当前大语言模型LLM很热,人们也试图把LLM应用在机器人中。借助LLM可以控制机器人,也算作一种高级智能体的应用。这种控制是通过LLM控制物理世界,而不仅仅是在网上的操作。
1、LLM在机器人中的作用
LLM 在机器人中主要承担高层语义理解、任务规划与自然语言交互,与传统实时控制分层耦合,形成 "LLM 做大脑、经典控制做手脚" 的混合智能架构,可显著提升开放环境下的泛化与交互能力。可提供如下能力:
| 应用维度 | 核心能力 | 典型实现与案例 |
|---|---|---|
| 自然语言交互 | 意图理解、多轮对话、模糊指令解析 | 优必选 Walker S + 文心大模型:"拿一瓶水"→语义解析→路径规划→执行;特斯拉 Optimus:理解 "左边第三个抽屉" 等空间约束 |
| 任务规划与分解 | 长程任务拆解、动态重规划、可行性校验 | Google SayCan(PaLM):"清理桌子"→"捡起杯子" 等原子动作,结合价值函数筛选;ELLMER 框架:咖啡制作 / 摆盘装饰,融合视觉 / 力反馈调整动作 |
| 多模态感知融合 | 视觉 / 力觉 / 激光雷达的语义化理解 | 场景语义解析:"收拾书房"→"整理书架→擦拭书桌";"给多肉浇水"→避障→精准喷淋 |
| 技能调用与代码生成 | 函数调用(Function Calling)、生成 ROS / 控制代码 | ChatGPT for Robotics:自然语言生成控制代码,调用 API 完成抓取 / 避障;LLM-ROS 中间件:话题解析与服务调用 |
| 具身智能推理 | 端到端多模态决策、物理场景推理 | PaLM-E:视觉 + 语言 + 动作统一建模,实现泛化具身控制;Vox Poser:专用具身大模型驱动动作生成 |
2、如何把自然语言理解转换为控制指令?
整体流程(一句话版)
自然语言 → LLM 语义理解 → 任务拆解 → 动作规划 → 转换成控制指令 / 代码 → 机器人执行
这里有一个疑惑,LLM是如何理解人类的自然语言并能控制机器人去执行指令呢?
主要通过提示词工程(Prompt),让LLM输出符合人类的格式,然后控制机器去执行。
代表为 :ChatGPT for Robotics
ChatGPT for Robotics 是微软研究院于 2023 年推出的开创性研究项目,核心是将 ChatGPT 作为机器人的 "大脑",通过提示词工程(Prompt Engineering),直接将人类的自然语言指令,转化为机器人可执行的控制逻辑与代码。
2.1、核心设计思想
传统机器人依赖工程师编写特定代码,灵活性极差。该项目的突破在于:
不训练模型:直接利用 ChatGPT 的零样本 / 小样本学习能力与常识推理。
函数库抽象:为机器人预定义高层级技能库(如 move_to, grasp, navigate)。
LLM 做规划:ChatGPT 负责理解意图、拆解任务、生成函数调用序列,底层控制器负责执行。
2.2、核心工作流程(Prompt 驱动)
1. 系统提示词(System Prompt)
这是项目的核心,通过精确的 Prompt 约束 ChatGPT 输出机器人专用代码 。
示例(官方核心模板):

通过上面的强约束,告诉LLM你是一个机器人控制专家,以及职责就是把自然语言转换为控制代码。
并提出了严格的规则,以及可提供的机器人API。然后用户结合前面的提示词把指令发出去,LLM就能按照人类的要求返回指令列表。就是这么神奇!
2. 用户输入(自然语言)
"把桌子上的红色杯子拿到厨房的台面上。"
3. ChatGPT 输出(可直接执行的控制代码)
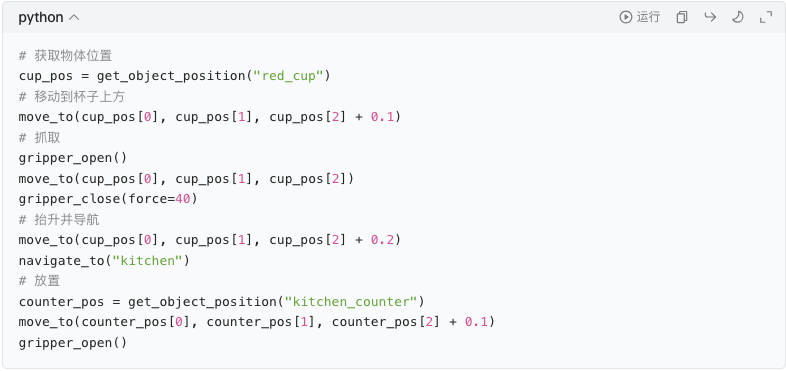
把大任务拆成机器人能执行的原子动作序列:
移动到桌子旁
视觉定位红色杯子
机械臂移动到杯子上方
闭合夹爪抓取
抬升机械臂
导航移动到厨房
机械臂移动到目标位置
松开夹爪放置
当然也可以输出ROS风格的指令代码序列。
这一步是 LLM 最强的地方:常识推理 + 逻辑规划。
然后这段代码控制机器人进行操作。
3、LLM如何做到能按照提示词的要求输出?
