论文信息
- 标题:UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
- 会议:CVPR 2026
- 单位:小鹏机器人、清华大学、香港大学
- 代码:https://xpeng-robotics.github.io/unit/
- 论文:https://xpeng-robotics.github.io/unit/UniT.pdf
一、引言:人形机器人的"语言不通"难题
想象一下:你花了1000小时教你的人形机器人拿杯子,结果换个杯子它就不会了;而人类小孩看一眼别人拿杯子,自己就能学会。这就是当前人形机器人最大的痛点:数据太少了。
训练一个通用人形机器人需要百万级别的高质量演示数据,但让机器人自己收集数据成本极高。反观人类,互联网上有数十亿小时的人类动作视频,这些数据免费又丰富。但问题来了:
人类和机器人长得不一样啊!人类有5根手指,机器人可能有20根;人类的关节自由度和机器人完全不同。直接把人类的动作塞给机器人,就像让猫学狗叫,根本行不通。
传统的解决方法是运动重定向:用复杂的运动学求解器把人类动作映射到机器人关节。但这个过程就像人工翻译,不仅慢、成本高,还经常出现"物理错误"------比如让机器人的手穿过桌子。
有没有可能发明一种统一的物理语言,让人类和机器人都能听懂?就像不管你说中文还是英文,"拿起杯子"这个意图是一样的。
这就是UniT要解决的问题。它提出了一个视觉锚定的统一潜动作分词器 ,把人类和机器人的异构动作都映射到同一个共享的离散潜空间。这个空间里的每个token都代表一个与体素无关的物理意图,比如"向前伸手"、"抓握"、"抬起"。这样一来,人类的知识就能直接"翻译"给机器人了。
二、核心思想:用视觉作为通用锚点
UniT的设计哲学非常巧妙:
虽然人类和机器人的关节长得不一样,但他们做同一个动作产生的视觉结果是一样的。不管是人类还是机器人拿起杯子,杯子都会从桌子上移动到空中。
这个视觉结果就是跨体素的通用锚点。UniT通过一个三分支交叉重建机制 ,强迫所有动作都必须能预测对应的视觉变化,同时所有视觉变化也必须能反推出对应的动作。这样一来,模型就只能学到真正的物理意图,而不是体素特定的关节细节或者无关的外观噪声。
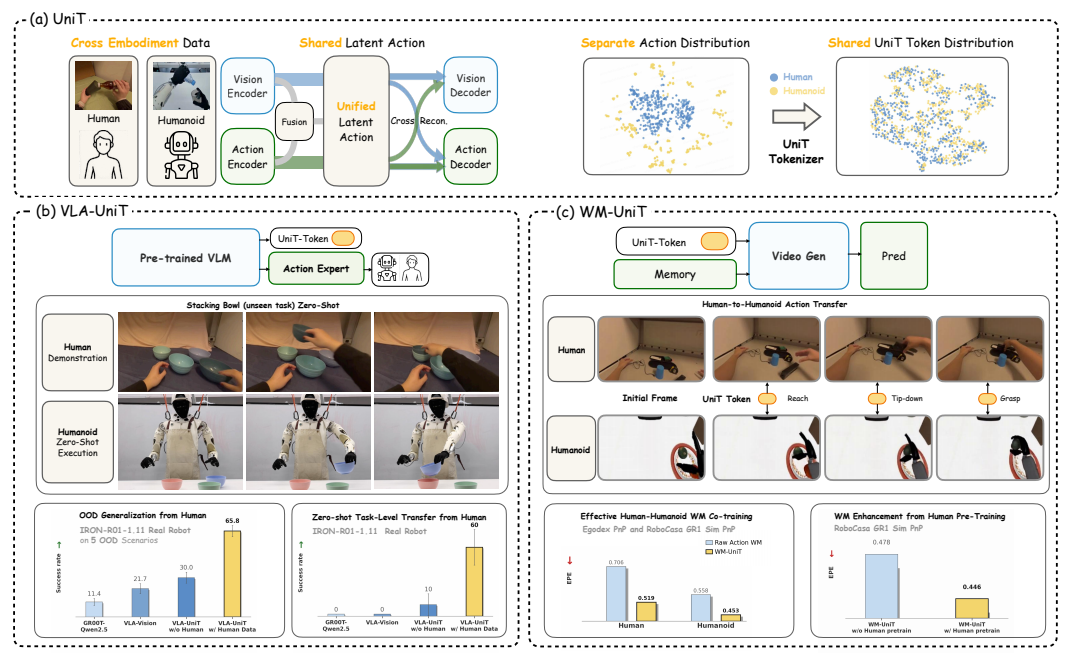
图1分析:UniT框架分为三部分:
- 统一分词:三分支交叉重建把异构动作映射到共享离散潜空间
- 策略学习(VLA-UniT):VLM预测统一token,再生成机器人动作
- 世界建模(WM-UniT):用统一token作为条件,生成跨体素视频
三、方法详解:三分支交叉重建的魔力
3.1 为什么之前的方法都不行?
