核心观点摘要
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
DeepSeek V4 是深度求索(DeepSeek)公司于 2026 年 4 月 24 日正式发布的新一代开源大语言模型系列,是当前全球参数规模最大、长上下文效率最具革命性的开源前沿成果。该系列并非对前代模型的小幅迭代,而是通过对 Transformer 基础架构的三项 "范式级" 技术改造,首次将万亿级参数、百万级上下文的高性能模型的推理成本与部署门槛,拉低到了工业界可大规模商用的区间 ------ 而其完全开放的开源授权策略,进一步放大了这一技术本身的行业重构效应。
**作为当前开源模型的标杆产品,DeepSeek V4 系列全面采用 MIT 开源许可协议,无保留开放模型权重与底层代码,允许企业和开发者免费用于商业用途、自由修改定制,支持在 Hugging Face、魔搭社区等主流平台直接下载部署。**全系标配 100 万 Token 级原生上下文窗口,旗舰版 Pro 与轻量化版 Flash 分别面向超高复杂度任务与高性价比普及场景,综合性能达到闭源顶级产品档位,在长文本、代码、推理等环节形成优势,多模态能力正通过灰度测试逐步释放,开源版本视觉权重计划于 2026 年第三季度发布。
其核心行业价值在于,用完全开放的技术授权模式,打破了顶级闭源模型对高性能长文本与复杂推理能力的垄断;更通过提前适配国产算力芯片的工程化能力,首次构建出从底层硬件到上层应用完全摆脱英伟达 CUDA 生态的国产大模型全栈方案,将万亿参数级 AI 模型的私有化部署门槛,从大型企业级预算拉低到了中小机构可及范围。
一、DeepSeek V4 模型架构与核心技术突破
DeepSeek V4 的核心竞争力并非源于对模型参数的简单堆砌 ------ 这是行业内首次在万亿级参数的 MoE 混合专家架构下,实现了极高的运行效率与工程化适配性。而支撑这一突破的,是直击 Transformer 架构长期性能瓶颈的三项关键技术创新。
1.1 混合注意力系统:CSA+HCA 架构革命
长上下文处理能力是当前大模型从 "可用" 走向 "大规模商用" 的最关键技术门槛 ------ 传统注意力机制的计算复杂度随上下文长度呈二次方增长,100 万 Token 的上下文意味着约 1 万亿次计算操作,显存占用量和运行成本都会突破工业场景容忍极限。这也是此前长窗口模型无法大规模普及的核心原因。
DeepSeek V4 彻底放弃了原生密集注意力机制,独创压缩稀疏注意力(CSA)+ 重度压缩注意力(HCA)的混合架构,从根上重构了长上下文的算力与显存消耗逻辑:
- 压缩稀疏注意力(CSA)模块,会先沿序列维度对键值(KV)缓存进行专业压缩,随后叠加 DeepSeek 自研的 DSA 稀疏注意力机制,初步筛选并过滤掉长文本中的冗余计算单元;
- 重度压缩注意力(HCA)模块则在 CSA 的压缩基础上,对键值缓存进行更激进的压缩优化 ------ 同时保留核心的密集注意力细节,确保经过两次压缩后的关键语义信息不会丢失。
两者的交替叠加,实现了长上下文场景下的算力消耗骤降:在 100 万 Token 长度下,Pro 版的推理计算量仅为前代 V3.2 的 27%,键值缓存占用量压缩至前代的 10%;轻量化的 Flash 版更将计算量压缩至前代的 10%,键值缓存占用量低至 7%。这是行业内首次将百万级长上下文的算力成本,压缩至实际商用可接受区间的工程化突破。
实测数据更直观验证了这一优化的商用级成熟度:V4-Pro 处理 100 万 Token 文档仅需 15 分钟左右,V4-Flash 快至 8 分钟;即使输入相当于 500 页专业编程手册的 80 万 Token 长度内容,输出结果也无上下文遗忘或逻辑错乱问题。更关键的是,该架构为百万级上下文提供了足够的效率冗余:后续即使进一步扩展上下文长度,实际推理算力成本的增长幅度也能控制在企业可承受范围内。
1.2 模型结构优化:mHC 流形约束超连接
在大模型架构设计领域,一直存在难以调和的稳定性与性能矛盾:模型层数越深、参数规模越大,残差连接带来的数值不稳定问题越明显;为追求稳定性而设置的大量冗余参数,会直接吞噬算力成本,让万亿级参数模型的实际运行成本突破工业场景极限。这也是此前万亿级参数模型无法投入实际商用的核心约束之一。
Hyper-Connections(超连接)架构曾是这一问题的潜在解决方案:它通过增加并行通道的方式,强化梯度流动性,减少对冗余参数的依赖。但行业实测结果显示,随着模型规模向万亿级参数突破,超连接架构会出现严重的训练崩溃风险 ------ 无法支撑大规模工业化预训练。
而 DeepSeek V4 引入的 mHC(流形约束超连接)技术,本质是为适配万亿级参数规模做的精准工程化改造:它将残差映射矩阵严格约束在 "双随机矩阵" 的特殊流形上,从根本上杜绝了模型激活值的过度漂移问题,让超连接方案首次具备了支撑万亿级参数模型的工业化稳定性。
