摘要
实现机器人操纵能力的规模化发展,既需要建立环境随动作演化的预测模型,也离不开对物理接触过程的精细化感知。本次讲座将介绍两条互为补充的研究方向,以攻克上述核心难题。
首先,受人类直觉物理认知启发,本文提出结构化世界模型:依托基于粒子与图结构的神经动力学融入物理先验知识,同时借助动作条件视频预测技术,直接从数据中学习视觉动态预测规律。该类模型可对刚体、可形变物体、铰接式物体及颗粒状物体等多类对象实现基于模型的规划与控制,支持长时序、高接触复杂度的操纵任务;同时也为构建融合神经网络与物理规律的数字孪生体提供支撑,可服务于规模化数据生成、策略迭代与算法评估。
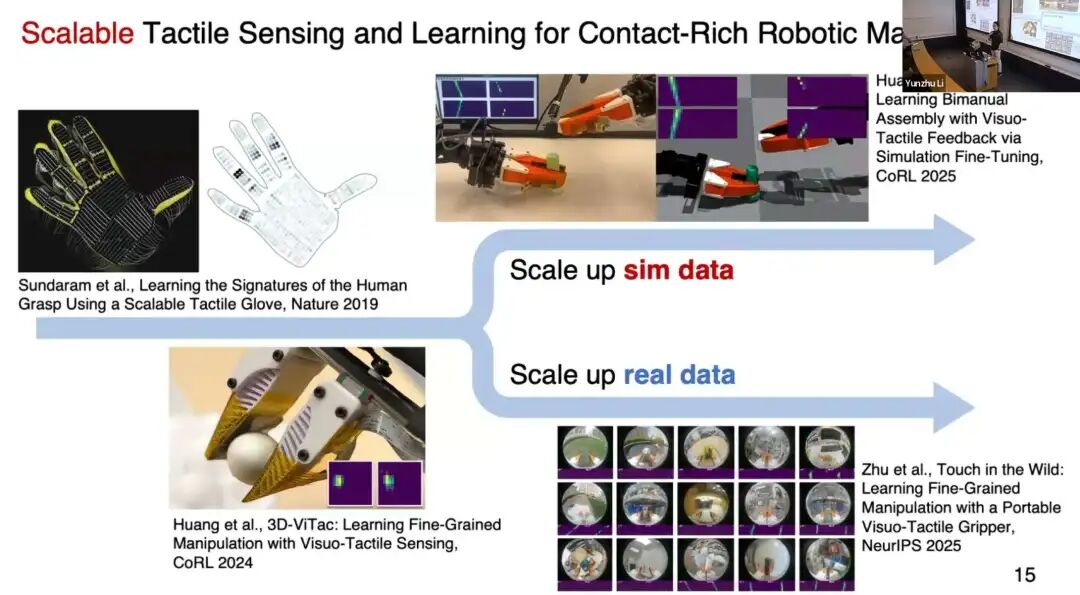
其次,将介绍团队在可规模化触觉感知领域的研究成果:从借助高密度触觉手套解析人类抓取机理,到研发柔性低成本触觉阵列、便携式视觉 - 触觉一体化夹爪。结合仿真平台与大规模真实场景数据采集,这套触觉感知系统能够在视觉遮挡、易碎物体操作、复杂物理交互等任务中实现鲁棒模型学习,并显著提升仿真到现实场景的迁移效果。
上述研究共同明确了机器人操纵向通用性、鲁棒性与物理交互能力进阶的核心要素,为构建具备物理根基的机器人基础模型奠定了研究基础。
1 开场介绍
Yunzhu Li是哥伦比亚大学计算机科学系的助理教授。

今天,我将和大家分享我们实验室长期以来的研究探索,主要围绕如何从两个核心维度实现机器人操作的规模化拓展 :第一个维度是结构化世界模型(structured world models) ,第二个维度是结构化触觉感知(structured tactile sensing),以此让机器人更细致地理解自身与环境的交互过程。

2 机器人领域现状与基础模型发展

近年来,机器人领域取得了巨大进展:人形机器人可以完成行走、舞蹈等动作,自动驾驶汽车的部署范围也越来越广。但机器人与环境之间复杂的物理交互能力发展如何?我们距离实现人类水平的操作能力还有多远?

如果你身处学术界,或许见过不少精彩的机器人演示。但只要走进任何一场工业展会,就会惊讶地发现,现场的机器人大多只能处理形状规整的箱体。这就是当前机器人系统在工业落地中的真实状态------机器人大多只能完成相对简单的物体操作与简单运动。

但我们对机器人的期望远不止于此。我们希望机器人不仅能在全结构化环境 中工作,还能适应半结构化 与非结构化环境 ;不仅能操作刚性物体,还能处理流体、布料、绳索、线缆等可变形物体;不仅能完成受限环境下的短周期任务,还能执行大场景下的长周期任务。这要求机器人具备远超当前水平的泛化能力与适应能力。
于是研究者开始思考:能否将LLM 与VLM 的成功经验迁移到机器人领域?这也是为什么大量研究热情与资本涌入机器人基础模型的研发中。

这些研究大致可分为两类:
-
利用现有的视觉、语言基础模型,将其与机器人系统结合,提升机器人性能。典型案例包括GPT、SAM、DINO等模型,将它们集成到机器人的感知与推理系统中十分有效。我们早期的工作FreedomBox Poser,就让机器人能接收自然语言指令,完成桌面级开放集物体的操作任务。
-
采用端到端的方式学习机器人基础模型,而非模块化思路。
当前机器人基础模型主要有两条技术路线:
-
第一条:基于视觉、语言基础模型与VLM 的成功,衍生出VLA模型 、large behavior models等,过去几年已有不少落地成果。
-
第二条:不基于视觉-语言任务预训练,而是在视频预测 或世界模型预测任务上预训练。Ani曾在Twitter上发布过一系列优质博客,我十分认可这些内容,它们详细解读了世界模型的内涵,及其在通用机器人智能体系中的定位。

3 现有机器人基础模型的核心问题
即便已有这些研究,仍有大量关键问题尚未解决:
- 可控性(steerability):
引导机器人完成新任务需要多少额外成本?现有VLA模型声称只需输入新的语言指令即可执行新任务,但实际应用中,模型往往不会遵循指令,而是根据视觉观测执行自认为合理的动作。可控性是当前所有模型面临的核心难题。
- 物理落地(physical grounding):
VLM 大多基于语言任务训练,对物理交互的理解不足;世界模型或视频模型则存在视频幻觉与机器人实际物理执行之间的巨大鸿沟。
- 可调试性(debugability):
任务失败时该如何修正?若预算允许采集10000条新演示数据或修正数据,该如何规划采集方向?如何评估数据采集后的机器人性能?这些问题均无答案。
- 可扩展性(scalability):
将系统迁移到更大场景、更长周期的任务中会面临什么问题?这也是我们正在全力攻克的问题。
对于这些研究方向,我从不否定其价值,但始终保持谨慎乐观。大家需要理性看待规模化拓展的前景,区分技术 hype 与实际价值。
4 研究切入点一:触觉感知(Tactile Sensing)
回到当前的基础模型,我们实验室的核心工作是定位技术缺口,并探索如何弥合这些缺口,尤其是连接现有基础模型与机器人物理交互能力的缺口。
触觉感知的重要性
我主要从三个维度切入研究:第一个维度是感知(sensing) 。当前绝大多数基础模型仅基于语言、视觉数据训练,缺失了关键的触觉感知。触觉感知对物理交互至关重要------单靠视觉,很难判断机器人是紧握还是轻握物体,只有触觉信号能反馈实际施加的力;人类能感知坐姿、站姿是否稳定,也依赖身体的触觉反馈。这类感知数据是我们习以为常的,但在当前机器人模型中几乎是空白。