在UniT之前,有三类潜动作表示方法,但都有致命缺陷:
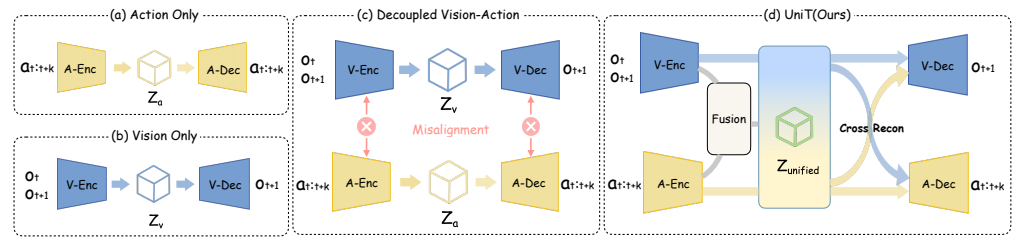
图2分析:
- 动作-only(a):只编码关节动作,没有视觉锚定。人类和机器人的动作分布完全不同,根本对齐不了。
- 视觉-only(b):只从视频推断动作。容易被纹理、光照这些外观噪声干扰,学不到精细的运动细节。
- 解耦视觉-动作(c):分别编码视觉和动作,但没有强制对齐。两个模态各说各的,形成不了统一语言。
- UniT(d):融合视觉和动作,通过交叉重建强制对齐。只有同时能解释视觉变化和动作的特征才会被保留。
3.2 UniT分词器的三大核心组件
UniT分词器的输入是:
- 连续两帧观察:oto_tot(当前帧)和ot+ko_{t+k}ot+k(k帧后)
- 当前状态:sts_tst(关节角度等)
- 动作块:at:t+ka_{t:t+k}at:t+k(连续k步的动作)
输出是:统一潜动作token,人类和机器人的动作都会被编码成这个空间里的离散值。
3.2.1 三分支编码
UniT用三个并行的Transformer编码器,分别提取不同模态的特征:
- 视觉分支EvE_vEv :输入是两帧图像的DINOv2特征(冻结的预训练模型),输出视觉过渡特征。 通俗解释:DINOv2是一个非常擅长提取通用视觉特征的模型,它能忽略纹理、光照这些干扰,只关注物体的形状和运动。用它作为视觉锚点,能保证跨体素的一致性。
- 动作分支EaE_aEa:输入是当前状态和动作块。先把不同体素的动作补全到统一长度,再用体素特定的MLP投影,输出运动控制特征。
- 融合分支EmE_mEm:把视觉和动作特征融合在一起,输出更鲁棒的视-动联合特征。
3.2.2 共享离散量化
三个分支输出的连续特征,都会通过同一个残差量化 (RQ-VAE)模块,映射到同一个共享码本C\mathcal{C}C:
z^i=RQ(zi;C),i∈{v,a,m}\hat{z}{i}=RQ(z{i};\mathcal{C}), \quad i\in \{ v,a,m\}z^i=RQ(zi;C),i∈{v,a,m}
- z^i\hat{z}_iz^i:量化后的离散潜变量
- ziz_izi:三个分支输出的连续潜变量
- C\mathcal{C}C:所有分支共享的离散码本
- i∈{v,a,m}i\in\{v,a,m\}i∈{v,a,m}:分别代表视觉、动作、融合分支
通俗解释:这就像给所有动作都编上统一的字典。不管是人类的"伸手"还是机器人的"伸手",都会被映射到字典里的同一个词条。残差量化的好处是能同时捕捉粗粒度的意图(比如"伸手")和细粒度的动作(比如"伸10厘米")。
3.2.3 交叉重建:UniT的灵魂
这是UniT最核心的设计:每个量化后的token,都必须能同时解码出视觉变化和动作 。
f^t+k(i)=Dv(z^i,ft),a^t:t+k(i)=Da(z^i,st)\hat{f}{t+k}^{(i)}=D{v}\left(\hat{z}{i}, f{t}\right), \quad \hat{a}{t: t+k}^{(i)}=D{a}\left(\hat{z}{i}, s{t}\right)f^t+k(i)=Dv(z^i,ft),a^t:t+k(i)=Da(z^i,st)
- f^t+k(i)\hat{f}_{t+k}^{(i)}f^t+k(i):解码出的k帧后DINOv2特征
- a^t:t+k(i)\hat{a}_{t:t+k}^{(i)}a^t:t+k(i):解码出的动作块
- DvD_vDv:所有体素共享的视觉解码器
- DaD_aDa:体素特定的动作解码器
- ftf_tft:当前帧的DINOv2特征
- sts_tst:当前状态
总损失是三个分支的交叉重建损失加上量化损失:
