最近要实现一个需求:需要对输入的8k可能嘈杂的音频(输入为裸的PCM流),做降噪处理,输出16k。网上查了一些资料,完成该模块后,经过测试,降噪效果明显,但是在设计的时候也踩了很多坑,在这里进行一个总结。
在处理实时语音或旧录音设备数据时,通常会面临两个问题,采样率低和背景噪音大,为了解决这个问题,我使用RNNoise和libresample构建了一个音频增强模块,实现了从8kHz采样率提升至16kHz,并同步完成深度学习降噪的闭环流程。
方案选择
**RNNoise:**是Xiph.Org基金会开发的轻量级、实时、深度学习语音降噪库。效果好、模型极小、延迟低。注意支持的音频格式:固定48000kHz、位深16bit(short)、单声道、帧长480样本(10ms)、原始PCM(.pcm),无压缩。
**libresample:**基于带限插值轻量级音频重采样库(高质量的 FIR 滤波器实现),主要用于在不同采样率之间(非整数倍也可以)做转换,在语音处理(尤其实时处理)里用得很多,因为API简单(C语言)、稳定、低延迟、支持流式处理(适合实时音频)。
- libresample:轻量、实时
- speexdsp resampler:更稳定
- soxr:高音质(离线)
RNNoise官方库原生只支持48kHz的音频,不直接支持16kHz的输入,它是专门为48kHz设计和训练的。
可以选择从8k重采样至48kHz,再使用RNNoise官方库深度学习降噪,处理完成之后再重采样至16k,但是可能会存在以下问题:
8kHz采样率意味着:根据奈奎斯特采样定理,最高只能表示4kHz的频率
- 8k->16k 最高仍然是4kHz(只是插值更平滑)
- 8k->48k 最高仍然是4kHz(不会变成24kHz)
信息已经丢了,升采样不会恢复。
- 8k->重采样至48k
插值倍率为6倍,中间会产生大量"虚假高频",高频是"编出来的",RNNoise/ML模型会误判,计算量增加(没收益)
- 8k->重采样至16k
插值倍率2倍,简单稳定、计算量低、频谱结构更自然,不容易引入伪影。
所以我没有采用8k->重采样48kHz->RNNoise(官方库),因为降噪效果可能变差、高频噪声"假信号增加)、模型输入分布异常,不仅不能提升音质,反而会严重浪费性能,甚至会让降噪效果变差。可以采用8k->重采样16k->RNNoise(魔改后的库)。
网上有魔改后的RNNoise库,支持16kHz,模型是按16kHz训练的,在使用之后,降噪效果也是可以的,下载下来就能用。
https://github.com/YongyuG/rnnoise_16k/tree/master
所以我们选择libresample做音频重采样,使用魔改后的RNNoise(下同)做深度学习降噪。libresample和RNNoise的API非常简单,注意实现时候的细节即可。
核心API介绍
libresample核心三个API:
cpp
// 创建重采样器。申请内存,建立滤波器管道
// highQuality音质,
void *resample_open(int highQuality, // 1表示高质量、0表示快速
double minFactor, // 最小重采样倍数
double maxFactor); // 最大重采样倍数
// 重采样核心:执行重采样
// factor=输出采样率/输入采样率
// 返回值为实际输出了多少采样点
// 必须放在一个 while 循环里反复调用,直到给的数据全部重采样完(不一定全部重采样完,也不一定全部输出完)
int resample_process(void *handle, // 重采样句柄
double factor, // 重采样比例
float *inBuffer, // 输入float音频
int inBufferLen, // 输入采样点数量
int lastFlag, // 1=最后一帧、0=还有数据
int *inBufferUsed, // 输出:实际用了多少输入采样
float *outBuffer, // 输出:float音频
int outBufferLen);// 输出:缓冲区最大长度
// 销毁重采样器
void resample_close(void *handle);好用归好用,但它也有两个非常容易踩坑的特点:
-
"群延迟"与输出不固定: 高质量的滤波器就像一个长长的缓冲管道,必然会带来几毫秒的计算延迟。必须配合 Ring Buffer(环形缓存) 才能驯服它。
-
它的 API 强制要求输入和输出必须是 float 或 double。这就意味着必须在外面包裹一层 short -> float 和 float -> short 的转换和限幅逻辑稍微增加了一点 CPU 的开销。
RNNoise核心三个API:
cpp
// 创建降噪器。申请内存,加载神经网络的初始权重,并分配RNN(循环神经网络)所需的历史隐藏状态
