一、Ollama 简介及下载
1、Ollama 简介
Ollama是一个专为macOS设计的开源工具,让你能在自己的Mac上轻松运行各类大语言模型。它最大的特点是"极简"--无需复杂的Python环境配置,无需CUDA驱动,只要一条命令就能完成模型的下载、安装和运行。
核心优势:
- 极致简单:
ollama run qwen3.5一行命令即可对话,零学习成本 - 苹果专属优化:最新0.19版本全面整合苹果MLX框架,在M系列芯片上推理速度提升近一倍
- 完全本地运行:数据不上云,隐私安全有保障
- 开箱即用:内置丰富的模型库,通义千问、Llama、DeepSeek等主流模型一键下载
- 开发者友好:提供OpenAI兼容的API,可轻松集成到其他应用中
无论你是AI开发者还是普通用户,Ollama都能让你在本机体验顶级大模型的魅力。
2、Ollama 下载安装
下载安装方式:
- 访问官网:打开浏览器,进入 Ollama 官网(ollama.com/)
- 下载版本:下载安装包(直接点击官网上对应系统 Download 按钮)
- 安装:打开下载的 .dmg 文件,将 Ollama 图标拖入 "Applications" 文件夹
- 首次启动:打开应用程序中的 Ollama,它会提示你安装命令行工具,按提示操作即可
验证方式:打开终端输入 ollama --version,如果显示 "ollama version is x.xx.x" 说明安装成功。

二、下载运行模型
1、运行 Ollama
在Ollama安装完成后, 一般会自动启动 Ollama 服务,而且会自动设置为开机自启动。

如果没有启动,可以通过如下命令启动:
bash
ollama serve其他常用的验证命令:
| 命令 | 作用 |
|---|---|
ollama list |
查看已下载的模型列表 |
ollama ps |
查看当前正在运行的模型进程 |
| `ps aux | grep ollama` |

你可以通过 http://localhost:11434 访问 Ollama 的 REST API 服务:
2、选择适合自己的模型
在我的 Mac mini M4 + 32GB 内存上,比较适合的模型是 qwen3.5-flash:35b (Q4_K_M量化版本)
| 考虑因素 | 分析 |
|---|---|
| 内存大小 | 32GB 统一内存。该模型采用 Q4_K_M 量化后约 20GB,为 macOS 系统和对话上下文预留了约 12GB,刚好舒适运行 |
| 架构优势 | 模型是 MoE(混合专家)架构,总参数 347 亿,但每次推理只激活约 30 亿 参数,速度快、内存占用低 |
| 预期速度 | 在 32GB Mac 上,预计可达 12-22 tokens/s,流畅可用 |
这是经过社区验证的"甜点配置"------32GB Mac + 32B Q4模型是本地 AI 的最佳性价比组合。
3、下载并启动模型
shell
ollama run mdq100/qwen3.5-flash:35b
或者:
ollama pull ollama run mdq100/qwen3.5-flash:35b
其他下载方式:
1、可以在 ollama.com/library 中选择自己想要的模型。
2、可以在魔搭社区 modelscope ( https://www.modelscope.cn/models?name=GGUF&page=1&tabKey=task )搜索你想要的模型安装。
参考文档:https://www.modelscope.cn/docs/models/advanced-usage/ollama-integration
命令说明
这条命令的作用是在 Ollama 中下载并启动 mdq100/qwen3.5-flash:35b 模型,然后进入一个可以直接与 AI 对话的交互式界面。
当你输入 ollama run mdq100/qwen3.5-flash:35b 并按回车后,Ollama 会在后台自动替你完成两件事:
| 步骤 | 做了什么 | 说明 |
|---|---|---|
| 1. 检查并下载模型 | 执行ollama pull操作 |
它会先检查你的电脑上是否已有这个模型。如果没有,就会自动开始下载。这个模型文件大小约 20GB,首次运行需要耐心等待下载完成。 |
| 2. 启动模型并进入对话 | 执行ollama run操作 |
下载完成后,它会自动加载模型,并进入一个 >>> 提示符的交互式命令行界面。此时,你就可以直接输入问题与 AI 进行对话。 |
简单来说,ollama run 是一个"一键运行"命令,它把"下载"和"启动"两步合并了,让你用最少的操作立刻开始使用模型。(如果已经下载过了,他会直接运行)
模型说明
关于这个模型 ------ mdq100/qwen3.5-flash:35b
这条命令里的模型名字虽然长,但每个部分都有含义,值得了解一下:
mdq100/:这是该模型在 Ollama 模型库中的作者或命名空间,表示由用户mdq100上传和维护。qwen3.5-flash:这是模型的名称。它源自阿里云通义千问团队开源的 Qwen3.5-35B-A3B 模型。此版本为纯文本模型,移除了图像识别等功能,但保留了核心的语言能力,使其运行更轻量、更快速。:35b:这是模型的标签或版本,指明了这是该系列中拥有约 350亿(35B)总参数的版本。
补充:该模型还有一个 :35b-code 版本,专门为代码生成任务优化了参数。如果你主要用于编程,可以尝试运行命令 ollama run mdq100/qwen3.5-flash:35b-code。
启动模型
模型运行起来后,你可以尝试:
- 直接对话:在
>>>提示符后输入你的问题。 - 退出对话:输入
/bye即可退出交互模式,回到终端。 - 查看所有可用命令:输入 /? 即可查看所有可用命令
你会看到类似下面的输出,表示你可以开始对话了:

三、核心功能使用
1、命令行交互对话
