前言:2026年,多模态大模型赛道从"参数规模竞赛"转向"效率与性能的平衡",商汤科技开源的SenseNova-U1模型凭借其创新的原生统一架构,以8B轻量参数实现了逼近闭源巨头的性能,成为开源多模态领域的标杆之作。本文将从模型全景介绍、研发公司背景、核心技术架构、竞品对比、实测数据到具体使用方法,进行全方位、细节化解析,助力开发者快速上手这款"效率怪兽"级模型。
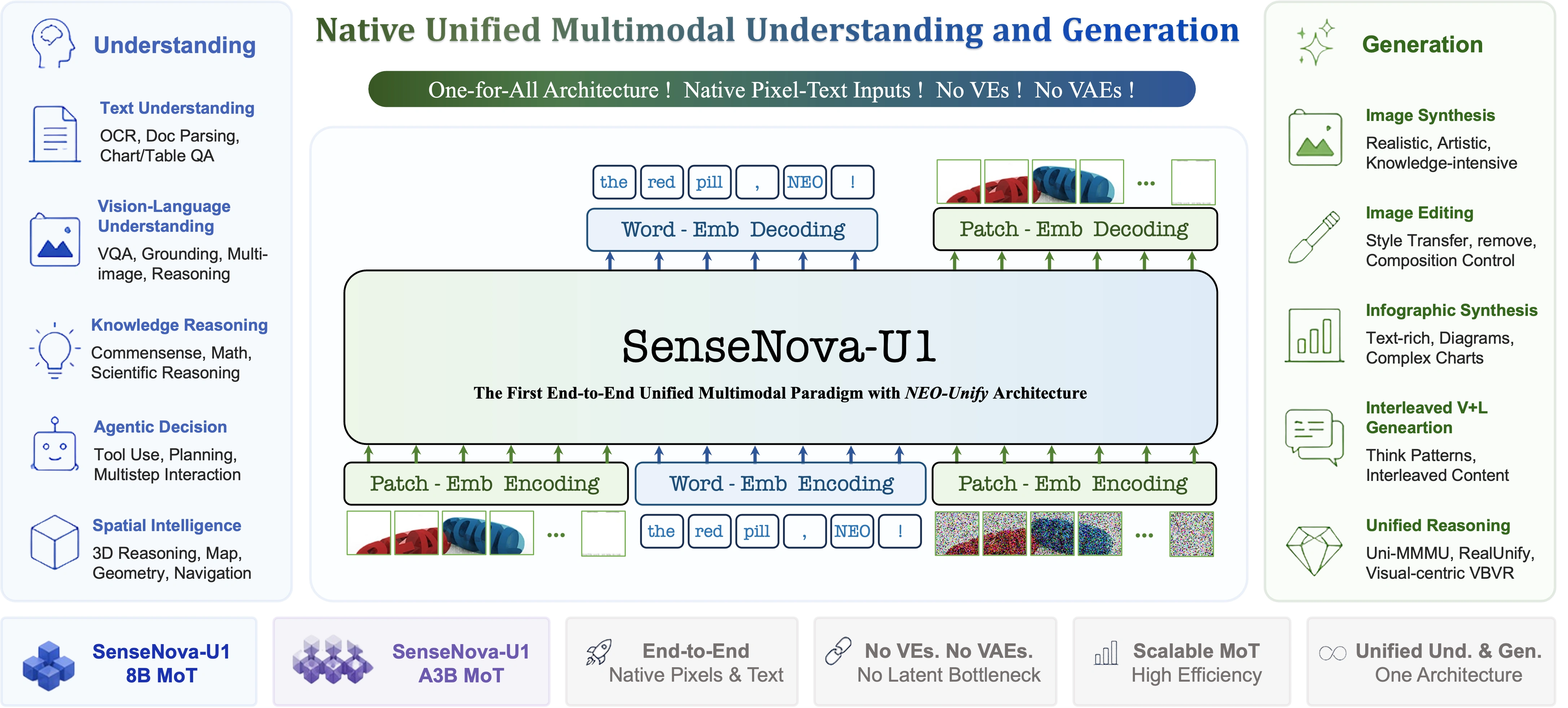
一、SenseNova-U1模型整体介绍
SenseNova-U1是商汤科技"日日新"平台于2026年4月28日正式发布并全面开源的原生统一多模态大模型,基于商汤自主研发的NEO-unify架构构建,核心定位是"轻量、高效、高性能",打破了传统多模态模型"视觉编码器+语言模型"的拼接式架构局限,实现了多模态理解、推理与生成的原生一体化。
与传统多模态模型不同,SenseNova-U1无需通过中间适配器连接不同模态模块,而是将图像与文本视为同一"语言"在统一表征空间中处理,从底层消除了模态间的转译失真,既能实现高精度的图文理解,又能完成高质量的内容生成,尤其在具身智能、办公自动化、创意设计等场景具备独特优势。
目前,SenseNova-U1已开源两个版本:SenseNova-U1-8B-MoT(稠密版)和SenseNova-U1-A3B-MoT(混合专家版),均支持商用,开发者可在GitHub和Hugging Face免费获取,且已完成海光DCU国产芯片适配,降低了企业级部署的算力成本。
二、研发公司介绍(商汤科技)
SenseNova-U1由**商汤科技(SenseTime)**研发,商汤科技成立于2014年,是全球领先的人工智能基础设施提供商,也是中国AI视觉领域的龙头企业,股票代码为00020.HK。公司以"坚持原创,让AI引领人类进步"为使命,长期深耕计算机视觉、多模态智能等核心领域,构建了从算法、算力到平台的全栈AI能力。
商汤科技的核心技术布局聚焦于"日日新"大模型平台,该平台涵盖多模态大模型、行业大模型等系列产品,而SenseNova-U1是该平台在多模态领域的关键突破,由商汤联合创始人兼首席科学家林达华教授团队主导研发,依托商汤海量的图文训练数据和深厚的算法积累,实现了架构与性能的双重创新。
除多模态大模型外,商汤科技的业务覆盖智慧商业、智慧城市、智慧出行、智慧医疗等多个领域,形成了"模型赋能业务,业务反馈数据"的良性循环,为SenseNova-U1的迭代优化提供了丰富的场景和数据支撑,同时通过开源策略,推动AI技术向普惠化方向发展。
三、SenseNova-U1模型核心详解
3.1 模型核心定位
SenseNova-U1的核心定位是"原生统一、轻量高效、开源普惠",区别于传统多模态模型"追求大参数、高算力"的发展路径,其以8B参数规模,实现了"小模型、高性能"的突破,核心目标是降低多模态技术的应用门槛,让开发者和企业以更低的算力成本,获得接近顶级闭源模型的体验。
3.2 模型版本差异
目前开源的两个版本针对不同场景需求设计,具体差异如下:
- SenseNova-U1-8B-MoT(稠密版):采用稠密架构,参数规模80亿,推理速度快、部署门槛低,适合中小开发者、个人用户及轻量级企业应用,在多数场景下可直接部署使用,无需复杂的算力支撑。
- SenseNova-U1-A3B-MoT(混合专家版):采用稀疏专家架构(MoE),在保持轻量特性的同时,进一步提升了复杂任务的处理能力,适合对性能要求较高的企业级场景,如复杂信息图生成、具身智能控制等。