L=∑i∈{v,a,m}λvLcos(f\^t+k(i),ft+k)+λaLact(a\^t:t+k(i),at:t+k)+LRQ\mathcal{L}=\sum_{i \in\{v, a, m\}}\left\\lambda_{v} \\mathcal{L}_{cos }\\left(\\hat{f}_{t+k}\^{(i)}, f_{t+k}\\right)+\\lambda_{a} \\mathcal{L}_{act}\\left(\\hat{a}_{t: t+k}\^{(i)}, a_{t: t+k}\\right)\\right+\mathcal{L}_{RQ}L=i∈{v,a,m}∑λvLcos(f\^t+k(i),ft+k)+λaLact(a\^t:t+k(i),at:t+k)+LRQ
- Lcos\mathcal{L}_{cos}Lcos:视觉特征的余弦相似度损失(衡量预测的视觉变化和真实的是否一致)
- Lact\mathcal{L}_{act}Lact:动作的MSE损失(衡量预测的动作和真实的是否一致)
- LRQ\mathcal{L}_{RQ}LRQ:RQ-VAE的承诺损失(让连续特征尽量靠近码本向量)
- λv,λa\lambda_v, \lambda_aλv,λa:两个损失的权重系数
通俗解释:这个损失就像一个双向考试。token必须能回答两个问题:
- 做了这个动作,接下来画面会变成什么样?(视觉解码)
- 要产生这个视觉变化,需要做什么动作?(动作解码)
只有两个问题都答对了,这个token才算合格。这样一来,token就只能学到真正的物理意图,而不是任何体素特定的细节或者噪声。
3.3 下游应用:统一token打通策略和世界模型
UniT的统一token不是只能用在一个地方,它能同时作为策略学习的预测目标 和世界建模的控制条件,打通了两个核心的人形机器人范式。
3.3.1 VLA-UniT:跨体素策略学习
VLA-UniT基于NVIDIA的GR00T框架,用Qwen2.5-VL作为视觉语言 backbone。它把策略学习分解成两步:
- UniT token预测 :VLM根据当前图像和语言指令,预测统一的潜动作token。目标是预训练好的UniT分词器输出的token,损失是交叉熵:
Ltoken=CE(p^t,ct)\mathcal{L}{token }=CE\left(\hat{p}{t}, c_{t}\right)Ltoken=CE(p^t,ct)
其中p^t\hat{p}_tp^t是VLM预测的token分布,ctc_tct是UniT分词器输出的真实token。 - 流匹配动作生成 :一个轻量级的流匹配头,根据VLM的视觉语言特征,生成体素特定的连续动作。损失是流匹配损失:
Lfm=Eτ,ϵ∥Vθ(Atτ∣xt,Enc(ot),τ)−(At−ϵ)∥22\mathcal{L}{fm}=\mathbb{E}{\tau, \epsilon}\left\\left\\\| V_{\\theta}\\left(A_{t}\^{\\tau} \| x_{t}, Enc\\left(o_{t}\\right), \\tau\\right)-\\left(A_{t}-\\epsilon\\right)\\right\\\| _{2}\^{2}\\rightLfm=Eτ,ϵ∥Vθ(Atτ∣xt,Enc(ot),τ)−(At−ϵ)∥22
通俗解释:这就像先让VLM理解"拿起红色杯子"这个语言指令,把它翻译成统一的物理意图token,然后再让动作专家把这个意图翻译成机器人能执行的具体关节动作。因为token是跨体素的,所以人类的演示数据也能用来训练VLM。
3.3.2 WM-UniT:跨体素世界建模
WM-UniT基于NVIDIA的Cosmos Predict 2.5视频生成模型。它用UniT动作分支的预量化特征作为控制条件,代替了传统的原始动作:
