目录
[理解 Karpathy 方法论的核心](#理解 Karpathy 方法论的核心)
[1.1 传统 RAG 的硬伤](#1.1 传统 RAG 的硬伤)
[1.2 Karpathy 解法:增量构建持久 Wiki](#1.2 Karpathy 解法:增量构建持久 Wiki)
[给 Obsidian 装上 AI 大脑](#给 Obsidian 装上 AI 大脑)
[2.1 安装 Obsidian](#2.1 安装 Obsidian)
[2.2 安装 Claude Code(命令行环境)](#2.2 安装 Claude Code(命令行环境))
[2.3 让 Claude Code 以图形界面嵌入 Obsidian------安装 Claudian 插件](#2.3 让 Claude Code 以图形界面嵌入 Obsidian——安装 Claudian 插件)
[步骤 1:安装 BRAT 插件(Beta 插件加载器)](#步骤 1:安装 BRAT 插件(Beta 插件加载器))
[步骤 2:通过 BRAT 安装 Claudian](#步骤 2:通过 BRAT 安装 Claudian)
[步骤 3:验证安装](#步骤 3:验证安装)
[2.4 【可选但推荐】安装模型切换工具 cc-switch](#2.4 【可选但推荐】安装模型切换工具 cc-switch)
[2.5 安装 Obsidian 官方的 5 个必备 Skill(技能包)](#2.5 安装 Obsidian 官方的 5 个必备 Skill(技能包))
[编写 CLAUDE.md 配置文件](#编写 CLAUDE.md 配置文件)
别再让你的笔记吃灰了。跟着这篇保姆级教程,用大模型把散乱的收藏夹变成能自我生长的"第二大脑"。
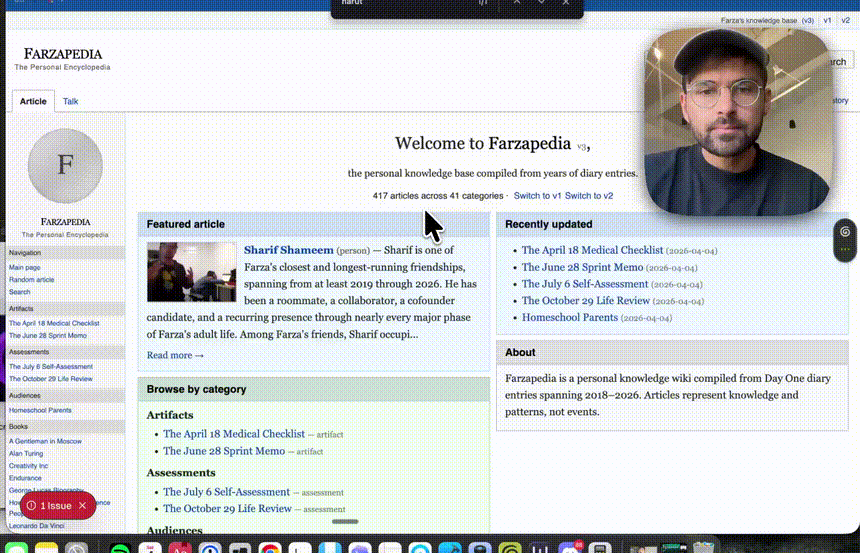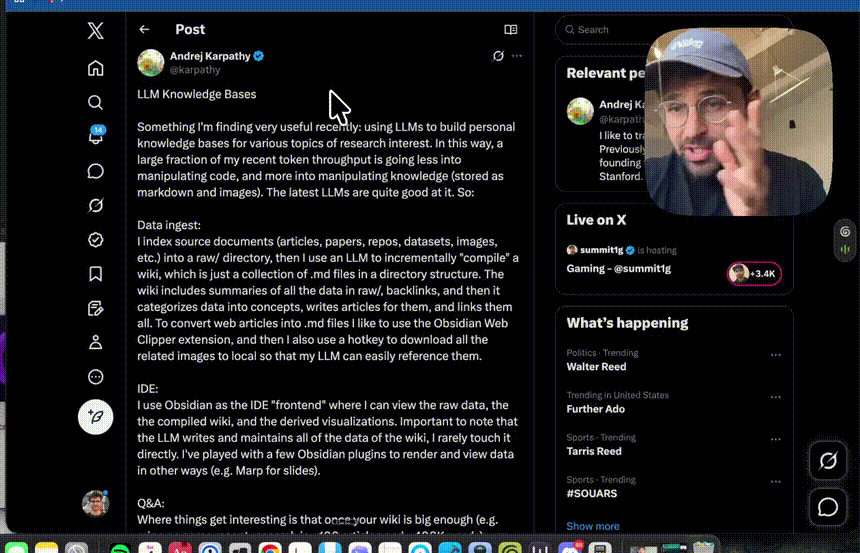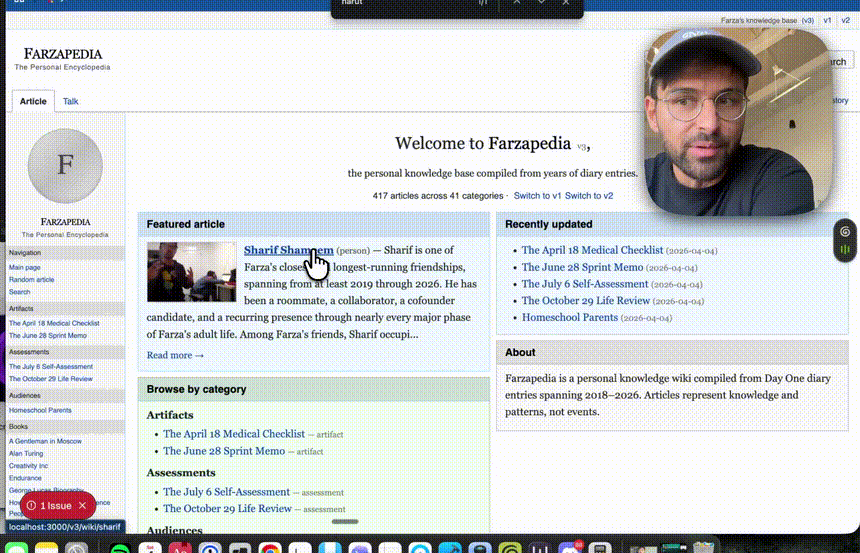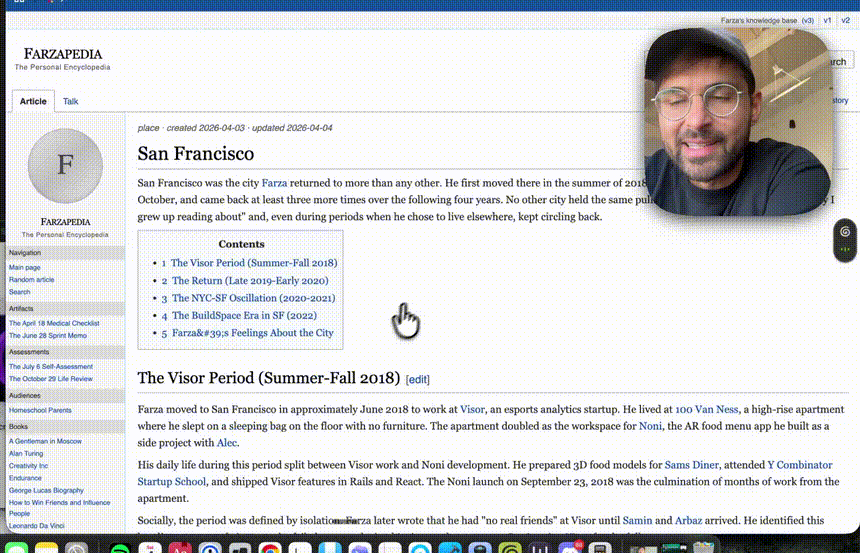
两周前,AI 领域传奇人物 Andrej Karpathy 发了一条推特,分享他最近发现的一个"非常有用"的事情:用 LLM 构建个人知识库。
