在DeepResearch(上):方法论、OpenAI Deep Research、SurfSence、MindSearch、morphik、Firesearch里简单介绍过SearXNG。本文尝试深度实战与问题记录。
SearXNG
传统搜索引擎(如百度、Google)往往会追踪用户的搜索历史,收集个人数据,甚至分析用户行为。
SearXNG,作为开源(GitHub,29.3K Star,2.8K Fork)的元搜索引擎,通过聚合来自多个搜索引擎的结果,保持对用户的匿名保护,确保不会进行任何追踪或数据收集。官方文档。
功能特点
- 无追踪搜索:完全避免用户数据的追踪和记录,保障用户的隐私。所有搜索请求都匿名处理,不会收集个人信息;
- 支持多种搜索引擎:聚合来自超多个搜索引擎(如Bing、DuckDuckGo等)的结果,为用户提供更广泛的搜索选择和更精准的结果;
- 开源自托管跨和平台支持:作为开源项目,允许用户根据需求自定义功能并自行托管。通过Docker部署,用户可以轻松在自己的服务器上运行,完全掌控数据和配置;
- 无广告干扰:提供干净、无广告的搜索体验,避免了传统搜索引擎中常见的广告干扰,让用户专注于搜索内容;
- 高度可定制:用户可以根据个人需求定制搜索引擎的配置,选择希望聚合的搜索源、设置搜索偏好等;
- 支持多语言:提供多语言支持,用户可以根据自己的语言偏好设置搜索界面,提供更便捷的使用体验;
- 过滤功能强大:提供灵活的过滤功能,用户可自定义过滤规则,屏蔽特定类型的结果,提供更加精准的搜索体验。
实战
支持多种安装部署方式:
- Docker:
searxng/searxng:latest - Docker Compose
本文基于macOS环境(当然也支持Windows和Linux),以Docker Compose方式部署。
此处踩过耗时近2小时血泪坑,看到此文的朋友们一定要引以为戒。
鬼使神差,没有想到直接打开GitHub项目主页,而是在2026年,依旧使用Bing/Google并搜索SearXNG docker compose关键词,谁曾想按照排名打开的2篇CN blogs(即博客园)文章里给出的配置文件都有问题!!!
各种报错问题抛给GPT(包括DeepSeek、Qwen和ChatGPT),始终没有解决:我还不信邪(犟脾气认死理),修改配置文件,重试,还是有问题,浪费将近2小时,终于放弃。
博客园的没落和破败不是没有原因的。
其实,直接使用官方文件:
yaml
name: searxng
services:
core:
container_name: searxng-core