LWM=Eτ,ϵ∥Vϕ(Xtτ∣ot,MLP(z\~ta),τ)−(Xt−ϵ)∥22\mathcal{L}{WM}=\mathbb{E}{\tau, \epsilon}\left\\left\\\| V_{\\phi}\\left(X_{t}\^{\\tau} \| o_{t}, MLP\\left(\\tilde{z}_{t}\^{a}\\right), \\tau\\right)-\\left(X_{t}-\\epsilon\\right)\\right\\\| _{2}\^{2}\\rightLWM=Eτ,ϵ∥Vϕ(Xtτ∣ot,MLP(z\~ta),τ)−(Xt−ϵ)∥22
其中z~ta=Ea(st,at:t+k)\tilde{z}{t}^{a}=E_a(s_t, a{t:t+k})z~ta=Ea(st,at:t+k)是UniT动作分支输出的连续预量化特征。
通俗解释:世界模型不再用机器人的原始关节动作作为控制信号,而是用统一的物理意图token。这样一来,你输入人类的动作,世界模型就能生成机器人执行这个动作的视频;输入机器人的动作,也能生成人类执行的视频。真正实现了跨体素的动力学转移。
四、实验结果:效果好到离谱
4.1 统一表示:人类和机器人终于"说同一种语言"了
作者用t-SNE可视化了不同层次的特征分布,结果非常震撼:
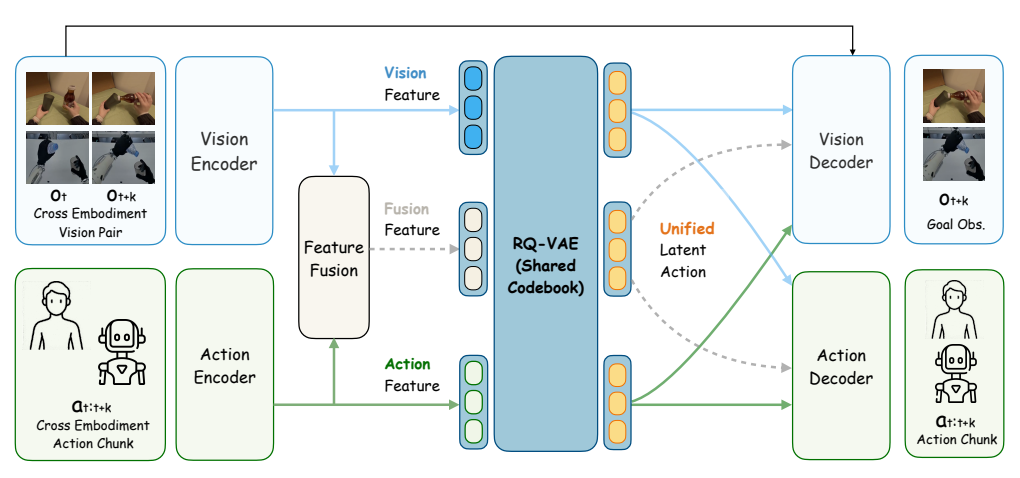
图3分析:
- 原始动作空间(a上):人类(蓝色)和机器人(黄色)的特征完全分开,没有任何重叠。
- UniT token空间(a下):人类和机器人的特征高度重叠,几乎分不清谁是谁。
- 下游VLA特征(b)和WM特征(c):用了UniT之后,下游模型的内部特征也跟着对齐了。
这说明UniT真的建立了一个人类和机器人共享的物理语言空间。
4.2 抗噪声能力:比纯动作分词器强10倍
真实世界的人类动作捕捉数据不可避免地有噪声(比如传感器抖动、标注错误)。作者测试了不同分词器在不同噪声水平下的重建质量:
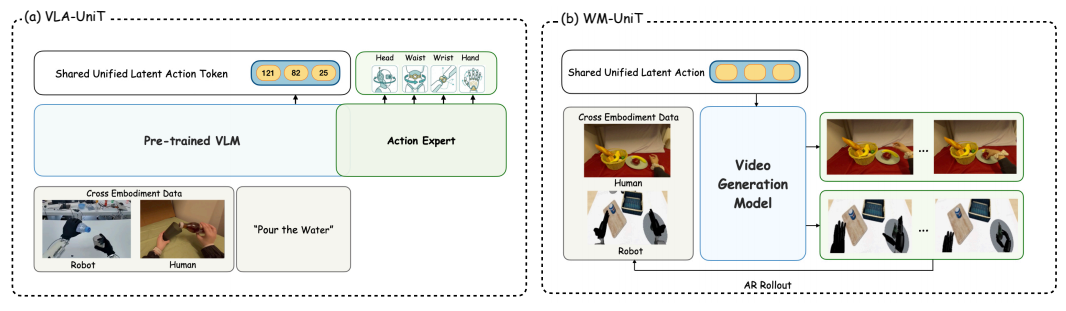
图4分析:当噪声水平σ=0.2时(相当于动作有20%的误差):
- FAST(纯动作分词器):性能退化10.7倍
- 动作-only分词器:性能退化2.7倍
- UniT:性能只退化1.7倍
这是因为UniT有视觉锚定。如果一个动作噪声没有对应的视觉变化,模型会自动把它过滤掉。这对于利用真实世界的嘈杂人类数据至关重要。
4.3 策略学习:数据效率提升10倍,零样本转移不是梦
在RoboCasa GR1仿真基准上,VLA-UniT取得了66.7%的整体成功率,比之前的SOTA FLARE高出11.7%,比GR00T基线高出18.9%。
更惊人的是数据效率:只用10%的训练数据(每个任务100条轨迹),VLA-UniT就能达到45.5%的成功率,已经接近用100%数据训练的GR00T基线(47.8%)。相当于数据效率提升了10倍。
零样本任务转移:机器人学会了人类的协调动作
作者测试了一个完全没有在机器人数据里见过的任务:堆叠碗。机器人训练数据里只有单个碗的拾取和放置,而人类数据里有堆叠的动作。
结果:
- GR00T基线:0%成功率
- VLA-UniT(无人类数据):10%成功率
- VLA-UniT(加人类数据):60%成功率
而且机器人还涌现出了人类特有的协调动作:腰部旋转和头部转动来调整视角,这在机器人训练数据里完全没有出现过。这说明UniT真的把人类的运动协调知识转移给了机器人。
4.4 世界建模:人类动作直接控制机器人视频生成
在可控视频生成任务上,WM-UniT全面优于原始动作和动作-only分词器:
表1 可控生成结果对比(来源:原文Table1)
| 数据集 | 方法 | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FVD ↓ | EPE ↓ |
