论文总结
该论文提出 RAMer 框架,用于解决多方对话场景下的多模态多标签情绪识别(MMER)问题,主要应对非说话者模态(如文本、声学)缺失的挑战。核心贡献如下:
-
问题定位:传统方法假设所有模态完整,但真实多方对话中非说话者常缺失声学/文本信号。RAMer 针对此设计,同时处理模态不完整、多表示融合及标签关联建模三大挑战。
-
核心机制:
-
重建对抗学习 :通过生成器与判别器对抗训练,提取模态间的共性 与特异性;引入重建网络和对比学习增强特征质量,缓解缺失模态问题。
-
个性辅助任务:利用人格特征(作为外部知识)并采用模态级注意力机制,补偿缺失模态,提升情绪推理能力。
-
堆叠混洗策略:在样本维和模态维进行堆叠混洗,增强标签间关联及模态-标签依赖关系的建模。
-
-
实验验证:在 MEMoR(多方)、CMU-MOSEI 和 M³ED(双人)三个基准上达到 SOTA;消融实验证实各组件有效性;可视化显示学习到的模态表征区分度高,且能捕获模态-标签相关性(如惊讶主要关联声学,愤怒主要关联视觉)。
-
优势总结:相较于现有方法,RAMer 在模态不完整的多方场景下鲁棒性更强,同时在双人场景也保持领先,并能有效融合个性知识提升性能。
-
有开源代码anonymousAccount01/RAMer。这个工作分了共性和特异性,其实就是特征解耦。
摘要
传统的多模态多标签情绪识别(MMER)假设对视觉、文本和声学模态的完全访问。然而,现实中的多方环境常常违反这一假设,因为非说话者往往缺乏声学和文本输入,导致模型性能显著下降。现有方法也倾向于将异质模态统一为单一表示,忽视每个模态的独特特征。为应对这些挑战,我们提出了RAMer(基于重建的情绪识别对抗模型),它通过探索模态的共性和特异性,关键是利用重构特征,并通过对比学习增强,完善多模态表示,克服数据不完整性并丰富特征质量。RAMer还引入了人格辅助任务,利用模态级注意力补充缺失的模态,提升情绪推理能力。为了进一步增强模型捕捉标签与模态相互依赖的能力,我们提出了一种栈洗牌策略,以丰富标签与模态特有特征之间的相关性。在三个基准测试------MEmoR、CMU-MOSEI 和 M 3ED 上进行的实验表明,RAMer 在二元和多方 MMER 场景中实现了最先进的性能。
引言
从视频中识别情感对于推动人机互动和社会智能的发展至关重要。多模态多标签情绪识别(MMER)利用视觉、文本和声学信号同时识别多种情绪(如快乐、悲伤)Zhang 等,2020;Zhang 等,2021a。传统的MMER方法如图1(a)所示,通常侧重于独白或双人模式,假设所有模态均可使用。然而,现实中的对话往往涉及多个参与者(即多方),而非说话者的模态数据不完整,且总是缺乏声学和文本信号。
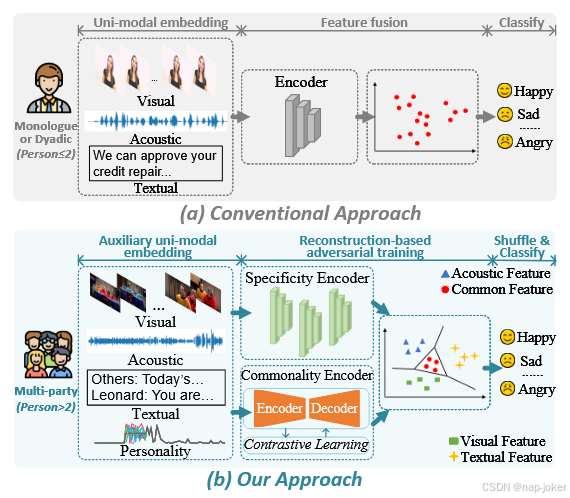
图1:(a) 展示了MMER在独白和双向对话中采用的传统方法,且具有完整模态且表现一致;(b) 描绘了我们在多方对话中对不完整模态的方法,将其重构并投射为具体性和共性表征。
