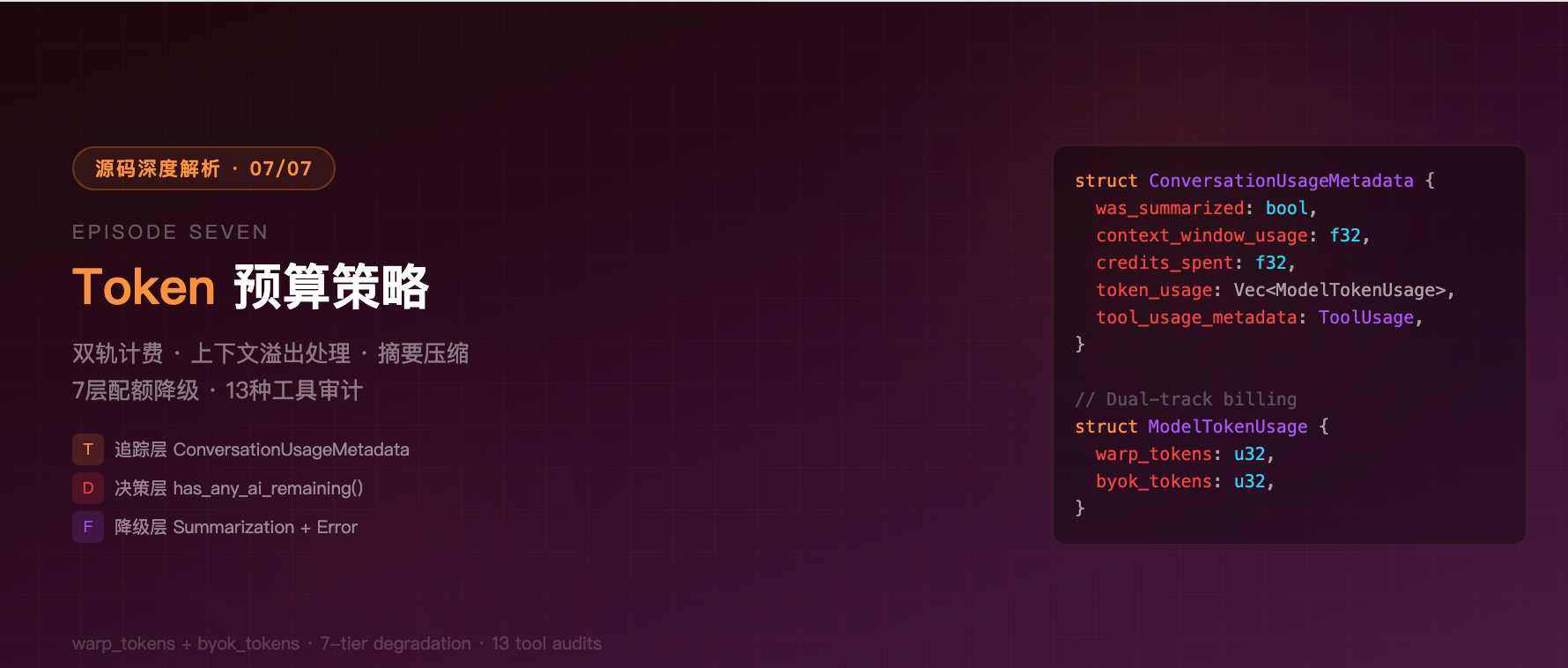
这是 Warp 源码深度解析系列的第七篇。Token 是 AI Agent 运行的"燃料"------用完了对话就死了。本文深入 Warp 的双轨 Token 计费(warp_tokens vs byok_tokens)、ConversationUsageMetadata 追踪、上下文窗口溢出处理、SummarizationType 摘要压缩、RequestUsageModel 6条件可用性检查,以及 ToolUsageMetadata 工具调用审计,完整还原 Token 从产生到消耗到审计的全生命周期。
一、Token 预算问题的本质
AI Agent 的 Token 预算管理面临三重挑战:
┌──────────────────────────────────────────────────────────────┐
│ 挑战1:计费复杂性 │
│ Warp 提供的 Token + 用户自带 Key 的 Token │
│ → 两套独立的计费和追踪系统 │
├──────────────────────────────────────────────────────────────┤
│ 挑战2:上下文溢出 │
│ 对话越长,上下文越大,最终超出模型窗口限制 │
│ → 需要优雅降级而非直接崩溃 │
├──────────────────────────────────────────────────────────────┤
│ 挑战3:多模型混用 │
│ 一次对话可能经过多个模型(主模型 + 快速模型 + 嵌入模型) │
│ → 需要按模型追踪 Token 用量 │
└──────────────────────────────────────────────────────────────┘Warp 的解法是一个三层架构:追踪层(ConversationUsageMetadata)→ 决策层(RequestUsageModel)→ 降级层(Summarization + Error Handling)。
二、双轨 Token 计费------warp_tokens vs byok_tokens
2.1 为什么需要双轨?
