文章目录
-
- 第一部分:入门基础------理解消息队列的本质
-
- [1. 什么是消息队列?为什么需要它?](#1. 什么是消息队列?为什么需要它?)
- [2. RabbitMQ 的核心概念模型](#2. RabbitMQ 的核心概念模型)
-
- [2.1 交换机(Exchange)](#2.1 交换机(Exchange))
- [2.2 队列(Queue)](#2.2 队列(Queue))
- [2.3 绑定(Binding)](#2.3 绑定(Binding))
- [2.4 消息(Message)](#2.4 消息(Message))
- 第二部分:进阶掌握------路由与消费模式
-
- [1. 路由机制的精细化控制](#1. 路由机制的精细化控制)
- [2. 消费模式的选择与优化](#2. 消费模式的选择与优化)
-
- [2.2.1 队列的消费模式(Consumption Patterns)](#2.2.1 队列的消费模式(Consumption Patterns))
- [2.2.2 消息确认机制(ACK/NACK)](#2.2.2 消息确认机制(ACK/NACK))
- 第三部分:精通境界------高可用、高性能与复杂场景
-
- [1. 消息的可靠性保障(The Three Pillars)](#1. 消息的可靠性保障(The Three Pillars))
-
- [1.1. 生产者端可靠性(确保消息不丢失)](#1.1. 生产者端可靠性(确保消息不丢失))
- [1.2. 队列和交换机持久化(确保基础设施不丢失)](#1.2. 队列和交换机持久化(确保基础设施不丢失))
- [1.3. 消费者端可靠性(确保消息不重复、不丢失)](#1.3. 消费者端可靠性(确保消息不重复、不丢失))
- [2. 高可用与集群部署](#2. 高可用与集群部署)
- [3. 性能优化与调优](#3. 性能优化与调优)
- [4. 高可用架构设计(Quorum Queues)](#4. 高可用架构设计(Quorum Queues))
- 总结与最佳实践
在现代的分布式系统中,服务之间的解耦、异步通信和可靠的数据传输是核心挑战。消息队列(Message Queue, MQ)正是解决这些问题的关键基础设施。而 RabbitMQ,作为业界最成熟、功能最丰富的消息代理之一,一直是企业级应用的首选。
本文旨在带领读者从 RabbitMQ 的基础概念出发,逐步深入到其高级特性、性能优化,最终达到能够设计和部署高可用、高吞吐量消息系统的精通境界。
第一部分:入门基础------理解消息队列的本质
1. 什么是消息队列?为什么需要它?
想象一个大型电商系统:用户下单(生产者),库存服务、支付服务、订单服务都需要知道这个事件。如果生产者直接调用这三个服务,那么:
- 耦合度高: 生产者必须知道所有下游服务的地址和接口。
- 容错性差: 如果支付服务宕机,整个下单流程可能会失败,影响用户体验。
- 同步阻塞: 生产者必须等待所有下游服务都响应,造成延迟。
消息队列(MQ)的引入,将这些服务之间的调用关系,从同步的、点对点的调用 ,转变为异步的、基于事件的发布/订阅模式。
