介绍
今天我们正式开源 Ling-2.6-flash ,这是一个总参数量达 1040亿 、激活参数量 74亿 的指令微调模型。
随着智能体能力进化,token消耗暴涨已成为落地应用的核心瓶颈。与传统对话不同,智能体工作流涉及海量输入与复杂多步执行,计算需求和用户成本急剧攀升。当行业纷纷转向"长推理"推高指标时,一个关键问题被忽视了:高频日常的智能体场景,真需要如此冗余的推理token吗?
面对愈演愈烈的token压力,Ling-2.6-flash选择了另一条路。它不以拉长输出换取指标提升,而是系统性地优化推理效率、token效率与智能体性能 ,在保持高度竞争力的同时,做到更快、更轻、更适配真实生产负载。
从顶层设计看,Ling-2.6-flash围绕三大核心优势构建:
- 混合线性架构带来更高推理效率
通过引入混合线性架构,我们在基础层面提升计算效率。在4×H20配置下,Ling-2.6-flash推理速度最高可达340 tokens/秒。换言之,它能以显著更优的能效比完成任务。 - token效率优化实现智能-效能平衡
训练阶段我们专门优化token效率,力求用更精简的输出完成任务。在完整Artificial Analysis 评测集中,Ling-2.6-flash仅用1500万token即达到竞争力表现,塑造出真正高性价比的智能-效能曲线。 - 针对智能体场景的定向强化
针对当前需求最旺盛的智能体场景,我们在工具调用、多步规划、任务执行等环节持续打磨。最终模型在BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench 等基准测试中,达到与更大激活参数模型相当的SOTA级表现。
评测表现
我们在多个权威基准测试中对Ling-2.6-flash进行了全面评估。Ling-2.6-flash 在BFCL-V4 、TAU2-bench 、SWE-bench Verified 、PinchBench 等代表性智能体基准中表现强劲。实际应用中,Ling-2.6-flash在Claude Code 、Kilo Code 、Qwen Code 、Hermes Agent 、OpenClaw等框架下均能提供优秀体验。