// 在整个音频流(比如一次通话、一个文件)开始时只调用一次。有状态,如果要同时处理两路不同的麦克风(比如双声道、或者会议里的两个人),必须调用两次create,生成两个独立的DenoiseState,绝不能混用,否则两路声音的状态会互相干扰,导致彻底乱码。
RNNOISE_EXPORT DenoiseState *rnnoise_create();
// 降噪处理核心。处理当前帧,传入一帧带噪声音频,经过神经网络计算,吐出一帧干净音频。
// out接收输出后数据的浮点数组,in输入的带噪数据的浮点数组(in和out可以指向同一个数组指针,RNNoise支持原地操作)
// 帧长是死规定:每次传入的数组长度必须严格是固定的(官方48k必须传480个float,魔改后的16k改版必须传160个float),少一个多一个都会越界崩溃。
RNNOISE_EXPORT float rnnoise_process_frame(DenoiseState *st, float *out, const float *in);
// 释放降噪器。释放内存。
RNNOISE_EXPORT void rnnoise_destroy(DenoiseState *st);代码实现
rnnoise_denoise.h
cpp
#ifndef RNNOISE_DENOISE_H
#define RNNOISE_DENOISE_H
#include <stdint.h>
#include <string.h>
#include <stdio.h>
#include "rnnoise.h"
#include "libresample.h"
#ifdef __cplusplus
extern "C"
{
#endif
// 固定配置
#define INPUT_8K_FRAME_SIZE 80 // 8kHz 80采样点 一帧 10ms
#define OUTPUT_16K_FRAME_SIZE 160 // RNNoise 改版支持 16kHz,一帧 10ms
// 将所有状态封装到一个上下文中,避免全局变量污染,并解决重采样吞吐延迟问题
typedef struct {
DenoiseState *denoise_st;
void *resample_st;
// 环形/线性缓存区:用于解决 libresample 输出点数不固定的问题
float resample_buffer[1024];
int buffer_len;
} AudioProcessorState;
// 创建降噪与重采样综合处理器
AudioProcessorState *audio_processor_create(void);
// 销毁处理器
void audio_processor_destroy(AudioProcessorState *st);
/**
* @brief 单次处理输入的一帧 8kHz 数据
* @param st 处理器句柄
* @param in_8k_buf 输入 16bit 单声道 8kHz PCM,固定 80 个采样点
* @param out_16k_buf 输出 16bit 单声道 16kHz PCM,固定 160 个采样点
* @return int 本次处理成功输出的 16kHz 采样点数(通常是 0 或 160)
*/
int audio_process_frame(AudioProcessorState *st, short *in_8k_buf, short *out_16k_buf);
#ifdef __cplusplus
}
#endif
#endif // RNNOISE_DENOISE_Hrnnoise_denoise.c
cpp
#include "rnnoise_denoise.h"
#include <stdlib.h>
AudioProcessorState *audio_processor_create(void)
{
// 分配内存
AudioProcessorState *st = (AudioProcessorState *)malloc(sizeof(AudioProcessorState));
if (!st)
return NULL;
// 1. 初始化降噪器
st->denoise_st = rnnoise_create();
if (!st->denoise_st)
{
fprintf(stderr, "rnnoise_create error.\n");
free(st);
return NULL;
}
// 2. 初始化重采样器 (highQuality=1, factor=2.0)
st->resample_st = resample_open(1, 2.0, 2.0);
if (!st->resample_st)
{
fprintf(stderr, "resample_open error.\n");
rnnoise_destroy(st->denoise_st);
free(st);
return NULL;
}
// 3. 初始化缓存状态
st->buffer_len = 0;