核心价值:
- 解耦(Decoupling): 生产者只知道消息队列,不知道任何消费者。
- 异步(Asynchronous): 生产者发送消息后立即返回,无需等待下游处理结果。
- 削峰(Throttling): 当突发流量(如秒杀活动)到来时,MQ 充当缓冲区,平滑地将流量分发给消费者,防止后端服务过载崩溃。
2. RabbitMQ 的核心概念模型
RabbitMQ 基于 AMQP(Advanced Message Queuing Protocol)协议实现,其核心模型包括以下几个关键组件:
2.1 交换机(Exchange)
交换机是消息的入口点。生产者不会直接将消息发送到队列,而是发送给一个交换机。交换机负责根据预设的路由规则(Binding Key),将消息转发给一个或多个队列。
2.2 队列(Queue)
队列是消息的存储地。消息到达交换机后,最终会进入一个或多个队列中等待被消费者消费。队列是消息的消费者端接收的"缓冲区"。
2.3 绑定(Binding)
绑定是连接交换机和队列的规则。它定义了"当消息携带特定路由键时,应该将消息发送到哪个队列"。一个交换机可以绑定多个队列,实现一对多、多对多的消息分发。
2.4 消息(Message)
消息是实际承载业务数据的载体,通常包含:
- Payload: 实际的业务数据(如 JSON 字符串)。
- Properties: 元数据,如消息类型、持久化标志、优先级等。
- Routing Key: 路由键,用于交换机进行路由决策。
第二部分:进阶掌握------路由与消费模式
理解了基础组件后,我们需要掌握如何利用它们实现复杂的业务逻辑。
1. 路由机制的精细化控制
RabbitMQ 提供了多种类型的交换机,以满足不同的路由需求:
- Direct Exchange (直连): 最简单直接。消息的
Routing Key必须与绑定的Binding Key完全匹配,消息才会投递。适用于"一对一"或"多对一"的精确路由。 - Fanout Exchange (扇出): 消息发送到此交换机后,会无差别地复制并发送给所有绑定到它的队列。适用于"一对多"的广播场景(如系统通知、日志记录)。
- Topic Exchange (主题): 最灵活、最强大的类型。它支持使用通配符(
*和#)进行模式匹配。*:匹配单个单词(例如:user.*可以匹配user.create但不能匹配user.login)。#:匹配零个或多个单词(例如:user.#可以匹配user.create和user.login.details)。
实战场景: 如果我们需要处理所有与"用户"相关的事件,无论事件类型如何(创建、登录、删除),Topic Exchange 结合 user.# 的绑定,就能完美实现。
2. 消费模式的选择与优化
消费者如何接收消息,决定了系统的可靠性和性能。
2.2.1 队列的消费模式(Consumption Patterns)
- 点对点(Point-to-Point): 最常见的模式。消息从队列中被一个消费者取出,并被标记为已消费(ACK)。队列中同一条消息只能被一个消费者处理。