多方MMER是一个更为复杂和实用的设定,它引入了三个关键挑战。首先,处理不完整的模态是一个重大的挑战,它需要稳健的方法来重建或推断缺失的信息。大多数现有的工作 Zhang et al , 2021a ;张杰等, 2022 ; Ge et al , 2023假设完整的模态访问,并独立地编码每个模态,忽略了缺失的数据。虽然一些方法 Ghosal et al . , 2019 ; Hu et al . , 2021利用了说话人感知的上下文建模,但在非说话人往往缺乏关键模态的多方环境中,它们的性能会下降。 其次,有效地表示不同的模态仍然具有挑战性,通常需要技术不仅可以整合不同的信息,而且可以从潜在的模态中重建丰富、完整的表示。目前的融合策略,如基于聚合的方法( e.g. ,串联,平均) Shen et al , 2020和混合方法曼苏尔et al , 2023,将模态投影到一个共享子空间中,往往忽略了它们的独特特性而降低了判断能力。
最近的方法 Zhang et al , 2022试图分离模式特异性和共享特征,但由于不充分地处理模态间的相关性而经常遭受信息损失。同样,保留模式特异性信息的方法 Peng et al , 2023可能会忽略跨模态的共性,限制了它们充分捕捉模态间关系的能力。最后,多标记学习在建模鲁棒的标记相关性以及捕获模态和标记之间复杂的相互依赖关系方面提出了挑战。现有的方法 Cisse et al . , 2013 ; Ma et al , 2021往往不能充分挖掘协同标签关系。此外,情感在不同模态之间存在差异,而不同的情感依赖于不同的模态特征,进一步增加了任务的复杂度。 为了解决这些问题,我们提出了RAMer,这是一个新颖的框架,旨在解决多方MMER问题的挑战。RAMer将多模态表示学习与多标签建模相结合,可以有效地处理多方设置中的不完整模态。如图1 ( b )所示,RAMer通过以下技术解决了多方MMER的挑战。为了解决不完整模态的挑战,我们提出了一个融合外部知识的辅助任务,例如人格特质,来补充现有的模态。利用这一点,我们使用模态级别的注意力机制来捕获个人之间和个人内部的特征。 基于重构的网络通过利用其他模态的信息来恢复和丰富任何模态的特征。为了有效地表示不同模态,并捕获具有判别性的特征,我们设计了一个对抗网络,在放大每个模态固有的特异性的同时,提取跨模态的共性。这有助于确保在融合过程中信息损失最小。此外,为了建模模态和标签之间的鲁棒关联,我们提出了一种新颖的模态混洗策略。该策略通过对样本和模态进行重排来丰富特征空间,基于模态的共性和特异性,提高模型捕获标签相关性和模态-标签关系的能力。 总的来说,本文的主要贡献有:·提出了一种新颖的多方MMER问题模型。我们提出了一种新的框架RAMer,它集中集成了对抗学习范式中的特征重构。RAMer善于捕获跨模态的共性和特异性,关键是利用稳健的重构特征来显著提高情感识别,特别是在不完整的模态数据下。·优化技术。为了增强多方情感识别的鲁棒性,RAMer使用对比学习来丰富重构特征,并集成了一个人格辅助任务来捕获模态级别的注意力。 我们还提出了一种堆栈洗牌策略,通过利用不同模态的共性和特异性来增强标签相关性和模态到标签关系的建模。·广泛的实验。我们在MEmoR、CMUMOSEI和M 3ED三个基准测试集上进行了不同会话场景下的全面实验。结果表明,RAMer在两方和多方MMER问题中都超越了现有的方法,并达到了最先进的性能。
