23年我入职了一家做连锁门店业务的公司。入职后接手的第一个事情,是从零到一设计门店进销存系统。
这套系统到现在跑了三年,几乎没出过问题。前段时间CTO专门过来说了句,这套系统很稳定。管门店业务的老大,也很认可。
我想聊聊这个设计背后的思路。不是因为这个设计有多精妙,恰恰相反,它并不复杂。任何一个愿意在动手之前多想一步的程序员,都能做出来。
门店进销存是什么
只要公司有线下门店,进销存系统就是绑死的需求。门店的日常经营离不开四个动作:订货、收货、退货、盘点。
订货是门店向总部或供应商发起采购。收货是货到了之后门店确认入库。退货是有问题的货退回去。盘点是定期核对实际库存和系统库存是否一致。
这四个动作产生的数据,需要同步到下游的库存中心和ERP系统。库存中心负责维护实时库存数据,ERP系统负责财务核算和供应链管理。
我之前在同行业的公司干过,对这块业务比较熟。入职后从零设计这套系统时,做了一个关键的技术决策。
反脆弱
这个决策用三个字概括:反脆弱。
意思是,所有进销存动作产生的数据,在往下游系统同步的过程中,必须满足两个条件:
- 下游系统出故障,不能影响门店的任何操作
- 每一条数据链路,都必须支持重推
拿收货举例。门店收了一批货,进销存系统会生成一张收货单据。这张单据需要同步到库存中心(更新库存数量)和ERP系统(做财务入账)。
传统的做法是,收货动作触发后,同步调用库存中心和ERP的接口,等它们都返回成功,才告诉门店操作成功。这个设计在正常情况下没问题,一旦库存中心或者ERP挂了,门店的收货操作就会失败。对门店来说,货已经搬进仓库了,系统却告诉你收货失败,这是不能接受的。
我的设计是:单据在进销存系统创建成功,门店的这个动作就算完结了。 下游的库存中心和ERP系统,哪怕长时间不可用,门店该怎么操作还怎么操作。
数据流是一条单向链路:
进销存系统 → 库存中心 → ERP系统
进销存系统把单据推给库存中心,库存中心处理完再把数据推给ERP。每一层之间,都支持重新推送。
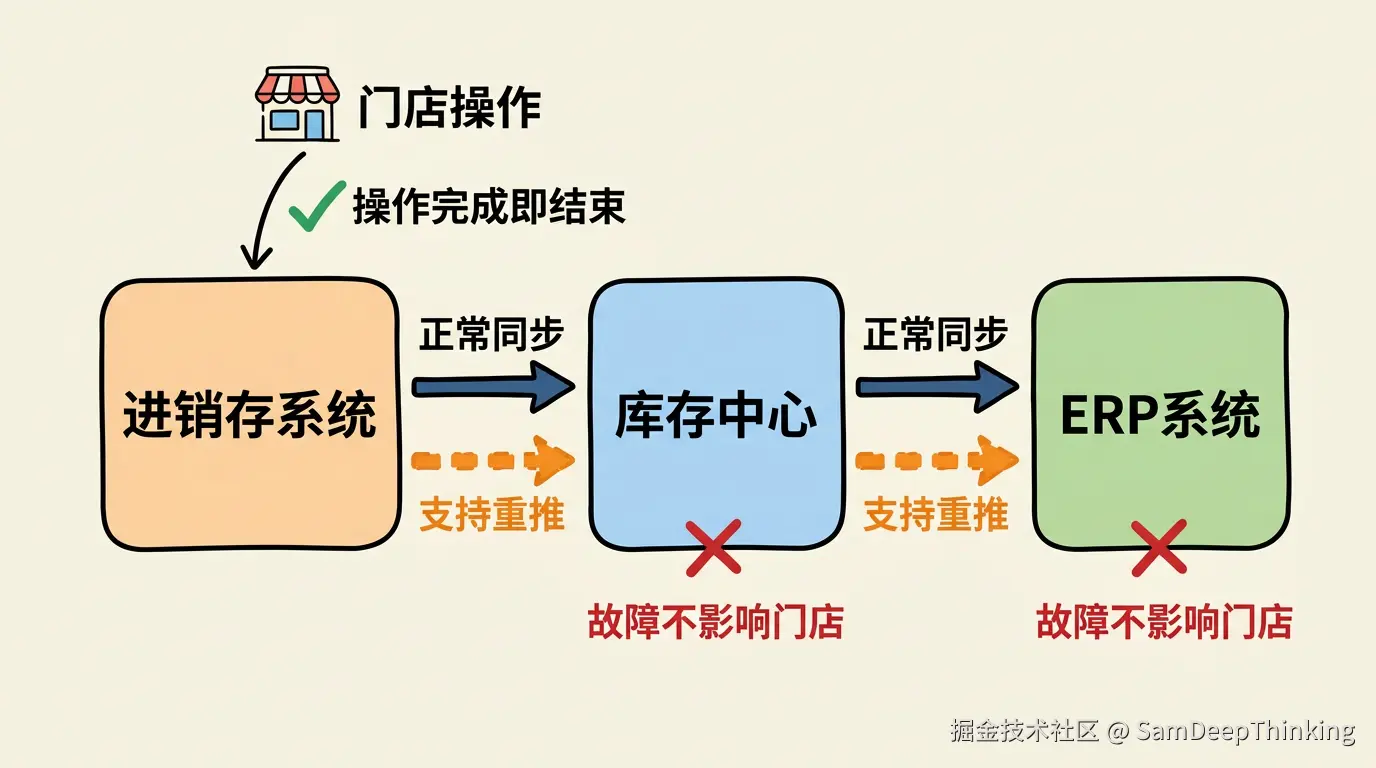
如果库存中心挂了,进销存系统的单据会暂存。收到告警后,用重推工具把数据重新推过去。库存中心恢复后,数据该怎么处理就怎么处理。