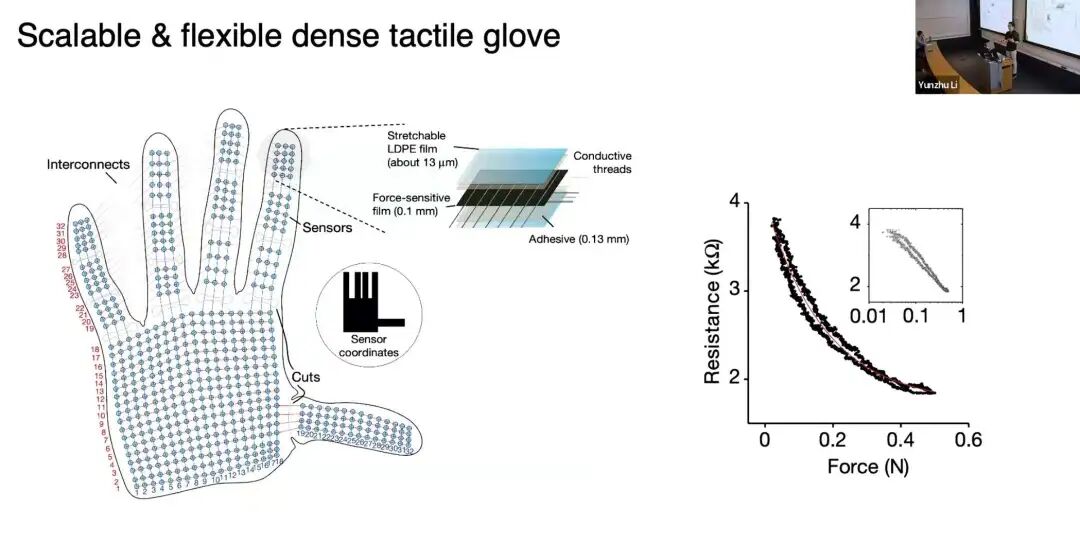
早期工作:Nature 触觉手套
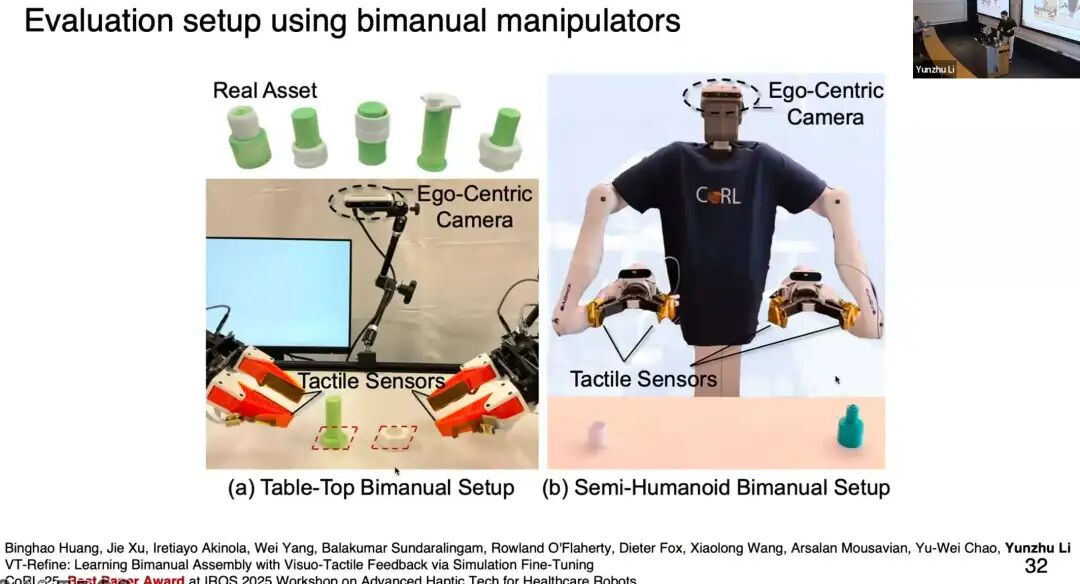
我在MIT读博期间,有一篇发表在Nature 的论文,研发了tactile glove,让手掌区域具备高密度触觉感知能力。左侧是交互过程,右侧是触觉信号可视化------点的疏密代表接触位置与受力大小,按压杯口时还能看到环形的接触图案。

这套感知机制的原理很简单:我们采用压阻材料(piezoresistive material) 制作传感器,其特性是受力越大,电阻越小,通过读取电路的电阻变化,就能获取触觉信息。
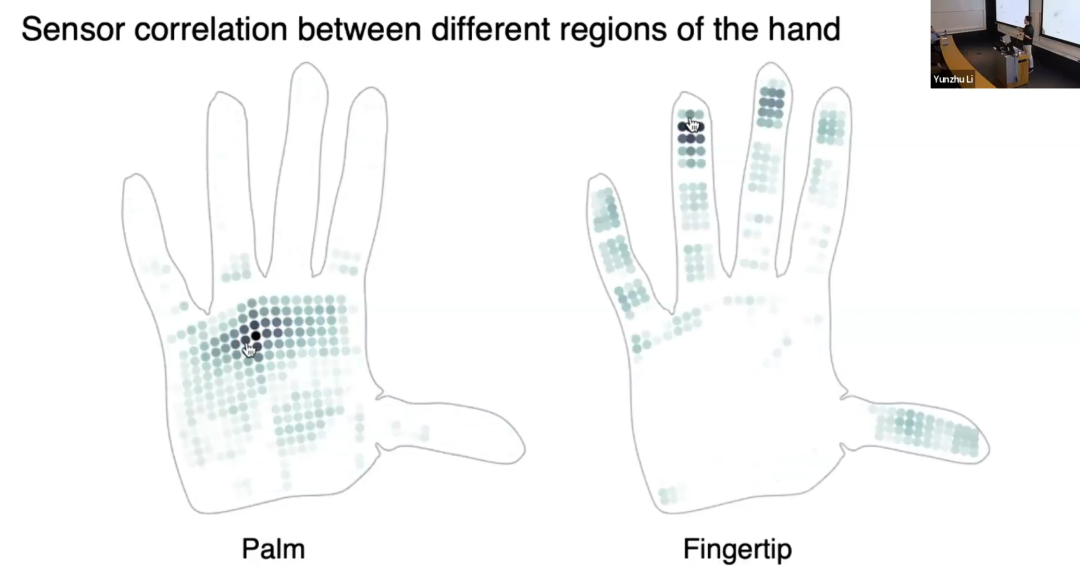
我们用这只触觉手套完成了物体识别等任务,采集了大量人手-物体交互数据,并做了一项有趣的研究:分析人类手部的使用规律。可视化结果显示,鼠标悬停在手部不同区域时,光点颜色代表该区域触点的协同使用概率:掌心附近的触点协同概率更高,指尖即便相距较远,协同概率也很高。这揭示了人类手部使用的特征规律,对触觉传感器、假肢工具的设计极具参考价值。

这只触觉手套目前被MIT博物馆收藏,进入博物馆AI展区首先就能看到它。如果大家有机会去波士顿,非常推荐去参观。

触觉传感器迭代与机器人实操验证
在此基础上,我们进一步探索:如何用这类传感器赋能机器人?我们主要沿两条路线推进:
-
构建触觉信号仿真系统,通过数字世界规模化生成数据;
-
在真实世界中规模化采集触觉数据。
首先要确保传感器对机器人实用。
我成立实验室后,对传感器进行了迭代升级:提升分辨率、优化信噪比,更重要的是让传感器能无缝集成到机器人上,配合模仿学习(imitation learning),让机器人自主完成各类操作任务。
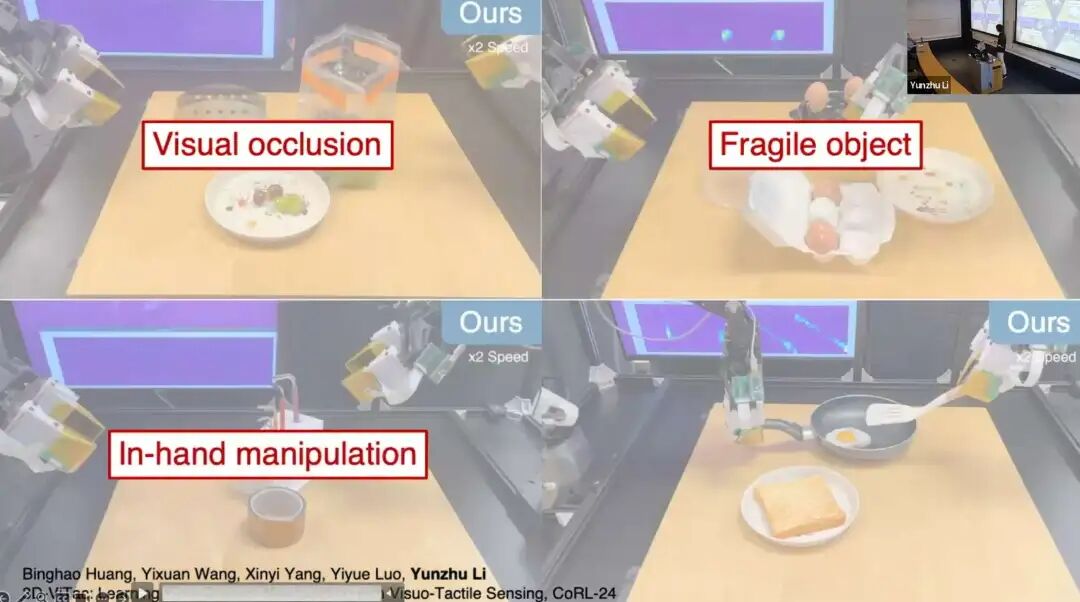
机器人伸手进入袋子抓取葡萄,放到盘子里,屏幕实时可视化触觉信号;除了视觉可见的任务,机器人还能操作易碎物体,即便受到外界干扰,也能通过触觉感知"手指间无信号",重新完成抓取;还能实现手部重定位(in-hand reorientation) ,触觉信号隐式地为策略提供物体精准位置与姿态信息;最后是**双手协调(bimanual coordination)**操作。

大家可能会好奇:如果没有触觉感知,会发生什么?