Warp 的商业模式有两种 Token 来源:
- warp_tokens --- Warp 提供的 Token(包含在订阅中,有配额限制)
- byok_tokens --- Bring Your Own Key(用户自带 API Key,无配额限制)
rust
// crates/persistence/src/model.rs:1069
pub struct ModelTokenUsage {
pub model_id: String,
/// Warp 提供的 Token 用量
/// 向后兼容:旧数据用 total_tokens 字段,通过 alias 映射
#[serde(default, alias = "total_tokens")]
pub warp_tokens: u32,
/// 用户自带 Key 的 Token 用量
#[serde(default)]
pub byok_tokens: u32,
/// 按 Category 细分的 Warp Token 用量
#[serde(default)]
pub warp_token_usage_by_category: HashMap<TokenUsageCategory, u32>,
/// 按 Category 细分的 BYOK Token 用量
#[serde(default)]
pub byok_token_usage_by_category: HashMap<TokenUsageCategory, u32>,
}2.2 向后兼容的 alias 设计
注意 #[serde(default, alias = "total_tokens")]------旧版本持久化的数据用 total_tokens 字段名,新版本改为 warp_tokens。通过 serde alias 实现零停机迁移:
rust
// 旧数据:{ "model_id": "gpt-4", "total_tokens": 1500 }
// 新数据:{ "model_id": "gpt-4", "warp_tokens": 1500, "byok_tokens": 0 }
// 两种格式都能正确反序列化2.3 Token Category 分类
rust
pub type TokenUsageCategory = String;
pub const PRIMARY_AGENT_CATEGORY: &str = "primary_agent";
pub const FULL_TERMINAL_USE_CATEGORY: &str = "full_terminal_use";当前只有两个分类,但用 String 类型而非枚举,是为了服务端可以动态添加新分类而无需客户端发版。这是一种前向兼容设计。
2.4 双轨数据的合并输出
rust
impl ModelTokenUsage {
pub fn to_proto_warp_usage(&self) -> Option<(String, ModelTokenUsage)> {
self.to_proto_usage(self.warp_tokens, &self.warp_token_usage_by_category)
}
pub fn to_proto_byok_usage(&self) -> Option<(String, ModelTokenUsage)> {
self.to_proto_usage(self.byok_tokens, &self.byok_token_usage_by_category)
}
pub fn to_proto_combined(&self) -> ModelTokenUsage {
// warp_tokens + byok_tokens 合并
ModelTokenUsage {
model_id: self.model_id.clone(),
total_tokens: self.warp_tokens + self.byok_tokens,
...
