文章目录
- 一、前言
- [二、Kafka 核心概念](#二、Kafka 核心概念)
-
- 1.基本操作
- [2.Kafka Tool](#2.Kafka Tool)
- 三、Java中操作Kafka
- 四、Kafka的幂等性
- 五、分区和副本策略
-
- 1.生产者分区写入策略
- 2.消费者组Rebalance机制(再均衡)
- 3.消费者分区分配策略
-
- [(1)Range 范围分配策略(默认)](#(1)Range 范围分配策略(默认))
- (2)RoundRobin轮询策略
- (3)Stricky粘性分配策略(推荐)
- 4.生产者的ACK机制
- 六、高级API与低级API
-
- [1. 高级 API(High-Level Consumer API)](#1. 高级 API(High-Level Consumer API))
- [2. 低级 API(Low-Level Consumer API)](#2. 低级 API(Low-Level Consumer API))
- [3. 手动消费分区数据(低级 API 示例)](#3. 手动消费分区数据(低级 API 示例))
- 七、Leader和Follower
-
- 1.AR、ISR、OSR
- 2.Controller与Leader选举
-
- [(1)Controller 的选举过程](#(1)Controller 的选举过程)
- [(2)Partition Leader 的选举过程](#(2)Partition Leader 的选举过程)
- 3.Leader的负载均衡
- 八、生产消费数据的工作流程
- 九、kafka数据的存储格式
- 十、消息不丢失
-
- 1.Broker数据不丢失------副本
- 2.生产者数据不丢失------ACK机制
- 3.消费者数据不丢失------offset管理
-
- [Exactly-Once 的实现](#Exactly-Once 的实现)
- 十一、数据积压
- 十二、数据清理
- 十三、面试问题
一、前言
Kafka 作为 Apache 基金会的顶级项目,由 LinkedIn 于 2011 年开源,已从最初的消息队列演化为一个成熟的分布式事件流平台------既能做消息缓冲,也能做日志采集、实时数据管道和流处理。
1.消息队列作用
- 缓冲 / 削峰:生产者瞬时流量远大于消费者处理能力时,Kafka 作为中间缓冲层,吸收峰值流量,防止下游系统被压垮。秒杀系统、日志采集、活动流量缓冲等场景都是典型应用。
- 系统解耦:引入 Kafka 后,上游系统只需往 Kafka 写入消息,下游系统自行订阅感兴趣的 Topic。上下游独立演进,新增消费者不影响生产者,下游故障也不会直接拖垮上游。
- 异步通信:用户注册等场景中,核心流程(写数据库)与耗时操作(发短信、发邮件)解耦,用户注册 → 写数据库 → 写 Kafka → 立即返回结果,非核心流程由消费者异步完成,接口响应速度显著提升。
2.消息队列的两种模型
- 点对点模型:消息被一个消费者消费后,通常会被删除。一条消息只被一个消费者处理,更像传统的队列。
- 发布订阅模型:消息按 Topic 分类,不同消费者组之间互不影响,每个消费者组都可以消费完整数据。Kafka 更接近发布订阅模型。
二、Kafka 核心概念
Kafka 本质上是一个分布式、高吞吐、可持久化、基于发布/订阅模型的事件流平台。其基本架构如下,图片来源
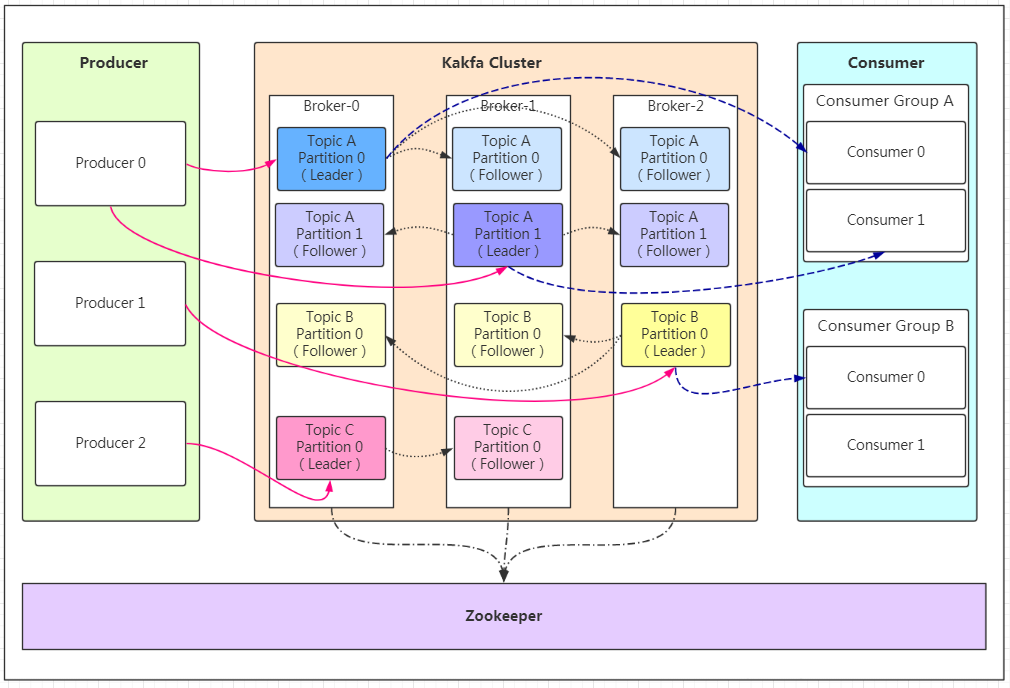
- Broker(代理) :一台 Kafka 服务器即为一个 Broker,多个 Broker 组成 Kafka 集群。
- Topic(主题) :消息的逻辑分类。
- Partition(分区) :Topic 被切分为多个分区,每个分区是一个有序的提交日志文件,是 Kafka 实现水平扩展和并发的核心机制。
- Replica(副本):每个 Partition 可以拥有多个副本,分布在不同的 Broker 上。副本分为 Leader(领导者)和 Follower(追随者)。Leader 负责所有读写请求,Follower 只被动地从 Leader 同步数据。当 Leader 故障时,某个 Follower 会被选举为新的 Leader。副本机制是 Kafka 高可用和数据不丢失的基础。
- Producer(生产者) :负责将消息发布到 Topic 的客户端。
- Consumer(消费者) :从 Topic 读取消息的客户端。
- Consumer Group(消费者组) :多个消费者组成一个 Consumer Group,组内的每个消费者负责消费不同的 Partition,实现并行消费。同一个 Partition 只能被组内的一个消费者消费。
- Zookeeper:保存集群的的元信息,来保证系统的可用性。
- Offset(偏移量):消息在 Partition 中的位置标识。消费者消费消息后,会提交(Commit)已处理的 Offset,记录消费进度。如果消费者组重启,将从提交的 Offset 恢复消费。
分区的数量没有上限,每个分区只有一个 Leader 副本负责读写,该 Leader 会落在某一个 Broker 上。其他 Broker 上可能存放该分区的 Follower 副本
分区的Leader 是动态分配的,可以落在任意 Broker 上,不是固定为 Broker1。Kafka 会尽量均匀分布。
副本因子不能超过 Broker 节点数
在同一个消费者组内,一个分区只能被该组内的一个消费者消费,上图理解为Consumer0消费了TopicA-Partition0,那么Consumer1就不能消费了,但是另一个消费者组B的Consumer0可以消费
当副本因子(replication factor)设置为 1 时,每个分区只有唯一的一个副本 Leader,负责该分区的所有读写请求。不存在 Follower
1.基本操作
现在有kafka集群kafka:9091、kafka:9092、kafka:9093。
(1)创建Topic主题
- kafka-topics.bat:管理 Topic 的工具。
- --create:执行创建操作。
- --bootstrap-server localhost:9091:告诉工具"集群入口在 localhost 的 9091 端口"。