memset(st->resample_buffer, 0, sizeof(st->resample_buffer));
return st;
}
void audio_processor_destroy(AudioProcessorState *st)
{
if (st)
{
if (st->denoise_st)
rnnoise_destroy(st->denoise_st);
if (st->resample_st)
resample_close(st->resample_st);
free(st);
}
}
int audio_process_frame(AudioProcessorState *st, short *in_8k_buf, short *out_16k_buf)
{
float in_float_buf[INPUT_8K_FRAME_SIZE]; // short -> float
float temp_resample_buf[512]; // 临时接收本次重采样的数据,给够余量防溢出
float denoised_float_buf[OUTPUT_16K_FRAME_SIZE]; // 存储降噪后的音频
// 1. 8k short -> float
for (int i = 0; i < INPUT_8K_FRAME_SIZE; i++)
{
in_float_buf[i] = (float)in_8k_buf[i];
}
// 2. 重采样 8k -> 16k
int input_consumed;
int out_samples = resample_process(st->resample_st,
2.0,
in_float_buf,
INPUT_8K_FRAME_SIZE,
0,
&input_consumed,
temp_resample_buf,
512);
// 3. 将重采样出来的点数追加到 Buffer 中
if (out_samples > 0)
{
// 防止极端情况下越界(实际正常使用一般不会超出 1024)
if (st->buffer_len + out_samples > 1024)
{
fprintf(stderr, "Buffer overflow warning!\n");
st->buffer_len = 0; // 强制清空,避免崩溃
}
else
{
memcpy(st->resample_buffer + st->buffer_len, temp_resample_buf, out_samples * sizeof(float));
st->buffer_len += out_samples;
}
}
// 4. 判断 Buffer 中的点数是否凑够了一帧 (160点)
if (st->buffer_len >= OUTPUT_16K_FRAME_SIZE)
{
// 5. 核心降噪:从 Buffer 开头取 160 个点处理
rnnoise_process_frame(st->denoise_st, denoised_float_buf, st->resample_buffer);
// 6. Buffer 移位:把用掉的 160 个点丢弃,剩余的数据往前挪
st->buffer_len -= OUTPUT_16K_FRAME_SIZE;
if (st->buffer_len > 0)
{
memmove(st->resample_buffer,
st->resample_buffer + OUTPUT_16K_FRAME_SIZE,
st->buffer_len * sizeof(float));
}
// 7. 为 short 限幅
for (int i = 0; i < OUTPUT_16K_FRAME_SIZE; i++)
{
float sample = denoised_float_buf[i];
// 严格限幅,防止爆音
if (sample > 32767.0f)
sample = 32767.0f;
if (sample < -32768.0f)
sample = -32768.0f;
out_16k_buf[i] = (short)sample;
}
return OUTPUT_16K_FRAME_SIZE; // 成功输出了一帧数据
}
// 如果没凑够 160 个点,返回 0,告诉调用者这次不用写文件
return 0;
}核心架构与"避坑"指南
在开发过程中,我遇到了几个足以让项目流产的"深水坑":
一、线性缓存:解决重采样"断音"
cpp
// 将所有状态封装到一个上下文中,避免全局变量污染,并解决重采样吞吐延迟问题
typedef struct {
DenoiseState *denoise_st;
void *resample_st;
// 线性缓存区:用于解决 libresample 输出点数不固定的问题
float resample_buffer[1024];
int buffer_len;
} AudioProcessorState;a.为什么需要缓存?
