
3742
如果是普通的方法的话,对于每个位置,都可能由其所位于的左侧或上侧到达,应当取他们的最大值,这是从分数角度;
设dpij为处于i,j位置时的分数
即dpij=max(dpi-1j,dpij-1)+sij
但是如何限制花费?
就是即在限制花费的情况下,又要保证分数最大?
如果直接套用原来的动态规划,那只能得到其中一个最优的,无法保证全最优
一种思路是先得到所有花费可行的,然后在其中找分数最大的;
最直接的是,dfs+剪枝
向右走的次数i,向下走的次数j,
dfs(i,j,s,c)
令c+=cij
判断c是否大于k,如果是的话,就continue兼职,直接return
不然就说明这步是合法的,记s+=sij
判断当前位置是否为终点,如果是就记录s的结果,res=max(s,res)
尝试向右走,
判断i+1是否大于m-1,如果是的话,说明已经到最右侧了,就不能走了,continue
不然就是可以向右走,为dfs(i+1,j,s,c)
尝试向下走
class Solution {
public:
int res=-1,K,m,n;
vector<vector<int>>G;
vector<vector
void dfs(int i,int j,int s,int c){
//int flag=grid[i][j],ds,dc;
int flag=G[i][j],ds,dc;
if(flag==0){ds=0,dc=0;}
else if(flag==1){ds=1,dc=1;}
else{ds=2,dc=1;}
//cout<<"i: "<<i<<" j: "<<j<<endl;
if(c+dc>K){return;}
//cout<<"i: "<<i<<" j: "<<j<<endl;
if((i==m-1)&&(j==n-1)){res=max(res,s+ds);return;}
if(i+1<=m-1){dfs(i+1,j,s+ds,c+dc);}
if(j+1<=n-1){dfs(i,j+1,s+ds,c+dc);}
}
int maxPathScore(vector<vector<int>>& grid, int k) {
K=k;
G=grid;
m=grid.size(),n=grid[0].size();
//cout<<"m: "<<m<<" n: "<<n<<endl;
dfs(0,0,0,0);
return res;
}
};可行,但是超时了;
说要实现记忆化,但是缓存什么呢?就是应该保存什么信息呢?
可是到当前位置的花费cost可以是不固定的,会随着之前选择的路径的不同而不同,即可能有多个值,那又该选择哪个cost来进行保存呢?
所以要用一个三维数组,即在原来位置信息的基础上,再加一个cost或者score
如果是cost,就是去选这个状态下最高的score,那么dp的意义就是score
那么向下走为dpijc=dpi-1jc+c\[ij]+sij
向右走为dpijc=dpij-1c+c\[ij]+sij
取这二者的最大值
最终,位置i和j是固定的,就是在c会有多个值,然后每个c的取值,都是在这个c下的最高score
但是,对于第三维c,如何去保存这个信息,如何去记录它?如果就是用数组的话,i和j的位置信息是连续的,就是数组上都是连续有值的,但是c不一定,可能是离散,就应该从0遍历到k,在其中找最大值
对于c的最大取值,就是向下走m次,向右走n次,都花费1,即m+n
如果使用vector来构建三维数组,初始化代码怎么写?就是锚定其一二三维的大小
对于确定的位置i和j可以使用for循环遍历,而对于c状态的不确定性,就没办法用for来遍历,还是得用dfs
由于在dfs当中要提前判断,所以定义dpijc为以c的代价到了i和j的位置,值表示此时记录的最高score,还没计算(i,j)地块带来的影响
不行啊,这样的话dp赋值就说不清了,就应该是算上i,j地块影响后的值,这样dp才能赋值
如果此时dp
就是存在一个矛盾,如果要对下一步的dp进行赋值,就必须得让当前的DP有值,而一开始的时候,DP都是没值的,要填表
具体说就是,如果dpijc表示处于i,j位置时的代价为c,还没有算上i,j位置的影响,那么要用上缓存,就应该判断dpijc是否有值,如果有值,就说明这个参数的dfs之前来过;同样,如果没值,那么dpijc就应该在此处被填值,但是这又和这个dfs的含义不同,因为dfs是要在这个参数下考虑该地块i,j的影响继续向下dfs赋值,所以赋值的应该是(i+1,j)或(i,j+1)等,如果就是要给(i,j)赋值,那么dpijc就表示已经算上了(i,j)地块的影响,这又和一开始dp的定义矛盾
如果定义dpijc为,以代价c到达i,j位置时所能达到的最高分数,那么从起点到终点,问题复杂度是越来越大的,即起点是最简子问题;
定义dfs(i,j,c)返回值为,从i,j出发,剩余K-C的预算时,所能获取的最大分数
ai说就应该让dpijc和dfs(i,jc)的参数对齐,保持同一定义意义,那么就假设i,j,c中的c和s是算上i,j影响后的数值
这样dpijc表示到达i,j时,付出代价为c后所达到的最高分数
如何定义dfs以辅助dp的赋值?或许并不需要

dfs(i,j,c,s)
先判断c是否超过k,如果超过就直接返回-1
不然说明此时的i,j,c是合法的
看此时的dpijc是否填值了
是的话直接返回
不然,就

这里关键就是dpijc填完值后,还可以继续被更新,被填值,不是说填完一次后就没事了
加了记忆化后
class Solution {
public:
int res=-1,K,m,n;