- --replication-factor 1:每个分区的副本数量为 1(即没有额外备份)。
- --partitions 1:该 Topic 只包含 1 个分区。
- --topic test:要创建的主题名称是 test。
bash
kafka-topics.bat --create --bootstrap-server localhost:9091 --replication-factor 1 --partitions 1 --topic test(2)生产消息到kafka
- kafka-console-producer.bat:控制台生产者工具,从标准输入读取消息并发送到 Kafka。
- --broker-list localhost:9091:指定至少一个 Broker 地址作为初始连接。注意:生产者的参数是 --broker-list(而不是 --bootstrap-server,新旧版本差异;新版也支持 --bootstrap-server,但这里按你的参考文章保留传统写法)。
- --topic test:消息发送到的目标主题。
bash
kafka-console-producer.bat --broker-list localhost:9091 --topic test(3)从kafka消费
- kafka-console-consumer.bat:控制台消费者工具,从 Kafka 拉取消息并打印到标准输出。
- --bootstrap-server localhost:9091:消费者使用 --bootstrap-server 参数指定集群入口。
- --topic test:订阅的主题。
- --from-beginning:从该主题的最早消息开始消费(如果没有这个参数,只消费启动后产生的新消息)。
bash
kafka-console-consumer.bat --bootstrap-server localhost:9091 --topic test --from-beginning2.Kafka Tool
(1)搭建kafka集群
在本地或云服务器上搭建一个多节点的 Kafka 集群(至少 3 个 Broker)
文章参考:windows下kafka集群搭建
(2)创建Topic
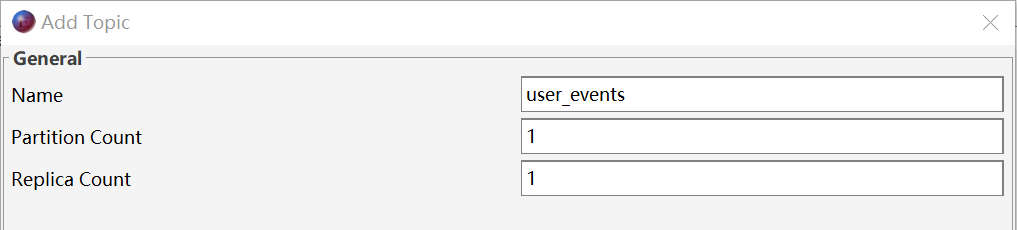
在 Offset Explorer 中,右键点击 Topics → Create Topic,弹出窗口需填写:
- Name:主题名称,如 user_events。
- Partition Count:分区数量。分区数越多,并行度越高,但也会增加 Leader 选举和元数据开销。一般根据预期吞吐量设置,可后期动态增加(但不能减少)。
- Replica Count:副本因子(Replication Factor)。每个分区的副本总数(包括 Leader)。例如设置为 3,表示每个分区有 1 个 Leader + 2 个 Follower。副本数越多,数据可靠性越高,但存储成本和网络同步开销也越大。生产环境通常设为 2 或 3。
三、Java中操作Kafka
1.导入依赖
在 Maven 项目的 pom.xml 中添加 Kafka 客户端依赖(建议使用与集群版本一致的最新稳定版)
xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>2.导入log4j.properties
将 log4j.properties 文件放入 src/main/resources 文件夹中,便于查看 Kafka 客户端运行日志:
properties
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n3.生产者使用同步的方式发送消息
同步发送:调用 send() 方法后,通过 Future.get() 阻塞等待 Kafka 的确认响应,能立刻知道发送结果,但吞吐量较低。
- bootstrap.servers:Kafka 集群地址(可写多个,逗号分隔)
- acks 表示当生产者生产的数据发送到Kafka中,Kafka会以什么样的策略返回
- 0:不等待确认(最快,可能丢消息)
- 1:仅 Leader 确认(折中)
- all 或 -1:所有 ISR 副本确认(最可靠)
- key.serializer / value.serializer:指定消息 key 和 value 的序列化方式(字符串、JSON、Avro 等)。
Kafka中的消息是以key、value键值对存储的,而且生产者生产的消息是需要在网络上传到Broker的,这里指定的是StringSerializer方式。
java
public class KafkaProducerTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.itcast.cn:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
// 3. 发送1-100的消息到指定的topic中
for(int i = 0; i < 100; ++i) {
// 构建一条消息,直接new ProducerRecord
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", null, "hello world-" + i);
// 利用Future<RecordMetadata>等待响应
Future<RecordMetadata> future = kafkaProducer.send(producerRecord);
// 调用Future的get方法等待响应
future.get();
System.out.println("第" + i + "条消息写入成功!");
}
// 4. 关闭生产者
kafkaProducer.close();
}
}4.生产者使用异步的方式发送消息
异步发送时,send() 方法立即返回,不阻塞;Kafka 收到响应后回调 onCompletion() 方法,适合高吞吐场景。
使用匿名内部类实现 Callback 接口,该接口中表示Kafka服务器响应给客户端,会自动调用OnCompletion方法
- metadata:消息的元数据(属于哪个topic,属于哪个partition,对应的offset是什么)