相关工作
多模态表示学习。情感识别已经从单模态方法黄群慧等, 2021 ; Saha et al , 2020发展到利用跨模态互补特征的多模态方法吕越等, 2021 ; Zhang et al , 2022。虽然单模态方法经常会出现人脸识别偏差 Huang et al , 2021,但多模态学习已经得到了广泛的关注,其中一个关键的挑战是异构模态的有效集成。早期的融合方法,如级联 Ngiam et al , 2011a、张量融合 Liu et al . , 2018a、平均 Hazirbas et al , 2017等,都与阻碍有效特征对齐的模态间隙作斗争。为了解决这个问题,基于注意力的方法应运而生 Ge et al .,2023;Tsai et al ,2019 利用交叉注意力机制在潜在空间中动态对齐特征,而对比学习 Chen et al . , 2020 ; Peng et al , 2023进一步提高了鲁棒性。然而,大多数基于注意力的方法将模态合并为一个联合嵌入,往往忽略了模式特异性特征。
视频中的多标签情感识别。MMER涉及给视频中的一个目标人物分配多个情感标签。早期的方法将多标签分类视为独立的二进制任务鲍特尔等, 2004,但使用类似邻域特征的相似性图嵌入( ASGE ) You et al , 2020,图卷积网络( GCN )等技术探索标签相关性 Chen et al ,2019 和多任务模式 Tsai and Lee , 2020来探索标签相关性。一些值得注意的策略张杰等, 2021b ; Zhang et al , 2022专注于通过视觉注意 Chen et al . , 2019和转换器 Zhang et al , 2022使能的标签特定的表示来建模标签特征相关性。除了独白场景,会话中的MMER已经引起了人们的兴趣,使用GCN Ghosal等, 2019和记忆网络哈扎里卡等, 2018来模拟动态说话人交互。然而,多方MMER特别具有挑战性,因为它需要对具有不完整模态的多个说话人进行情感识别。此外,个体的人格特征对标签-特征关系的影响仍未得到充分的研究。
对抗训练。 对抗训练( AT ) 古德费洛等, 2014,涉及两个模型:一个估计样本概率的判别器,一个产生与实际数据无法区分的样本的生成器。这种设置形成了一个极小极大的两人博弈,增强了模型的稳健性。该技术已用于CV和NLP应用 Wang et al . , 2017。例如,Miyato等人 Miyato等, 2016通过对词嵌入引入扰动,将AT扩展到文本分类中。Wu等人 Wu et al . , 2017将其应用在多标记学习框架中,以促进关系抽取。此外,AT已被用于学习多模态 Tsai et al , 2018之间的联合分布。最近,Ge等人 Ge .等,2023 在MMER任务中应用AT来减少模态和数据偏差。然而,Zhang等人 Zhang et al , 2022实现了AT以提取多模态的共性和多样性,但由于跨模态信息融合不充分而遭受了模态信息的显著损失。
