前面简单介绍了知识图谱:知识图谱入门-CSDN博客
如何在Windows中安装Neo4j:Windows 安装 Neo4j(2025最新·极简)-CSDN博客
基于前面的基础,现在一起来学习一个简单的小案例,走通从构建结构化数据 → 将数据构建成节点表,关系表 → 导入到Neo4j中进行图形绘制和编写Cypher语句回答问题的整个流程。
目录
[1. 项目介绍](#1. 项目介绍)
[2. 下载项目](#2. 下载项目)
[3. 知识图谱构建](#3. 知识图谱构建)
[3.1 知识抽取](#3.1 知识抽取)
[3.2 知识融合](#3.2 知识融合)
[3.3 知识存储](#3.3 知识存储)
[任务1:准备 CSV 文件](#任务1:准备 CSV 文件)
[任务4:重启 neo4j 服务](#任务4:重启 neo4j 服务)
1. 项目介绍
stock-knowledge-graph项目是开源的中文 A 股投资研究知识图谱,目的是找出值得买、卖的"投资标的",并给出合理的价位或者时机。适合零基础快速体验知识图谱构建全流程。
2. 下载项目
项目来源: https://github.com/lemonhu/stock-knowledge-graph
进入链接,点击 Code -> Download ZIP,解压后用 Pycharm 打开项目,配置环境并安装依赖(这里不做过多讲解,不会的同学可以找一个学习链接)。该项目的依赖在 requirements.txt 中,包括
-
HTML/XML处理库--lxml
-
数据分析库--pandas
-
超文本解析库--beautifulsoup4
-
金融数据接口库--tushare
在 PyCharm 底部打开 Terminal,执行下面命令:
bash
pip install -r requirements.txt
个人喜欢这种解压缩包的方式,大家也可以直接用git通过链接在 Pycharm 中拉取项目。
目录工程结构:
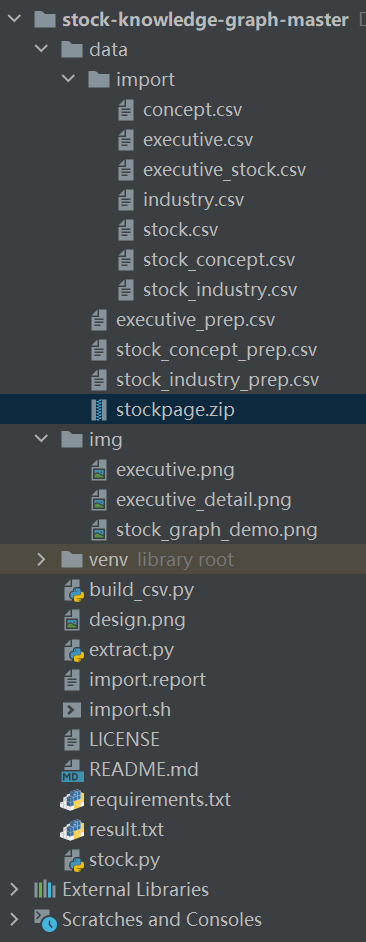
1、所有数据都存放在 data 文件夹:
stockpage.zip:同花顺董事页面 html 文件。
**结构化数据:**分别从 stockpage.zip 中爬取的董事人员信息表executive_prep.csv、股票行业信息表 stock_industry_prep.csv、股票信息表 stock_concept_prep.csv。
import 文件夹:分别存放从上面三个信息表中提取出来的
4个实体表("人"实体表executive.csv、概念实体表 concept.csv、行业实体表 industry.csv、公司实体表 stock.csv)
3个实体之间的关系表(人和公司关系表 executive_srock.csv 、公司和概念关系表 stock_concept.csv、公司和行业关系表 stock_industry.csv)
2、项目中的代码文件:
**extract.py:**把同花顺董事页面批量解析成结构化的csv。
**stock.py :**调取 Tushare 的证监会行业分类接口和同花顺概念分类接口。
**build_csv.py :**构建 4 个实体表 和 3 个关系表。
3. 知识图谱构建
3.1 知识抽取
前面说知识抽取就是从非结构化或半结构化的文本中抽取实体、关系和属性。那么我们得分析一下要抓取什么信息才能得到我们需要的实体,从而去分析他的关系和属性。
知识图谱要解决什么问题?
可以查询出"这家公司董事长是谁,炒什么题材,同行是谁?"
提问:
某公司的董事长是谁?
张三同时在哪些公式任独立董事?
同行业董事长平均年龄?
某公司属于哪些概念(标签)?
某概念下有多少家公司?
所有严重亏损(ST)的公司名单?
同行公司列表?
"张三"任职的 ST 公司属于哪些概念?