在 ollama run 启动的交互界面中,你可以直接输入问题并获得回答
2、指定系统提示
通过 /set system 命令在对话开始前添加"系统提示词",为模型设定一个"角色"或"行为准则"。这样,模型后续的回答都会遵循你设定的专家角色。


3、Ollama 参数调整
Ollama的参数调整主要有四种方式:Modelfile预设参数(一劳永逸)、环境变量(改服务行为)、命令行参数(临时用)、API动态传参(实时调)。
3.1、通过 Modelfile 设置参数(永久生效,推荐)
创建自定义模型,把参数写死在模型配置里,以后每次运行自动生效,不用反复设置。
操作步骤
1. 导出原模型的 Modelfile 作为模板
shell
ollama show --modelfile mdq100/qwen3.5-flash:35b > Modelfile2. 编辑 Modelfile,在 PARAMETER 区域添加或修改参数
shell
# Modelfile 内容示例
FROM mdq100/qwen3.5-flash:35b
# 基础参数(最常用)
PARAMETER temperature 0.7 # 创造力:0.1保守~1.2随机,默认0.8
PARAMETER num_ctx 32768 # 上下文长度(记忆长度),默认2048
PARAMETER num_predict 2000 # 最大回答长度,默认-1(无限制)
PARAMETER top_p 0.9 # 核采样,默认0.9
PARAMETER seed 42 # 固定随机种子,让回答可复现
PARAMETER stop "User:" # 碰到这些词就停止生成
PARAMETER stop "Assistant:"
# 系统角色设定(软性格)
SYSTEM """你是一个专业的编程助手,回答要简洁、准确,优先提供代码示例。"""3. 创建新模型
shell
ollama create my-qwen-model -f Modelfile4. 运行新模型
shell
ollama run my-qwen-model常用 PARAMETER 参数速查
| 参数 | 作用 | 默认值 | 推荐设置 |
|---|---|---|---|
temperature |
控制创造性,越高越放飞 | 0.8 | 代码/数学:0.3-0.5;聊天/文案:0.8-1.2 |
num_ctx |
上下文窗口(记忆多少tokens) | 2048 | 长对话/长文档:8192-32768 |
num_predict |
最大生成长度(tokens) | -1(无限) | 日常:500-1000;长输出:2000+ |
top_p |
核采样,与temperature配合 | 0.9 | 通常保持0.9,调低可让回答更聚焦 |
seed |
随机种子,固定后输出可复现 | 0(随机) | 调试时固定为42 |
stop |
终止符,出现即停止生成 | 无 | stop "User:" stop "\n\n" |
repeat_penalty |
重复惩罚,避免车轱辘话 | 1.1 | 1.05-1.2 |
3.2、通过环境变量设置(改变Ollama服务行为)
这些变量影响整个Ollama服务,需要在启动前设置。
macOS 上设置方法
临时设置(当前终端会话):
shell
# 在启动Ollama服务前设置
export OLLAMA_NUM_PARALLEL=4 # 允许4个并发请求
export OLLAMA_KEEP_ALIVE=10m # 模型保持加载10分钟
export OLLAMA_FLASH_ATTENTION=1 # 开启Flash Attention,降低内存占用
ollama serve永久设置(推荐):
shell
# 编辑shell配置文件
echo 'export OLLAMA_NUM_PARALLEL=4' >> ~/.zshrc
echo 'export OLLAMA_KEEP_ALIVE=10m' >> ~/.zshrc
echo 'export OLLAMA_FLASH_ATTENTION=1' >> ~/.zshrc
source ~/.zshrc
# 然后重启Ollama服务(在活动监视器里杀掉进程,或重启电脑)常用环境变量速查
| 变量 | 作用 | 默认值 | 你的配置建议 |
|---|---|---|---|
OLLAMA_NUM_PARALLEL |
并行请求数(同时处理几个问题) | 1 | 2-4(32GB内存足够) |
OLLAMA_KEEP_ALIVE |
模型保持加载的时间 | 5m | 15m或30m,避免频繁加载 |
OLLAMA_FLASH_ATTENTION |
开启Flash Attention,省内存 | 0 | 1(强烈推荐开启) |
OLLAMA_KV_CACHE_TYPE |
KV缓存量化,省显存 | f16 | q8_0(几乎无精度损失) |
OLLAMA_HOST |
服务监听地址 | 127.0.0.1:11434 | 本地用默认;局域网分享改0.0.0.0:11434 |
OLLAMA_MODELS |
模型存放路径 | ~/.ollama/models |
若256G硬盘吃紧,可改到外置盘 |
关于 num_ctx 的特殊说明
num_ctx(上下文长度)既可以在 Modelfile 里设置(永久),也可以通过环境变量设置全局默认值:
shell
# 设置全局默认上下文长度为32768
export OLLAMA_CONTEXT_LENGTH=32768
ollama serve注意:Modelfile 里的 num_ctx 优先级更高,会覆盖环境变量。
3.3、通过命令行参数临时设置(运行时覆盖)
如果你只想临时调整一次,不想新建模型,可以直接在 ollama run 时传参:
shell
# 临时调低temperature,让回答更严谨
ollama run my-qwen-model --temperature 0.3
