为什么需要输出解析器
我们在使用大语言模型的时候,无论是使用 LangChain,还是直接使用模型的 API,都会遇到大语言模型的输出解析问题,以 OpenAI 的模型为例:
python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
# 示例1
llm.invoke("告诉我1+1等于几?") # 输出: 1 + 1 等于 2。
# 示例2
llm.invoke("告诉我3个动物的名字。") # 输出: 好的,这里有三种动物的名字:
# 1. 狮子
# 2. 大熊猫
# 3. 斑马
# 示例3
llm.invoke("给我一个json数据,键为a和b,值为任意的整型。") # 输出: {
# "a": 10,
# "b": 20
# }虽然整体的问题已经回答了,但是返回的内容都是一个字符串,并不是结构化的数据,某些场合下我们需要的仅仅是对应的返回值,而不是多余的内容,就需要对返回的内容进行结构化、格式化或者解析。
例如下方为修改后的提示,尽可能先让大语言模型按照特定的规则输出内容,然后再进行解析
python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
# 示例1,输出:2
llm.invoke("告诉我1+1等于几?除了答案其他内容均不要返回。")
# 示例2,输出:1.老虎\n2.狮子\n3.斑马
llm.invoke("告诉我3个动物的名字。返回示例:1.狮子\n2.大熊猫")
# 示例3,输出:{"a": 10, "b": 20}
llm.invoke("给我一个json数据,键为a和b,值为任意的整型。除了json数据,其他内容均不要返回。")因此,如果需要 LLM 理解你想要的格式,需要向 LLM 告知要输出的结构信息,当 LLM 进行推理并输出之后,我们需要对 LLM 约定的格式进行解析,于是就诞生了 输出解析器 的概念。
简单拆解:输出解析器 = 预设提示 + 解析功能
输出解析器的解析场景:
- 将非结构化的文本转换为结构化的数据:将文本解析为一个 JSON 或者是 Python 里的字典等。
- 截取部分文本:只要结果中的某一部分即可。
- 自定义处理:在提示中注入其他的指令,告诉语言模型如何去给我返回一个格式的答案,然后解析器可以根据返回提示文本对应的内容做对应的解析。
OutputParser输出解析器
在 LangChain 中预设了大量的输出解析器,输出解析器通常包含两个抽象函数的实现,这也是自定义输出解析器需要实现的两个函数:
- get_format_instructions:用来约定输出的格式,并转换为描述文本。
- parse:用来解析 LLM 的输出为约定的格式。
但在实际的使用中,输出解析器大部分场景都是解析大语言模型的输出内容,所以可以直接使用 invoke 函数进行调用,在 invoke 函数的底层,还是调用了 parse 函数进行解析。
在 LangChain 中 OutputParser 的基类及子类划分如下:
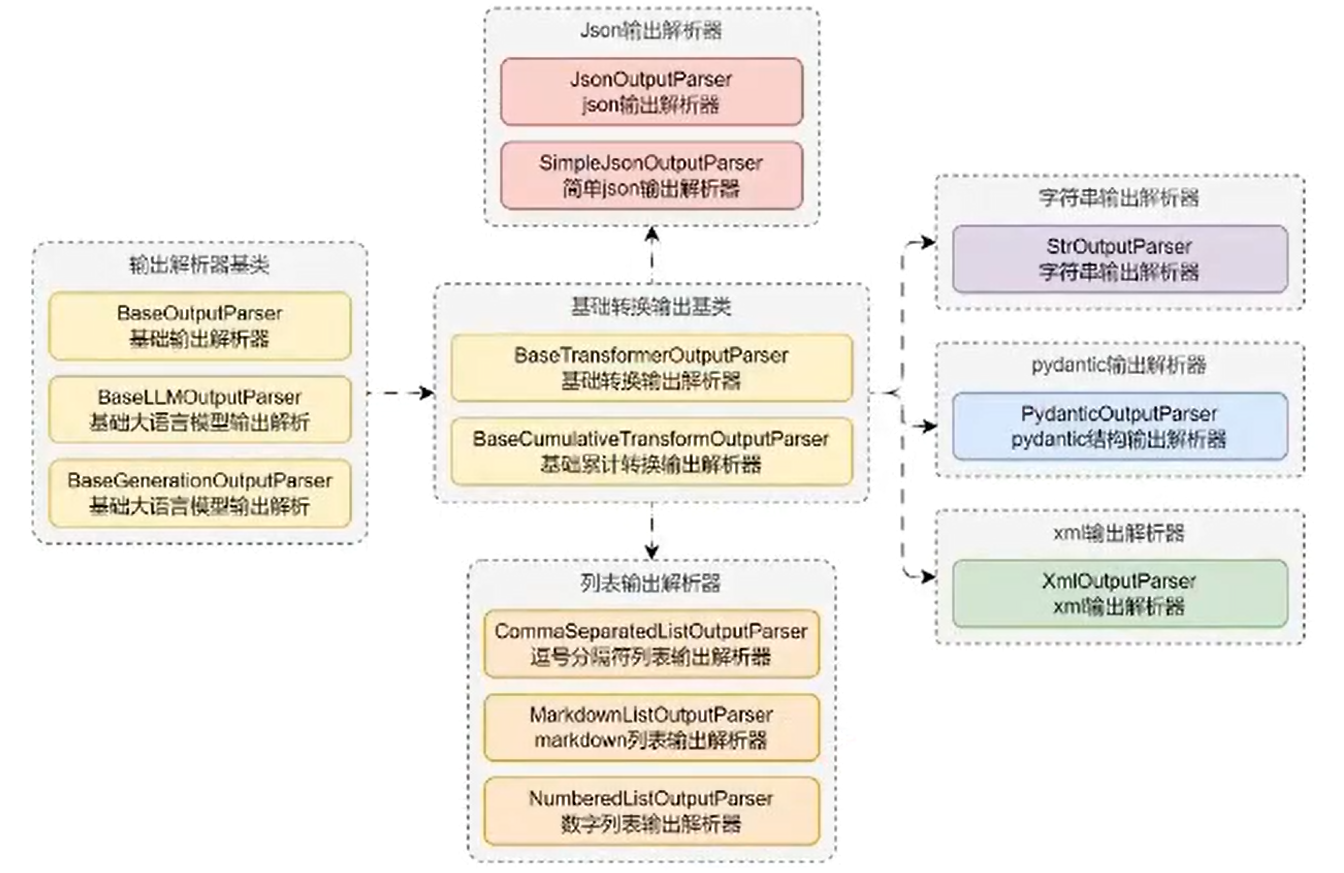
StrOutputParser
StrOutputParser 是 LangChain 中使用频率最高的输出解析器,使用也非常简单,它会将传入的文本原样返回,常用于解析得到 AIMessage 中的输出文本。
python
from langchain_core.output_parsers import StrOutputParser
StrOutputParser().parse("程序员的梦工厂")输出内容
python
程序员的梦工厂源码实现
python
def parse(self, text: str) -> str:
"""Returns the input text with no changes."""
return textJsonOutputParser
JsonOutputParser 用于将对应的 LLM 输出转换为特定格式的 json 或 Python 字典,在使用前必须定义 BaseModel 规范解析的数据结构,并将解析器提供的描述文本嵌入到提示中,使用示例如下:
python
import dotenv
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1. 创建一个json数据结构,用于告诉大语言模型这个json长什么样子
class Joke(BaseModel):
# 冷笑话
joke: str = Field(description="回答用户的冷笑话")
# 冷笑话的笑点
punchline: str = Field(description="这个冷笑话的笑点")
parser = JsonOutputParser(pydantic_object=Joke)
# 2 构建一个提示函数
prompt = ChatPromptTemplate.from_template("请根据用户的提问进行回答。\n{format_instructions}\n{query}").partial(format_instructions=parser.get_format_instructions())
# 3构建一个大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 4 传递提示并进行解析
joke = parser.invoke(llm.invoke(prompt.invoke({"query": "请讲一个关于程序员的冷笑话"})))
print(joke)其他思路参考
如果使用的模型支持 Function Calling 或者 Tool Calling,可以不使用解析器,而是直接定义一个函数,规定它的函数参数为对应要解析的格式,并强制模型调用这个函数,模型就可以精准无误地按照特定的约束输出。
思考 & 问题:
- 如果 outputParser 输出解析失败了,该如何解决?有几种解决方案?
- 针对小参数的模型,并且没有函数 / 工具回调,哪一类输出解析器会更稳定?