}
}
}三种输出模式各有用途:
warp_usage--- Warp 计费系统用byok_usage--- 用户查看自己的 Key 消耗combined--- 展示总用量
三、ConversationUsageMetadata------对话级 Token 追踪
3.1 核心结构
rust
// crates/persistence/src/model.rs:1297
pub struct ConversationUsageMetadata {
/// 对话是否已被摘要压缩
pub was_summarized: bool,
/// 上下文窗口使用比例(0.0~1.0),由服务端报告
pub context_window_usage: f32,
/// 总花费的 Credits
pub credits_spent: f32,
/// 最近一个 Block(一次 Agent 交互)的 Credits
pub credits_spent_for_last_block: Option<f32>,
/// 按模型细分的 Token 用量
#[serde(default)]
pub token_usage: Vec<ModelTokenUsage>,
/// 工具调用审计数据
#[serde(default)]
pub tool_usage_metadata: ToolUsageMetadata,
}3.2 context_window_usage------服务端的"油表"
context_window_usage 是一个 0.0~1.0 的浮点数,由服务端在每次响应中报告,不是客户端计算的。这是一个重要的设计决策:
客户端无法准确知道上下文占用了多少 Token,因为:
1. 不同模型的 Token 计算方式不同
2. 系统提示词的长度客户端不知道
3. 工具定义的长度客户端不知道
4. 服务端可能插入额外上下文
→ 让服务端报告是最准确的3.3 was_summarized------单向门
rust
// app/src/ai/agent/conversation.rs:1611
// A conversation can never go from summarized to un-summarized,
// so we only update the summarized flag if it's going from false to true.
if usage_metadata.summarized && !self.conversation_usage_metadata.was_summarized {
self.conversation_usage_metadata.was_summarized = usage_metadata.summarized;
}was_summarized 是一个单向门 ------只能从 false 变为 true,永远不能回退。这反映了一个事实:一旦对话被摘要压缩,原始上下文已经丢失,"恢复"是不可能的。
3.4 Token 用量更新流程
rust
// app/src/ai/agent/conversation.rs:1568
if let Some(usage_metadata) = usage_metadata {
// 1. 更新上下文窗口使用量
self.conversation_usage_metadata.context_window_usage =
usage_metadata.context_window_usage;
// 2. 更新 Credits
self.conversation_usage_metadata.credits_spent = usage_metadata.credits_spent;
// 3. 双轨 Token 用量合并到 HashMap
let mut token_usage: HashMap<_, ModelTokenUsage> = HashMap::new();
for (model_id, usage) in usage_metadata.warp_token_usage {
let entry = token_usage.entry(model_id.clone()).or_default();
entry.warp_tokens += usage.total_tokens;
for (category, tokens) in usage.token_usage_by_category {
*entry.warp_token_usage_by_category.entry(category).or_default() += tokens;
}
}
for (model_id, usage) in usage_metadata.byok_token_usage {
let entry = token_usage.entry(model_id.clone()).or_default();
entry.byok_tokens += usage.total_tokens;
for (category, tokens) in usage.token_usage_by_category {
*entry.byok_token_usage_by_category.entry(category).or_default() += tokens;
}
}
// 4. 转换为 Vec 持久化
self.conversation_usage_metadata.token_usage = token_usage
.into_iter()
.map(|(name, mut usage)| { usage.model_id = name; usage })
.collect();
// 5. 更新工具调用审计
self.conversation_usage_metadata.tool_usage_metadata =