我们做了对比实验:完全相同的数据、仅使用视觉观测,完成内六角扳手重定位任务。机器人看似完成了合理操作,但差之毫厘,谬以千里------没有触觉感知,机器人无法精准感知手指间扳手的位置与姿态。抓取葡萄的任务中,无触觉感知的机器人要么抓空,要么用力过大,直接捏碎易碎的果实。
视觉触觉反馈与传感器关键指标
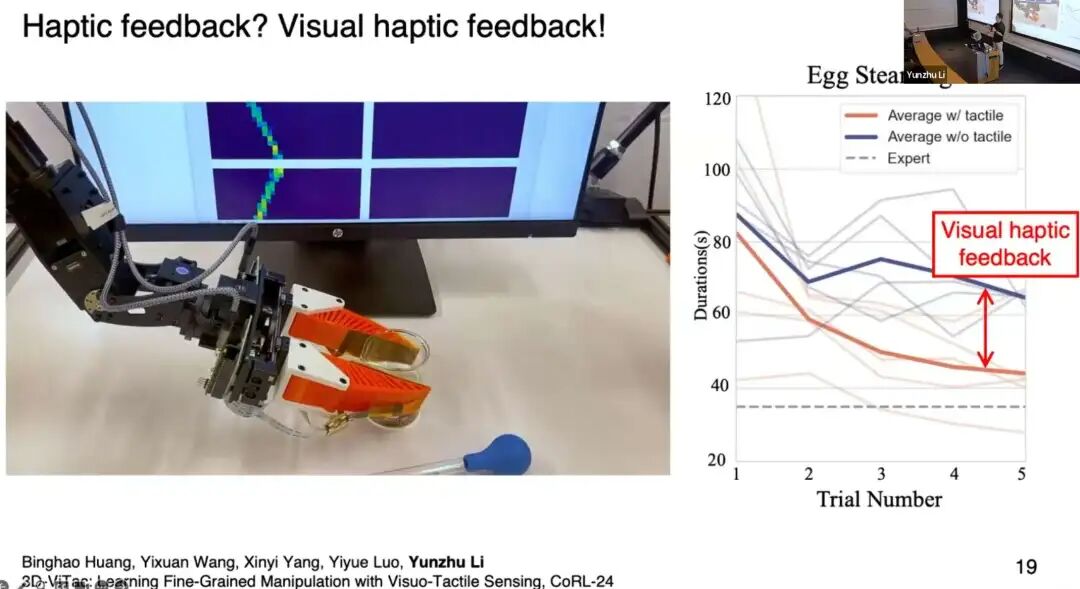
这里有一个细节需要说明:数据采集时,远程操作员是否获得力反馈?我们没有使用真实的力级反馈,而是实时可视化触觉信号 ,称之为视觉触觉反馈(visual haptic feedback)。这一设计大幅提升了远程操作员的操作效率、成功率与行为一致性。
提问:确认一下,之前视频中的相机信号是策略的输入吗?
回答 :我们使用了外部相机观测环境,这个项目没有用腕部相机,而是将点云观测 与触觉感知 融合到统一的3D表征空间,采用diffusion policy架构完成策略学习。
提问:如果加入腕部相机,触觉感知的作用会有多大变化?业界常说相机足以替代触觉,我想知道你的看法。
回答 :这个问题很关键,我后面会放视频解答。我们在机器人腕部搭载了GoPro相机,底部实时显示触觉信号,任务是试管重定位后插入,过程中有人持续干扰机器人。即便相机已对准透明试管,视觉仍难以精准判断试管在手指间的位置与姿态,但触觉信号能提供精准描述。机器人会持续从干扰中恢复,直到试管直立再完成插入。这个案例充分证明,触觉感知对任务成功至关重要。
我们发现,为远程操作员提供视觉触觉反馈,不仅能提升任务成功率、保证行为一致性,还能建立触觉信号与机器人动作之间的因果关联。
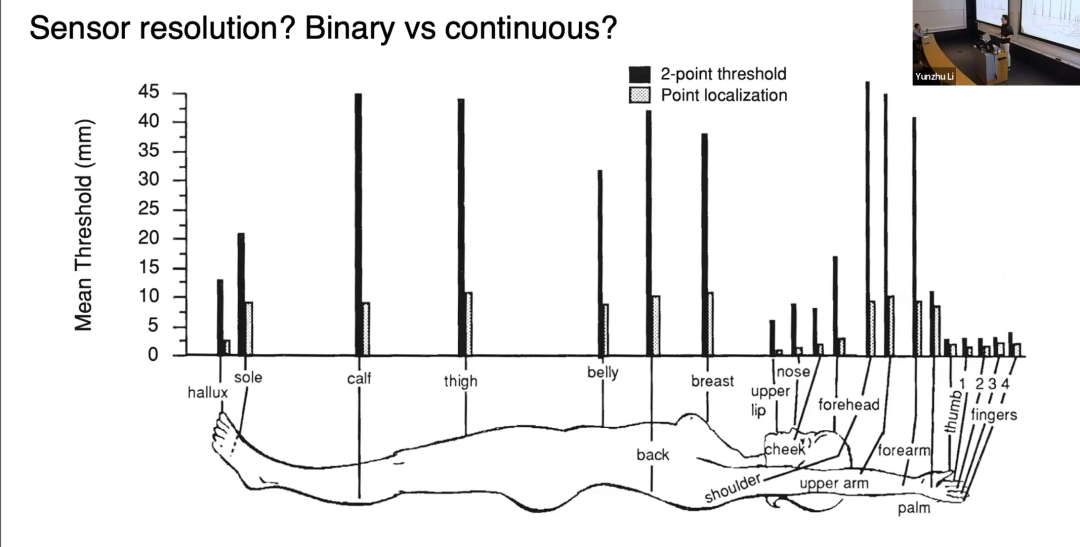
很多人问我们传感器的分辨率:我们设计的传感器相邻触点间距为2毫米 。这一参数参考了人类触觉感知的经典研究------two-point discrimination 实验:用两根针触碰身体不同部位,测量人能分辨出两根针的最小距离。人类指尖的分辨距离恰好是2-3毫米,也就是说,我们的触觉传感器分辨率与人类指尖相当;而人体触觉最灵敏的部位其实是嘴唇。
传感器开源与商业化


我们实验室受益于众多开源硬件项目,因此也全力回馈社区:开源了触觉传感器的完整复刻指南 。发布一年多来,这款传感器已被全球众多高校与企业采用,衍生出大量操作任务相关研究。就在不久前的GTC大会上,我们的合作伙伴Analog Devices 已启动传感器商业化,将其与夹具、Shadow Hand集成,完成线缆、插座等精细操作任务。