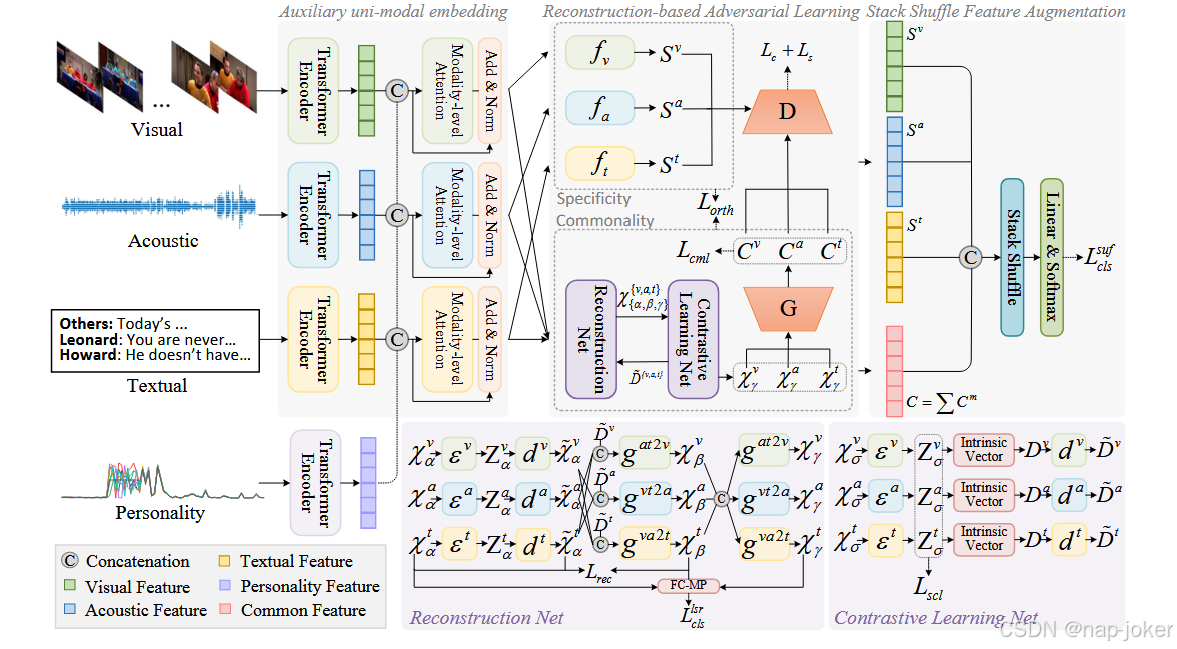
图2:RAMer框架。在不完全多模态输入的情况下,RAMer首先通过辅助任务对每个单独的模态进行编码,然后将特征输入到基于重建的对抗网络中,以提取特异性和共同性。最后,使用堆栈洗牌策略来学习增强的表示。
问题定义
在本节中,我们介绍了使用的符号,并对多方多模态多标签情感识别问题进行了形式化定义。注释。标量( e.g. , v)使用小写字母,向量( e.g. , Y)使用大写字母,矩阵( e.g. , X)使用黑体。用元组( V、Pt、Sr、Et、r)表示一个数据样本,其中:

每个样本涉及视觉( v )、听觉( a )、文本( t )和个性特征( p )等模态。对于每个模态m∈{ v,a,t,p },对应的特征表示为X 1,X 2,· · ·,X m,其中X k∈Rlk × dk表示第k个模态的特征空间。这里:lk表示序列的长度,dk表示模态的维数。设Y = { y1,y2,· · ·,yζ }表示一个带有ζ个可能情感标签的标签空间。
多方Mmer问题。 给定训练数据集D = n X { 1,2,· · ·,m } τ,有N个数据样本Y τ oN τ = 1,其中:( 1 ) Xτm∈X m表示样本τ中每个模态m的特征,( 2 ) Yτ = { 0,1 } ζ是表示情感标签存在( 1 )或不存在( 0 )的多热点向量,其中Y τ υ = 1表示样本τ属于υ类,否则Y τ υ = 0。多方MMER问题的目标是学习一个函数F:X 1 × X 2 × · · · × X m 7→Y,该函数利用多个模态的上下文信息来预测段Sr中人物Pt的目标情感Et,r。讨论。值得注意的是,目标人物Pt可能具有不完整的模态信息,这意味着他们可能不同时具有视觉、文本或声学表征。 这在目标片段Sr的模态上引入了不确定性,使得预测任务更具挑战性。
方法
图2展示了RAMer的框架,它由三个部分组成:辅助单模态嵌入、基于重建的对抗学习和栈式洗牌特征增强。
辅助单模态嵌入
为了从每个模态中提取上下文信息,我们使用了4个独立的变压器编码器 Vaswani et al , 2017,每个编码器专用于一个特定的模态m。每个编码器由nm个相同的层组成,以确保一致和深层的表示。对于有T个参与者的不完整模态的多方会话视频,我们引入了一个利用个性的可选辅助任务来补充缺失的模态。具体来说,我们将人格嵌入X p与每个模态X m∈{ v,t,a }串联,以丰富特征空间。然后,我们应用尺度化的点积注意力来计算每个片段内的人与人之间的注意力,以及每个个体 Shen et al , 2020在片段维度上的人与人之间的注意力。 这种模态级别的注意力机制旨在通过有效地捕获数据内部的人际动态和时间模式来增强模型的情感推理能力。这样,我们得到人格增强表征X mα∈Rl × d。