- exception:这个对象对Kafka生产消息封装了出现的异常,如果为null,表示发送成功,如果不为null,表示出现异常。
java
// 二、使用异步回调的方式发送消息
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic:"test", key:null, value:i + "");
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 1.判断发送消息是否成功
if(exception == null) {
// 发送成功
// 主题
String topic = metadata.topic();
// 分区id
int partition = metadata.partition();
// 偏移量
long offset = metadata.offset();
System.out.println("topic:" + topic + " 分区id:" + partition + " 偏移量:" + offset);
}
else {
// 发送出现错误
System.out.println("生产消息出现异常!");
// 打印异常消息
System.out.println(exception.getMessage());
// 打印调用栈
System.out.println(exception.getStackTrace());
}
}
});5.消费者拉取消息
消费者通过 poll() 不断拉取消息,自动或手动提交偏移量(offset)。
- group.id:消费者组的概念,可以在一个消费者组中包含多个消费者。如果若干个消费者的group.id是一样的,表示它们就在一个组中,一个组中的消费者是共同消费Kafka中topic的数据。
- Kafka是一种拉消息模式的消息队列,在消费者中会有一个offset,表示从哪条消息开始拉取数据
- KafkaConsumer.poll:Kafka的消费者API是一批一批数据的拉取
java
public class KafkaConsumerTest {
public static void main(String[] args) {
// 1.创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1.itcast.cn:9092");
// 消费者组(可以使用消费者组将若干个消费者组织到一起,共同消费Kafka中topic的数据)
// 每一个消费者需要指定一个消费者组,如果消费者的组名是一样的,表示这几个消费者是一个组中的
props.setProperty("group.id", "test");
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2.创建Kafka消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Arrays.asList("test"));
// 4. 使用一个while循环,不断从kafka的topic中拉取消息
while(true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// key\value
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
}
}
}四、Kafka的幂等性
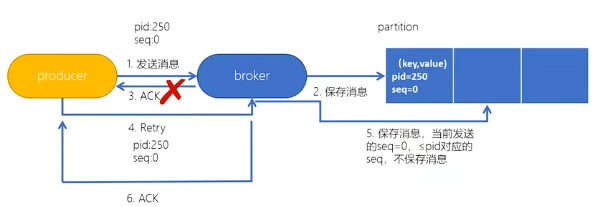
幂等性
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
五、分区和副本策略
1.生产者分区写入策略
生产者写入消息到 Topic 时,Kafka 会根据不同的分区写入策略将消息分配到不同的分区。分区的设计直接影响到消息的顺序性、并行度以及消费者的负载均衡。
(1)轮询分区策略
Kafka 默认的分区策略。消息依次轮流发送到每个可用分区。适用于无特殊顺序要求、无 key 的普通消息。
示例:假设 Topic 有 3 个分区,消息 1 → 分区0,消息2 → 分区1,消息3 → 分区2,消息4 → 分区0,以此类推。
(2)随机分区策略(不使用)
当前版本已不再使用
(3)按key分区分配策略
当消息指定了 key 时,Kafka 对 key 进行哈希计算,根据哈希值将消息分配到固定分区。相同 key 的消息永远进入同一个分区,从而保证分区内有序。但如果某个 key 的消息量极大,可能导致数据倾斜。
- 计算公式为:partition = murmur2(key_bytes) % numPartitions。murmur2表示一种非加密哈希函数,输入为 key 的字节数组,输出为 32 位整数。numPartitions是主题当前的分区总数。
(4)自定义分区策略
需要根据业务逻辑(如用户ID、地区、时间等)自行决定分区号。可以实现 Partitioner 接口,覆盖 partition() 方法。
java
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 自定义逻辑:例如将消息全部发到分区 0
return 0;
}
// 省略 close() 和 configure()
}使用时在生产者配置中指定:
java
props.put("partitioner.class", "com.example.CustomPartitioner");乱序问题
- Kafka 中,一个分区内的消息是严格有序的(写入顺序即消费顺序)。
- 跨分区的消息无法保证全局有序,因为不同分区可以并行写入/消费
如果业务要求消息严格按顺序处理(如订单状态流转),应将相关消息发送到同一个分区(使用相同的 key)。但这会牺牲一定的并行能力,Kafka 的分布式优势主要体现在高吞吐,而非全局顺序。
2.消费者组Rebalance机制(再均衡)
Rebalance 是 Kafka 保证消费者组内所有消费者公平分配订阅 Topic 的分区的核心机制。
Rebalance触发的时机有:
- 消费者组内成员变化:新消费者加入、现有消费者主动离开或崩溃(心跳超时)。
- 订阅的 Topic 数量变化:消费者组订阅的正则表达式匹配到了新 Topic,或 Topic 被删除。