这一技术的实际效果,远不止提升模型运行稳定性这么简单:它将万亿级参数模型的冗余度压缩到了行业最低区间 ------ 配合融合内核、选择性重计算等系统级优化手段,模型额外运行时间增幅被控制在 6.7% 的极低水平。这意味着,企业为万亿级参数模型的高稳定性付出的算力成本增量,几乎可以忽略不计。
1.3 训练与推理效率提升:Muon 优化器的混合策略
训练效率是制约超大规模模型迭代速度与落地门槛的核心短板,DeepSeek V4 是全球首个采用 Muon 优化器作为核心训练引擎的万亿级参数大模型,并基于实际场景需求对优化策略进行了精准混合:
- 针对模型的主体核心参数,采用 Muon 优化器进行高维空间优化;而对词元嵌入层、预测头部、RMSNorm 归一化层等对精度更敏感的附属模块,沿用成熟的 AdamW 优化器进行微调。这种 "主体提速 + 细节保稳" 的混合策略,在确保模型收敛稳定性的前提下,大幅提升了训练阶段的算力利用率和迭代速度。
配合自研的低秩自适应优化(LoRA)混合策略,V4 在训练与推理场景的效率都实现了质的飞跃 ------ 在没有额外增加算力成本的前提下,模型的有效训练算力利用率较前代提升了近 40%。
值得强调的是,V4 的架构创新并非孤立存在:它完整继承了 DeepSeekV3 验证成熟的 MoE 混合专家框架和多词元预测(MTP)策略。这些经过多代产品迭代的能力与新架构优化协同叠加,进一步放大了长文本处理、复杂推理等场景的性能优势。
1.4 双版本 MoE 架构设计
DeepSeek V4 全系采用稀疏激活 MoE 混合专家架构,根据推理性能与成本定位,精准划分成两个版本 ------ 两者都标配 100 万 Token 原生上下文窗口,均提供 Base 基础模型与 Instruct 指令模型的权重版本,核心差异体现在参数规模与场景定位上:
- DeepSeek V4-Pro(旗舰版) :总参数规模 1.6 万亿,激活参数 49B,是当前全球已发布的最大规模开源大模型。稀疏激活架构是其支撑万亿级参数的关键技术逻辑:日常推理仅调用不到 50B 的有效激活参数,既保障了超高复杂度场景的推理能力,又将实际运行成本控制在商用可承受区间。该版本精准面向超高难度推理、大规模代码库分析、复杂智能体构建、前沿科研探索等对性能要求苛刻的场景;
- DeepSeek V4-Flash(普及版) :总参数规模 2840 亿,激活参数仅 13B,稀疏化比例更高。它牺牲了部分极限推理性能,换取了部署门槛与推理成本的进一步降低 ------ 但仍完整保留了 Pro 版的长上下文核心能力,足以支撑绝大多数主流商用场景,定位中低复杂度常规任务。
这种双版本策略,相当于同时覆盖了企业的 "极限性能需求" 与 "大规模普及需求",是极具针对性的商用布局。
二、分领域性能评估与竞品基准对比
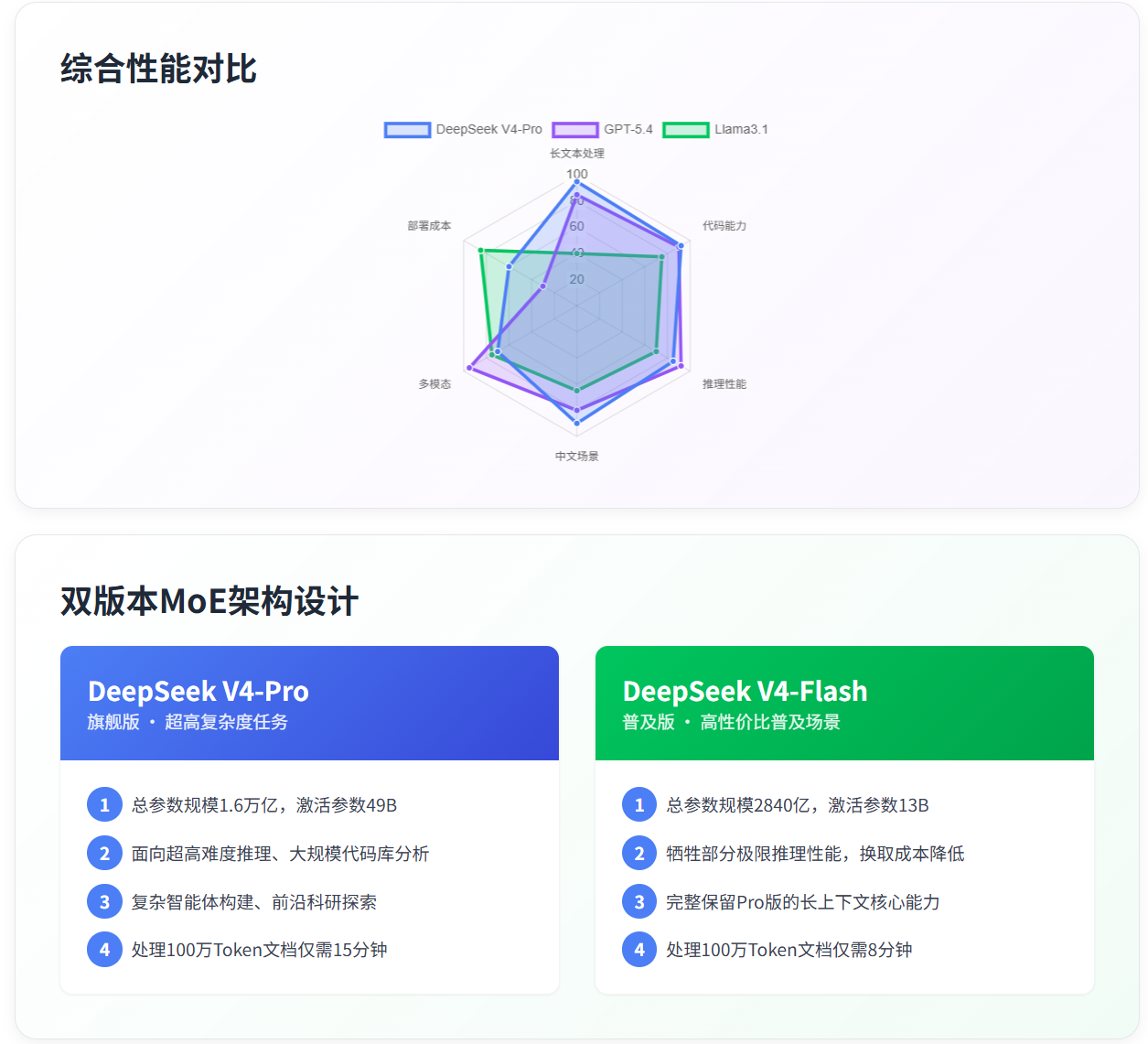
为验证 DeepSeek V4 的实际商用能力,我们选取行业主流闭源大模型(GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro)与开源大模型(Llama3.1、Qwen2.5),进行分维度的横向能力对比。需说明的是,由于各厂商官方基准测试的数据集与评估口径存在差异,本次对比以第三方科技媒体公开实测数据为统一参考基准。
2.1 文本生成与通用推理
文本与通用推理是大模型落地最广泛的基础场景,也是检验一款模型成熟度的核心标尺 ------ 在这一基础维度上,DeepSeek V4 的综合表现,已经达到了可正面对标头部闭源模型的水平。
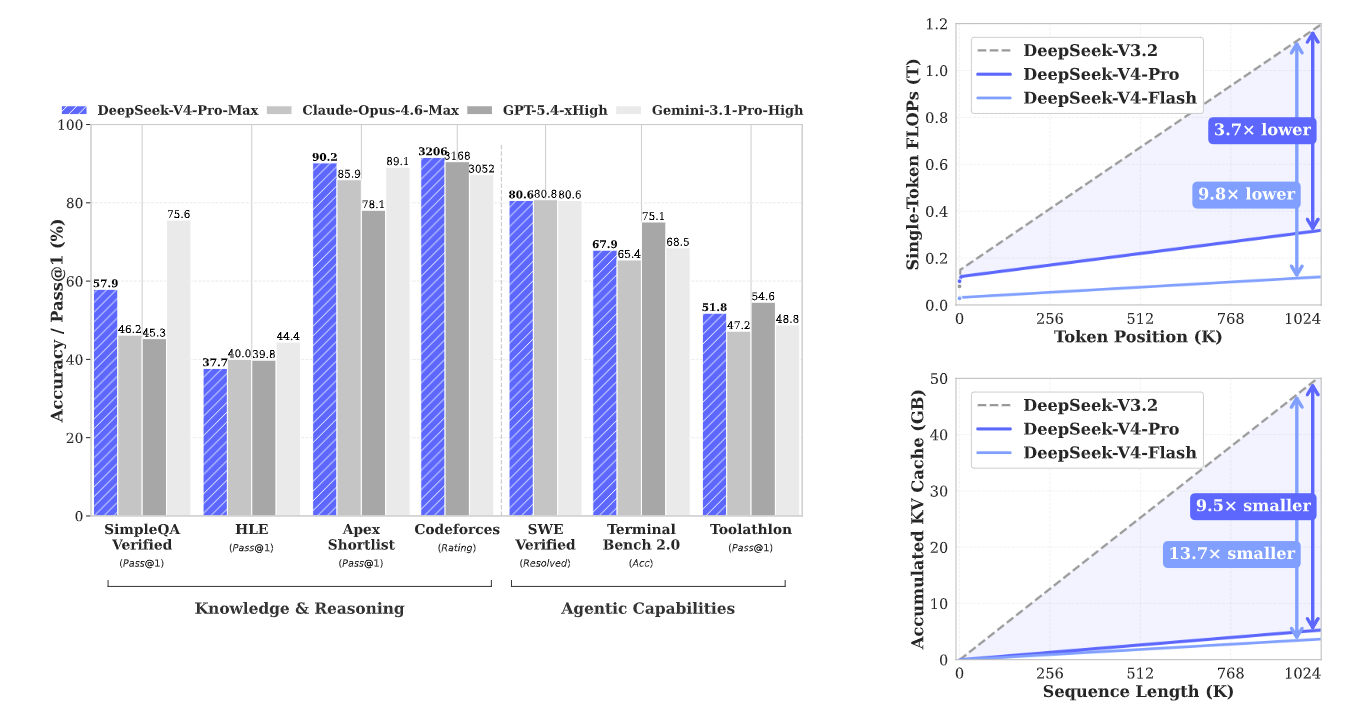
具体基准表现为:长文本处理能力是 V4 的核心优势项 ------ 在综合评估长文本理解精度的 LongBench 基准测试中,V4-Pro 平均得分 72.1,较前代 V3.1 提升近 11 个百分点,甚至超过了 GPT-5 的 69.8 分,仅略低于以 200K 长窗口为核心设计的 Claude Opus 4.6;在专门针对中文长文本理解能力设计的 MRCR 1M 基准测试中,V4-Pro 得分超过 83%,对超长中文文本的关键信息提取、逻辑梳理精度,远超其他闭源与开源竞品;在代表复杂推理能力的 HLE 基准测试中,V4-Pro 得分 37.7%,略低于 Claude Opus 4.6 和 Gemini 3.1 Pro,但仍优于其他主流开源模型;在通用知识维度,V4-Pro 的 MMLU-Pro 基准测试得分为 87.5%,SimpleQA-Verified 得分为 57.9%------ 除略低于 Gemini 3.1 Pro 的同类表现外,优于其他绝大多数闭源或开源竞品;在中文场景下的功能性写作、创意写作等实用维度,实测胜率超过 60%,大幅领先 Gemini 3.1 Pro 等国际闭源模型。
