从零构建企业大脑:RAG系统全流程实战
作者 :Weisian
发布时间:2026年4月

直击痛点:
"公司有成千上万份PDF、Word、Excel文档,员工每天花大量时间翻找资料,却总是找不到想要的答案。想让AI基于内部知识库回答问题,但它要么胡说八道,要么说'我不知道'。更头疼的是,文档每天都在更新,AI的记忆却停留在上周------难道只能让知识继续沉睡在文件服务器里?"
当你试图让大模型基于企业内部知识回答问题时,纯RAG系统面临着三大挑战:文档格式繁杂(PDF、Word、Excel、PPT)、检索精度不够(关键信息漏掉)、知识无法实时更新(文档改了,AI还在用旧数据)。
想象一下:你给公司知识库配了一个"图书管理员"(RAG系统):
- 文档加载器:能读懂PDF、Word、Excel等各种格式的"书籍"
- 文本分割器:把厚书拆成"章节卡片",方便快速查找
- 向量检索:建立"索引卡",根据问题快速定位相关章节
- 重排序:从一堆卡片中挑出最相关的几张
- LLM阅读:基于找到的卡片,用通俗语言回答问题
- 引用溯源:告诉用户答案来自哪本书、哪一页

这一切的破局点,在于构建一套完整的RAG系统------它让LLM从"胡说八道的书生"变成"有据可查的专家"。
📌 核心一句话 :
企业级RAG系统 = Ingestion Pipeline(数据摄入) + Retrieval Engine(检索引擎) + Generation(生成链路) ,让LLM基于企业私有知识库给出准确、可追溯、可更新的答案。
📌 RAG金句先记牢:
- 核心类比:RAG = 给LLM配一个"图书馆+图书管理员"
- 核心流程:Ingest(摄入)→ Index(索引)→ Retrieve(检索)→ Rerank(重排)→ Generate(生成);
- 数据管道:从文档到向量库的"加工流水线"------加载→分割→嵌入→存储
- 混合检索:关键词匹配(BM25)+ 语义检索(向量)双管齐下 = 召回率↑ + 精准度↑;
- 重排序:从100个候选结果中挑出最相关的5个(像面试复试),把最相关段落顶到前面;
- 引用溯源:答案来自哪份文档的哪一页,可追溯可验证
- 评估体系:Ragas自动化测试------不再凭感觉调优
- 增量更新:文档变了,向量库也跟着变,AI不会"失忆"
- 部署关键:LangServe 封装为 API,前端通过 Streamlit 调用,支持权限控制与审计。

一、认知入门:为什么企业需要RAG系统?
1.1 纯LLM的"知识边界"
如果你直接让大模型回答企业内部问题,会遇到三个致命问题:
- 知识缺失:LLM训练数据不包含企业私有文档
- 时效性差:文档更新后,LLM的知识还停留在几个月前
- 无法溯源:不知道答案来自哪里,无法验证真伪
python
# ❌ 纯LLM无法回答企业私有问题
from langchain_ollama import ChatOllama
llm = ChatOllama(model="qwen2_5-7b-q6", base_url="http://localhost:11434")
response = llm.invoke("根据公司制度,年假怎么申请?")
print(response.content)
# 输出:我不知道,或者给出通用的年假知识(不是公司特有的)
1.2 RAG的核心价值:给LLM配一个"图书馆"
| 模式 | 类比 | 核心特点 | 适用场景 |
|---|---|---|---|
| 纯LLM | 闭门造车的学者 | 靠记忆回答,知识有限 | 通用知识问答 |
| 微调LLM | 死记硬背的学生 | 记住特定知识,但更新成本高 | 固定知识领域 |
| RAG | 带图书馆的专家 | 实时检索最新资料,答案可溯源 | 企业知识库、动态数据 |
核心结论 :RAG是企业私有知识库问答的最优解,90%的企业场景都应该优先选择RAG而非微调。

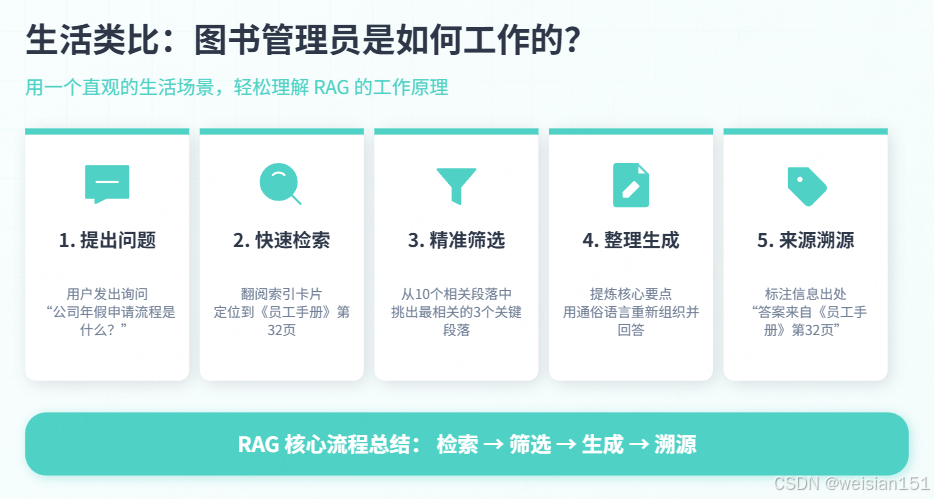
1.3 生活类比:图书管理员是如何工作的?
想象你有一个图书管理员:
- 你提问:"公司年假申请流程是什么?"
- 管理员检索:快速翻阅索引卡,找到《员工手册》第32页
- 管理员筛选:从10个相关段落中,挑出最相关的3个
- 管理员整理:把关键信息摘出来,用通俗语言告诉你
- 管理员溯源:告诉你答案来自《员工手册》第32页
这就是RAG的核心流程:检索 → 筛选 → 生成 → 溯源
二、架构设计:企业 RAG 的五大核心模块
2.1 整体架构图
[用户提问]
↓
[API网关 (FastAPI/LangServe)] → [权限校验]
↓
[检索引擎]
├─ 向量检索 (Chroma + BGE-Embedding)
├─ 关键词检索 (BM25)
└─ 混合融合 + BGE-Reranker 重排序
↓
[生成链路]
├─ Prompt 注入上下文 + 引用要求
├─ LLM 生成答案 (Qwen/Ollama)
└─ 后处理:提取引用信息
↓
[返回结果:答案 + 溯源链接]
[后台任务]
├─ 数据管道:定时扫描 docs/ 目录
├─ 增量更新:新文件自动解析入库
└─ 评估系统:Ragas 定期跑测试集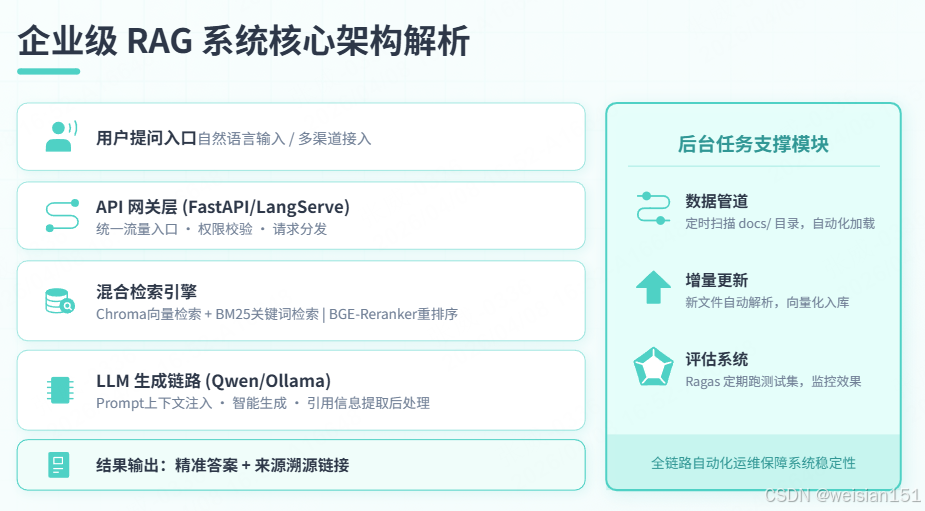
2.2 核心模块职责与选型说明

模块一:接入与安全层
- 职责:统一 API 入口、请求路由、用户认证与权限校验。
- 选型 :FastAPI + LangServe
- FastAPI 提供高性能异步接口、自动文档(Swagger)
- LangServe 原生支持 LangChain 链路的快速部署与调试
- 补充说明:支持基于角色的访问控制(RBAC),可在网关层拦截未授权请求,保障企业数据安全。
模块二:检索引擎(检索增强核心)
-
职责:从知识库中快速、精准地检索与用户问题相关的文档片段。
-
技术组合 :
组件 选型 作用 稠密向量检索 BGE-M3 Embedding + Chroma 语义匹配,捕捉深层含义 稀疏关键词检索 BM25 (通过 LangChain 或 Elasticsearch 集成) 精确匹配专业术语、编号等 混合融合 加权平均 / RRF(倒数排名融合) 综合语义与关键词结果,提升召回鲁棒性 重排序 BGE-Reranker-V2-M3 对候选结果精细排序,将最相关片段置于前列 -
优化点 :
- 支持元数据过滤(如按部门、时间、文档类型筛选),提升检索精准度
- 可配置检索阈值与 Top-K 数量,适配不同业务场景
模块三:生成链路(答案合成)
-
职责:将检索到的上下文与用户问题组合,调用 LLM 生成结构化、可信的答案。
-
关键流程 :
- Prompt 构建:注入上下文、引用格式要求、角色设定(如"你是企业知识助手")
- LLM 调用:Qwen2.5-7B(Ollama 本地部署),兼顾性能与数据隐私
- 后处理 :从 LLM 输出中提取引用标记,结构化为引用列表(如
[1] 文件名.pdf)
-
输出格式示例 :
json{ "answer": "根据文档,... [1]", "references": [ {"source": "docs/技术方案.pdf", "content": "相关片段..."} ] }

模块四:数据管道与知识库管理
- 职责:实现文档的自动化入库、更新、删除,保持知识库与源文件同步。
- 技术实现 :
- 使用
Unstructured统一解析 PDF、Word、Markdown 等格式 - 支持增量更新:通过文件哈希或修改时间检测变更,仅处理新增/修改文件
- 定时任务(如 APScheduler)或文件系统监听(watchdog)触发同步流程
- 使用
- 数据流向:原始文档 → 解析 → 切片(chunking) → 向量化 → 写入 Chroma + 元数据存储
模块五:评估与运维体系
- 职责:持续监控 RAG 系统质量,支撑迭代优化。
- 评估工具 :Ragas
- 支持指标:上下文相关性(Context Relevancy)、答案真实性(Faithfulness)、答案相关性(Answer Relevancy)等
- 可定期(如每日)在测试集上运行,生成质量报告
- 运维补充 :
- 日志记录:记录每次请求的检索结果、生成耗时、引用情况,便于回溯分析
- 可视化监控:可选集成 LangSmith 或本地 Prometheus + Grafana 展示检索延迟、召回率等指标
2.3 技术栈选型总览(本地化优先)
| 组件 | 选型 | 理由 |
|---|---|---|
| LLM | Qwen2.5-7B (Ollama) | 中文理解与生成能力强,支持工具调用,可完全本地化部署,无数据外传风险 |
| Embedding | BGE-M3 (Ollama) | 支持稠密 + 稀疏向量联合表示,中英双语表现优异,适合混合检索架构 |
| Reranker | BGE-Reranker-V2-M3 | 开源中文重排序 SOTA,显著提升排序头部相关性,降低 LLM 幻觉风险 |
| 向量库 | Chroma | 轻量级、嵌入式部署,支持元数据过滤与持久化,与 LangChain 集成顺畅 |
| 文档解析 | Unstructured + PyPDF2 + python-docx | 覆盖 PDF、Word、Excel、PPT、Markdown 等常见格式,解析稳定性高 |