usage_metadata.tool_usage_metadata.as_ref()
.map(Into::into)
.unwrap_or_default();
// 6. 单向门:was_summarized
if usage_metadata.summarized && !self.conversation_usage_metadata.was_summarized {
self.conversation_usage_metadata.was_summarized = usage_metadata.summarized;
}
}四、上下文窗口溢出处理
4.1 溢出错误映射
当 LLM 服务端返回 Token 超限错误时,Warp 统一处理为 ContextWindowExceeded:
rust
// ContextWindowExceeded 和 MaxTokenLimit 都映射到同一个用户可见错误
ContextWindowExceeded | MaxTokenLimit => {
RenderableAIError::ContextWindowExceeded
}4.2 对话状态转换
对话进行中 (Active)
│
├── 服务端返回 ContextWindowExceeded
│
▼
对话失败 (Failed)
│
├── 用户看到:上下文窗口已超出
└── 建议:开启新对话关键设计 :Warp 不会自动截断对话内容或强制摘要。上下文溢出直接导致对话失败,用户需要主动处理。这是一个显式优于隐式的设计决策------自动摘要可能让用户丢失重要上下文而不自知。
4.3 SummarizationCancellationConfirmation
当用户尝试取消正在进行的摘要操作时,Warp 会弹出确认对话框:
rust
// FeatureFlag: SummarizationCancellationConfirmation
// 确认:你确定要取消摘要吗?这可能导致对话无法继续。这也说明摘要是不可逆操作------取消意味着对话可能无法恢复。
五、SummarizationType------两种摘要模式
5.1 枚举定义
rust
// app/src/ai/agent/mod.rs:1621
pub enum SummarizationType {
/// 对话摘要------压缩整个对话历史
ConversationSummary,
/// 工具调用结果摘要------压缩长工具输出
ToolCallResultSummary,
}5.2 两种摘要的触发场景
| 类型 | 触发场景 | 目的 |
|---|---|---|
ConversationSummary |
上下文窗口即将溢出 | 压缩对话历史,释放 Token 空间 |
ToolCallResultSummary |
工具输出过长(如 cat 大文件) | 压缩单次工具调用结果,释放 Token 空间 |
5.3 Summarization 输出消息
rust
pub enum AIAgentOutputMessageType {
Summarization {
text: AIOutputText,
finished_duration: Option<Duration>,
summarization_type: SummarizationType,
/// 摘要消耗的 Token 数
token_count: Option<u32>,
},
// ...
}摘要本身也消耗 Token(token_count),这些 Token 会计入对话的 ConversationUsageMetadata。
5.4 服务端驱动的摘要
Warp 的摘要是服务端驱动的------客户端不决定何时摘要,只负责:
- 接收服务端的
summarized: true标记 - 更新
was_summarized单向门 - 渲染 Summarization 输出消息
- 追踪摘要消耗的 Token
这种设计简化了客户端逻辑,但也意味着客户端无法主动触发摘要。
5.5 SummarizationViaMessageReplacement Flag
rust
// FeatureFlag: SummarizationViaMessageReplacement
// 用消息替换方式实现摘要,而非删除原始消息传统摘要实现可能直接删除旧消息。SummarizationViaMessageReplacement 用替换方式------保留消息 ID,更新消息内容。这让 UI 可以显示"此消息已被摘要"的状态,而不是突然消失。
六、RequestUsageModel------6 条件可用性检查
6.1 has_any_ai_remaining()
这是 AI 可用性的终极检查------6 个条件只要满足一个就可以继续使用:
rust
// app/src/ai/request_usage_model.rs:381
pub fn has_any_ai_remaining(&self, ctx: &AppContext) -> bool {
// 条件1:基础套餐还有请求额度
let has_base_plan_ai_requests = self.has_requests_remaining();
// 条件2:用户有个人赠送 Credits
let user_bonus_credits = self.total_user_interactive_bonus_credits_remaining() > 0;
// 条件3:工作空间有赠送 Credits
let workspace_bonus_credits = current_workspace
.map(|w| self.total_workspace_bonus_credits_remaining(w.uid) > 0)
.unwrap_or_default();
// 条件4:工作空间启用了超量使用
let workspace_has_overages =