与开源阵营的主流产品相比,DeepSeek V4 的优势更显著:Llama3.1 与 Qwen2.5 的标配上下文窗口仅为 128K------ 即使通过扩展方案支持更长的上下文,推理效率和输出精度也会出现断崖式下滑;而 V4 全系原生支持 100 万 Token 上下文,长文本与通用推理得分均领先前者 10% 以上。
2.2 代码理解与生成
代码能力是 DeepSeek V4 的传统优势场景,也是本次迭代优势最明显的维度 ------ 实测表现显示,其代码能力已全面追平甚至部分超越顶级闭源模型。
具体基准表现为:在代码能力核心评估基准的 HumanEval 多语种测试中,V4-Pro 的 Pass@1 得分为 90.4%,Codeforces 竞赛级代码评估得分 3206------ 这一成绩超过了 GPT-5.4-xHigh、Claude Opus 4.6 等头部闭源模型,相当于 Codeforces 平台人类选手排名前 2% 的水平;在更贴近实际开发场景的 LiveCodeBench 基准测试中,V4-Pro 的 Pass@1 得分高达 93.5%------ 意味着其对真实工业级复杂开发需求的一次性输出正确率,已经达到了可直接嵌入开发流程的水平。
长代码库理解是 V4 在代码场景的 "杀手锏" 级能力。传统代码模型通常需要先对代码库进行拆分、做向向量库切片处理,而 V4 可直接将整个数十万行规模的代码库纳入一次上下文请求中,完成全局理解并输出跨文件的逻辑调整建议 ------ 这是 Llama3.1 等传统开源模型无法比拟的优势:Llama3.1 仅能支持小代码库的简单理解,对跨文件依赖的梳理精度不足。
不过第三方实测结果显示,在部分对健壮性要求极高的极端开发场景下,V4 偶发 "过度工程化" 问题 ------ 会输出超出需求冗余代码,与闭源模型的顶级表现仍有微小差距。但这一问题可通过工程化指令约束有效规避,不影响绝大多数工业级开发场景的实际落地。
2.3 多模态处理能力
多模态是当前大模型生态最主流的生产力场景,也是 DeepSeek V4 受行业关注的关键升级项 ------ 其多模态能力的发布节奏,与实际开放进度存在明确差异,需分阶段客观说明:
2026 年 4 月 24 日正式发布时,V4 核心开放的是文本模态能力 ------ 但官方并未将多模态作为后续独立版本的迭代卖点,而是在架构层面完成了全模态布局:其采用统一多模态架构进行底层重构,用 ViT-14B 视觉编码器替代了传统的外挂模块,每幅图像会生成 256 个连续向量的专属视觉 Token,和文本 Token 纳入同一预训练体系进行融合学习;视频帧则以 1fps 的频率转换为视觉 Token 参与建模。
发布仅 5 天后的 4 月 29 日,V4 的网页端、App 端便低调开启了 "识图模式" 灰度测试,官方核心研究员在 X 平台实锤了这一进展。这一能力并非简单的图像识别,而是具备 "代码 + 图像联合理解" 的级联推理能力:比如上传一张微服务架构的技术架构图或复杂财务报表截图,V4 可以直接分析图表逻辑、推导核心结论,甚至还原出部分核心模块的示例代码。但截至 2026 年 4 月 30 日,这一能力仅通过 API 向特定灰度用户开放,开源版本的视觉权重并未同步释放 ------ 官方明确披露,这部分能力将在 2026 年第三季度补充开源,供本地部署用户进行全模态微调。
对多模态要求较高的场景而言,这是一个明显的阶段性短板:无论是 GPT-5.4、Claude Opus 4.6 还是 Gemini 3.1 Pro,都已支持成熟的全模态处理;同级别开源模型中,也有部分产品支持基础的图文理解。而 V4 目前仅开放了文本模态的开源权重,企业暂无法在私有化环境中部署基于多模态的业务场景。
2.4 长上下文性能
长上下文是 DeepSeek V4 区别于传统开源模型的标志性能力,也是本次架构优化的重中之重 ------ 从实际表现看,这一升级已经将百万级长文本从 "实验室样品" 变成了 "商用级生产力工具"。
V4 全系标配 100 万 Token 级原生上下文窗口 ------ 这是 Llama3.1、Qwen2.5 等主流开源模型标配的 128K 窗口的 8 倍;Claude Opus 4.6 等顶级闭源模型,仅支持最高 20 万 Token 的上下文窗口。更关键的是,V4 并非单纯扩展了窗口上限,而是用混合注意力架构从底层支撑了长上下文的效率:在 100 万 Token 场景下,Pro 版推理计算量是 V3.2 的 27%,KV 缓存为 10%;Flash 版更是将计算量压缩到 V3.2 的 10%,KV 缓存压缩至 7%。