vector<vector<vector<int>>>dp;
vector<vector<int>>G;
// vector<vector
void dfs(int i,int j,int s,int c){
//if(dp[i][j][c]){return;}
//int flag=grid[i][j],ds,dc;
if(c>K){return;}
if(dp[i][j][c]>=s){return;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<" s: "<<s<<endl;
dp[i][j][c]=s;
// int flag=G[i][j],ds,dc;
// if(flag==0){ds=0,dc=0;}
// else if(flag==1){ds=1,dc=1;}
// else{ds=2,dc=1;}
//cout<<"i: "<<i<<" j: "<<j<<endl;
// if(c+dc>K){return;}
//cout<<"i: "<<i<<" j: "<<j<<endl;
//if((i==m-1)&&(j==n-1)){res=max(res,s+ds);return;}
int flag,dc,ds;
if(i+1<=m-1){
flag=G[i+1][j],dc=flag?1:0,ds=flag;
dfs(i+1,j,s+ds,c+dc);
}
if(j+1<=n-1){
flag=G[i][j+1],dc=flag?1:0,ds=flag;
dfs(i,j+1,s+ds,c+dc);
}
}
int maxPathScore(vector<vector<int>>& grid, int k) {
m=grid.size(),n=grid[0].size();
G=grid;
K=k;
dp.resize(m);
for(int i=0;i<m;i++){
dp[i].resize(n);
for(int j=0;j<n;j++){
dp[i][j].resize(k+1,-1);
}
}
dfs(0,0,0,0);
for(int i=0;i<=k;i++){
//cout<<"c: "<<i<<" s: "<<dp[m-1][n-1][i]<<endl;
res=max(dp[m-1][n-1][i],res);
}
return res;
}
};
依然超时
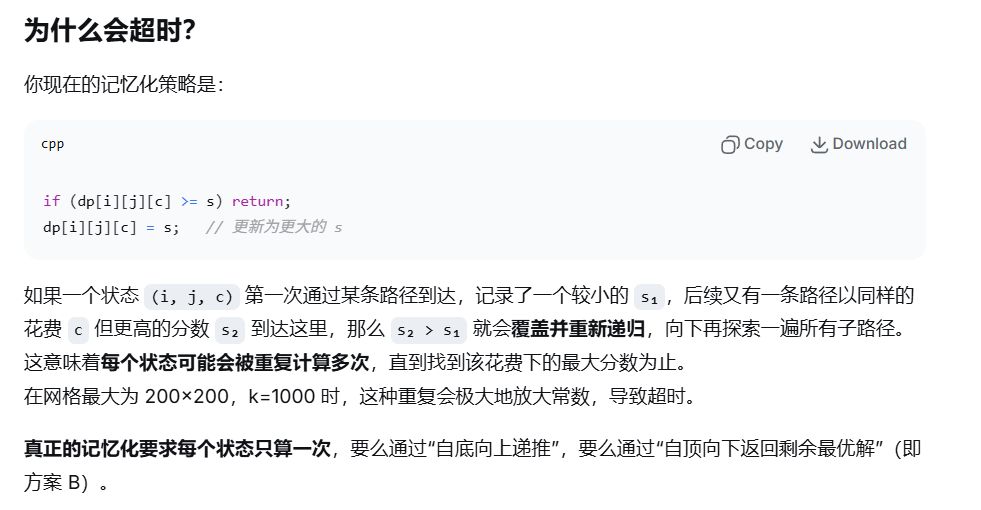
这个就是说,对于前面的(i1,j1,c1)状态,先到的时候,先计算,以此为基点,往下算完一次遍历树;后面又有新的基点,到之前遍历过的节点时,如果s比不过还好,但如果超过了,就会造成覆盖,就会重新、再次遍历一次;这对于DFS遍历的记忆缓存化,是无法避免的
采用for循环的方式
保存c状态,就是在保存一种当前不是最大值,但由此c状态可能达到全局最大值的可能性
采用递推DP的方式,三层循环就是在遍历每种可能达到的状态
而当前这个状态是否可达,是由之前的for循环所确定的
即状态的for循环方向至关重要,必须满足从问题规模从小到大的方向,并在小问题规模时,递推下一步可达的所有未来
即对于每个状态i,j,c,都必须保证其上方和左方都已被遍历,唯一确定了此时保留的最优状态集合
这样,从左到右,从上到下的顺序是可以满足的
定义dpijc为i,j,c状态下所能达到的最大分数,已考虑i,j地块的影响
在每个状态中,
先判断是否可达,即dp是否等于-1,如果是负一,说明其左侧和上侧都不可达该状态,直接过滤掉
有向下和向右两种状态转移方式
对于向下,给此状态能达到的它赋值,即dpi+1jc+dc=max(dpi+1jc+dc,dpijc+ds)
对于向右,dpij+1c+dc=max(dpij+1c+dc,dpijc+ds)
可以考虑初始化i=1;j=1的两种情况,然后for遍历时直接从1,1开始,避免处于边界时,对边界情况的检查
class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
vector<vector<vector<int>>>dp(m,vector<vector<int>>(n,vector<int>(k+2,-1)));
dp[0][0][0]=0;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
for(int c=0;c<=k;c++){
if(dp[i][j][c]==-1){continue;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
int flag,dc,ds;
if(i+1<=m-1){
flag=grid[i+1][j],ds=flag,dc=flag?1:0;
//if(c+dc>k){continue;}
dp[i+1][j][c+dc]=max(dp[i+1][j][c+dc],dp[i][j][c]+ds);
}
if(j+1<=n-1){
flag=grid[i][j+1],ds=flag,dc=flag?1:0;
//if(c+dc>k){continue;}
dp[i][j+1][c+dc]=max(dp[i][j+1][c+dc],dp[i][j][c]+ds);
}
}
}
}
int res=-1;
for(int c=0;c<=k;c++){
//cout<<"c: "<<c<<" dp: "<<dp[m-1][n-1][c]<<endl;