|---|---|---|---|---|---|---|
| DROID | Raw Action | 21.02 | 0.820 | 0.097 | 76.38 | 0.2662 |
| WM-Action | 20.86 | 0.819 | 0.102 | 80.30 | 0.2593 | |
| WM-UniT | 21.32 | 0.823 | 0.095 | 76.44 | 0.2588 | |
| EgoDex+RoboCasa | Raw Action | 24.84 | 0.800 | 0.164 | 171.37 | 0.706 |
| WM-UniT | 28.06 | 0.858 | 0.086 | 130.87 | 0.519 |
表1分析:WM-UniT在所有指标上都优于基线,尤其是EPE(端点误差,衡量可控性)。在人类-机器人混合数据集上,WM-UniT的FVD降低了40.5,说明视频的真实感和可控性都有巨大提升。
更神奇的是跨体素条件生成:输入人类的动作序列,WM-UniT能生成机器人执行这个动作的视频;输入机器人的动作序列,也能生成人类执行的视频。而且能精确保留动作的语义、幅度和时间顺序,这是原始动作完全做不到的。
五、核心代码实现
下面是UniT分词器的核心实现,包含三分支编码、RQ-VAE量化和交叉重建损失:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from vector_quantize_pytorch import ResidualVQ
class UniTTokenizer(nn.Module):
def __init__(
self,
visual_dim=768, # DINOv2特征维度
action_dim=50, # 机器人动作维度
state_dim=50, # 机器人状态维度
latent_dim=256, # 潜变量维度
codebook_size=1024,# 码本大小
num_quantizers=4, # RQ-VAE量化层数
):
super().__init__()
# 1. 三分支编码器
self.visual_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=visual_dim, nhead=8, dim_feedforward=1024),
num_layers=2
)
self.visual_proj = nn.Linear(visual_dim, latent_dim)
self.action_encoder = nn.Sequential(
nn.Linear(action_dim + state_dim, 512),
nn.ReLU(),
nn.Linear(512, latent_dim)
)
self.fusion_encoder = nn.Sequential(
nn.Linear(latent_dim * 2, 512),
nn.ReLU(),
nn.Linear(512, latent_dim)
)
# 2. 共享RQ-VAE码本
self.rq = ResidualVQ(
dim=latent_dim,
codebook_size=codebook_size,
num_quantizers=num_quantizers
)
# 3. 解码器
self.visual_decoder = nn.Sequential(
nn.Linear(latent_dim + visual_dim, 512),
nn.ReLU(),
nn.Linear(512, visual_dim)
)
self.action_decoder = nn.Sequential(
nn.Linear(latent_dim + state_dim, 512),