同样的道理,如果ERP挂了,库存中心的单据已经生成了,库存数据不受影响。等ERP恢复后,再把库存中心的单据重推到ERP。
重推的方式有很多,可以用业务task系统做自动重试,也可以提供一个手动推送的后台页面。具体用哪种不重要,关键是这个能力必须具备。
这里有个细节值得多说两句。为什么不用消息队列来做异步解耦,非要自己做重推?消息队列当然可以用,实际上我们在某些环节也用了。选择自己做重推能力的原因是,消息队列解决的是异步投递的问题,它不能覆盖所有失败场景。比如消息消费成功了,写库的时候失败了;或者下游服务逻辑有bug,处理结果不对。这些情况下,你还是需要有按单据维度重推的能力。消息队列和重推机制不是二选一,它们解决的是不同层面的问题。
这套设计上线之后,团队的人跟我说过一句话:幸亏当初是这么设计的,不然真没法活。原因是ERP系统经常出各种各样我们控制不了的问题,接口报错、数据不一致、服务超时,什么情况都遇到过,有几次ERP整整瘫痪了一天。如果当初采用的是同步调用的方案,ERP一挂,门店的收货、退货全部跟着瘫痪,业务根本没法正常运转。正是因为进销存系统和下游做了彻底的解耦,ERP不管出什么状况,门店该干什么干什么,等ERP恢复后重推数据补齐就行。
这也反过来印证了一件事:反脆弱设计的价值,往往不是在系统正常运行时体现的,而是在下游出问题的时候才能看出来。你不知道下游什么时候会挂,但你可以提前把「挂了也不怕」这件事设计好。
监控到位
反脆弱设计只是硬币的一面。系统能容忍下游故障,前提是你能第一时间知道哪里出了问题。不然数据积压了一个星期你才发现,重推也救不了你。
这里有一个设计上的关键点:告警必须按业务模块拆分,每个核心模块有自己独立的告警群。
我见过很多团队的做法是,一个系统就建一个告警群,所有模块的告警都往里面丢。退货的、收货的、订货的、盘点的,全混在一起。这样做的问题是,消息量一上来,没人能盯得住。收货出了问题,告警淹没在一堆退货和订货的消息里,很容易被漏掉。等发现的时候,数据已经积压了。
我的做法是按进销存的业务模块,每个模块建独立的告警群。退货有退货告警群,收货有收货告警群,订货有订货告警群,盘点有盘点告警群。每个告警群里,都指定了明确的负责人。收货告警群响了,负责收货模块的同事第一时间就能看到,不需要在一堆无关的消息里翻找。
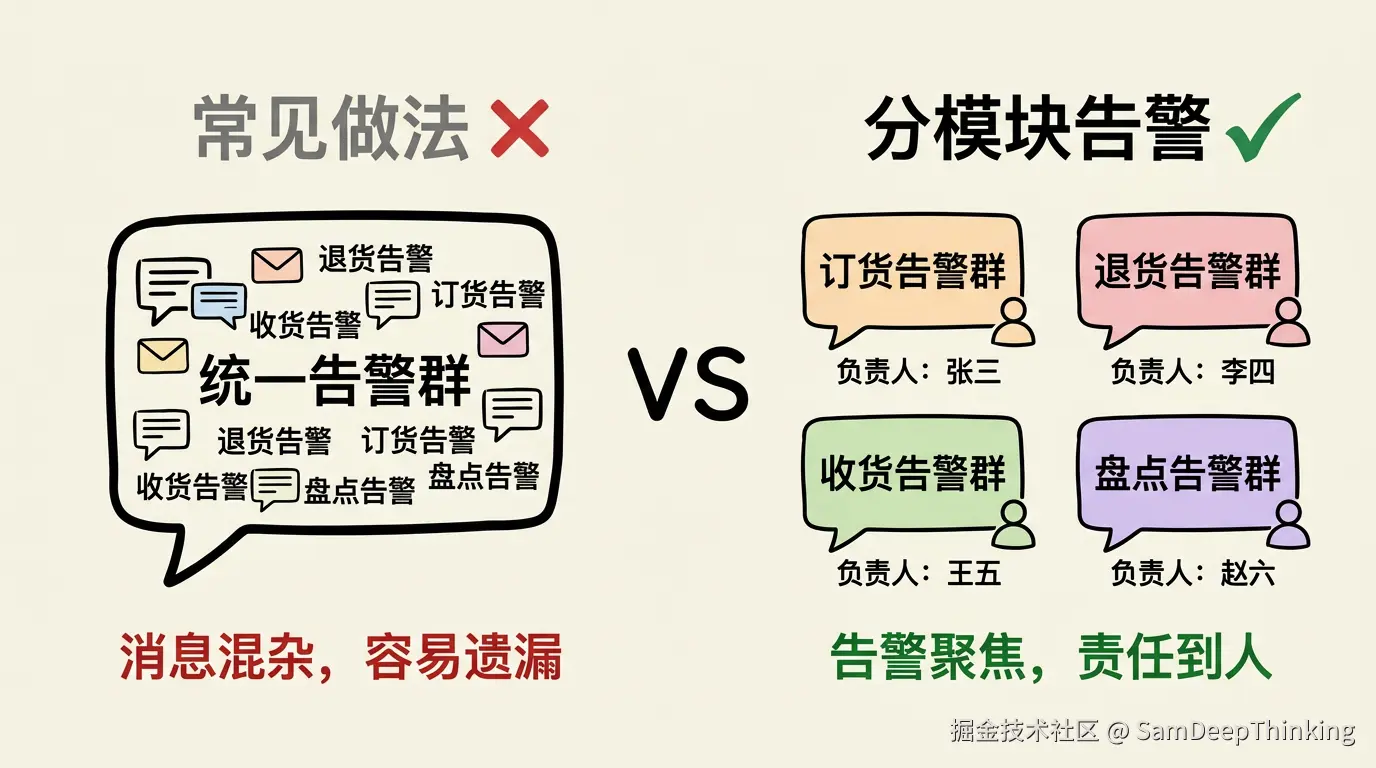
分模块告警看起来只是多建了几个群,实际效果差别很大。告警群越聚焦,里面的消息和你越相关,你越不会忽略它。一个告警群如果什么消息都有,时间长了就变成了没人看的群,和没有告警没区别。
每个告警群的规则是:群里出现告警,就意味着必须马上处理。
这句话听起来理所当然,实际上很多团队做不到。常见的情况是,告警群一天几百条消息,大部分是正常波动触发的,时间长了没人看。真正的故障混在噪音里,被忽略了。
有效告警和无效告警的区别在于告警的阈值设计和触发条件。我的做法是,只对确定性的异常触发告警。比如单据推送库存中心失败了,这是一个确定性事件,必须告警。库存中心的响应时间从50毫秒变成了200毫秒,这不告警,这是性能监控的事,不应该混在业务告警里。
告警群一旦变成没人看的消息洪水,这个告警体系就等于不存在。 保持告警的有效性,比多加几个告警规则重要得多。
这套分模块告警的机制,是我在项目最初期就定下来的,不是后面补的。团队里所有人开发进销存相关的模块,都必须按这个标准来:独立告警群、指定负责人、告警零噪音。不管你是做订货的还是做盘点的,规矩一样。
我对这件事要求很严格,原因是它直接决定了所有核心模块的稳定性、一致性、可维护性和可告警性。如果每个人按自己的理解来搞,有的模块有告警,有的没有,有的告警群里塞满了噪音,时间长了整个监控体系就废了。
这也是我做技术这些年一个很深的体会:设计层面的事情,越早确定越好。 在项目初期把规范和标准立好,团队照着执行,后面省的事远比你想象的多。等系统跑了一年再回头补监控、补告警,成本高不说,中间漏掉的问题已经造成影响了。很多系统之所以越跑越乱,不是后来的人能力不行,是一开始就没有人把标准立起来。
反脆弱设计自检清单
把上面的经验提炼一下,整理成一份自检清单。不只是进销存场景,任何需要和下游系统交互的业务模块,都可以用这个清单对照一下自己的设计。
| 检查维度 | 具体问题 | 达标标准 |
|---|---|---|
| 操作解耦 | 用户的操作是否依赖下游系统的实时响应? | 用户操作在本系统内完成即可,不依赖下游返回 |
| 重推能力 | 每条数据链路是否支持按单据维度重新推送? | 任意一条链路失败后,都能单独重推,不需要用户重新操作 |
| 监控粒度 | 监控告警是否按业务模块划分? | 每个业务模块有独立的告警通道,故障定位不需要在一堆告警里翻找 |
| 告警有效性 | 告警群里的每条消息,是否都需要人工处理? | 告警群零噪音,出现消息就意味着有事要处理 |
| 重推工具 | 是否有现成的工具可以执行重推操作? | 不管是自动task还是手动后台,工具必须就绪,不能出了问题再临时写脚本 |
| 数据一致性 | 下游恢复后,数据能否自动或半自动地补齐? | 有明确的数据对账机制,能发现并修复不一致 |
这份清单可以在做系统设计评审的时候拿出来逐项过一遍。一个系统如果这六项都达标了,它对下游故障的容忍能力会高很多。
程序员之间的差距在架构设计
回过头看这个反脆弱设计,技术上没有任何高深的地方。没用到分布式事务,没用到复杂的中间件方案,没有什么精巧的算法。它就是一个在动手之前想清楚了「下游挂了怎么办」的设计。
这个设计能稳定跑三年,不是因为代码写得多好,是因为在架构层面把容错和可恢复想明白了。
我面试4到5年经验的开发者时,第一看的就是架构设计能力。技术面试里,算法和八股文能反映基础功底,架构设计能反映你有没有独立负责过一个模块或系统、你在面对复杂场景时怎么做取舍。
工作4到5年的人,CRUD肯定是没问题的。这个阶段大家拼的已经不是写代码的速度和熟练度了。能不能在一个业务场景面前,给出一个考虑周全、经得起生产环境验证的架构方案,这才是真正拉开差距的地方。
可能有人会说:我就是写业务代码的,哪有机会做架构设计?
这个想法我理解,很多人的日常工作确实是接需求、写接口、调联调、提测上线,看起来和架构设计沾不上边。我早年也这样觉得。后来发现不是这样。任何一个稍微复杂一点的需求,都存在架构设计的空间。接口之间怎么交互、数据怎么流转、异常怎么处理、上下游怎么解耦,这些都是架构层面的思考。差别在于,你是随手写了一个能跑的方案,还是想清楚了各种情况再动手。
如何提升架构设计能力
两件事。
第一,去承担有挑战的任务。舒适区里做再久,架构能力也长不出来。只有在真实的、有压力的场景里做过设计决策,踩过坑,扛过线上问题,你才会对「什么方案靠谱、什么方案有隐患」形成自己的判断。
第二,日常养成一个思考习惯:遇到任何技术问题,问自己,这种问题的最佳实践是什么? 不妥协,不随意。接到一个需求,不是能跑就完事了,而是想想这类问题业界是怎么解决的,有没有更合理的方案。这个习惯坚持下来,你看问题的角度会和大多数人不一样。
这两件事说起来简单,做起来有个现实的前提:你得先拿到有挑战的任务。
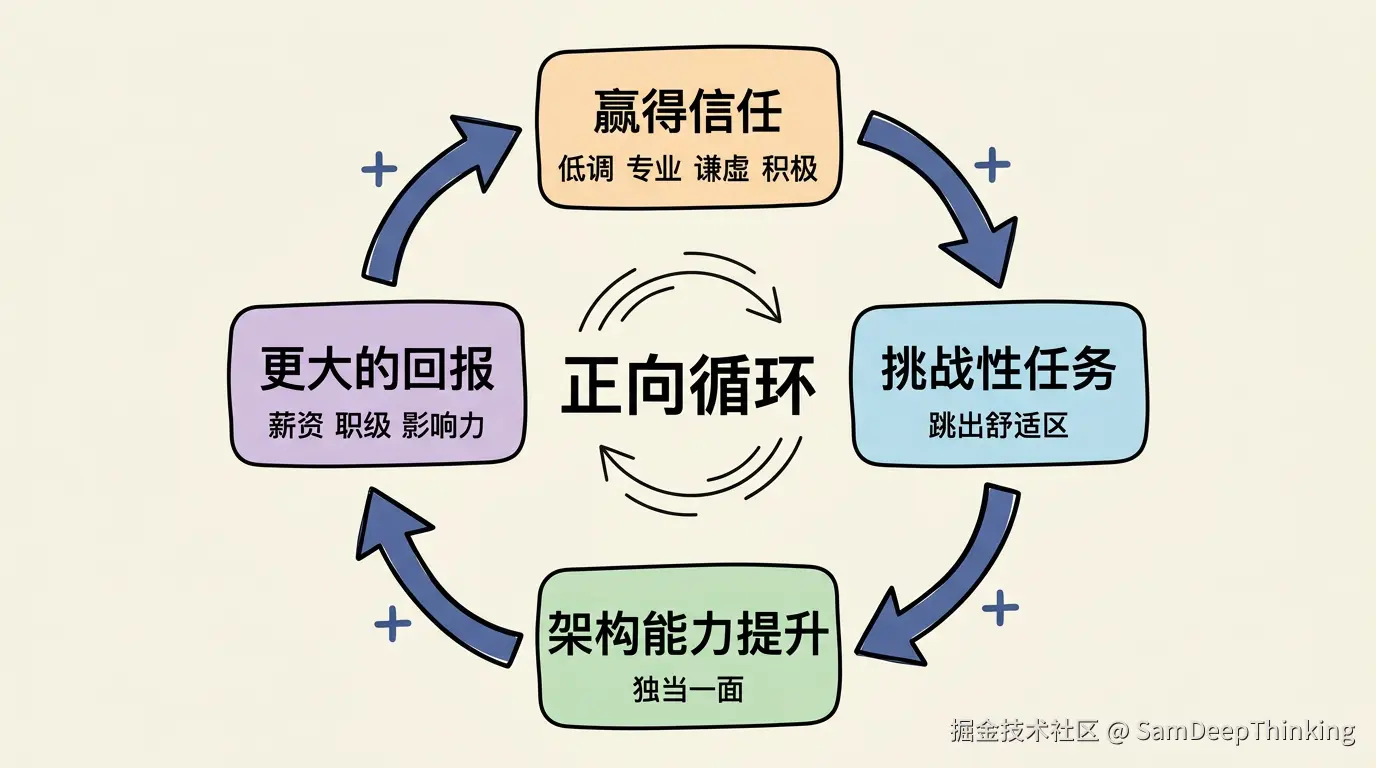
leader不会随便把高难度的任务交给一个他没把握的人。做砸了,leader自己要承担后果。你要拿到这样的机会,得先赢得leader的信任。
怎么赢得信任?四个词:低调、专业、谦虚、积极。
低调,是不张扬、不抢功、不搞办公室政治。专业,是交给你的事情,完成质量一直在线。谦虚,是遇到不懂的不装懂,能听进去别人的建议。积极,是不等着别人推,主动发现问题、主动补位。
这四个一个都不能少。少了哪个,信任建立的过程都会变慢。
信任建立之后,自然就会有更有挑战的任务交到你手上。做好了,信任进一步加深,下一次给你的任务难度和重要性又会上一个台阶。这是一个正向循环。
反过来,如果一直在舒适区待着,做的都是没有风险的活,技术能力很难有大的突破。几年下来,简历上写的项目经历会很单薄,面试的时候也聊不出什么有深度的东西。
小结
这套进销存系统的设计,我前后花在架构思考上的时间不超过两天。落地的方案也不复杂,团队里的同事都能理解和维护。三年没出问题,不是因为运气好,是因为在设计阶段就把「下游挂了怎么办」这个问题想清楚了。
技术成长这件事,我一直觉得方向比努力更重要。很多人工作了好几年,技术水平停在CRUD层面,不是能力不行,是从来没逼自己去想那些「麻烦但重要」的问题。每次接到需求,能跑就行,不去追问还能不能更好。日积月累,差距就出来了。
好的架构方案,往往不需要多复杂的技术手段。它需要的是你在动手之前,多花半天时间想想:这个系统上线之后,可能会遇到什么问题?遇到了我怎么兜底?这些问题想明白了,方案自然就出来了。
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
我的知乎账号:
- SamDeepThinking