| 评估 | Ragas | 无需人工标注即可自动化评估 RAG 各环节质量,便于持续迭代 |
| 部署 | LangServe + Docker | 快速封装 RAG 链为 RESTful API,Docker 容器化便于编排与横向扩展 |
2.4 架构亮点与设计考量
- 本地化优先:全栈模型与中间件均支持私有化部署,满足企业对数据安全与合规的要求。
- 检索增强鲁棒性:混合检索 + 重排序架构兼顾语义理解与关键词精确匹配,提升复杂查询的召回与排序质量。
- 可观测与可迭代:内置评估体系(Ragas)与日志机制,支持数据驱动的持续优化。
- 轻量但不失扩展性:Chroma + FastAPI + Ollama 组合资源占用低,可单机运行,也可通过容器化平滑扩展为分布式部署。
三、项目初始化:目录结构与依赖
3.1 项目目录结构
rag_enterprise/
├── data/ # 原始文档目录
│ ├── raw/ # 待处理的文档
│ └── processed/ # 处理后的文档
├── chroma_db/ # 向量数据库存储
├── src/
│ ├── ingestion/ # 数据摄入模块
│ │ ├── loader.py # 文档加载器
│ │ ├── splitter.py # 文本分割器
│ │ └── pipeline.py # 数据管道
│ ├── retrieval/ # 检索引擎
│ │ ├── vector_store.py # 向量库操作
│ │ ├── hybrid_search.py # 混合检索
│ │ └── reranker.py # 重排序
│ ├── generation/ # 生成链路
│ │ ├── prompt.py # Prompt模板
│ │ └── llm_client.py # LLM调用
│ ├── api/ # API接口
│ │ └── app.py # FastAPI服务
│ └── evaluation/ # 评估模块
│ └── ragas_eval.py # 自动化测试
├── scripts/
│ ├── ingest.py # 数据摄入脚本
│ └── update.py # 增量更新脚本
├── requirements.txt
└── README.md3.2 依赖安装
bash
# requirements.txt
langchain==0.3.0
langchain-community==0.3.0
langchain-ollama==0.2.0
chromadb==0.5.0
pypdf==4.0.0
python-docx==1.1.0
openpyxl==3.1.0
sentence-transformers==2.7.0
fastapi==0.115.0
uvicorn==0.30.0
streamlit==1.37.0
ragas==0.1.0
bash
# 安装依赖
pip install -r requirements.txt四、数据管道:从文档到向量库
4.1 文档加载器(支持多格式)

python
# src/ingestion/loader.py
"""
多格式文档加载器
支持:PDF、Word、Excel、TXT、Markdown
"""
import os
from typing import List, Dict, Any
from langchain_community.document_loaders import (
PyPDFLoader,
UnstructuredWordDocumentLoader,
UnstructuredExcelLoader,
TextLoader,
UnstructuredMarkdownLoader
)
from langchain_core.documents import Document
class MultiFormatLoader:
"""多格式文档加载器"""
def __init__(self, data_dir: str = "data/raw"):
self.data_dir = data_dir
self.loaders = {
".pdf": PyPDFLoader,
".docx": UnstructuredWordDocumentLoader,
".doc": UnstructuredWordDocumentLoader,
".xlsx": UnstructuredExcelLoader,
".xls": UnstructuredExcelLoader,
".txt": TextLoader,
".md": UnstructuredMarkdownLoader
}
def load_documents(self) -> List[Document]:
"""加载目录下所有文档"""
all_docs = []
for root, dirs, files in os.walk(self.data_dir):
for file in files:
file_path = os.path.join(root, file)
ext = os.path.splitext(file)[1].lower()
if ext in self.loaders:
try:
loader_class = self.loaders[ext]
# TextLoader需要指定编码,避免中文乱码/报错
if ext == ".txt":
loader = loader_class(file_path, encoding="utf-8")
else:
loader = loader_class(file_path)
docs = loader.load()
# 添加元数据
for doc in docs:
doc.metadata["source"] = file_path
doc.metadata["filename"] = file
doc.metadata["filetype"] = ext
all_docs.extend(docs)
print(f"✅ 已加载: {file}")
except Exception as e:
print(f"❌ 加载失败 {file}: {str(e)}")
print(f"\n📊 共加载 {len(all_docs)} 个文档片段")
return all_docs
# 测试
if __name__ == "__main__":
loader = MultiFormatLoader("data/raw")
docs = loader.load_documents()
print(f"文档片段数: {len(docs)}")运行结果:
4.2 文本分割器(智能切分)

python
# src/ingestion/splitter.py
"""
智能文本分割器
支持:按语义切分、重叠窗口、自定义分隔符
"""
from langchain_text_splitters.character import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from typing import List
class SmartSplitter:
"""智能文本分割器"""
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
"""
初始化分割器
:param chunk_size: 每个片段大小(字符数)
:param chunk_overlap: 重叠窗口大小
"""
self.splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""],
length_function=len
)
def split_documents(self, documents: List[Document]) -> List[Document]:
"""分割文档"""
chunks = self.splitter.split_documents(documents)
# 为每个片段添加索引
for i, chunk in enumerate(chunks):
chunk.metadata["chunk_id"] = i
chunk.metadata["chunk_size"] = len(chunk.page_content)
print(f"📄 分割完成: {len(documents)} 个文档 → {len(chunks)} 个片段")
return chunks
# 测试
if __name__ == "__main__":
from loader import MultiFormatLoader
loader = MultiFormatLoader("data/raw")
docs = loader.load_documents()
splitter = SmartSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
print(f"片段数: {len(chunks)}")
print(f"平均长度: {sum(len(c.page_content) for c in chunks)/len(chunks):.0f} 字符")运行结果:
4.3 向量嵌入与存储

python
# 👇 修复模块路径(必须放在最顶部)
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../..")))
