目录
[1. 全称与定义](#1. 全称与定义)
[2. 下推到底是什么?](#2. 下推到底是什么?)
[3. 典型适用场景](#3. 典型适用场景)
[1. 前置准备:实战演示表结构](#1. 前置准备:实战演示表结构)
[2. 无索引下推(MySQL5.5 及以下 / 手动关闭)](#2. 无索引下推(MySQL5.5 及以下 / 手动关闭))
[3. 有索引下推(默认开启)](#3. 有索引下推(默认开启))
[三、索引下推(ICP)vs 覆盖索引](#三、索引下推(ICP)vs 覆盖索引)
[1. 单项通俗解析](#1. 单项通俗解析)
[覆盖索引(Covering Index)](#覆盖索引(Covering Index))
[2. 极简对比表](#2. 极简对比表)
在日常 MySQL 慢查询优化中,很多人会遇到一个困惑:明明建了联合索引,范围查询依然很慢,IO 占用极高。
排查后发现,大量时间浪费在「回表查询」上。而 MySQL 5.6 版本推出的索引下推(ICP),正是解决这一问题的低成本、高收益优化利器 ------ 无需修改业务 SQL、无需重构索引,默认开启就能大幅提升查询性能。
本文结合真实业务表结构,通俗拆解索引下推,看完既能线上落地优化,又能从容应对面试追问。
一、什么是「索引下推(ICP)」?
1. 全称与定义
ICP 全称 Index Condition Pushdown ,中文译为「索引条件下推」。它是 MySQL 5.6 及以上版本默认开启的查询优化策略,仅针对 InnoDB、MyISAM 引擎的二级索引生效。
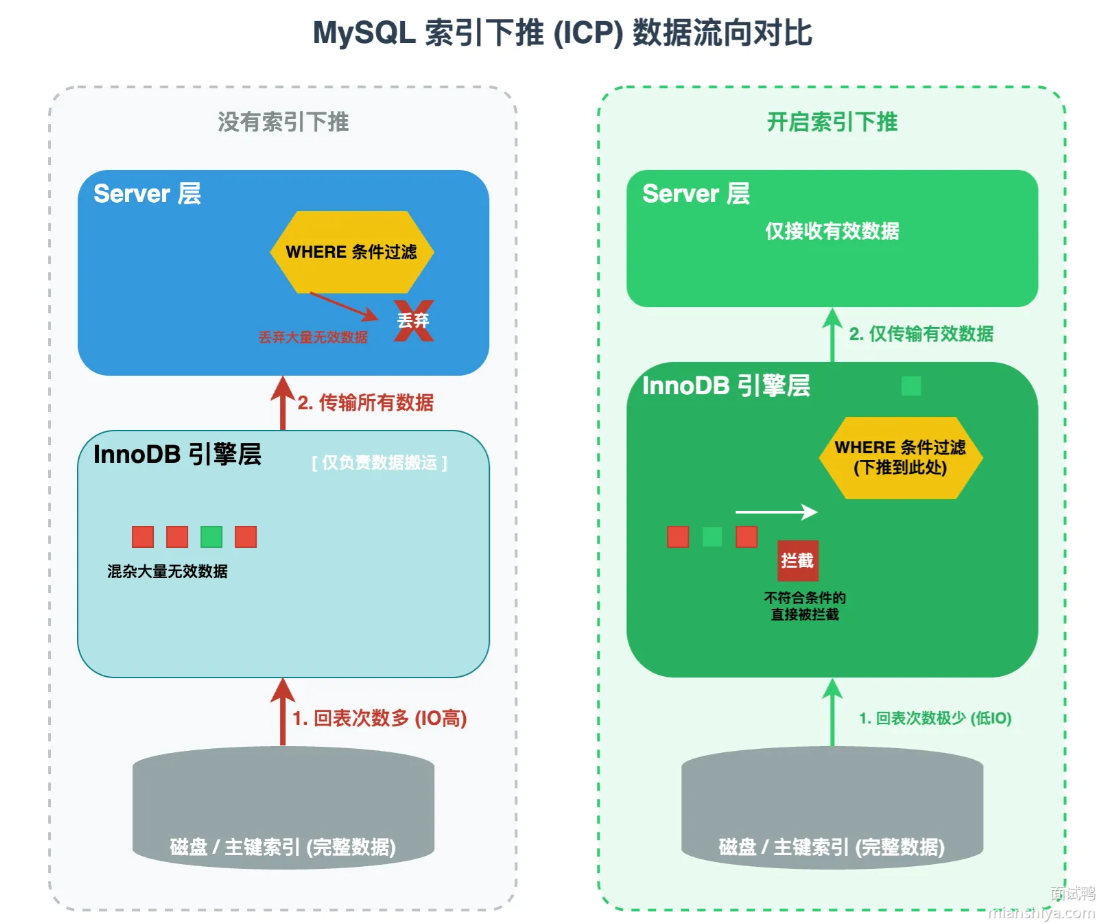
2. 下推到底是什么?