实测数据更能体现这一优化的商业价值:V4-Pro 处理 100 万 Token 文档仅需 15 分钟左右,Flash 版仅需 8 分钟;即使输入 500 页、约 80 万 Token 的专业 Python 编程手册内容,模型也能精准回答关于函数嵌套逻辑、跨文件依赖关系的具体细节问题,无逻辑错乱或信息遗忘问题。第三方实测报告进一步验证了其稳定性:在 LongBench 长文本基准测试中,V4-Pro 得分 72.1,较前代高出近 11 个点,超过了 GPT-5 的 69.8 分;在中文场景下的表现优势更大。
这意味着,DeepSeek V4 的长文本能力,已经可以支撑绝大多数行业级超长文本分析场景 ------ 这是此前开源模型无法覆盖的高价值空间。
2.5 综合对比总结
综合技术规格与实测性能,可将 DeepSeek V4 与主流竞品的关键维度的对比结论整理如下 ------ 由于各厂商官方基准测试环境与数据集存在差异,本次对比统一采用第三方公开实测口径作为评价基准:
- 与同级别闭源模型对比:V4-Pro 的综合性能与 GPT-5.4、Claude Opus 4.6 等处于同一档水平,在代码能力、100 万 Token 长文本处理、中文场景适配三项高价值维度上,甚至具备一定优势;不足则集中在通用逻辑推理的严谨性上 ------ 尤其是面对非英文场景的冷门知识问题时,输出准确率略低于头部闭源模型。更关键的差异在于,闭源模型的能力被厂商以 API 服务形式垄断,而 V4 支持私有化部署、可自由定制;
- 与传统开源模型对比:无论是 Pro 版还是 Flash 版,在参数规模、上下文窗口长度、长文本处理效率、代码能力、推理精度等所有核心维度上,V4 都具备碾压级优势。Llama3.1、Qwen2.5 等开源产品,仅在部署门槛、生态成熟度上有一定基础优势;
- V4 双版本间的差异:Flash 版牺牲了部分参数冗余度与极限推理性能,但换来了更低的部署门槛 ------ 它对常规商用场景的适配性几乎与 Pro 版无差异,成本优化幅度足以覆盖绝大多数企业级需求。
综合评价结果显示,DeepSeek V4-Pro 是当前综合能力最强的开源模型,在长文本、代码、推理、中文适配等高价值商用场景下,已经具备了替代闭源模型的实力;Flash 版则将顶级模型的商用门槛,压缩到了中大型企业可普及的区间。
三、DeepSeek V4 开源属性的行业影响分析

在行业头部企业纷纷将顶级模型技术专利化、用闭源服务形成生态锁定的背景下,DeepSeek V4 的开源策略极具行业冲击性 ------ 而其采用的 MIT 协议,是放大这种冲击性的核心变量。
3.1 开源协议与行业背景逻辑
DeepSeek V4 没有采用限制商业场景的非商用开源授权,也没有采用商业场景需公开衍生代码的 Copyleft 授权,而是全系采用了对商业应用最友好的 MIT 协议开放权重:协议内容明确,任何企业或个人均可免费使用、复制、修改、分发 V4 的代码与模型权重,无需公开衍生工程的源码,也无需额外支付专利授权费。
在 AI 行业,这种 "无保留开源" 的模式极具战略冲击性:当前闭源模型厂商的主流商业模式,本质是将模型技术作为生产资料垄断,通过 API 调用收费、功能增值收费的模式,对下游企业进行长期流量变现 ------ 下游企业的业务规模越大,API 调用成本越高,永远无法摆脱对上游模型厂商的技术依赖。
而 MIT 协议赋予的商业自由度,恰好击中了闭源生态的痛点:它允许企业将模型完整部署在自身私有化环境中,根据业务场景自由定制模型能力,彻底消除了 API 调用量的成本天花板 ------ 企业的核心业务逻辑,也无需再通过调用接口的方式暴露给闭源平台。这相当于将顶级模型的技术控制权,完全交还给了下游使用方。
需要特别强调的是,V4 的开源授权范围,不止是可执行代码和模型权重文件:官方随产品同步发布了完整的 58 页技术报告,将模型架构、预训练方案、优化策略的技术细节全部公开;代码仓库完整开放了从训练到推理的全链路脚本 ------ 这意味着,整个开源生态可以完全复现官方的模型迭代工作流,而非只能基于现有权重做简单微调。这为后续的行业级技术适配,提供了基础保障 ------ 截至 4 月 28 日,已有超过 3000 家行业企业申请接入 V4 生态,将其嵌入从工业制造到金融服务的核心业务场景。
3.2 技术层面的开源扩散效应
作为当前全球性能最先进的开源模型,DeepSeek V4 的技术溢出效应,远超此前开源模型的发布周期,甚至直接加速了整个开源大模型的长文本适配节奏。
从技术扩散的底层逻辑看,V4 等于给全行业提供了一个 "技术模板":企业和科研机构无需再投入数亿元的超大规模算力成本,重新从预训练阶段开发基础大模型 ------ 可以直接基于 V4 的权重和架构,快速微调适配行业场景的专属模型,跳过基础预训练阶段的试错成本。而开放的训练脚本与架构设计细节,也为中小规模模型的长文本优化提供了成熟参考方案 ------ 这将直接缩短全球开源模型社区在长上下文、复杂推理等技术维度的迭代周期。
更关键的技术扩散价值,体现在国产算力适配的工程化经验上:在 V4 发布之前,绝大多数顶级模型的适配逻辑,都围绕英伟达 CUDA 生态的技术栈设计;而 DeepSeek 在第一时间与华为昇腾、寒武纪、摩尔线程等本土算力厂商完成了 "Day0 级" 联调适配,验证了非 CUDA 算力栈运行万亿参数级模型的可行性。DeepSeek 并未独占这些适配经验,而是将相关优化脚本开放到开源社区 ------ 这直接降低了国产算力平台适配其他模型的技术门槛,加速了国产算力与开源模型的生态融合进程。
对开源生态而言,DeepSeek V4 的出现,是一次标准层面的价值重塑:发布短短数天内,LangChain、LlamaIndex、Dify 等主流 AI 应用框架,都已完成了对其接口的适配;大量面向行业场景的微调优化方案,已经在 GitHub、Hugging Face 等平台快速积累 ------ 围绕 V4 的技术栈,正在快速形成行业级标准。
3.3 商业层面的开源解构效应
DeepSeek V4 的开源策略,对大模型商业生态的冲击性影响,远不止免费授权这么简单。本质上,它是通过技术开放,重构了大模型产业的上下游议价权。
这一重构效应的最直接体现,是闭源模型 API 调用成本的定价逻辑被击穿。在 V4 之前,企业要在生产级场景使用 100 万 Token 上下文的模型,只能依赖几家头部闭源厂商的 API 服务,每百万输入 Token 的调用成本在百元级不等;而 V4 将长上下文的处理成本直接压缩到了 "地板价" 区间 ------ 以处理 100 万 Token 的长文档为例,闭源模型的调用成本足以覆盖 V4-Flash 版的私有化部署硬件摊销成本;若采用 V4 的 API 调用模式,成本降幅更超过 90%。这直接压缩了闭源厂商的议价空间,将长文本场景的行业级应用门槛,从大型企业预算级拉低到了中小机构可及范围。
更具行业解构性的逻辑是,它彻底改变了模型厂商与下游企业的关系:闭源 API 服务模式下,厂商掌握所有数据和技术权力;而 V4 的私有化部署能力,让企业将数据和核心场景的控制权牢牢掌握在自己手中 ------ 这对数据敏感行业的企业极具吸引力。根据官方披露的数据,截至 2026 年 4 月 28 日,已有三一重工、中国平安等超过 3000 家各行业头部企业申请接入 DeepSeek V4 的适配生态。
资本市场的反应,进一步验证了这一商业效应的传导逻辑:在 DeepSeek V4 发布前后的窗口期,国产算力芯片板块集体上涨 ------ 中芯国际、华虹半导体等头部算力产业链标的股价出现明显涨幅。这背后的资本判断逻辑是:DeepSeek V4 的 "Day0 级适配" 表现,首次证明了国产算力可以承载全球最顶级的开源模型;而 V4 带来的长文本场景普及化,将同步扩大国产算力的工业化落地空间。
从行业长期发展维度看,DeepSeek V4 的出现,将大模型的行业级定制门槛压缩到了之前的十分之一以下:此前企业开发行业定制模型,一般需要基于闭源模型的服务接口做上层应用开发,或自行投入算力重新训练一个参数规模小得多的基础模型;现在企业可以直接基于 V4 的完整架构,在相对普通的硬件集群上,用极低的成本快速训练出效果更好的专属行业模型。
四、商业应用场景分析
DeepSeek V4 的技术特性与开源授权组合,高度贴合当前企业级 AI 市场的核心需求 ------ 从场景适配性看,其最具商业落地潜力的方向集中在以下四大类,均是高价值、高付费意愿的企业级刚需场景:
4.1 超长文本处理与分析
这是 V4 最具技术壁垒的场景优势,也是当前企业级 AI 需求最集中的方向 ------ 其本质是将长文本处理从 "高成本专属服务" 变成了 "标准化基础能力"。
V4 的 100 万 Token 原生上下文窗口,可一次性处理超过 50 万字的文本内容,高度适配各行业头部企业的典型长文本业务需求:比如金融机构的超长年报、行业研究报告的一次性分析,直接将数十个数据维度的财务文本输入模型,就能自动生成风险评估框架;法律与合规机构可将整份超过 10 万字的合同、全量合规条款直接输入模型,完成跨文件的风险点检索、多版本差异比对或合规性初审,无需再做规则拆分或分段摘要;企业可将海量历史客服对话、用户调研日志合并做全量分析,精准挖掘用户投诉的核心关联因素;甚至学术研究人员可将一整篇数百页的专业论文、实验报告输入模型,一次性梳理研究脉络、复现实验逻辑。
此前要支撑这类场景,企业只能依赖闭源厂商提供的专属定制化 API 服务 ------ 调用成本极高,还需将业务数据上传至厂商的服务接口,存在一定的数据泄露风险。而基于 V4 的私有化部署方案,企业不仅能以更低的成本支撑业务,还能将所有敏感数据完整保留在内部机房环境中,从根本上规避了数据合规风险。这是长文本场景下,企业级用户的核心决策痛点。
4.2 代码生成与 IT 开发辅助
这是 V4 成熟度最高、验证最充分的场景,也是当前企业级需求最明确的方向 ------ 其本质是将 AI 从 "代码补全工具",升级成了 "工程化协同开发工具"。
实测显示,V4 的代码能力足以覆盖工业级软件开发的全流程需求:在应用开发阶段,它可以根据微服务架构图的逻辑约束,一次性生成后端接口、数据模型定义甚至对应的 Dockerfile 配置文件;在维护阶段,它可以对数十万行规模的遗留代码库进行逻辑梳理,自动生成标准化接口文档,甚至将遗留代码的逻辑重构为新的语言框架;在质量保障阶段,可根据业务功能的核心逻辑,自动生成满足分支覆盖率要求的单元测试用例代码;在技术管理场景,架构师可以将数十份技术调研文档、架构规范直接输入模型,自动整理技术选型的关键维度的对比报告、接口规范文档等开发交付物。
与闭源模型的代码能力相比,私有化部署的 V4 有两个不可替代的商业价值:第一是更安全 ------ 企业的核心业务代码库无需上传到第三方 API 服务,可在企业内部环境中完成所有分析环节,避免核心知识产权通过 API 接口泄露;第二是成本极低 ------ 代码场景的 API 调用频率高、数据量大,闭源服务的调用成本会随着研发规模线性增长,而 V4 的私有化方案完全消除了调用成本的天花板。
从行业适配性看,这一能力的覆盖范围极广:既可以支撑软件企业的研发流程提效,也可以支撑传统行业企业的 IT 部门,将其作为内部研发协同工具,辅助核心业务系统的迭代与维护。
4.3 企业级知识检索与智能体 RAG/Agent
这是 V4 落地最顺畅的场景 ------ 其本质是长上下文能力与开源能力的叠加,直接解决了传统企业知识库的检索痛点,为企业提供了高性价比的 "垂直搜索 + 智能摘要" 方案。
传统企业 RAG 检索增强生成方案,往往需要对企业知识库做段落拆分、向量化存储,再通过多段召回 + 摘要拼接的模式,回答企业的复杂专业问题。这种模式的核心缺陷,是无法进行跨文档的长逻辑链推理 ------ 如果业务人员的问题涉及多个文档、多维度逻辑关系,拼接结果容易出现逻辑断裂、内容遗漏,甚至数据自相矛盾。
而基于 V4 的长上下文能力,可以直接简化传统 RAG 的复杂架构:无需再对文档做精细拆分,可将企业的多个相关文档一次性输入模型,基于全局内容进行精准回答 ------ 检索准确率高达 99%。这大幅降低了企业搭建私有知识库的技术门槛,落地成本较传统方案大幅降低。
此外,作为优秀的基础模型,DeepSeek V4 可被封装为能力更强的领域专属智能体核心大脑:它的长上下文适配多轮对话逻辑链跟踪,其推理能力可支撑任务规划、拆解、调用企业自有工具接口并总结结果;更重要的是,其开源特性可保障行业数据和流程的安全性。例如,它可以作为企业内部流程自动化机器人的核心大脑,或生产级 RAG 系统的基础支撑。
4.4 全模态应用场景落地规划
尽管当前 V4 的多模态能力仅对灰度用户开放,但这是其未来重要的新场景增长点 ------ 多模态版将直接支撑需要联合分析文本、代码、图像和音视频的复杂企业级场景;而开源版本的多模态权重释放后,会进一步扩展商业覆盖边界。
从官方披露的节奏看,这些场景的落地规划已经明确:在工业制造领域,工程师可以将设备原理示意图、运维流程文档、实时传感器读数的文本化数据结合,进行故障诊断或运维指导;金融行业可将财务报表的截图、扫描版审计报告,与业务数据库的核心数据做关联分析,辅助风险审核或投资决策;广告行业可根据产品宣传图和文档化的市场定位建议,生成多风格的宣传文案;安防行业可对监控视频的帧数据进行结构化分析,结合安保规则输出风险预警,完全覆盖了现代企业对大数据处理分析的主要需求。
值得强调的是,虽然多模态权重暂未开源,但这一能力的落地节奏已经与行业头部用户同步:比如三一重工、中国平安等核心接入方,已经在基于灰度 API 测试相关场景的适配方案,将在开源权重发布后第一时间上线对应应用。
4.5 商业化落地的现实边界
必须客观指出的是,DeepSeek V4 当前版本的技术短板,也明确限制了其部分商业场景的落地边界 ------ 并非所有行业都能无门槛接受。
这一短板的核心是高幻觉率问题:根据第三方机构 Artificial Analysis 的评测数据,V4-Pro 的基础幻觉率为 94%,轻量化的 Flash 版基础幻觉率高达 96%;而顶级闭源模型的幻觉率普遍在 50% 以内。这意味着,当模型遇到不确定的专业问题时,极大概率会输出看似合理但实际错误的信息。对绝大多数互联网业务场景而言,这是一个无法接受的硬伤;但商业场景下的实测数据显示,通过添加严格的业务约束指令、配置专属的检索增强生成(RAG)知识库等工程化手段,可以将这一比例压缩至 6% 以内 ------ 基本满足绝大多数商业场景的可靠性要求。
另一项短板是相对较高的部署成本门槛。尽管通过架构创新大幅压缩了算力需求,但万亿级参数模型的基础规模仍决定了其硬件门槛:FP8 量化的 Pro 版模型需要总计近 TB 级显存的高端显卡支撑,企业私有化部署需要投入相当规模的硬件成本和技术人力成本;轻量化的 Flash 版虽然可在消费级级显卡上运行,但需要具备一定的技术能力进行优化调优。这意味着,中小规模企业很难独立承担其部署和运维成本。
这两项短板,明确限制了 DeepSeek V4 在高风险行业场景的直接落地 ------ 比如医疗诊断、航空航天、金融投资、法律咨询等对输出结果的准确性、严谨性要求极高的领域,暂时无法直接将其作为生产级核心模型使用。这些行业的用户,或继续采用精度更高的闭源模型服务,或需等待 DeepSeek 后续版本解决这一问题。
五、适配与生态支持情况
作为私有化部署的核心前提,DeepSeek V4 的生态适配成熟度,直接决定了其商业落地效率 ------ 而从实际情况看,其适配进展足够成熟,覆盖了企业从 "测试验证" 到 "规模化上线" 的全链路需求。
5.1 硬件适配性
作为侧重私有化部署的开源模型,DeepSeek V4 对异构算力栈的兼容能力,直接决定了其商业化落地效率 ------ 而其最具行业价值的突破,是实现了从英伟达 CUDA 生态到国产算力栈的跨平台兼容适配,且在国产算力栈上的实测性能表现更优。
官方的 "Day0 级" 适配合作覆盖了华为昇腾、寒武纪、摩尔线程等主流国产算力品牌;实测结果显示,华为昇腾 950 运行 V4-Pro 的推理性能可达英伟达 H20 的 2.87 倍。这意味着,国内企业级用户可以基于国产算力栈,完整搭建从硬件到模型的全链路国产化 AI 应用,无需依赖国外高端算力芯片或 CUDA 生态 ------ 为国产替代提供了一个可行的全栈化解决方案。
同时,它并未放弃对传统英伟达算力生态的兼容:模型支持从高端数据中心级 GPU 到普通消费级显卡的多级别英伟达算力适配。企业用户可根据场景的性能需求,灵活选择对应级别的算力基础设施。
不同场景的典型硬件配置参考如下:
- DeepSeek V4-Pro(数据中心级部署方案) :在 INT4 量化的最低配置模式下,需总计约 700GB 的显存空间,推荐采用 8 张英伟达 H100 80GB 显卡或等效国产算力集群作为基础算力支撑;
- DeepSeek V4-Flash(企业级部署方案) :在 FP8 量化的推荐配置模式下,推荐采用 4 张英伟达 RTX B200/B300 显卡或华为 Atlas 800 八卡服务器,可获得较流畅的体验;
- DeepSeek V4-Flash(小规模测试方案) :可在 24GB 显存的英伟达 RTX 4090 级消费级显卡上运行推理服务,甚至在显存为 8GB 的普通级显卡上进行功能验证,大幅降低了企业的技术探索门槛。
这一跨平台适配逻辑,让企业能根据数据中心现有资源,灵活选择成本最优的部署方案。
5.2 软件生态与企业级服务
DeepSeek V4 的软件生态成熟度,也足以支撑从测试验证到大规模商用的全链路需求。
在模型管理层面,Hugging Face 和魔搭社区都已提供 DeepSeek V4 的模型权重仓库与专属适配化镜像,开发者可通过 Git LFS、ModelScope CLI 工具直接下载所需的版本,快速完成本地环境部署;主流大模型部署框架如 vLLM、TGI 以及 NVIDIA Triton 推理服务器均已完成适配优化,支持企业级的高并发推理服务。值得一提的是,其接口完全兼容 OpenAI 的格式,企业原有基于 OpenAI 接口开发的应用,几乎无需修改代码即可切换到 V4 接口服务。
在应用开发层面,DeepSeek V4 发布数天内,LangChain、LlamaIndex、Dify 等主流 AI 应用开发框架就已完成适配 ------ 这些框架提供了大量的调用示例、代码库,支撑企业快速搭建 RAG 系统、智能体等应用,大幅降低了二次开发的技术门槛;私有化部署的模型,也可以通过 API 网关,给业务方应用提供高性能服务。
在商业支持层面,深度求索公司已经推出了商业授权与企业级运维支撑服务 ------ 对购买了商业授权的企业用户,提供专属技术支持、性能调优培训、场景化适配指导、高并发运维等专业服务,解除企业私有化部署的后顾之忧;部分算力厂商也联合发布了部署联合方案,为企业提供从硬件采购适配、模型调优到业务场景上线的一站式集成服务。
此外,为平衡性能与成本需求,DeepSeek 还推出了 "混合云" 部署方案:对并发量较大但业务逻辑常规的通用业务场景,调用成本极低的公共 API 服务;对数据敏感性强、业务价值高的核心业务场景,采用私有化部署方案 ------ 企业可以根据业务数据价值等维度,灵活调配部署模式,实现性能、成本、安全性的相对平衡。
六、结论
综合技术表现、场景优劣势与行业影响,可得出对 DeepSeek V4 的系统性评估结论:
6.1 技术评估结论
DeepSeek V4 代表了当前开源大模型的技术性能巅峰 ------ 它用工程化的务实方案,解决了 Transformer 架构落地到工业级场景的最大两个技术痛点:长上下文成本与参数规模瓶颈。
从技术维度上看,它在长文本处理、代码能力、推理性能、中文场景适配等核心维度上的表现,已经达到了全球闭源旗舰产品的档位;但仍在多模态成熟度、幻觉控制、部署成本等维度上,与顶级闭源模型存在一定差距。它并非一个毫无短板的 "终极技术方案",而是精准击中了当前企业级市场的核心刚需 ------ 尤其是长上下文场景,是当前所有开源模型与闭源模型中的不可替代项。
更重要的是,这一代模型的技术底座(混合注意力、流形约束、MoE 稀疏激活),为后续迭代提供了足够的扩展冗余 ------ 配合完全开放的代码权重,能支撑行业快速迭代出更适配垂直场景的微调版本。
6.2 商业应用结论
DeepSeek V4 是企业级市场的 "颠覆级商业玩家"------ 它的出现,大幅拉低了顶级大模型能力的商用门槛,改变了闭源模型厂商与下游企业的商业博弈逻辑。
对企业而言,选择 DeepSeek V4 的核心逻辑,不只是节省模型调用的技术成本,更是掌握业务的主动权:它的性能足够支撑绝大多数高价值企业级场景 ------ 超长文档分析、代码库辅助开发与企业 RAG 场景,都具备替代闭源模型的实力;而 MIT 协议的私有化部署模式,赋予了企业数据安全、业务定制化、成本可控三大收益 ------ 不用再将核心业务数据和场景逻辑暴露给闭源平台,无需为使用 AI 能力支付长期授权费用。
但企业在采用前,需要客观评估其短板与场景的适配性:高幻觉率的技术短板,决定了其在高风险行业场景的应用受限,需要配套额外的技术方案进行质量兜底;部署成本门槛,决定了其主要服务中大型规模企业级用户的需求。
总体而言,DeepSeek V4 是闭源 API 服务模式的强劲替代选项 ------ 对数据敏感度高、业务价值高的中大型企业场景而言,它是当前最值得选择的开源模型。
6.3 行业效应结论
DeepSeek V4 的发布,不只是一次产品版本迭代,更是一次行业级的战略拆墙行为。
它的开源效应,本质是技术成本、商业格局两个维度的平权效应:
- 在技术成本维度,它将万亿级参数、百万级上下文的大模型技术,从头部企业的专利壁垒中释放出来,大幅降低了中小算力投入进行商用的技术门槛 ------ 企业无需再投入巨额预训练成本,可直接基于成熟的架构和权重做行业适配;
- 在产业格局维度,它有效对冲了海外闭源模型的技术垄断 ------ 配合国产算力栈,国内企业无需再依赖闭源模型的 API 服务,可基于完全自主的全栈化解决方案搭建业务场景;更直接推动了整个行业的长上下文服务定价的下降。
对开源社区而言,V4 不只是开放了一个模型权重文件:其开放的训练代码、优化脚本、测试案例与技术经验,极大降低了国产模型跟进长文本、高性价比技术路线的试错成本,为后续开源模型的进化提供了坚实的技术基座。
6.4 综合建议
综合性能、成本、安全等维度,DeepSeek V4 是企业级用户的务实选择 ------ 对中国企业而言,其价值适配性更贴合本地化需求。建议不同类型的市场玩家,采取不同的落地跟进策略:
- 企业级用户选型建议:优先以长文本处理、代码辅助场景为切入点,快速验证上线;在部署过程中,需配套强化 RAG 知识库与行业指令约束,对模型输出做合规兜底;对多模态场景有需求的企业,可先基于官方灰度 API 进行业务场景测试,待多模态权重开源后再部署私有化版本;
- 行业生态玩家的适配建议:算力厂商应加速适配方案优化,降低企业选型的综合成本;AI 应用开发商、集成服务商应基于 V4 开发面向不同行业的标准化微调模型、场景适配模板,共享微调优化经验,助力企业用户挖掘长上下文场景下的业务价值;
- 技术跟进建议:密切跟踪两个维度的迭代节奏 ------DeepSeek V4 的多模态完整版开源进度,以及其后续版本在幻觉控制、部署成本、并发性能上的优化进展;重点关注国内同级别开源模型在长上下文、稀疏架构方向的适配节奏。
长期来看,DeepSeek V4 的发布,标志着开源大模型从闭源模型的补充选项,进化到了与闭源模型正面抗衡、甚至部分场景替代的新阶段。模型技术开放性、私有化定制成本与国产化算力适配能力,将成为企业级市场选型的核心竞争力 ------ 而 V4 已经占据了领先身位。