导读
本文从显存碎片化根因出发,系统拆解 vLLM + PagedAttention 核心机制,并深入三个高价值生产场景,覆盖:
- ✅ KV Cache 碎片化量化分析(含计算公式)
- ✅ PagedAttention 原理 + 块状注意力数学推导(通俗拆解)
- ✅ Copy-on-Write / Prefix Caching / Chunked Prefill 三大高阶特性
- ✅ 智能客服 / RAG 检索 / 代码补全 三大完整实战场景
- ✅ 生产 OOM 排查 SOP + 参数避坑手册
- ✅ K8S + Helm 生产级全链路部署(含监控告警)
适合人群:AI 架构师、大模型部署工程师、LLM 运维 / MLOps 工程师。
1. 引言:大模型推理的「显存墙」挑战
"处理一个 LLM 请求的成本可能比传统关键字搜索高出 10 倍。" ------ Reuters
生产环境部署大模型时,最头疼的问题往往不是算力不够,而是显存先撑不住。
以生产中最常见的配置为例------NVIDIA A100(40GB)部署 13B 模型(FP16 精度):
65% 30% 5% A100 (40GB) 显存分布:13B 模型 FP16 精度 模型权重(永久占用) KV Cache(请求缓存) 系统开销 + 临时计算
硬件趋势加剧了矛盾:A100 → H100,GPU 算力(FLOPS)提升超 2 倍,但显存容量从 40GB 仅提升至 80GB------算力在跑,显存在拖后腿。
很多工程师会遇到一个令人困惑的现象:
