你在 AI 编程工具里开发一个新功能,突然产品过来让修复一个紧急 bug。于是你开了两个 AI Agent:
- Agent A :在
feature/new-dashboard上写新功能 - Agent B :在
fix/login-bug上修一个登录 Bug
你心想:"两个 Agent 同时干活,效率翻倍。"
但三分钟后你回到编辑器,看到的是一幅这样的画面:
css
app/
├── dashboard.tsx ← Agent A 刚改了这里,但没写完
├── login.tsx ← Agent B 也改了这里,把 A 的改动覆盖了
├── utils.ts ← 两个 Agent 都在改,互相覆盖了三轮工作区一团乱麻,冲突标记满屏飞,两个 Agent 都以为自己在独占仓库。
这就是多 Agent 协作最大的痛点 :当多个 AI Agent 同时在同一个工作目录里操作时,它们会互相踩脚。
如何解决?答案就是 Git Worktree。
核心思路:给每个 Agent 一个独立工位
Git Worktree 允许你在同一个仓库上同时 checkout 多个分支到不同的目录。
核心命令只有4个:
bash
# 创建一个新的 worktree
git worktree add ../project-feature-b feature-b
# 列出所有 worktree
git worktree list
# 用完删除
git worktree remove ../project-feature-b
# 清理已被删除的 worktree 记录
git worktree prune使用流程也很简单:创建(add) -> 开发 -> 删除(remove) -> 清理(prune)。
这并不是 Git 的新功能,它已经存在 10 年了,为了解决多任务开发时来回切换分支导致冲突的情况。
你当然也可以使用 git clone 建两个仓库,但是 worktree 和复制多一个仓库相比,它共享对象存储、耗时更短、不留垃圾。
在多 Agent 场景下,多任务导致冲突的的情况更明显,worktree 被更多使用起来。
这是它在多 Agent 下的应用框架:
bash
主仓库: ~/project(你的主工作区)
├── Agent A 的工作区: ~/project-agent-a(git worktree add feature/new-dashboard)
├── Agent B 的工作区: ~/project-agent-b(git worktree add fix/login-bug)
└── Agent C 的工作区: ~/project-agent-c(git worktree add refactor/api)⚠️ 注意:这里主仓库跟工作区是同级目录。
多 Agent 有无 worktree 的情况对比:
| 维度 | 同一目录跑多 Agent | Worktree 隔离 |
|---|---|---|
| 工作目录 | 共享同一个目录 | 各自独立目录 |
| 文件改动 | 互相覆盖,冲突不断 | 完全隔离,互不影响 |
| Git 状态 | 被对方打断,git status 混乱 | 各管各的分支 |
| 依赖安装 | 可能互相破坏 | 各有独立 node_modules |
| 杀手级优势 | --- | 你可以在主工作区继续写代码 |
Agent 的 worktree 可看作是一个一次性沙箱------创建、工作、提 PR、删除,生命周期清晰干净。
工具支持情况
理解了 worktree 对 AI Agent 的价值之后,一个很自然的问题是:现在的 AI Coding 工具,哪些对 worktree 有原生支持?
答案是:分化很明显。
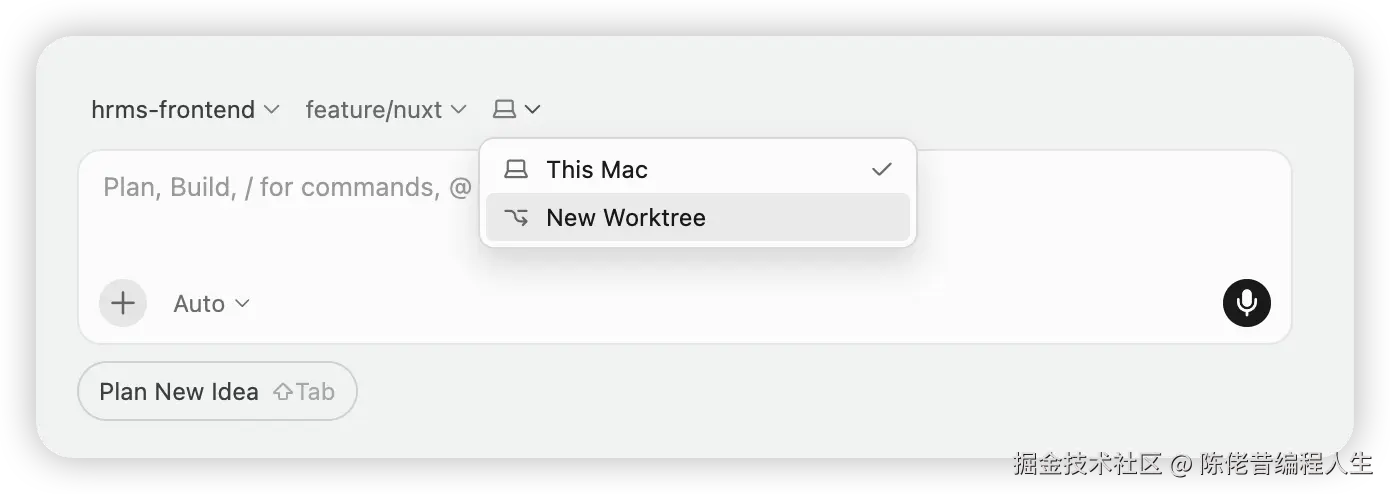
目前我只看到 Cursor 的 Agent 窗口有明显 Worktree 入口。选择之后,所有的修改都在 worktree 中进行。
而 cline 支持命令行操作:
bash
# 并行启动三个 Agent,各自在独立的 worktree 里工作
cline --cwd ~/project/agent-a -y "实现用户认证模块" &
cline --cwd ~/project/agent-b -y "撰写 API 文档" &
cline --cwd ~/project/agent-c -y "修复已知的 3 个 Bug" &
wait
echo "三个 Agent 均已完成任务!"除了 IDE 自身之外,还会有流程工具、skill等协助完成 worktree 流程,比如 SDD 工具 SpecKit 就会每一个需求建立一个 worktree。