# 设置更长的生成上限
ollama run my-qwen-model --num-predict 3000
# 查看当前模型的参数配置
ollama show my-qwen-model --parameters但注意:Ollama 原生命令行支持的参数有限,大部分参数需要写在 Modelfile 里。
3.4、通过 API 动态传参(适合编程调用)
如果你用代码调用 Ollama 的 API,可以在每次请求时动态传参,这是最灵活的方式:
bash
curl http://localhost:11434/api/generate -d '{
"model": "my-qwen-model",
"prompt": "用Python写一个快速排序",
"options": {
"temperature": 0.3,
"num_ctx": 32768,
"num_predict": 1500,
"top_p": 0.85,
"stop": ["```", "User:"]
}
}'Python 调用示例:
python
import requests
response = requests.post('http://localhost:11434/api/generate', json={
'model': 'my-qwen-model',
'prompt': '解释递归',
'options': {
'temperature': 0.5,
'num_ctx': 16384
}
})3.5、最佳实践建议🔥
作者的电脑配置是Mac mini M4 + 32GB,35B-A3B MoE 模型,推荐配置如下:
专属模型
shell
# 1. 导出配置
ollama show --modelfile mdq100/qwen3.5-flash:35b > Modelfile
# 在文件开头或结尾添加参数(注意不要写在同一行注释)
echo "" >> Modelfile
echo "PARAMETER temperature 0.7" >> Modelfile
echo "PARAMETER num_ctx 8192" >> Modelfile
echo "PARAMETER num_predict 2000" >> Modelfile
echo "PARAMETER top_p 0.9" >> Modelfile
echo "PARAMETER repeat_penalty 1.1" >> Modelfile
echo "" >> Modelfile
echo 'SYSTEM """你是一个专业的技术助手,擅长编程和问题解答。回答简洁、准确,必要时提供代码示例。"""' >> Modelfile
# 创建模型
ollama create xj-qwen -f Modelfile
# 4. 设置环境变量(写入 ~/.zshrc)
echo 'export OLLAMA_FLASH_ATTENTION=1' >> ~/.zshrc
echo 'export OLLAMA_KV_CACHE_TYPE=q8_0' >> ~/.zshrc
echo 'export OLLAMA_KEEP_ALIVE=30m' >> ~/.zshrc
source ~/.zshrc
# 5. 重启Ollama服务后运行
ollama run xj-qwen这套配置能让我的 Mac 跑得更快、更省内存,同时对话体验也更好。配置完成后可以查看配置是否生效:
shell
xj@Mac ~ % ollama show xj-qwen
Model
architecture qwen35moe
parameters 34.7B
context length 262144
embedding length 2048
quantization Q4_K_M
Capabilities
completion
tools
thinking
Parameters
num_predict 2000
presence_penalty 1.5
repeat_penalty 1.1
temperature 0.7
top_k 20
top_p 0.9
num_ctx 8192
System
你是一个专业的技术助手,擅长编程和问题解答。回答简洁、准确,必要时提供代码示例。
License
Apache License
Version 2.0, January 2004
...4、API 服务
使用 Ollama API 主要有两种方式:直接调用原生的 REST API,或通过 OpenAI 兼容的 API。
4.1、启动模型并监听 API
通过 ollama serve 访问 Ollama 的 REST API 服务。此时,接口默认监听在 http://localhost:11434,调用本地 API 不需要认证。
4.2、方式一:原生 HTTP API
Ollama 默认提供的 REST API,功能最直接。
对话接口/api/chat
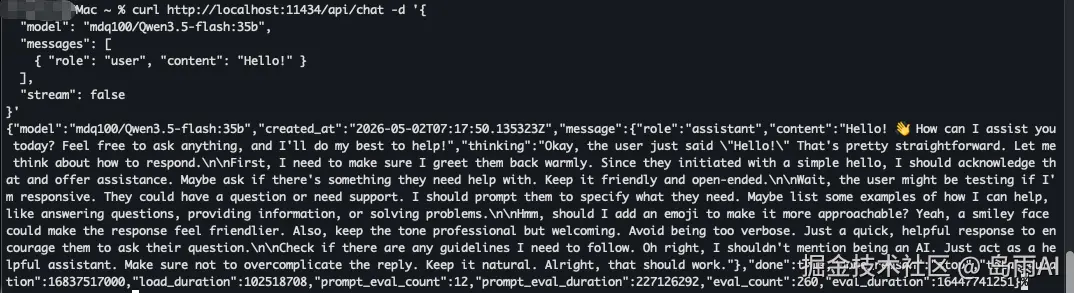
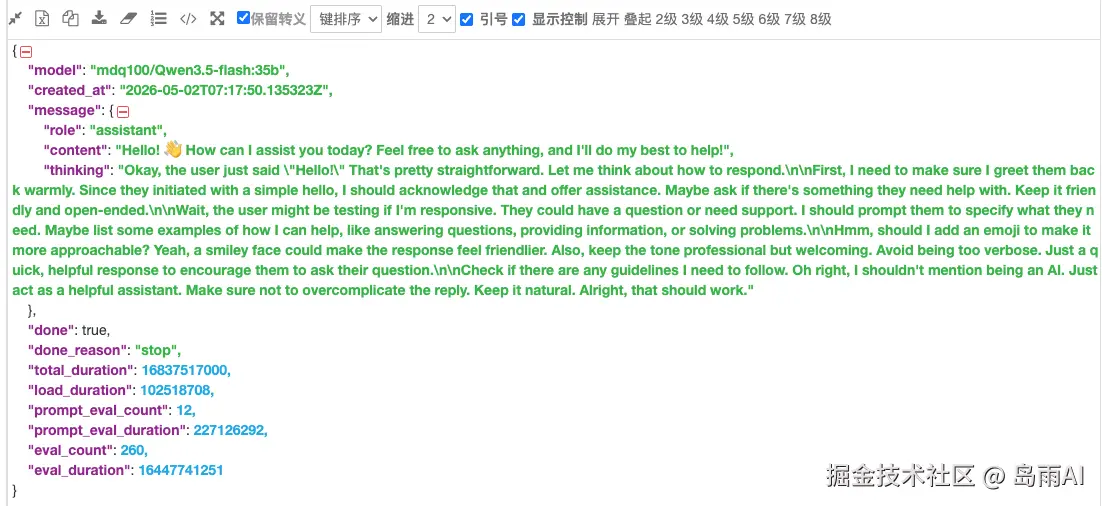
这是你与模型进行多轮对话的主要方式。cURL 示例 (非流式):
shell
curl http://localhost:11434/api/chat -d '{
"model": "mdq100/Qwen3.5-flash:35b",
"messages": [
{ "role": "user", "content": "Hello!" }
],
"stream": false
}'如果想改为流式输出,只需将 "stream": false 改为 true ,模型会一个字一个字地生成回复。
Python 示例:
python
import requests
import json
response = requests.post(
"http://localhost:11434/api/chat",
json={
