手写数据库内核!从零实现ToyDB第5章:查询执行引擎与火山模型
导语 :你的 SELECT 语句经历了 SQL 解析后,如何从磁盘上的页面变成一行行结果?本章我们将用火山模型亲手打造查询执行引擎,并且实现全表扫描、条件过滤、列投影、结果截断四大基础算子。读完本文,你将彻底看懂一条查询在数据库内部最核心的执行路径,面试时可以对执行计划娓娓道来。
一、学习目标
- 理解迭代器模型、物化模型、向量化模型的区别,以及为什么我们选择火山模型
- 掌握火山模型算子统一接口
open() → next() → close()的设计哲学 - 亲手实现
SeqScan、Filter、Project、Limit四个算子 - 构建表达式求值系统,支撑 WHERE 条件和算术运算
- 将 AST 转换为算子树,并执行带有
WHERE和LIMIT的查询 - 通过实验观察算子执行流程,能分析虚函数调用开销
二、理论基础:数据库如何执行你的查询
在 SQL 解析器生成抽象语法树(AST)之后,数据库需要将逻辑上的"做什么"变为物理上的"怎么做"。这个转换过程就是查询执行引擎的职责。执行模型决定了数据如何在算子间流动,直接影响 CPU、内存和 I/O 的效率。
2.1 迭代器模型(火山模型)
火山模型(Volcano / Iterator Model) 由数据库先驱 Goetz Graefe 在 1994 年提出。其核心思想是:将每一个关系代数操作(扫描、过滤、投影、排序等)封装成一个迭代器(Iterator),所有迭代器都实现三个统一接口:
python
open() → 初始化资源
next() → 获取下一行数据,若无数据返回 None
close() → 释放资源上层算子通过调用下层算子的 next() 来"拉取"数据,数据像一个元组一样自底向上流动。这种按行拉取的模式天然形成流水线(pipeline),几乎不占用额外内存。
next
next
返回一行
满足条件则返回
根算子 (Project)
中间算子 (Filter)
叶子算子 (SeqScan)
优势 :接口统一,算子可任意组合;内存开销小;非常适合 OLTP 场景。
劣势:每处理一行都要经历虚函数调用链,CPU 缓存命中率低,难以利用现代 CPU 的 SIMD 批量计算。
2.2 物化模型与向量化模型
- 物化模型:每个算子一次性处理所有输入,生成完整的结果集再传给上层。缺点是需要大量内存存放中间结果,延迟高。
- 向量化模型:介于二者之间,每次处理一批(几百到几千行)数据,可利用 CPU 的矢量指令,大幅减少函数调用次数,是现代 OLAP 数据库(ClickHouse、DuckDB)的主流选择。
2.3 选择火山模型的理由
在 ToyDB 中,我们选择火山模型,因为:
- 接口清晰,代码量少,完美契合教学目的;
- 扩展性强,后续可平滑加入排序、聚合、连接等算子;
- 理解火山模型后,再学习向量化执行引擎将事半功倍。
三、架构设计:火山模型在 ToyDB 中的定位
整个执行引擎位于查询处理器的最底层,接收优化器产出的物理执行计划(或直接接收 AST),与事务管理器、缓冲池交互,完成数据读写。
查询处理器
SQL解析器
查询优化器
执行引擎
缓冲池 BufferPool
磁盘管理器
目录管理器
执行引擎内部,我们通过下列类协同工作:
| 类 | 职责 |
|---|---|
ExecutorContext |
持有全局组件(Catalog、BufferPool、LockManager)的引用 |
Iterator |
所有算子的抽象基类 |
SeqScan |
全表扫描 |
Filter |
条件过滤 |
Project |
列投影 |
Limit |
结果截断 |
ExpressionEvaluator |
表达式求值(比较、算术、逻辑运算) |
QueryExecutor |
将 AST 转换成算子树并驱动执行 |
四、代码实现:手把手打造每一个算子
4.1 环境准备:ExecutorContext 与 Iterator 基类
为了让算子能够访问缓冲池和目录,我们引入执行上下文,避免全局变量。
python
# src/query/execution/context.py
class ExecutorContext:
def __init__(self, catalog, buffer_pool):
self.catalog = catalog
self.buffer_pool = buffer_pool
self.lock_manager = None # 为事务章节预留所有算子的统一接口:
python
# src/query/execution/iterator.py
from abc import ABC, abstractmethod
class Iterator(ABC):
@abstractmethod
def open(self) -> None: ...
@abstractmethod
def next(self): # 返回 Optional[Dict]
...