基于重构的对抗学习
第二个成分通过捕获模态间的共性,同时保留模态特有的特征来利用多个模态。为了解决对抗网络古德费洛et al , 2014 ; Zhang et al , 2022的局限性,即会导致信息丢失和难以学习模态-标签依赖,我们引入了一种基于重建的方法。它使用对比学习来学习模态独立但与标签相关的表示,同时在训练过程中重建缺失的模态以增强鲁棒性。
**对抗训练。**为了平衡模态特异性和共性,我们采用对抗训练来提取判别性特征。 将单峰嵌入X m α送入3个全连接网络fm,提取特异性Sm,m∈{ v,a,t }。并行地,X m α也通过一个重构网络,该重构网络与对比学习网络耦合,再通过一个生成器G ( · ; θG),得到共性Cm。然后,特异性和通用性都通过线性层,并在鉴别器D ( · ; θD)中使用softmax激活,以区分输入来自哪种模态。生成器通过将不同的重构嵌入X m γ投影到一个共享的潜在子空间来捕获公共Cm,从而确保跨模态的分布对齐。 因此,该结构鼓励生成器G( · ; θG)通过模糊Cm的源模态来产生挑战判别器D ( · ; θD)的输出。生成器和判别器在游戏理论设置中联合训练,以增强特征对模式特异性偏差的鲁棒性。公共性对抗损失LC和特异性对抗损失LS都是通过交叉熵损失as,计算得到的。
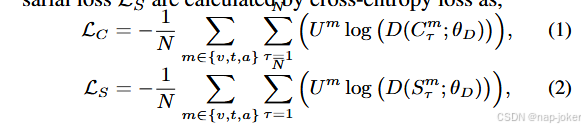
其中U∈{ U v,U t,U a }表示判别器输入对应的基真标签。
在共享子空间中,使用各种模态的统一表示来促进多标签分类是有利的。这种表示旨在消除冗余信息,提取不同模态共有的元素,从而引入一个共同的语义损失,定义为。
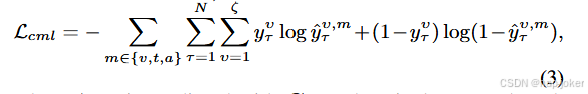
其中y τ ν,m用Cm和y τ ν表示基真标签。为了对多模态数据的不同方面进行编码,我们引入了正交损失Lorth,通过最小化它们的重叠来鼓励公共Cm和特异性Sm子空间保持不同。
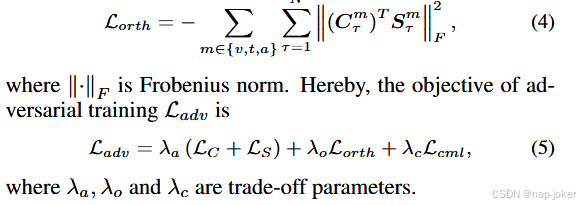
**多模态特征重建。**通过利用其他模态的信息来重建任何模态的特征。我们采用了一个由模式特异性编码器ε m,解码器dm组成的重建网络和一个利用多层线性网络g ( · )的二级重建过程。给定来自不同模态的输入Xm α,利用三个由MLP组成的编码器ε m将Xm α投影到隐空间Sz中的隐嵌入Z α m。随后,3个对应的解码器dm将这些隐向量转化为解码向量Xem α。 在第一级重构网络中,由对比学习网络得到的本征向量De m和语义特征Xe { v,t,a } \ m α级联构成输入,经过处理生成X m β用于第二级重构网络。据此,重构网络可以表述为,
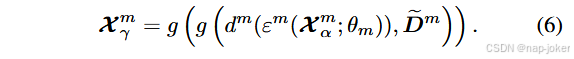