缓存的作用主要有两个:
a.解决运算延迟导致的"断流"或"断音"问题。
b.解决算法库本身所需的缓存与实际传递数据的格式不匹配问题。
1、 运算延迟导致断流:libresample在转换采样率时(例如从8kHz转换到16kHz),并非输入多少数据就立刻输出成比例的数据。由于它使用的是高阶滤波算法,数据进入滤波器后会产生一定的延迟。当第一次输入80个采样点时的数据时,它可能正在"填满管道",因此输出的可能是0个点。如果这时不适用缓存把后续输出的数据暂存起来,就会出现音频播放时的"断流"或"断音"现象。
2、 输入输出格式格式不匹配:重采样后,输出的数据点数往往不是预期的固定数值。例如,期望每次都输出160个采样点(RNNoise处理一帧数据的硬性要求),但重采样器可能由于某些因素,某次只吐出了150个点。如果不使用缓存,直接把这150个点传递给RNNoise处理,程序就会出错,因为RNNoise必须接收满160个点才能进行计算。
因此,代码中通过memmove实现的"线性缓存",像一个"水池"一样,它的工作方式是:
- "蓄水":每次从重采样拿到数据后,先不急着处理,而是把它追加存入缓存(st->resample_buffer)中。
- "开闸":检查缓存中的数据是否满足了后续处理的最低要求(例如攒够了160个点)。
- "放水":只有满足条件了,才从缓存头部截取160个点送给RNNoise处理。
- "清空水池前部":处理完毕后,利用memmove将用掉的数据丢弃,把后面未满一帧的"零头数据"(例如剩下的10个点)挪到最前面,等待下一次"蓄水"。
这就完美解决了由于输入输出数据量不稳定而造成的各种问题,让后续的流水线能够平稳、顺滑的运行。
b.什么是"线性移位缓存"和"环形缓存?
判断一个缓存是不是真正的"环形缓存",核心标准只有一个:数据在缓存中是否会发生物理位置的移动。
cpp
// 6. Buffer 移位:把用掉的 160 个点丢弃,剩余的数据往前挪
st->buffer_len -= OUTPUT_16K_FRAME_SIZE;
if (st->buffer_len > 0)
{
memmove(st->resample_buffer,
st->resample_buffer + OUTPUT_16K_FRAME_SIZE,
st->buffer_len * sizeof(float));
}线性移位:当消费掉头部的160个数据后,调用了memmove。这个操作会强制将数组后半部分(剩余的未消费数据)整体复制并粘贴到数组的头部。数据在内存中的物理地址发生了真正的搬运。
环形缓存(标准的Ring Buffer):在真正的环形缓存中,数据一旦存入,其物理地址就再也不会改变。只移动"读指针"和"写指针"。当读指针读到数组的末尾时,它会瞬间"折返"到数组的开头继续读取,仿佛这个数组首尾相连成了一个圆环。
c.为什么代码实现成"线性缓存"?
通常来说,环形缓存因为不需要搬运内存,性能更高,被视为更优雅的数据结构。但在结合RNNoise和音频帧处理的特定场景下,"线性移位"方案不仅是合理的,甚至可以说是最佳实践。
主要原因有以下两点:
核心原因1: 算法接口的强制要求(内存必须连续)
这是最致命的限制。来看RNNoise的调用接口:
cpp
// RNNOISE_EXPORT float rnnoise_process_frame(DenoiseState *st, float *out, const float *in);
rnnoise_process_frame(st->denoise_st, denoised_float_buf, st->resample_buffer);RNNoise的rnnoise_process_frame核心降噪函数,要求传入的输入缓冲区(即第三个参数,const float *in),必须是一个物理内存连续的160个float的数组。
如果使用标准的环形缓存,由于它首位相接的特性,极有可能出现这样的情况:比如要读取的160个点中,前100个点在数组的末尾,后60个点"折返"到了数组的开头。这160个点在物理内存上不连续,被切断了。
那么,在面对这种情况时,怎么把数据喂给RNNoise呢?还需要再分配一个临时的160个大小的数组,把尾部的100个点复制进去,再把头部的60个点复制进去拼接在一起。
这不仅破坏了环形缓存"零拷贝"的初衷,还让代码逻辑变得极其复杂,很容易出现索引越界。
而代码实现的线性缓存,通过每次memmove,保证了未处理的数据永远都从索引0开始,并且永远是连续的。这就让喂给RNNoise的操作变得极其简单且安全。
核心原因2:性能损耗微乎其微(忽略不计)
使用memmove频繁搬运内存,难道不浪费CPU吗?