"model": "mdq100/Qwen3.5-flash:35b",
"messages": [{"role": "user", "content": "Hello!"}],
"stream": False
}
)
print(response.json()["message"]["content"])文本生成接口/api/generate
用于一次性的文本补全任务,不维护对话历史。
shell
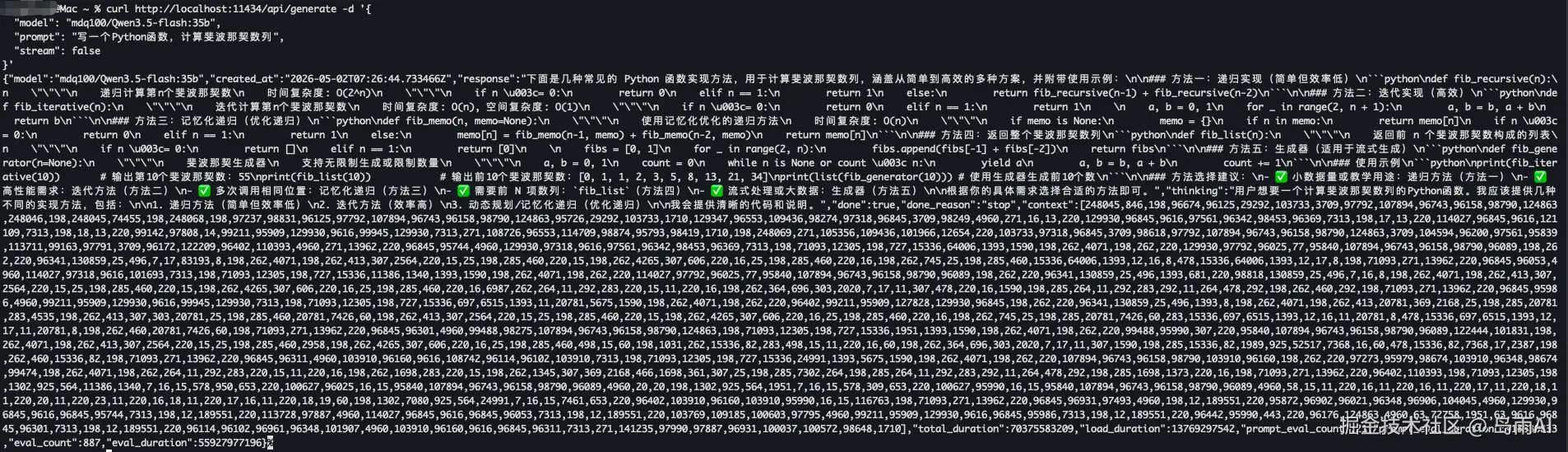
curl http://localhost:11434/api/generate -d '{
"model": "mdq100/Qwen3.5-flash:35b",
"prompt": "写一个Python函数,计算斐波那契数列",
"stream": false
}'
Java 代码示例:
java
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
public class OllamaDemo1 {
// Ollama API 地址(默认本地运行)
private static final String OLLAMA_API_URL = "http://localhost:11434/api/generate";
// 要使用的模型名称(如 llama2, mistral, qwen 等)
private static final String MODEL_NAME = "mdq100/Qwen3.5-flash:35b";
public static void main(String[] args) {
try {
// 调用 Ollama API
String response = callOllama("你好,请介绍一下你自己");
System.out.println("模型回答:" + response);
} catch (IOException e) {
System.err.println("调用失败:" + e.getMessage());
e.printStackTrace();
}
}
/**
* 调用 Ollama 生成文本
*/
public static String callOllama(String prompt) throws IOException {
URL url = new URL(OLLAMA_API_URL);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// 设置请求头
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "application/json");
conn.setDoOutput(true);
// 构建请求体
String requestBody = String.format(
"{"model": "%s", "prompt": "%s", "stream": false}",
MODEL_NAME, prompt
);
// 发送请求
try (OutputStream os = conn.getOutputStream()) {
byte[] input = requestBody.getBytes("utf-8");
os.write(input, 0, input.length);
}
// 读取响应
int status = conn.getResponseCode();
if (status == HttpURLConnection.HTTP_OK) {
try (BufferedReader br = new BufferedReader(
new InputStreamReader(conn.getInputStream(), "utf-8"))) {
StringBuilder response = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
response.append(line);
}
return extractResponse(response.toString());
}
} else {
throw new IOException("HTTP 错误:" + status);
}
}
/**
* 从 JSON 响应中提取生成的文本
*/
private static String extractResponse(String jsonResponse) {
// 简单解析 JSON 中的 response 字段
int start = jsonResponse.indexOf(""response":");
if (start != -1) {
start = jsonResponse.indexOf(""", start + 11);
int end = jsonResponse.indexOf(""", start + 1);
if (end != -1) {
return jsonResponse.substring(start + 1, end);
}
}
return jsonResponse;
}
}
模型管理接口
你可以通过 API 来管理模型,比如查看已安装的模型列表。
- 列出已安装模型:
curl http://localhost:11434/api/tags - 查看正在运行的模型:
curl http://localhost:11434/api/ps
4.3、方式二:OpenAI 兼容 API
这个接口让你的 Ollama 可以无缝替代 OpenAI API,从而直接使用为 OpenAI 开发的各类客户端、SDK 和工具。
- 访问地址:
http://localhost:11434/v1。 - 使用方式:只需将原有 OpenAI 客户端的
base_url和api_key(任意值即可,如ollama)替换掉。例如,使用 Pythonopenai库:
python
from openai import OpenAI
# 只需修改这一处配置!
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # api_key 可以是任意非空字符串
)
response = client.chat.completions.create(
model="mdq100/Qwen3.5-flash:35b",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)4.4、场景化实践
在 Continue 中配置 OpenAI 兼容模式:如果你想让 Continue 通过 OpenAI 的方式调用本地模型,可以在 config.yaml 中这样配置:
yaml
models:
- name: Qwen3.5-Flash-35B
provider: openai
model: mdq100/Qwen3.5-flash:35b
apiBase: http://localhost:11434/v1
apiKey: ollamaContinue 会自动适配这个 OpenAI 风格的接口。
构建你自己的 AI 应用:
- 智能客服:可以用 Python Flask 框架封装一个
/chat接口,内部调用 Ollama API,实现完整的对话功能。 - 脚本自动化:在 Bash 或 Python 脚本中,临时调用模型处理文本,比如批量翻译文档、总结日志等。
- 工具调用 (Function Calling):Ollama 也支持让模型调用外部工具。例如,你可以给模型一个查询天气的功能,模型会根据对话内容判断何时使用它。
4.5、官方文档与资源
完整 API 参考:关于所有接口的详细参数(如 temperature, num_ctx 等),可以查阅官方文档:docs.ollama.com/api
多语言 SDK:
- 官方 Python 库:
pip install ollama - 社区 PHP SDK:
composer require lewenbraun/ollama-php-sdk
四、IDE 中使用本地大模型
在 VSCode 和 JetBrains IDE 中接入本地 Ollama 模型主要有以下几种方式:
- Continue 插件:最流行、功能全面的 AI 编程助手,支持代码补全、对话、编辑等
- 各 IDE 原生的 Ollama 集成:JetBrains 系直接支持,VSCode 通过 Copilot 侧边栏也能快速接入
- 其他插件备选:CodeGPT、DevoxxGenie、UltraCodeAI 等
1、VSCode-推荐 Continue 插件
Continue 是目前 VSCode 上最好用的本地 AI 编程助手,支持代码补全、侧边栏对话、代码编辑和解释等功能 。
第一步:确保 Ollama 模型已下载
先确认你已经在终端下载了之前推荐的那个模型:
shell
ollama pull qwen3.5-flash:35b或者你自建的模型名称,替换成你有的模型即可。(这一步还没配置的可以先看上面第二章节)
第二步:安装 Continue 插件
- 打开 VSCode,进入左侧扩展商店 (
Cmd + Shift + X) - 搜索 Continue(作者是 "continue.dev")
- 点击安装
第三步:配置 Continue 连接 Ollama
安装完成后:
- 点击左侧活动栏的 Continue 图标(对话气泡)
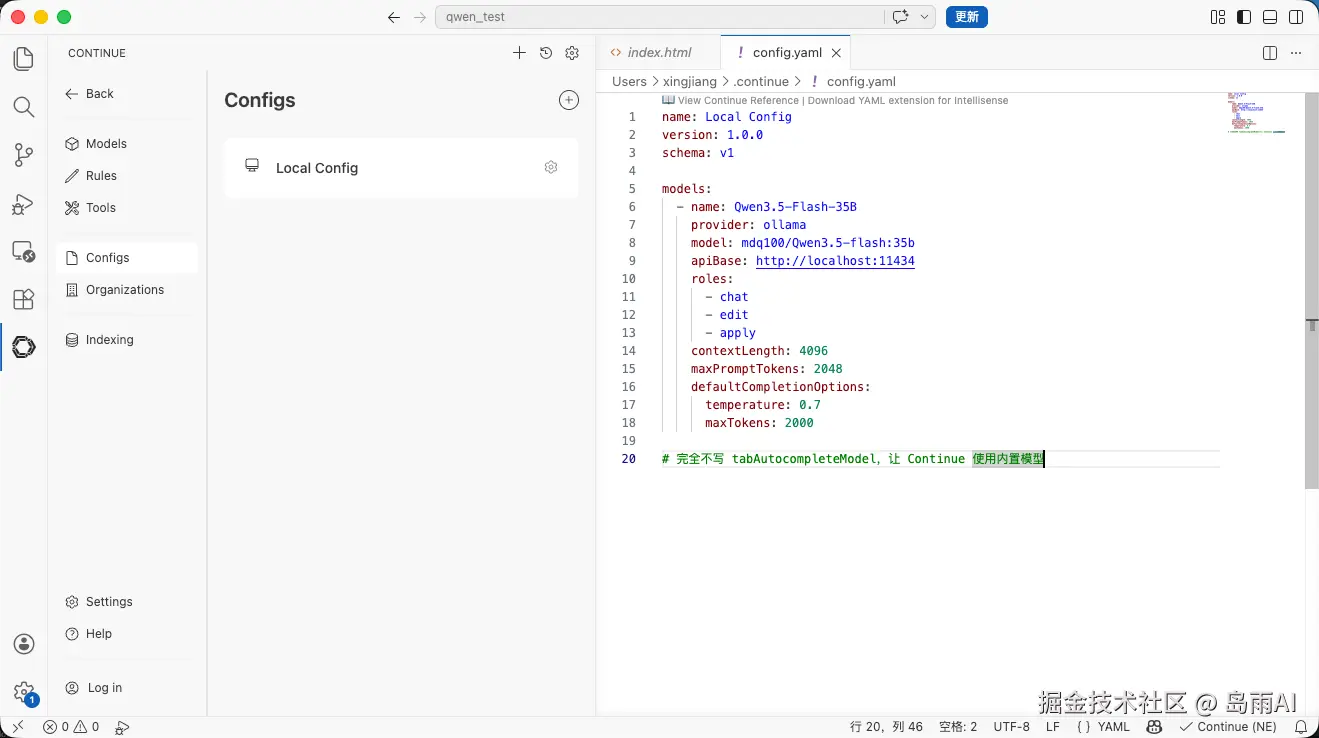
- 初次打开会提示配置,点击 「Open config.json」
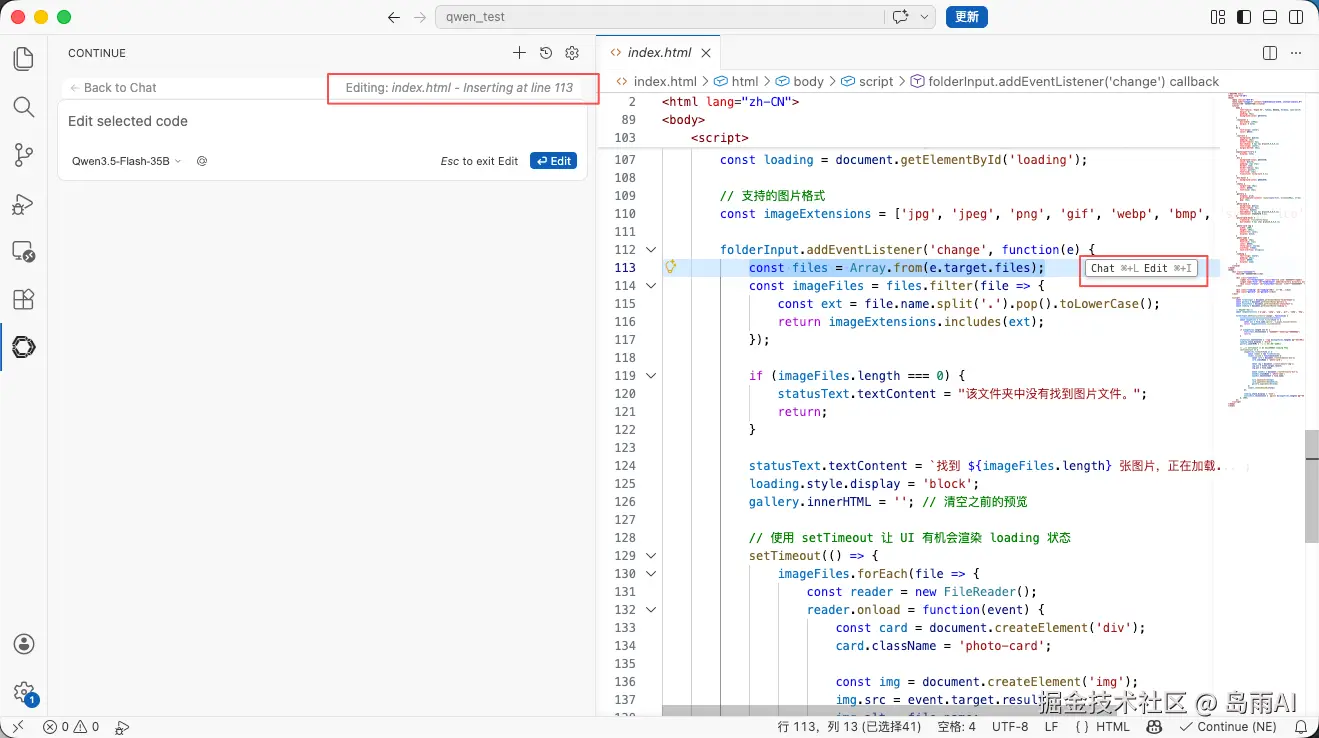
- 将配置修改为以下内容(将
qwen3.5-flash:35b换成你自己的模型名称):
yaml
name: Local Config
version: 1.0.0
schema: v1
models:
- name: Qwen3.5-Flash-35B
provider: ollama
model: mdq100/Qwen3.5-flash:35b
apiBase: http://localhost:11434
roles:
- chat
- edit