@abstractmethod
def close(self) -> None: ...4.2 全表扫描算子 SeqScan
SeqScan 从目录获取表的首页 ID,通过缓冲池逐页读取,反序列化记录并按顺序返回。
磁盘 BufferPool SeqScan 上层算子 磁盘 BufferPool SeqScan 上层算子 alt 当前页记录已耗尽 loop 每页 open() 获取首页ID next() get_page(page_id) Page 反序列化记录列表 返回一行 close()
核心代码(已进行简化):
python
class SeqScan(Iterator):
def __init__(self, ctx: ExecutorContext, table_name: str, schema):
self.ctx = ctx
self.table_name = table_name
self.schema = schema
self.current_page = None
self.current_page_id = -1
self.records = []
self.record_idx = 0
def open(self):
meta = self.ctx.catalog.get_table(self.table_name)
self.current_page_id = meta.first_page_id
def next(self):
while self.record_idx >= len(self.records):
if not self._load_next_page():
return None
record = self.records[self.record_idx]
self.record_idx += 1
return record
def _load_next_page(self) -> bool:
if self.current_page_id == -1:
return False
page = self.ctx.buffer_pool.get_page(self.current_page_id)
self.records = page.get_records_with_schema(self.schema)
self.current_page_id = page.next_page_id
self.record_idx = 0
return len(self.records) > 0
def close(self):
self.current_page = None4.3 投影算子 Project
Project 只返回 SELECT 指定的列,列名列表为 ["*"] 时保留所有列。
python
class Project(Iterator):
def __init__(self, child: Iterator, columns: List[str]):
self.child = child
self.columns = columns
def open(self): self.child.open()
def close(self): self.child.close()
def next(self):
row = self.child.next()
if row is None: return None
if self.columns == ["*"]:
return row
return {col: row[col] for col in self.columns if col in row}4.4 条件过滤 Filter 与表达式求值系统
Filter 不断从子算子拉取行,送入表达式求值器判断条件,只返回 True 的行。
表达式求值器支持列引用、字面量、比较运算、算术运算以及 AND/OR 逻辑,并具备基本的类型自动转换。
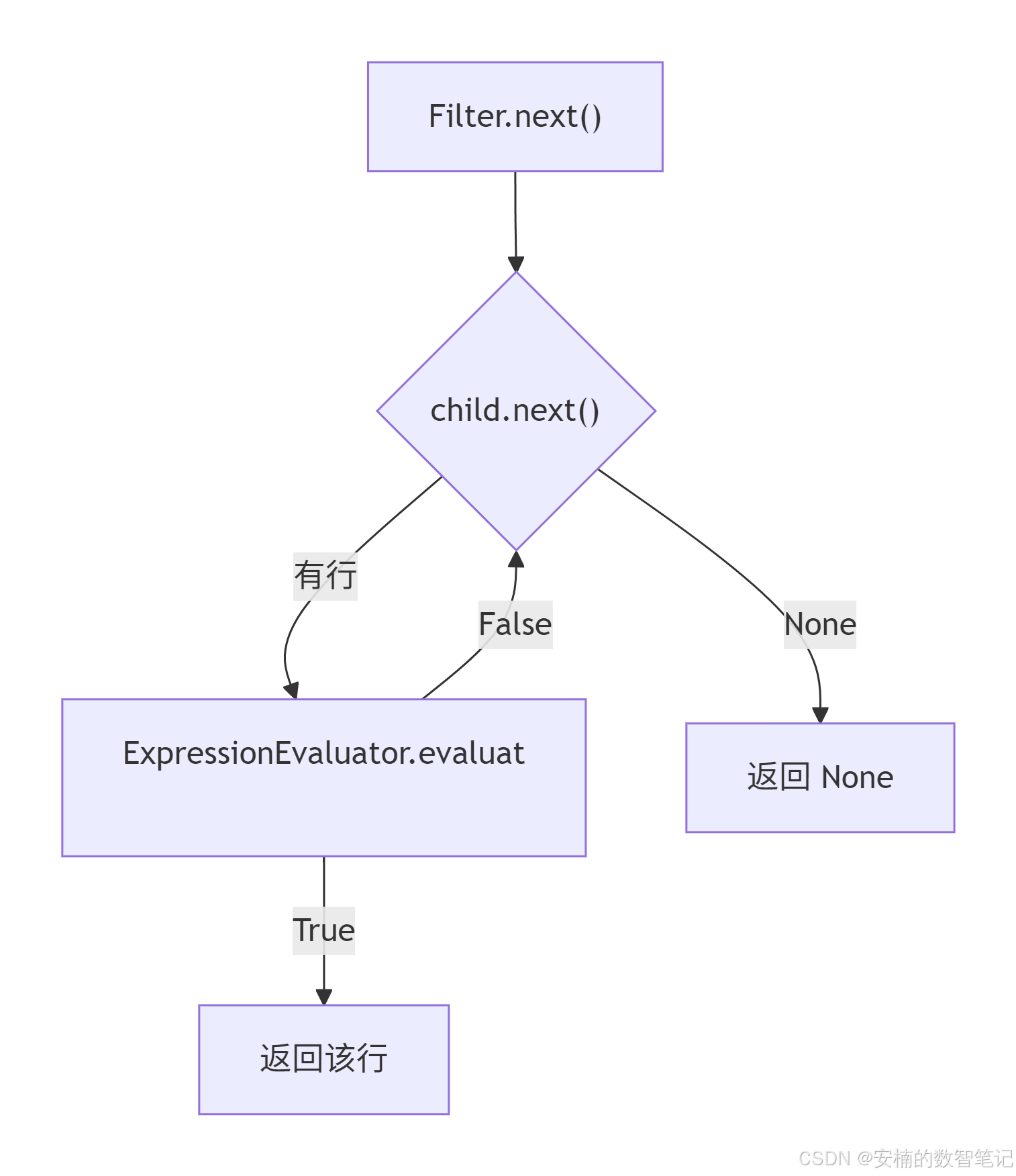
表达式求值器核心:
python
class ExpressionEvaluator:
@staticmethod
def evaluate(expr, record: Dict[str, Any]) -> Any:
if isinstance(expr, str): # 列引用
return record.get(expr)
if isinstance(expr, Literal): # 常量
return expr.value
if isinstance(expr, BinaryExpression):
left = ExpressionEvaluator.evaluate(expr.left, record)
right = ExpressionEvaluator.evaluate(expr.right, record)
left, right = ExpressionEvaluator._coerce_types(left, right)
return ExpressionEvaluator._apply_op(expr.operator, left, right)
raise ValueError(f"不支持的表达式类型: {type(expr)}")
@staticmethod
def _apply_op(op: str, left, right):
ops = {
"=": lambda a,b: a == b, "<>": lambda a,b: a != b,
"<": lambda a,b: a < b, ">": lambda a,b: a > b,
"<=": lambda a,b: a <= b,">=": lambda a,b: a >= b,
"+": lambda a,b: a + b, "-": lambda a,b: a - b,
"*": lambda a,b: a * b, "/": lambda a,b: a / b,