**总结:**任何人,公司,行业,概念,ST,只要1条查询就能拉出来关联网络。
注:
**"概念"**是一群股票被贴上同一个故事标签,例如,所有做电池材料,电芯,设备的公司都属于"锂电池概念"。
**"ST"**标记公司为严重亏损状态。
**"行业"**以核心业务为准,例如,新能源汽车行业比亚迪。
任务1:从网页中抽取董事会的信息
项目的 /data/stockpage/stockpage.zip中存放的是 同花顺董事页面 html。
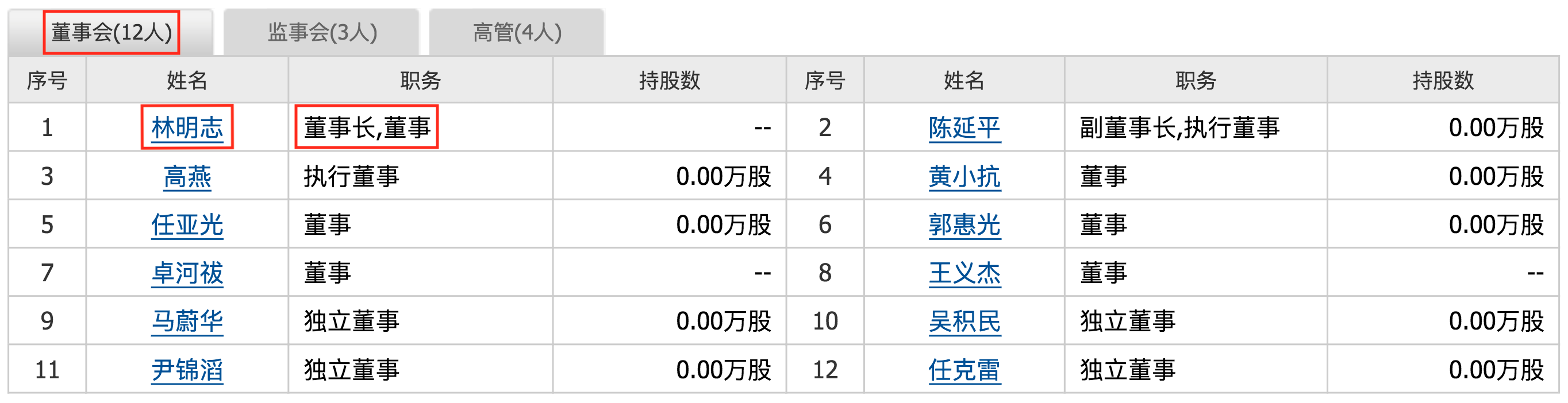
现在抽取每一个公司/股票的董事会成员信息,包括董事会成员的"姓名","职务","性别","年龄"共四个字段。
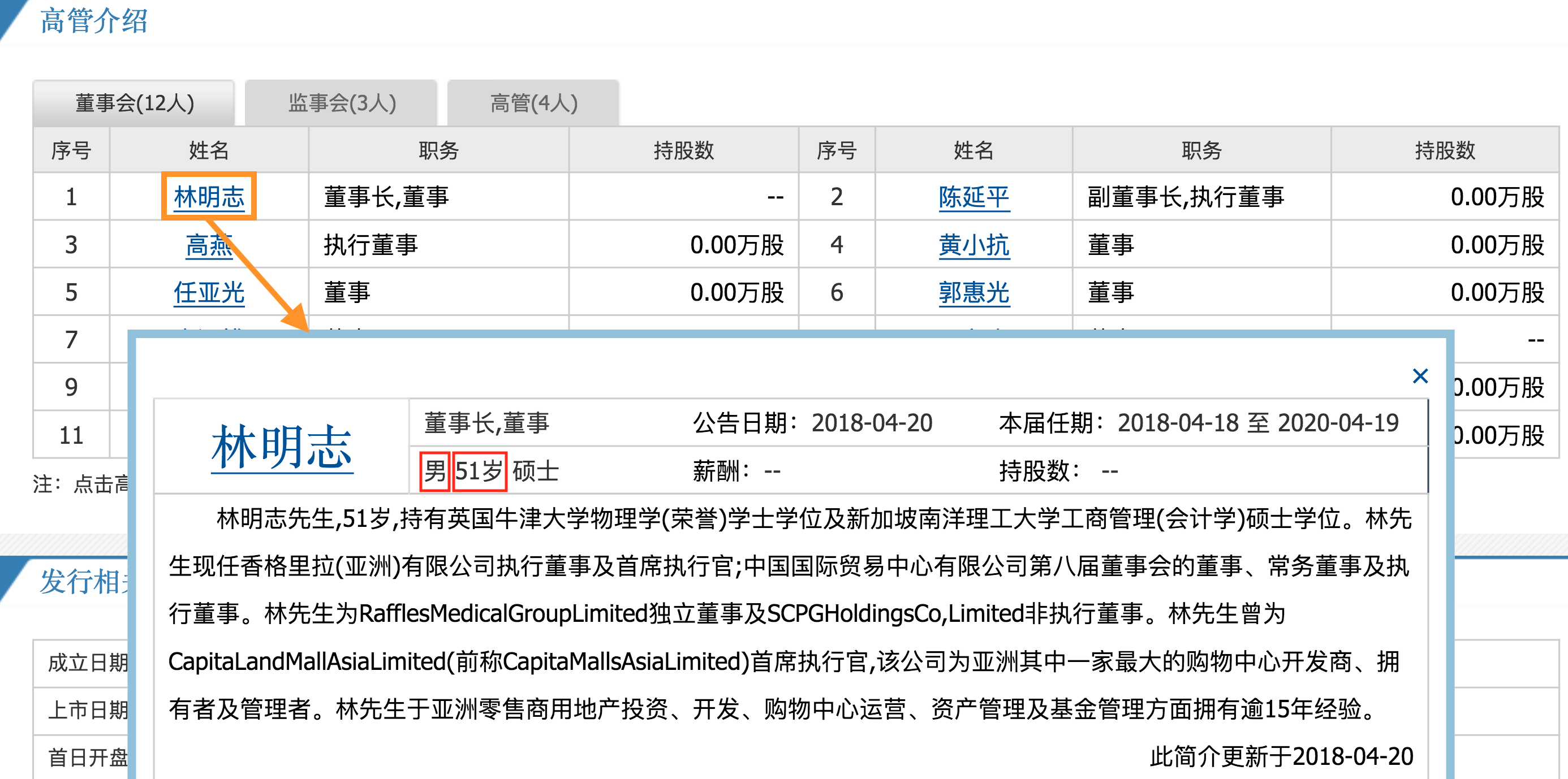
代码文件为 extract.py,主要是一个网页解析脚本,把"同花顺个股董事页面" html 批量读进来,提取每位高管的姓名、性别、年龄、职位,并写入csv,为后续建知识图谱提供"人-公司-任职"原始数据。
python
# -*- coding: utf-8 -*-
import os # 遍历文件夹
import csv # 写 CSV 文件
from lxml import etree # 解析 HTML 网页
def extract(stockpage_dir, executive_csv):
"""把同花顺董事页面 HTML 批量解析成结构化 CSV
Args:
stockpage_dir: 存放 html 的目录
executive_csv: 输出 csv 完整路径
"""
# 1. 拿到目录下所有 html 文件全路径,并过滤非 html
pages = map(lambda _: os.path.join(stockpage_dir, _), os.listdir(stockpage_dir))
pages = filter(lambda _: _.endswith('html'), pages)
# 2. 定义输出字段,必须与后续 Neo4j 导入一致
headers = ['name', 'gender', 'age', 'code', 'jobs']
# 3. 打开输出文件,用 DictWriter 按字段写行
with open(executive_csv, 'w', encoding='utf-8') as file_directors:
file_directors_csv = csv.DictWriter(file_directors, headers)
file_directors_csv.writeheader() # 写表头
# 4. 逐个 html 文件处理
for page in pages:
print(page) # 调试:看当前处理哪个文件
file_name = page.split(r'/')[-1] # 取文件名 000001.html
code = file_name.split('.')[0] # 股票代码 = 000001(后续作节点 ID)
executives = [] # 当前文件所有董事列表
# 5. 读 HTML 并解析
with open(page, 'r', encoding='gbk') as file_page:
content = file_page.read()
html = etree.HTML(content) # lxml 解析成 DOM 树
# 6. XPath 定位每个董事卡片(同花顺固定结构)
divs = html.xpath('//div[@id="ml_001"]//div[contains(@class, "person_table")]')
for div in divs:
item = {} # 单条董事字典
# 7. 提取姓名(在 h3>a 标签内)
item['name'] = div.xpath('.//thead/tr/td/h3/a/text()')[0].replace(',', '-')
# 8. 提取职位(thead 第 1 行第 2 列)
item['jobs'] = div.xpath('.//thead/tr[1]/td[2]/text()')[0].replace(',', '/')
# 9. 性别、年龄、学历在同一行,先 split
gender_age_education = div.xpath('.//thead/tr[2]/td[1]/text()')[0].split()
# 10. 性别在第 1 段,且只能是男/女,否则记 null
try:
item['gender'] = gender_age_education[0]
if item['gender'] not in ('男', '女'):
item['gender'] = 'null'
except IndexError:
item['gender'] = 'null'
# 11. 年龄在第 2 段,去掉"岁"字并转 int;失败记 -1
try:
item['age'] = gender_age_education[1].strip('岁')
try:
item['age'] = int(item['age'])
except ValueError:
item['age'] = -1
except IndexError:
item['age'] = -1
# 12. 把当前股票代码写进这条记录
item['code'] = code
executives.append(item) # 加入当前文件列表
# 13. 当前 html 所有董事一次性写进 CSV
file_directors_csv.writerows(executives)