除智能体任务外,Ling-2.6-flash在通用知识 、数学推理 、指令跟随 和长上下文理解等方面同样表现优异,与同尺寸SOTA模型保持对齐。
- PinchBench:对比分数直接取自PinchBench官方排行榜(截至2026年4月20日),遵循其评估模式(可能为推理模式)。
- Claw-Eval:对比分数源自Claw-Eval官方排行榜(2026年3月25日版本),遵循其评估模式(可能为推理模式)。GPT-OSS-120B和GPT-5.4-mini的官方分数当前不可用,已省略。
- TAU2-Bench:使用官方v1.0.0代码和数据集进行评估。遵循GLM-5评估协议,我们在零售和电信领域进行了轻微提示调整,以确保用户清晰表达请求并防止会话过早终止。此外,所有评估领域均采用GPT-5.2作为用户代理。
- IFBench:GPT-OSS-120B(低配版)和GPT-5.4-mini(非推理版)的分数取自AA(人工分析)排行榜。所有其他模型性能数据均基于内部评估结果。
架构
Ling-2.6-flash延续了Ling 2.5引入的架构方向。在Ling 2.0基础上,我们采用了混合线性注意力机制 ,通过增量训练将原有的GQA注意力 设计升级为1:7 MLA + Lightning Linear混合架构。
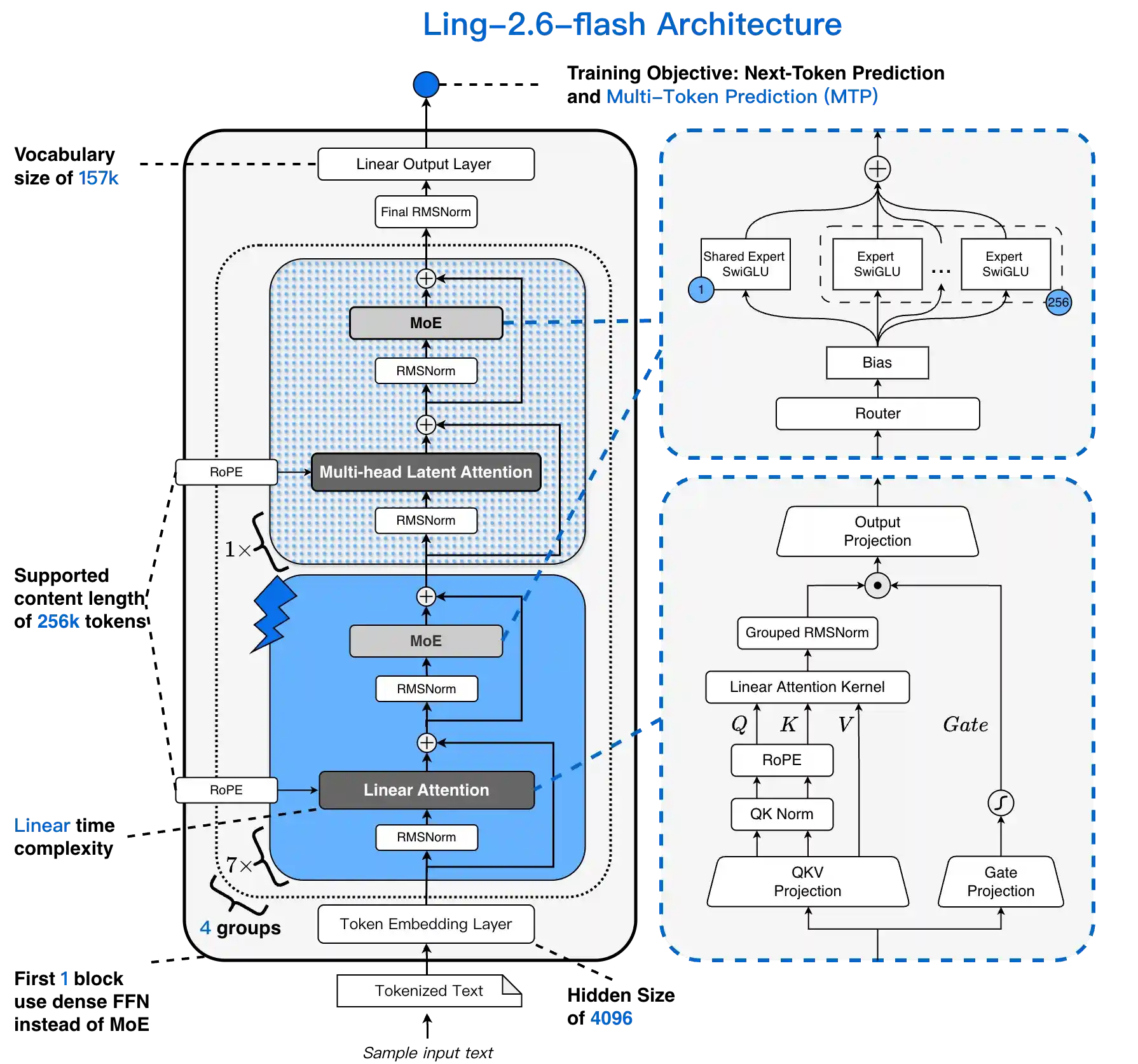
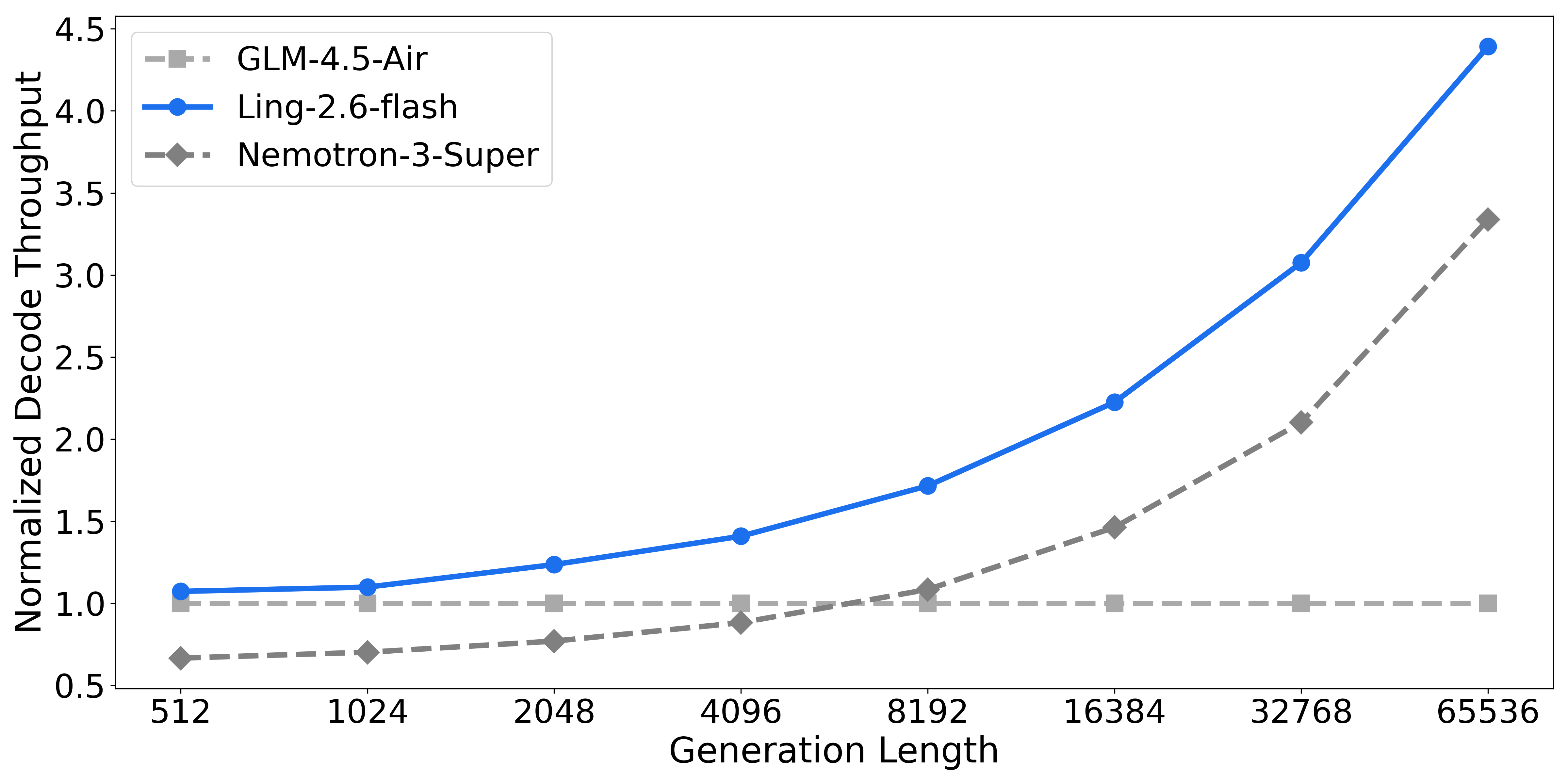
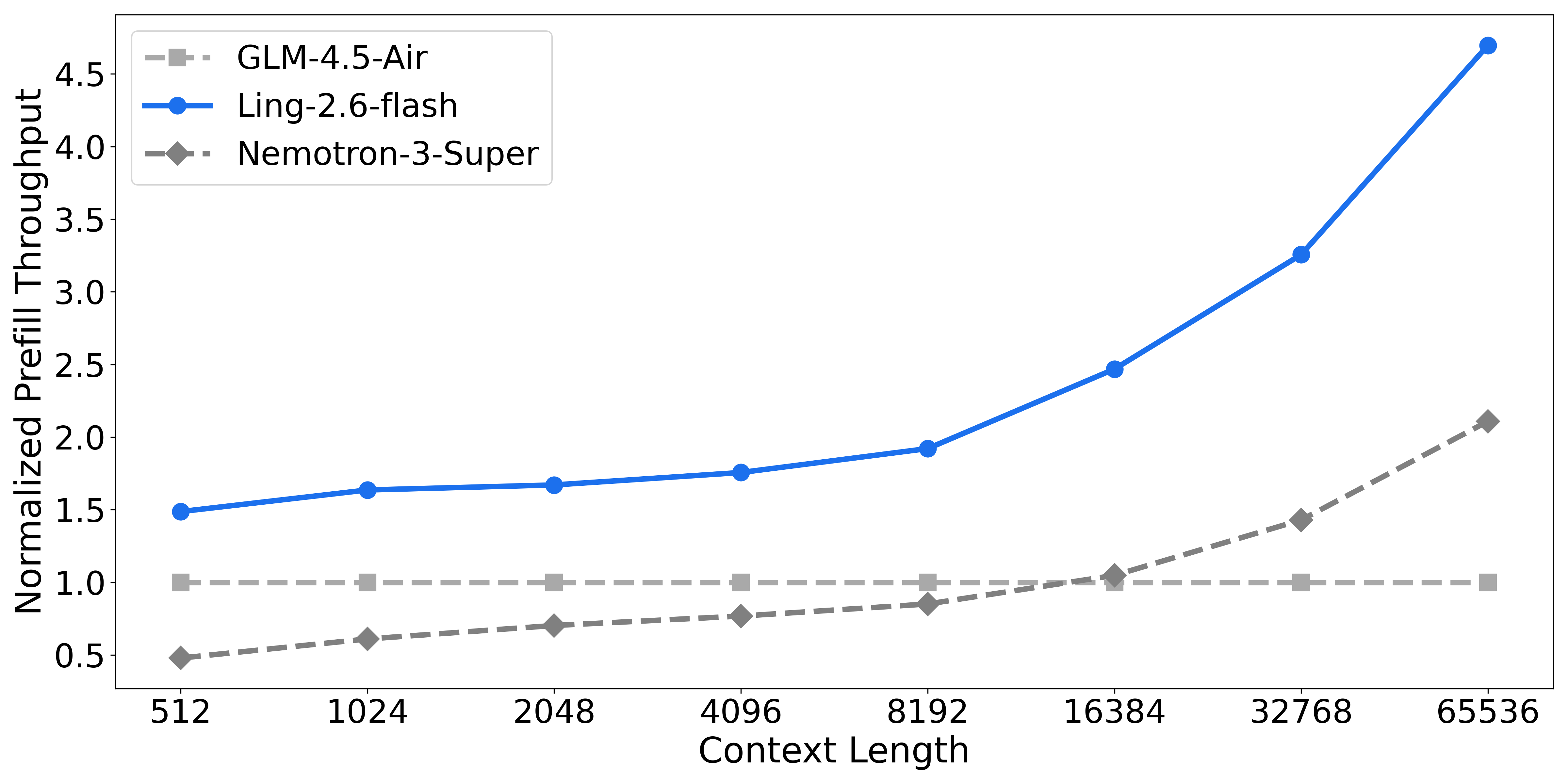
混合注意力机制 与高度稀疏的MoE架构 相结合,使Ling-2.6-flash在推理效率上具有显著优势。与同类规模的主流SOTA模型相比,Ling-2.6-flash不仅实现更快的首token响应速度,在长文本生成场景下还能获得大幅更高的吞吐量。其峰值预填充吞吐量 和解码吞吐量 最高可提升约4倍。
如下图所示,随着上下文长度和生成文本长度的增加,Ling-2.6-flash的吞吐量优势愈发明显。更重要的是,这种优势不仅体现在静态基准测试指标上。在实际部署环境中,模型会随着任务复杂度的提升持续释放更强的加速效益。
