业务属性(如部门、日期)过滤,提升相关性。
-
系统健壮性与可观测性:
- 错误处理:为LLM API、向量数据库连接添加重试和熔断机制。
- 日志与监控:记录每次问答的检索到的文档、耗时、Token消耗等,用于问题回溯和成本分析。
- 权限控制:不同部门/用户只能查询其权限范围内的知识。
-
安全与合规:
- 在知识处理和RAG生成全链路进行敏感信息检测和脱敏。
总结
通过Spring AI与Milvus的组合,成功将企业级RAG架构从一个复杂的系统工程项目,转变为一次高效率的、以业务逻辑为核心的集成开发。
核心路径可归纳为:
**选择高性能向量数据库(Milvus)-> 利用高抽象框架(Spring AI)搭建骨架 -> 填充业务处理与优化的血肉。**
这种模式不仅极大降低了开发门槛和后期维护的复杂性,还确保了系统在高并发、大规模数据场景下的性能与可扩展性。
可以以此为基础,根据自身业务特性,在混合检索、多路召回、Agentic RAG等高级模式上不断探索,从而构建出更智能、更精准、更个性化的AI智能体。这不仅是技术的落地,更是数据资产向生产力的有效转化。