# 14. 脚本入口,指定输入输出路径
if __name__ == '__main__':
stockpage_dir = './data/stockpage' # HTML 目录
executive_csv = './data/executive_prep.csv' # 输出宽表
extract(stockpage_dir, executive_csv)最后生成一个executive_prep.csv文件,格式如下:
| name | gender | age | code(股票代码) | jobs |
|---|---|---|---|---|
| 杜玉岱 | 男 | 58 | 601058 | 董事长/董事 |
| 延万华 | 男 | 45 | 601058 | 副董事长/董事 |

任务2:获取股票行业和概念的信息
股票行业和概念上面已做介绍,该项目利⽤工具Tushare获取这部分信息,官网为http://tushare.org/,使用pip命令进行安装即可。
python
pip install tushare下载完之后,在python里即可调用股票行业和概念信息。参考链接:http://tushare.org/classifying.html#id2,通过 stock.py 代码获得股票行业信息 和股票概念信息。
python
import tushare as ts
# 获得并保存股票行业信息
df_industry = ts.get_industry_classified()
df_industry.to_csv("./data/stock_industry_prep.csv", index=False, sep=',')
# 获得并保存股票概念信息
df_concept = ts.get_concept_classified()
df_concept.to_csv("./data/stock_concept_prep.csv", index=False, sep=',')并把返回的信息分别存储在stock_industry_prep.csv文件和stock_concept_prep.csv文件里。格式如下:
股票行业信息 stock_industry_prep.csv
| code | name | c_name |
|---|---|---|
| 600051 | 宁波联合 | 综合行业 |
| 600209 | 罗顿发展 | 综合行业 |
| 600132 | 江泉实业 | 综合行业 |
股票概念信息stock_concept_prep.csv
| code | name | c_name |
|---|---|---|
| 600007 | 中国国贸 | 外资背景 |
| 600114 | 东睦股份 | 外资背景 |
| 600132 | 重庆啤酒 | 外资背景 |
任务3:设计知识图谱
前面说过,我们可以根据提问去设计知识图谱,下面是实体和关系的设计。
实体:
创建"人"实体,这个人拥有姓名、性别、年龄
创建"公司"实体,除了股票代码,还有股票名称
创建"概念"实体,每个概念都有概念名
创建"行业"实体,每个行业都有⾏业名
给"公司"实体添加"ST"的标记,这个由LABEL来实现
关系:
创建"人"和"公司"的关系,这个关系有董事长、执行董事等等
创建"公司"和"概念"的关系
创建"公司"和"行业"的关系
把设计图存储为design.png文件。
**注:**实体名字和关系名字需要易懂,对于上述的要求,并不一定存在唯一的设计,只要能够覆盖上面这些要求即可。"ST"标记是⽤用来刻画⼀个股票严重亏损的状态,这个可以从给定的股票名字前缀来判断,背景知识可参考百科ST股票,"ST"股票对应列表为'\*ST', 'ST', 'S\*ST', 'SST'。
用 build_csv.py 代码获取实体和关系表:
python
# -*- coding: utf-8 -*-
import os # 遍历文件夹
import csv # 读写 CSV
import hashlib # 生成 MD5,用作 Neo4j 唯一 ID
def get_md5(string):
"""根据任意字符串生成 32 位 MD5,用来当 Neo4j 的 :ID"""
byte_string = string.encode("utf-8")
md5 = hashlib.md5()
md5.update(byte_string)
return md5.hexdigest() # 返回 32 位小写十六进制
def build_executive(executive_prep, executive_import):
"""把 executive_prep.csv → Neo4j 节点文件 executive.csv
格式要求:person_id:ID,name,gender,age:int,:LABEL
LABEL 统一为 Person
"""
print('Writing to {} file...'.format(executive_import.split('/')[-1]))
# 同时打开源文件和目标文件
with open(executive_prep, 'r', encoding='utf-8') as file_prep, \
open(executive_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
# 写 Neo4j bulk-import 要求的表头
headers = ['person_id:ID', 'name', 'gender', 'age:int', ':LABEL']
file_import_csv.writerow(headers)
for i, row in enumerate(file_prep_csv):