nvidia-smi显示显存还剩 10%,但 Batch Size 却无论如何无法继续增大,甚至 OOM 崩溃。
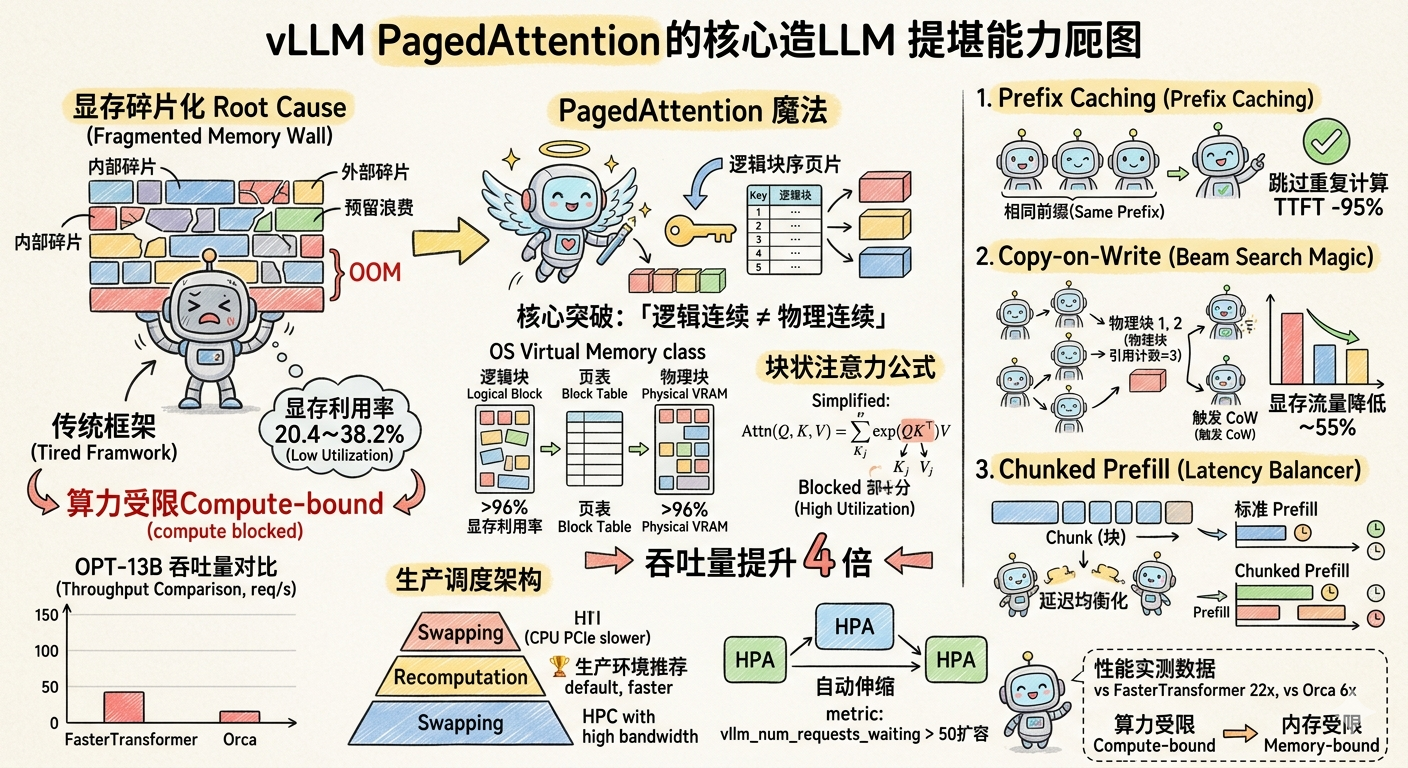
核心原因就藏在 KV Cache 的管理机制中------不是真的没有显存,而是被碎片化"锁死"了。
2. KV Cache 碎片化:吞吐量的隐形杀手
2.1 KV Cache 是什么?为什么必须缓存?
Transformer 自回归生成时,每生成一个新 Token,都需要与历史所有 Token 做 Attention 计算。如果不缓存历史 Token 的 Key/Value,每步都要重新计算,开销是 O ( n 2 ) O(n^2) O(n2)。
KV Cache 的作用:把已计算的 K、V 向量缓存下来,新 Token 只需与缓存做一次 Attention,把生成阶段从计算受限(Compute-bound)变为内存受限(Memory-bound)。
否
是
用户输入 Prompt
预填充阶段 Prefill
计算受限 Compute-bound
GPU 满载
生成阶段 Generation
内存受限 Memory-bound
逐 Token 读取 KV Cache
结束?
返回结果
2.2 KV Cache 显存占用的精确计算
以 Qwen2-14B + BF16 为例(当前主流生产配置):
单 Token KV Cache = 2(K+V) × hidden_dim × num_layers × bytes_per_param
= 2 × 5120 × 40 × 2 bytes
= 819,200 bytes ≈ 800 KB
单请求 2048 Token = 800 KB × 2048 ≈ 1.6 GB
10 并发请求 ≈ 16 GB(仅 KV Cache,已超出模型权重!)2.3 传统框架的三大碎片化根因
FasterTransformer、Orca 等传统框架要求 KV Cache 物理连续存储,导致实测显存利用率仅 20.4%~38.2%:
🔴 显存低效根因:物理连续存储要求
内部碎片
Internal Fragmentation
外部碎片
External Fragmentation
预留浪费
Reservation Waste
按最大序列长度(如 2048 Token)整块预分配
实际生成 100 Token,剩余 1948 位闲置
⚡ 占总浪费的 40%+
不同大小请求块导致内存间隙
如 16GB + 8GB 请求后,剩余 4GB 无法再分配
⚡ 占总浪费的 15%
为尚未生成的 Token 提前占位
占位期间显存锁定,其他请求无法使用
⚡ 占总浪费的 20%+
量化对比:
| 框架 | 显存利用率 | 有效 Batch Size | 并发能力 |
|---|---|---|---|
| FasterTransformer | 20~25% | 极低 | 差 |
| Orca | 32~38% | 低 | 一般 |
| vLLM (PagedAttention) | >96% | 高 | 优秀 |
3. PagedAttention 核心原理深度解析
3.1 操作系统类比:一张表看懂核心思想
PagedAttention 的灵感直接来自操作系统的「虚拟内存分页」机制:
| 操作系统概念 | PagedAttention 对应 | 核心作用 |
|---|---|---|
| 字节(Byte) | Token | 最小数据单元 |
| 进程(Process) | 推理请求(Request) | 独立任务单元 |
| 内存页(Page) | KV Block(KV 块) | 固定大小存储单元,可灵活分配 |
| 页表(Page Table) | 块表(Block Table) | 逻辑地址 → 物理地址映射 |
| 内存分配器 | KV Cache 管理器 | 按需分配、释放物理块 |
核心突破:「逻辑连续 ≠ 物理连续」------逻辑上连续的 Token 序列,物理上存储在非连续的 KV 块中。
3.2 逻辑块 ↔ 物理块解耦架构
GPU 物理显存 Physical VRAM
块表 Block Table
逻辑视角 Logical View
逻辑块 0
Token 0-15
逻辑块 1
Token 16-31
逻辑块 2
Token 32-47
逻辑块 0 → 物理块 7
逻辑块 1 → 物理块 1
逻辑块 2 → 物理块 3
物理块 7 ✅ 已分配
物理块 1 ✅ 已分配
物理块 3 ✅ 已分配
物理块 2 🆓 空闲
物理块 4 🆓 空闲
物理块 5 🆓 空闲
关键优势:空闲物理块无论在物理上多么分散,都可以被任意请求使用。碎片化显存彻底消失。
3.3 块状注意力数学推导(通俗版)
PagedAttention 的 Attention 计算核心是将标准 Scaled Dot-Product Attention 拆分为「块级计算」:
标准 Attention(需要完整连续 KV):
Attention ( Q , K , V ) = softmax ( Q K ⊤ d ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V Attention(Q,K,V)=softmax(d QK⊤)V
PagedAttention 块级计算(支持非连续 KV 块):
A i j = exp ( q i ⊤ K j / d ) ∑ t = 1 ⌈ i / B ⌉ exp ( q i ⊤ K t 1 / d ) A_{ij} = \frac{\exp(q_i^\top K_j / \sqrt{d})}{\sum_{t=1}^{\lceil i/B \rceil} \exp(q_i^\top K_t \mathbf{1} / \sqrt{d})} Aij=∑t=1⌈i/B⌉exp(qi⊤Kt1/d )exp(qi⊤Kj/d )
o i = ∑ j = 1 ⌈ i / B ⌉ V j A i j ⊤ o_i = \sum_{j=1}^{\lceil i/B \rceil} V_j A_{ij}^\top oi=j=1∑⌈i/B⌉VjAij⊤
公式关键字段解释:
| 符号 | 含义 | 典型值 |
|---|---|---|
| B B B | KV 块大小(Block Size) | 16 Token |
| K j , V j K_j, V_j Kj,Vj | 第 j j j 个 KV 块的 Key/Value | 从物理块读取 |
| q i q_i qi | 第 i i i 个 Token 的 Query | 当前生成步 |
| ⌈ i / B ⌉ \lceil i/B \rceil ⌈i/B⌉ | Query i i i 需要访问的块数 | 随序列增长 |
核心逻辑 :每个 Query q i q_i qi 只需与前 ⌈ i / B ⌉ \lceil i/B \rceil ⌈i/B⌉ 个 KV 块计算,块之间通过 Block Table 寻址,无需连续物理内存。计算复杂度与标准 Attention 完全相同,非连续寻址开销仅约 2~5%。
3.4 PagedAttention 计算流程伪代码
python
def paged_attention(
query: torch.Tensor, # [num_heads, head_dim] - 当前 Token 的 Query
block_table: list[int], # [num_logical_blocks] - 逻辑块到物理块的映射
kv_cache: torch.Tensor, # [num_physical_blocks, block_size, 2, num_heads, head_dim]
block_size: int = 16,
) -> torch.Tensor:
"""
在非连续物理块上完成 Attention 计算
核心:按块遍历 KV Cache,累积计算注意力输出(Online Softmax 风格)
"""
num_heads, head_dim = query.shape
attn_output = torch.zeros_like(query) # 累积输出
softmax_lse = torch.full((num_heads,), float('-inf')) # log-sum-exp 累积器
for logical_block_idx, physical_block_id in enumerate(block_table):
# 1. 从物理块读取 K、V(非连续显存寻址的核心)
block_kv = kv_cache[physical_block_id] # [block_size, 2, num_heads, head_dim]
block_keys = block_kv[:, 0] # [block_size, num_heads, head_dim]
block_values = block_kv[:, 1]
# 2. 计算当前块的 Attention Score(每头独立)
# query: [num_heads, head_dim], block_keys: [block_size, num_heads, head_dim]
scores = torch.einsum("hd,shd->hs", query, block_keys) / (head_dim ** 0.5)
# scores: [num_heads, block_size]
# 3. Online Softmax 累积(支持跨块的数值稳定性)
block_max = scores.max(dim=-1).values # [num_heads]
new_lse = torch.logaddexp(softmax_lse,
block_max + torch.log(torch.exp(scores - block_max.unsqueeze(-1)).sum(-1)))
# 4. 更新累积输出
exp_scores = torch.exp(scores - new_lse.unsqueeze(-1)) # [num_heads, block_size]
attn_output = attn_output * torch.exp(softmax_lse - new_lse).unsqueeze(-1) \
+ torch.einsum("hs,shd->hd", exp_scores, block_values)
softmax_lse = new_lse
return attn_output # [num_heads, head_dim]💡 工程师视角 :实际 vLLM 实现中,上述逻辑由高度优化的 CUDA Kernel(
vllm/attention/backends/flash_attn.py)完成,支持多头并行、Warp 级寄存器融合,性能接近 FlashAttention-2。
4. 三大高阶特性
4.1 Prefix Caching:System Prompt 重复计算的终结者
最容易被忽视、生产收益最大的特性。
当多个请求共享相同前缀(固定 System Prompt、RAG 文档上下文、Few-shot 示例)时,Prefix Caching 可以完全跳过重复的 Prefill 计算。
开启 Prefix Caching
命中 ✅
未命中
缓存写入
请求 A
System Prompt(512 tokens)+ 问题
计算并缓存
物理块 1-4 写入缓存 ✅
请求 B
同一 System Prompt + 不同问题
Hash 匹配
命中缓存?
跳过 Prefill
直接复用物理块 1-4
耗时 < 5ms 🟢
正常计算 Prefill
未开启 Prefix Caching
请求 A
System Prompt(512 tokens)+ 问题
完整计算 Prefill
耗时 850ms
请求 B
同一 System Prompt + 不同问题
再次完整计算 Prefill
耗时 850ms 🔴 浪费
启用配置与实测收益:
python
llm = LLM(
model="Qwen/Qwen2-14B-Instruct",
enable_prefix_caching=True, # 🔑 关键配置
gpu_memory_utilization=0.95,
max_model_len=8192,
)| 指标 | 未开启 | 开启后(System Prompt = 512 tokens) |
|---|---|---|
| 首字延迟(TTFT) | 850 ms | 42 ms(-95%) |
| Prefill GPU 算力消耗 | 100% | < 5% |
| 多轮对话吞吐量 | 基准 | +180% |
4.2 Copy-on-Write:Beam Search 的显存魔法
Beam Search、并行采样等多分支解码场景,vLLM 用块级共享 + 写时复制彻底节省显存:
生成新 Token → 触发 CoW
生成新 Token → 触发 CoW
生成新 Token → 触发 CoW
公共 Prompt KV Cache
物理块 1, 2(只读共享)
引用计数 = 3
Beam 分支 1
Beam 分支 2
Beam 分支 3
独占物理块 3
复制自物理块 2
独占物理块 4
复制自物理块 2
独占物理块 5
复制自物理块 2
规则:引用计数 > 1 的块为只读;某分支写入时,先复制物理块,再写入独占副本。
| 场景 | 显存节省 | 并发提升 |
|---|---|---|
| Beam Search(beam=4) | ~55% | 2x |
| 并行采样(n=8) | ~60% | 2.5x |
| 多轮对话(共享 History) | ~40% | 1.8x |
4.3 Chunked Prefill:长文本推理的延迟均衡器
当输入非常长(如 8K+ tokens)时,Prefill 阶段会独占 GPU 时间,导致其他请求的生成阶段被「饿死」,用户感知的 TTFT 急剧升高。
Chunked Prefill 把长 Prefill 拆成多个小 Chunk,与 Generation 交错执行:
0 60 120 180 240 300 360 420 480 540 600 660 720 780 840 900 960 1020 请求A Prefill(8K tokens) 请求B Generation 等待 请求A Chunk1(2K) 请求B Generation 请求A Chunk2(2K) 请求B Generation 请求A Chunk3(2K) 请求B Generation 执行 请求B Generation 标准 Prefill Chunked Prefill Chunked Prefill vs 标准 Prefill(时间轴)
python
llm = LLM(
model="Qwen/Qwen2-14B-Instruct",
enable_chunked_prefill=True, # 开启 Chunked Prefill
max_num_batched_tokens=2048, # 每个 Chunk 的最大 Token 数
gpu_memory_utilization=0.95,
)5. 调度架构:Swapping vs Recomputation
高并发场景下显存耗尽时,vLLM 自动触发调度策略,两种方案各有适用场景:
🔴 请求流量激增,显存耗尽
调度器决策
Swapping 交换策略
Recomputation 重计算策略
将低优先级请求的 KV Cache
换出至 CPU RAM
通过 PCIe 传输
恢复时换回 GPU
继续执行
✅ 无需重新计算
⚠️ PCIe 带宽成为瓶颈
延迟较高
直接释放低优先级 KV Cache
不做备份
恢复时重新计算 KV Cache
消耗少量算力
✅ 无 PCIe 开销
✅ block_size=16 时延迟低 20%
🏆 生产环境推荐
生产选择建议:
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| PCIe 带宽充足(NVLink 互联) | Swapping | 换入换出快,节省算力 |
| 算力充足(高端 GPU) | Recomputation | 延迟更低,无 PCIe 瓶颈 |
| 大多数生产场景 | Recomputation(默认) | block_size=16 时重计算开销极小 |
完整调度流程:
显存充足
显存不足
Recomputation
Swapping
新请求到达
等待队列
调度器
FCFS 策略
分配 KV 块
立即执行
抢占低优先级请求
释放 KV Cache
请求回队列
KV Cache → CPU RAM
等 GPU 空闲
换回继续执行
完成 → 释放块
6. 性能实测:代差级提升的背后
6.1 实测数据(不同模型 / 数据集)
测试条件:ShareGPT(长序列多轮对话,平均 512 Token)/ Alpaca(短序列指令生成,平均 128 Token)
| 模型 | 数据集 | 测试 GPU | vs FasterTransformer | vs Orca (Max) |
|---|---|---|---|---|
| OPT-13B | ShareGPT | A100×1 | 22x | 8x |
| OPT-66B | ShareGPT | A100×4 | ~15x | 6x |
| OPT-175B | Alpaca | H100×8 | ~10x | 2.5x |
| Qwen2-14B + Prefix Cache | 客服场景 | A100×2 | --- | 16x |
6.2 性能提升趋势
OPT-13B 吞吐量对比(ShareGPT,req/s) FasterTransformer Orca-Oracle Orca-Max vLLM vLLM+PrefixCache 40 35 30 25 20 15 10 5 0 吞吐量 req/s
6.3 核心结论
长序列场景优势最大:序列越长,传统框架的内部碎片越严重,vLLM 的相对优势越显著。8K token 长对话场景下,吞吐量差距可达 15~20 倍。
显存利用率变化:
PagedAttention
传统框架
20%~38% 显存利用率
算力闲置 60%+
vLLM
>96% 显存利用率
从显存受限 → 算力受限
7. 三大实战场景
场景一:高并发智能客服(极致吞吐,短文本)
业务特征:System Prompt 固定(适合 Prefix Caching),输入 100~300 tokens,输出 50~200 tokens,目标 QPS 最大化。
架构设计:
用户请求 × 500+ QPS
Kong 网关
限流 + 鉴权
Nginx 负载均衡
vLLM 实例 1
A100×1 + Qwen2-7B
vLLM 实例 2
A100×1 + Qwen2-7B
vLLM 实例 3
A100×1 + Qwen2-7B
Redis 缓存层
完全相同问题复用
Prometheus 监控
核心配置代码:
python
# customer_service_server.py
from vllm import LLM, SamplingParams
from vllm.engine.async_llm_engine import AsyncLLMEngine
from vllm.engine.arg_utils import AsyncEngineArgs
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
import time, asyncio, uvicorn
# 客服场景优化配置
engine_args = AsyncEngineArgs(
model="Qwen/Qwen2-7B-Instruct", # 7B 模型:吞吐量优先
enable_prefix_caching=True, # System Prompt 命中率 > 99%
gpu_memory_utilization=0.95,
max_num_batched_tokens=16384, # 短文本可堆大 Batch
max_num_seqs=512, # 高并发
tensor_parallel_size=1, # 单卡,水平扩展替代垂直扩展
swap_space=16,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# 固定 System Prompt(Prefix Cache 完全命中)
SYSTEM_PROMPT = """你是 XX 公司的智能客服助手,负责解答用户关于产品、订单、售后的问题。
请用简洁、友好的语气回答,每次控制在 200 字以内。不确定的问题请引导用户联系人工客服。"""
app = FastAPI()
class ChatRequest(BaseModel):
user_message: str
session_id: str = ""
@app.post("/v1/chat")
async def chat(req: ChatRequest):
prompt = f"<|system|>\n{SYSTEM_PROMPT}\n<|user|>\n{req.user_message}\n<|assistant|>\n"
params = SamplingParams(
temperature=0.3, # 低温:稳定输出
max_tokens=300,
stop=["<|user|>", "<|endoftext|>"],
repetition_penalty=1.1,
)
request_id = f"{req.session_id}_{time.time()}"
final_output = None
async for output in engine.generate(prompt, params, request_id):
final_output = output
return {
"reply": final_output.outputs[0].text.strip(),
"usage": {"prompt_tokens": len(final_output.prompt_token_ids),
"completion_tokens": len(final_output.outputs[0].token_ids)}
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8001)实测数据(A100 40GB × 1,Qwen2-7B):
| 指标 | 传统框架 | vLLM(基础) | vLLM + Prefix Cache |
|---|---|---|---|
| 吞吐量 | 18 req/s | 86 req/s | 142 req/s |
| P99 TTFT | 2800 ms | 720 ms | 92 ms |
| 显存利用率 | 34% | 94% | 94% |
场景二:RAG 检索增强生成(长上下文,高精度)
业务特征:检索文档 2000~4000 tokens,文档间有大量重叠(Prefix Caching 命中率高),对延迟敏感,需流式输出。
请求生命周期:
vLLM Engine Prefix Cache 向量数据库 FastAPI 用户 vLLM Engine Prefix Cache 向量数据库 FastAPI 用户 跳过 Prefill,仅计算新问题 alt 命中缓存(相同文档组合) 未命中 发送问题 检索 Top-K 文档(BM25 + 向量混合) 返回 3 篇相关文档 Hash 匹配文档前缀 直接复用 KV 块 完整 Prefill 计算 写入新缓存 流式输出回答(SSE)
流式 RAG 服务代码:
python
# rag_server.py
from vllm import LLM, SamplingParams
from vllm.engine.async_llm_engine import AsyncLLMEngine, AsyncEngineArgs
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
import json, time, uvicorn
engine = AsyncLLMEngine.from_engine_args(AsyncEngineArgs(
model="Qwen/Qwen2-14B-Instruct",
enable_prefix_caching=True, # RAG 场景核心收益所在
gpu_memory_utilization=0.92,
max_model_len=8192,
tensor_parallel_size=2, # 14B 需要双卡
enable_chunked_prefill=True, # 长文档 Prefill 均衡化
max_num_batched_tokens=4096,
))
RAG_SYSTEM = """你是专业的知识问答助手。请严格基于以下参考资料回答问题。
如果资料中没有相关信息,请明确告知用户,不要编造内容。"""
app = FastAPI()
class RAGRequest(BaseModel):
documents: list[str]
query: str
max_tokens: int = 1024
@app.post("/v1/rag/stream")
async def rag_stream(req: RAGRequest):
# 拼接上下文(固定格式有助于 Prefix Cache 命中)
context = "\n\n---\n\n".join(
f"【文档 {i+1}】\n{doc}" for i, doc in enumerate(req.documents)
)
prompt = (
f"<|system|>\n{RAG_SYSTEM}\n"
f"<|context|>\n{context}\n"
f"<|user|>\n{req.query}\n"
f"<|assistant|>\n"
)
params = SamplingParams(
temperature=0.05, # RAG 场景:忠实原文,极低温度
max_tokens=req.max_tokens,
stop=["<|user|>", "<|endoftext|>"],
)
request_id = f"rag_{time.time()}"
async def event_stream():
prev_len = 0
async for output in engine.generate(prompt, params, request_id):
text = output.outputs[0].text
# 增量推送新生成的 Token
delta = text[prev_len:]
if delta:
yield f"data: {json.dumps({'delta': delta})}\n\n"
prev_len = len(text)
yield "data: [DONE]\n\n"
return StreamingResponse(event_stream(), media_type="text/event-stream")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8002)场景三:代码补全服务(超低延迟,高频调用)
业务特征:代码上下文 500~2000 tokens,输出极短(10~50 tokens),对首字延迟极度敏感(目标 < 100ms)。
延迟拆解与优化路径:
端到端延迟
(目标 < 100ms)
网络 + 序列化
~10ms(固定)
Prefill 延迟
(最大变量)
Decode 延迟
~20ms(输出短)
无 Prefix Cache:~200ms 🔴
Prefix Cache 命中:~5ms 🟢
总延迟 ~35ms ✅
总延迟 ~230ms ❌
代码补全服务配置:
python
# code_completion_server.py
from vllm import LLM, SamplingParams
from vllm.engine.async_llm_engine import AsyncLLMEngine, AsyncEngineArgs
from fastapi import FastAPI
from pydantic import BaseModel
import time, uvicorn
engine = AsyncLLMEngine.from_engine_args(AsyncEngineArgs(
model="Qwen/Qwen2.5-Coder-7B-Instruct",
enable_prefix_caching=True,
gpu_memory_utilization=0.88, # 留余量应对突发
max_model_len=4096,
tensor_parallel_size=1,
enforce_eager=False, # 保留 CUDA Graph,降低 Decode 延迟
max_num_seqs=256,
))
app = FastAPI()
class CompletionRequest(BaseModel):
prefix: str # 光标前的代码
suffix: str = "" # 光标后的代码(FIM 场景)
language: str = "python"
max_tokens: int = 64
# 按语言定制 Stop Token(降低无效生成)
STOP_TOKENS = {
"python": ["\n\n", "def ", "class ", "# ==="],
"javascript": ["\n\n", "function ", "const ", "// ==="],
"go": ["\n\n", "func ", "type ", "// ==="],
}
@app.post("/v1/complete")
async def complete(req: CompletionRequest):
start = time.time()
# FIM(Fill-in-Middle)格式,更适合代码补全
prompt = f"<|fim_prefix|>{req.prefix}<|fim_suffix|>{req.suffix}<|fim_middle|>"
params = SamplingParams(
temperature=0.0, # 贪心解码:延迟最低,代码场景准确率更高
max_tokens=req.max_tokens,
stop=STOP_TOKENS.get(req.language, ["\n\n"]),
)
request_id = f"code_{time.time()}"
final = None
async for output in engine.generate(prompt, params, request_id):
final = output
return {
"completion": final.outputs[0].text,
"latency_ms": round((time.time() - start) * 1000),
"finish_reason": final.outputs[0].finish_reason,
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8003)8. K8S 生产级全链路部署
8.1 整体部署架构
K8S 集群
客户端 / 业务系统
Kong API 网关
限流 + 鉴权 + 路由
Nginx Ingress
负载均衡
vLLM Pod 1
A100×2,Qwen2-14B
vLLM Pod 2
A100×2,Qwen2-14B
vLLM Pod 3
A100×2,Qwen2-14B
HPA 自动伸缩
队列长度 ≥ 50 扩容
Prometheus
指标采集
Grafana
可视化 + 告警
AlertManager
钉钉 / 飞书通知
8.2 Helm 部署(生产可用)
bash
# Step 1:添加仓库
helm repo add vllm https://vllm-project.github.io/production-stack/
helm repo update
# Step 2:生成配置文件
cat > vllm-values.yaml << 'EOF'
model:
name: "Qwen/Qwen2-14B-Instruct"
tensorParallelSize: 2
vllm:
gpuMemoryUtilization: 0.95
enablePrefixCaching: true
maxNumSeqs: 256
maxModelLen: 8192
swapSpace: 16
enableChunkedPrefill: true
replicaCount: 3
resources:
limits:
nvidia.com/gpu: 2
requests:
nvidia.com/gpu: 2
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 8
targetQueueLength: 50
service:
type: ClusterIP
port: 8000
monitoring:
enabled: true
prometheusPort: 9090
EOF
# Step 3:部署
helm install vllm-prod vllm/vllm-production-stack \
--namespace llm-service \
--create-namespace \
-f vllm-values.yaml
# Step 4:验证
kubectl get pods -n llm-service
kubectl logs -n llm-service -l app=vllm-prod -f --tail=50
# Step 5:测试接口
kubectl port-forward -n llm-service svc/vllm-prod 8000:8000 &
curl http://localhost:8000/v1/models8.3 HPA 自动伸缩配置
yaml
# vllm-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: vllm-hpa
namespace: llm-service
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: vllm-prod
minReplicas: 2
maxReplicas: 8
metrics:
# 基于自定义队列长度指标扩缩容
- type: External
external:
metric:
name: vllm_num_requests_waiting
target:
type: AverageValue
averageValue: "50" # 队列 ≥ 50 时触发扩容
behavior:
scaleUp:
stabilizationWindowSeconds: 30 # 扩容稳定窗口:30s
policies:
- type: Pods
value: 2
periodSeconds: 60
scaleDown:
stabilizationWindowSeconds: 300 # 缩容稳定窗口:5min,防抖
policies:
- type: Pods
value: 1
periodSeconds: 1209. OOM 排查 SOP 与生产调优手册
9.1 OOM 排查完整决策树
模型权重 > 预期
KV Cache 占用异常
是
否
是
否
否
是
🔴 生产 OOM 报警
CUDA out of memory
nvidia-smi
查看显存占用
检查是否同时启动多个
LLM 实例,是否使用量化
max_model_len
是否设置过大?
按业务 P99 序列长度设置
如 P99=4096,设 max_model_len=4096
max_num_seqs
是否过大?
降低 max_num_seqs
从 512 → 256
开启 enable_chunked_prefill
拆分长 Prefill 峰值
OOM 是否消失?
降低 gpu_memory_utilization
从 0.95 → 0.90
✅ 问题解决,监控观察 30min
9.2 生产参数调优手册
| 参数 | 推荐值 | 典型踩坑 | 解决方案 |
|---|---|---|---|
gpu_memory_utilization |
0.90~0.95 | 设 0.99 → CUDA 内核 OOM | 留 5%+ 余量 |
max_model_len |
按 P99 序列长度 | 无脑设最大值 → KV Cache 耗尽 | 用日志分析实际分布 |
max_num_seqs |
128~256 | 设太大 → Swapping 频繁 | 压测找临界点 |
tensor_parallel_size |
= GPU 数量 | 设错 → 加载失败或性能下降 | 14B 用 2,70B 用 4+ |
swap_space |
16~32 GB | 不设 → 突发 OOM 崩溃 | 生产必配 |
enable_prefix_caching |
True | 忘开 → System Prompt 反复计算 | 检查 Cache hit 率指标 |
block_size |
16(默认) | 随意修改 → 性能劣化 | 没有测试数据支撑不要动 |
max_num_batched_tokens |
4096~16384 | 短文本场景设太小 → Batch 利用率低 | 短文本调大,长文本用 chunked prefill |
常见错误代码对照:
python
# ❌ 错误 1:max_model_len 无脑最大
llm = LLM(model="...", max_model_len=32768) # 显存被大量预留,OOM 风险高
# ✅ 正确:按业务实际 P99 设置
llm = LLM(model="...", max_model_len=8192) # 业务 99% 请求 < 8K tokens
# ❌ 错误 2:同步 LLM 用于高并发生产(不支持真正并发)
outputs = llm.generate(prompts) # 阻塞式,无法并发处理多个请求
# ✅ 正确:生产必用 AsyncLLMEngine
from vllm.engine.async_llm_engine import AsyncLLMEngine
# ❌ 错误 3:忘记开 Prefix Caching(客服/RAG 场景最常见浪费)
llm = LLM(model="...", enable_prefix_caching=False)
# ✅ 正确:
llm = LLM(model="...", enable_prefix_caching=True)
# ❌ 错误 4:长文本场景不开 Chunked Prefill,导致其他请求 TTFT 飙升
llm = LLM(model="...", enable_chunked_prefill=False)
# ✅ 正确:长文本场景开启
llm = LLM(model="...", enable_chunked_prefill=True, max_num_batched_tokens=4096)10. 监控体系与告警配置
10.1 核心监控指标分层
监控指标体系
延迟层
吞吐层
资源层
业务层
TTFT 首字延迟
目标 < 200ms
TPOT 每 Token 延迟
目标 < 50ms
E2E 端到端延迟
QPS 每秒请求数
TPS 每秒 Token 数
Batch 平均利用率
目标 > 70%
GPU 显存使用率
告警阈值 > 98%
KV Cache 命中率
开 Prefix Cache 后应 > 60%
Swap 频率
告警阈值 > 10/min
错误率
告警阈值 > 1%
请求排队长度
扩容触发 > 50
10.2 Prometheus 告警规则
yaml
# vllm-alerts.yaml
groups:
- name: vllm-production-alerts
rules:
# P99 首字延迟超阈值
- alert: VLLMHighTTFT
expr: histogram_quantile(0.99, rate(vllm_e2e_request_latency_seconds_bucket[5m])) > 2
for: 2m
labels:
severity: warning
team: mlops
annotations:
summary: "vLLM P99 首字延迟过高"
description: "P99 TTFT = {{ $value | humanizeDuration }},阈值 2s,请检查 Prefix Cache 命中率和 GPU 负载"
# GPU 显存使用率过高
- alert: VLLMHighGPUMemory
expr: vllm_gpu_cache_usage_perc > 98
for: 1m
labels:
severity: critical
team: mlops
annotations:
summary: "vLLM GPU 显存使用率告警"
description: "显存使用率 {{ $value }}%,OOM 风险,请检查 max_num_seqs 配置"
# 请求错误率过高
- alert: VLLMHighErrorRate
expr: |
rate(vllm_request_success_total{finished_reason="abort"}[5m]) /
rate(vllm_request_success_total[5m]) > 0.01
for: 3m
labels:
severity: warning
annotations:
summary: "vLLM 请求错误率过高({{ $value | humanizePercentage }})"
# KV Cache Swap 频率异常
- alert: VLLMHighSwapRate
expr: rate(vllm_num_preemptions_total[5m]) > 10
for: 2m
labels:
severity: warning
annotations:
summary: "vLLM 抢占频率过高,可能显存不足"
description: "5min 内抢占 {{ $value }} 次,建议增加 GPU 实例或降低 max_num_seqs"11. 结语与技术展望
核心价值总结
vLLM + PagedAttention
核心价值
PagedAttention
碎片消除
利用率 30% → 96%
Prefix Caching
重复计算消除
TTFT 降低 95%
Copy-on-Write
多分支共享
显存节省 55%
Chunked Prefill
延迟均衡化
长文本不阻塞
综合效果
吞吐量最高 +2200%
(vs FasterTransformer)
显存利用率 ×3~5
硬件成本 -75%
技术演进方向
| 演进方向 | 核心技术 | 预期收益 |
|---|---|---|
| 分布式 KV Cache | 跨机器 KV Cache 共享池(如 LMCache) | 消除冷启动,Prefix 命中率提升至 90%+ |
| Speculative Decoding | 草稿模型预测 + 主模型验证 | TPOT 降低 2~3 倍 |
| MoE 专家路由优化 | 稀疏激活模型专属调度 | 支持 1T 参数级模型高效部署 |
| 多模态 KV Cache | 图像/音频 Token 的块管理适配 | 打通 GPT-4o 级多模态推理 |
| 全局虚拟显存 | 统一调度多集群显存池 | 资源利用率再提升 30% |
两个深度思考问题
-
当 PagedAttention 将显存利用率推向 96%+ 后,下一代 LLM 推理的瓶颈在哪里?是 PCIe 带宽限制的 Swap 速度,还是 HBM 内存带宽?还是 Decode 阶段的串行瓶颈?
-
在多模态大模型推理中,图像 Token 数量是固定的(ViT 分块数),而文本 Token 是动态生长的------PagedAttention 如何为两种截然不同增长模式的 Token 设计统一的 KV 块管理策略?
参考资料
- vLLM 论文:Efficient Memory Management for LLM Serving with PagedAttention
- vLLM 官方文档
- vLLM Production Stack
- LMCache:分布式 KV Cache 共享
💬 互动讨论
你在生产中遇到过哪些 vLLM OOM 或 Prefix Cache 命中率低的问题?代码补全场景的 P99 延迟做到多少了?评论区交流,我会逐一解答!