- apply
contextLength: 4096
maxPromptTokens: 2048
defaultCompletionOptions:
temperature: 0.7
maxTokens: 2000
# 完全不写 tabAutocompleteModel,让 Continue 使用内置模型需要注意的是:
1、Continue 配置文件里的 contextLength (上下文长度) 参数。这个值决定了模型一次能"记住"多少字符。云端模型可以轻松处理几万 tokens,但本地如果设置得太高,会瞬间撑爆你显卡的显存 (VRAM),导致模型被迫回退到极其缓慢的 CPU 上运行。可以先从 4096 开始尝试,如果效果不错,再根据你的显存大小逐步上调。
2、Continue 有一个内置的轻量级模型 continue-starcoder,专门用于自动补全,会在你首次使用时自动下载(约 500MB)。你只需要保留聊天配置,补全配置完全不用写。这样最终的效果就是:
- 聊天用你的 35B 大模型
- 自动补全用 Continue 内置的轻量模型(不占用 Ollama 资源)
- 响应快速(几十毫秒级别)
- 保存文件,重启 VSCode
第四步:开始使用
配置完成后:
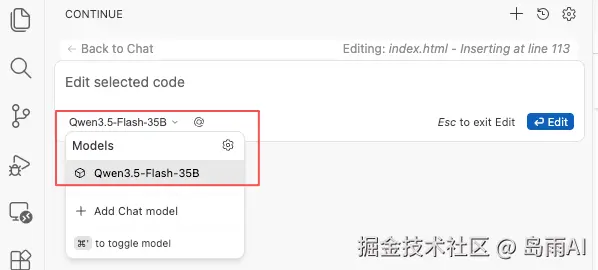
- 侧边栏对话:点击左侧 Continue 图标即可输入问题
- 内联编辑:选中代码后
Cmd + I唤出指令框 - 代码补全:打字时会自动提示补全建议(Tab键接受)
2、JetBrains IDE
方案一:官方原生 Ollama 集成(最推荐)
新版 IntelliJ IDEA 已经原生支持 Ollama,这是最简单干净的方式 。
注意使用前提:需要一个 JetBrains AI 订阅(这是一个付费服务),配置完成后还是会走本地的 Ollama 模型 。
具体步骤:
- 打开 IntelliJ / PyCharm
- 点击右侧边栏的 AI 助手图标(或通过
Tools → AI Assistant打开) - 在模型下拉菜单 → 点击「Set up Local Models」
