https://blog.csdn.net/qq_41822101/article/details/137688484
之前介绍了TensorRT部署ONNX模型,发现我的模型比较特殊(实现的太烂了 ),使用TensorRT推理不能得到正确的结果,使用ORT部署成功了,因此分享一下ORT的部署过程。
〇、 准备工作
-
老生常谈的安装 CUDA Toolkit 和 cuDNN
-
安装 ONNX Runtime
先给一个官网地址: ORT官网,官网的C++安装方式好像是针对.Net项目的(反正我是没看懂 )。所以这里简单介绍一下怎么安装,有两种方法:
a. 下载仓库编译好的ORT库(推荐)
仓库编译好的ORT库有系统版本与CPU和GPU版本区分注意选择自己需要的,ORT下载地址。
同时注意ORT所支持的CUDA和cuDNN版本,见CUDA支持官方文档。
我的 CUDA Toolkit 是12.1,cuDNN是8.9.7,因此选用1.17版本ORT。
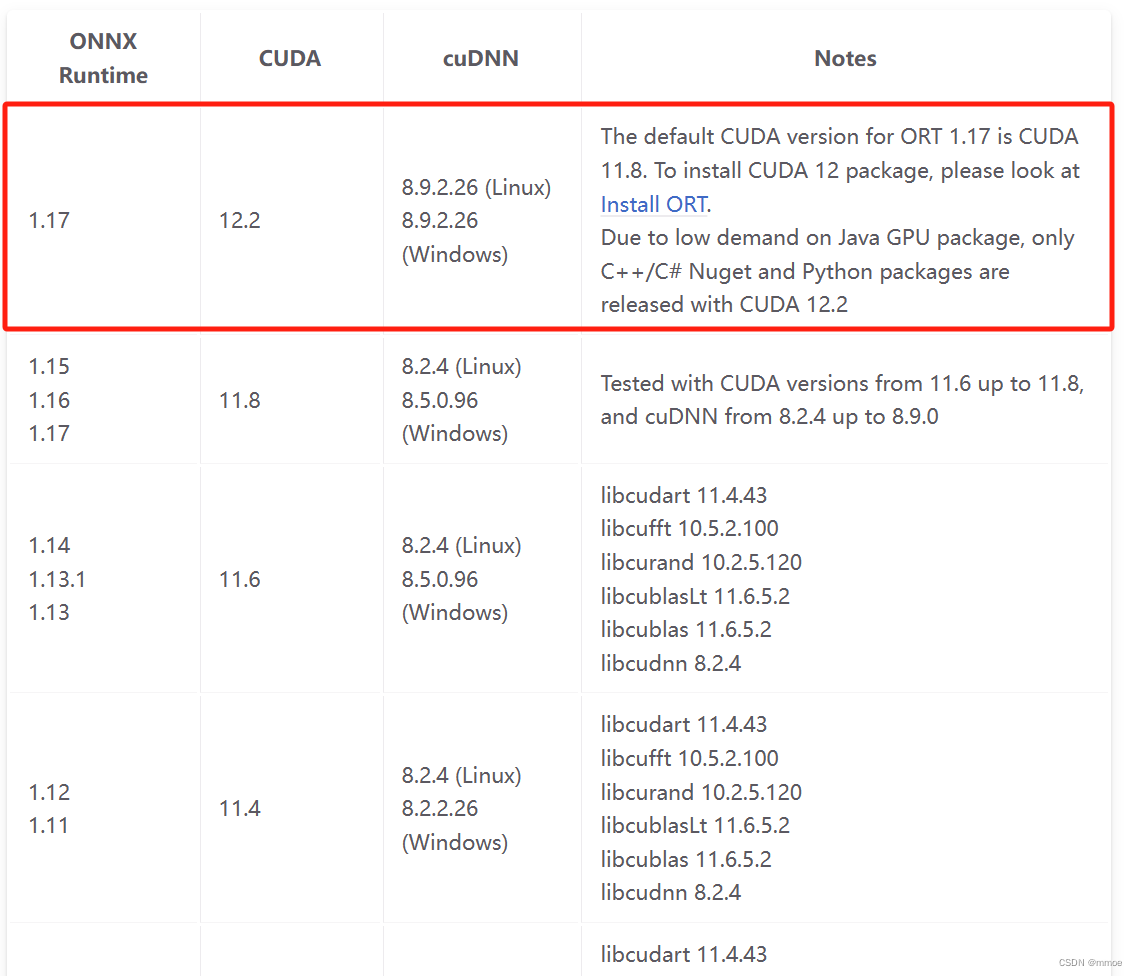
我需要使用GPU版本ORT,并且我的CUDA版本是12.1因此选择以下文件。
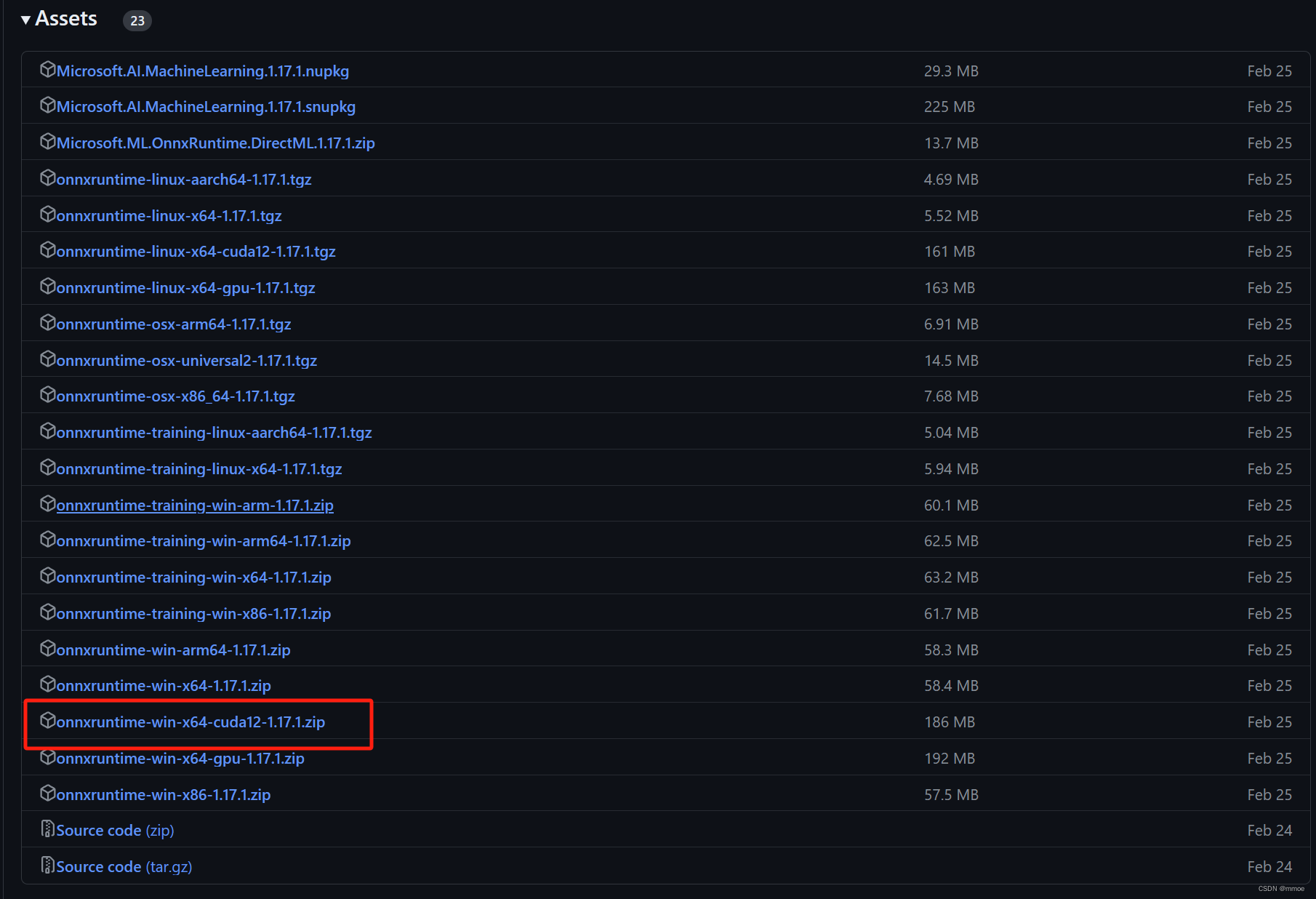
下载完成得到以下文件。
! 最后记得把库目录添加到PATH环境变量中
Note:
CUDA版本只向下兼容大版本号,即12.2只支持12.x,而不支持11.x。
ORT支持使用TensorRT作为后端来提高模型的推理性能。(ORT真好用啊,薄纱TensorRT ),若想使用TensorRT,需要使用源码自己编译ORT库,同时要注意ORT所支持的CUDA和TensorRT版本,见TensorRT支持官方文档。
b. 下载源码自己编译
这里分享一个中文编译教程:Windows下编译Onnxruntime
既然有官方二进制版本,为什么我们还要自己编译呢?