if i == 0 or len(row) < 3: # 跳过表头或残缺行
continue
# 取姓名、性别、年龄
info = [row[0], row[1], row[2]]
# 用"姓名,性别,年龄"拼字符串 → MD5 → 全局唯一 ID
info_id = get_md5('{},{},{}'.format(row[0], row[1], row[2]))
info.insert(0, info_id) # 插到最前面
info.append('Person') # 加 Label
file_import_csv.writerow(info)
print('- done.')
def build_stock(stock_industry_prep, stock_concept_prep, stock_import):
"""把行业+概念两个 CSV → Neo4j 节点文件 stock.csv
格式:stock_id:ID,name,code,:LABEL
LABEL 默认 Company;若股票名以 ST/S*ST 等开头 → Company;ST
"""
print('Writing to {} file...'.format(stock_import.split('/')[-1]))
stock = set() # 用 set 去重:'code,name'
# 先读行业文件,加入 set
with open(stock_industry_prep, 'r', encoding='utf-8') as file_prep:
file_prep_csv = csv.reader(file_prep, delimiter=',')
for i, row in enumerate(file_prep_csv):
if i == 0: continue
code_name = '{},{}'.format(row[0], row[1].replace(' ', ''))
stock.add(code_name)
# 再读概念文件,加入 set(已去重)
with open(stock_concept_prep, 'r', encoding='utf-8') as file_prep:
file_prep_csv = csv.reader(file_prep, delimiter=',')
for i, row in enumerate(file_prep_csv):
if i == 0: continue
code_name = '{},{}'.format(row[0], row[1].replace(' ', ''))
stock.add(code_name)
# 写 Neo4j 节点文件
with open(stock_import, 'w', encoding='utf-8') as file_import:
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['stock_id:ID', 'name', 'code', ':LABEL']
file_import_csv.writerow(headers)
for s in stock:
split = s.split(',')
ST = False
states = ['*ST', 'ST', 'S*ST', 'SST']
info = []
# 只要股票名以 ST 前缀开头 → 加 Company;ST 双 Label
for state in states:
if split[1].startswith(state):
ST = True
split[1] = split[1].replace(state, '') # 去掉前缀
info = [split[0], split[1], split[0], 'Company;ST']
break
if not ST:
info = [split[0], split[1], split[0], 'Company']
file_import_csv.writerow(info)
print('- done.')
def build_concept(stock_concept_prep, concept_import):
"""把概念 CSV → Neo4j 节点文件 concept.csv
格式:concept_id:ID,name,:LABEL LABEL=Concept
"""
print('Writing to {} file...'.format(concept_import.split('/')[-1]))
with open(stock_concept_prep, 'r', encoding='utf-8') as file_prep, \
open(concept_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['concept_id:ID', 'name', ':LABEL']
file_import_csv.writerow(headers)
concepts = set() # 去重概念名
for i, row in enumerate(file_prep_csv):
if i == 0: continue
concepts.add(row[2]) # 第 3 列是概念名
for concept in concepts:
concept_id = get_md5(concept) # MD5 当 ID
new_row = [concept_id, concept, 'Concept']
file_import_csv.writerow(new_row)
print('- done.')