"""
完整数据摄入管道
流程:加载 → 分割 → 嵌入 → 存储
"""
import os
import hashlib
from typing import List, Optional
from datetime import datetime
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from src.ingestion.loader import MultiFormatLoader
from src.ingestion.splitter import SmartSplitter
class IngestionPipeline:
"""数据摄入管道"""
def __init__(
self,
data_dir: str = "data/raw",
persist_dir: str = "chroma_db",
embedding_model: str = "nomic-embed-text:v1.5-32", # 嵌入模型
chunk_size: int = 500,
chunk_overlap: int = 50
):
self.data_dir = data_dir
self.persist_dir = persist_dir
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
# 初始化组件
self.loader = MultiFormatLoader(data_dir)
self.splitter = SmartSplitter(chunk_size, chunk_overlap)
# 初始化嵌入模型(使用Ollama)
self.embeddings = OllamaEmbeddings(
model=embedding_model,
base_url="http://localhost:11434"
)
# 初始化向量库
self.vector_store = Chroma(
collection_name="enterprise_knowledge",
embedding_function=self.embeddings,
persist_directory=persist_dir
)
def compute_doc_hash(self, file_path: str) -> str:
"""计算文件哈希,用于检测变化"""
with open(file_path, 'rb') as f:
return hashlib.md5(f.read()).hexdigest()
def ingest(self, force_reload: bool = False):
"""
执行数据摄入
:param force_reload: 是否强制重新加载所有文档
"""
print("="*60)
print("开始数据摄入")
print("="*60)
# 1. 加载文档
print("\n📚 步骤1: 加载文档...")
raw_docs = self.loader.load_documents()
if not raw_docs:
print("⚠️ 未找到文档,请将文档放入 data/raw/ 目录")
return
# 2. 分割文档
print("\n✂️ 步骤2: 分割文档...")
chunks = self.splitter.split_documents(raw_docs)
# 3. 添加时间戳和哈希
for chunk in chunks:
chunk.metadata["ingested_at"] = datetime.now().isoformat()
chunk.metadata["source_hash"] = self.compute_doc_hash(
chunk.metadata["source"]
)
# 4. 存入向量库
print("\n💾 步骤3: 存入向量库...")
if force_reload:
# 清空现有数据
self.vector_store.delete_collection()
self.vector_store = Chroma(
collection_name="enterprise_knowledge",
embedding_function=self.embeddings,
persist_directory=self.persist_dir
)
# 批量添加
batch_size = 100
for i in range(0, len(chunks), batch_size):
batch = chunks[i:i+batch_size]
self.vector_store.add_documents(batch)
print(f" 已添加 {min(i+batch_size, len(chunks))}/{len(chunks)} 个片段")
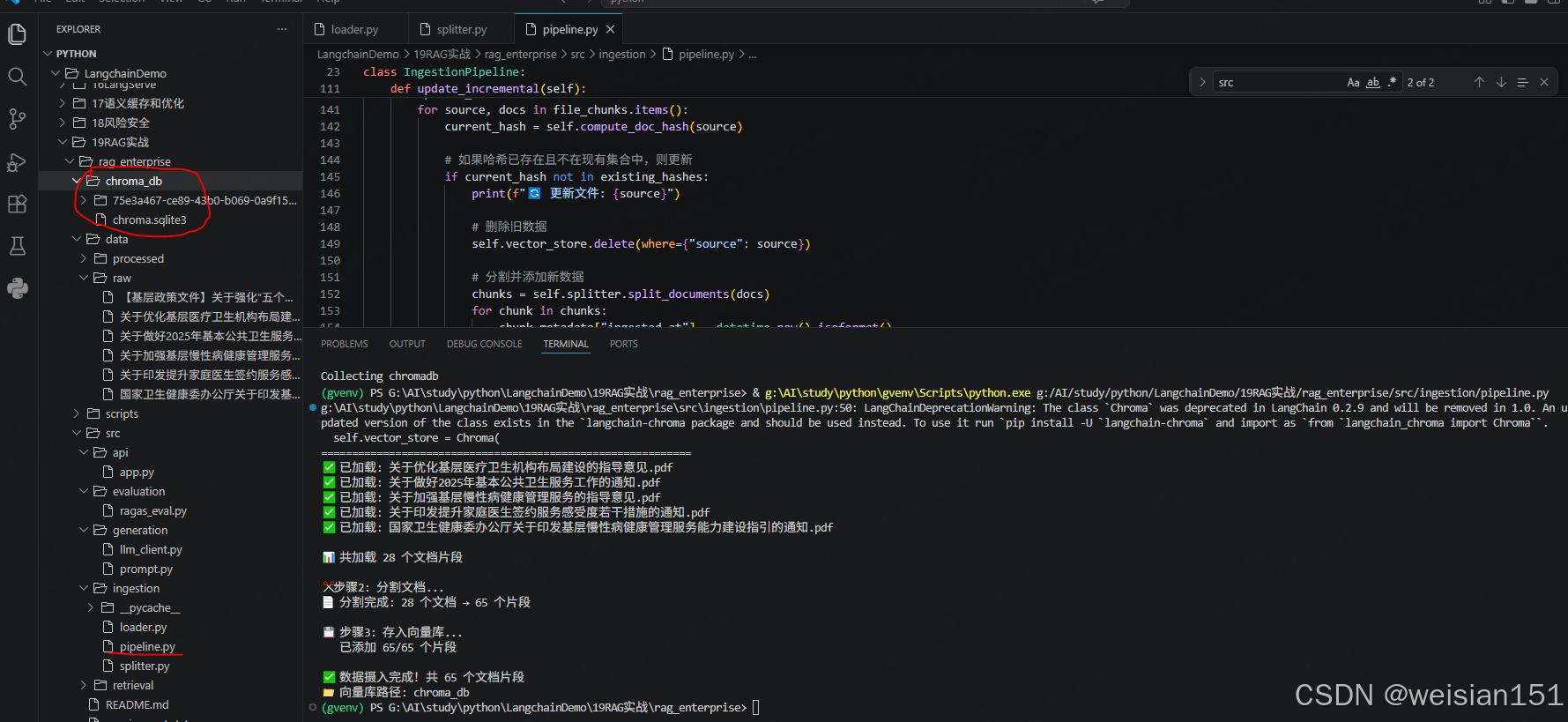
print(f"\n✅ 数据摄入完成!共 {len(chunks)} 个文档片段")
print(f"📁 向量库路径: {self.persist_dir}")
def update_incremental(self):
"""增量更新:只处理新增或修改的文档"""
print("="*60)
print("开始增量更新")
print("="*60)
# 获取当前已存储的文档哈希
existing_hashes = set()
try:
all_data = self.vector_store.get()
if all_data and "metadatas" in all_data:
for meta in all_data["metadatas"]:
if meta and "source_hash" in meta:
existing_hashes.add(meta["source_hash"])
except Exception as e:
print(f"⚠️ 读取现有数据失败: {e}")
# 加载所有文档
raw_docs = self.loader.load_documents()
# 按文件分组
file_chunks = {}
for doc in raw_docs:
source = doc.metadata["source"]
if source not in file_chunks:
file_chunks[source] = []
file_chunks[source].append(doc)
# 检查每个文件是否需要更新
updated_count = 0
for source, docs in file_chunks.items():
current_hash = self.compute_doc_hash(source)
# 如果哈希已存在且不在现有集合中,则更新
if current_hash not in existing_hashes:
print(f"🔄 更新文件: {source}")
# 删除旧数据
self.vector_store.delete(where={"source": source})
# 分割并添加新数据
chunks = self.splitter.split_documents(docs)
for chunk in chunks:
chunk.metadata["ingested_at"] = datetime.now().isoformat()
chunk.metadata["source_hash"] = current_hash
self.vector_store.add_documents(chunks)
updated_count += 1
print(f"\n✅ 增量更新完成!更新了 {updated_count} 个文件")
# 测试
if __name__ == "__main__":
pipeline = IngestionPipeline(
data_dir="data/raw",
persist_dir="chroma_db",
chunk_size=500,
chunk_overlap=50
)
# 首次摄入
pipeline.ingest(force_reload=True)
# 增量更新(第二次运行时使用)
# pipeline.update_incremental()运行结果:
五、检索引擎:混合搜索 + 重排序
5.1 混合检索(BM25 + 向量)

python
# src/retrieval/hybrid_search.py
"""
混合检索引擎
结合:BM25关键词匹配 + 向量语义检索
"""
from typing import List, Tuple
from langchain.schema import Document
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