当然作为一个存在已久的功能,即使不用专门的工具,你也可以通过自然语言操作它。
新建一个worktree,完成以下需求:【你的需求描述】甚至你可以把它放在系统提示词中,以减少自己每次判断是否要新建 worktree。
三种多 Agent 协作模式
模式一:领航员模式(1:1)
一个 Agent + 一个 Worktree,最基础的模式。
你指派每个 Agent 一个独立分支、一个独立 worktree,Agent 在 worktree 里改代码、提交、提 PR。你 review 合并后,删除 worktree 即可。
css
你 👉 Agent A → worktree-a(feature/new-dashboard)
你 👉 Agent B → worktree-b(fix/login-bug)
你 👉 Agent C → worktree-c(refactor/api)适用场景:功能明确、互不依赖的任务。
模式二:竞赛模式(N:1)
多个 Agent 在不同 worktree 里尝试同一个任务的不同方案,结束后比较结果,选最优的合并。
css
同一个任务:"优化数据库查询性能"
├── Agent A in worktree-a:方案 A --- 加索引
├── Agent B in worktree-b:方案 B --- 改写 SQL
└── Agent C in worktree-c:方案 C --- 引入缓存输入如下提示词:
bash
新建 worktree A,优化数据库查询,再新建一个 worktree B,用不同方式优化数据库查询最后,比较两个 worktree 的 benchmark 结果,选最优的合并。
适用场景:需要探索多种技术方案、不确定哪种最优的时候。不把鸡蛋放在一个篮子里。
模式三:流水线模式(1:N)
一个 worktree 的输出作为另一个 worktree 的输入,形成处理流水线。
bash
新建 worktree a,为 auth 模块写单元测试;
完成后,新建 worktree b,实现 auth 模块,确保通过 worktree a 里的测试;或者更精妙的------先试错,再纠正:
bash
新建 worktree a,尝试重构 auth 模块,如果失败只输出失败原因
如果 worktree a 失败了,这是原因。用不同的方法在 worktree b 里实现适用场景:任务之间有依赖关系,需要接力完成。
最佳实践:如何安全地让多个 AI Agent 同时工作
1. 一个 Agent 一个分支
命名规范:
bash
Agent A → agent/feat/new-dashboard
Agent B → agent/fix/login-bug
Agent C → agent/refactor/api用 agent/ 前缀统一标识,方便后续批量清理。
2. 任务粒度要恰当
每个 Agent 的任务粒度很重要:
- 太小(改一行配置)→ worktree 的开销 > 收益
- 太大(重构整个项目)→ 等太久,worktree 分支落后太多
合适的粒度:一个 Agent 完成一个可独立提 PR 的功能单元(一个模块、一个功能、一组相关的修复)。
3. 用完即弃
bash
# Agent 完成任务后:
git worktree remove ../project-agent-a
git worktree prune不要让 worktree 堆积。每次 Agent 任务完成后,合并 PR → 删除 worktree → 清理记录。保持整洁。
4. 用 .gitignore 保护 worktree 目录
如果你把 worktree 放在项目目录下(如 .worktrees/),一定确保它们被 gitignore 了:
gitignore
.worktrees/否则你的 git status 会看到成百上千个"变化文件",因为 worktree 里的改动会被主仓库看到。
5. 预留"缓冲区"
不要让 Agent 分支直接从 main 拉出后长时间不合并。如果 Agent 任务预计耗时较长(超过半天),定期让 Agent 把主分支的最新代码合并进来。
总结
AI 多 Agent 协作不是未来的概念------它现在就发生在你的编辑器里。而 Git Worktree 解决了多 Agent 协作的核心问题:工作区隔离。
多 Agent 协作 = Agent 能力 × Worktree 隔离 × 任务编排缺了任何一环,多 Agent 带来的就不是效率提升,而是混乱。有了 worktree 支撑,你就可以放心地让多个 AI Agent 同时为你工作,而不必担心它们互相踩脚。
你用过多 Agent + Worktree 的方案吗?踩过哪些坑?欢迎在评论区分享。