image: docker.io/searxng/searxng:${SEARXNG_VERSION:-latest}
restart: always
ports:
- ${SEARXNG_HOST:+${SEARXNG_HOST}:}${SEARXNG_PORT:-8080}:${SEARXNG_PORT:-8080}
env_file: ./.env
volumes:
- ./core-config/:/etc/searxng/:Z
- core-data:/var/cache/searxng/
valkey:
container_name: searxng-valkey
image: docker.io/valkey/valkey:9-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: always
volumes:
- valkey-data:/data/
volumes:
core-data:
valkey-data:2分钟部署成功。自动在本地新增如下文件(夹)
浏览器打开http://localhost:8080,页面如下
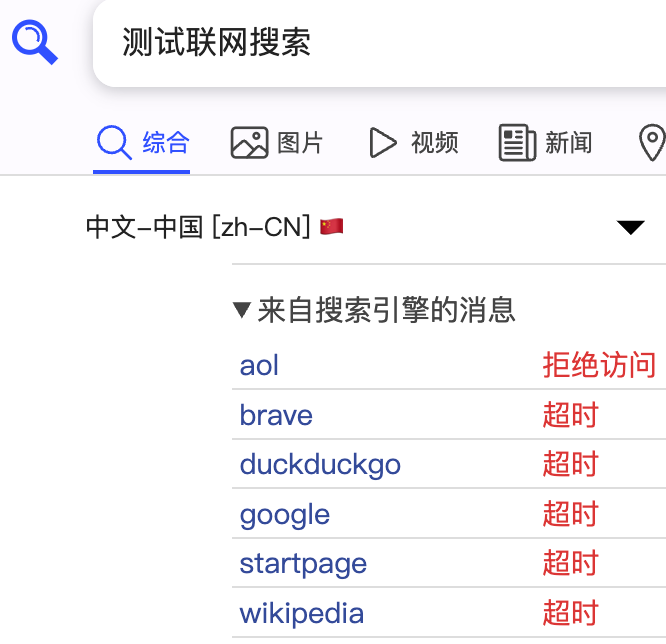
一定一定要确保SearXNG服务所在机器有网络服务能力,否则页面打开是这样的
其次,如果本机能访问网络,但搜索依旧超时,则需配置【首选项】。
具体步骤:首选项-搜索引擎-综合-禁用所有
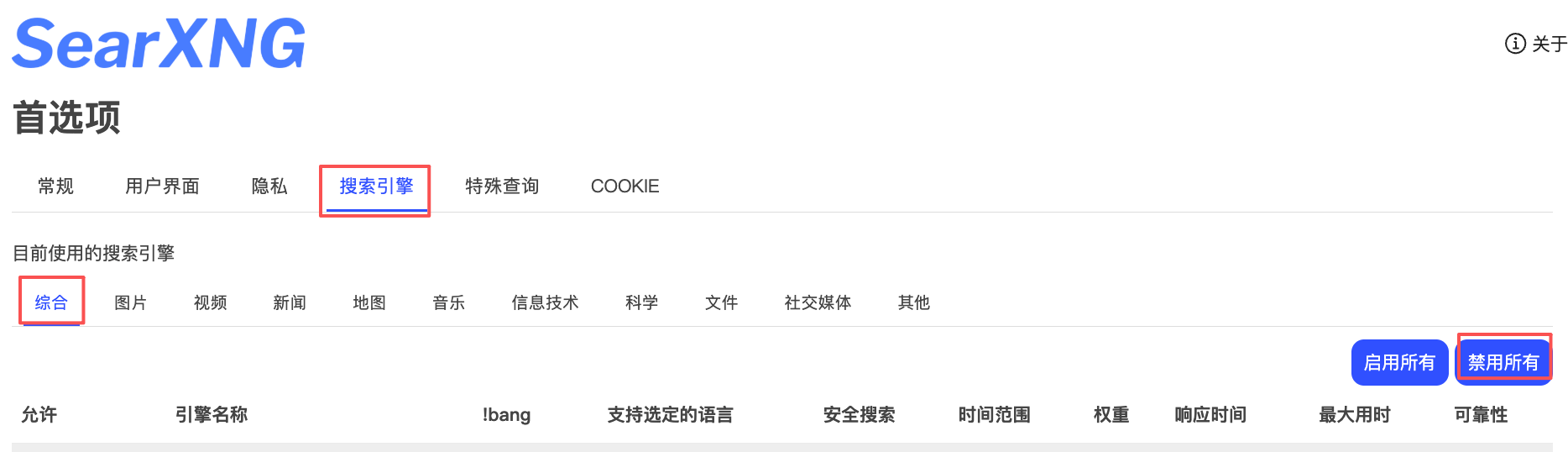
然后开启sougou,点击保存

然后再次测试搜索功能,正常返回。
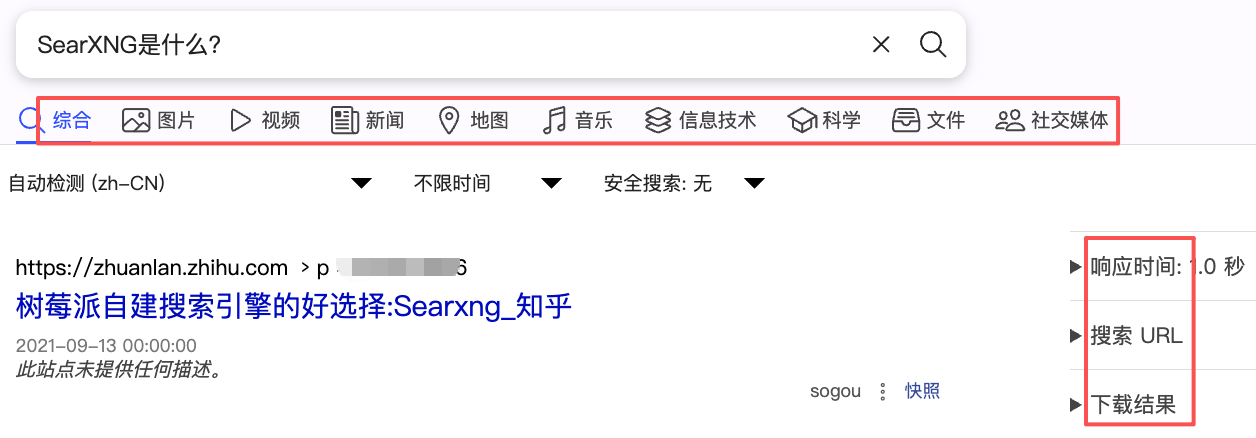
如上截图所示,几点解读:
- 支持细粒度搜索管理。搜索场景分类为:综合(默认)、图片、视频、新闻、地图、音乐、IT、科学、文件、社媒、其他。
- 搜索结果支持多语言、时间和安全设置,前两者大家都不陌生,安全搜索分3个等级(严格、中等、无),适用于过滤有害内容
- 搜索指标:响应时间、搜索URL、下载结果(JSON)。其中URL即下面将提到的接口测试。
再回过头看看首选项:常规、UI、隐私、搜索引擎、特殊查询、cookie,基本上见名知意。