def build_industry(stock_industry_prep, industry_import):
"""把行业 CSV → Neo4j 节点文件 industry.csv
格式:industry_id:ID,name,:LABEL LABEL=Industry
"""
print('Write to {} file...'.format(industry_import.split('/')[-1]))
with open(stock_industry_prep, 'r', encoding="utf-8") as file_prep, \
open(industry_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['industry_id:ID', 'name', ':LABEL']
file_import_csv.writerow(headers)
industries = set()
for i, row in enumerate(file_prep_csv):
if i == 0: continue
industries.add(row[2]) # 第 3 列是行业名
for industry in industries:
industry_id = get_md5(industry)
new_row = [industry_id, industry, 'Industry']
file_import_csv.writerow(new_row)
print('- done.')
def build_executive_stock(executive_prep, relation_import):
"""生成关系文件 executive_stock.csv
格式::START_ID,jobs,:END_ID,:TYPE
START_ID = 人(MD5),END_ID = 股票代码,TYPE = employ_of
"""
with open(executive_prep, 'r', encoding='utf-8') as file_prep, \
open(relation_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = [':START_ID', 'jobs', ':END_ID', ':TYPE']
file_import_csv.writerow(headers)
for i, row in enumerate(file_prep_csv):
if i == 0: continue
# 人 ID = MD5(姓名,性别,年龄)
start_id = get_md5('{},{},{}'.format(row[0], row[1], row[2]))
end_id = row[3] # 股票代码
relation = [start_id, row[4], end_id, 'employ_of']
file_import_csv.writerow(relation)
def build_stock_industry(stock_industry_prep, relation_import):
"""生成关系文件 stock_industry.csv
格式::START_ID,:END_ID,:TYPE
START_ID = 股票代码,END_ID = 行业 MD5,TYPE = industry_of
"""
with open(stock_industry_prep, 'r', encoding='utf-8') as file_prep, \
open(relation_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = [':START_ID', ':END_ID', ':TYPE']
file_import_csv.writerow(headers)
for i, row in enumerate(file_prep_csv):
if i == 0: continue
industry = row[2] # 行业名
start_id = row[0] # 股票代码
end_id = get_md5(industry) # 行业 MD5
relation = [start_id, end_id, 'industry_of']
file_import_csv.writerow(relation)
def build_stock_concept(stock_concept_prep, relation_import):
"""生成关系文件 stock_concept.csv
格式::START_ID,:END_ID,:TYPE
START_ID = 股票代码,END_ID = 概念 MD5,TYPE = concept_of
"""
with open(stock_concept_prep, 'r', encoding='utf-8') as file_prep, \
open(relation_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = [':START_ID', ':END_ID', ':TYPE']
file_import_csv.writerow(headers)
for i, row in enumerate(file_prep_csv):
if i == 0: continue
concept = row[2] # 概念名
start_id = row[0] # 股票代码
end_id = get_md5(concept)
relation = [start_id, end_id, 'concept_of']
file_import_csv.writerow(relation)
# 14. 主函数:一次生成 7 个 Neo4j bulk-import 文件
if __name__ == '__main__':
import_path = 'data/import'
if not os.path.exists(import_path):
os.makedirs(import_path) # 自动建 output 目录
# 依次生成节点文件
build_executive('data/executive_prep.csv', 'data/import/executive.csv')
build_stock('data/stock_industry_prep.csv', 'data/stock_concept_prep.csv',
'data/import/stock.csv')
build_concept('data/stock_concept_prep.csv', 'data/import/concept.csv')
build_industry('data/stock_industry_prep.csv', 'data/import/industry.csv')
# 生成关系文件
build_executive_stock('data/executive_prep.csv', 'data/import/executive_stock.csv')
build_stock_industry('data/stock_industry_prep.csv', 'data/import/stock_industry.csv')
build_stock_concept('data/stock_concept_prep.csv', 'data/import/stock_concept.csv')最后生成的节点文件和关系文件存放在 \data\import\ 文件夹下面。
3.2 知识融合
该项目非常轻量级别,属于 规则式融合 ,而不是(字符串相似度、别名对齐、外部知识库映射)等机器学习或者复杂算法融合。
该项目主要将同一数据集去重、ST前缀清洗、Md5生成ID,没有对齐、MERGE导入图级去重。
3.3 知识存储
使用图数据库(Neo4j)存储知识图谱。这里的操作可以参考Neo4j官方导入数据 -作手册。
任务1:准备 CSV 文件
前面代码已经生成需要的 csv 文件,现将 7 个csv文件(节点表和关系表)放入Neo4j安装路径下面和bin同级的import目录。
节点和关系表格式规范:导入Neo4j 数据库的 节点表和关系表有固定要求的格式。
(1)节点表必须有一个 :ID 和一个标签 :LABEL,还可以添加 节点实体的 其他属性,例如 executive.csv 人实体表,格式包括(ID,姓名,性别,年龄,标签)
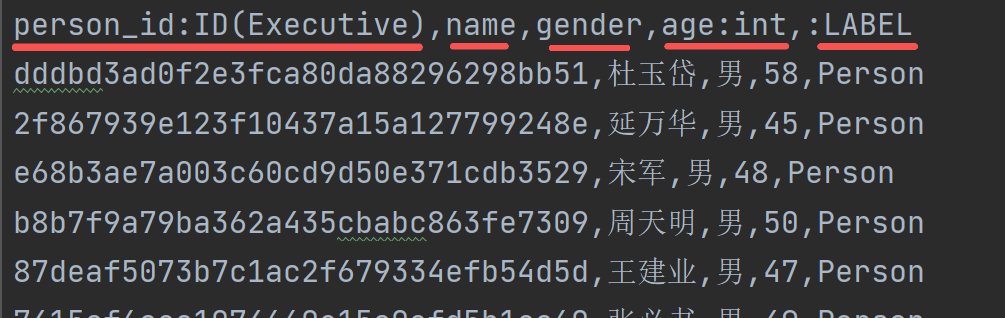
其中,ID用于在关系文件中查找和连接节点。为了确保跨文件ID的唯一性,可以指定ID所属的组,例如 :ID(Executive),添加字段名称方便理解该列的作用,例如,person_id:ID(Executive)。
(2)关系数据有三个必填字段:
-
:START_ID------ ID 指的是一个节点(起始节点)。 -
:END_ID------ ID 指的是一个节点(结束节点)。 -
:TYPE------关系类型。
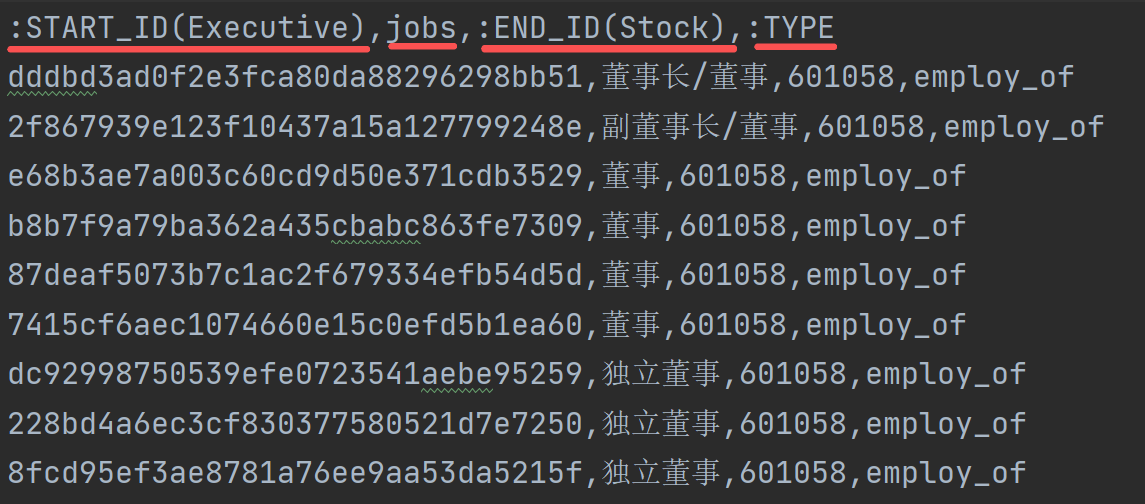
executive_stock.csv文件建立的是 人实体(Executive)和公司实体(Stock)的关系表。
任务2:停止Neo4j服务
导入前,必须停止Neo4j服务。在 cmd 命令行中执行以下命令:
bash
neo4j stop
任务3:执行导入命令
在cmd 命令行中进入Neo4j的bin目录,然后运行格式正确的 **import **命令。
import 命令为:
bash
neo4j-admin database import full neo4j --verbose --overwrite-destination --nodes=import/concept.csv --nodes=import/executive.csv --nodes=import/industry.csv --nodes=import/stock.csv --relationships=import/executive_stock.csv --relationships=import/stock_concept.csv --relationships=import/stock_industry.csv断行的写法如下,其中第一行最后的 neo4j 指的是你要导入的数据库,该数据库必须为空。
bash
neo4j-admin database import full neo4j ^
--verbose ^
--overwrite-destination ^
--nodes=import/concept.csv ^
--nodes=import/executive.csv ^
--nodes=import/industry.csv ^
--nodes=import/stock.csv ^
--relationships=import/executive_stock.csv ^
--relationships=import/stock_concept.csv ^
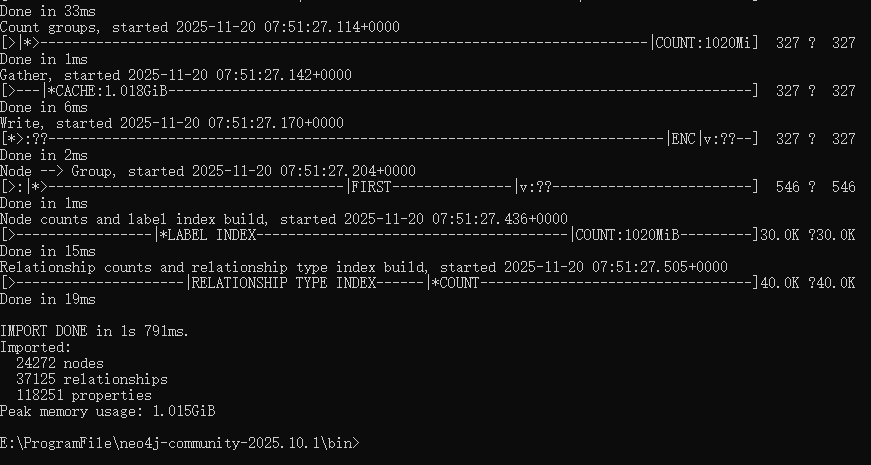
--relationships=import/stock_industry.csv导入成功后:
注意:import 命令只能将数据导入到一个全新的、空的目标数据库。如果指定的数据库已存在,导入会失败,物理删除数据库的方法比如我现在要导入的数据库名字为 neo4j,则可以依次执行:
bash# 从 bin 目录退到 neo4j 的安装目录 cd.. # 进入数据目录 cd data/databases/ # 删除数据库文件夹(请将 `neo4j` 替换为您的实际数据库名) rmdir /s neo4j # 同时建议删除对应的事务日志文件夹 rmdir /s ..\transactions\neo4j\进入 neo4j 安装目录下的 data\databases\ 目录,删除 neo4j 数据库,同时进入\data\transactions\ 目录下删除 neo4j 事务日志文件。运行效果如下:


任务4:重启 neo4j 服务
bash
neo4j start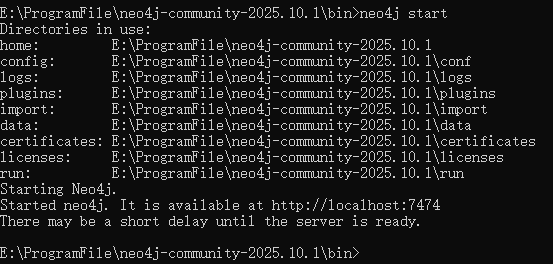
任务5:查询
从链接Neo4j Browser进入neo4j 数据库界面,输入账户和密码进入 browser 。
(1)依次输入简单查询命令
sql
# 查询node
MATCH (n:Concept) RETURN n LIMIT 25
# 查询relationship
MATCH p=()-[r:industry_of]->() RETURN p LIMIT 100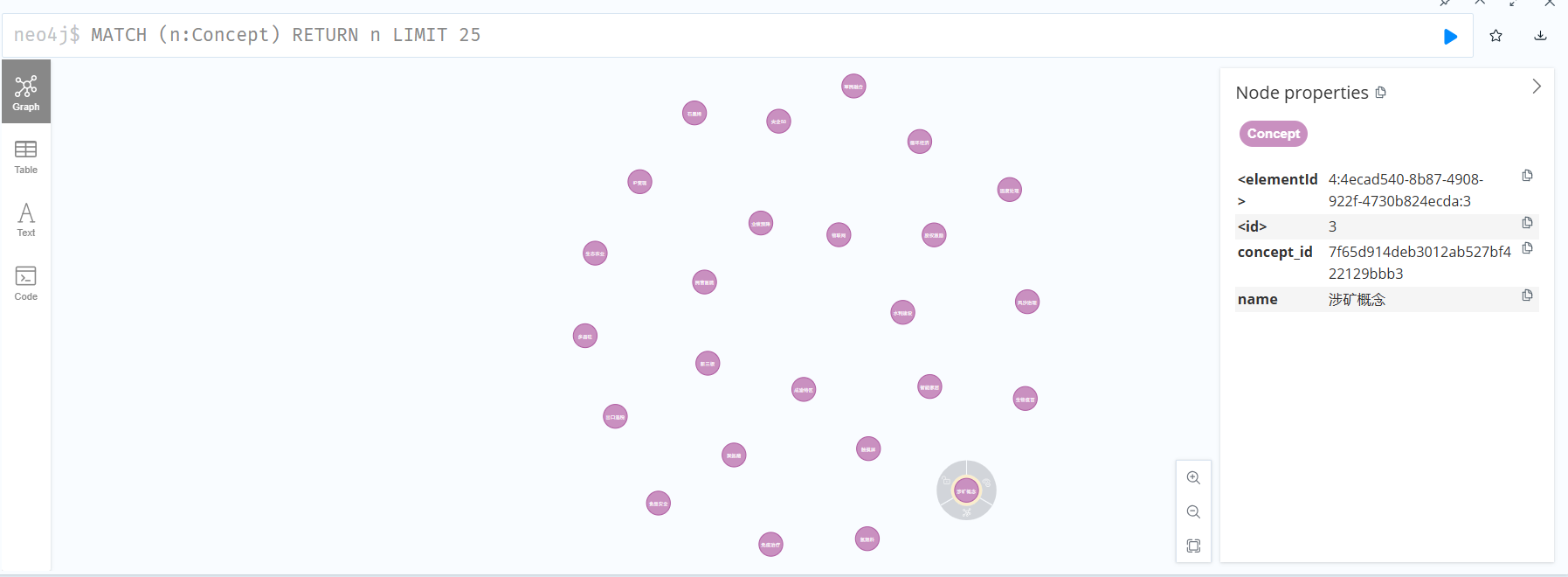
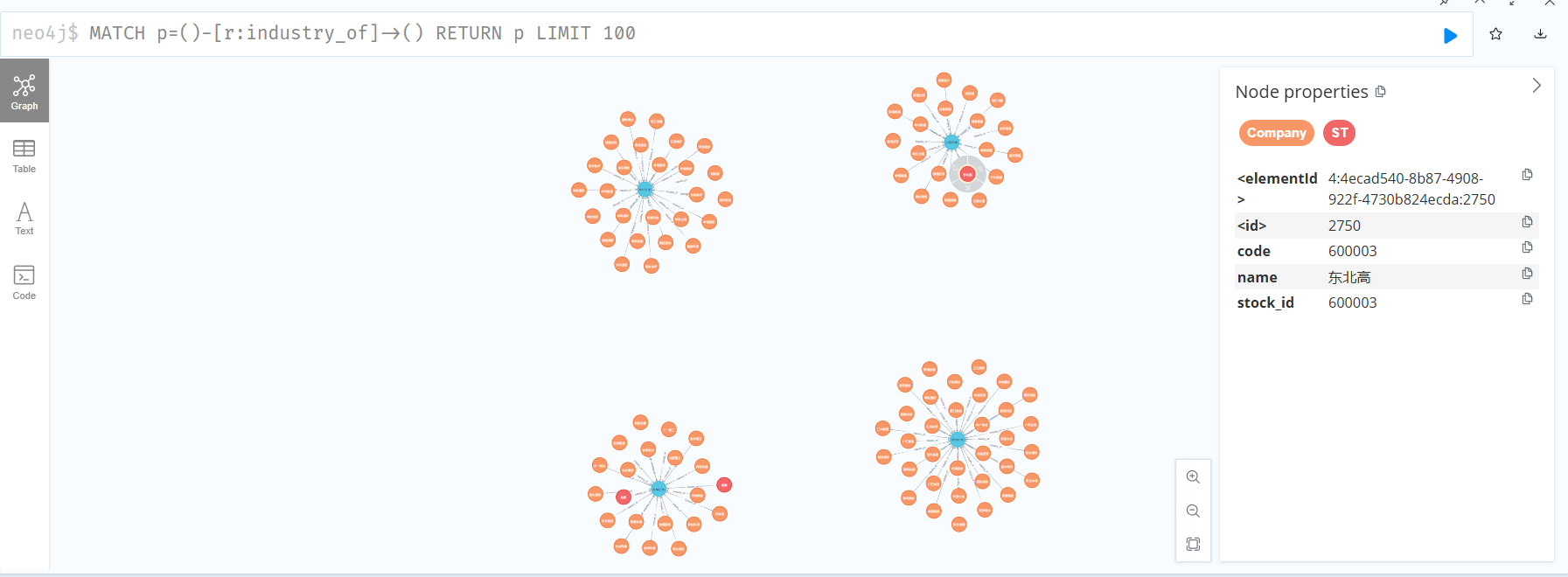
(2)编写Cypher 语句回答如下问题
1.有多少个公司目前是属于"ST"类型的?
sql
match (n:ST) return count(distinct(n))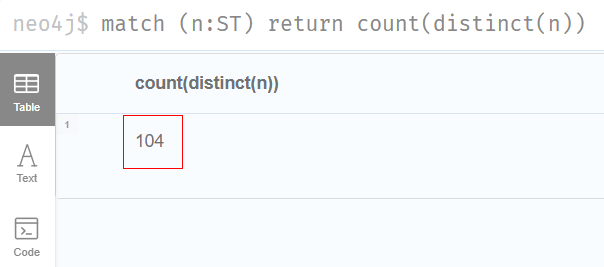
2."600519"公司的所有独立董事人员中,有多少人同时也担任别的公司的独立董事职位?
sql
MATCH (m:Company{code:'600519'})<-[:employ_of{jobs:'独立董事'}]-(n:Person)-[:employ_of{jobs:'独立董事'}]->(q:Company)
RETURN count(distinct(n))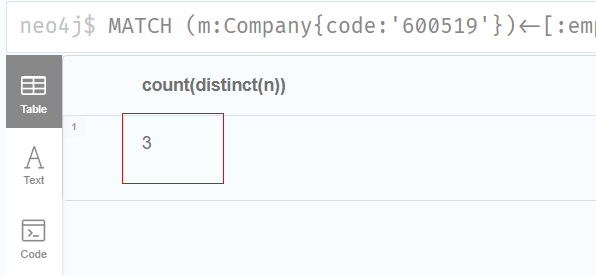
3.有多少公司既属于环保行业,又有外资背景?
sql
MATCH (:Concept{name:'外资背景'})<-[:concept_of]-(m:Company)-[:industry_of]-(:Industry{name:'环保行业'})
RETURN count(distinct(m))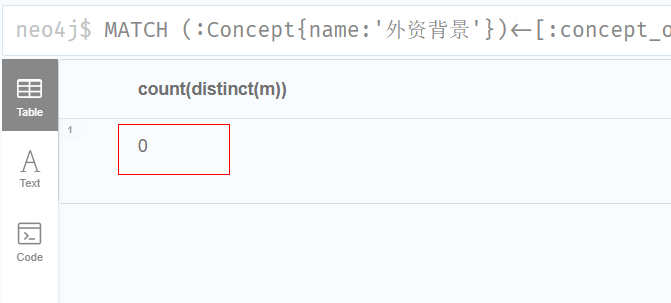
4.对于有锂电池概念的所有公司,独立董事中女性人员比例是多少?
sql
MATCH (m:Concept{name:'锂电池'})<-[:concept_of]-(n:Company)<-[:employ_of{jobs:'独立董事'}]-(p:Person{gender:'女'})
MATCH (m:Concept{name:'锂电池'})<-[:concept_of]-(n:Company)<-[:employ_of{jobs:'独立董事'}]-(p2:Person)
RETURN count(distinct(p))*1.0/count(distinct(p2))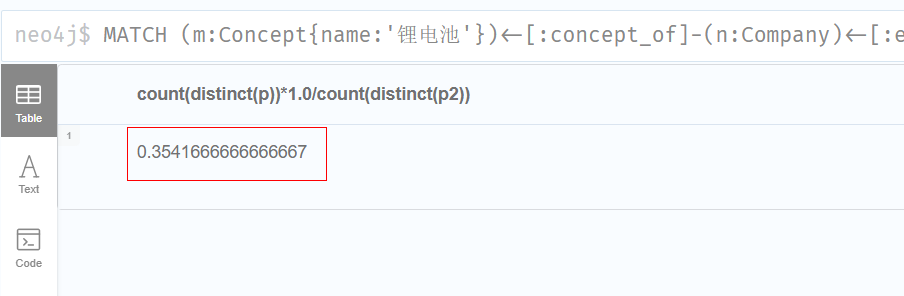
4.问题
构建人的实体时,重名问题具体怎么解决?
(1) 最好的方式是用身份证或者其他唯一能确定人的方式去关联。
(2) 在本例中,我用 姓名、年龄、性别3个字段做唯一的,将这3个字段做md5。