在宏观计算中确实如此,但在当前音频场景下,这种开销小到了可以忽略不计的地步:
1.数据量极小:resample_buffer只有1024个float,总共才4KB的内存。
2.搬运极快:现代的CPU都有专门针对小内存块移动的硬件优化指令,搬运几千个字节连几微妙都用不了。
3.触发频率低:这种搬运每10ms才发生一次,且通常只搬运几十个到一百多个点(因为每次都会尽量凑够160个点消耗掉)。
二、数值范围:RNNoise的"胃口"
这是最坑的一点!通常我们习惯将音频归一化到-1,0,1.0,但RNNoise的C库实际上是按16bit PCM的数值范围(+-32768)进行内部计算的。
错误做法:传入归一化后的0.0001,导致算法认为那是静音,完全不干活。
正确做法:保持原始浮点数值传入,降噪效果瞬间体现。
降噪测试
魔改的RNNoise库,也提供了测试demo,下载下来,编译后,会在bin目录下生成可执行文件rnn_gao_new,可直接快速测试16kHz的音频降噪效果。
提供16kHz的WAV格式音频,输出降噪后的16kHz的WAV格式音频。
bash
[root@VM-8-11-centos rnnoise_16k-master]# ./bin/rnn_gao_new
Usage:./rnn_gao_new [inputWav] [RNNnoise_output]下面是自己编写的一段测试代码。
test.c
cpp
#include <stdio.h>
#include <stdlib.h>
#include "rnnoise_denoise.h"
int main(int argc, char *argv[])
{
FILE *fin, *fout;
short in_8k[INPUT_8K_FRAME_SIZE];
short out_16k[OUTPUT_16K_FRAME_SIZE];
if (argc != 3) {
fprintf(stderr, "用法: %s <输入8k.pcm> <输出16k降噪后.pcm>\n", argv[0]);
return -1;
}
// 打开纯 PCM 文件
fin = fopen(argv[1], "rb");
fout = fopen(argv[2], "wb");
if (!fin || !fout) {