import numpy as np
class HybridRetriever:
"""混合检索器"""
def __init__(
self,
vector_store: Chroma,
bm25_weight: float = 0.3,
vector_weight: float = 0.7
):
"""
初始化混合检索器
:param vector_store: 向量库实例
:param bm25_weight: BM25权重
:param vector_weight: 向量检索权重
"""
self.vector_store = vector_store
self.bm25_weight = bm25_weight
self.vector_weight = vector_weight
# BM25索引(需要从所有文档构建)
self.bm25_index = None
self.documents = []
def build_bm25_index(self, documents: List[Document]):
"""构建BM25索引"""
from rank_bm25 import BM25Okapi
import jieba
# 分词处理
tokenized_docs = []
for doc in documents:
tokens = list(jieba.cut(doc.page_content))
tokenized_docs.append(tokens)
self.bm25_index = BM25Okapi(tokenized_docs)
self.documents = documents
print(f"✅ BM25索引构建完成,共 {len(documents)} 个文档")
def hybrid_search(
self,
query: str,
k: int = 10,
rerank: bool = True
) -> List[Tuple[Document, float]]:
"""
混合检索
:param query: 查询文本
:param k: 返回文档数
:param rerank: 是否使用重排序
:return: (文档, 分数) 列表
"""
# 1. 向量检索
vector_results = self.vector_store.similarity_search_with_score(
query, k=k*2
)
# 2. BM25检索(如果有索引)
bm25_results = []
if self.bm25_index:
import jieba
query_tokens = list(jieba.cut(query))
bm25_scores = self.bm25_index.get_scores(query_tokens)
# 获取top-k的BM25结果
top_indices = np.argsort(bm25_scores)[-k*2:][::-1]
bm25_results = [
(self.documents[idx], bm25_scores[idx])
for idx in top_indices
]
# 3. 分数归一化
all_docs = {}
# 向量检索结果
for doc, score in vector_results:
doc_id = doc.metadata.get("source", id(doc))
all_docs[doc_id] = {
"doc": doc,
"vector_score": 1 - score, # 转换为相似度分数
"bm25_score": 0
}
# BM25检索结果
for doc, score in bm25_results:
doc_id = doc.metadata.get("source", id(doc))
if doc_id in all_docs:
all_docs[doc_id]["bm25_score"] = score / max(bm25_scores) if bm25_scores else 0
else:
all_docs[doc_id] = {
"doc": doc,
"vector_score": 0,
"bm25_score": score / max(bm25_scores) if bm25_scores else 0
}
# 4. 计算混合分数
for doc_id in all_docs:
v_score = all_docs[doc_id]["vector_score"]
b_score = all_docs[doc_id]["bm25_score"]
all_docs[doc_id]["hybrid_score"] = (
self.vector_weight * v_score +
self.bm25_weight * b_score
)
# 5. 排序
sorted_results = sorted(
all_docs.values(),
key=lambda x: x["hybrid_score"],
reverse=True
)[:k]
return [(r["doc"], r["hybrid_score"]) for r in sorted_results]5.2 重排序器(BGE-Rerank)
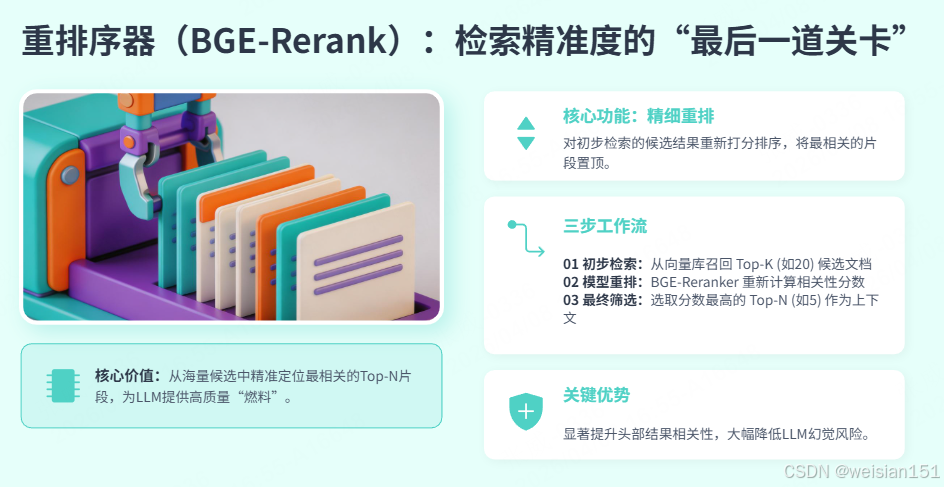
python
# src/retrieval/reranker.py
"""
重排序器
使用 BGE-Rerank 模型对检索结果精排
"""
import os
# 👇 关键:设置国内镜像(解决网络问题)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from typing import List, Tuple
from langchain_core.documents import Document
import torch
from sentence_transformers import CrossEncoder
class Reranker:
"""重排序器"""
def __init__(self, model_name: str = "BAAI/bge-reranker-base"):
"""
初始化重排序器
:param model_name: 重排序模型名称
"""
print(f"📥 加载重排序模型: {model_name}")
self.model = CrossEncoder(model_name)
def rerank(
self,
query: str,
documents: List[Tuple[Document, float]],
top_k: int = 5
) -> List[Tuple[Document, float]]:
"""
对检索结果重排序
:param query: 查询文本
:param documents: (文档, 原分数) 列表
:param top_k: 返回前k个
:return: (文档, 新分数) 列表
"""
if not documents:
return []
# 准备输入对
pairs = [(query, doc.page_content) for doc, _ in documents]
# 计算重排序分数
scores = self.model.predict(pairs)
# 组合新分数
reranked = [
(doc, float(score))
for (doc, _), score in zip(documents, scores)
]
# 按新分数排序
reranked.sort(key=lambda x: x[1], reverse=True)
return reranked[:top_k]
# 测试
if __name__ == "__main__":
# 模拟文档
query = "如何申请年假"
docs = [
(Document(page_content="年假申请需要提前3天提交"), 0.8),
(Document(page_content="请假流程:填写OA表单"), 0.7),
(Document(page_content="周末加班可调休"), 0.5),
]
reranker = Reranker()
results = reranker.rerank(query, docs, top_k=2)
for doc, score in results:
print(f"分数: {score:.4f} - {doc.page_content[:50]}")运行结果:
5.3 完整检索引擎集成

python
# 👇 修复模块路径(必须放在最顶部)
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../..")))