将3个不同特征空间得到的3个嵌入X m α、X m β和X m γ送入全连接网络并进行最大池化。我们可以将重构损失Lrec和分类损失Llsr表述为,
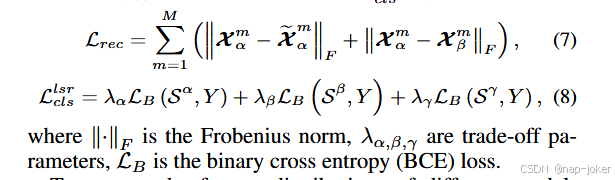
为了捕获不同模态的特征分布,并用于指导不完整模态的恢复,通过有监督的对比学习网络 Khosla et al , 2020得到的本征向量De m被纳入到重建网络中。编码器ε m投影输入Xm σ,对比嵌入Z σ m,.Σ∈{ α,β,γ }。给定一个对比嵌入集Z = n Z { v,t,a } σ0,一个锚向量zi∈Z,假设在基于滑动平均的训练过程中更新的原型向量为μ m j,k,其中模态m∈{ v,t,a },标签类别j∈ ζ ,标签极性k∈{ pos,neg },则内蕴向量Dem可由下式推导得到。

堆栈洗牌进行特征增强
为了构建更鲁棒的标签之间的相关性,并对模态和标签之间的复杂关联进行建模,我们提出了一种结合堆栈洗牌机制的多模态特征增强策略。在获得共性和特异性表示之后,我们在一批样本上依次执行样本级和模态级的洗牌过程。为了加强标签之间的相关性,我们首先使用基于样本的shuffle。由Cm和Sm得到的特征沿样本维度被拆分成k个堆栈,每个堆栈的顶层元素循环弹出并添加以形成新的向量。接下来,引入了基于模态的shuffle来帮助模型捕获和整合不同模态之间的信息。
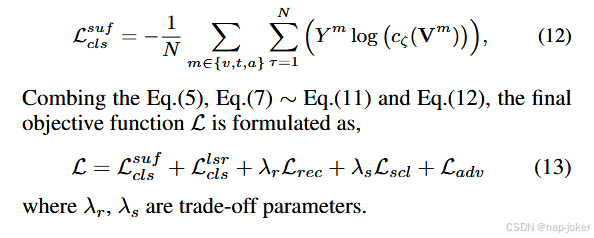
实验
实验配置
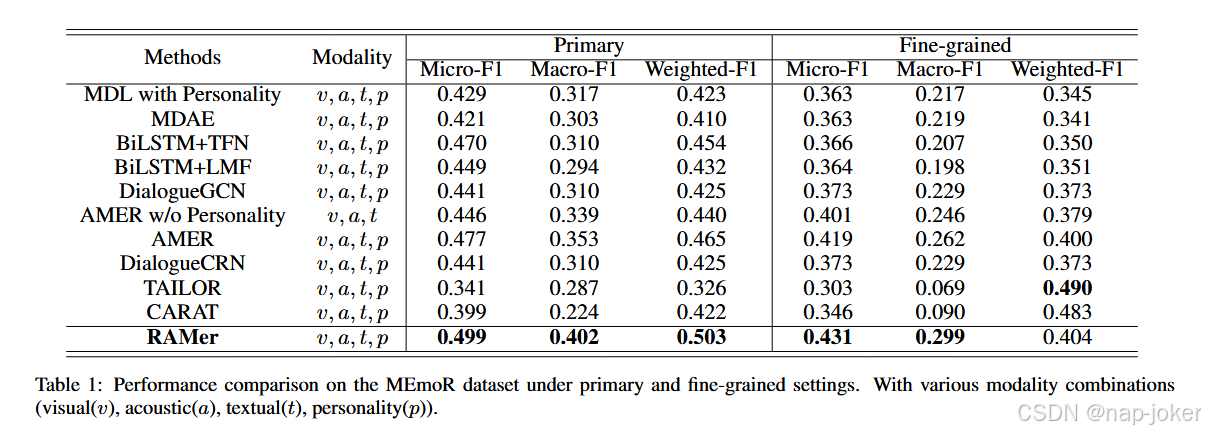
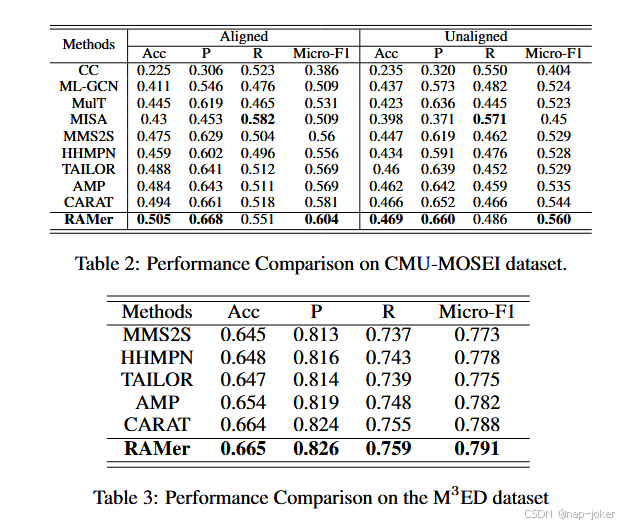
数据集和度量指标 。我们在3个基准数据集上评估了RAMer:包含人格信息的多方会话数据集MEmoR Shen et al . , 2020,以及不包含人格信息的二元会话数据集CMU - MOSEI Zadeh et al , 2018和M 3ED Zhao et al , 2022。评估是在这些数据集的协议下进行的。对于CMU - MOSEI和M 3ED,我们采用了4个常用的评价指标:准确率( Acc )、Micro - F1、精确率( P )和召回率( R )。对于MEmoR,我们遵循基准测试的协议,使用了Micro - F1,Macro - F1和Weighted - F1度量。**基线。**对于MEmoR数据集,我们将RAMer与多方会话基线进行比较,包括MDL、MDAE Ngiam et al , 2011b、Bi LSTM + TFN Zadeh et al ,2017 、Bilstm + Lmf Liu et al . , 2018b、Dialoguegcn Ghosal等, 2019、Dialoguecrn Hu et al . , 2021和Amer Shen et al . , 2020。我们进一步评估了其对最近的二元模型的稳健性,包括CARAT Peng et al , 2023和TAILOR Zhang et al , 2022。