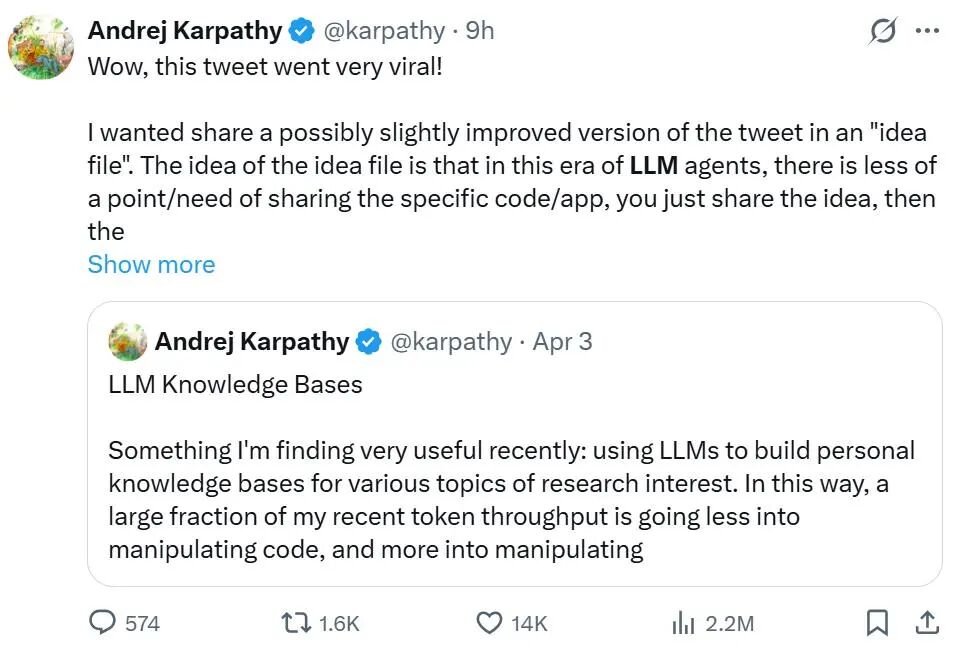
他说,过去大部分 token 消耗在写代码上,现在则更多地花在处理内容上------让 AI 把各种资料整合、整理、关联,变成一个持续生长的私人维基百科。
这条推文在两天内收获了上千万浏览和 4 万多收藏。但收藏不等于拥有,今天我就用一篇超级详细的保姆级教程,带你真正动手,在 Obsidian 里复刻 Karpathy 大神同款 AI 知识库。
理解 Karpathy 方法论的核心
1.1 传统 RAG 的硬伤
绝大多数人用 AI 处理文档的方式是 RAG(检索增强生成):
-
上传一堆 PDF / Word 到 ChatGPT / NotebookLM。
-
提问时,AI 从文档里检索相关段落。
-
AI 现场拼凑答案。
问题在于: AI 每次回答问题都要重新检索、重新理解,没有积累。你今天问的和昨天问的毫无关联,AI 不会因为读过你的文档而变得更懂你。这就像一个每次考试都临时抱佛脚的学生,永远没有形成知识体系。
1.2 Karpathy 解法:增量构建持久 Wiki
Karpathy 的思路是:让 AI 成为你的全职图书管理员,而不是临时工。
1.原始资料层(raw/):你负责收集文章、笔记、截图,丢进这个文件夹。AI 只读,绝不修改。
2.知识库层(wiki/):AI 读完原始资料后,把内容拆解、重组成结构化的 Markdown 文件。它会:
· 给每篇文章写摘要。
· 提取文中提到的实体(人、公司、产品)和概念,创建独立页面。
· 用 \[双链] 把这些页面全部连接起来。
· 发现不同文章对同一件事的矛盾说法,并标记出来。
3.Schema 文件(CLAUDE.md):一份写满规则的文件,告诉 AI 怎么整理、什么该建页面、什么不该建。这是 AI 的"工作手册"。
核心价值: 知识只编译一次,之后永久复用。随着你扔
"秀米,打动你的人群",再小的个体,也有自己希望打动的人群。希望用秀米,你能做出或简洁、或惊艳、或浓墨重彩或意蕴绵长的各种效果,打动你的人群。
进 raw/ 的文章越多,wiki/ 里的链接网越密,AI 对你的领域理解越深。你每次提问,AI 都是在一个已经整理好的、结构化的知识图谱上工作,回答质量自然天差地别。