fprintf(stderr, "文件打开失败\n");
return -1;
}
// 初始化降噪与重采样处理器
AudioProcessorState *proc_st = audio_processor_create();
if (!proc_st) {
fprintf(stderr, "初始化失败\n");
return -1;
}
int total_out_samples = 0;
// 直接逐帧读取、处理、写入,没有任何文件头的干扰
while (fread(in_8k, sizeof(short), INPUT_8K_FRAME_SIZE, fin) == INPUT_8K_FRAME_SIZE)
{
// 返回 > 0 说明成功凑够了一帧(160点)输出
int out_count = audio_process_frame(proc_st, in_8k, out_16k);
if (out_count > 0) {
fwrite(out_16k, sizeof(short), out_count, fout);
total_out_samples += out_count;
}
}
// 释放资源
audio_processor_destroy(proc_st);
fclose(fin);
fclose(fout);
printf("处理完成!总共输出 %d 个 16kHz 的采样点\n", total_out_samples);
return 0;
}如果音频为8kHz的WAV格式,首选需要将8kHz的WAV音频,转换成8kHz的PCM。绝不能直接读.wav的前44个字节当音频,那是字符信息,必爆音,建议先用sox或ffmpeg转成纯.pcm。
准备一个8kHz的wav音频,使用sox或ffmpeg转成纯.pcm(绝不能直接读.wav的前44个字节当音频,那是字符信息,必爆音),编译生成可执行文件,运行输入8k的.pcm,输出降噪后的16k的.pcm,再使用sox或ffmpeg转成可以收听的wav音频。
例如:
bash
// 将8kwav音频转换成纯.pcm
sox 8k_noisy.wav -t raw -c 1 -r 8000 -b 16 -e signed-integer 8k.pcm
// 编译