一方面,onnxruntime和cuda、cudnn、tensorRT、编译器等环境是绑定的,直接下载的不一定和你当前项目的环境一致。另一方面,onnxruntime有很多特性,发布的二进制中只编译了一些基础特性,可能你需要的特性并未被包含在其中。
如果下载的二进制不能满足需要,那么我们就只能自己编译了,编译本身很简单,只是有一些坑需要注意。
编译环境
Windows 10
Visual Studio 2017
cuda 10.0
cudnn7.6.5
TensorRT-7.0.0.11
注意:
VS要用2017或更高版本,更低的版本编译会失败,项目用到了一些较新的特性。
TensorRT也需要7.0或以上版本,低版本会有各种莫名问题,我尝试过6.0,问题太多。
源码下载
onnxruntime源码地址
https://github.com/microsoft/onnxruntime
(1)下载源码
git clone -b rel-1.3.0 --recursive https://github.com/Microsoft/onnxruntime
注意:一定要加递归**--recursive**,不然子项目下载不到。版本分支按照需要选取就行了。
(2)更新包
cd onnxruntime
git submodule update --init --recursive
如果下载慢,也可以用gittee上的镜像https://gitee.com/mirrors_microsoft/onnxruntime
但是在递归下载子项目的时候,还是会从github上拖。
编译脚本
用管理员打开命令行控制台,进入onnxruntime目录:
选好自己的cuda、cudnn、tensorRT路径,执行脚本,就可以开始编译。
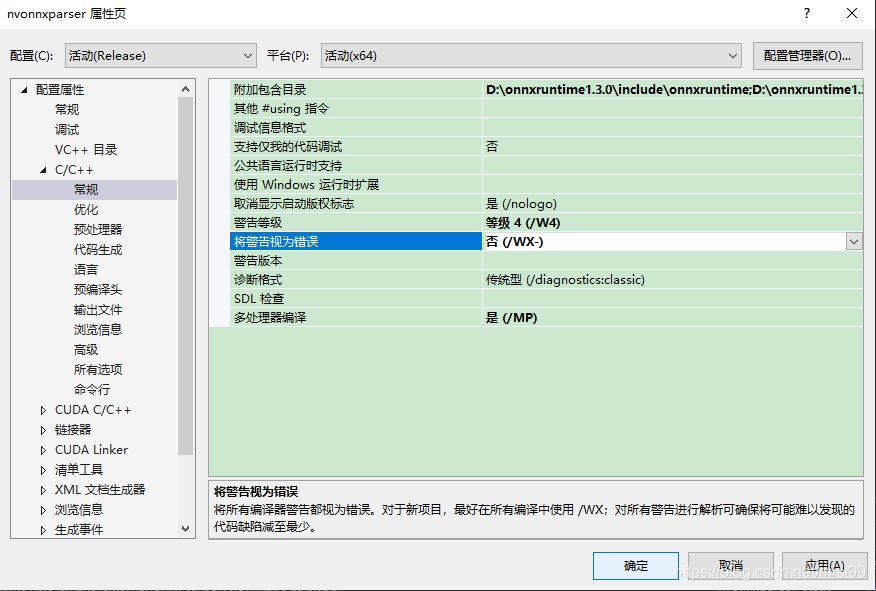
.\build.bat --build_shared_lib --config Release --use_cuda --cudnn_home "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0" --cuda_home "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0" --use_tensorrt --tensorrt_home "C:\TensorRT-7.0.0.11"用VS2017打开工程onnxruntime.sln ,选择Release,x64。
下一步,将每个工程中"C/C++/常规/将警告视为错误 "这条,改成否。
修改改完后,直接在onnxruntime上右键选择编译就可以了。
编译完成后在Release下会生成需要的onnxruntime动态库。