搜索引擎支持非常非常全,很多完全没听说过:bing、brave、duckduckgo、google、karmasearch、karmasearch videos、mojeek、presearch、presearch videos、qwant、startpage、wiby、yahoo、seznam(CZ)、naver(KO)、wikimedia(包括wikibooks、wikiquote、wikisource、wikispecies、wikiversity、wikivoyage)、aol、ask、boardreader、crowdview、ddg definitions、encyclosearch、fynd、gmx、mwmbl、searchmysite、tineye、wikidata、wikipedia、wolframalpha、yacy、yandex、 yep、bpb(DE)、 tagesschau(DE)、wikimini(FR)、360search(ZH)、baidu(ZH)、quark(ZH)、sogou(ZH)。
API
未联网或未配置情况下,Postman请求是这样的:
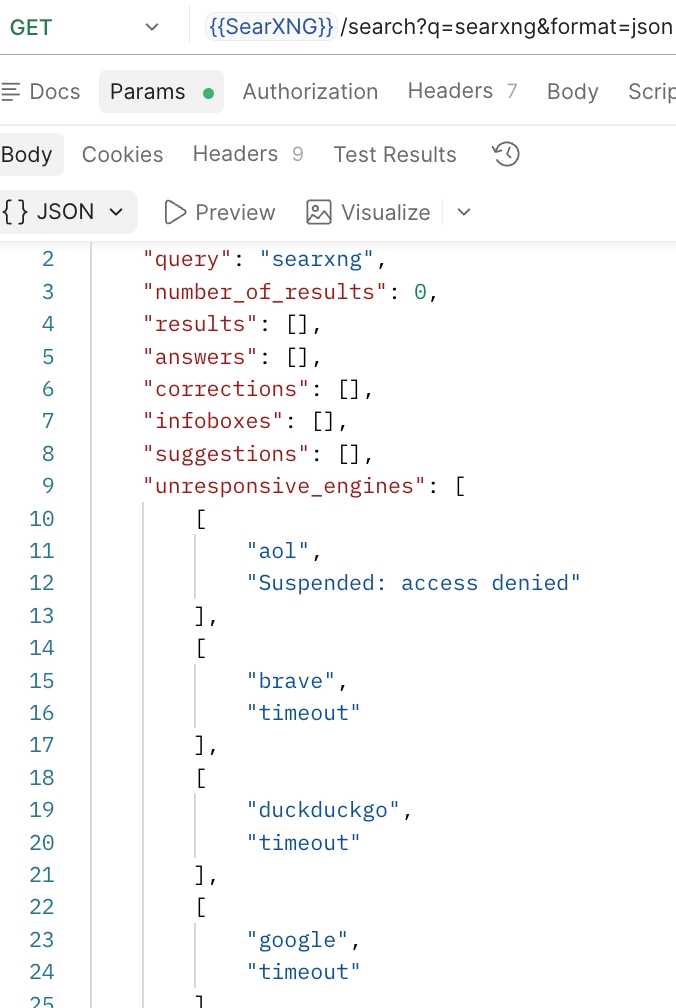
参数:
q:搜索关键词,唯一一个不可为空的参数format:默认是html,支持jsonlanguage:默认auto,即自动检测q使用的语言,并优先返回该语言内容time_range:时间范围,默认不限时间safesearch:安全搜索,默认0,即无,不使用安全搜索categories:分类,默认general即综合
问题
API
如上图琐事,已经将搜索引擎全局禁用后,仅开启sougou,使用Postman测试,依旧超时,截图类似上面截图。
解决方法:
- 【可能是】需要调整
settings.yaml文件,并重启服务。怀疑是浏览器上看到的首选项只能控制页面搜索,无法控制API搜索。 - 打开本地代理,让搜索走
brave等搜索引擎。
403
报错截图
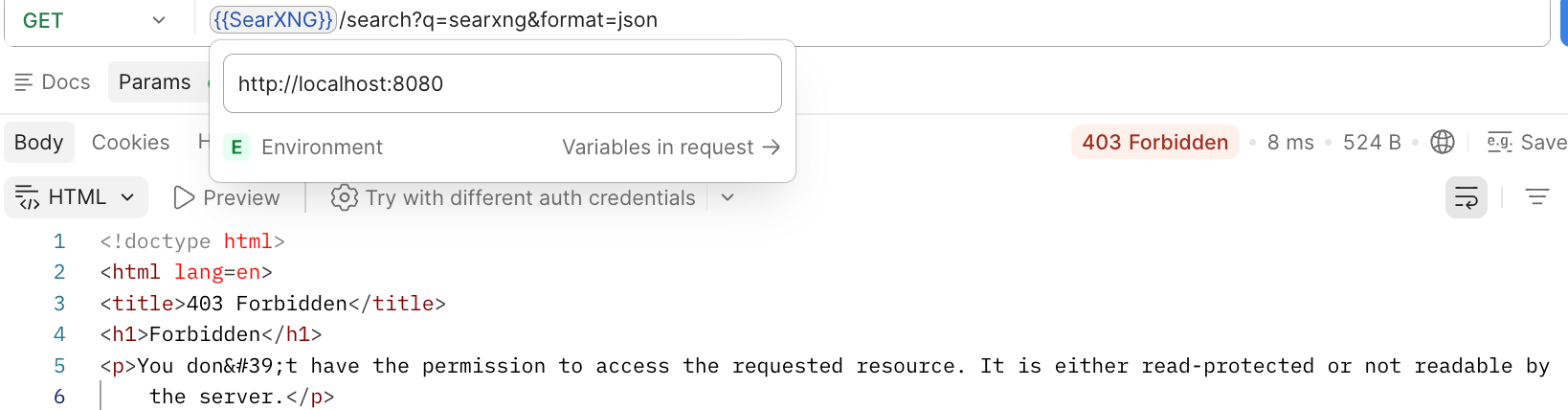
原因解读:SearXNG出于安全考虑,默认禁用JSON格式的API访问。
解决方法:在自动下载的settings.yml文件里对search.formats配置项增加json,仅需重启searxng-core服务:docker compose restart searxng-core。
Invalid character
在浏览器或Postman搜索latest version of java都能成功返回,但Java代码里请求search接口报错:
ERROR - 运行时异常:Invalid character ' ' for QUERY_PARAM in "latest version of java"