开源地址:https:/github.com/karpathy/llm-wiki
给 Obsidian 装上 AI 大脑
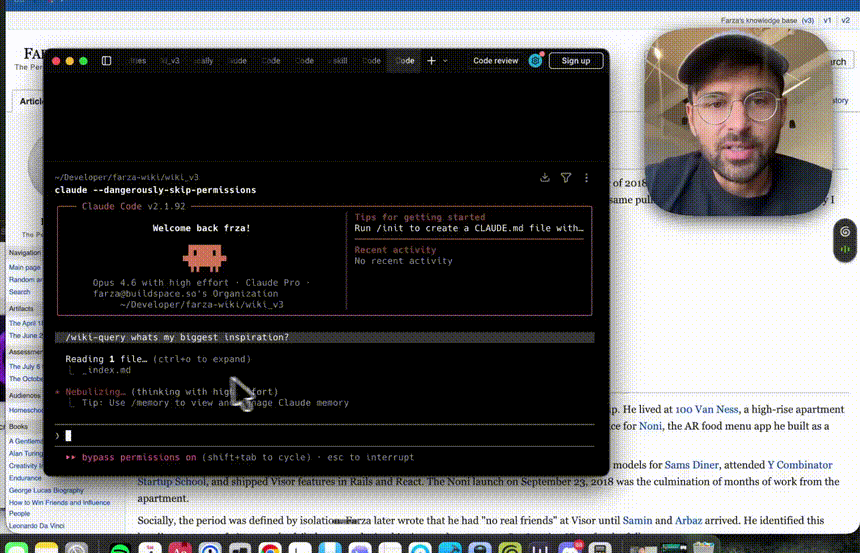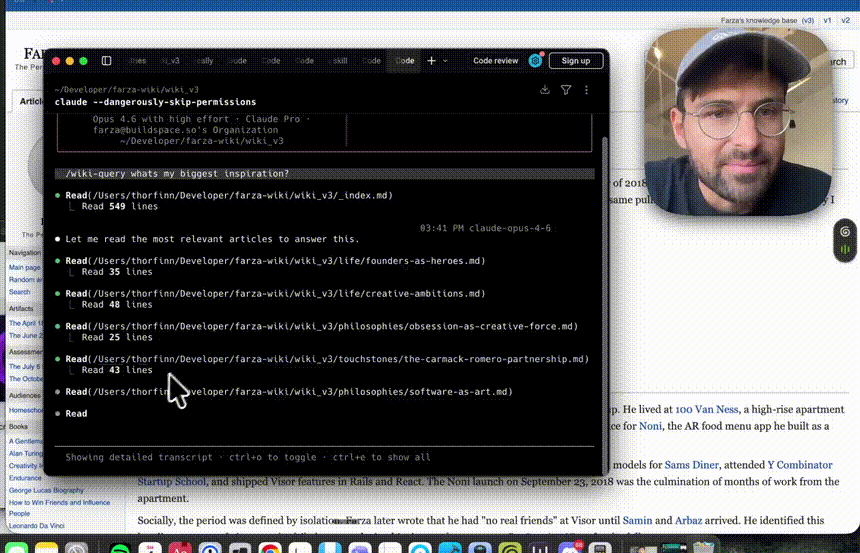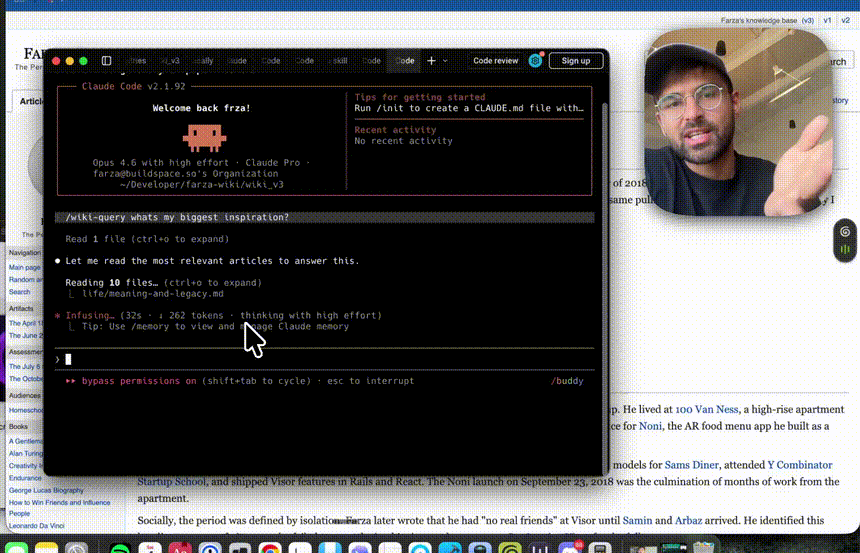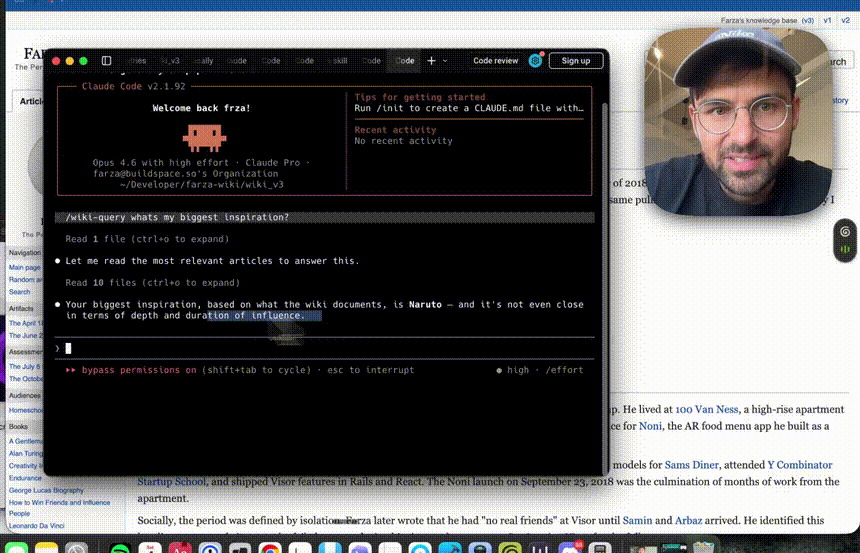
我们要用到的核心工具是 Obsidian 和 Claude Code(或任何能读写文件的 AI Agent,如 Cursor、Codex)。
Obsidian:免费、本地优先、基于 Markdown 的笔记软件,用来浏览和查看知识库。
Claude Code:Anthropic 官方的命令行 AI 编程工具,我们将通过插件把它嵌入 Obsidian 的图形界面。
2.1 安装 Obsidian
-
访问 Obsidian 官网 obsidian.md 下载对应系统的安装包。
-
双击安装,一路下一步即可。
-
打开 Obsidian,点击"创建新仓库",选择一个文件夹(比如 My-Knowledge-Base),点击"创建"。
现在你有了一个空的知识库容器。
2.2 安装 Claude Code(命令行环境)
Claude Code 需要 Node.js 环境,不同系统安装方式略有不同。
macOS / Linux 用户:
bash
# 1. 确保已安装 Node.js 18+ 和 npm
node -v
npm -v
# 2. 全局安装 Claude Code
npm install -g @anthropic-ai/claude-code
# 3. 验证安装
claude --versionWindows 用户:
-
前往 Node.js 官网 下载 LTS 版本安装。
-
打开 PowerShell 或 CMD,执行 npm install -g @anthropic-ai/claude-code。
-
安装完成后,输入 claude 测试。
首次运行需要认证: 在终端输入 claude,根据提示登录 Anthropic 账号并授权。如果你有 API Key,也可以设置环境变量 ANTHROPIC_API_KEY。