current_workspace.is_some_and(|w| w.are_overages_remaining());
// 条件5:企业版按量付费
let is_payg_enabled = current_workspace
.is_some_and(|w| w.billing_metadata.is_enterprise_pay_as_you_go_enabled());
// 条件6:企业版自动充值
let is_enterprise_auto_reload_enabled = current_workspace
.is_some_and(|w| w.billing_metadata.is_enterprise_auto_reload_enabled());
// 条件7(隐藏条件):用户自带 API Key
let has_byo_api_key = UserWorkspaces::as_ref(ctx).is_byo_api_key_enabled()
&& ApiKeyManager::as_ref(ctx).keys().has_any_key();
has_base_plan_ai_requests
|| (user_bonus_credits || workspace_bonus_credits)
|| workspace_has_overages
|| is_payg_enabled
|| is_enterprise_auto_reload_enabled
|| has_byo_api_key
}6.2 7 层降级策略
用户发送请求
│
├── 1. 基础套餐有额度 → 直接使用
│
├── 2. 个人赠送 Credits → 消耗赠送额度
│
├── 3. 工作空间赠送 Credits → 消耗团队额度
│
├── 4. 超量使用(Overages)→ 按量计费
│
├── 5. 企业按量付费(PAYG)→ 企业计费
│
├── 6. 企业自动充值 → 自动充值后使用
│
└── 7. BYOK → 用户自带 Key,不受限制BYOK 是终极降级------只要你自己的 API Key 还有额度,Warp 的配额限制不影响你。
6.3 默认配额
免费用户:
- 150 请求/月
- 3 个代码库索引
- 5000 文件/仓库七、ToolUsageMetadata------工具调用审计
7.1 完整审计结构
rust
// crates/persistence/src/model.rs:1204
pub struct ToolUsageMetadata {
pub run_command_stats: RunCommandStats, // 执行命令
pub read_files_stats: ToolCallStats, // 读取文件
pub search_codebase_stats: ToolCallStats, // 搜索代码库
pub grep_stats: ToolCallStats, // Grep 搜索
pub file_glob_stats: ToolCallStats, // 文件匹配
pub apply_file_diff_stats: ApplyFileDiffStats, // 应用文件 Diff
pub write_to_long_running_shell_command_stats: ToolCallStats, // 写入长运行命令
pub read_mcp_resource_stats: ToolCallStats, // 读取 MCP 资源
pub call_mcp_tool_stats: ToolCallStats, // 调用 MCP 工具
pub suggest_plan_stats: ToolCallStats, // 建议计划
pub suggest_create_plan_stats: ToolCallStats, // 建议创建计划
pub read_shell_command_output_stats: ToolCallStats, // 读取命令输出
pub use_computer_stats: ToolCallStats, // Computer Use
}13 种工具调用,每一种都有独立的统计。total_tool_calls() 方法汇总所有工具调用次数:
rust
impl ToolUsageMetadata {
pub fn total_tool_calls(&self) -> i32 {
self.run_command_stats.count
+ self.read_files_stats.count
+ self.search_codebase_stats.count
+ self.grep_stats.count
+ self.file_glob_stats.count
+ self.write_to_long_running_shell_command_stats.count
+ self.read_mcp_resource_stats.count
+ self.call_mcp_tool_stats.count
+ self.suggest_plan_stats.count
+ self.suggest_create_plan_stats.count
+ self.apply_file_diff_stats.count
+ self.read_shell_command_output_stats.count
+ self.use_computer_stats.count
}
}7.2 为什么要按工具类型追踪?
- 成本分析 --- 不同工具消耗的 Token 不同(Computer Use 截图远比 Grep 贵)
- 行为审计 --- 某个 Agent 是否过度调用 MCP 工具?
- 配额控制 --- 未来可能按工具类型设置不同的配额
- 产品决策 --- 哪些工具最受欢迎?哪些工具使用率低需要改进?