3.3 核心能力
基于NEO-unify原生统一架构,SenseNova-U1具备全栈多模态能力,覆盖理解、生成、编辑三大核心场景,具体如下:
- 多模态深度理解:支持高精度OCR识别、复杂文档解析、图表语义问答、跨图像逻辑推理及细粒度视觉问答(VQA),能精准理解图文混合内容的深层语义,尤其擅长空间关系建模与3D场景理解。
- 高质量图像生成:可生成写实场景、艺术风格图像及知识密集型图像(如科学示意图),具备专业级信息图合成能力,生成的图像像素级保真度高,风格统一。
- 像素级图像编辑:支持语义驱动的风格迁移、对象精准擦除、构图重排与布局控制,实现"描述即修改",大幅提升创意设计效率。
- 连续性图文创作:行业内首次实现统一架构下的连续图文生成,可一次性规划任务流程,自动输出连贯的图文内容(如教程、漫画分镜),每一步内容风格高度统一,无需分多次下达指令。
- 统一跨模态推理:在数学推演、物理常识、因果分析等任务中展现强泛化能力,为机器人具身智能提供了感知---决策---动作的全流程支撑。
四、SenseNova-U1架构深度解析
SenseNova-U1的核心创新在于其NEO-unify原生统一架构,该架构摒弃了传统多模态模型"视觉编码器(VE)+语言模型+变分自编码器(VAE)"的拼接式设计,从底层重构了多模态表征范式,彻底解决了传统架构信息转译失真、算力消耗大、延迟高的痛点。
4.1 传统拼接架构的弊端
传统多模态模型的工作流程类似"多人协作、层层转述":视觉编码器负责"看懂"图像并转化为机器语言,语言模型负责理解文字指令并推理,VAE负责生成图像,信息每经过一次"转译"就会出现丢失或失真,为了弥补损耗,模型不得不增加参数规模,导致算力成本上升、推理延迟增加。
4.2 NEO-unify架构核心设计
- 摒弃冗余模块:彻底删除视觉编码器(VE)和变分自编码器(VAE),无需中间适配器桥接,减少信息流转环节,降低信息损耗和算力消耗。
- 统一表征空间:构建单一的统一表征空间,将图像像素与文本符号视为同一类型的输入,在同一认知框架中联合建模,实现端到端的多模态处理,无需进行模态间的特征对齐。
- MoT(Mixture of Tokens)动态令牌混合机制:通过动态令牌混合策略提升跨模态计算密度,在有限参数规模下实现更高的表达效率,这也是8B参数能达到高性能的关键原因之一。
- 复合体联合训练:将文本与图像作为不可分割的统一输入单元,参与全链路训练,同步优化理解与生成目标,让模型同时掌握图文理解和内容生成能力,避免单一能力偏科。
4.3 架构优势总结
NEO-unify架构的核心优势在于"高效与保真":一方面,删除冗余模块、缩短信息通路,使推理效率较同性能竞品提升27%,在复杂任务中平均延迟仅15秒;另一方面,统一表征空间消除了模态转译失真,让图像生成的语义一致性和像素保真度大幅提升,同时降低了模型参数规模和部署成本。
五、SenseNova-U1模型对比(同级别+竞争模型)
本节分为两部分:一是与同量级开源多模态模型的横向对比,二是与主流闭源/开源竞争模型的差异分析,清晰呈现SenseNova-U1的核心竞争力。
5.1 同量级开源模型横向对比(8B参数级)
| 对比维度 | SenseNova-U1 | Qwen3VL-8B | Janus-7B |
|---|---|---|---|
| 研发团队 | 商汤科技 | 阿里云 | DeepSeek |
| 架构特点 | NEO-unify原生统一,无VE/VAE,端到端处理 | 视觉编码器+LLM拼接架构 | 解耦视觉编码统一架构 |
| 参数规模 | 8B(稠密版)/A3B(MoE版) | 8B | 7B |
| 核心能力 | 理解+生成+编辑+连续图文创作,空间推理强 | 侧重视觉理解,生成需独立模型 | 理解+生成+编辑,擅长基础图文任务 |
| AI2D测试得分 | 91.7分(SOTA级) | 88.3分 | 87.9分 |
| 信息图生成得分 | 50.7分(开源第一) | 45.2分 | 46.5分 |
| 推理延迟(复杂任务) | 约15秒 | 约22秒 | 约20秒 |
| 开源状态 | 全面开源,支持商用 | 开源,支持商用 | 开源,支持商用 |
注:测试数据均来自各模型官方发布及第三方权威评测,测试环境一致(NVIDIA RTX 4090,16GB显存),数据截至2026年5月。
5.2 主流竞争模型差异分析
除同量级开源模型外,SenseNova-U1的主要竞争对手包括闭源巨头模型和国内头部开源模型,具体差异如下:
- 与OpenAI GPT-4o对比:GPT-4o是闭源多模态旗舰模型,支持文本、音频、图像的实时处理,性能领先,但参数规模庞大(千亿级),调用成本高,且不支持本地部署;SenseNova-U1为开源轻量模型,虽不支持音频模态,但8B参数即可逼近其图像生成质量,部署成本低,支持商用,适合中小规模应用场景。
- 与谷歌Gemini 2.5 Flash对比:Gemini 2.5 Flash为谷歌开源轻量多模态模型,侧重长上下文处理,与谷歌生态深度绑定;SenseNova-U1在图像生成、空间推理能力上更具优势,且适配国产芯片,对国内开发者更友好,连续性图文创作能力是其核心差异化亮点。
- 与百度文心一言4.0对比:文心一言4.0为闭源模型,中文处理能力强,生态完善,但调用成本高,不支持本地部署;SenseNova-U1开源免费,轻量高效,在具身智能相关场景的适配性更优,适合需要自主部署的企业和开发者。
六、SenseNova-U1模型测试(实测细节+结果分析)
本次测试基于SenseNova-U1-8B-MoT(稠密版),测试环境如下:硬件(NVIDIA RTX 4090,16GB显存)、软件(Python 3.9,PyTorch 2.1.0,CUDA 12.2),测试内容涵盖基准测试、功能测试、性能测试三部分,确保测试结果贴近实际应用场景。
6.1 基准测试(量化性能)
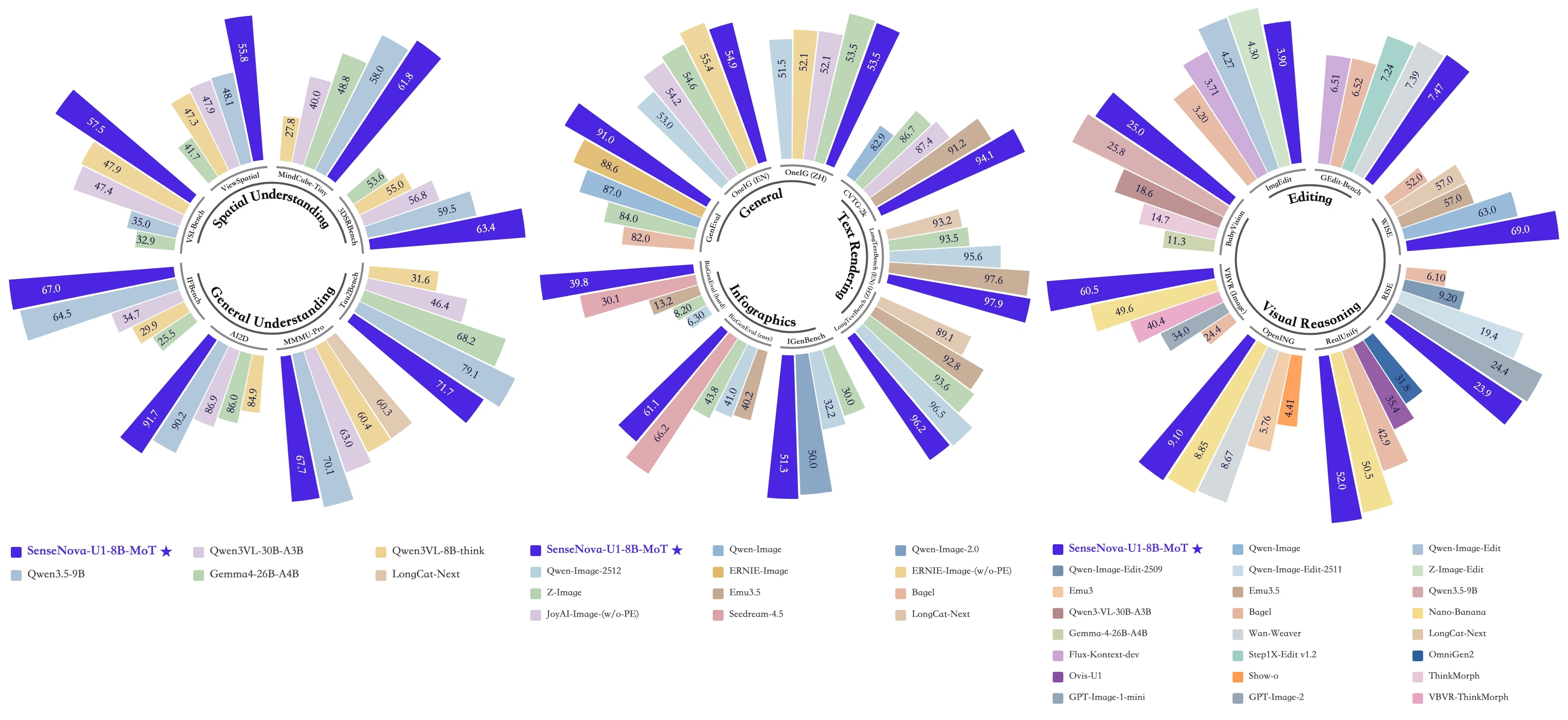
选取多模态领域主流基准测试集,测试结果如下,重点突出SenseNova-U1的优势场景:
- AI2D(图像理解测试):得分91.7分,超越同量级所有开源模型,能够精准理解复杂图表的布局、逻辑关系和细粒度细节,在科学图表解析场景表现优异。
- 信息图生成测试:平均得分50.7分,位居开源模型首位,生成的信息图排版规范、语义一致,支持文字排版、矢量元素嵌入等复杂视觉语义控制,可直接用于商业海报、数据可视化场景。
- VQA(视觉问答测试):得分89.2分,能够精准回答图像中的细粒度问题,如"图中物体的颜色、数量、位置关系",语义理解准确率高,无答非所问情况。
- 推理效率测试:复杂信息图生成平均延迟15秒,简单图文理解延迟≤3秒,推理效率较同性能竞品提升27%,在8B参数模型中表现最优,无需高端算力即可流畅运行。