java.lang.IllegalArgumentException: Invalid character ' ' for QUERY_PARAM in "latest version of java"
at org.springframework.web.util.HierarchicalUriComponents.verifyUriComponent(HierarchicalUriComponents.java:422)基于WebClient实现时遇到上述问题,解决方法

Degoog
开源(GitHub)功能强大且高度可定制搜索聚合引擎,它可以从多个搜索引擎获取结果并在一个界面中展示。它支持自定义搜索引擎、bang 命令插件和 slot 插件,旨在为用户提供更私密、更个性化的搜索体验。官方文档。
特点
- 多引擎聚合:同时查询多个搜索引擎,将结果整合显示,避免单一引擎的偏见和限制
- 插件系统:支持 bang 命令插件和 slot 插件,可扩展搜索功能和界面布局
- 隐私保护:作为本地部署的搜索引擎代理,避免搜索历史被追踪和收集
- 高度可定制:支持自定义搜索引擎、主题、别名等配置,满足个性化需求
应用场景 - 隐私搜索:注重隐私的用户可以使用 Degoog 替代传统搜索引擎,避免搜索行为被追踪
- 研究工作:研究人员需要从多个搜索引擎获取信息,Degoog 可以一站式展示结果
- 开发测试:开发人员可以快速测试不同搜索引擎的 API 和结果格式
- 家庭网络:在家庭服务器上部署,为全家提供统一的隐私搜索入口
- 企业内网:在企业内部部署,作为内部知识搜索的聚合工具
实战
提供多种本地部署方式
- 基于Docker:
bash
docker run -d \
--name=degoog \
--user 1000:1000 \
--restart=unless-stopped \
-p 4444:4444 \
-v $(pwd)/data:/app/data \
ghcr.io/fccview/degoog:latest- 基于
docker-compose.yml:
yaml
services:
degoog:
image: ghcr.io/fccview/degoog:latest
container_name: degoog
restart: unless-stopped
user: "1000:1000"
ports:
- "4444:4444"
volumes:
- ./data:/app/data浏览器打开http://localhost:4444,开始体验。
Settings --> General ,启用 Proxy 并设置代理服务的地址,