无论是长上下文理解 还是长文本生成 任务,Ling-2.6-flash在保持模型能力的同时,始终能提供更快的响应速度、更高的吞吐量以及更优的实际部署效率。
快速开始
SGLang(推荐)
环境准备
bash
pip install uv
uv venv ~/my_ling_env
source ~/my_ling_env/bin/activate
# uv pip "sglang-kernel>=0.4.1"
uv pip install "sglang[all]>=0.5.10.post1" --prerelease=allow运行推理
SGLang 现在支持 BF16 和 FP8 模型。具体取决于 ${MODEL_PATH} 中模型的 dtype。以下是在 4 个 GPU 上运行 Ling-2.6-flash 的示例,其中主节点 IP 为 ${MASTER_IP},服务器端口为 ${PORT}:
服务器
1. 标准推理(无 MTP)
bash
python -m sglang.launch_server \
--model-path $MODEL_PATH \
--tp-size 4 \
--pp-size 1 \
--dp-size 1 \
--trust-remote-code \
--context-length 262144 \
--tool-call-parser qwen25 \
--json-model-override-args '{"rope_scaling": {"rope_type": "yarn", "factor": 2.0, "rope_theta": 6000000, "partial_rotary_factor": 0.5, "original_max_position_embeddings": 131072}}' \
--dist-init-addr $MASTER_IP:2345 \
--port $PORT \
--nnodes 12. 基于MTP(多令牌预测)的推理