- 发布/订阅(Publish/Subscribe): 利用 Fanout 或 Topic Exchange 实现。消息被复制并发送给所有订阅者。
- 工作队列(Work Queue / Competing Consumers): 多个消费者连接到同一个队列,它们会竞争消费消息。这确保了消息的唯一性,但需要注意,如果消费者处理速度不一致,可能会导致某些消费者长时间处于忙碌状态。
2.2.2 消息确认机制(ACK/NACK)
这是保证消息可靠性的基石。
- 自动确认(Auto-Ack): 消费者一收到消息,MQ 立即认为消息已成功处理,并将其从队列中移除。(风险极高,不推荐用于业务消息)
- 手动确认(Manual-Ack): 消费者必须在业务逻辑处理完成后,主动向 MQ 发送确认信号(ACK)。只有收到 ACK,消息才会被移除。
- 拒绝与重试(NACK/Reject): 如果消费者处理失败(如业务数据格式错误),可以发送 NACK。MQ 可以根据配置,将该消息重新放回队列(重试),或将其发送到死信队列(DLX)。
第三部分:精通境界------高可用、高性能与复杂场景
达到精通级别,意味着你不仅知道如何让消息流动起来,更知道如何在系统故障、流量洪峰和复杂业务规则下,保证消息的不丢失、不重复、不误到。
1. 消息的可靠性保障(The Three Pillars)
1.1. 生产者端可靠性(确保消息不丢失)
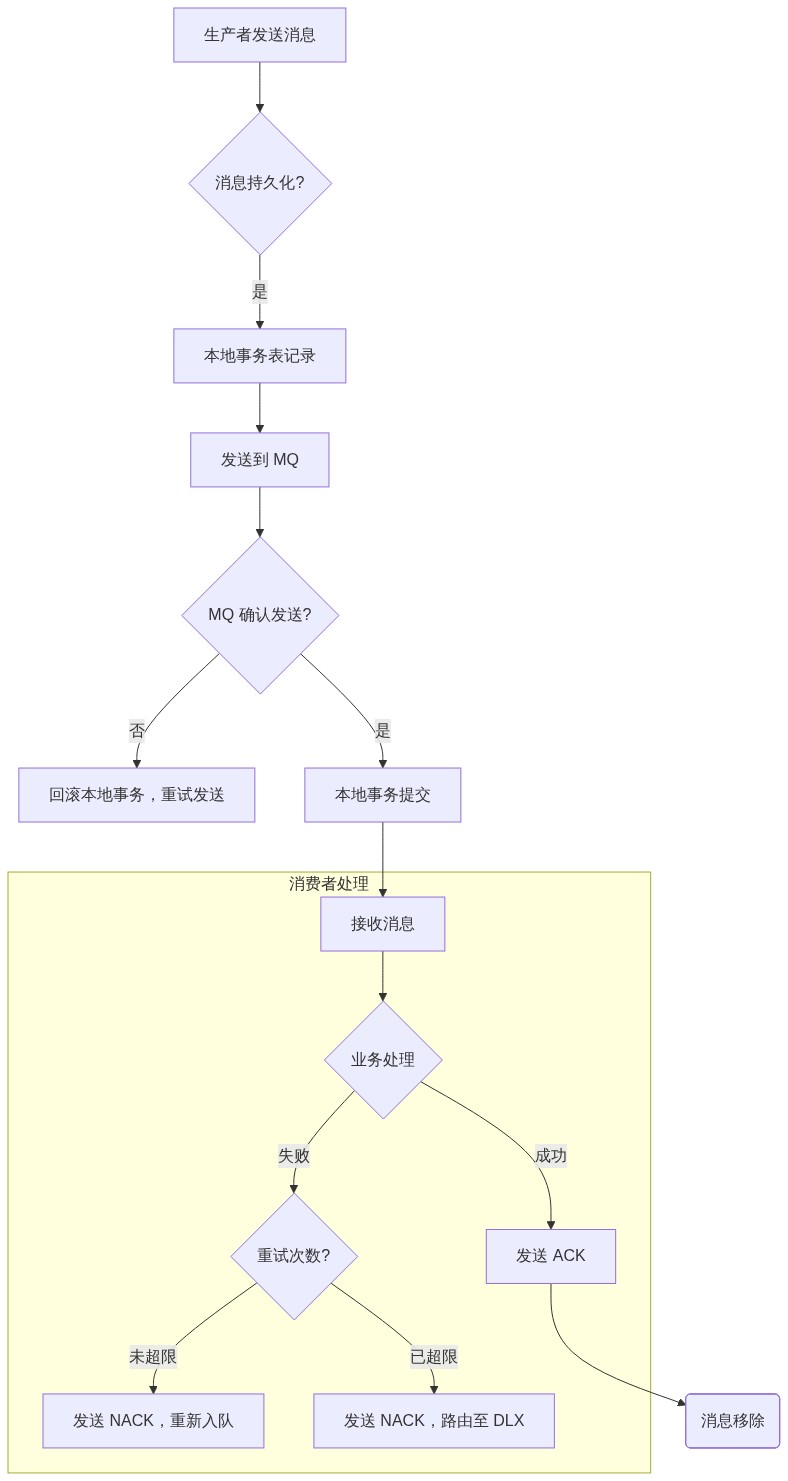
生产者发送消息时,必须设置消息的**持久化(Durable)标志,并确保连接和通道也是持久化的。更重要的是,需要实现本地消息表(Local Transaction)**机制:
- 业务操作(如扣减库存)写入本地数据库。
- 消息发送到 MQ。
- 只有当 MQ 发送成功后,才提交数据库事务。
如果 MQ 发送失败,则回滚本地事务,重试发送。
1.2. 队列和交换机持久化(确保基础设施不丢失)
必须将队列和交换机都设置为持久化(Durable) ,并确保消息本身也设置了持久化(Persistent)。这样,即使 RabbitMQ 节点重启,队列结构和消息内容依然存在。
1.3. 消费者端可靠性(确保消息不重复、不丢失)
- 幂等性(Idempotency): 这是最重要的概念。由于网络抖动、重试机制的存在,消息可能会被消费多次。消费者必须设计成"多次处理一次结果不变"的幂等逻辑。通常的做法是在消息体中携带全局唯一的
Message ID,并在数据库写入前,先检查该 ID 是否已处理过。 - 死信队列(Dead Letter Exchange, DLX): 当消息处理失败达到最大重试次数,或者被手动拒绝,不应该让它无限循环重试。此时,应将消息路由到 DLX,并由专门的监控服务进行人工介入或分析。
2. 高可用与集群部署
单个 RabbitMQ 节点无法满足生产环境的可用性要求。
- 集群(Clustering): 部署多个 RabbitMQ 节点,它们共同组成一个集群。
- 镜像队列(Mirrored Queues): 为了实现高可用,需要将关键队列设置为镜像队列。当一个节点宕机时,其他节点可以立即接管该队列的全部消息,保证服务不中断。