自研传感器核心优势

我简单梳理一下我们的传感器在触觉传感领域的定位:目前触觉传感器的技术路线尚未像视觉传感器那样统一,存在光学式、磁式、电容式等多种方案。

我读博初期的第一个项目,就是研究基于光学的触觉传感器GelSight。我们的传感器核心优势在于:
-
可扩展性:极易拓展到大尺寸或小尺寸场景,我们甚至制作过触觉地毯,完成大尺寸接触测量。
-
柔性:传感器本质如同一张纸,可弯曲、扭曲,适配人手等可变形表面。
-
可定制化:可定制为手指、机器人皮肤、触觉手套等多种形态。
-
鲁棒性与一致性:这是我对光学式触觉传感器最大的不满------橡胶材质会逐渐老化、性能漂移,GelSight、GelSlim、丰田研发的软气泡夹具都存在这类问题。而我们的传感器极其稳定:2024年夏天,我的学生为Nvidia制作的四片传感器,至今仍正常工作,证明其在时间与不同制作批次间的稳定性。
-
仿真兼容性 :我们已搭建触觉信号仿真系统。第一行是真实交互与传感器特性,第二行是仿真效果。我们用极简的弹簧-阻尼-质量模型(spring-damper-mass model),就能根据仿真器的状态读数渲染触觉信号。
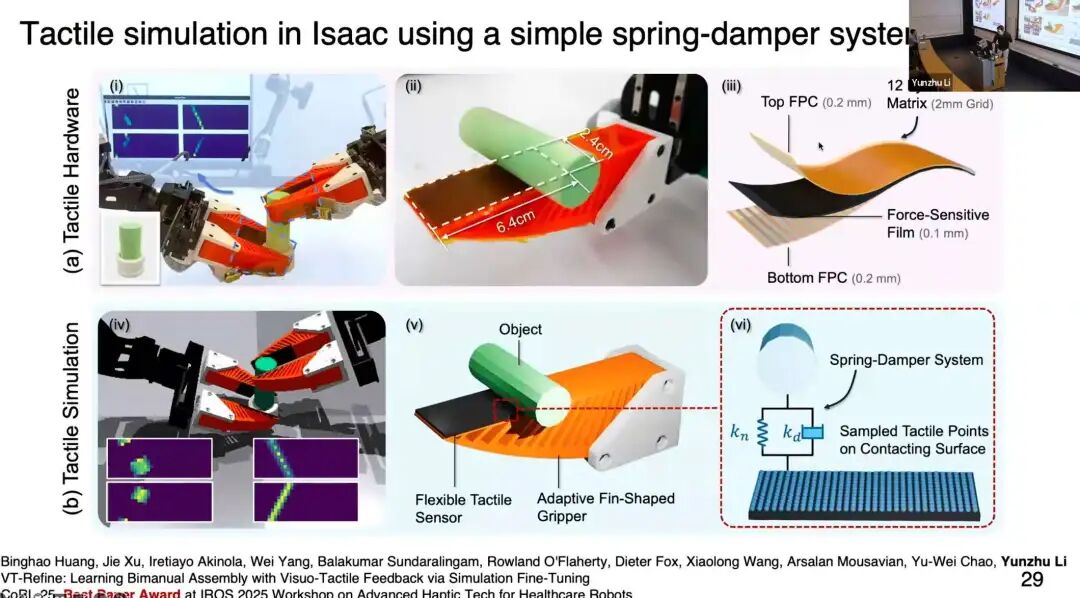
触觉信号仿真与虚实迁移
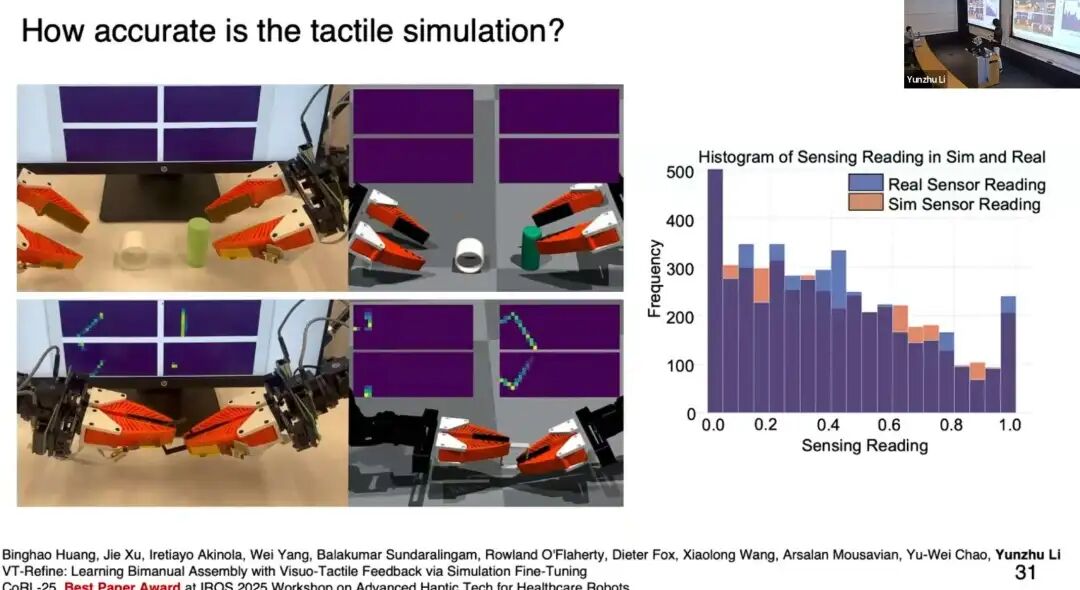
左右对比:左侧是机器人执行双手装配任务的真实触觉信号可视化,右侧是相同策略在数字环境中的仿真触觉信号,二者定性匹配度极高。

我们还做了定量测试:让远程操作员在真实环境采集数据,在仿真中复现动作,分别采集真实与仿真触觉信号,绘制直方图。蓝色柱代表真实信号,橙色柱代表仿真信号,二者分布高度吻合。
这一点至关重要:sim-to-real需要做域随机化(domain randomization) ,而仿真精度越高,所需的随机化越少,机器人落地精度越高。
我们在实验室的桌面级Aloha平台,以及Nvidia的半人形机器人平台上验证了这套框架。通过在仿真环境中完成RL微调,策略能处理工厂基准测试中的各类装配任务。这里展示的是我们实验室机器人的操作演示,以及Nvidia机器人的操作演示------数字环境让我们能高效、泛化地适配不同形态的机器人。
这个过程中还有一个关键发现:不仅存在sim-to-real 间隙,还存在real-to-sim间隙。具体流程是:先在真实环境采集演示数据,训练策略,成功率约40%-50%;将策略导入仿真,性能因real-to-sim间隙小幅下降;再在仿真中通过RL(DPO)微调,性能大幅提升,最后迁移回真实环境。
尽管两次迁移都有性能下降,但仿真中的微调仍能让整体性能显著提升。仿真间隙依旧存在并会降低性能,但RL微调能有效弥补,而触觉感知是RL流程解锁最终性能的关键。
提问:在仿真中采集演示数据会不会更好?
回答 :这个问题很有意思。我们发现,仿真中的远程操作有时比真实环境更难------真实环境中,操作员可以转头多角度观测,还能获得音频、振动等多模态线索,这些信息会间接通过视觉传递,辅助操作;但仿真中缺失这些线索,会大幅增加操作难度。不过这仍是可行方案,仿真环境也有很大的优化空间。
提问:你是否发现真实环境与仿真之间存在偏差?比如仿真中的受力比真实环境更小?
回答 :这正是我们需要做**校准(calibration)**的原因。右侧是力读数分布曲线,原理类似图像的白平衡匹配:分别统计真实与仿真触觉力信息的直方图,通过优化触觉模型中的、与穿透深度等参数,完成系统辨识,让力分布匹配。
真实世界触觉数据规模化采集

除了规模化仿真数据,我们也在探索真实世界数据的规模化采集。这一工作源于Shan的通用操作接口(Universal Manipulation Interface, UMI),我们弥补了其关键缺口。
熟悉UMI的研究者知道,它的手持夹具带有机械弹簧,操作员采集数据时能获得触觉反馈,感知大致的受力大小,但原始UMI设计不会存储这些力信息,仅记录视觉与夹具位置信息,难以应用于需要力感知的任务。

而我们的触觉传感器恰好弥补了这一缺口:通过交互过程中的触觉信号,间接存储操作员获得的触觉信息。

我们设计的夹具便携易用,可在野外环境采集数据。我们已在哥伦比亚大学校园的室内、室外场景,采集了大量同步数据------第一行是视觉观测,第二行是同步触觉信号。


用这些数据做预训练,再结合特定任务的演示数据微调,策略就能完成易碎、透明物体的手部重定位任务;还能完成铅笔的手部旋转与削笔器插入操作;以及需要精准**力调节(force modulation)**的任务------比如吸取液体时,需适度松开夹具,既保证液体吸入,又不脱落玻璃器皿;还有擦拭任务,需保持恒定的擦拭力。
以上就是我们在触觉数据规模化方面的研究。我们研发并迭代触觉传感器,推动其普及化,通过数字世界与真实世界双路径实现数据规模化;将触觉感知集成到多种形态的设备中,构建生态系统,让全球研究者都能定制触觉传感器,为机器人物理交互的基础理解提供支撑。
5 研究切入点二:结构化世界模型(Structured World Models)
我们定位的第二个核心缺口,是机器人对环境动力学的理解 ,也就是如今热门的世界模型。
世界模型的技术谱系
人类天生具备强大的直觉世界模型:我们能预测执行特定动作后环境的变化,比如面团的形状、洋葱块的运动轨迹。正是这种前向预测能力,让人类能完成逆规划、修正行为规划,结合环境反馈,稳健地完成现实任务。

这类预测模型的技术路线呈谱系分布:

-
最左侧:纯学习路线 ,即标准的世界模型定义------基于动作条件的视频预测,典型代表是Genie 3。这类模型基于海量游戏数据训练,大多聚焦导航任务,且游戏数据的物理精度不足,难以精准描述物理交互。
-
最右侧:纯物理路线 ,比如Nvidia Warp、Newton,基于第一性原理(如)构建数字环境与仿真系统。但这类方法需要环境的全状态信息,且假设已知动力学控制方程,面对复杂现实环境时,这一假设往往不成立。
我们的核心研究问题是:能否在谱系中间找到平衡点,融合两条路线的优势?
图神经动力学模型 GND
我们的重要研究方向是:基于粒子表征的图神经动力学模型(graph-based neurodynamics model) ,我们称之为Graphics Neurodynamics(GND)。该模型能建模环境中多样的物体,包括绳索、布料、毛绒玩具、多物体交互,还凭借弹塑性物体(面团)建模工作获得最佳系统论文奖。

粒子建模的核心思路:将物体分解为若干球体,用边连接球体,描述物体内部及不同物体间的交互。

模型采用图神经动力学架构:
-
当前状态是一张图,包含若干节点与有向边;
-
每条从B指向A的有向边,通过边编码器提取发送端B与接收端A的信息,生成边表征;
-
每个节点聚合所有以其为接收端的边表征,更新节点表征;
-
可自定义任意目标函数,本研究中以环境演化的预测精度为监督信号。
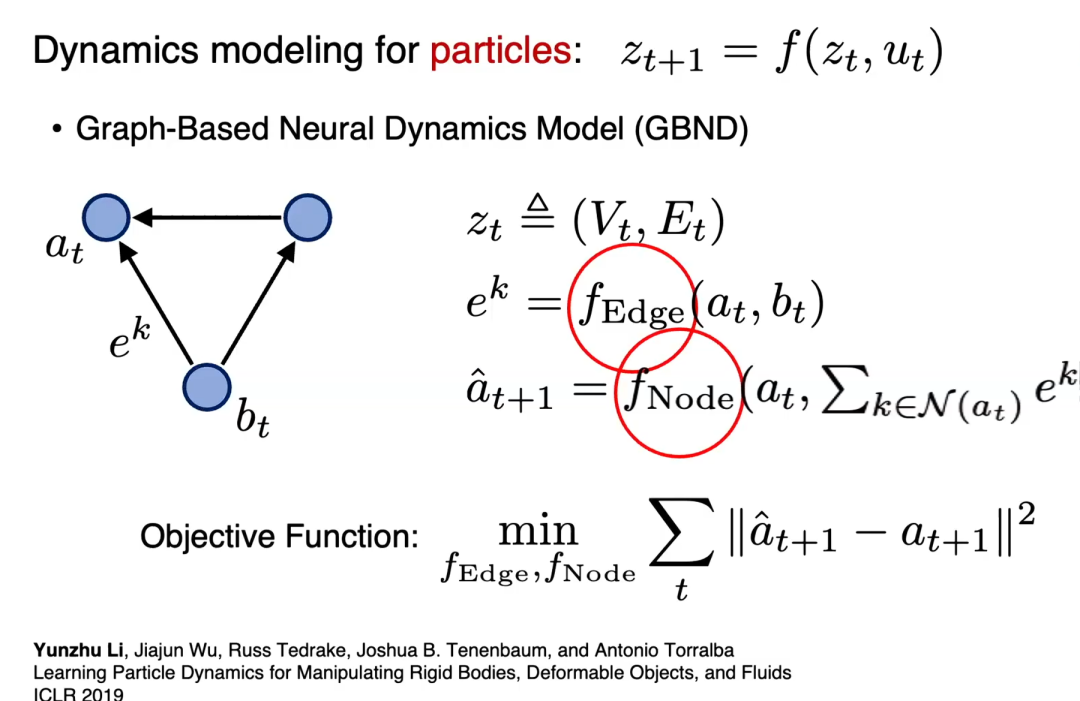
由于节点编码器与边编码器在所有节点、边之间共享,模型能自然适配训练时未见过的更大/更小规模系统。
实验证明,该模型能建模流体下落、融合,弹塑性物体形变,流体波动等现象。
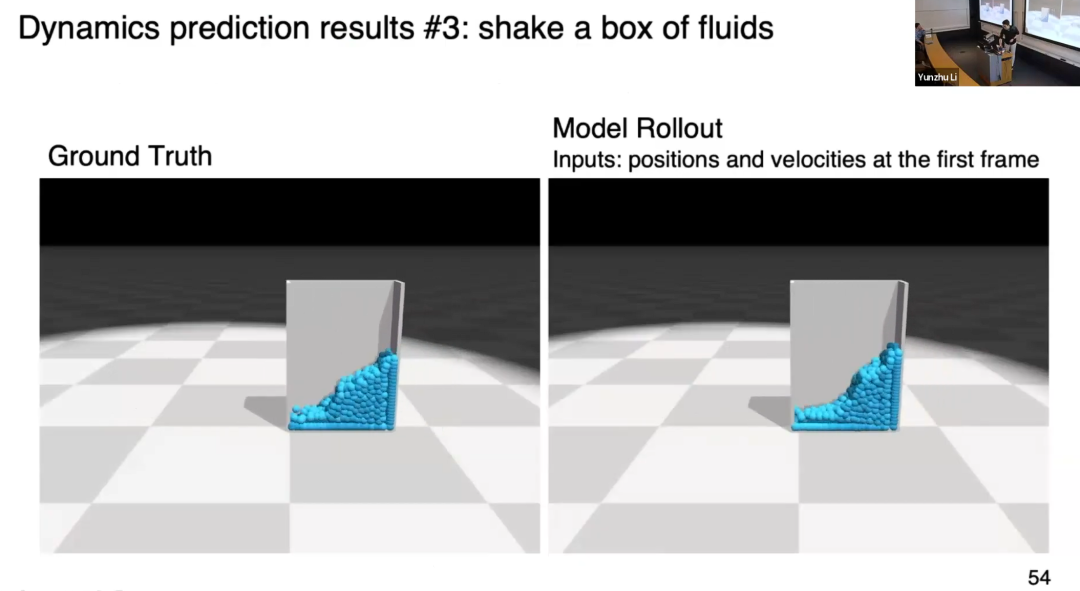
将其拓展到真实物体建模也十分直接:用真实物体观测构建图表征,用边连接不同部分,为模型注入归纳偏置,捕捉物体整体结构。

真实数据训练与复杂任务验证
我们完成的最复杂的任务之一,是用该模型建模面团的动力学,实现包饺子操作。

实验 setup:15种3D打印工具供机器人选择,4台RGBD相机观测环境,红色圆圈为机器人工作空间。

模型训练完全不依赖仿真,所有数据均采集自真实环境:为每种工具设计原始动作空间,在真实环境中随机探索采集数据,用GND模型学习"特定工具执行特定动作后面团形状的变化规律"。
第一行是模型的开环预测,第二行是真实环境结果------蓝色球体表示面团形状,红色球体表示工具形状。模型能精准预测按压、滚动等动作后面团面积的变化。
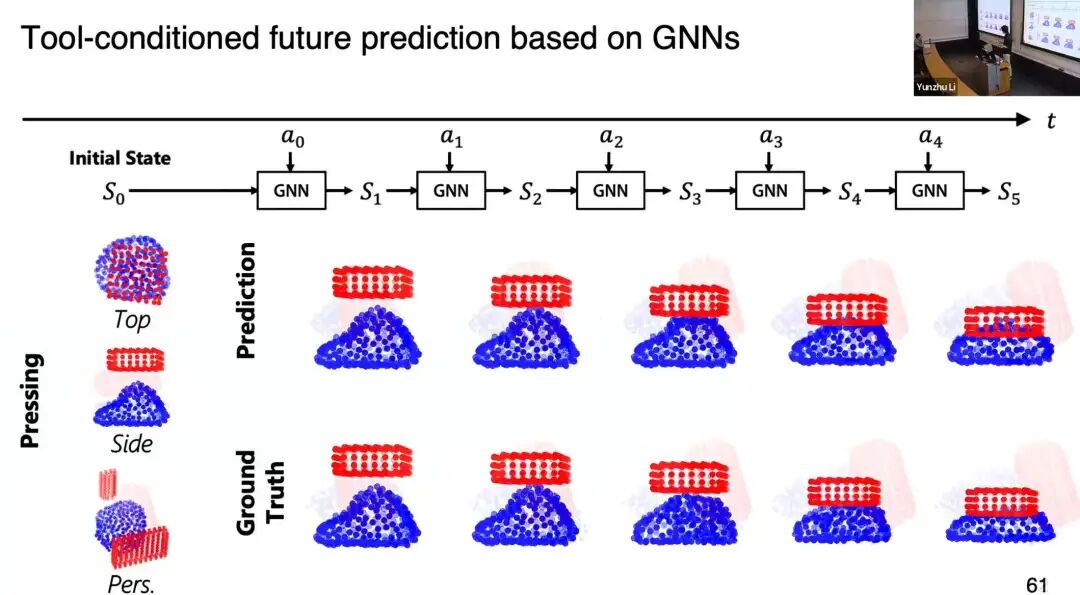
基于这些能力,机器人能完成极具挑战的长周期任务,即便过程中受到人为持续干扰,仍能保持鲁棒性。这对验证模型的泛化边界与非结构化环境适应能力至关重要。
基于这个仅用真实数据训练的预测模型,机器人能解决逆规划问题,规划分为两个层级:
-
离散层:选择使用的工具;
-
连续层:确定工具的连续动作,推进任务进程。
这些能力均源于GND模型对动作-面团形变关系的精准预测。
最精彩的部分:机器人切出饺子皮时,人为破坏全部操作,机器人会判断任务失败,从头开始重新执行整个流程。这充分展现了机器人面对外部干扰时的稳定性。
我们还与基于物理的仿真器物质点法(MPM) 对比:即便经过大量系统辨识,直接从真实数据学习的动力学模型,精度仍显著高于MPM。这也是机器人能完成高难度任务的核心原因。