res=max(res,dp[m-1][n-1][c]);
}
return res;
}
};在状态转移当中,对于k,可能出现越界情况,对于开到k+1来说,但因为对于C状态的遍历是直到K,所以C最大取值是K+1,那么处理方式,一种就是把数组开到K+2,允许状态合法,但是不遍历;其二,就是直接进行判断,直接不允许对K+1赋值
class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
vector<vector<vector<int>>>dp(m,vector<vector<int>>(n,vector<int>(k+1,-1)));
dp[0][0][0]=0;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
for(int c=0;c<=k;c++){
if(dp[i][j][c]==-1){continue;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
int flag,dc,ds;
if(i+1<=m-1){
flag=grid[i+1][j],ds=flag,dc=flag?1:0;
if(c+dc<=k){dp[i+1][j][c+dc]=max(dp[i+1][j][c+dc],dp[i][j][c]+ds);}
}
if(j+1<=n-1){
flag=grid[i][j+1],ds=flag,dc=flag?1:0;
if(c+dc<=k){dp[i][j+1][c+dc]=max(dp[i][j+1][c+dc],dp[i][j][c]+ds);}
}
}
}
}
int res=-1;
for(int c=0;c<=k;c++){
//cout<<"c: "<<c<<" dp: "<<dp[m-1][n-1][c]<<endl;
res=max(res,dp[m-1][n-1][c]);
}
return res;
}
};对每个状态的确定,所需要的只是其所对应的上方和左方数据,如果已经确定了,那么就不再需要它们了
所以考虑滚动数组,即只保存当前要确定的位置i,j的上一行和左侧数据
先一直向右,确定出第一行,或者可以叫这步为初始化;
对于第二行及以后的处理
cur表示当前正在填表的一行,prev表示其上一行
那么在从左到右的过程中,可以保证每个位置的左侧和右侧都是被填的
其上方就是prevjc
其左方就是curj-1c
class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
//vector<vector<vector<int>>>dp(m,vector<vector<int>>(n,vector<int>(k+1,-1)));
//vector<vector<int>>prev(n,vector<int>(k+1,-1)),cur(n,vector<int>(k+1,-1));
//vector<vector<int>>prev(n),cur(n);
vector<unordered_map<int,int>>prev(n),cur(n);
//dp[0][0][0]=0;
//prev[0].push_back(0);
prev[0][0]=0;
int flag,dc,ds,i=0;
// for(int j=0;j<n;j++){
// for(int c=0;c<=k;c++){
// if(prev[j][c]==-1){continue;}
// if(j+1<=n-1){
// flag=grid[0][j],dc=flag?1:0,ds=flag;
// if(c+dc<=k){
// prev[j+1][c+dc]=prev[j][c]+ds;
// }
// }
// }
// }
// for(int j=0;j<n;j++){
// for(int ci=0;ci<prev[j].size();ci++){
// if(j+1<=n-1){
// flag=grid[0][j],dc=flag?1:0,ds=flag;
// if(prev[j][ci]+dc<=k){
// //prev[j+1][c+dc]=prev[j][c]+ds;
// prev[j+1].push_back(prev[j][ci]+dc);
// }
// }
// }
// }
for(int j=0;j<n;j++){
for(auto iter:prev[j]){
if(j+1<=n-1){
flag=grid[i][j],dc=flag?1:0,ds=flag;
if(iter.first()+dc<=k){
prev[j+1][iter.first()+dc]=ds+iter.second();
}
}
if(i+1<=m-1){
flag=grid[i][j],dc=flag?1:0,ds=flag;
if(iter.first()+dc<=k){
cur[j][iter.first()+dc]=ds+iter.second();
}
}
}
}
i++;
for(;i<m;i++){
// for(auto iter:prev[0]){
// flag=grid[i][0],dc=flag?1:0,ds=flag;
// if(iter.first()+dc<=k){cur[0][iter.first()+dc]=ds+iter.second();
// }