- 订阅的分区数变化:管理员删除/增加了 Topic 的分区数。
Rebalance 的影响
- 发生 Rebalance 时,consumer group下的所有consumer都会协调在一起共同参与,Kafka使用分配策略尽可能达到最公平的分配。
- Rebalance 过程会对 consumer group 产生非常严重的影响,Rebalance 的过程中所有的消费者都将停止工作,直到Rebalance 完成。
3.消费者分区分配策略
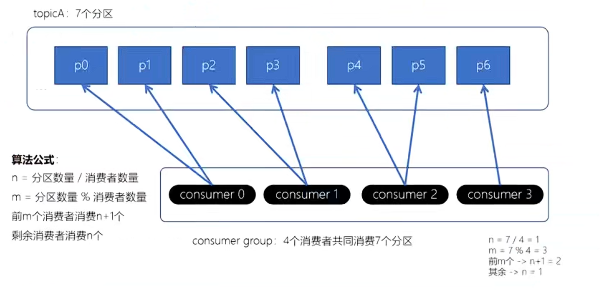
(1)Range 范围分配策略(默认)
按 Topic 逐个分配。将每个 Topic 的分区按数字顺序排序,消费者按名称排序,然后计算每个消费者应得的分区数。
算法公式
- n=分区数量/消费者数量。
- m=分区数量%消费者数量。
- 前m个消费者消费n+1个。
- 剩余消费者消费h个。
如下例所示,在同一个Topic A 中,存在7个分区,计算 n = 7 / 4 = 1,m= 7 % 4 = 3,那么前 3 个消费者消费两个分区,剩余消费者消息1个分区。
(2)RoundRobin轮询策略
按照整体的Topic进行分配,将所有订阅 Topic 的所有分区排序后,轮询分配给消费者
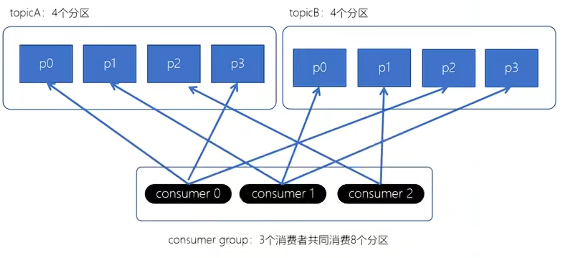
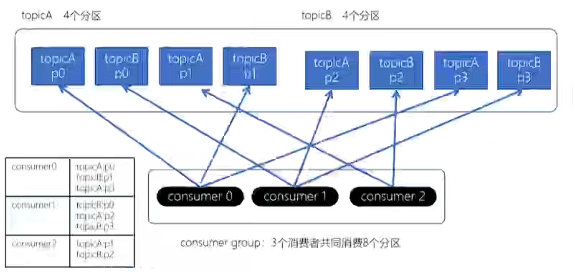
(3)Stricky粘性分配策略(推荐)
从Kafka0.11.x开始,引入此类分配策略。目标是使分区分配尽量均匀,同时解决前两种策略在 Rebalance 后分配变动过大的问题,分区的分配尽可能与上一次分配保持相同。
Striky粘性分配策略,保留rebalance之前的分配结果。这样可以明显减少系统资源的浪费。
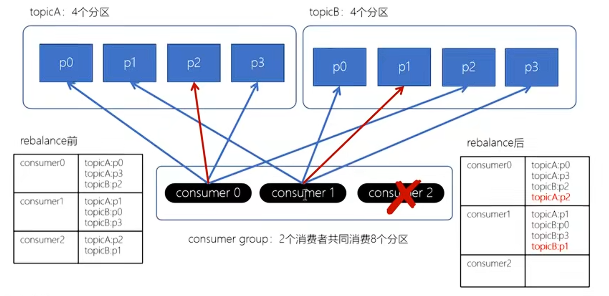
4.生产者的ACK机制
acks 参数控制生产者发送消息后,需要多少个副本确认才算成功。它直接影响可靠性和延迟。
- ACK=0:不等待broker确认,直接发送下一条数据,性能最高,但可能会存在数据丢失的情况。
- ACK=1等待leader副本确认接收后,才会发送下一条数据,性能中等。
- ACK=-1或者all:等待所有副本已经将数据同步后。
才会发送下一条数据,性能最慢。
根据业务情况来选择ack机制,是要求性能最高,一部分数据丢失影响不大,可以选择0。如果要求数据一定不能丢失,就得配置为-1/all。
六、高级API与低级API
Kafka 提供了两种消费者 API:高级 API 和 低级 API。它们的主要区别在于对偏移量(offset)、分区分配等底层细节的控制能力不同。
1. 高级 API(High-Level Consumer API)
高级 API 由 Kafka 统一管理分区、副本以及偏移量(offset),开发者无需关注底层细节。
- 不需要手动管理 offset,offset 会自动保存在 ZooKeeper 中。
- 消费者会根据上一次在 ZooKeeper 中保存的 offset 继续拉取数据。
- 不同的消费者组(group)消费同一个 Topic 时,ZooKeeper 会分别为每个组记录不同的 offset,互不影响。
- 分区分配由 Kafka 的 Rebalance 机制自动完成。
优点
- 开发简单,无需关注底层细节。
- 自动管理 offset,无需手动记录。
- 消费者组自动进行分区分配和 Rebalance。
缺点
- 不能控制 offset:例如无法从指定的任意位置开始读取。
- 不能细化控制:无法细化控制分区、副本、ZooKeeper 等底层细节。
2. 低级 API(Low-Level Consumer API)
低级 API 允许开发者自己控制 offset、连接分区、自定义负载均衡等。
- 可以自己控制 offset:想从哪儿读,就从哪儿读。
- 可以自己控制连接到哪个分区,并找到该分区的 Leader。
- offset 可以不使用 ZooKeeper 存储,而是自己选择存储位置,例如:文件、MySQL、Redis,甚至是内存中。
- 原有的 Kafka 自动分配策略会失效,需要自己实现消费机制。
特点
- 优点:细粒度控制(offset、分区、负载均衡等),适合高级场景。
- 缺点:开发复杂,需要手动处理 offset、分区连接、Leader 查找等。
3. 手动消费分区数据(低级 API 示例)
通常情况下,使用 subscribe() 方法让 Kafka 自动为消费者分配分区。但在某些场景下,我们需要指定要消费的分区,例如:
- 程序将某个指定分区的数据保存到外部存储(如 Redis、MySQL),只需要消费该指定分区。
- 程序具有高可用性,在故障重启时需要从指定的分区重新开始消费(如 Flink、Spark 应用)。
步骤:
- 不再使用 subscribe()方法订阅主题,而是使用 assign() 方法直接指定需要消费的分区。
- 指定分区后,像之前一样在循环中调用 poll() 方法消费消息。
java
// 指定要消费的分区
String topic = "test";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
// 然后正常 poll 消费
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
// 处理消息
}
}七、Leader和Follower
在Kafka中,每个topic都可以配置多个分区以及多个副本。每个分区都有一个 leader 以及0个或者多个follower,在创建topic时,Kafka会将每个分区的 leader 均匀地分配在每个broker上。
正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的 follower 都复制 leader 的日志数据文件,如果 leader出现故障时,follower就会被选举为 leader。
- Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步;
- 如果leader出现故障,其他follower会被重新选举为leader;
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中。