同一套GND模型还能适配其他物体类别:比如建模颗粒物料在推动动作下的运动;结合模型预测控制(MPC),指定目标(A-Z字母形状),机器人能自主生成动作序列,结合环境反馈,将颗粒物料排布为目标形状。这一任务极具挑战,需要完成非平凡的物料重分布与精细对齐。

我们还将GND模型应用于多物体交互,用GPU加速的图神经动力学模型,完成收纳任务的规划。

去年年底,我们在Science Robotics发表了一篇综述,回顾了过去十年基于学习的动力学模型在机器人操作中的研究进展。这篇论文的结构源于我的博士论文,是对该领域十年探索的深度复盘。如果大家感兴趣,强烈推荐阅读。

数字孪生 PhysTwin
接下来的问题是:未来的方向是什么?

当前我们已构建起技术谱系,世界模型领域的核心目标应如何设定?
我们需要让机器人处理更复杂的任务与物体、更多样的交互类型,不再局限于桌面环境,充分利用当前大规模数据采集的成果。
当下,行业投入大量资本与时间采集真实环境演示数据,如果仅将这些数据用于模仿学习,是巨大的浪费------数据中包含丰富的环境动力学信息,亟待挖掘。
我们的目标是:通过结构化世界模型 ,构建可规模化的数据引擎与评估引擎。我们探索的核心方案之一,是PhysTwin------介于GND与纯物理路线之间的技术。

简单来说,我们为真实环境中的物体构建数字孪生(digital twin),即捕捉物体外观、几何与动力学特性的实体。
左侧是几秒的真实世界物体交互视频;中间是物体的重建几何与跟踪结果,人头上的白色球体代表人类动作;右侧分为前景与背景:背景是原始视频,前景是基于动作条件的开环3D视频预测,从与输入相同的视角渲染,前景与背景高度吻合,证明数字孪生的重建精度。
这个数字孪生同样基于粒子构建,同时融入物理先验,约束相邻粒子的相对运动,通过几何、运动、渲染三个目标函数完成重建。

拥有数字孪生后,可通过键盘、鼠标随意操控,完成基于动作条件的3D视频预测,适配可变形物体、布料、绳索等。

作为机器人研究者,我始终希望将数字孪生与机器人结合。视频中是我的学生Kyone远程操作双臂Xarm平台,我们记录动作,并在真实环境(右下角)与数字孪生(前景)中实时复现。这是基于动作条件的开环未来预测,叠加效果证明两点:
-
预测结果与真实环境高度吻合;
-
全流程基于GPU实现,实时运行,帧率与真实环境同步。
数字环境评估的核心价值

谷歌的同行曾联系我们:能否用这套数字环境评估机器人策略?因为评估是机器人模型迭代的核心痛点------机器人基础模型的迭代需要物理实验,不安全、难规模化,速度比LLM迭代慢数个数量级。Drew与Annie已有相关研究,尝试在数字环境中完成评估。
当时谷歌的同行表示,他们有充足预算推进研究,但我确信,一旦迁移到更大、更复杂的环境,这种进展会迅速放缓。因此,数字环境评估是推动机器人技术发展的核心环节。

我们与谷歌合作,搭建了一套精简流程:
-
用手机环绕机器人拍摄,重建机器人、环境、交互物体的外观与几何;
-
校准iPhone相机与深度相机的色彩空间;
-
用几秒的真实交互数据,完成物体动力学建模。

核心结果:第一行是数字世界,第二行是真实环境。所有策略仅用真实数据训练,未经过联合训练,直接在数字环境中运行,行为与真实场景的相关性达到业界顶尖水平,不仅适配刚性物体,也适配可变形物体。
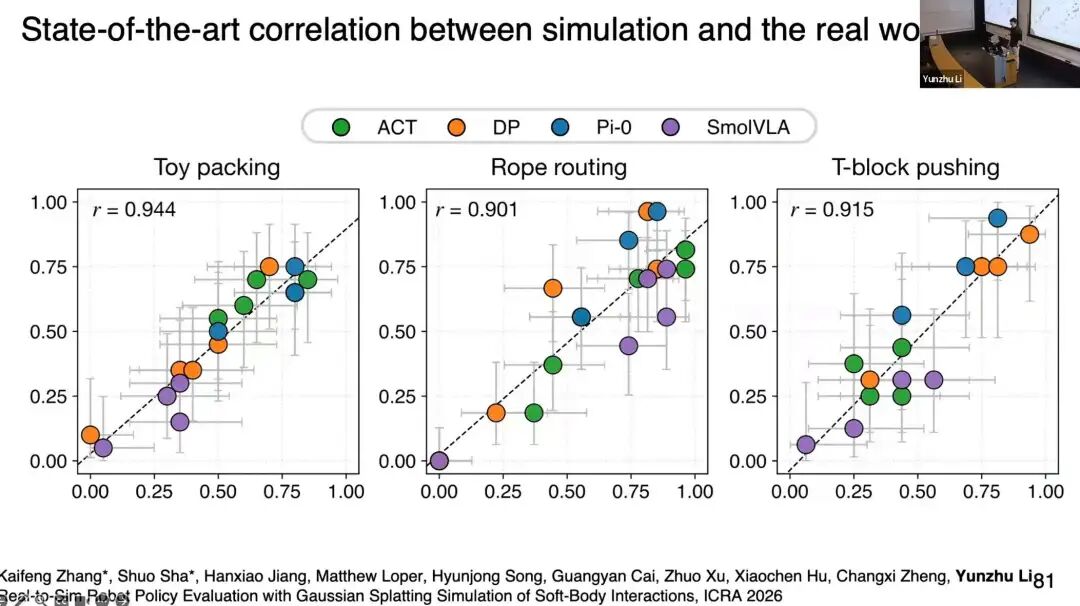
我们用纵轴表示数字世界评估结果,横轴表示真实环境评估结果,测试了DP、Pi0、smallVLA等四类策略的多个检查点,相关系数均超过0.99。
这里必须强调:任何评估结论都需要明确、具体的评估协议。我们沿用了丰田研发的最佳实践,确保评估信号清晰可信,其中最核心的一点是:明确策略训练与评估的数据分布。

现在我会要求学生必须展示训练与评估数据的重叠分布,否则我无法认可结果的可信度。通过重叠分布重置环境初始状态,确保同一策略不同检查点、不同策略、真实环境与数字世界的评估初始状态一致,这是保证评估相关性严谨性的前提。

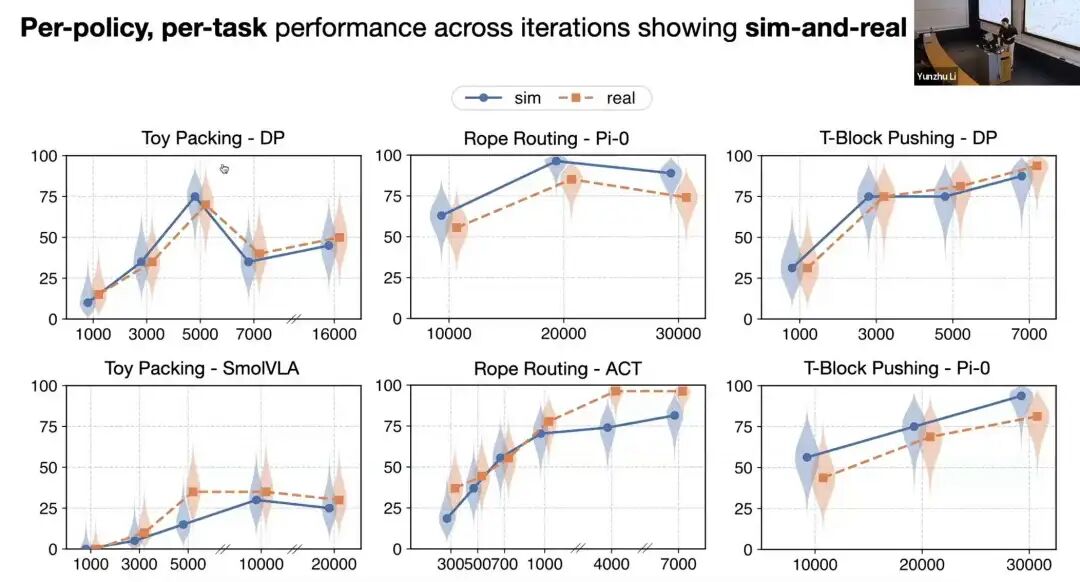
相比其他环境,我们通过精准对齐动力学与外观,让相关性大幅提升。这套系统还能用于检查点选择:不同任务与策略的训练迭代(横轴)与成功率(纵轴)曲线中,仿真与真实评估结果高度吻合,最优检查点往往不在训练最后阶段,而在中间过程,这对策略开发迭代极具价值。