2.3 让 Claude Code 以图形界面嵌入 Obsidian------安装 Claudian 插件
默认 Claude Code 是命令行工具,我们需要一个桥梁插件 Claudian,它在 Obsidian 右侧生成一个聊天面板,背后实际调用的就是本地的 Claude Code。
步骤 1:安装 BRAT 插件(Beta 插件加载器)
· 打开 Obsidian,点击左下角齿轮图标进入"设置"。
· 左侧菜单选择"第三方插件"。
· 点击"社区插件市场"旁边的"浏览"。
· 在搜索框输入 BRAT,找到后点击"安装",然后"启用"。
步骤 2:通过 BRAT 安装 Claudian
· 再次进入 Obsidian 设置 → "BRAT" 选项(左侧列表底部)。
· 点击"Add Beta plugin"按钮。
· 在弹出的输入框中粘贴 GitHub 仓库地址:
https://github.com/YishenTu/claudian
· 点击"Add Plugin"。
· 安装完成后,回到"第三方插件"列表,找到 Claudian 并启用它。
步骤 3:验证安装
· 启用后,Obsidian 右上角会出现一个🤖 小机器人图标。
· 点击图标,右侧边栏会滑出对话界面。此时你应该能看到 Claude Code 的欢迎语。
2.4 【可选但推荐】安装模型切换工具 cc-switch
如果你使用的是 Claude 官方订阅,跳过这步。但如果你用的是国产大模型 API(如 DeepSeek、智谱、通义千问)或第三方代理,cc-switch 可以帮你无缝切换模型,省钱又好用。
bash
# 安装 cc-switch
npm install -g cc-switch
# 设置要使用的 API 地址和密钥(以 DeepSeek 为例)
cc-switch config --provider deepseek --api-key sk-xxxxxx之后在 Obsidian 中使用 Claudian 时,实际调用的就是国内模型了,速度更快且无封号风险。
下载地址:https://github.com/farion1231/cc-switch(需要魔法)
2.5 安装 Obsidian 官方的 5 个必备 Skill(技能包)
Obsidian CEO Kepano 亲自编写了 5 个 skill,教会 Claude Code 如何操作 Obsidian 的特定功能(比如管理标签、创建画板、使用 Dataview 查询等)。安装方式非常简单:
在 Claudian 对话框中直接输入以下内容:
"请帮我安装以下技能包,仓库地址是:https://github.com/kepano/obsidian-skills"
AI 会自动读取该仓库的说明,并将 skill 文件添加到你的本地配置中。完成后,Claude 就学会了 Obsidian 的"方言"。
编写 CLAUDE.md 配置文件
这是整个系统中最关键的一步。没有 Schema 文件,AI 会随意发挥,把你的笔记弄得一团糟。有了它,AI 才是一个听话的图书管理员。
在你知识库的根目录下新建一个文件,命名为 CLAUDE.md(如果是给 Codex 用就叫 AGENTS.md)。把下面的内容完整复制进去,并根据自己的需求稍作修改。
提示:以下配置是我根据 Karpathy 方法论优化后的版本,增加了"创建时机规则",防止 AI 过度创建页面。你可以直接使用。
bash
markdown
# Wiki Schema --- 我的知识库
> 这是 Claude 的行为配置文件。每次会话开始时,Claude 应先阅读此文件,再阅读 `wiki/index.md`,再开始工作。
## 仓库结构
My-Knowledge-Base/
├── CLAUDE.md ← 本文件:Schema 配置(Claude 的"说明书")
├── raw/ ← 原始资料层(只读,不可修改)
│ ├── articles/ ← 存放网页剪藏、PDF 导出的 Markdown
│ ├── images/ ← 文章内嵌图片的本地存储
│ └── README.md
├── wiki/ ← 知识库层(Claude 全权维护)
│ ├── index.md ← 内容索引(每次 ingest 后更新)
│ ├── log.md ← 操作日志(仅追加)
│ ├── 实体/ ← 实体页:人、公司、产品、工具等
│ ├── 概念/ ← 概念页:原理、方法论、技术术语
│ ├── 来源/ ← 来源摘要页:每篇原始资料的提炼
│ └── 对比/ ← 对比分析页:跨来源横向综合
└── 方法论参考/ ← Karpathy 原始思路文档
### 层级规则
| 层级 | 目录 | 谁可以修改 |
|------|------|-----------|
| 原始资料 | `raw/` | **只有用户**,Claude 只读 |
| 知识库 | `wiki/` | **只有 Claude**,用户可读 |
| Schema | `CLAUDE.md` | 用户和 Claude 共同演进 |
## Wiki 页面约定
### Frontmatter(YAML)
所有 wiki 页面都应有以下 frontmatter:
yaml
type: entity | concept | source | comparison
tags: [tag1, tag2]
sources: [来源文件名或 URL]
created: YYYY-MM-DD
updated: YYYY-MM-DD页面类型说明
|------------|----------|------------------|-------------|
| 类型 | 目录 | 命名格式 | 说明 |
| entity | wiki/实体/ | 实体名.md | 具体的人、组织、产品 |
| concept | wiki/概念/ | 概念名.md | 核心原理、方法论、术语 |
| source | wiki/来源/ | YYYY-MM-DD 标题.md | 原始资料的摘要和要点 |
| comparison | wiki/对比/ | 对比主题.md | 跨来源横向对比分析 |
写在最后:动手,而不是收藏
Karpathy 的推文被收藏了 4.4 万次,但真正动手搭建的人可能不到 1%。
这套系统的美妙之处在于它的反脆弱性:
· 你收集的每一篇文章都会强化它。
· 你提出的每一个好问题都会沉淀成新的页面。
· 你运行的每一次 lint 都会让它更精确。
它不会让你变成一个更勤奋的笔记整理者,而是让你变成一个更聪明的提问者。
今晚就花 30 分钟,完成前三步:安装 Obsidian → 配置 Claudian → 复制 CLAUDE.md → 让 AI 生成文件夹结构。然后,用 Web Clipper 剪藏你收藏夹里吃灰最久的那篇文章,告诉 AI:
"请摄取这篇文章。"
剩下的,交给你的 AI 图书管理员。