这个是最本质的问题
一句话核心答案
LLM 本质是预测下一个词,但它在训练时学到了:
当文本里出现 "规则、要求、角色、格式" 时,后续内容要严格遵循前面的约束。
提示词 = 给模型一个强上下文先验,让它把生成方向 "锁死" 在你规定的轨道上。
3.1、LLM 到底在做什么?(极简原理)
Transformer 模型做的只有一件事:
根据前面所有文本,预测下一个最合理的 token(字 / 词)。
它不是 "理解规则",也不是 "有意识执行",
而是:
训练数据里大量出现过 "先给规则 → 再按规则输出" 的句式,
模型学会了这种模式匹配 。
例如训练语料里有:
- 请按以下规则写作文...
- 按 JSON 格式输出如下...
- 你是医生,只回答医疗问题...
- 只输出代码,不要解释...
- 模型见过几百万次这种结构,因此学会了 "遵循前置约束"。
3.2、提示词为什么能控制输出?(关键 4 点)
(1)上下文窗口 = 模型的 "短期记忆"
你写的 Prompt 会全部进入上下文,
模型生成每一个字时,都能看到你写的所有规则。
它不是 "记住规则",
而是每一步生成都重新看一遍规则。
(2)指令微调(Instruction Tuning)让模型天生 "听话"
GPT、文心、通义、Llama 等都经过:
指令微调
人类偏好对齐(RLHF)
目标就是:
看到 "请你...""你要...""规则如下" 就优先服从。
这是人为教出来的能力:遵循指令 > 自由发挥。
(3)强约束词会显著提高模型 "顺从度"
你在 Prompt 里用这些词,模型会更严格:
- 必须
- 严格遵守
- 只输出
- 禁止
- 不要
- 只能
- 绝对不要
这些词在训练数据里对应强约束模式,
模型会自动降低创造性,提高格式服从性。
(4)示例(Few-shot)让模型瞬间懂格式
如果你给 1~2 个示例:
用户:A
输出:1,2,3
模型会立刻学到:
哦,原来要输出这种结构。
这比纯规则更有效,因为模式比描述更容易被模型捕捉。
3.3、为什么机器人 Prompt 特别有效?
机器人控制 Prompt 本质是:
- 限定角色
你是机器人指令生成器 - 限定动作空间
只能用这几个 API:move、grab、navigate - 限定输出格式
只代码 / 只指令 / 只 JSON - 禁止幻觉
不许编造函数 - 给示例
模型一看就懂
模型看到这种结构,
生成空间被极度压缩,
只能从合法指令里预测下一个词,
几乎不会乱编。
3.4、 用一个超简单类比理解
你可以把 LLM 看作:
一个超级巨大的概率文本接龙机器
提示词 = 给它一个开头
规则 = 给它一个范围
它做的事情是:
前面写了 "只输出 Python 代码"
- → 下一个词大概率是 def / import / 变量名
前面写了 "只输出指令" - → 下一个词是 MOVE_TO、GRASP、NAVIGATE
前面写了 "按 JSON 输出" - → 下一个词是 { " :
它不是 "理解规则",而是 "概率上只往符合规则的方向走"。
3.5、为什么有时候不听话?(幻觉来源)
- 规则不够强
- 上下文太长,模型看不到前面约束
- 任务太复杂,模型优先 "完成任务" 而不是 "遵守格式"
- 模型太小,能力弱
解决方法就是我们机器人 Prompt 里做的:
强约束 + 少动作 + 固定格式 + 示例
3.6、最终极简总结(最关键)
LLM 能按提示词输出,是因为三件事:
- 训练数据里大量包含 "规则 + 输出" 的结构,模型学会了顺从前置指令
- 指令微调让模型天生就会 follow instruction
- 提示词把上下文、格式、约束全部喂给模型,每一步生成都被引导
它不是真的 "懂你的要求",
而是在概率上,最合理的续写就是严格按你给的规则输出。
4、为什么提示词工程(Prompt Engineering)有效?
一句话核心结论:提示词工程本质是利用 Transformer 的注意力机制和预训练模式,把模型庞大的 "知识概率空间" 压缩、引导到你想要的输出轨道上,无需改动模型参数就能精准控制输出。
下面从底层原理、核心机制、生效逻辑三层讲透,完全贴合你之前机器人控制 Prompt 的场景,好懂又硬核。
4.1、先锚定:LLM 的本质是什么?
