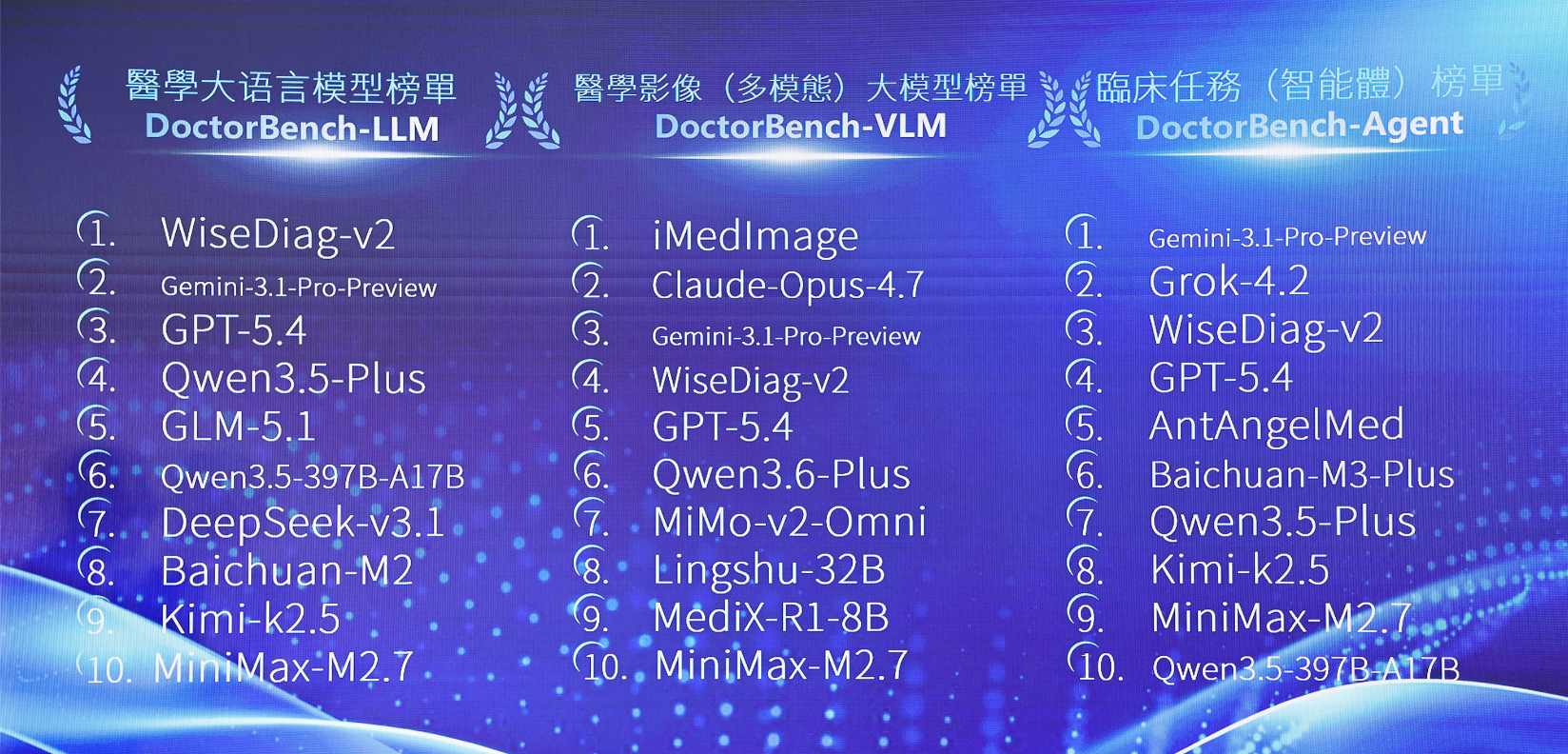
4月30日,杭州德适生物科技股份有限公司(2526.HK,简称 "德适")在中国香港正式发布医疗AI评测平台DoctorBench,并揭晓首期全球医疗大模型排行榜。杭州智诊科技的WiseDiag-v2、谷歌的Gemini-3.1-Pro-Preview、OpenAI的GPT-5.4 位列前三甲。
该平台首次以 "临床实战能力" 为核心标尺,为全球医疗大模型构建起一套贴近真实诊疗场景的多维评测体系。
专业人士指出,当前,全球医疗大模型正加速从实验室走向临床应用,但行业始终缺乏一套能够真正衡量模型"看病能力" 的评测标准。现有的评测大多聚焦于医学知识问答,难以反映模型在复杂临床情境中的综合表现------这种评测与临床实践之间的鸿沟,正在成为制约医疗AI落地应用的全球性挑战。
此前,OpenAI发布HealthBench,标志着领先企业开始重视这一挑战。然而,医疗具有强烈的本土化特征------不同国家和地区的诊疗指南、语言习惯、患者群体存在显著差异,任何单一评测体系都难以实现全球普适。
正是基于对这一全球性挑战的深刻认识,德适发起并打造了DoctorBench 平台。这一平台的诞生,植根于一个跨学科团队近十年的深耕与协作。德适汇聚了基础医学、临床医学、人工智能、医疗产业等多领域的专家,将严谨的临床医学逻辑与前沿的深度学习算法深度融合,让DoctorBench既能理解AI技术的边界,又能洞察临床实践的复杂需求,并以此为标准构建评测体系。
DoctorBench的核心理念是不再只考核大模型的 "知识储备",而是考核其 "像医生一样思考" 的临床沟通与决策能力。平台构建了三大榜单体系 ------ 医学主榜单(LLM)、多模态榜单(VLM)与智能体榜单(Agent),分别评测模型的文本诊疗能力、多模态理解能力,以及模拟诊疗环境中的多轮决策与工具调用能力。

在评测机制上,DoctorBench首创"2大核心维度(安全性和准确性)+3 项通用维度(交互质量、信息优先级、主动询问)+5 项专项模块(证据与引用、可解释推理、可执行性、个体化适配、情感支持)" 的多维架构,并搭载 "场景自适应权重"------根据不同临床场景的风险等级,动态调整各维度权重,使评分逻辑更贴近真实诊疗决策。
尤为关键的是,平台将 "医学事实准确" 与 "安全与风险控制" 设为具有 "一票否决权" 的核心红线 ------ 任何模型若在关乎患者安全的关键问题上出现严重偏差,无论其他维度表现如何突出,均无法获得高分。这一设计源于团队对医疗本质的深刻理解:在关乎生命的领域,安全性永远是第一要义,没有妥协余地。

"医疗AI的发展是一场关乎人类共同健康福祉的长跑,既需要颠覆式的技术创新和跨学科、跨地域的深度协作,更需要对生命健康的绝对敬畏与坚守。" 德适创始人宋宁博士表示,期待与全球更多科研机构、临床中心和行业伙伴携手,让真正有实力的技术被看见、被信赖,最终惠及每一位患者。