sudo gcc -std=c99 -o test_denoise rnnoise_denoise.c test.c -I/root/rnnoise_16k-master/include -L /root/rnnoise_16k-master/src -l rnnLib -l resample -lm
// 输入8k的.pcm 输出降噪后的16k的.pcm
./test_denosie 8k.pcm output.pcm
// 将降噪后的16k的.pcm转换成16kwav音频
sox -t raw -c 1 -r 16000 -b 16 -e signed-integer output.pcm 降噪后8k_noisy.wav视觉验证
下面是我测试的一段嘈杂音频,降噪前后的频谱图。
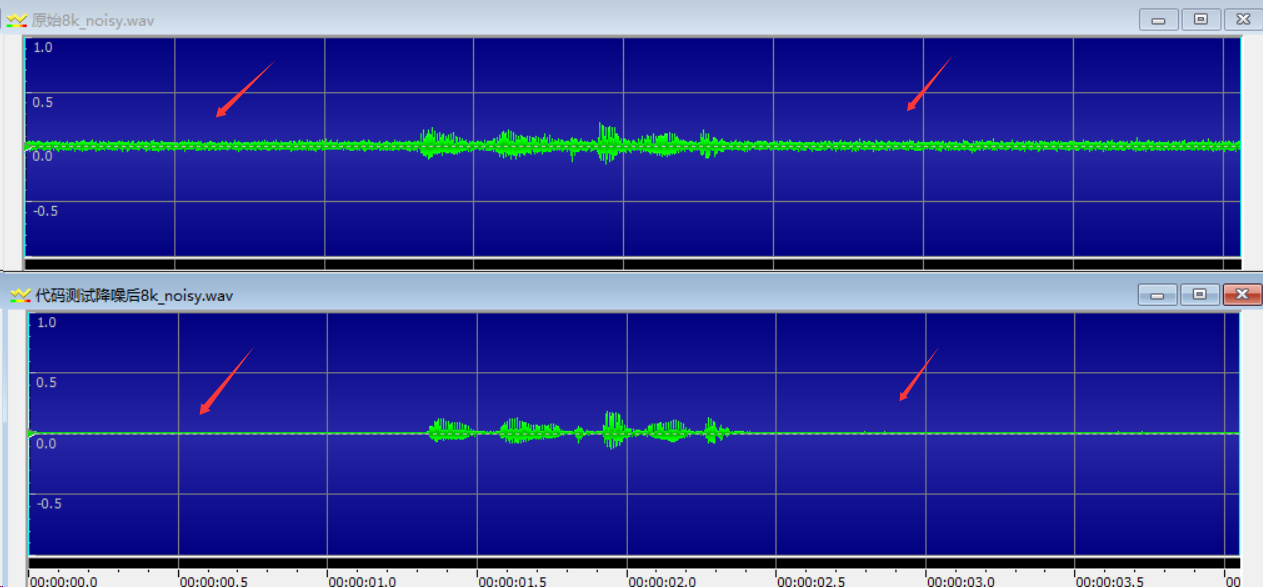
通过生成的频谱图,可以清晰看到降噪后的战果。
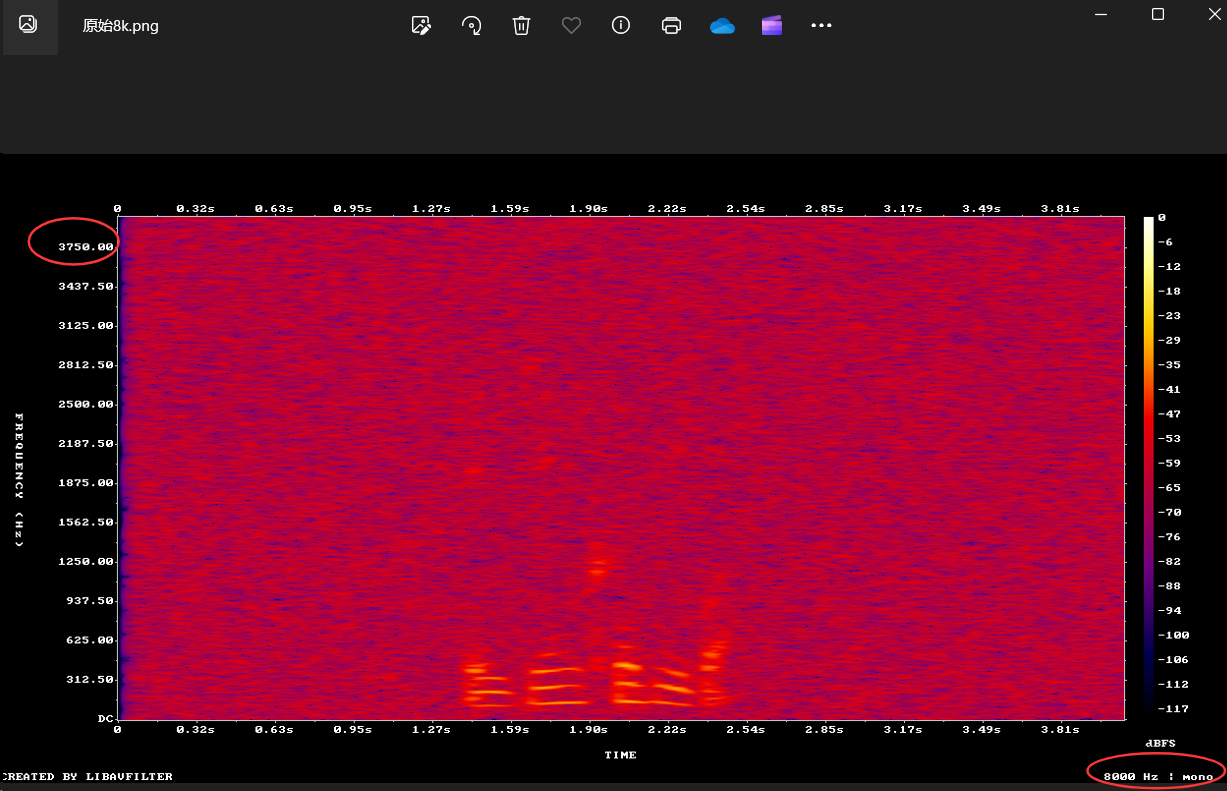
测试前频谱图:
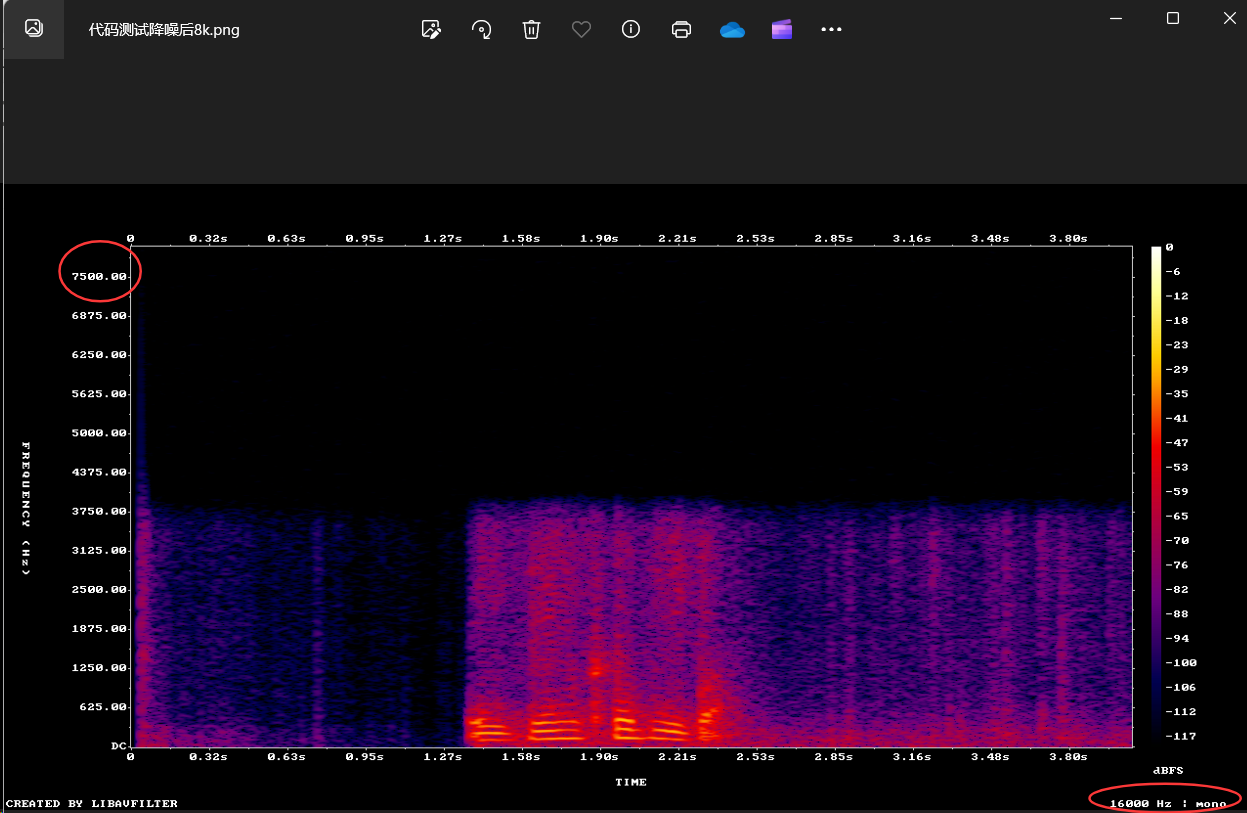
测试后频谱图:
1、降噪算法缺失在卖力干活:
看降噪前频谱图:整个画面充满了大面积的红色和橙色,说明背景里存在极其巨大的全频段底噪。
看降噪后频谱图:刺眼的红色/橙色噪点变成了深蓝色/黑色,证明RNNoise极其准确地识别并压制了环境噪音,同时保留了中间那坨红色的语音能量。
2、完美印证了重采样的成功:
看降噪前频谱图纵轴:原本的8k音频,频谱纵轴最高只到大约4000Hz的位置,右下角文字也显示了8000Hz:mono。
看降噪后频谱图纵轴:频谱纵轴的上限被拉高到了接近8000Hz,右下角文字也显示16000Hz:mono,证明libresample重采样代码毫无瑕疵的完成了从8k到16k的重采样。
经过视觉和听觉的验证,降噪效果是非常明显的。
集成模块
该模块集成到项目中,应该这样使用。
cpp
#include "rnnoise_denoise.h"
// ==========================================
// 1. 初始化(在程序启动,或打开麦克风时调用一次)
// ==========================================