LLM 不是 "思考机器",是基于上下文的概率续写器:
- 训练时吞下万亿级文本,学到了语言模式、逻辑常识、格式规范、角色行为;
- 生成时只做一件事:根据上下文,预测下一个最可能的 Token(字 / 词 / 符号);
- 它没有 "主动意愿",输出完全由上下文输入和训练学到的概率分布决定。
提示词工程的核心,就是通过设计上下文,改写下一个 Token 的概率分布,让 "符合要求的输出" 概率最大化,"不符合的" 概率趋近于 0。
4.2、提示词工程有效的 4 个底层核心机制(关键)
1. 注意力机制:让模型 "聚焦" 你给的规则
Transformer 的自注意力机制 ,会让模型生成每一个 Token 时,优先关注上下文里的关键约束 :
你写的 "角色定义、API 列表、输出格式、禁止规则",会被模型标记为高权重上下文;
生成代码 / 指令时,注意力会反复扫描这些约束,优先匹配规则内的内容;
比如机器人 Prompt 里的 "只使用 move_to/gripper_open",会让模型注意力锁定这几个 API,大幅降低编造新函数的概率。
👉 类比:像老师划重点,模型生成时眼睛只盯着你划的 "重点规则",忽略无关知识。
2. 模式匹配:复用训练时的 "规则 - 输出" 范式
LLM 训练语料里,存在海量 "前置约束 + 后置输出" 的固定模式:
- 比如:"按 JSON 格式输出:{...}""只写代码,不解释:xxx""你是翻译官,只译中文:xxx";
- 模型通过海量数据,学到了 "看到某类约束句式,就输出对应格式内容" 的强关联;
- 提示词工程就是复刻这种训练范式,用同样的句式触发模型学到的 "模式匹配逻辑",让它自动输出符合格式的内容。
👉 机器人 Prompt 里的 "只输出 Python 代码,不解释",本质就是触发模型学到的 "代码生成模式",和训练时的代码注释、编程问答范式完全对齐。
3. 指令对齐(RLHF / 指令微调):模型天生 "学会听话"
现在的 LLM(GPT、Llama、文心等)都经过指令微调 + 人类偏好对齐(RLHF) :
训练目标被优化为:优先服从人类指令,而非自由续写;
对 "严格、明确、强约束" 的指令(如 "必须""禁止""只能"),会显著提升服从概率;
提示词工程通过强化约束语气、明确边界 ,进一步激活模型的 "服从天性",让它放弃 "自由发挥",优先满足规则。
👉 比如你写 "不许编造函数",模型会因为对齐训练,主动降低 "幻觉编造" 的概率,更严格遵守 API 列表。
4. 上下文锁定:压缩模型的 "生成可能性空间"
LLM 的知识是通用的,生成可能性无限大;提示词工程的核心作用就是 "锁死可能性":
限定角色 :从 "通用模型"→"机器人控制引擎",过滤无关知识;
限定动作空间 :只能用指定 API,排除所有非法函数;
限定输出格式 :只代码 / 只 JSON / 只指令,固定输出结构;
限定约束条件 :禁止解释、禁止序号、禁止编造,进一步缩小范围。
每多一条约束,模型的合法生成空间就缩小一圈,最终只能在你划定的轨道内续写,自然精准可控。
4.3、结合前面的机器人场景:为什么那个 Prompt 特别有效?
用上面的机制,拆解你之前的机器人控制 Prompt,一看就懂:

- 注意力机制:模型反复扫描 API 列表,只调用合法函数;
- 模式匹配:触发训练时 "指令→代码" 的生成范式;
- 指令对齐:服从 "只输出代码" 的强约束,不闲聊;
- 空间压缩:排除所有无关输出,只生成控制逻辑。
👉 这就是为什么复制 Prompt 后,模型能稳定输出可执行的机器人指令,几乎不会乱编。
4.4、补充:为什么有时候提示词会 "失效"?
本质是上面 4 个机制没被激活,常见原因:
- 约束太模糊:"尽量按格式" 不如 "必须严格按格式",激活不了强服从;
- 上下文太长:规则被淹没,注意力无法聚焦约束;
- 模型能力不足:小模型没学到复杂模式匹配,无法理解多层约束;
- 约束冲突:规则自相矛盾,模型概率分布混乱,输出失控。
4.5、极简终极总结
提示词工程有效,是因为它做了 3 件事:
利用注意力 :让模型盯着你的规则看;
利用训练模式 :触发模型学到的 "约束→输出" 范式;
利用指令对齐 :激活模型的服从天性,压缩生成空间。
全程不改动模型参数,只通过设计上下文,让通用 LLM 精准变成 "机器人控制引擎""代码生成器""格式转换器",这就是它高效、低成本的核心原因。
5、LLM 服从度的底层原理(注意力机制)
LLM 服从度 底层原理:完全靠「注意力机制」+ 预训练对齐
5.1、先一句话结论
LLM 为什么听话、服从指令、按要求做事?