对于CMU - MOSEI和M 3ED数据集,我们测试了三类方法。1 )经典方法。CC Read et al , 2011,它将所有可用的模态连接起来作为二进制分类器的输入。2 )基于深度的方法。MLGCN Chen et al . , 2019,使用图卷积网络来映射标签表示并捕获标签相关性。3 )多模态多标记方法。其中包括用于跨模式相互作用的MulT Tsai et al , 2019,MISA 哈扎里卡et al ,2020 用于学习模态不变和模式特异性特征,以及MMS2S 张杰等, 2020,HHMPN Zhang et al , 2021a,TAILOR Zhang et al , 2022,AMP Ge et al , 2023和CARAT Peng et al , 2023等方法。
和SOTA对比
我们分别在表1,表2和表3中给出了RAMer在MEmoR,CMU - MOSEI和M3ED数据集上的性能比较。1 )在MEmoR数据集上,RAMer明显优于所有基线。虽然TAILOR在细粒度设置下取得了较高的加权F1分数,但由于偏向于频繁且易于识别的类,其整体性能较弱。RAMer在所有设置中都能持续地提供强大的结果,这表明它有能力学习更有效的表示。2 )在CMU - MOSEI和M3ED数据集上,RAMer在除召回率之外的所有指标上都超过了最先进的方法,在这些背景下,与准确率和Micro - F1相比,RAMer的重要性较低。 3 )基于深度的方法优于经典方法,突出了捕获标签相关性对提高分类性能的重要性。4 ) HHMPN和AMP等多模态方法显著优于单模态ML - GCN,强调了多模态交互的必要性。5 )针对二元会话优化的模型,如CARAT,在不完全模态的多方会话场景中性能下降明显。相比之下,RAMer在这两种场景下均表现优异,在MEmoR数据集上的Micro - F1和Macro - F1分数均有大幅提升。
消融实验
为了更好地理解RAMer各组成部分的重要性,我们对各种烧蚀变体进行了比较。如表4所示,我们做了如下观察:·特殊性和共同性增强了MMER性能。变体( 1 )、( 2 )和( 3 )表现出较低的Micro-F1高于变体( 11 )。这表明联合学习特异性和共同性可以获得更好的性能,强调了同时捕获模式特异性特异性和共享共同性的重要性。·对比学习有利于MMER。在对抗训练中加入损失函数Lscl导致了渐进的性能提升,( 4 )的优异结果证明了这一点。·特征重构网络有利于MMER。变量( 5 )、( 6 )、( 7 )比( 11 )更差,( 8 )显示为0。045,表明特征重构可以提高模型性能。

图3:模态嵌入的t - SNE可视化。( a ) ( b ):无/有对抗训练的特异性和共同性特征。颜色表示模态(文本的、视觉的、声学的);饱和度区分了特异性(暗)和共同性(光)成分。( c ) ( d ):无/有RN和CLN的重构嵌入,其中色调表示模态,饱和度表示情感。
定性分析