1.AR、ISR、OSR
选举之前,先要明确几个概念Kafka中,把follower可以按照不同状态分为三类AR、ISR、OSR
- 分区的所有副本称为「AR」(Assigned Replicas------已分配的副本)
- 所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成[ISR」(In-Sync Replicas------在同步中的副本)。
- 由于follower副本同步滞后过多的副本(不包括leader副本)组成[OSR」(Out-of-Sync Replias)
AR =ISR + OSR- 正常情况下,所有的follower副本都应该与leader副本保持同步,即AR=ISR,OSR集合为空。
2.Controller与Leader选举
因为 Kafka 的吞吐量很高、延迟很低,所以选举 Leader 必须非常快。
Kafka 启动时,会在所有的 Broker 中选择一个 Controller。注意:
- 前面所说的 Leader 和 Follower 是针对 Partition 层面的;
- 而 Controller 是针对 Broker 层面的。
创建 Topic、添加分区、修改副本数量等管理任务,都是由 Controller 完成的。Kafka 分区 Leader 的选举,也是由 Controller 决定的。
(1)Controller 的选举过程
- 在 Kafka 集群启动时,每个 Broker 都会尝试在 ZooKeeper 上注册成为 Controller(通过创建临时节点)。
- 最终只有一个 Broker 竞争成功,成为 Controller;其他 Broker 会注册该节点的监视器(Watcher)。
- 一旦该临时节点状态发生变化(例如 Controller 宕机导致节点消失),其他 Broker 会立即重新竞争,注册成为新的 Controller。
- Controller 也是高可用的:一旦某个 Broker 崩溃,其他 Broker 会重新注册为 Controller。
(2)Partition Leader 的选举过程
优先选ISR中的,如果全部宕机就设置Leader 为 -1(表示无可用 Leader)
所有 Partition 的 Leader 选举都由 Controller 决定:
- Controller 会将 Leader 的改变直接通过 RPC 的方式通知需要为此作出响应的 Broker。
- Controller 读取当前分区的 ISR,只要还有一个 Replica 幸存,就选择其中一个作为 Leader;
- 如果该 Partition 的所有 Replica 都已经宕机,则新的 Leader 为 -1(表示无可用 Leader)。
3.Leader的负载均衡
Leader选举后Topic1-Leader和Topic2-Leader都在同一个Broker ,此时需要进行负载均衡让Leader尽量均匀分配
在 ISR 列表中,第一个 Replica 就是 preferred-replica(优先副本)。
- 第一个分区存放的 Broker,就是 preferred-replica。
- Kafka 会尽量让 Leader 分布在不同的 Broker 上,并且可以通过工具触发优先副本的 Leader 选举,以实现 Leader 的负载均衡。
在生产环境中,定期执行 kafka-leader-election.sh 可以使 Leader 分布更加均匀,避免某个 Broker 承担过多的 Leader 角色。
八、生产消费数据的工作流程
1.生成数据流程
生产者向 Kafka 写入一条消息时,背后经历了以下步骤:
-
获取分区 Leader 信息
生产者首先向任意一个 Broker 发送 元数据请求 (实际开发中,生产者配置了 bootstrap.servers,会先连接该地址获取集群元数据)。
在旧版 Kafka(依赖 ZooKeeper)中,生产者可以从 ZooKeeper 的 /brokers/topics/{topic}/partitions/{partition}/state节点找到该分区的 Leader 所在的 Broker ID。
(新版本中,元数据通过 Broker 内部的 Metadata 请求获取,不再直接访问 ZooKeeper。)
-
连接 Leader Broker
生产者根据获取到的 Broker ID,连接到该 Broker 上的分区 Leader。
-
Leader 写入本地日志
Leader 将消息顺序追加到本地的分区日志文件(.log 文件)中。
-
Follower 同步数据
分区下的所有 Follower 副本(属于 ISR 集合中的)主动从 Leader 拉取新的消息,写入各自的本地日志文件中。
-
Follower 发送 ACK
每个 Follower 完成同步后,向 Leader 发送确认(ACK)。
-
Leader 返回 ACK 给生产者
当 Leader 接收到所有 ISR 副本的 ACK(具体数量由生产者 acks参数决定)后,才会向生产者返回成功响应。
简化理解:生产者找到分区的 Leader → Leader 存消息 → Follower 来复制 → 复制完成 → Leader 告诉生产者"成功"。
2.消费数据流程
Kafka 采用 拉取模型(Pull),消费者主动向 Broker 请求数据,而不是 Broker 主动推送。
-
确定消费分区
消费者加入消费者组后,根据分区分配策略(默认 RangeAssignor)获得自己要消费的分区列表。
-
获取消费偏移量(offset)
消费者从 内部主题 __consumer_offsets(旧版存在 ZooKeeper 中)读取自己对应的 offset。
- 如果是首次消费,根据 auto.offset.reset 配置决定从最早(earliest)或最新(latest)开始。
- 如果是续消费,则从上次提交的 offset 之后继续。
-
找到分区 Leader
消费者通过元数据请求找到每个分区当前的 Leader Broker(因为 Leader 可能发生切换)。
-
拉取消息
消费者向 Leader Broker 发送 Fetch 请求,拉取从指定 offset 开始的一批消息。
-
消费处理
消费者收到消息后执行业务逻辑(例如打印、存储、计算等)。
-