八、Credits 与 Token 的关系
8.1 双重计量
Warp 有两套并行的计量系统:
Credits(Warp 虚拟货币)
├── credits_spent: 总花费
├── credits_spent_for_last_block: 最近一次交互花费
└── 用于 Warp 商业计费
Token(LLM 计量单位)
├── warp_tokens: Warp 提供的 Token
├── byok_tokens: 用户自带 Key 的 Token
└── 用于 LLM 层面追踪Credits 是面向用户的计费单位,Token 是面向技术的追踪单位。一次请求的 Credits 和 Token 不一定是简单的线性关系------Warp 可能在 Token 成本上加价,也可能对不同模型使用不同的 Credit 汇率。
8.2 credits_spent_for_last_block 的重置
rust
if was_user_initiated_request {
*credits_spent_for_last_block = 0.;
}
*credits_spent_for_last_block += request_cost.value() as f32;每次用户发起新请求时重置 credits_spent_for_last_block,然后累加这次请求的所有服务端响应的 Cost。这让 UI 可以显示"这次交互花了多少 Credits"。
九、Feature Flag 与 Token 策略的关联
| Flag | 对 Token 策略的影响 |
|---|---|
FullSourceCodeEmbedding |
代码库上下文消耗更多 Token |
CrossRepoContext |
跨仓库上下文进一步增加 Token 消耗 |
ContextWindowUsageV2 |
上下文窗口使用量的 v2 计算方式 |
SummarizationViaMessageReplacement |
摘要替换方式影响 Token 计数 |
RetryTruncatedCodeResponses |
截断重试消耗额外 Token |
SummarizationCancellationConfirmation |
摘要取消确认的 UI |
AgentViewBlockContext |
自动附加 Block 增加上下文 Token |
最关键的权衡 :AgentViewBlockContext 增强了 Agent 的感知能力(自动附加终端输出),但也增加了 Token 消耗。Warp 用 Feature Flag 让用户/团队自己决定是否承担这个额外成本。
十、Token 生命周期完整流程
1. 用户发起请求
│
▼
2. has_any_ai_remaining() 检查 6 条件
│
├── 不通过 → 显示配额不足
│
└── 通过 ↓
│
3. 组装上下文(AIAgentContext × 9)
│
▼
4. 发送到 LLM Server
│
├── 正常响应 → 更新 ConversationUsageMetadata
│ ├── context_window_usage 更新
│ ├── credits_spent 累加
│ ├── token_usage 按模型按分类累加
│ └── tool_usage_metadata 按工具累加
│
├── ContextWindowExceeded → 对话失败
│
├── 需要摘要 → 服务端返回 summarized: true
│ ├── was_summarized 设为 true(单向门)
│ ├── Summarization 消耗额外 Token
│ └── 对话继续(上下文已被压缩)
│
└── 其他错误 → 错误处理十一、设计模式总结
| 模式 | 实现 | 价值 |
|---|---|---|
| 双轨计费 | warp_tokens + byok_tokens | 商业灵活性和用户自主性 |
| 服务端油表 | context_window_usage 由服务端报告 | 准确性优于客户端估算 |
| 单向门 | was_summarized 只能 false→true | 防止错误的"恢复"操作 |
| 7 层降级 | has_any_ai_remaining() 6 条件 + BYOK | 配额耗尽时的优雅降级 |
| 按工具审计 | 13 种 ToolUsageMetadata | 精细化成本分析 |
| Feature Flag 权衡 | AgentViewBlockContext 增强但增加 Token | 用户自主选择成本/能力平衡 |
| 向后兼容 | serde alias total_tokens → warp_tokens |
零停机数据迁移 |
| 前向兼容 | TokenUsageCategory = String 而非枚举 | 服务端可动态添加分类 |
十二、与其他 Agent 框架对比
| 特性 | Warp | Claude Code | Cursor | GitHub Copilot |
|---|---|---|---|---|
| 计费模式 | 双轨(warp + BYOK) | 单轨(订阅) | 单轨(订阅) | 单轨(订阅) |
| Token 追踪粒度 | 模型 × 分类 × 工具 | 按对话 | 按月 | 按月 |
| 上下文使用量 | 服务端报告 f32 | 客户端估算 | 客户端估算 | 不透明 |
| 溢出处理 | 对话失败 + 摘要 | 自动摘要 | 自动截断 | 自动截断 |
| 摘要类型 | 对话 + 工具调用双类型 | 对话 | 无 | 无 |
| 工具调用审计 | 13 种独立统计 | 无 | 无 | 无 |
| 配额降级 | 7 层 | 2 层 | 2 层 | 2 层 |
| BYOK | 原生支持 | 支持 | 部分 | 不支持 |
Warp 在 Token 管理上的核心优势是精细化追踪------不是简单记录"用了多少 Token",而是按模型、按分类、按工具类型分别追踪,并且区分 Warp 提供和用户自带的 Token。这种粒度对于企业级 Agent 的成本管理至关重要。
系列索引: