****论文题目:****FreDN: Spectral Disentanglement for Time Series Forecasting via Learnable Frequency Decomposition(基于可学习频率分解的时间序列预测的频谱解纠缠)
会议:AAAI2026
****摘要:****时间序列预测在现实世界的广泛应用中是必不可少的。最近,频域方法因其捕获全局依赖关系的能力而吸引了越来越多的兴趣。然而,当这些方法应用于非平稳时间序列时,会遇到谱纠缠和复值学习的计算负担。频谱纠缠是指由于频谱泄漏和非平稳性的存在,导致频谱上的趋势、周期性和噪声的重叠。然而,现有的分解不适合解决光谱纠缠。为了解决这个问题,我们提出了频率分解网络(FreDN),它引入了一个可学习的频率分解模块来直接在频域中分离趋势分量和周期分量。此外,我们提出了一个理论上支持的ReIm块,以降低复杂值操作的复杂性,同时保持性能。我们还重新审视频域损失函数,并为其有效性提供新的理论见解。在七个长期预测基准上的广泛实验表明,FreDN比最先进的方法高出10%。此外,与标准的复值架构相比,我们的实-虚共享参数设计将参数计数和计算成本减少了至少50%。
FreDN:用可学习频率分解打破时间序列预测中的频谱纠缠
一、为什么频域方法在非平稳时间序列上遇到麻烦?
近年来,频域方法(如 FreTS、FITS、FreDF)在时间序列预测领域受到越来越多的关注。与时域方法相比,频域方法天然擅长捕获全局依赖和周期性结构,也有更强的噪声抑制能力。然而,当这些方法被应用于真实世界的非平稳时间序列时,两个根本性的挑战始终如影随形。
挑战一:频谱纠缠(Spectral Entanglement)
在理想情况下,时间序列的趋势、周期和噪声成分应当在频域中清晰分离------趋势占据低频,周期成分集中在若干特定频率,噪声均匀分布。然而现实并非如此,这三类成分的频谱能量在实际中大量重叠,这一现象被称为频谱纠缠。
造成频谱纠缠的原因有两个:
1. 频谱泄露:离散傅里叶变换(DFT)的频率分辨率受到回望窗口长度 L 的限制。任何真实频率只要不与 DFT 的离散基严格对齐,其能量就会"泄漏"并扩散到所有频率上,污染整个频谱。
2. 非平稳趋势的宽频特性:趋势成分本身不具有周期性,因此无法用少数几个正弦基准确表示。它的频谱能量天然分布在所有频率上,与周期成分的频谱深度交织在一起。
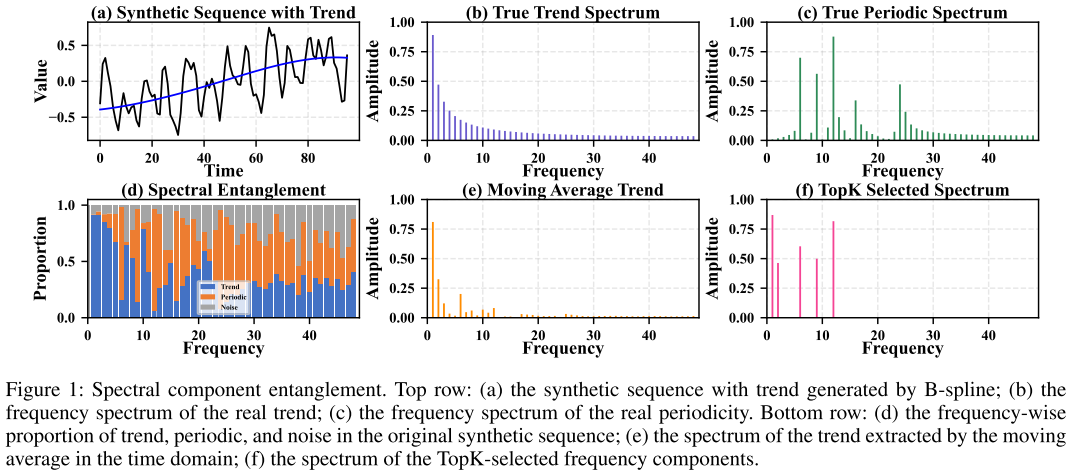
【配图:Figure 1】 展示了一个含趋势的合成序列及其频谱纠缠情况。可以看到 (d) 图中趋势、周期和噪声在每个频率上的比例相互混叠;(e) 图显示移动平均提取的趋势频谱存在明显旁瓣泄露;(f) 图显示 Top-K 选频的结果同样不能干净地分离成分。
挑战二:现有分解方法力不从心
面对频谱纠缠,已有的两类经典处理方式均存在明显缺陷:
- 移动平均(Moving Average) :等价于在频域施加一个固定低通滤波器,其滤波器频率响应为
,存在显著的旁瓣,会在提取的趋势中引入系统性的频谱伪影,并非真实趋势的频谱特性。
- Top-K 频率选择:仅保留幅度最大的 K 个频率作为周期成分,但由于泄露和重叠,这 K 个频率并不能真正代表干净的周期信息,而且丢弃的频率中同样可能包含有用的趋势能量。
挑战三:复数值学习的计算负担
频域学习本质上涉及复数运算。现有工作(如 FEDformer、FreTS)直接采用复数矩阵乘法,需要同时维护实部和虚部两套参数,不仅参数量翻倍,也难以与标准实数值神经网络(如带 LayerNorm、GELU、Dropout 的 MLP)无缝集成。
二、FreDN 的整体架构
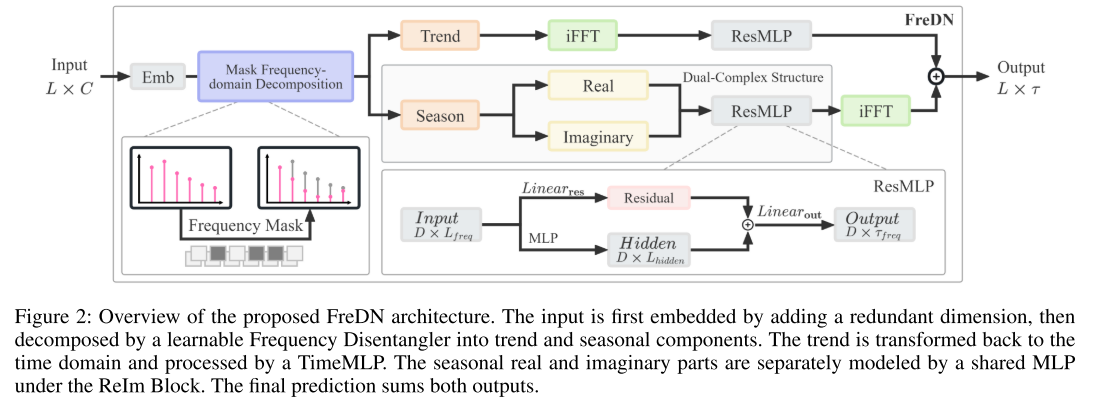
【配图:Figure 2】 FreDN 的整体架构图。
FreDN(Frequency Decomposition Network)的完整前向推理过程如下:
- RevIN 归一化:对输入做可逆实例归一化,消除分布偏移。
- 序列嵌入(Series Embedding) :将输入
- FFT 变换 :沿时间轴做实值 FFT,得到频域表示
- Frequency Disentangler:自适应地将频谱分解为趋势和季节成分。
- 趋势分支:将趋势成分逆变换回时域,由 TimeMLP 建模。
- 季节分支:季节成分在频域由 ReIm Block 处理。
- 合并预测 :
三、核心创新一:可学习频率解纠缠器(Frequency Disentangler)
理论基础:Sobolev 光滑趋势的频谱衰减
论文首先从理论上刻画了平滑趋势在频域的特性。对于 Sobolev 光滑函数 (
),其 Fourier 系数满足:
这意味着平滑趋势在所有频率上均有非零能量,但随频率指数 k 增大而衰减。B-样条、局部多项式回归、核平滑等常见趋势表示都属于此类函数。因此,试图用"低频 = 趋势、高频 = 季节"这样的简单二分法来分解频谱是有缺陷的------每个频率都同时包含趋势和季节的贡献。
自适应频率解纠缠
基于上述理论,FreDN 引入一个可学习掩码 ,对频域的每个频率成分独立分配趋势和季节权重:
其中 为 sigmoid 函数,保证权重在 0,1 之间,且趋势和季节权重之和为 1(即软性频率分配)。初始化时,利用趋势频谱衰减的先验知识,当 m=1 时可用
初始化趋势权重,引导模型从合理的起点开始学习。
这种设计的关键优势在于:每个频率的解纠缠是独立的、自适应的,而不是依赖于固定的频率边界或振幅排序。解纠缠后的趋势频谱平滑、连续,季节频谱则相对平稳,为后续分支的建模提供了更干净的输入。
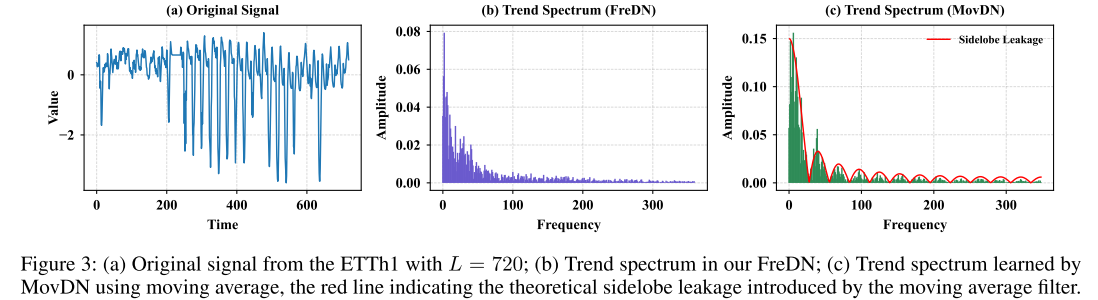
【配图:Figure 3】 对比 FreDN 和 MovDN 在 ETTh1 真实数据(L=720)上提取的趋势频谱:FreDN 的趋势频谱(b图)平滑衰减,而 MovDN 的趋势频谱(c图)存在明显的旁瓣泄露(红线标示理论旁瓣位置)。
消融实验:解纠缠方式对比
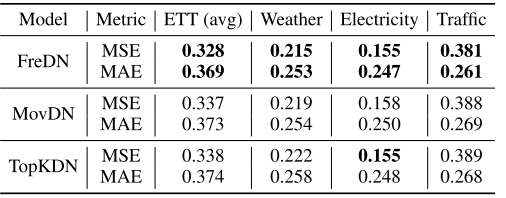
【配表:Table 2】 不同分解方法(FreDN、MovDN、TopKDN)的预测性能对比。
在四个 ETT 数据集的平均 MSE 上,FreDN(0.328)明显优于 MovDN(0.337)和 TopKDN(0.338)。在 Weather 和 Traffic 数据集上也呈现一致的优势,充分说明在频域直接进行自适应解纠缠是更有效的分解策略。
四、核心创新二:ReIm Block(实虚共享参数块)
动机:避免完整复数运算的复杂性
标准的复数线性层形如:
其中实部权重 对输入做实数加权投影,而虚部权重
相当于对输入做 90° 正交旋转后再做实数加权投影,两者使用不同参数。这导致参数量比对应的实数网络翻倍,且无法直接使用 LayerNorm、GELU 等激活和正则化操作(PyTorch 中这些操作不原生支持复数张量)。
理论保证:实数投影的表达能力
论文证明(Theorem 2):对于复值输入向量 ,若其中至少存在两个分量
满足相位差
(即在复平面上实线性无关),则实数加权投影
(
)可以表示任意复数。
直觉上,复平面是一个二维实向量空间,只要输入中存在两个方向不平行的复数,它们的实线性组合就能张满整个复平面,从而表示任意复数。对于真实时间序列,频谱的复杂性几乎总能保证这一条件成立。
ReIm Block 的具体形式
实部和虚部分别通过共享权重的同一个 MLP 处理,结果重新组合为复数形式再做 IFFT。这样:
- 参数量相比 Complex-Linear 减少超过 50%
- 可以无缝集成 LayerNorm、GELU、Dropout 等标准组件
- 没有性能损失,实验中甚至略优于 Complex-Linear
效率对比实验
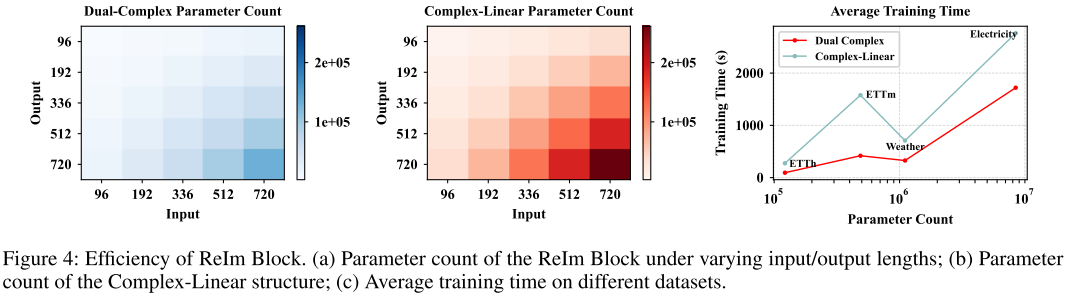
【配图:Figure 4】 ReIm Block 与 Complex-Linear 在不同输入/输出长度下的参数量对比,以及在不同数据集上的平均训练时间对比。
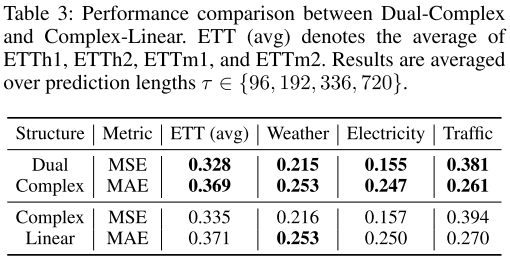
【配表:Table 3】 ReIm Block(Dual-Complex)与 Complex-Linear 在各数据集上的预测性能对比。
ReIm Block 在所有输入/输出长度配置下,参数量均约为 Complex-Linear 的一半;训练时间在 ETTm 数据集上最多缩短 75%;同时在 ETT 平均 MSE(0.328 vs 0.335)、Weather、Electricity 等数据集上均保持持平或更优的预测精度。
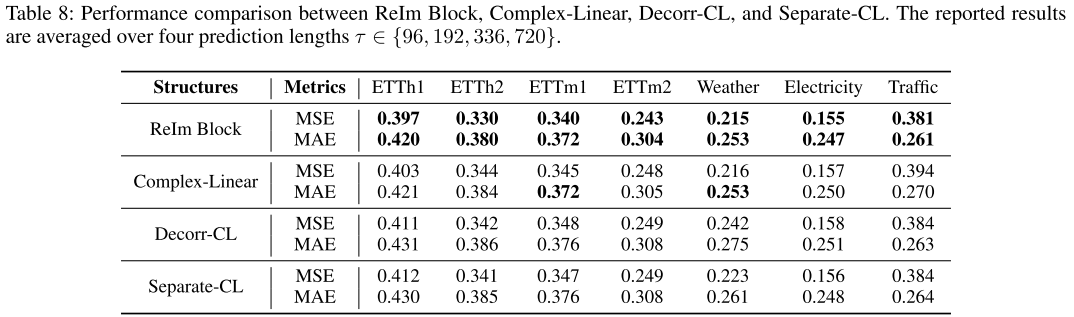
【配表:Table 8】 进一步与 Decorr-CL、Separate-CL(引入复数 LayerNorm 和激活的强化版 Complex-Linear)的全面对比,ReIm Block 仍以更少的参数量取得最优性能。
五、核心创新三:频域 MAE 损失的梯度视角分析
四种损失函数的梯度行为
论文对时域 MSE、频域 MSE、时域 MAE 和频域 MAE 四种损失函数的梯度进行了系统推导:
| 损失函数 | 梯度 | 特性 |
|---|---|---|
| 时域 MSE | 与时域 MAE 仅相差常数因子 | |
| 频域 MSE | 与时域 MSE 等价,仅差常数 | |
| 时域 MAE | 每个时间步收到 ±1 的孤立局部梯度 | |
| 频域 MAE | 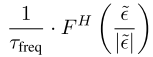 |
每个频率分量携带单位模长的复数梯度,其相位编码了正弦基在时域中的时移信息,反变换后产生全局结构化梯度,使得每个时间步的更新来自多个频率成分的贡献,有利于捕获全局时序模式。 |
频域 MAE 为何更有效?
时域 MAE 的梯度在每个时间步都是一个实数标量(+1 或 -1),由该时刻的残差符号单独决定------这是局部、孤立的梯度信号,不同时间步之间没有协调。
频域 MAE 的梯度则完全不同: 是每个频率上的单位复数,其相位编码了该频率对应正弦基的时移信息。经过
(逆 DFT)映射回时域后,每个时间步的梯度更新是所有频率成分贡献的叠加------这是全局、结构化的梯度信号。这种长程梯度相互作用有助于模型在反向传播中捕获全局时序模式,与主导频率对齐。

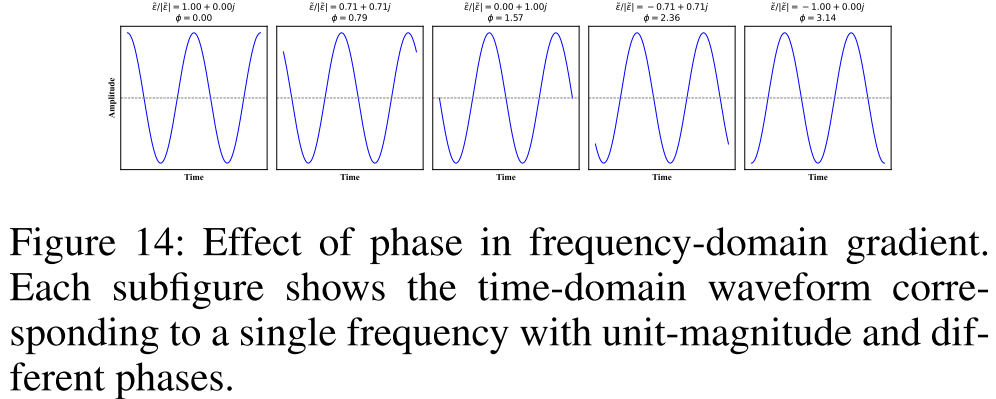
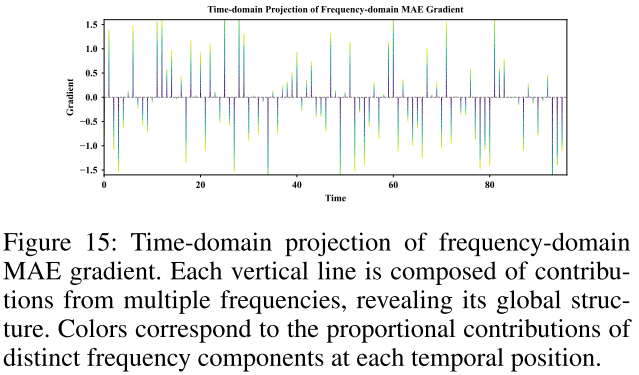
【配图:Figure 12 & 13 & 14 & 15】 直观对比时域 MAE 梯度(每步孤立的 ±1)与频域 MAE 梯度(单位模长复数,经逆变换后形成全局结构化波形叠加)。
论文同时指出了 FreDF 原文中的一个理论错误:频域 MAE 并非因为"去除了标签的自相关性"而有效------DFT 作为线性变换会保留残差的相关结构,不能做到去相关。其有效性真正来源于上述结构化梯度的全局传播特性。
六、实验结果
主实验:七大基准数据集
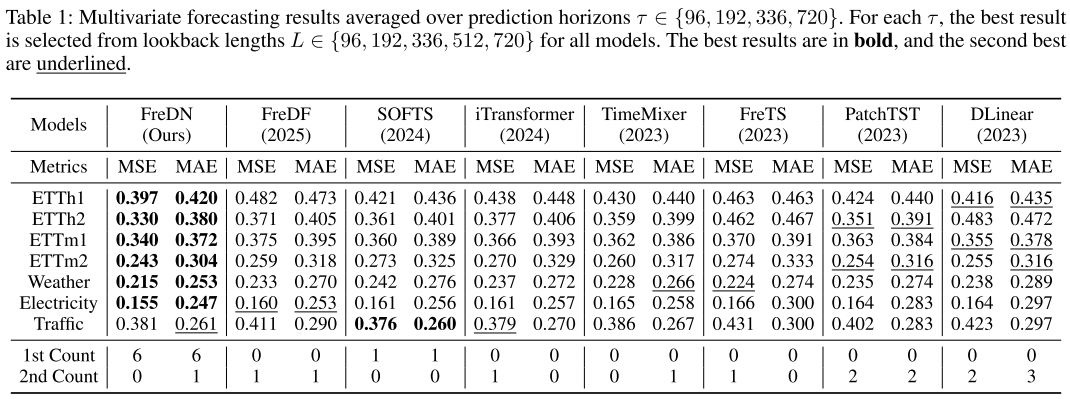
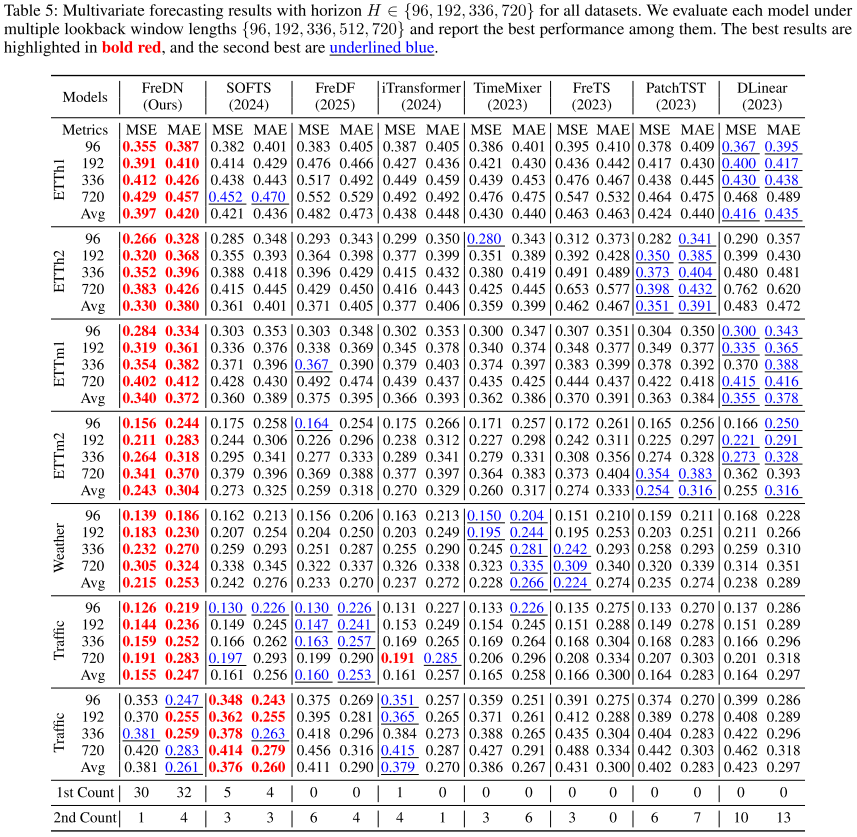
【配表:Table 1(主文)/ Table 5(附录完整版)】 七个数据集上的多变量长期预测结果(MSE 和 MAE,平均自 τ∈{96,192,336,720})。
实验在 ETTh1、ETTh2、ETTm1、ETTm2、Weather、Electricity、Traffic 七个广泛使用的基准上进行,基线包括 MLP 类(DLinear、TimeMixer、SOFTS)、频域类(FreTS、FreDF)和 Transformer 类(iTransformer、PatchTST)共七个模型。所有模型在相同预测长度下对五个回望窗口 取最优结果进行比较。
主要结论:
- FreDN 在平均 MSE 上比 FreDF 提升约 10% ,比 FreTS 提升约 14% ,比 SOFTS 和 TimeMixer 提升约 6%。
- 在 35 个 MSE 评测条目中,FreDN 30 个排名第一 ;在 35 个 MAE 评测条目中,FreDN 32 个排名第一。
- Wilcoxon 符号秩检验(28 个预测任务)显示,FreDN 对 FreDF 和 SOFTS 的提升均具有统计显著性(
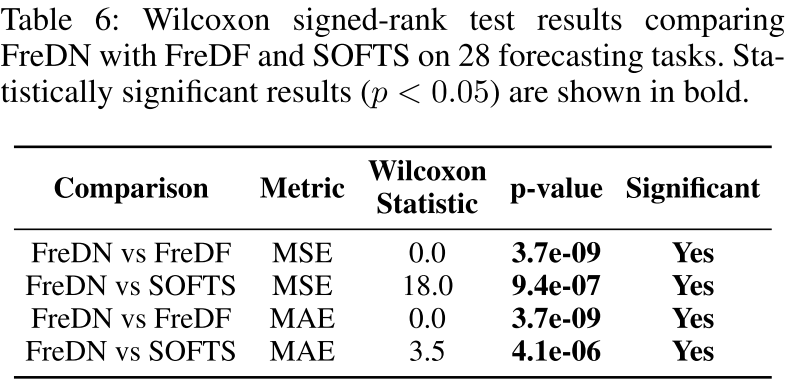
【配表:Table 6】 Wilcoxon 符号秩检验结果。
与 TimeMixer++(ICLR 2025)的对比也显示 FreDN 全面占优,但由于 TimeMixer++ 使用固定 且无公开实现,未纳入主对比。

【配表:Table 7】 与 TimeMixer++ 的对比结果。
回望窗口长度的影响
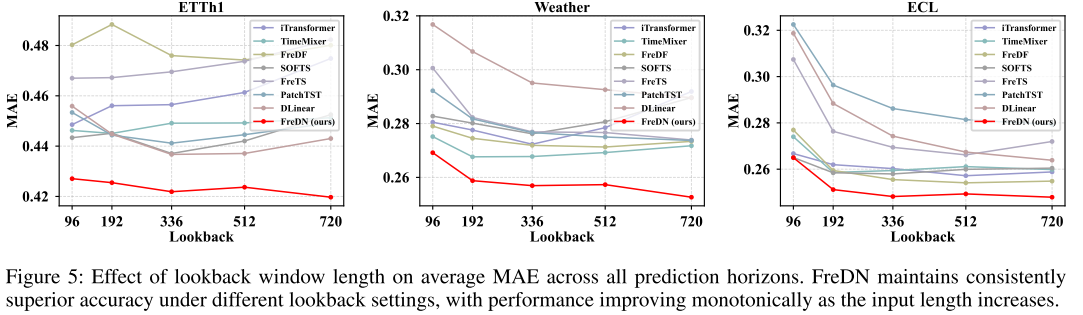
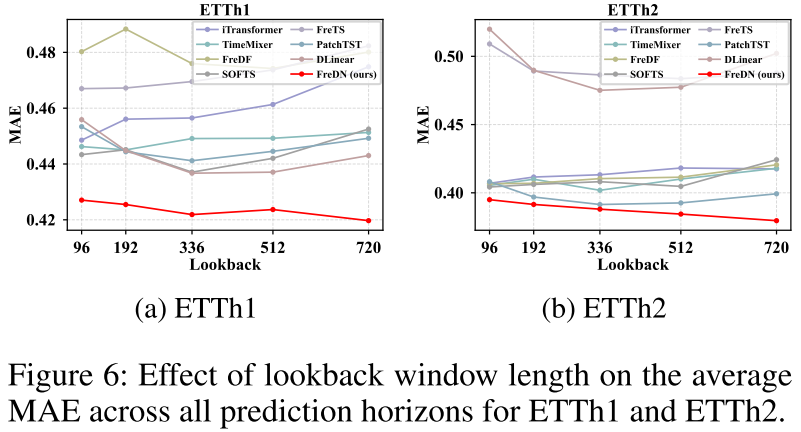
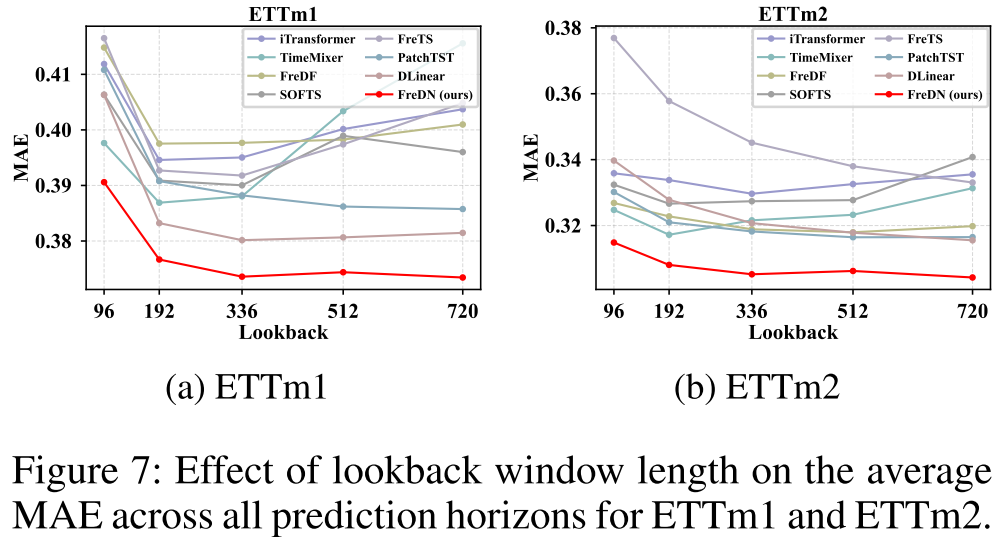
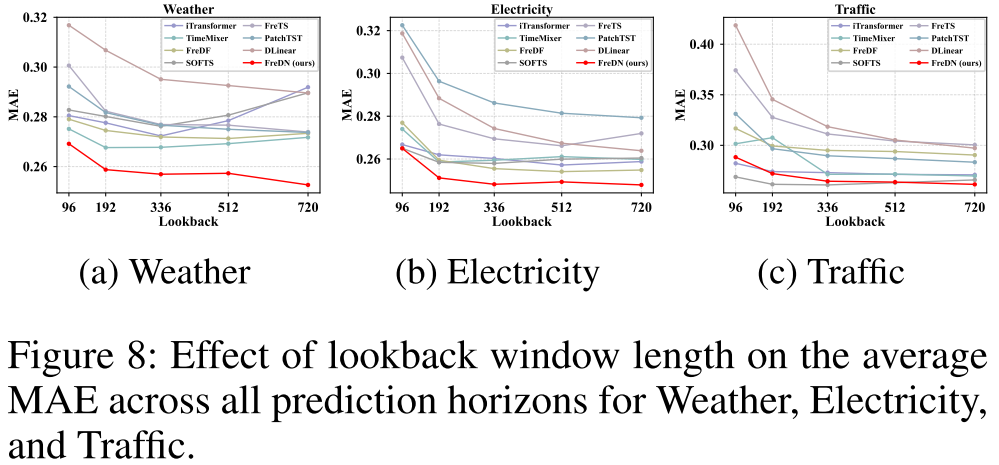
【配图:Figure 5 / Figure 6 / Figure 7 / Figure 8】 不同回望窗口长度下,FreDN 与各基线在各数据集上的平均 MAE 变化曲线。
这是一组非常有说服力的实验结果。随着回望窗口 L 从 96 增大到 720,大多数基线模型的性能出现退化 ------更长的历史输入反而带来更差的预测。FreDN 则是唯一一个在所有数据集上都保持单调改善的模型,且在高维数据集(Electricity、Traffic)上性能提升的斜率最陡。这表明频域解纠缠框架能更充分地利用长程时序信息,而不会因远距离输入与未来目标的弱相关性而受到干扰。
稳定性验证
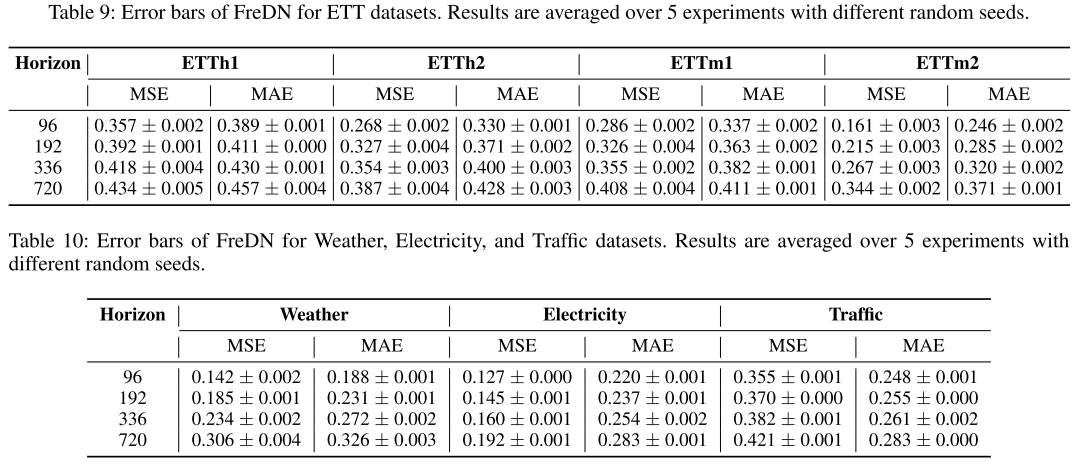
【配表:Table 9 & 10】 FreDN 在五个不同随机种子下的均值与标准差。
所有数据集和预测长度下,标准差均保持在很低的水平,证明 FreDN 的性能稳定可靠,不依赖特定的随机初始化。
七、预测可视化
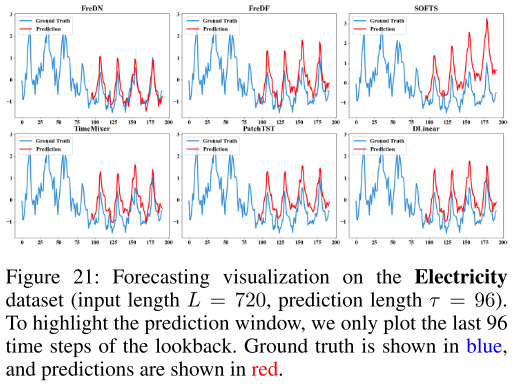
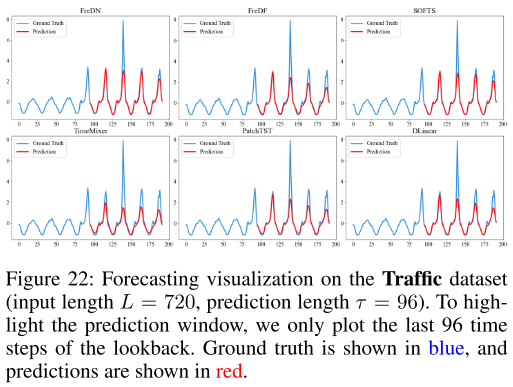
【配图:Figure 16--22】 在七个数据集上(输入长度 L=720,预测长度 τ=96),FreDN 与各基线的预测曲线对比(蓝色为真实值,红色为预测值)。【这里只给出了21、22】
从可视化结果中可以直观看出,FreDN 在周期性较强的数据集(如 ETTh1、ETTm1)上能更准确地复原周期结构,在趋势较明显的数据集(如 Weather)上也能更平滑地跟踪变化趋势,整体预测连贯性最优。
八、局限性与未来方向
论文在附录中坦诚地列出了 FreDN 当前的三点局限:
- 无显式周期先验:Frequency Disentangler 纯靠数据驱动学习,未融入信号处理领域对周期性或平滑性的先验知识,在更不规则的序列上泛化性有待提升。
- ReIm Block 的表达上限:共享权重的实数分支相比完整复数网络仍有表达能力的理论差距,自适应相位控制、复数门控等更复杂的复数建模技术值得探索。
- 数据集适应性:频域建模的收益依赖数据集的输入长度、维度和周期强度,对高度不规则或突发性强的数据效果可能有限,未来可引入实例自适应的时频混合策略。
九、总结
FreDN 以"频谱纠缠"为切入点,系统地诊断了现有频域时间序列预测方法的核心缺陷,并给出了三个相互呼应的解决方案:
| 问题 | 解决方案 | 效果 |
|---|---|---|
| 趋势/季节/噪声在频域混叠 | 可学习 Frequency Disentangler | 自适应、细粒度的频谱分离 |
| 复数运算复杂、参数量大 | ReIm Block(实虚共享权重 MLP) | 参数和计算量减少 >50%,性能持平甚至更优 |
| 频域 MAE 缺乏理论解释 | 梯度传播视角分析 | 揭示结构化长程梯度的优势机制 |
在七个主流基准上的大规模实验表明,FreDN 以相对轻量的架构实现了当前最优的长期预测性能,为频域时间序列建模提供了新的理论视角和实践范式。