监控慢 SQL 的核心手段是开启 MySQL 的慢查询日志,它会把执行时间超过阈值的 SQL 自动记录下来。拿到慢 SQL 后,用 EXPLAIN 分析执行计划,找出问题所在,再针对性优化。
整个流程分三步:
1)开启慢查询日志,设置合理的时间阈值,线上一般设 1-2 秒
2)定期分析慢查询日志,用 mysqldumpslow 或 pt-query-digest 工具汇总统计
3)对高频慢 SQL 用 EXPLAIN 分析,检查是否走了索引、扫描了多少行、有没有文件排序等,再针对性优化
sql
-- 查看慢查询日志是否开启 ON开启
SHOW VARIABLES LIKE 'slow_query_log';
-- 查看慢查询阈值 一般1-2秒
SHOW VARIABLES LIKE 'long_query_time';
-- 查看慢查询日志路径
SHOW VARIABLES LIKE 'slow_query_log_file';也可以在线动态开启,不用重启 MySQL:
sql
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/var/log/mysql/mysql-slow.log';
SET GLOBAL long_query_time = 2.0;
SET GLOBAL log_queries_not_using_indexes = 'ON';注:生产环境不建议长期开启 ,因为会带来约 3--5% 的性能开销,并可能快速产生大量日志,占用磁盘空间,需要时临时启动
▼
索引不一定有效。建了索引不代表查询就会用,用了索引也不代表查询就快。
MySQL 最终是否走索引,靠的是优化器的成本计算。优化器会评估走索引和全表扫描各自的 I/O 成本和 CPU 成本,哪个便宜选哪个。有时候全表扫描确实成本低,比如表就几百行数据,走索引还不如直接扫;有时候是统计信息不准,导致优化器算错账,明明该走索引却选了全表扫描。
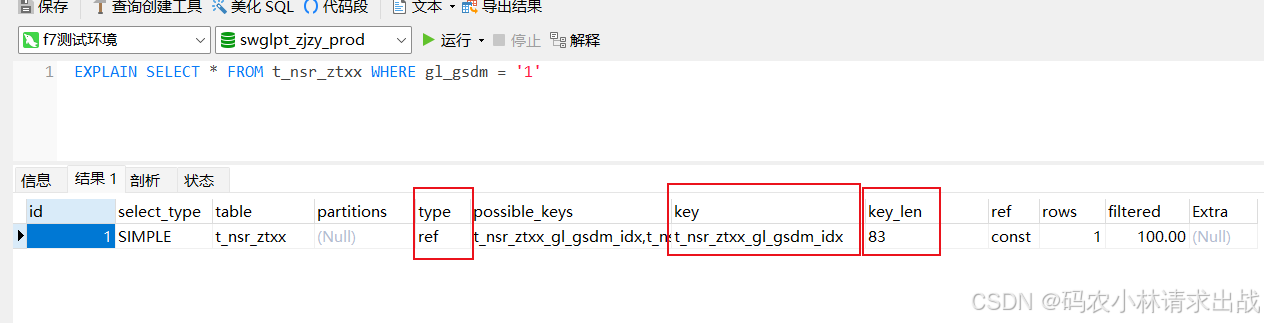
排查索引效果最直接的办法就是用 EXPLAIN 命令。在 SQL 前面加上 EXPLAIN,就能看到 MySQL 选择的执行计划。重点看这几个字段:
1)type:访问类型,ALL 是全表扫描,range 是范围扫描,ref 是等值匹配,index 是全索引扫描。ALL 基本就是没走索引,ref 和 range 才是真正利用了索引的快速查找能力。
ref > rang > index > all(没走索引)
2)key:实际用的索引名称,NULL 就是没用上索引。
3)rows:预估扫描的行数,这个数字越大说明查询代价越高
从索引性质看,有这几种:
1)主键索引:唯一且非空,每张表只能有一个。InnoDB 里主键索引就是聚簇索引。
2)唯一索引:保证列值不重复,但允许有 NULL,可以有多个 NULL。
3)普通索引:没有唯一约束,纯粹为了加速查询。
4)联合索引:多列组合成一个索引,遵循最左前缀原则,列顺序很重要。
5)全文索引:文本搜索用。
6)空间索引:GIS 数据用。