目前,我们已将数字化对象拓展到弹塑性、铰接式物体。左上角是仿真,右上角是真实环境------注意这是仿真而非动画,数字环境仅输入初始状态与后续动作,就能精准复现真实效果。下方是长周期复杂操作任务(双耳插入插槽)的真实环境、数字世界与叠加效果,二者高度对齐。

我始终认为:所有能在现实中落地的机器人应用(无人机、火箭、扫地机器人、四足机器人、管道机器人),核心前提是拥有模型------即便模型不完美,也能完成sim-to-real迁移。操作任务之所以困难,是因为需要同时建模机器人与环境,但这绝不是放弃环境建模的理由。

在学习与物理的谱系之间,有大量工具能帮助我们精准建模环境,实现数字世界与真实世界的高相关性,释放远超仅依赖真实数据的潜力。
交互式世界模拟器

最后简要介绍我们几周前发布的最新工作:Interactive World Simulator。

这项工作介于纯学习路线与GND之间,用学习先验构建动力学模型,本质是基于动作条件的视频预测模型 ,支持操作员以15帧/秒的速率与预测结果实时交互,能稳定完成超过10分钟的长周期未来预测。
对我而言,这是首个有力证明:基于动作条件的视频预测不仅适用于导航,也能处理复杂的环境物理交互,包括绳索、推块、颗粒、绳索操作等。
我们首先用该模型完成数据生成 :在世界模拟器中采集演示数据,训练策略,零样本、无真实数据直接落地到真实环境,成功率极高。

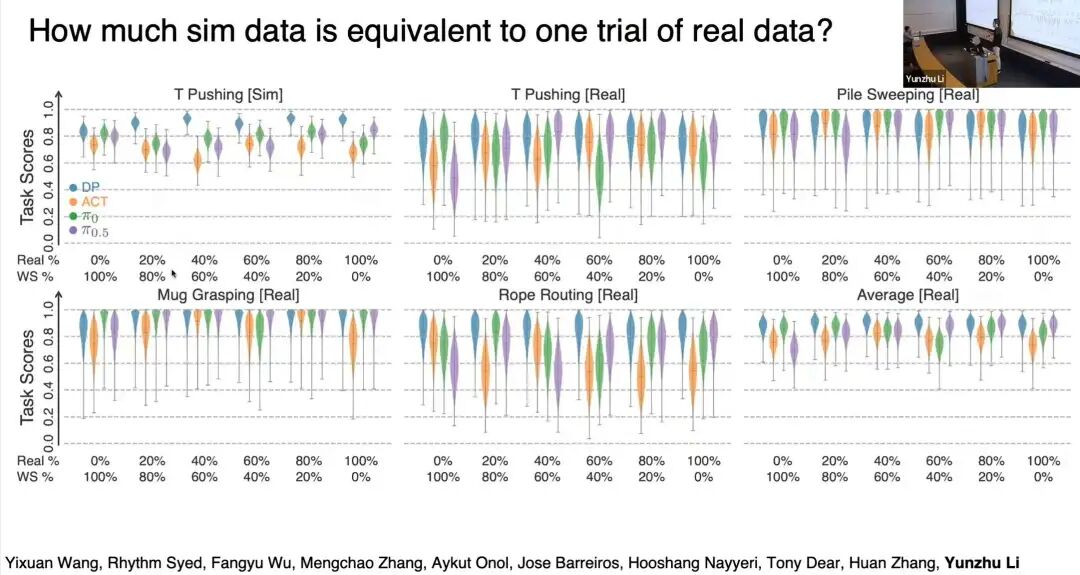
很多人问:多少仿真数据等价于一条真实数据?
我们在仿真与真实环境中开展对照实验:改变真实数据与仿真数据的占比,保持总数据量不变,不同混合比例的性能表现基本一致。我们可以稳妥地得出结论:数字数据与真实数据具备等价性,这一结果极具突破性。
这里为大家现场演示我们的数字环境:
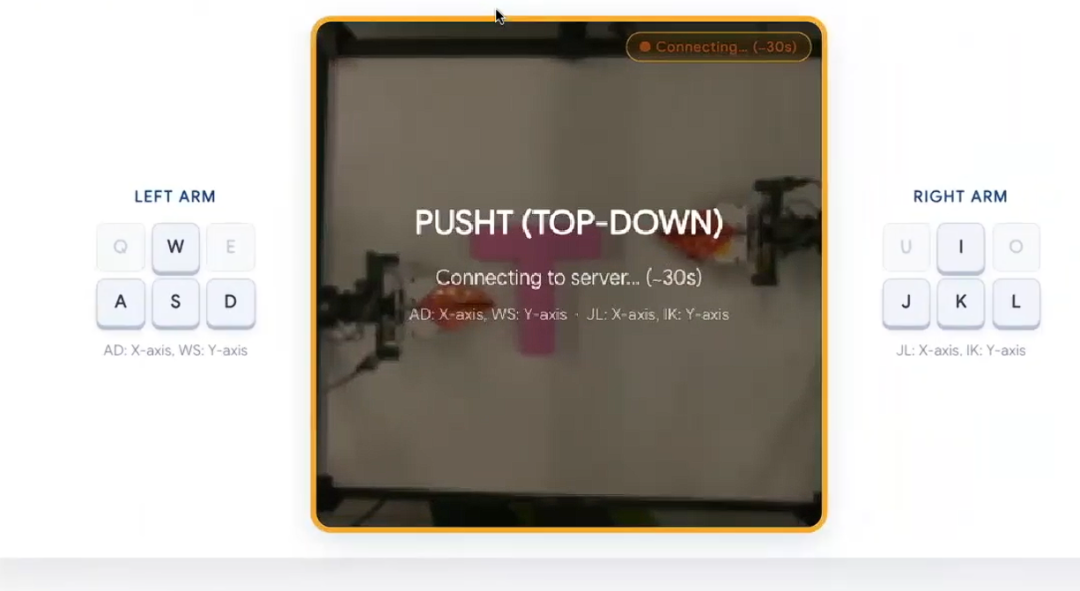
第一个任务是推块:连接服务器后,通过键盘远程操作数字世界中的机器人,能实时、稳定地完成长周期预测。因网络原因存在轻微延迟,但整体效果已能体现精准长周期未来预测的能力。
第二个任务是双手绳索操作:可抬升、下降机械臂,能将绳索挂在指定位置,过程中出现的伪影也证明这是视频预测,而非预录制视频。甚至能远程操作画面中的人物,实现"远程操作过去的自己",这是非常有趣的交互体验。
6 数据:机器人基础能力的第三块基石
最后,不可或缺的第三个维度是数据。
我们实验室参与了多项大规模数据采集项目:

-
真实环境:Open X-Embodiment;
-
合作项目:斯坦福视觉与学习实验室的Behavior团队,规模化采集数字与仿真数据;
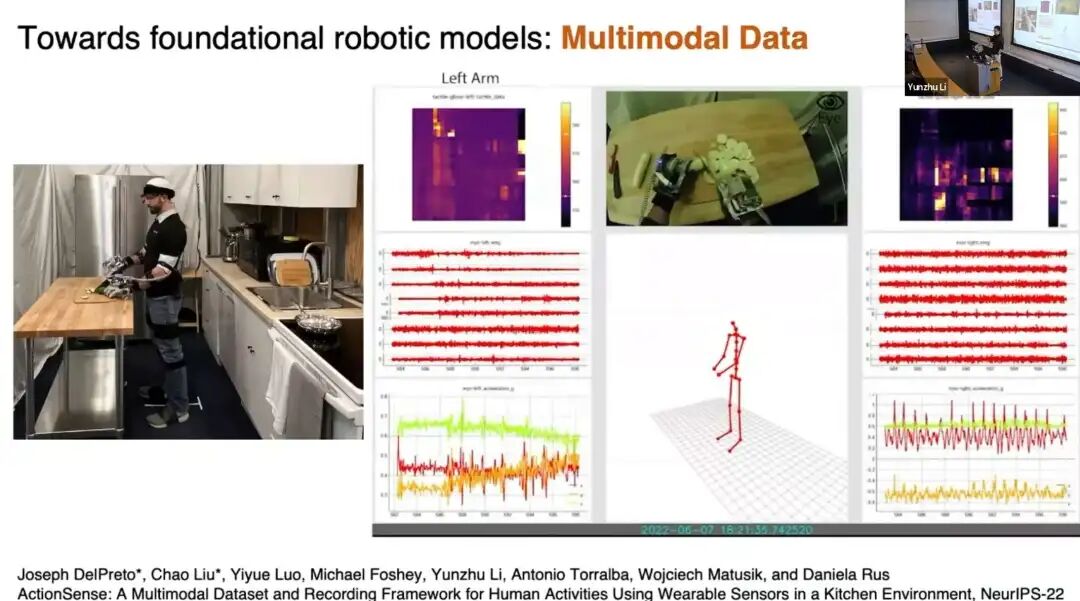
- 多模态数据:采集人类厨房活动的视觉、触觉、人体姿态、肌电、音频等数据;
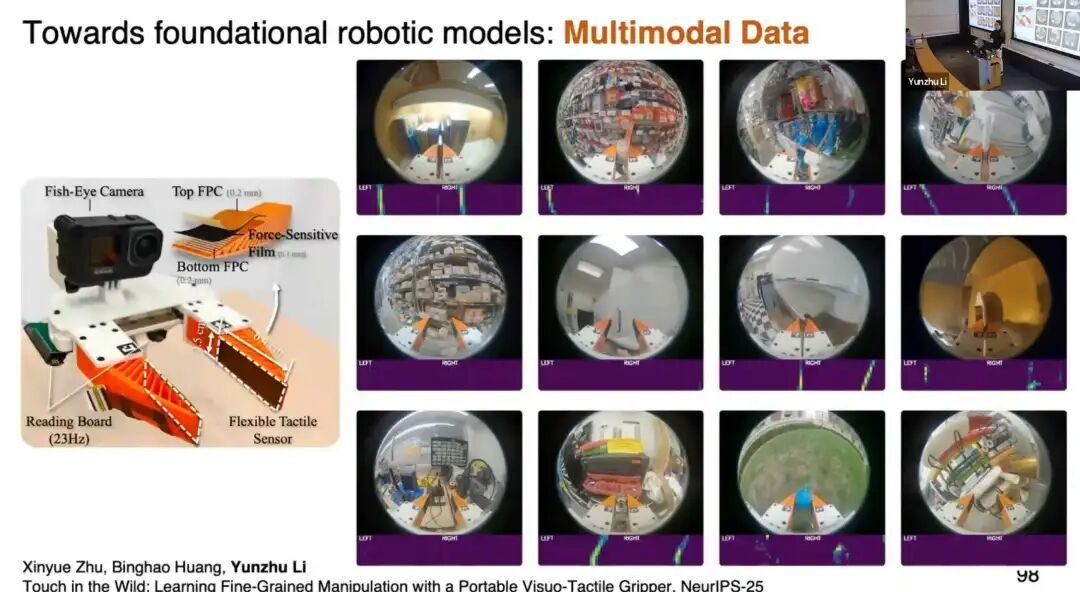
- 便携式多模态夹具:采集融合视觉与触觉的大规模数据。
7 机器人基础能力的最终愿景
最后,我想阐述我对机器人基础能力的理解,这一灵感借鉴了其他领域的研究。

当前的VLM 与LLM,输出未必完美,但总能生成合理、可信的结果。我希望机器人基础能力能实现同样的目标:生成的动作未必最优,但一定能在真实环境中合理、稳定执行,让机器人适配全结构化、半结构化、非结构化全场景任务。

8 致谢
感谢所有合作者,尤其是我的学生们,没有他们,这些研究都无法完成。同时感谢所有资助机构。
问答
提问:世界模型部分,你提到两条路线:一条是2D像素(视频预测),一条是3D点云学习世界模型。未来哪种观测空间更重要?2D有大量预训练模型,3D则具备物理一致性,各有优劣。你的看法是什么?
回答:这个问题很好,但坦白说,我目前没有定论。这也是我展示学习与物理谱系的原因------两条路线各有优势:结构化环境表征更容易融入几何、物理先验;像素/视频则更容易利用海量数据。当然,具体效果还取决于是否能获取视频中的动作标签。
因此,我们正在谱系上的不同点位布局研究,探索哪种方案能为机器人带来最佳的可扩展性与精度。即便我们还未找到最优方案,也明确了评估标准:模型能否高效生成训练数据、能否精准区分90%与92%的成功率,这是我们评估世界模型的核心指标。
提问:关于质量评估,我了解到很多工作的核心指标是仿真与真实环境的成功率相关性。你是否观察到仿真与真实环境的失败模式存在相似性?
回答 :这个问题很深刻,也很细致。我们目前已实现高相关性,但仍观察到一定比例的假阳性与假阴性:真实环境成功的任务,仿真中可能失败;仿真中成功的任务,真实环境可能失败。尽管比例不高,但这是未来需要重点攻克的方向------在数字世界中精准复现失败案例,完成失败点附近的数据增强,提升策略对状态空间的鲁棒覆盖。
实际上,在交互式世界模拟器的论文中,我们已成功用基于动作条件的视频预测模型,定位策略实现中的漏洞,对策略调试与迭代极具价值。但我们仍需承认,假阳性与假阴性问题依然存在,这也是我们实验室当前的重点研究方向。
提问:还是关于评估的问题。你之前的幻灯片提到,需要明确训练与评估的初始分布(真实/仿真)。在你的数字孪生仿真器中,当前的匹配效果很好,但如果超出训练初始分布,还能保持高相关性吗?
回答:这个问题涉及很多细节。比如将插槽移到训练分布之外,策略在真实环境与仿真中都会出现异常行为。但我们的数字环境基于物理感知的环境建模,动力学建模的泛化能力依然出色,问题出在策略本身。
我们观察到:训练初期,策略输出随机行为,真实与仿真环境都会出现任意失败,但失败形式略有差异------未训练好的策略会输出不连续、剧烈振动的动作,甚至震动桌面,但仿真中不会出现桌面震动。不过,随着策略性能提升,仿真与真实的失败模式会越来越接近。
提问 :第58页幻灯片中,你展示了箱体仿真,并说明模拟了弹性行为。我好奇你的物理模型如何处理历史依赖特性?比如纸张具有塑性,加载-卸载阶段的特性会变化,模型如何适配?
回答 :这个问题很好,我简短解释。模型中设置了描述关节疲劳度 的参数,疲劳参数变化会改变模型的塑性特性。视频中展示的是单段序列的复现,针对该序列估计特定参数;但实际应用中,需要关注参数分布,让策略对分布内所有数据都具备鲁棒性。我们当前正在研究这一方向。
提问:回到纯物理到纯学习的世界模型谱系,你直觉上认为哪一侧未来更有价值,尤其是在评估方面?从交互式世界模拟器来看,模型执行动作时会趋向任务目标,比如绳索即便未靠近插销,也会向目标方向靠拢;木块会避开另一机械臂,避免碰撞,这是在规避训练分布中未见过的情况。不依赖物理规则,能否仅通过视觉与动作条件,构建可靠且有评估价值的模型?还是必须依赖物理规则?
回答 :我从两个维度回答。 第一个维度是数据偏置 。这个模型仅用了我学生Ishan在真实环境中采集的6小时数据 训练。如果将数据量扩大10倍、100倍、1000倍(工业界完全可实现),通过play data 而非任务专用数据采集,能获得更全面的数据覆盖,学习到偏置更小的模型。这是学术界与工业界的分工:学术界证明新技术的可行性与规模化潜力,工业界通过合作等方式完成规模化落地。我认为数据偏置并非最紧迫的问题,更关键的是模型可控性------更换新物体、改变摩擦系数、切换机器人形态,或模拟不同摩擦表面的环境,都需要参数辨识,这是当前更突出的局限。
第二个维度是评估与训练的差异 。我们用该模型同时完成策略训练与评估,发现视觉保真度 与动力学保真度的重要性不同:
-
评估:视觉保真度至关重要,动力学保真度要求稍低。因为待评估的策略已具备良好性能,只需区分90%与92%的成功率,策略不会出现异常行为。
-
训练 :视觉保真度影响较小,可做大量视觉随机化;但动力学保真度更重要,因为需要在数字环境中做RL,确保仿真器/数字世界不会被RL智能体轻易过拟合。
综上,选择视频预测路线还是结构化路线,取决于模型的用途是评估 还是训练。