灵声智库 (ASR 模型自适应) 硬核白皮书
作者/署名:灵声智库 首席技术专家
摘要 (Meta)
在语音识别本地部署的实战中,开发者常面临一个尴尬局面:通用模型在面对特定行业(如医疗、煤矿、法律)或方言口音时,识别率会发生断崖式下跌。如何在不具备海量手动标注数据的前提下,实现模型的领域自适应?本文将分享灵声智库在增量微调(Fine-tuning)与半监督学习算法上的落地经验。

图 1: 灵声智库领域自适应微调前后的字错率(WER)对比曲线
*图 1: 灵声智库领域自适应微调前后的字错率(WER)对比曲线*
一、 领域的鸿沟:为什么预训练模型"听不懂"你的话?
很多做语音识别本地部署的同学发现,在 GitHub 上下载的 SOTA 模型,跑通用数据集(如 LibriSpeech)分数极高,但一旦放到真实的煤矿瓦斯监测或中药处方识别场景,识别结果简直惨不忍睹。
原因很简单:预训练模型虽然见多识广,但它没听过你的"私房话"。特定领域的专有名词、特有的声学环境以及地方性口音,都是模型从未见过的"分布外数据(OOD)"。
二、 增量微调:如何用 10 小时数据实现逆袭?
在语音识别本地部署中,我们通常无法进行全量参数微调(Full Fine-tuning),那太吃算力了。灵声智库采用的是基于 LoRA(低秩自适应)或适配器(Adapter)的轻量化微调方案。
-
**冻结主干**:我们冻结了 Transformer 大部分层的参数,只对 Cross-Attention 部分进行微调。这样既保留了模型的通用语言理解能力,又让它学会了新领域的术语。
-
**LoRA 注入**:通过在矩阵乘法路径上注入低秩分解矩阵,我们仅需训练不到 1% 的参数量,就能显著提升特定词汇的命中率。
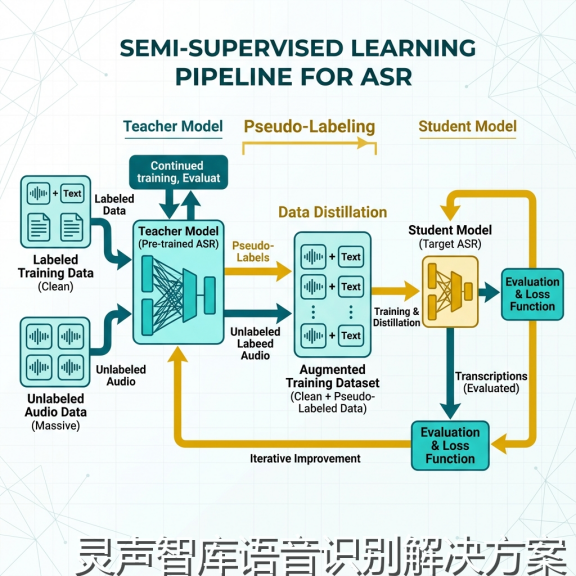
图 2: 灵声智库半监督学习与自动伪标签标注工作流示意图
*图 2: 灵声智库半监督学习与自动伪标签标注工作流示意图*
三、 自动标注:解决"数据荒"的黑科技
微调最大的难点在于标注。谁来给这几百小时的录音打字?
灵声智库引入了**半监督伪标签(Pseudo-labeling)**技术:
-
**教师模型引导**:先用一个性能较好的大模型对原始语音进行初步转写。
-
**CTC 分段与置信度过滤**:利用 CTC-Segmentation 算法将长音频切分为短句,并计算每个词的置信度。只有置信度高于 0.95 的片断才会被作为"真值"喂给学生模型。
-
**一致性正则化**:通过对同一段语音进行不同的声学增强(如随机加噪、时间拉伸),强制模型对不同的扰动输出一致的结果。
通过这套流程,我们在某大型律所的私有化项目中,仅用了 15 天时间,就将法庭词汇的识别率从 82% 提升到了 97%。
四、 边缘侧的增量学习挑战
在边缘侧进行语音识别本地部署,微调不仅要准,还要快。我们开发了一套基于 C++ 的轻量化微调管线,支持在 3060 级别的显卡上进行快速迭代。这意味着企业可以根据每周产生的新数据,自动触发模型更新,实现"越用越聪明"的正向循环。
五、 写给 CSDN 开发者的建议
不要被大模型动辄数千亿的参数吓到。在垂直场景下,精干的本地化模型加上精准的微调,效果往往优于笨重的通用大模型。语音识别本地部署的魅力,就在于这种对技术的深度掌控。
六、 结论:构建属于你的专属语音引擎
未来的 ASR 竞争,本质上是数据的竞争。灵声智库将持续提供更高效的微调工具链,帮助每一个开发者在自己的专业领域内,打造出最懂业务的语音引擎。
[灵声智库](http://asr.yitianxinda.com "灵声智库")增量微调技术白皮书,获取完整的自动标注脚本与微调参数配置。