其他:Linux下
Linux下的编译基本是一样的,把build.bat换成build.sh就行了。脚本如下:
.\build.sh --build_shared_lib --config Release --use_cuda --cudnn_home [cuda路径] --cuda_home [CuDNN路径] --use_tensorrt --tensorrt_home [TensorRT路径] --update --build
3. 导出成功的ONNX模型
4. 配置 Visual Studio
主要是配置包含路径和依赖库,类似OpenCV配置。
准备就绪,终于可以开始愉快的部署过程了。
// 初始化ONNX Runtime
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "sdp infer");
// 创建会话选项并添加CUDA
Ort::SessionOptions session_options;
uint32_t device_id = 0; // CUDA 设备 ID
// 启用CUDA
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, device_id));
// 加载模型
const std::wstring model_path = L"model.onnx";
Ort::Session session(env, model_path.c_str(), session_options);上面代码主要做了2件事,(1)创建ORT环境env,其全局唯一 ;(2)创建会话session,可以存在多个 ,一个会话对应一个ONNX模型,env可以运行多个session。
二、设置输入与输出
设置输入输出需要与ONNX模型的输入输出严格对应,这里推荐一个查看模型结构的工具:Netron
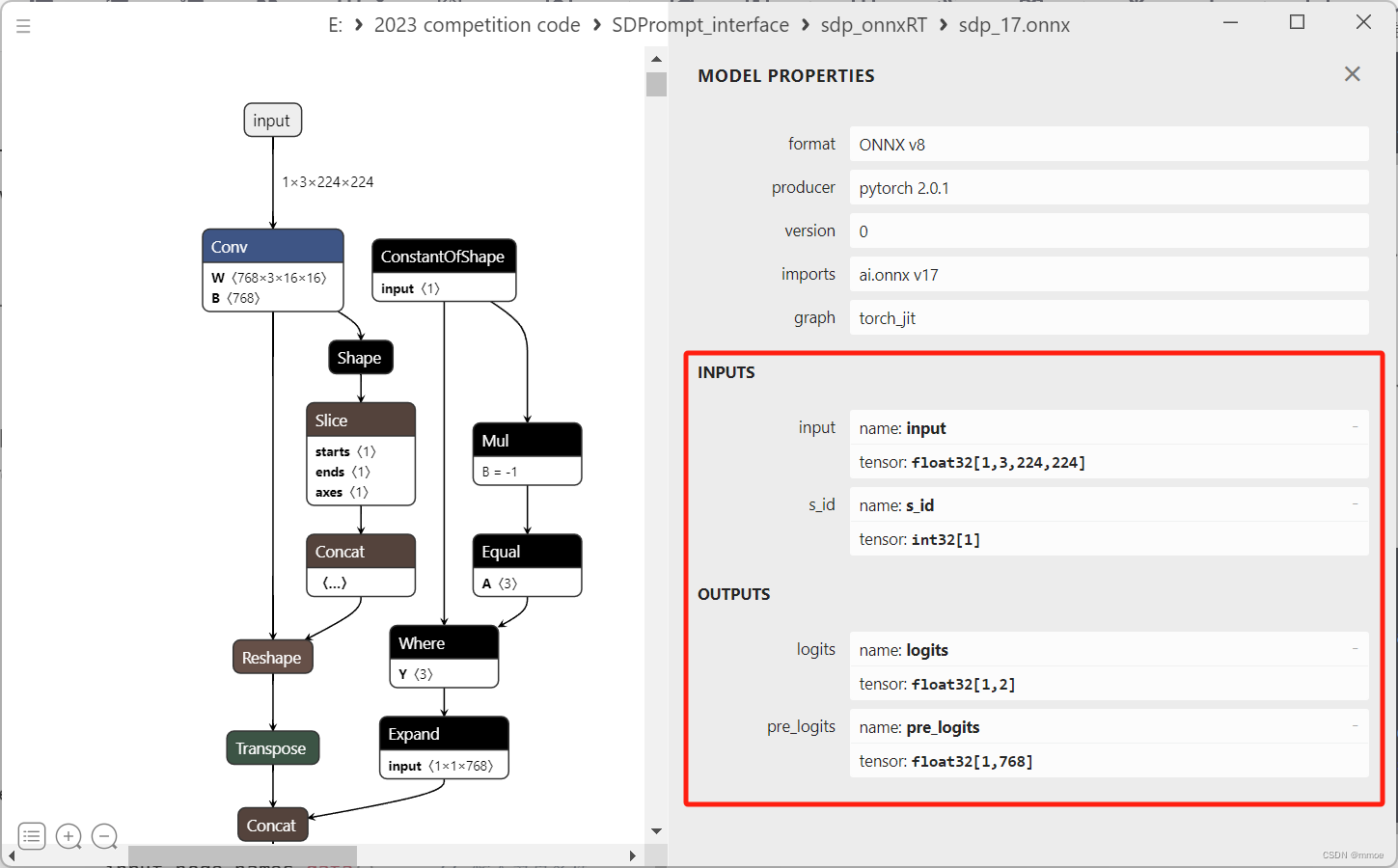
使用Netron可以看到我的模型的输入输出节点名称与数据类型和形状信息。
下面我们使用这些信息设置输入输出,在例子中我需要2输入input, s_id,1输出logits。并且输入图像需要先进行预处理,我们可以使用OpenCV辅助。基本上都是些公式化的书写,注意代码中的数据类型与模型对应。
//// 图像预处理 /////
// 用于保存input张量值
std::vector<float> input_tensor_values; // float32 input
// 创建输入张量
cv::Mat img = cv::imread("E:/myDataset/mya1/train/fake/1100.bmp");