提交 offset
消费者消费完消息后,将当前已消费的 offset 提交到 __consumer_offsets 主题(自动或手动)。
- 自动提交:按固定时间间隔提交(enable.auto.commit=true)。
- 手动提交:调用 commitSync() 或 commitAsync() 精确控制提交时机。
重要特性:消费者可以任意重置 offset,从而重新消费历史消息或跳过某些消息。例如将 offset 重置为 0,即可从头开始消费。
九、kafka数据的存储格式
1.基本存储结构
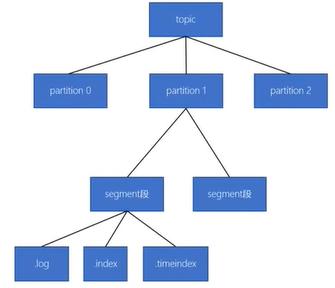
- 一个 Topic 可以包含多个 Partition(分区)
- 每个Partition 在磁盘上对应一个目录,目录中包含多个 Segment(段)
- 每个 Segment 由三个文件组成:
- .log 文件:实际存储消息数据
- .index 文件:稀疏索引,记录每条消息的 offset 在 .log 文件中的物理位置(偏移量)。方便根据 offset 快速定位消息。。
- .timeindex 文件:按时间戳索引,用于根据时间查找消息
Segment 可以理解为一个「数据分块」。Kafka 不会把所有消息塞进同一个大文件,而是把分区内的消息切分成多个小文件,每个小文件就是一个 Segment。
每个 Segment 有大小限制(默认 log.segment.bytes = 1GB,即 1024×1024×1024 字节)。当一个 Segment 写满 1GB 后,Kafka 会自动创建新的 Segment 文件继续写入。
删除过期消息时,直接删除整个 Segment 文件即可,便于消息清理 ,同时,根据 offset 可以快速定位到某个 Segment,再在 Segment 内查找具体消息,提高查找效率。
2.文件名规则
每个 Segment 的文件名都以该 Segment 中第一条消息的 offset 作为文件名(固定 20 位数字,不足前补零)。例如:
bash
00000000000000000000.log
00000000000000000123.log
00000000000000000456.log因为每个分区的起始 offset 是 0,所以第一个 Segment 的文件名一定是 00000000000000000000。
当第一个 Segment 写满 1GB 后,第二个 Segment 的第一条消息的 offset 是 123,那么它的文件名就是 00000000000000000123.log。
这种命名方式可以直接根据 offset 大小定位到对应的 Segment:Segment 文件名 ≤ 目标 offset < 下一个 Segment 文件名。
3.读取消息
假设消费者要读取分区中 offset = 350 的消息。查找步骤如下:
-
定位 Segment
由于每个 Segment 的文件名就是它的起始 offset,Kafka 会找到满足「起始 offset ≤ 350」的最大文件名。
例如:存在 00000000000000000300.log(起始 300)和 00000000000000000400.log(起始 400),则目标 Segment 是 00000000000000000300。
-
在 Segment 内查找
打开对应的 .index 文件,此时相对 offset = 50 ,每条消息大小不同,因此需要寻找在这个 .log 文件,二分查找 offset 350 在索引中的位置,获取该 offset 在 .log 文件中的物理偏移量(例如 2048 字节)。
-
读取消息
跳转到 .log 文件的 2048 字节位置,读取一条完整的消息返回。
二分查找 offset 350 在索引中的位置可能不会明确定位,例如二分查找到了40,得到前面 40 条消息总长度为 4096 字节,此时就需要从 4096 字节处开始,依次读取消息直到找到第50个消息处
注意:这里的 offset(例如 350)是相对于整个分区的全局 offset ,而每个 Segment 内部的索引是基于文件内局部偏移的。
4. 日志清理(消息过期删除)
Kafka 不会无限存储消息。它会根据配置定期删除旧的 Segment 文件。
- 删除策略:一次删除整个 Segment 文件,不会单独删除其中的某条消息。
- 触发条件(由 server.properties 配置):
- log.retention.hours:消息保留时间(默认 168 小时 = 7 天)
- log.retention.bytes:分区总大小限制(默认 -1,无限制)
- log.segment.bytes:单个 Segment 最大大小(默认 1GB)
- 执行方式:Kafka 的日志管理器(LogManager)会定期扫描,删除那些创建时间超过保留期限的 Segment 文件,或者当总大小超过限制时删除最老的 Segment。
正是因为按 Segment 为单位删除,Kafka 才能在不影响其他消息的情况下高效清理旧数据。
十、消息不丢失
1.Broker数据不丢失------副本
Broker 层面通过 多副本机制保证数据不丢失:
- 生产者将消息写入分区的 Leader 副本后,所有 ISR(In-Sync Replicas) 中的 Follower 会从 Leader 拉取数据并同步。
- 只要 ISR 中至少有一个 Follower 保持同步,即使 Leader 崩溃,Kafka 也能从 ISR 中选举出新的 Leader,已写入的消息不会丢失。
关键配置:
- min.insync.replicas:指定 ISR 的最小副本数(例如设为 2),配合生产者的 acks=all,确保消息至少被写入指定数量的副本后才算成功。
- unclean.leader.election.enable=false:禁止 ISR 以外的副本被选为 Leader,防止数据不一致。
2.生产者数据不丢失------ACK机制
生产者通过 ACK 机制 控制消息可靠性,共有三个可选配置:
| acks 值 | 含义 | 可靠性 | 性能 |
|---|---|---|---|
| 0 | 生产者只负责发送,不等待任何确认 | 最低(可能丢失) | 最高 |
| 1 | Leader 收到消息后即返回确认 | 中等(Leader 宕机会丢数据) | 中等 |