- 在 Third Party AI Providers 中选择 Ollama
- 确认 Host URL 为
http://localhost:11434 - 点击 OK 后,在下拉菜单中选择你的模型(如
qwen3.5-flash:35b)
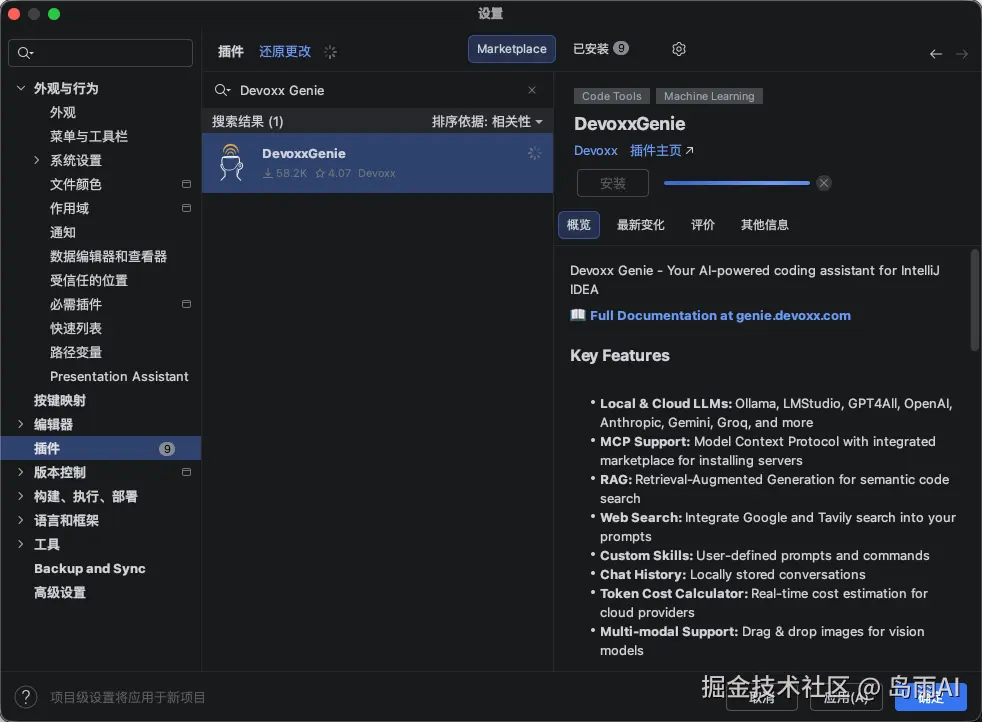
方案二:Devoxx Genie 插件(无需订阅、免费)
如果你没有 JetBrains AI 订阅,推荐使用 Devoxx Genie,这是一个 100% 免费的本地 LLM 插件 。
安装步骤:
- 打开
Settings → Plugins - 搜索
Devoxx Genie并安装(作者 devoxx) - 重启 IDE
配置步骤:
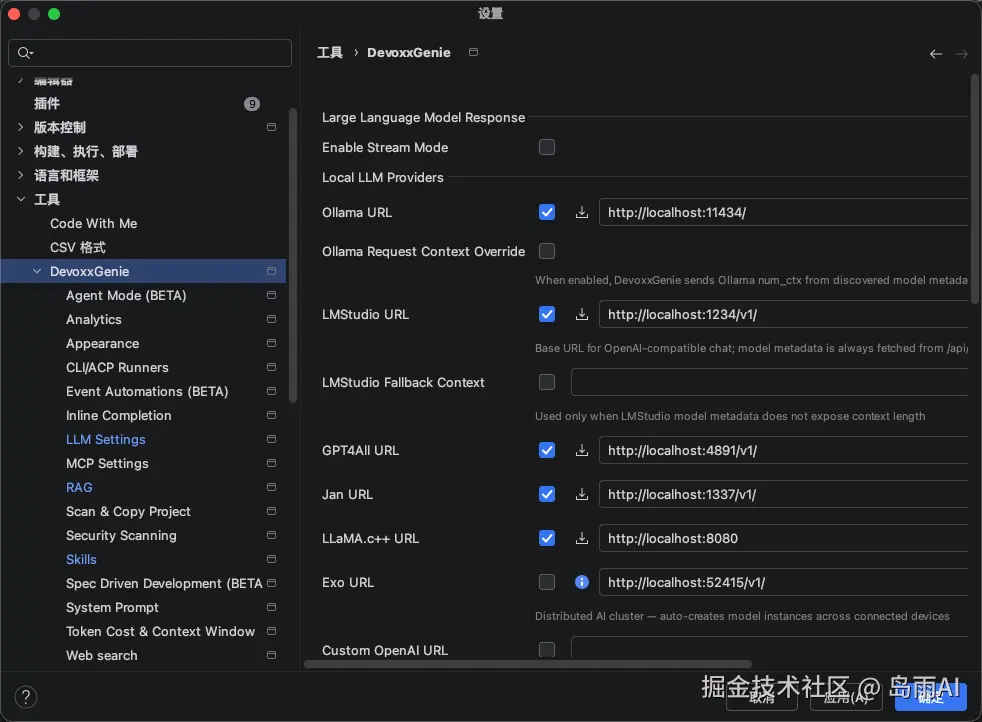
- 进入
Settings → Tools → DevoxxGenie - 在 LLM Provider 中选择 Ollama
- 填写 Base URL:
http://localhost:11434 - 在 Model Name 中输入你的模型名称:
qwen3.5-flash:35b
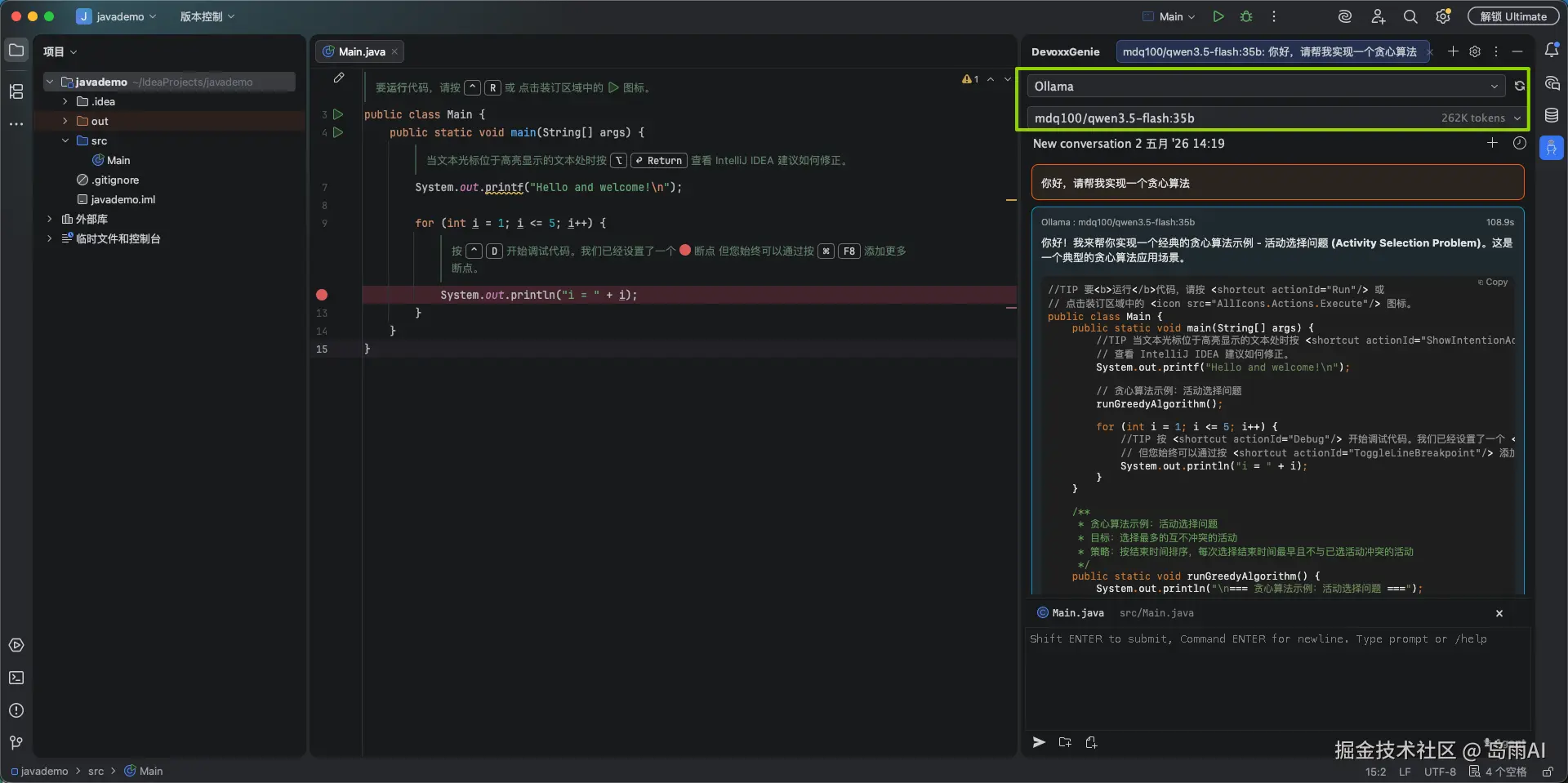
功能亮点:
- 支持
/test生成单元测试 - 支持
/review审查代码 - 支持
/explain解释代码 - 支持自定义快捷指令
方案三:CodeGPT 插件
另一个备选是 CodeGPT,同样支持 Ollama 本地模型,配置方式类似上方。
3、其他插件备选
| 插件名 | IDE | 特点 |
|---|---|---|
| Continue | VSCode | 功能最全面,体验最佳 |
| Devoxx Genie | JetBrains | 免费、功能完整,支持 RAG |
| UltraCodeAI | JetBrains | 较新,支持代码错误分析 |
| CodeGPT | JetBrains | 经典插件,稳定性好 |
| Copilot 侧边栏 | VSCode | 最简单的接入方式,但功能有限 |