cv::Size imgSize(224, 224);
cv::Mat blob; // 用于存储预处理后的图像
if (img.size() != imgSize)
{
cv::resize(img, blob, imgSize, 0, 0, cv::INTER_AREA); // 图像缩放
}
else
{
img.copyTo(blob);
}
blob = cv::dnn::blobFromImage(blob, 1.0 / 255, blob.size(), cv::Scalar(0, 0, 0), true, false, CV_32F); // 图像转为blob格式
float* data_ptr = reinterpret_cast<float*>(blob.data); // 获取blob数据指针
int num_elements = blob.total() * blob.channels(); // 获取blob数据元素个数
// 将blob数据拷贝到input张量中
for (int i = 0; i < num_elements; ++i)
{
/*std::cout << data_ptr[i] << " ";*/
input_tensor_values.push_back(std::move(data_ptr[i]));
}
//// 图像预处理 over /////
// 创建内存信息
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
// 创建input张量
std::vector<int64_t> input_tensor_shape = { 1, 3,224,224 }; // input张量形状
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_values.size(), input_tensor_shape.data(), input_tensor_shape.size());
// 创建s_id张量
std::vector<int64_t> sid_tensor_shape = { 1 }; // s_id张量形状
std::vector<int32_t> sid_tensor_values = { 0 }; // int32 s_id
Ort::Value sid_tensor = Ort::Value::CreateTensor<int32_t>(memory_info, sid_tensor_values.data(), sid_tensor_values.size(), sid_tensor_shape.data(), sid_tensor_shape.size());