| all 或 -1 | Leader 等待所有 ISR 副本确认后才返回 | 最高 | 较低 |
生产者可以采用同步或异步两种方式发送数据:
- 同步发送:调用 send() 后等待 Future.get() 返回结果,能直接感知发送是否成功。
- 异步发送:提供回调函数(Callback),发送完成后回调 onCompletion() 方法,在回调中处理成功或失败逻辑。
注意事项:
- 如果 Broker 迟迟不返回 ACK(例如网络问题),生产者的缓冲区(buffer)可能填满。可以通过配置 max.block.ms 和 request.timeout.ms 来控制超时行为,也可以设置 retries 让生产者自动重试。
- 开启幂等性(enable.idempotence=true)可避免因重试导致的消息重复。
3.消费者数据不丢失------offset管理
消费者通过管理 offset(偏移量)来保证数据不丢失。核心原则是:先处理消息,后提交 offset。
- 消费者端的三种语义保障机制如下
| 语义 | 描述 | 实现方式 |
|---|---|---|
| At most once(最多一次) | 消息可能丢失,但不会重复处理 | 先提交 offset,后处理消息。若处理过程失败,消息不会重试。 |
| At least once(最少一次) | 消息不会丢失,但可能重复处理 | 先处理消息,后提交 offset。若提交前崩溃,重启后会重新消费。 |
| Exactly once(精确一次) | 消息既不丢失也不重复 | 需要结合幂等性、事务或外部存储的原子提交。 |
Exactly-Once 的实现
- 消息丢失:消费者先提交 offset,再处理消息。处理过程中消费者崩溃,重启后将从已提交的 offset 之后继续消费,导致崩溃前已拉取但未处理的消息丢失。
- 重复消费:消费者先处理消息,再提交 offset。若处理完成后、提交 offset 前消费者崩溃,重启后会重新消费该批消息,导致重复处理。
实现 Exactly-Once的方案如下:
-
使用数据库事务:将消费到的消息处理结果和该消息的 offset 保存在同一个数据库事务中,实现简单,但会降低吞吐量:
- 事务提交时,业务数据和 offset 同时持久化;
- 事务回滚时,两者都不生效,消费者可重新拉取并重试。
-
使用 Kafka 事务 API:该方案通常用于Kafka Streams 或需要同时读写 Kafka 的场景,配置复杂度较高。
- 生产者端设置 transactional.id,使用 beginTransaction() / commitTransaction() 包裹消息发送;
- 消费者端设置 isolation.level=read_committed,只读取已提交的事务消息。
-
借助流处理框架:在 Flink、Spark Streaming 等流处理框架中,框架本身提供了 Exactly-Once 保障:
实践建议:对于大多数业务系统,数据库事务方案是最直观可靠的选择。如果对吞吐量要求极高且上下游都是 Kafka,可考虑 Kafka 事务 API。
十一、数据积压
数据积压(Message Backlog)指生产者发送消息的速度超过了消费者处理消息的速度,导致未消费的消息在 Kafka 中不断堆积,消费者 Lag(滞后)越来越大。
常见原因
- 消费者处理能力不足:消费者业务逻辑复杂(如写数据库、调用外部接口),单条消息处理耗时过长。
- 网络延迟:消费者与 Kafka Broker 之间的网络不稳定,拉取数据耗时增加。
- 下游系统故障:例如消费者将数据写入 MySQL 时,MySQL 连接超时或写入失败,导致消费者阻塞或不断重试。
- 分区数不足:消费者组内的消费者数量远小于分区数,单个消费者需要处理多个分区,负载过高。
- 消费者 Rebalance 频繁:频繁的 Rebalance 会导致消费者短暂停止工作,加剧积压。
积压的解决办法
- 增加消费者数量(不超过分区数):优化消费者业务逻辑,减少单条消息处理时间;
- 增加 Topic 的分区数(注意:分区数只能增加不能减少);
- 监控消费者 Lag 指标(如使用 Kafka 自带的 kafka-consumer-groups 命令或 Prometheus 等),设置阈值告警,提前干预。
- 确保下游存储(如 MySQL、Redis)性能足够,或使用异步写入方式。
十二、数据清理
Kafka 的消息存储在磁盘中,为了控制磁盘占用空间,需要定期清理过期或不再需要的消息。清理的基本单位是 Segment(日志分段)。Kafka 提供了两种日志清理方式:
- 日志删除(Log Deletion):按照时间或大小直接删除符合条件的 Segment 文件。
- 日志压缩(Log Compaction):针对有相同 key 的消息,只保留最新的 value(适用于维护状态类数据,如配置变更)。
(1)基于时间的保留策略
Kafka 通过以下参数设置消息保留时间,超时后自动删除:
- log.retention.hours 保留小时数(默认 168,即 7 天)
- log.retention.minutes 保留分钟数
- log.retention.ms 保留毫秒数(优先级最高)
优先级:log.retention.ms >log.retention.minutes > log.retention.hours。
如果同时配置了多个,Kafka 会使用优先级最高的那个。
(2)基于日志大小的保留策略
通过 log.retention.bytes 参数限制分区总大小(默认 -1,表示无限制)。当日志总大小超过该阈值时,Kafka 会删除最旧的 Segment 文件,直到总大小低于阈值。
注意:这里针对的是每个分区的大小(而非 Topic 总大小)。如果要限制 Topic 总大小,需要将 log.retention.bytes 乘以分区数。
(3)删除过程:当满足时间或大小条件时,Kafka 的日志清理定时任务会执行以下步骤:
- 标记删除:从日志文件对象维护的跳跃表(索引结构)中移除待删除的 Segment,确保没有线程正在读取这些文件。
- 重命名文件:将待删除的 .log、.index、.timeindex 文件添加 .deleted 后缀(例如 00000000000000000000.log.deleted)。
