1. 数值稳定性


向量与向量之间的求导得到的就是矩阵;
所以上面求导完,再相乘就相当于d-t个矩阵相乘,会造成下面的问题

① MLP:多层感知机。
② 对角矩阵(diagonal matrix)是一个主对角线之外的元素皆为0的矩阵,常写为diag(a1, a2, ..., an)。
③ diag * W 把diag和W分开看。这就是个链式求导,diag是n维度的relu向量对n维度relu的输入的求导,向量对自身求导就是对角矩阵。

2. 梯度爆炸
① 当W元素值大于1时,层数很深时,连乘会导致梯度爆炸。


3. 梯度消失
① 蓝色为原函数,黄色为梯度函数。
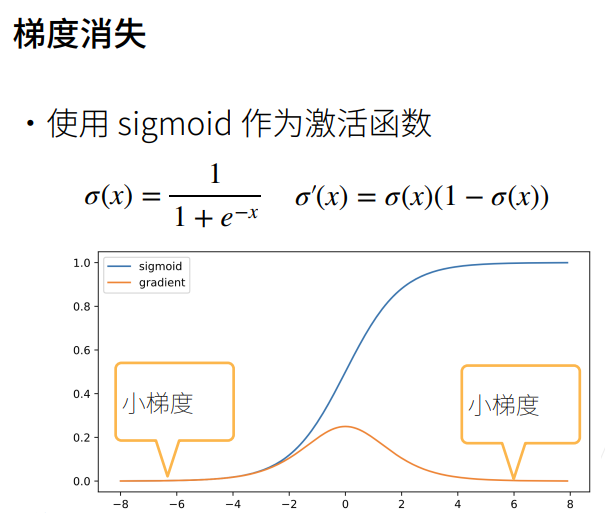
② 当激活函数的输入稍微大一点时,它的导数就变为接近0,连续n个接近0的数相乘,最后的梯度就接近0,梯度就消失了。


4. 总结

1. 训练更稳定



让每一层都保证:均值为0,方差为常数

① 假设权重是独立的同分布,均值为0。
② 假设输入与权重是相互独立的。
"w_i_j^t 是i.i.d"意味着w_i_j这个元素同其他元素(如w_a_b)没有任何依赖关系 是独立存在的。以简化计算和推理
h(t-1,i)表示第t-1层网络的第i个神经元的输出,也就是第t层网络的输入
w(t, i, j)表示第t层网络的第i个神经元的第j个特征的权重




如果想要使均值为0,就要使
这个式子为0,但由于ahi为上一层的,均值为0,所以这一层只需保证β为0就可以了。
如果要使方差为常数,
就要使该式子中的左边=右边,所以阿发为1.
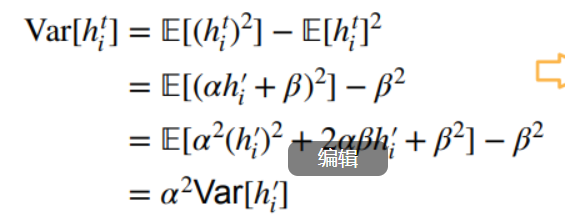


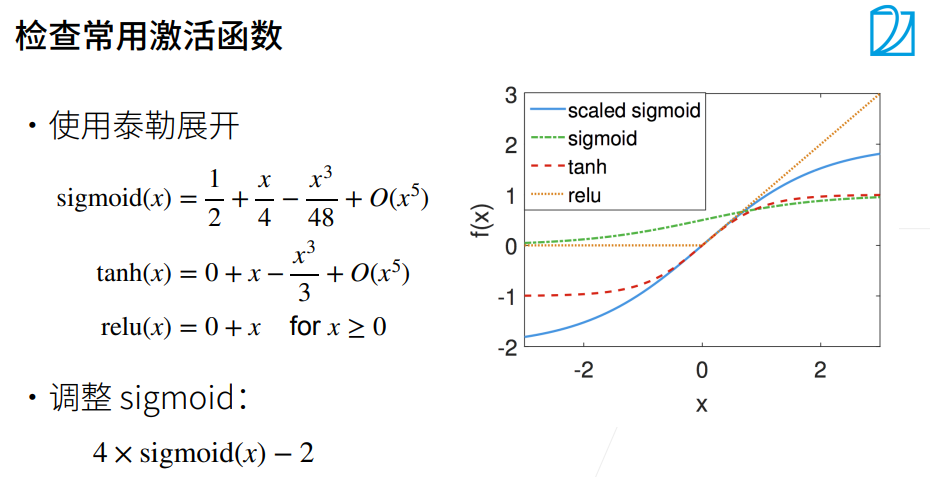
如果使用tanh(x),relu(x),他们在0点附近比较符合标准,贴合函数
但是sigmoid(x)不贴合,所以要调整这个函数
2. 总结