- Quorum Queues (法定人数队列): 这是 RabbitMQ 3.8+ 引入的更先进的机制,它基于 Raft 协议,提供了更强的数据一致性和更简单的故障切换机制,是目前推荐的生产环境选择。
核心组件
客户端应用/BI工具
网络协议
SQL Server 实例
查询解析器/优化器
查询执行引擎
内存管理/缓存 (Buffer Pool)
事务管理器 (Transaction Manager)
存储引擎 (Storage Engine)
文件系统/磁盘 I/O
3. 性能优化与调优
在处理每秒数万条消息的场景下,性能是关键。
- 批量发送与消费(Batching): 无论是生产者还是消费者,都应尽量采用批量发送和批量消费的方式,减少网络往返次数(Round Trip Time, RTT)。
- 内存与磁盘配置: 调整 RabbitMQ 的内存使用限制和磁盘 I/O 策略。对于高吞吐量场景,确保消息的持久化策略不会成为性能瓶颈。
- 消费者并发度(Concurrency): 适当调整消费者线程池的大小。过大会导致资源争抢和上下文切换开销;过小则无法充分利用硬件资源。最佳并发度需要根据业务负载和机器性能进行实验确定。
4. 高可用架构设计(Quorum Queues)
在设计高可用架构时,理解传统镜像队列的局限性至关重要。传统镜像队列的同步和故障切换机制相对复杂。
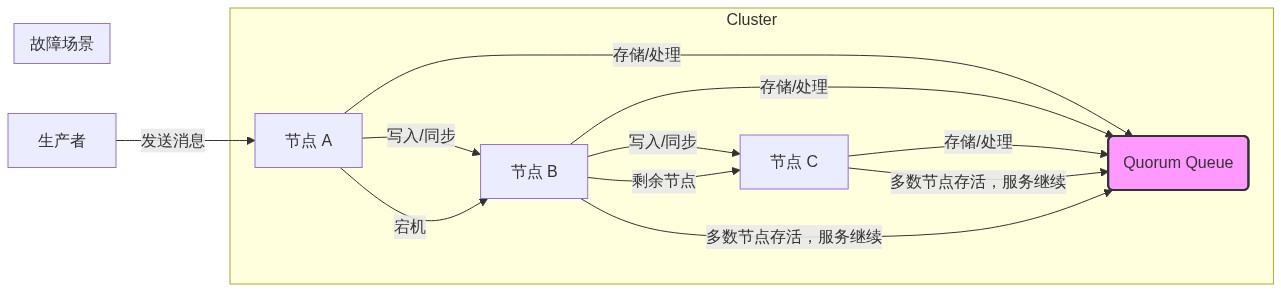
Quorum Queues (法定人数队列) 是基于分布式共识算法(Raft)实现的,它将队列本身视为一个分布式状态,保证了数据在集群节点间的强一致性。
工作流程:
- 消息写入时,需要获得集群中多数节点(Quorum)的确认。
- 即使部分节点宕机,只要多数节点存活,消息写入和读取操作依然可以继续,从而实现了更平滑、更可靠的故障切换。
总结与最佳实践
从入门到精通,RabbitMQ 的学习路径是一个从"能用"到"可靠"再到"极致稳定"的过程。
| 阶段 | 核心知识点 | 目标 | 关键实践 |
|---|---|---|---|
| 入门 | 交换机、队列、绑定、基本发送/接收 | 实现基础的异步通信。 | 掌握 Fanout 和 Topic 的使用。 |
| 进阶 | ACK/NACK、持久化、DLX、路由键 | 确保消息的传输不丢失、不误到。 | 引入死信队列,实现重试机制。 |
| 精通 | 幂等性、本地事务、Quorum Queues、集群调优 | 确保系统在任何故障场景下都能持续、正确地运行。 | 强制设计幂等消费逻辑,使用法定人数队列。 |
最终建议:
- 永远不要信任网络和系统。 所有的业务流程都必须假设网络会中断、服务会宕机、消息会重复。
- 优先考虑幂等性。 这是解决所有分布式系统消息问题的通用解法。
- 拥抱法定人数队列。 在新的项目中,应优先使用 Quorum Queues 来构建核心的、对可靠性要求极高的消息通道。
掌握了这些知识点,您就具备了设计和维护企业级、高可靠、高性能消息中间件系统的全部能力。