"AND": lambda a,b: bool(a) and bool(b),
"OR": lambda a,b: bool(a) or bool(b),
}
return ops[op](left, right)
@staticmethod
def _coerce_types(left, right):
if type(left) == type(right):
return left, right
# 数值统一转为float
if isinstance(left, (int, float)) and isinstance(right, (int, float)):
return float(left), float(right)
# 字符串与数值互转可在此扩展
return left, rightFilter 算子实现:
python
class Filter(Iterator):
def __init__(self, child: Iterator, condition):
self.child = child
self.condition = condition
def open(self): self.child.open()
def close(self): self.child.close()
def next(self):
while (row := self.child.next()) is not None:
if self.condition is None or ExpressionEvaluator.evaluate(self.condition, row):
return row
return None4.5 结果截断 Limit
Limit 在内部维护计数器,一旦达到上限,无论下游是否还有数据,直接返回 None,这一特性能极大提升 TOP N 查询的性能。
python
class Limit(Iterator):
def __init__(self, child: Iterator, limit: int):
self.child = child
self.limit = limit
self.count = 0
def open(self):
self.child.open()
self.count = 0
def next(self):
if self.count >= self.limit:
return None
row = self.child.next()
if row is not None:
self.count += 1
return row
def close(self): self.child.close()五、执行计划树:从 AST 到算子树
QueryExecutor 负责将解析后的 SelectStatement 转换成实际执行的算子树。对于 SELECT id, name FROM employees WHERE dept='tech' LIMIT 10,生成的算子树如下:
Limit(10)
Project(id, name)
Filter(dept='tech')
SeqScan(employees)
QueryExecutor 的关键逻辑:
python
class QueryExecutor:
def __init__(self, ctx: ExecutorContext):
self.ctx = ctx
def execute_select(self, stmt: SelectStatement):
schema = self.ctx.catalog.get_table_schema(stmt.table)
# 叶子:全表扫描
plan = SeqScan(self.ctx, stmt.table, schema)
# 过滤
if stmt.where:
plan = Filter(plan, stmt.where)
# 投影
plan = Project(plan, stmt.columns)
# 截断
if hasattr(stmt, 'limit') and stmt.limit is not None:
plan = Limit(plan, stmt.limit)
# 执行并收集结果
results = []
try:
plan.open()
while (row := plan.next()) is not None:
results.append(row)
finally:
plan.close()
return results六、实验环节:亲手跑通你的第一个查询
实验 6-1:添加 LIMIT 算子并集成
- 在
src/query/execution/limit.py中实现Limit类(代码如上)。 - 修改
QueryExecutor,在构建计划时根据stmt.limit添加Limit节点。 - 编写测试用例
test_limit.py:- 向表中插入 100 行数据;
- 执行
SELECT * FROM t LIMIT 20; - 断言返回结果数量为 20。
实验 6-2:扩展表达式求值,支持算术运算
在 ExpressionEvaluator._apply_op 中补全 +, -, *, / 的支持后,测试 SELECT salary * 1.1 FROM employees,观察薪水计算是否正确。
实验 6-3:使用 cProfile 观察算子调用链
在你的 Python 脚本中引入 cProfile,对带 WHERE 和 LIMIT 的查询进行性能剖析。重点关注:
next()方法的调用次数;- 虚函数调用(抽象类方法)的累积时间;
- Limit 提前终止对下游算子的影响。
示例命令:
python
import cProfile
cProfile.run('executor.execute_select(stmt)', sort='cumtime')七、常见问题与调试
-
算子未关闭导致缓冲池泄漏?
SeqScan中持有的 Page 引用若不及时释放,可能导致缓冲池页钉死(pinned)。始终使用try...finally确保close()被调用,后续可封装上下文管理器自动管理。 -
类型转换失败
目前
_coerce_types只处理了简单的数值互转,遇到WHERE age > '25'(字符串与整数比较)会直接返回原类型,导致比较失败或意外结果。生产数据库会用更严格的类型系统,在绑定阶段就报错。暂时可手动插入显式转换函数。 -
NULL 值处理
在 SQL 标准中,任何与 NULL 的比较(包括
NULL = NULL)都应返回UNKNOWN而非TRUE。目前我们的求值器简单把None等同于 Python 的None,会比较失败。接下来的事务和存储章节会引入 NULL 的位图标记,届时需要扩展表达式求值器支持三值逻辑。 -
Limit 算子中断下游
当你看到
Limit生效后,下游算子(如Filter)的next()调用次数骤减,这是正常的优化效果。但如果后续扩展ORDER BY,需要注意Limit必须在排序之后插入,否则结果不正确。
八、本章小结与思考题
核心要点回顾
- 火山模型通过
open/next/close统一接口组织算子树,数据按行拉取、流水线执行。 - 我们实现了四个基础算子:
SeqScan、Filter、Project、Limit,它们可以像乐高积木一样自由组合。 - 表达式求值器负责计算 WHERE 条件和算术表达式,是执行引擎的"大脑"。
- 执行引擎将 AST 转换为物理算子树并驱动执行,至此 ToyDB 已能完成带过滤和截断的单表查询。
思考题
- 如果要支持
SELECT DISTINCT消除重复行,你会设计一个怎样的算子? LIMIT为什么能提高查询性能?如果查询包含ORDER BY,LIMIT应该放在算子树中的什么位置?- 假设你需要实现一个支持
OFFSET的算子,它和Limit有什么不同? - 火山模型最大的性能瓶颈在哪里?有哪些可能的改进方向?
- 尝试画出你曾用过的某个数据库(如 MySQL)中
EXPLAIN输出的执行计划,与我们现在的算子树做对比。
💬 欢迎在评论区留下你的答案和实验心得,每一条我都会认真阅读并回复!
九、下集预告与资源获取
下一章 :我们将进入查询分析与逻辑优化 ,学习谓词下推、列裁剪、常量折叠等基于规则的优化,让查询计划在物理执行前就"瘦身"成功,性能再上一个大台阶。
本章完整源码已更新到 GitHub ,包含 ExecutorContext、所有算子和表达式求值器的实现及配套测试。
🔗 GitHub仓库 :ToyDB - 从零实现的数据库系统
🏷️ 本章Tag :
chapter-05-query-execution(可对比增量代码)📦 包含完整实验代码与测试用例
提示:如未及时更新代码库,请后续再查看,地址不变,代码一直再更新中,谢谢理解......
如果本文帮你打通了查询执行引擎的任督二脉,请点赞、收藏、转发,这是对我最大的鼓励!
关注我,第一时间获取后续章节------让我们一起,从零造出现代数据库的每个轮子。
本文为《从零开始编写数据库系统:架构设计与实现》系列第5章,作者:安楠的数智笔记。未经授权,禁止转载。