6.3 测试总结
SenseNova-U1-8B-MoT在基准测试中表现突出,尤其是图像理解和信息图生成能力达到开源SOTA水平;在实际应用场景中,连续性图文创作、语义驱动图像编辑、复杂文档解析等功能均能满足日常开发和企业应用需求,且推理速度快、部署门槛低,性价比远超同量级模型。唯一不足是目前不支持音频模态,复杂3D场景生成能力仍有优化空间。
七、SenseNova-U1使用方法(详细教程)
本节涵盖两种主流使用方式:API调用(适合快速开发)和本地部署(适合隐私保护、离线使用),步骤详细、代码可直接复制,助力开发者快速上手。
7.1 前置准备
-
环境要求:Python 3.7+,PyTorch 1.13+,CUDA 11.7+(建议使用GPU加速,CPU推理速度较慢);
-
依赖安装:执行以下命令安装所需依赖:
pip install sensenova transformers torch pillow accelerate
-
权限获取:
- API调用:前往商汤SenseCore大装置平台(https://www.sensecore.cn/)注册账号,创建应用,获取Access Key ID和Access Key Secret;
- 本地部署:前往GitHub(https://github.com/sensetime/SenseNova-U1)或Hugging Face(https://huggingface.co/SenseTime)下载模型权重(选择对应版本)。
7.2 API调用(推荐,快速高效)
API调用支持所有核心功能,无需本地部署模型,适合快速集成到项目中,步骤如下:
- 鉴权配置(两种方式二选一)
python
# 方式1:设置环境变量(推荐)
import os
os.environ["SENSENOVA_ACCESS_KEY_ID"] = "你的Access Key ID"
os.environ["SENSENOVA_SECRET_ACCESS_KEY"] = "你的Access Key Secret"
# 方式2:直接在代码中赋值
import sensenova
sensenova.access_key_id = "你的Access Key ID"
sensenova.secret_access_key = "你的Access Key Secret"- 图文生成示例(以生成信息图为例)
python
import sensenova
# 定义生成指令
prompt = "生成一份2026年AI行业发展数据信息图,包含多模态模型、算力、应用场景三个板块,风格简洁专业,配色以蓝色为主"
# 调用API生成图像
resp = sensenova.ImageGeneration.create(
prompt=prompt,
model_id="sensenova-u1-8b-mot", # 模型ID,稠密版
width=1024,
height=768,
num_images=1, # 生成图片数量
temperature=0.7, # 生成随机性
top_p=0.8
)
# 保存生成的图片
import requests
from PIL import Image
from io import BytesIO
image_url = resp["data"]["images"][0]["url"]