AudioProcessorState *proc_st = audio_processor_create();
if (!proc_st) {
// 处理初始化失败逻辑...
}
// ==========================================
// 2. 音频回调/循环处理(假设每 10ms 触发一次)
// ==========================================
short input_8k[80]; // 你的业务输入:8kHz音频,固定80个点 (10ms)
short output_16k[160]; // 用于接收输出:16kHz降噪后音频,160个点
// -> 这里填充你的 8kHz 原始音频到 input_8k 中
// read_from_mic(input_8k, 80);
// -> 调用处理核心
int out_count = audio_process_frame(proc_st, input_8k, output_16k);
// -> 判断是否有有效输出(非常重要!)
if (out_count > 0) {
// 成功!output_16k 中现在包含了 160 个点的 16kHz 干净声音
// 可以拿去播放、推流、编码或保存
// send_to_speaker(output_16k, out_count);
} else {
// 内部缓存还没凑够一帧,本次暂无输出。
// 这是正常现象,直接跳过本次写入,等下一次循环继续喂数据即可。
}
// ==========================================
// 3. 退出时释放(关闭程序,或关闭麦克风时调用)
// ==========================================
audio_processor_destroy(proc_st);扩展:
彻底告别"爆音":还可以将一个软启动(Fade-in):在音频流开启的前100ms施加一个平滑的增益渐变,压制算法冷启动时的脉冲噪声。
总结:音频处理不仅仅是算法的堆砌,更是对数据流细节的极致掌控。虽然由于8kHz原始高频信息丢失,我们无法完全还原成"录音室音质",但在实时通讯和语音识别的处理中,这套音频降噪模块已经足够强大。