核心底层:
注意力机制 让模型优先看懂人类指令、绑定指令与回答
预训练 + SFT/RLHF 把「指令→服从回答」训练成强注意力先验
注意力权重分配 = 模型的 "听话优先级"
5.2、注意力机制 核心原理(极简易懂)
1. 自注意力核心作用
Transformer 自注意力:
每个单词 / 字,都会计算和全文所有 token的关联权重:
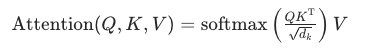
Q:当前内容查询
K:上下文所有内容
注意力权重:决定「我重点看哪部分信息」
2. 关键:指令 Prompt 会获得极高注意力权重
人类输入格式:
指令(你需要 xxx)+ 问题 / 任务 + 上文内容
在注意力计算中:
✅ 指令 token 对后续所有回答 token,拥有极高注意力分数
✅ 模型每生成一个字,都会强关联前面的指令
✅ 无关内容注意力权重被压低、忽略
👉 这就是服从的物理底层:
回答全程被指令的高注意力绑定、约束、引导。
5.3、服从度完整三层原理(层层递进)
第一层:原生注意力结构(天生基础)
模型生成是自回归 :从左往右一字一字生成
前文所有内容(尤其是开头指令)永久可见
因果掩码保证:回答只能看指令,不能乱生成无关内容
结构上,天生就具备「被前文指令约束」的能力
第二层:预训练阶段(形成语言常识服从)
海量文本里天然存在:
提问→回答
要求→执行式文本
模型通过注意力学习到:
前文要求语句 → 后文必须对应回应
潜移默化学会基础 "听话逻辑"
第三层:对齐训练(SFT/RLHF 强化服从,关键)
1、**SFT 监督微调
大量「指令 + 标准服从回答」数据
用注意力强制学习:
指令特征 → 必须映射到合规、贴合要求的输出
2、RLHF 人类反馈强化学习
惩罚:跑偏、拒绝、答非所问
奖励:服从、精准按指令执行
最终结果:
模型主动抬高指令注意力权重 ,
主动降低自由发挥、乱编、叛逆输出的权重。
5.4、用注意力解释「为什么会不服从 / 叛逆」
指令太长 → 注意力分散,关键指令权重被稀释
模糊指令 → 注意力关联弱,模型自由发挥
越狱提示词 → 人为破坏注意力约束、绕过指令权重
小模型注意力头少、建模弱 → 服从度天然差
5.5、小结
LLM 的服从度底层依托 Transformer 自注意力机制 实现:
模型通过计算上下文 Token 间的注意力权重,赋予用户指令更高的关联权重 ,使每一步生成过程都强绑定指令语义;
结合预训练语言规律、有监督微调 SFT 与人类反馈强化学习 RLHF,进一步强化指令与目标输出的注意力关联,约束生成方向,最终使大模型具备理解指令、遵循约束、稳定服从人类要求的能力。
5.6、补充:和你之前机器人内容串联
LLM:注意力机制实现指令服从、语义理解
VLM/VLA:跨模态注意力,绑定视觉 + 语言指令
世界模型:物理约束兜底
整套机器人:LLM 听懂指令 → 规划 → 控制执行
6、核心挑战与应对策略
| 挑战 | 具体表现 | 应对策略 |
|---|---|---|
| 实时性不足 | LLM 推理延迟(数百毫秒)与工业控制(10--100ms)不匹配 | 分层解耦,LLM 仅做高层决策;端侧部署轻量模型;云端处理长规划,边缘做快速决策 |
| 幻觉与安全风险 | 语义误解、生成无效 / 危险动作,对抗样本攻击 | RAG + 可行性校验;多候选计划 + 仿真验证;传感闭环异常检测;动作白名单与急停 |
| 物理常识缺失 | 生成不合理动作(如推重物、过力抓取) | 融合世界模型 / 物理约束;加入力 / 位姿阈值校验;模仿学习补充物理直觉 |
| 输出不稳定 | 同一指令生成不同动作序列 | 结构化 Prompt(固定动作格式);强化学习优化动作序列;可解释审计链路 |
| 人机交互歧义 | 模糊指令、隐含偏好导致执行偏差 | 多轮澄清与反问;场景化上下文理解;用户偏好建模 |
| 输出不稳定 | 同一指令生成不同动作序列 | 结构化 Prompt(固定动作格式);强化学习优化动作序列;可解释审计链路 |
| 精度不足 | LLM 擅长逻辑,但缺乏底层精确的物理控制能力 | 靠传感器反馈以及物理调控 |