学习到的模态表示的可视化
为了评估基于重建的对抗训练的有效性,我们使用t - SNE来可视化在对齐的CMUMOSEI数据集中学习到的共性和特异性表示。在图3 ( a )中,在没有对抗训练的情况下,特异性和共性是松散分离的,但在某些区域,如右下角,它们的分布是重叠的。相比之下,图3 ( b )显示出更清晰的共同性和特异性的分离,形成了明显的边界,有效地区分了跨模态的情绪。图3 ( c )表明,在没有重建网络( RN )和对比学习网络( CLN )的情况下,模态嵌入是可区分的,但情感标签是相同的。情态仍然是混杂的。相比之下,图3 ( d )在模态和情绪上都显示出明显的分离,表明基于重构的模块提高了表征的区分度。总体而言,RAMer准确地捕捉到了不同模态的共性和特异性。模态与标签相关性的可视化为了探究模态与标签之间的关系,我们将标签与其最相关模态的相关性进行可视化。如图4所示,无论是否存在对抗训练,不同的情绪标签受到不同模态的影响。例如,惊讶主要与声音模态相关,而愤怒主要与视觉模态相关。 这表明每个模态从不同的角度捕获了标签的可区分的语义信息。案例研究为了证明RAMer在复杂场景下的鲁棒性,图5展示了MMER在MEmoR数据集上的一个例子,其中特定的目标人物具有不完整的模态信号。前三行显示来自视频片段的不同模态,用对齐的多模态信号进行语义分割。主要观察指标包括:1 )目标时刻需要识别说话人(例如,霍华德)和非说话人( e.g. , Penny和Leonard)的情绪。虽然说话人通常拥有完整的多模态信号,但非说话人往往缺乏某些模态。 TAILOR受限于缺失的模态,由于其自注意力机制难以将标签与缺失的特征对齐,从而产生部分预测。2 )单一模态或不完整模态的局限性。单一模态,如文本,往往不足以进行准确的情感推断(也就是说,只有霍华德的《欢乐》能从文本中被发现)。尽管CARAT试图重建缺失的信息,但它未能捕获跨模态的共性,从而导致错误的预测。3 )人际互动和外部知识(例如,个性特征)发挥了重要作用。人与人之间的注意力有助于弥补缺失数据,而个性感知推理提高了参与者之间的情感推断,突出了用户画像和情感识别之间的协同作用。实验结果表明,RAMer在复杂的现实场景中具有较好的鲁棒性和有效性。
总结
在本文中,我们提出了RAMer框架,该框架使用基于重建的对抗学习来改进多模态表示,以解决多方多模态多标签情感识别问题。RAMer使用对抗学习模块捕获跨模态的共性和特异性,通过重建和对比学习增强其区分情感标签的能力,即使在数据缺失的情况下也是如此。我们还引入了一个人格辅助任务来补充不完整的模态,通过模态级别的注意力来提高情感推理。此外,堆栈洗牌策略丰富了特征空间,并加强了标签和模态之间的相关性。 在3个数据集上的大量实验表明,RAMer在两方和多方MMER场景中的性能均优于现有方法。
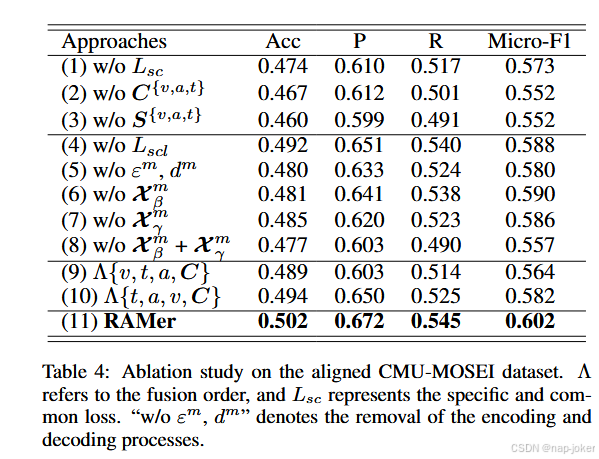
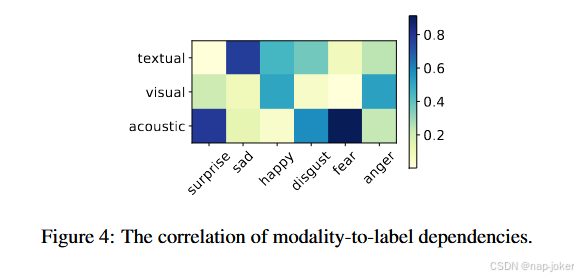

图5:案例研究结果示例。