- 推什么 :把本该在Server 层 执行的**
WHERE过滤条件**,「往下推」到InnoDB 引擎层去执行。- 推到哪:从「上层的 Server 层」→「下层的存储引擎层」。
- 核心目的 :在引擎层提前拦截无效数据,不让它流到 Server 层,从而减少回表次数、降低随机 IO。
3. 典型适用场景
联合索引 + 前缀范围 / 模糊匹配 + 后缀索引字段过滤 + 需要查询全字段(必须回表)
4.关键原理:为什么能「下推」?
联合索引遵循最左前缀原则:
- 当索引前缀字段使用
LIKE、>、<等范围匹配时,后续字段无法用于索引查找;- 但这些字段仍存储在二级索引中,因此可以在引擎层直接用于过滤,无需回表。
这就是「下推」的底层依据 ------利用索引内的字段提前过滤,避免无效回表。
二、有无索引下推的区别
1. 前置准备:实战演示表结构
基于日常通用用户基础表,自带联合索引
sql
CREATE TABLE `user_demo` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键自增ID',
`name` varchar(50) DEFAULT NULL COMMENT '用户名',
`age` int DEFAULT NULL COMMENT '用户年龄',
`city` varchar(50) DEFAULT NULL COMMENT '所在城市',
`description` text COMMENT '个人简介(大文本)',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`) COMMENT '联合索引:用户名+年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;核心关键点:二级联合索引 idx_name_age (name, age),这是触发索引下推的核心前提。
接下来我们用高频业务查询 SQL 对比演示,直观看懂性能差距:
需求:查询用户名以「张」开头、年龄 20 岁的所有用户完整信息
sql
SELECT * FROM user_demo WHERE name LIKE '张%' AND age = 20;2. 无索引下推(MySQL5.5 及以下 / 手动关闭)
- 走联合索引
idx_name_age,匹配前缀name LIKE '张%',扫描所有「姓张」的索引条目;- 从索引中批量提取所有符合前缀条件的主键 ID;
- 全量逐条回表(通过主键查聚簇索引,获取完整行数据,含大文本 description);
- 回到 MySQL 服务层,判断过滤
age = 20,丢弃大量不符合年龄的无效数据。
致命痛点:假设 1000 个姓张用户,仅 10 个年龄 20,仍要无差别回表 1000 次,99% 的 IO 都是无效浪费,数据量越大查询越慢。
执行流程如下:
sql
1. MySQL Server 层
↓ 下发查询指令(只带 name 条件)
2. InnoDB 存储引擎
↓ 利用联合索引 idx_name_age
↓ 匹配 name LIKE '张%'
↓ 得到一批主键 ID
3. InnoDB **逐条回表查询完整数据**
↓ 读取所有字段(id、name、age、city、description)
4. 把所有完整数据返回给 Server 层
↓