nn.ReLU(),
nn.Linear(512, action_dim)
)
def forward(self, f_t, f_tk, s_t, a_tk):
"""
前向传播
Args:
f_t: 当前帧DINOv2特征 [B, D]
f_tk: k帧后DINOv2特征 [B, D]
s_t: 当前状态 [B, S]
a_tk: 动作块 [B, A]
Returns:
loss: 总损失
z: 量化后的潜变量
"""
# 视觉分支:编码两帧的视觉过渡
visual_feat = torch.cat([f_t, f_tk], dim=1) # [B, 2D]
visual_feat = self.visual_encoder(visual_feat.unsqueeze(1)).squeeze(1)
z_v = self.visual_proj(visual_feat)
# 动作分支:编码状态和动作
action_feat = torch.cat([s_t, a_tk], dim=1) # [B, S+A]
z_a = self.action_encoder(action_feat)
# 融合分支:融合视觉和动作
fusion_feat = torch.cat([z_v, z_a], dim=1) # [B, 2L]
z_m = self.fusion_encoder(fusion_feat)
# 共享量化
all_z = torch.stack([z_v, z_a, z_m], dim=1) # [B, 3, L]
quantized, _, commit_loss = self.rq(all_z)
z_v_q, z_a_q, z_m_q = quantized.unbind(dim=1)
# 交叉重建:每个量化特征都要解码视觉和动作
loss = 0.0
for z_q in [z_v_q, z_a_q, z_m_q]:
# 视觉重建
visual_input = torch.cat([z_q, f_t], dim=1)
f_pred = self.visual_decoder(visual_input)
loss += F.cosine_similarity(f_pred, f_tk, dim=-1).mean() * -1.0 # 余弦损失
# 动作重建
action_input = torch.cat([z_q, s_t], dim=1)
a_pred = self.action_decoder(action_input)
loss += F.mse_loss(a_pred, a_tk)
# 加上量化损失
loss += commit_loss.mean()
return loss, z_m_q # 融合分支的token用于下游任务六、结论与展望
UniT通过一个简单但极其有效的视觉锚定交叉重建机制,建立了人类和机器人共享的统一物理语言。它的核心贡献可以总结为三点:
- 统一分词器:首次实现了真正跨体素的潜动作表示,人类和机器人的动作能映射到同一个空间。
- VLA-UniT:大幅提升了人形机器人策略的数据效率和泛化能力,实现了零样本任务转移。
- WM-UniT:首次实现了跨体素的世界建模,人类动作能直接用来控制机器人视频生成。
未来,UniT有两个非常激动人心的方向:
- 无标注互联网视频预训练:视觉分支不需要成对的动作标注,这意味着我们可以用互联网上数十亿小时的无标注人类视频来预训练UniT,获取海量的物理常识。
- 策略与世界模型的闭环:策略提出统一潜动作,世界模型模拟其视觉后果,然后用模拟结果作为奖励信号来优化策略。这可能是实现通用人形机器人的关键路径。
UniT证明了:只要找到正确的"通用语言",人类积累的海量知识就能直接赋能机器人。这可能是人形机器人从"专用"走向"通用"的重要一步。