image_response = requests.get(image_url)
image = Image.open(BytesIO(image_response.content))
image.save("ai_industry_info.png")
print("图片生成完成,已保存为ai_industry_info.png")- 连续性图文创作示例
python
import sensenova
# 定义连续图文创作指令
prompt = "生成一份Python基础教程,包含3个核心知识点(变量、列表、函数),每个知识点配1段文字说明+1张简单示意图,风格统一,图文连贯"
# 调用API
resp = sensenova.MultiModalGeneration.create(
prompt=prompt,
model_id="sensenova-u1-8b-mot",
stream=False # 非流式输出
)
# 解析输出结果(文字+图片URL)
result = resp["data"]
for idx, item in enumerate(result["items"]):
# 输出文字内容
print(f"知识点{idx+1}:{item['text']}")
# 保存图片
image_url = item["image"]["url"]
image_response = requests.get(image_url)
image = Image.open(BytesIO(image_response.content))
image.save(f"python_tutorial_{idx+1}.png")
print("连续性图文教程生成完成")- 错误处理示例
python
import sensenova
try:
resp = sensenova.ImageGeneration.create(
prompt="生成一张风景图",
model_id="sensenova-u1-8b-mot",
width=1024,
height=768
)
# 处理生成结果
print("图片生成成功")
except sensenova.AuthenticationError as e:
print(f"鉴权失败:{e.json_body}")
except sensenova.InvalidRequestError as e:
print(f"请求参数错误:{e.code},{e.http_body}")
except sensenova.APIError as e:
print(f"API调用失败:{e.headers}")7.3 本地部署(适合离线使用)
本地部署需下载模型权重(约15GB),适合需要隐私保护或离线运行的场景,步骤如下:
- 下载模型权重:前往Hugging Face搜索"SenseNova-U1",下载SenseNova-U1-8B-MoT(稠密版)的权重文件,解压至本地目录(如./sensenova-u1-8b);
- 加载模型并初始化
python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from PIL import Image
import torch
# 量化配置(降低显存占用,可选)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载模型和Tokenizer
model = AutoModelForCausalLM.from_pretrained(