5. Server 层在内存中过滤
↓ 判断 age = 20
↓ 丢弃不符合的数据
6. 返回最终结果3. 有索引下推(默认开启)
- 走联合索引
idx_name_age,前缀精准匹配name LIKE '张%';- 不立即回表!直接在二级索引页判断
age = 20(其实就相当于将age=20这个条件下推到引擎层进行判断);- 索引层提前过滤冗余数据,仅保留 10 条符合所有条件的主键 ID;
- 仅 10 次精准回表,直接返回最终完整结果。
极致优化收益:回表次数从 1000 次降至 10 次,随机 IO 大幅减少,查询性能提升数十倍甚至上百倍。
这里我也给出执行计划进行演示:
sql
EXPLAIN SELECT * FROM user_demo
WHERE name LIKE '张%' AND age = 20;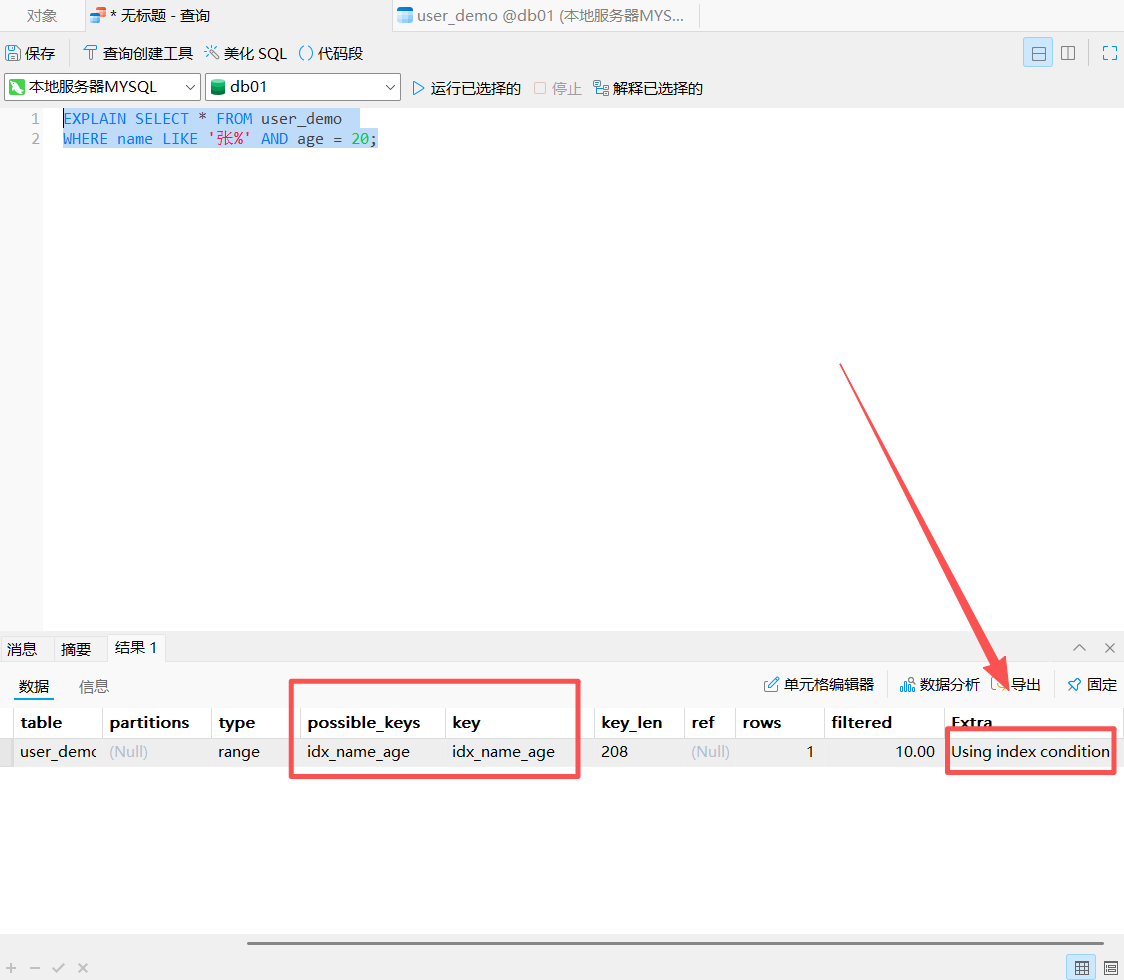
可以看到使用到了索引下推
生效标志:
type:range(走索引范围查询)Extra:Using index condition
执行流程如下:
sql
1. MySQL Server 层
↓ 把查询条件**全部下推**给 InnoDB 引擎
2. InnoDB 存储引擎
↓ 利用联合索引 idx_name_age
↓ 第一步:匹配 name LIKE '张%'
↓ 第二步:**直接在索引上判断 age = 20**
3. InnoDB 引擎提前过滤掉不符合的数据
↓ 只保留符合所有条件的主键 ID
4. 仅对少量有效数据**回表查询完整数据**
↓
5. 把有效数据返回给 Server 层
↓
6. Server 层直接返回结果三、索引下推(ICP)vs 覆盖索引
很多开发者易混淆两者,实则优化逻辑、核心目标完全不同,一句话精准区分:
- 覆盖索引:彻底不需要回表
- 索引下推:必须回表,但大幅减少回表次数
1. 单项通俗解析
覆盖索引(Covering Index)
- 核心定义:查询所需所有字段,全部存在二级索引中
- 优化逻辑:索引即数据,直接从索引取数,跳过回表步骤
- 演示 SQL:
SELECT name,age FROM user_demo WHERE name='张三' AND age=20;- EXPLAIN 标志:
Extra:Using index
索引下推(ICP)
- 核心定义:需查询全字段必须回表,引擎层提前过滤无效数据
- 优化逻辑:不避免回表,只减少回表次数
- 演示 SQL:
SELECT * FROM user_demo WHERE name LIKE '张%' AND age=20;- EXPLAIN 标志:
Extra:Using index condition
2. 极简对比表
| 对比维度 | 覆盖索引 | 索引下推(ICP) |
|---|---|---|
| 核心目标 | 完全杜绝回表 | 大幅减少回表次数 |
| 是否需要回表 | 永不回表 | 必须回表,仅减少数量 |
| 优化核心阶段 | 数据取值阶段 | 条件过滤阶段 |
| 触发核心条件 | 查询字段全部命中索引 | 联合索引 + 范围查询 + 需查全字段 |
| 执行计划标识 | Using index | Using index condition |
| 性能优先级 | 最高(最优查询) | 高(次优优化) |
感兴趣的宝子可以关注一波,后续会更新更多有用的知识!!!