// 设置输入节点名称
std::vector<const char*> input_node_names = { "input","s_id" };
// 创建输入张量数组
std::vector<Ort::Value> input_tensors; // 多输入
input_tensors.push_back(std::move(input_tensor));
input_tensors.push_back(std::move(sid_tensor));
// 设置输出节点名称
std::vector<const char*> output_node_names = { "logits" };Note:
Ort::Value删除了赋值操作,因此要使用std::move移动语义对其对象操作
三、进行推理
// 进行推理
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, // 运行选项 为空即可
input_node_names.data(), // 输入节点名称
input_tensors.data(), // 输入张量
input_tensors.size(), // 输入张量数量
output_node_names.data(), // 输出节点名称
output_node_names.size() // 输出张量数量
);四、获得结果
// 获取输出张量
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
for (int i = 0; i < 2; i++)
printf(" %f\n", floatarr[i]);使用GetTensorMutableData获取数据头指针。
※ 可能遇到的问题
1. Ort::Global::api_ 是 nullptr。
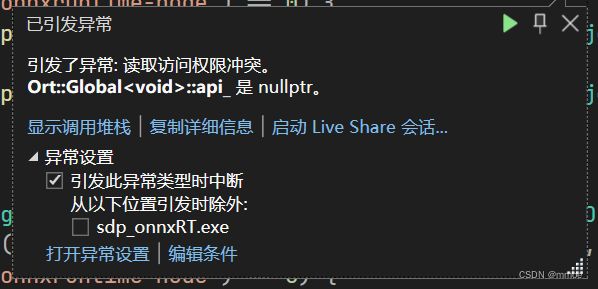
这是由于Windows默认的System32下存在同名的onnxruntime.dll,其优先级高于ORT库中的。
解决方法: 将ORT的lib文件夹里的onnxruntime.dll、onnxruntime_providers_shared.dll、onnxruntime_providers_cuda.dll复制到工程生成的exe文件夹下。
2. ThrowStatus函数报错
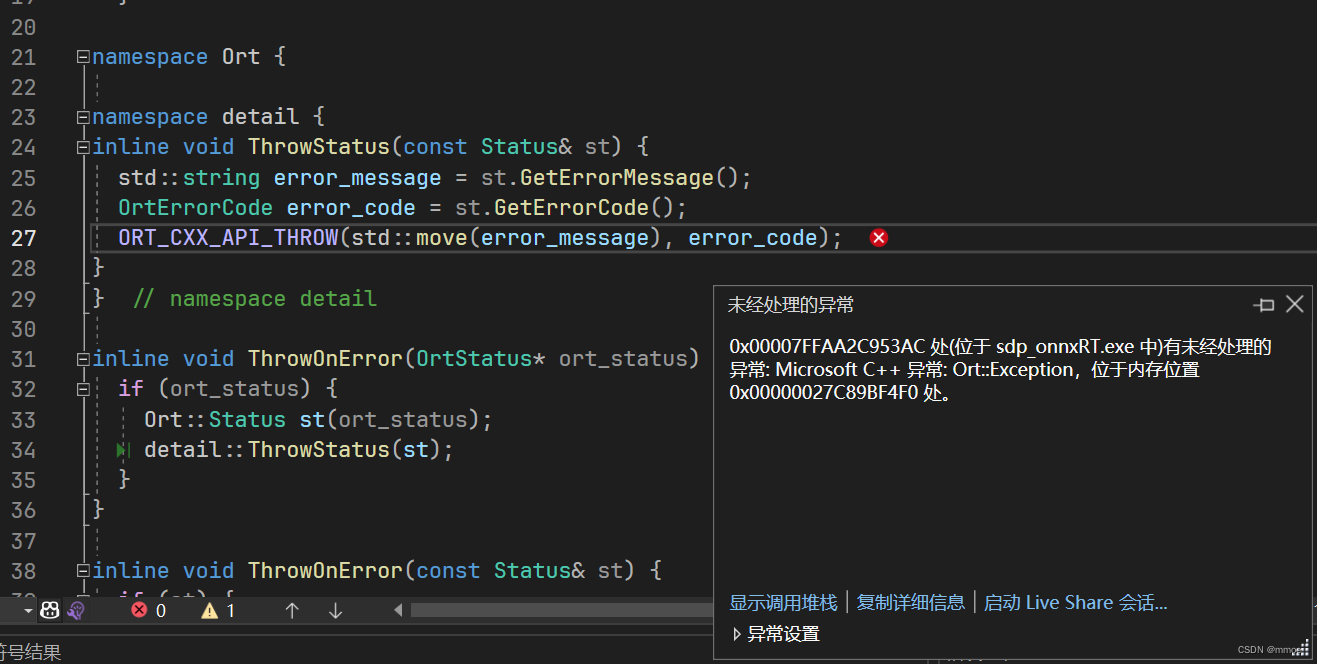
这个错误有很多原因引起,CUDA错误、输入数据类型与模型不一致、env或session为空指针等等。
解决方法: 通过调用堆栈查看报错语句处理,或者使用try-catch捕捉Ort::Exception获取错误信息。