- 物理删除:Kafka 的后台线程会定期扫描 .deleted 后缀的文件,并根据 file.delete.delay.ms 参数(默认 60000 毫秒,即 1 分钟)延迟后真正删除文件。
这种先标记、后删除的机制保证了正在被读取的 Segment 不会突然消失,避免读取异常。
十三、面试问题
1.Kafka 和 RocketMQ、RabbitMQ的区别
| 对比维度 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 开发语言 | Scala/Java | Java | Erlang |
| 核心定位 | 高吞吐分布式流处理平台 | 金融级互联网消息中间件 | 企业级通用消息中间件 |
| 原生场景 | 海量日志/事件采集、实时流计算、大数据管道 | 电商/金融核心业务、事务消息、顺序消息 | 企业异构系统通信解耦、复杂路由 |
| 吞吐量 | 百万级 TPS(最高) | 十万级 TPS | 万级 TPS |
| 延迟 | 毫秒级(约 2-5ms) | 毫秒级 | 微秒级(最低延迟) |
| 消息模型 | 发布/订阅(拉模式) | 发布/订阅(拉模式+推模式) | 点对点 + 发布/订阅(推模式为主) |
| 顺序消息 | 分区内有序 | 支持严格全局有序 | 队列内有序 |
| 事务消息 | 支持(0.11+版本) | 原生支持(金融级) | 不支持 |
| 延迟消息 | 不支持(需插件) | 原生支持 | 原生支持(插件增强) |
| 死信队列 | 不支持原生 | 支持 | 支持 |
| 存储设计 | 分区顺序日志(磁盘) | 顺序写 + 索引 | 内存 + 磁盘 |
| 海量堆积性能 | 无性能损耗 | 10亿级无性能下降 | 海量堆积性能急剧下降 |
| 扩展方式 | 水平扩展(增加分区/Broker) | 水平扩展 | 镜像集群,横向扩容弱 |
| 协议支持 | Kafka 自定义协议 | 兼容 RocketMQ 协议 + 部分 Kafka 协议 | AMQP 协议(跨语言优势强) |
| 生态集成 | 大数据生态完善(Flink、Spark、Hadoop 等) | 阿里生态为主 | 多语言客户端成熟 |
2.Kafka 高吞吐的原因/原理?
- 分区并行架构 :一个 Topic 可以拆分为多个 Partition,分布在不同 Broker 节点上。生产者和消费者可以并行地向不同分区写入和读取数据,吞吐量随分区数线性提升。同一消费者组内,每个分区只被一个消费者消费,避免了消费竞争。
- 顺序写入 + 页缓存 :Kafka 采用追加写入 的方式,数据按到达顺序追加到日志文件末尾,磁盘顺序写入速度接近内存(比随机写入快 10 倍以上)。消息写入时先落入操作系统页缓存(Page Cache) ,由操作系统异步刷盘,生产者无需等待实际磁盘 I/O 完成,极大减少写入阻塞。读取时优先从页缓存命中,热点数据常驻内存,降低了磁盘物理 I/O 频率
- 零拷贝技术:Kafka 利用操作系统 sendfile系统调用,实现数据直接从内核 Page Cache 传输到 Socket 缓冲区,绕过了「磁盘 → 内核 → 用户态 → 内核 → Socket」的多次数据拷贝,大幅减少 CPU 和内存开销,显著提升网络传输效率
- 批量处理与压缩:生产者通过 batch.size(默认 16KB)积攒消息,批量发送到 Broker,减少网络请求次数;消费者通过 fetch.min.bytes 批量拉取数据,降低交互开销reference:15。同时,Kafka 支持 GZIP、Snappy、LZ4、ZSTD 等压缩算法,批量压缩后传输可减少 3-5 倍网络带宽和磁盘存储占用。
3.Kafka 如何保证顺序读取消息
- Kafka 仅保证单分区内的消息有序,跨分区不保证全局顺序。
- 生产者端确保消息顺序:为了保证消息写入同一分区从而确保顺序性,生产者需要将消息发送到指定分区。可以通过自定义分区器来实现,通过为消息指定相同的Key,保证相同Key的消息发送到同一分区。
- 消费者端保证顺序消费:消费者在消费消息时,需要单线程消费同一分区的消息,这样才能保证按顺序处理消息。如果使用多线程消费同一分区,就无法保证消息处理的顺序性。
4.RocketMQ相较于Kafka的核心区别?
RocketMQ诞生于阿里巴巴双十一高并发场景,核心目标是高可靠性和复杂业务逻辑支撑(支付、订单、库存等对数据一致性要求极高的业务)
- 消息确认机制的核心差异
- 生产者确认机制:两者都支持配置,但Kafka的acks参数本质上是异步刷盘的多种等待策略 ,不提供同步刷盘选项;RocketMQ则提供同步刷盘和同步双写两种更强力的选择,将消息真正写入磁盘或复制到从节点后才返回确认。
- 消费者端的确认机制:Kafka基于Offset机制 。消费者消费后需提交Offset,但Kafka不支持消费者主动发送ACK;RocketMQ支持显式ACK确认机制。消费者处理完消息后需向Broker发送ACK,Broker才认为消息已成功消费;否则触发消息重试,消息会重新投递给其他消费者。
- Broker架构差异
- 元数据管理:Kafka早期依赖ZooKeeper管理集群元数据,功能强大但较重,Kafka 2.8开始引入KRaft模式 逐步替代ZooKeeper。RocketMQ采用自研的NameServer,一个极其轻量、无状态的组件,节点间不直接通信,通过Producer和Consumer定期上报信息更新元数据。
存储模型(最核心):Kafka每个Partition对应一组独立的日志文件(Segment),多Topic多Partition时磁盘上文件数量爆炸,写入不同Topic的Partition可能变成随机写,造成性能下降。RocketMQ单个Broker下所有Topic的消息全部写入一个统一的CommitLog文件,从根本上将随机写变为单一文件顺序追加,所有Topic共享一个文件,数据刷盘时没有文件切换开销。(Kafka多Topic多Partition多Segment的时候文件爆炸,RocketMQ单个Broker下所有Topic写入统一的文件)
- 高可用机制:Kafka副本基于Partition维度,Leader可自动切换到Follower。 RocketMQ副本基于Broker维度。Master宕机时,读请求可路由到Slave,但写请求会被路由到该Topic的其他Broker,不会自动将Slave升级为Master。