当前官方的SGLang实现版本存在MTP相关漏洞。为获得更优推理性能,我们建议安装修复后的版本。该补丁已提交审核,预计很快将合并至官方SGLang库。
安装我们的SGLang版本
bash
git clone -b ling_2_6 git@github.com:antgroup/sglang.git
cd sglang
pip install --upgrade pip
pip install -e "python"启动服务器
bash
python -m sglang.launch_server \
--model-path $MODEL_PATH \
--tp-size 4 \
--pp-size 1 \
--dp-size 1 \
--context-length 262144 \
--mamba-scheduler-strategy extra_buffer \
--speculative-algorithm NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.75 \
--max-running-requests 64 \
--max-mamba-cache-size 256 \
--tool-call-parser qwen25 \
--json-model-override-args '{"rope_scaling": {"rope_type": "yarn", "factor": 2.0, "rope_theta": 6000000, "partial_rotary_factor": 0.5, "original_max_position_embeddings": 131072}}' \
--trust-remote-code \
--dist-init-addr $MASTER_IP:2345 \
--port $PORT \
--nnodes 1客户端
bash
curl -s http://${MASTER_IP}:${PORT}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "auto", "messages": [{"role": "user", "content": "What is the capital of France?"}]}'vLLM
环境准备
bash
pip install uv
uv venv ~/my_ling_env
source ~/my_ling_env/bin/activate
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 uv pip install --editable . --torch-backend=auto运行推理
服务器
bash
vllm serve $MODEL_PATH \
--port $PORT \
--served-model-name my_model \
--trust-remote-code --tensor-parallel-size 4 \
--gpu-memory-utilization 0.85客户端
bash
curl -s http://${MASTER_IP}:${PORT}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "auto", "messages": [{"role": "user", "content": "What is the capital of France?"}]}'局限性与未来规划
灵析2.6-flash模型在追求极致智能与效率平衡的道路上已取得显著突破。该模型在工具调用、多步规划、长周期任务执行 等核心能力上实现大幅提升,配合推理效率与交互体验的系统性优化,现可更高效支撑规模化、高频率的自动化工作流,在实际生产环境中创造更大价值。
与此同时,我们清醒认识到极致效率必然伴随取舍。在部分高复杂度场景中,模型仍可能因推理深度限制出现工具幻觉 现象。此外,在中英文自然切换 与高度复杂指令合规性等方面仍有优化空间。
未来我们将持续探索智能效率边界:在保持模型高效推理特性的同时,着力优化输出质量 与token效率 的平衡,并持续增强模型在更广泛现实场景中的稳定性、易用性与交互体验。