# src/retrieval/__init__.py
"""
检索引擎统一接口
"""
from typing import List, Dict, Any
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from src.retrieval.hybrid_search import HybridRetriever
from src.retrieval.reranker import Reranker
class RetrievalEngine:
"""统一检索引擎"""
def __init__(
self,
vector_store: Chroma,
use_hybrid: bool = True,
use_rerank: bool = True,
bm25_weight: float = 0.3,
vector_weight: float = 0.7
):
self.vector_store = vector_store
self.use_hybrid = use_hybrid
self.use_rerank = use_rerank
# 初始化混合检索器
if use_hybrid:
self.hybrid_retriever = HybridRetriever(
vector_store, bm25_weight, vector_weight
)
# 初始化重排序器
if use_rerank:
self.reranker = Reranker()
def search(
self,
query: str,
top_k: int = 5,
retrieve_k: int = 20
) -> List[Document]:
"""
检索文档
:param query: 查询文本
:param top_k: 最终返回文档数
:param retrieve_k: 初步检索文档数
:return: 文档列表
"""
# 1. 初步检索
if self.use_hybrid:
# 混合检索
results = self.hybrid_retriever.hybrid_search(
query, k=retrieve_k, rerank=False
)
else:
# 纯向量检索
results = self.vector_store.similarity_search_with_score(
query, k=retrieve_k
)
# 2. 重排序
if self.use_rerank and results:
results = self.reranker.rerank(query, results, top_k=top_k)
else:
results = results[:top_k]
return [doc for doc, _ in results]六、生成链路:带引用的回答生成
6.1 Prompt模板设计

python
# src/generation/prompt.py
"""
Prompt模板设计
支持:上下文注入、引用格式、安全规则
"""
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 基础RAG Prompt模板
RAG_PROMPT = ChatPromptTemplate.from_messages([
("system", """你是一个专业的企业知识库助手,基于提供的文档内容回答问题。
### 规则 ###
1. 只基于【参考文档】中的内容回答,不要使用外部知识
2. 如果文档中没有相关信息,明确说"未找到相关信息"
3. 回答要简洁、准确、有条理
4. 必须在回答末尾标注引用来源,格式:[来源: 文档名称]
### 参考文档 ###
{context}
### 当前对话 ###
用户问题: {question}
请回答:""")
])
# 带历史记录的Prompt模板
RAG_WITH_HISTORY_PROMPT = ChatPromptTemplate.from_messages([
("system", """你是一个专业的企业知识库助手,基于提供的文档内容回答问题。
### 规则 ###
1. 只基于【参考文档】中的内容回答
2. 结合对话历史理解问题
3. 必须在回答末尾标注引用来源
### 参考文档 ###
{context}"""),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{question}"),
])
def format_context(documents: list) -> str:
"""格式化文档上下文"""
context_parts = []
for i, doc in enumerate(documents, 1):
source = doc.metadata.get("filename", "未知来源")
content = doc.page_content
context_parts.append(f"[文档{i}] 来源: {source}\n{content}\n")
return "\n---\n".join(context_parts)
def format_references(documents: list) -> str:
"""格式化引用信息"""
sources = set()
for doc in documents:
source = doc.metadata.get("filename", "未知来源")
sources.add(source)
if not sources:
return ""
refs = "\n".join([f"- {s}" for s in sources])
return f"\n\n📚 引用来源:\n{refs}"6.2 LLM客户端封装
python
# 👇 修复模块路径(必须放在最顶部)
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../..")))
# src/generation/llm_client.py
"""
LLM客户端封装
支持:流式输出、引用提取、错误处理
"""
from typing import List, Dict, Any, Generator
from langchain_ollama import ChatOllama
from langchain_core.documents import Document
from src.generation.prompt import RAG_PROMPT, format_context, format_references
class LLMClient:
"""LLM客户端"""
def __init__(
self,
model: str = "qwen2_5-7b-q6",
base_url: str = "http://localhost:11434",
temperature: float = 0.1
):
self.llm = ChatOllama(
model=model,
base_url=base_url,
temperature=temperature,
num_ctx=8192
)
def generate(
self,
question: str,
documents: List[Document],
stream: bool = False
) -> Dict[str, Any]:
"""
生成回答
:param question: 用户问题
:param documents: 检索到的文档
:param stream: 是否流式输出
:return: 包含answer和references的字典
"""
# 格式化上下文
context = format_context(documents)
# 构建Prompt
prompt = RAG_PROMPT.format_messages(
context=context,
question=question
)
# 调用LLM
if stream:
return self._stream_generate(prompt, documents)
else:
return self._sync_generate(prompt, documents)
def _sync_generate(
self,
prompt: list,
documents: List[Document]
) -> Dict[str, Any]:
"""同步生成"""
response = self.llm.invoke(prompt)
return {
"answer": response.content,
"references": format_references(documents),
"documents": documents
}
def _stream_generate(
self,
prompt: list,
documents: List[Document]
) -> Generator[str, None, None]:
"""流式生成"""
for chunk in self.llm.stream(prompt):
yield chunk.content
# 最后返回引用
yield format_references(documents)
# 测试
if __name__ == "__main__":
client = LLMClient()
# 模拟文档
docs = [
Document(
page_content="年假申请需要提前3个工作日提交,由部门经理审批。",
metadata={"filename": "员工手册.pdf"}
),
Document(
page_content="年假天数:工作满1年5天,满3年10天,满5年15天。",
metadata={"filename": "考勤制度.docx"}
)
]
result = client.generate("年假怎么申请?有多少天?", docs)
print(f"回答:\n{result['answer']}")
print(f"\n{result['references']}")运行结果:
七、API封装与前端对接
7.1 FastAPI服务
python
# 👇 修复模块路径(必须放在最顶部)
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../..")))
# src/api/app.py
"""
FastAPI服务
提供:问答接口、文档上传、健康检查
"""
from fastapi import FastAPI, HTTPException, UploadFile, File
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional
import shutil
import os
from src.ingestion.pipeline import IngestionPipeline
from src.retrieval import RetrievalEngine
from src.generation.llm_client import LLMClient
# 初始化应用
app = FastAPI(title="企业智能知识库", version="1.0.0")
# CORS配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# 全局组件
pipeline = IngestionPipeline()
retrieval_engine = None
llm_client = LLMClient()
# 请求/响应模型
class QueryRequest(BaseModel):
question: str
top_k: int = 5
use_hybrid: bool = True
use_rerank: bool = True
class QueryResponse(BaseModel):
answer: str
references: str
documents: List[dict]
class DocumentInfo(BaseModel):
filename: str
size: int
# ===================== API端点 =====================
@app.get("/")
async def root():
return {"message": "企业智能知识库API", "status": "running"}
@app.post("/query")
async def query(request: QueryRequest) -> QueryResponse:
"""
问答接口
"""
try:
# 1. 检索文档
documents = retrieval_engine.search(
query=request.question,
top_k=request.top_k
)
# 2. 生成回答
result = llm_client.generate(
question=request.question,
documents=documents
)
# 3. 格式化文档信息
doc_list = [
{
"content": doc.page_content[:200],
"source": doc.metadata.get("filename", "未知"),
"score": getattr(doc, "score", 0.0)
}
for doc in documents
]
return QueryResponse(
answer=result["answer"],
references=result["references"],
documents=doc_list
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/upload")
async def upload_document(file: UploadFile = File(...)):
"""
上传文档
"""
try:
# 保存文件
file_path = f"data/raw/{file.filename}"
with open(file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
# 增量更新
pipeline.update_incremental()
return {
"message": "文档上传成功",
"filename": file.filename,
"size": os.path.getsize(file_path)
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/documents")
async def list_documents() -> List[DocumentInfo]:
"""
列出所有文档
"""
documents = []
if os.path.exists("data/raw"):
for file in os.listdir("data/raw"):
file_path = os.path.join("data/raw", file)
if os.path.isfile(file_path):
documents.append(DocumentInfo(
filename=file,
size=os.path.getsize(file_path)
))
return documents
@app.post("/reload")
async def reload_knowledge():
"""
重新加载知识库
"""
try:
pipeline.ingest(force_reload=True)
return {"message": "知识库重载成功"}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# ===================== 启动服务 =====================
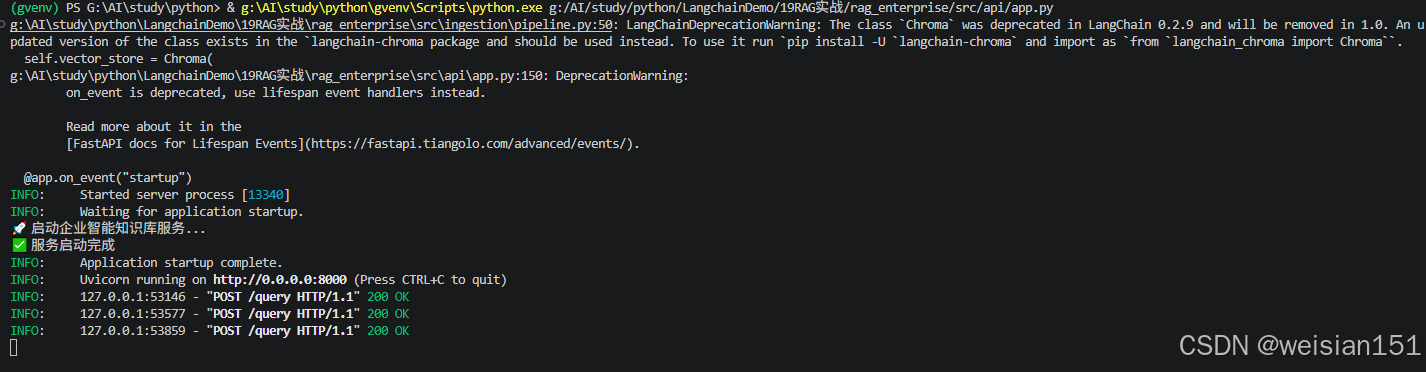
@app.on_event("startup")
async def startup_event():
"""启动时初始化组件"""
global retrieval_engine
print("🚀 启动企业智能知识库服务...")
# 加载向量库
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(
model="nomic-embed-text:v1.5-32",
base_url="http://localhost:11434"
)
vector_store = Chroma(
collection_name="enterprise_knowledge",
embedding_function=embeddings,
persist_directory="chroma_db"
)
# 初始化检索引擎
retrieval_engine = RetrievalEngine(
vector_store=vector_store,
use_hybrid=True,
use_rerank=True
)
print("✅ 服务启动完成")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)运行结果:
7.2 Streamlit前端界面

python
# frontend/app.py
"""
Streamlit前端界面
提供:聊天界面、文档管理、知识库状态
"""
import streamlit as st
import requests
import os
# 页面配置
st.set_page_config(
page_title="企业智能知识库",
page_icon="📚",
layout="wide"
)
# API地址
API_URL = "http://localhost:8000"
# ===================== 侧边栏 =====================
with st.sidebar:
st.title("📚 企业智能知识库")
st.markdown("---")
# 知识库状态
st.subheader("📊 知识库状态")
col1, col2 = st.columns(2)
with col1:
st.metric("文档数量", "12")
with col2:
st.metric("向量片段", "1,234")
st.markdown("---")
# 文档上传
st.subheader("📤 上传文档")
uploaded_file = st.file_uploader(
"支持 PDF、Word、Excel、TXT",
type=["pdf", "docx", "xlsx", "txt"]
)
if uploaded_file:
if st.button("上传并更新知识库"):
files = {"file": uploaded_file}
response = requests.post(f"{API_URL}/upload", files=files)
if response.status_code == 200:
st.success("文档上传成功!知识库已更新")
st.rerun()
else:
st.error(f"上传失败: {response.text}")
st.markdown("---")
# 操作按钮
if st.button("🔄 重新加载知识库"):
response = requests.post(f"{API_URL}/reload")
if response.status_code == 200:
st.success("知识库重载成功")
else:
st.error("重载失败")
# 检索配置
st.markdown("---")
st.subheader("⚙️ 检索配置")
top_k = st.slider("返回文档数", 1, 10, 5)
use_hybrid = st.checkbox("启用混合检索", value=True)
use_rerank = st.checkbox("启用重排序", value=True)
# ===================== 主界面 =====================
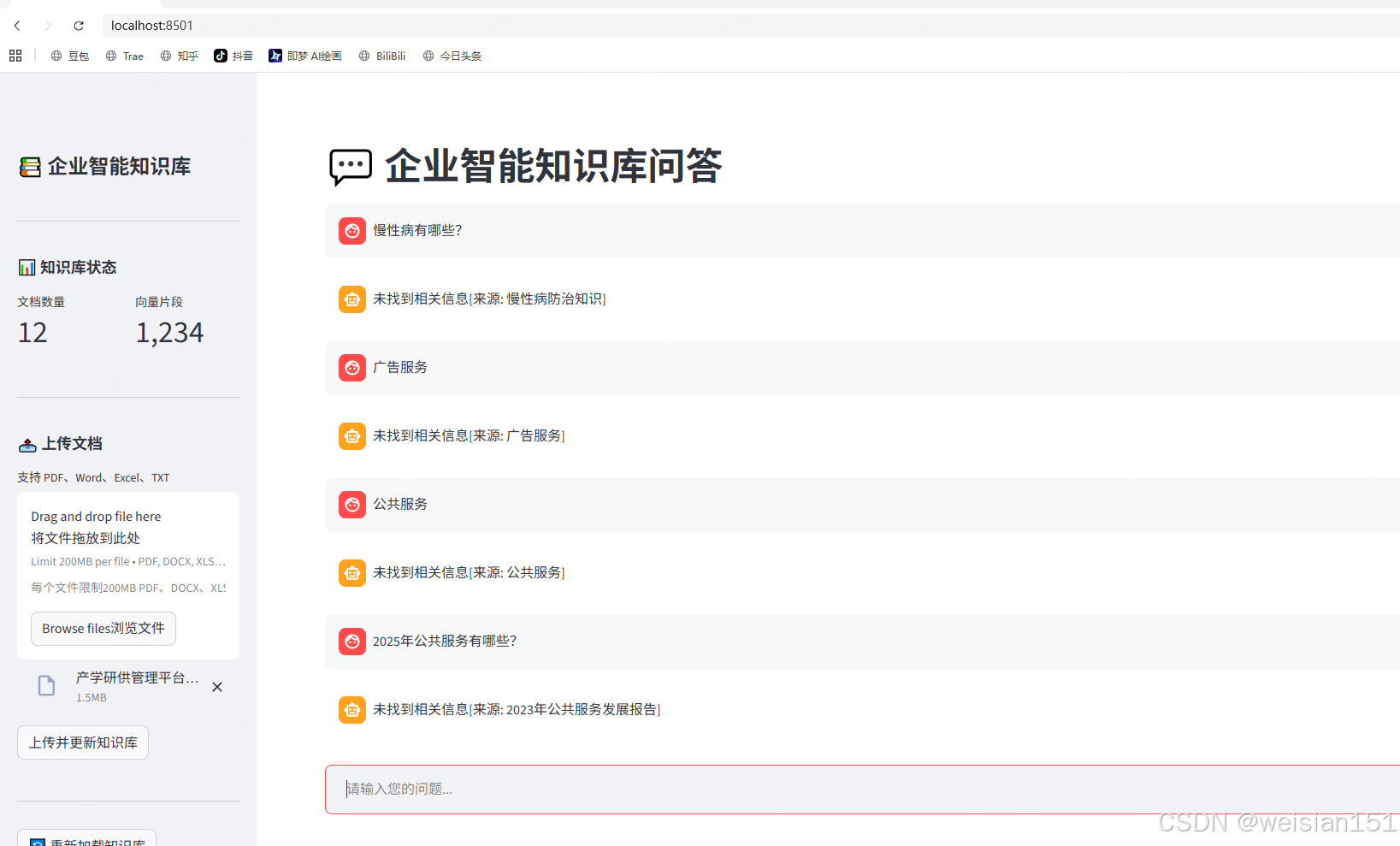
st.title("💬 企业智能知识库问答")
# 初始化对话历史
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示历史消息
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 显示引用来源
if "references" in message and message["references"]:
with st.expander("📚 引用来源"):
st.markdown(message["references"])
# 输入框
if prompt := st.chat_input("请输入您的问题..."):
# 显示用户消息
st.chat_message("user").markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
# 调用API
with st.chat_message("assistant"):
with st.spinner("思考中..."):
response = requests.post(
f"{API_URL}/query",
json={
"question": prompt,
"top_k": top_k,
"use_hybrid": use_hybrid,
"use_rerank": use_rerank
}
)
if response.status_code == 200:
data = response.json()
answer = data["answer"]
references = data["references"]
# 显示回答
st.markdown(answer)
# 显示引用
if references:
with st.expander("📚 引用来源"):
st.markdown(references)
# 保存历史
st.session_state.messages.append({
"role": "assistant",
"content": answer,
"references": references
})
else:
st.error(f"请求失败: {response.text}")运行方式:
bash
streamlit run g:/AI/study/python/LangchainDemo/19RAG实战/rag_enterprise/src/frontend/app.py注意:
需要先启动api/app.py服务。
运行结果:
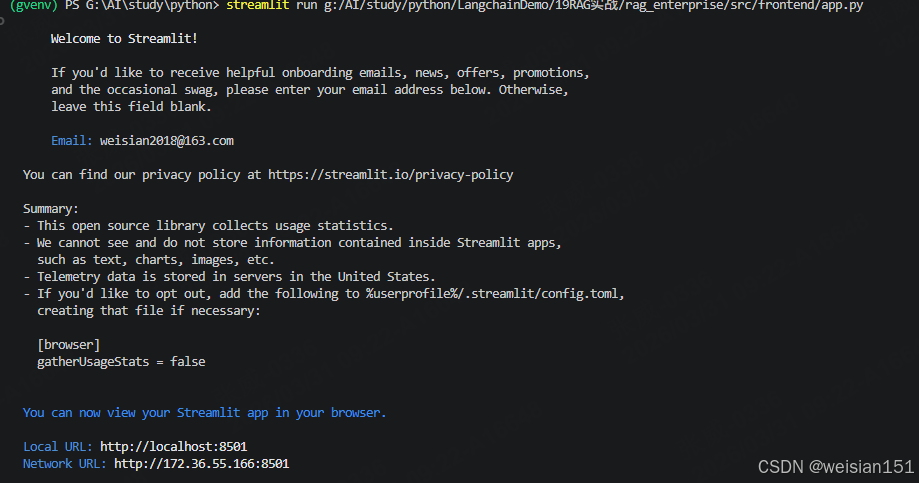
前端示例:
八、评估体系:Ragas自动化测试

python
# src/evaluation/ragas_eval.py
"""
RAG系统评估
使用Ragas框架进行自动化测试
"""
import pandas as pd
from ragas import evaluate
from ragas.metrics import (
answer_relevancy,
context_relevancy,
context_recall,
faithfulness
)
from datasets import Dataset
from typing import List, Dict
import json
class RAGEvaluator:
"""RAG系统评估器"""
def __init__(self, test_data_path: str = "data/test_questions.json"):
"""
初始化评估器
:param test_data_path: 测试数据路径
"""
self.test_data_path = test_data_path
self.test_data = self._load_test_data()
def _load_test_data(self) -> List[Dict]:
"""加载测试数据"""
with open(self.test_data_path, 'r', encoding='utf-8') as f:
return json.load(f)
def prepare_dataset(self, predictions: List[Dict]) -> Dataset:
"""
准备评估数据集
predictions格式: [
{
"question": "问题",
"answer": "生成的答案",
"contexts": ["上下文1", "上下文2"],
"ground_truth": "标准答案"
}
]
"""
df = pd.DataFrame(predictions)
return Dataset.from_pandas(df)
def evaluate(self, predictions: List[Dict]) -> Dict:
"""
执行评估
:param predictions: 预测结果
:return: 评估指标
"""
dataset = self.prepare_dataset(predictions)
# 选择评估指标
metrics = [
faithfulness, # 忠实度:答案是否基于上下文
answer_relevancy, # 答案相关性
context_relevancy, # 上下文相关性
context_recall # 上下文召回率
]
# 执行评估
result = evaluate(
dataset=dataset,
metrics=metrics
)
return {
"faithfulness": result["faithfulness"],
"answer_relevancy": result["answer_relevancy"],
"context_relevancy": result["context_relevancy"],
"context_recall": result["context_recall"]
}
def generate_report(self, results: Dict) -> str:
"""
生成评估报告
"""
report = f"""
========================================
RAG系统评估报告
========================================
评估指标:
- 忠实度 (Faithfulness): {results['faithfulness']:.2%}
- 答案相关性 (Answer Relevancy): {results['answer_relevancy']:.2%}
- 上下文相关性 (Context Relevancy): {results['context_relevancy']:.2%}
- 上下文召回率 (Context Recall): {results['context_recall']:.2%}
========================================
"""
return report
# ===================== 测试数据示例 =====================
def create_test_data():
"""创建测试数据"""
test_data = [
{
"question": "年假怎么申请?",
"ground_truth": "年假需要提前3个工作日提交申请,由部门经理审批。",
"contexts": [
"年假申请流程:登录OA系统→填写年假申请单→提交部门经理审批→HR备案",
"年假需提前3个工作日申请"
]
},
{
"question": "年假有多少天?",
"ground_truth": "工作满1年5天,满3年10天,满5年15天。",
"contexts": [
"年假天数根据工作年限计算:1-3年5天,3-5年10天,5年以上15天"
]
}
]
with open("data/test_questions.json", "w", encoding="utf-8") as f:
json.dump(test_data, f, ensure_ascii=False, indent=2)
# 测试
if __name__ == "__main__":
# 创建测试数据
create_test_data()
# 模拟预测结果
predictions = [
{
"question": "年假怎么申请?",
"answer": "年假需要提前3个工作日提交申请,由部门经理审批。",
"contexts": [
"年假申请流程:登录OA系统→填写年假申请单→提交部门经理审批→HR备案",
"年假需提前3个工作日申请"
],
"ground_truth": "年假需要提前3个工作日提交申请,由部门经理审批。"
}
]
evaluator = RAGEvaluator()
results = evaluator.evaluate(predictions)
report = evaluator.generate_report(results)
print(report)九、部署与运维
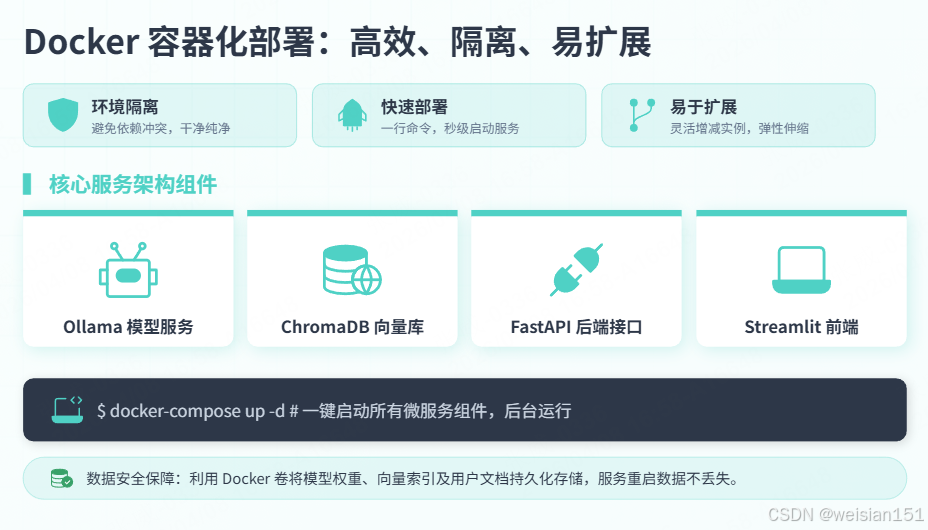
9.1 Docker部署
dockerfile
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y \
gcc \
g++ \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制代码
COPY . .
# 创建数据目录
RUN mkdir -p data/raw chroma_db
# 暴露端口
EXPOSE 8000 8501
# 启动脚本
COPY scripts/start.sh .
RUN chmod +x start.sh
CMD ["./start.sh"]
dockerfile
# docker-compose.yml
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
restart: unless-stopped
chromadb:
image: chromadb/chroma:latest
ports:
- "8001:8000"
volumes:
- chroma_data:/chroma/chroma
environment:
- IS_PERSISTENT=TRUE
restart: unless-stopped
api:
build: .
ports:
- "8000:8000"
depends_on:
- ollama
- chromadb
volumes:
- ./data:/app/data
- ./chroma_db:/app/chroma_db
environment:
- OLLAMA_HOST=http://ollama:11434
restart: unless-stopped
frontend:
build: .
command: streamlit run frontend/app.py --server.port 8501 --server.address 0.0.0.0
ports:
- "8501:8501"
depends_on:
- api
restart: unless-stopped
volumes:
ollama_data:
chroma_data:
bash
# scripts/start.sh
#!/bin/bash
# 等待Ollama启动
echo "等待Ollama服务..."
until curl -s http://ollama:11434/api/tags > /dev/null; do
sleep 1
done
# 下载模型(如果不存在)
echo "检查模型..."
ollama pull qwen2.5:7b
ollama pull nomic-embed-text
# 初始化知识库
echo "初始化知识库..."
python scripts/init_db.py
# 启动API服务
echo "启动API服务..."