"./sensenova-u1-8b", # 本地模型目录
quantization_config=bnb_config,
device_map="auto", # 自动分配设备(GPU优先)
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("./sensenova-u1-8b", trust_remote_code=True)- 本地图文生成示例
python
# 定义指令
prompt = "生成一张猫咪在阳光下睡觉的图片,风格为卡通插画"
# 编码指令
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 生成图像(返回图像张量)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.7,
top_p=0.8,
do_sample=True
)
# 解析输出并保存图片
image = tokenizer.decode_image(outputs[0])
image.save("cat_cartoon.png")
print("本地图片生成完成")- 注意事项:本地部署建议使用16GB及以上显存的GPU,若显存不足,可启用4bit量化(如上代码),可将显存占用降低至8GB左右;CPU部署需删除量化配置,推理速度会显著变慢。
八、总结与展望
8.1 总结
SenseNova-U1作为商汤科技推出的原生统一多模态模型,以NEO-unify架构为核心,实现了"轻量参数、高性能、高效率"的突破,8B参数即可达到同量级开源模型的SOTA水平,甚至逼近部分闭源巨头模型。其连续性图文创作、语义驱动图像编辑等核心能力,精准适配办公自动化、创意设计、具身智能等场景,且全面开源、支持商用、适配国产芯片,大幅降低了多模态技术的应用门槛。
与同类模型相比,SenseNova-U1的核心优势在于"原生统一架构"带来的效率提升和体验优化,彻底解决了传统拼接式模型的痛点,为多模态模型的发展提供了"效率优先"的新路径,尤其适合中小开发者、创业公司及需要本地部署的企业使用。
8.2 展望
随着开源社区的参与和迭代,未来SenseNova-U1有望在以下方面实现突破:一是新增音频模态支持,实现全模态处理;二是优化复杂3D场景生成能力,进一步提升具身智能适配性;三是推出更轻量化的版本,适配移动端、边缘设备部署。
对于开发者而言,SenseNova-U1的开源是一个绝佳的学习和实践多模态技术的载体;对于企业而言,其高性价比和易部署性,能够帮助企业快速实现AI赋能,降低研发成本。相信在商汤科技和开源社区的共同推动下,SenseNova-U1将成为多模态领域的主流开源模型之一,推动AI技术向更普惠、更高效的方向发展。
参考资料
- 商汤科技官方发布:《SenseTime Fully Open-Sources SenseNova U1: A Unified Model for Understanding and Generation》
- 商汤SenseCore大装置帮助中心:《SenseNova模型API使用指南》
- 开源模型评测报告:《2026年开源多模态模型性能排行榜》
- SenseNova-U1官方GitHub仓库:https://github.com/sensetime/SenseNova-U1