uvicorn src.api.app:app --host 0.0.0.0 --port 80009.2 性能调优配置
python
# config.py
"""
系统配置
支持:缓存、并发、批处理
"""
import os
from functools import lru_cache
from typing import Optional
class Config:
"""系统配置"""
# 模型配置
LLM_MODEL = os.getenv("LLM_MODEL", "qwen2_5-7b-q6")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "nomic-embed-text")
RERANK_MODEL = os.getenv("RERANK_MODEL", "BAAI/bge-reranker-base")
# 检索配置
DEFAULT_TOP_K = 5
RETRIEVE_K = 20 # 初步检索数量
BM25_WEIGHT = 0.3
VECTOR_WEIGHT = 0.7
# 分块配置
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
# 缓存配置
CACHE_SIZE = 100 # LRU缓存大小
CACHE_TTL = 3600 # 缓存过期时间(秒)
# 并发配置
MAX_WORKERS = 4
BATCH_SIZE = 32
# 向量库配置
CHROMA_PERSIST_DIR = "chroma_db"
CHROMA_COLLECTION = "enterprise_knowledge"
# API配置
API_HOST = "0.0.0.0"
API_PORT = 8000
API_WORKERS = 4
@classmethod
@lru_cache(maxsize=1)
def get_config(cls) -> "Config":
"""获取配置单例"""
return cls()十、避坑指南
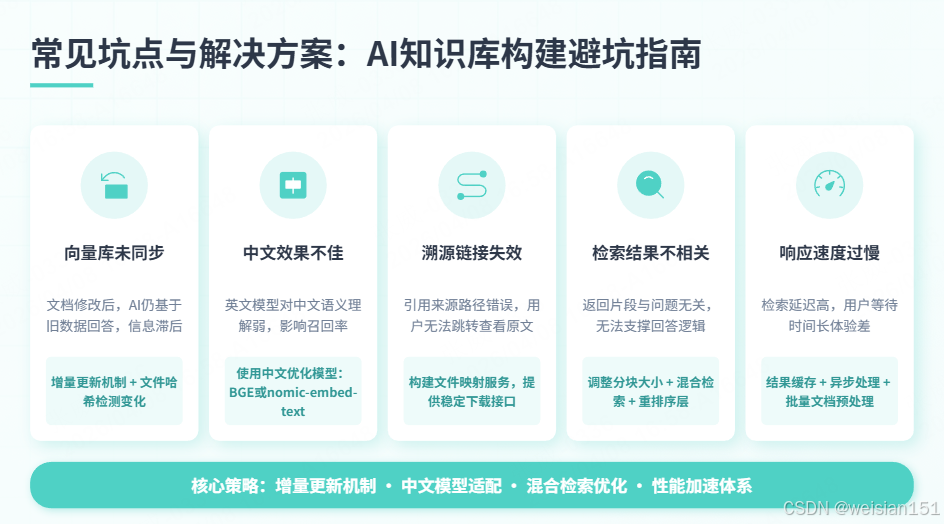
坑点1:文档更新后向量库未同步
问题:文档修改后,AI还基于旧数据回答
解决方案:实现增量更新机制
python
# 每次上传时计算文件哈希,检测变化
def should_update(file_path: str) -> bool:
current_hash = compute_hash(file_path)
stored_hash = get_stored_hash(file_path)
return current_hash != stored_hash坑点2:中文Embedding效果不佳
问题:英文Embedding模型对中文支持差
解决方案:使用中文优化模型
python
# 推荐的中文Embedding模型
# - nomic-embed-text (Ollama自带,支持中文)
# - BAAI/bge-large-zh (专用中文模型)
# - text-embedding-3-large (OpenAI)坑点3:溯源链接失效
问题:引用来源路径错误,用户无法查看原文
解决方案:构建文件映射服务
python
# 提供文件下载接口
@app.get("/download/{file_id}")
async def download_file(file_id: str):
file_path = get_file_path(file_id)
return FileResponse(file_path, filename=os.path.basename(file_path))坑点4:检索结果相关性低
问题:返回的文档片段与问题不相关
解决方案:
- 调整分块大小(500-1000字符)
- 启用混合检索(BM25 + 向量)
- 添加重排序层(Rerank)
坑点5:响应速度慢
问题:用户等待时间长
解决方案:
- 实现结果缓存
- 使用异步处理
- 批量处理文档
十一、总结
核心知识点速记
RAG系统四步走,加载分割存检索
多格式文档都能读,PDF Word加Excel
混合检索双保险,BM25加向量查
重排序再精挑,BGE模型来把关
Prompt模板要设计,引用来源不能忘
API服务FastAPI,前端界面Streamlit
评估用Ragas,指标全自动
Docker一键部署,运维轻松又省心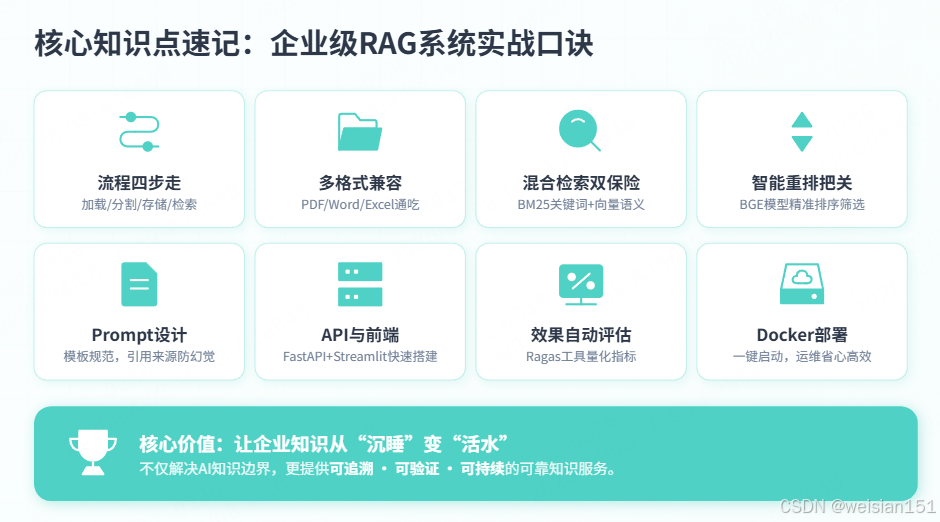
核心价值
企业级RAG系统让LLM从"胡说八道"变成"有据可查",让企业知识从"沉睡"变成"活水"。它不仅解决了AI的知识边界问题,更重要的是提供了可追溯、可验证、可持续的知识服务能力。
下一步优化方向
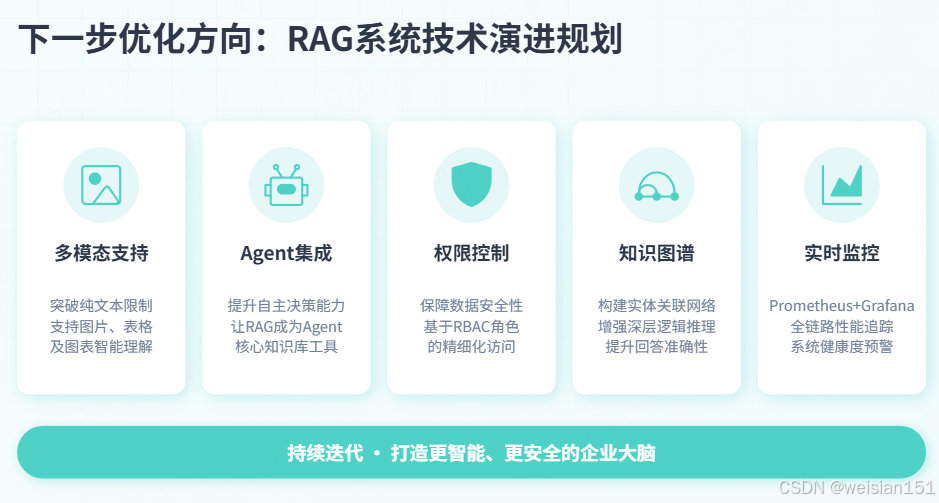
- 多模态支持:图片、表格、图表理解
- Agent集成:让RAG成为Agent的工具
- 权限控制:基于角色的文档访问
- 知识图谱:增强实体关系理解
- 实时监控:Prometheus + Grafana监控
写在最后
构建一个企业级RAG系统,就像建造一座图书馆。你需要考虑如何收纳书籍(数据摄入)、如何快速查找(检索引擎)、如何呈现给读者(生成链路)、如何保证书籍最新(增量更新)。
当你真正掌握这套体系,你的AI就不再是一个只会聊天的花瓶,而是能真正理解、运用、传承企业知识的智能大脑。这正是AI从"玩具"走向"工具"的关键一步。