vector<unordered_map<int,int>>tmp;
for(int j=0;j<=n-1;j++){
for(auto iter:cur[j]){
if(j+1<=n-1){
flag=grid[i][j],dc=flag?1:0,ds=flag;
if(iter.first()+dc<=k){
prev[j+1][iter.first()+dc]=ds+iter.second();
}
}
if(i+1<=m-1){
flag=grid[i][j],dc=flag?1:0,ds=flag;
if(iter.first()+dc<=k){
prev[j][iter.first()+dc]=ds+iter.second();
}
}
}
}
tmp=cur;
cur=prev;
prev=cur;
}
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
for(int c=0;c<=k;c++){
if(dp[i][j][c]==-1){continue;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
if(i+1<=m-1){
flag=grid[i+1][j],ds=flag,dc=flag?1:0;
if(c+dc<=k){dp[i+1][j][c+dc]=max(dp[i+1][j][c+dc],dp[i][j][c]+ds);}
}
if(j+1<=n-1){
flag=grid[i][j+1],ds=flag,dc=flag?1:0;
if(c+dc<=k){dp[i][j+1][c+dc]=max(dp[i][j+1][c+dc],dp[i][j][c]+ds);}
}
}
}
}
int res=-1;
for(int c=0;c<=k;c++){
//cout<<"c: "<<c<<" dp: "<<dp[m-1][n-1][c]<<endl;
res=max(res,dp[m-1][n-1][c]);
}
return res;
}
};
class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
//vector<vector<vector<int>>>dp(m,vector<vector<int>>(n,vector<int>(k+1,-1)));
//vector<vector<int>>prev(n,vector<int>(k+1,-1)),cur(n,vector<int>(k+1,-1));
//vector<vector<int>>prev(n),cur(n);
//vector<unordered_map<int,int>>prev(n),cur(n);
vector<unordered_map<int,int>>cur(n);
//dp[0][0][0]=0;
//prev[0].push_back(0);
//prev[0][0]=0;
cur[0][0]=0;
int flag,dc,ds,i=0;
//1.第一行初始化,是否真的需要摘出来?
// for(int j=0;j<n;j++){
// for(int c=0;c<=k;c++){
// if(prev[j][c]==-1){continue;}
// if(j+1<=n-1){
// flag=grid[i][j+1],dc=flag?1:0,ds=flag;
// if(c+dc<=k){
// prev[j+1][c+dc]=prev[j][c]+ds;
// }
// }
// if(i+1<=m-1){
// flag=grid[i+1][j],dc=flag?1:0,ds=flag;
// if(c+dc<=k){
// cur[j][c+dc]=ds+prev[j][c];
// }
// }
// }
// }
// for(int j=0;j<n;j++){
// for(int ci=0;ci<prev[j].size();ci++){
// if(j+1<=n-1){
// flag=grid[0][j],dc=flag?1:0,ds=flag;
// if(prev[j][ci]+dc<=k){
// //prev[j+1][c+dc]=prev[j][c]+ds;
// prev[j+1].push_back(prev[j][ci]+dc);
// }
// }
// }
// }
// for(int j=0;j<n;j++){
// for(auto iter:prev[j]){
// if(j+1<=n-1){
// flag=grid[i][j],dc=flag?1:0,ds=flag;
// if(iter.first()+dc<=k){
// prev[j+1][iter.first()+dc]=ds+iter.second();
// }
// }
// if(i+1<=m-1){
// flag=grid[i][j],dc=flag?1:0,ds=flag;
// if(iter.first()+dc<=k){
// cur[j][iter.first()+dc]=ds+iter.second();
// }
// }
// }
// }
//i++;
//2.后续迭代,如何处理prev与cur的转换
for(;i<m;i++){
vector<unordered_map<int,int>>next(n);
//vector<vector<int>>next(n,vector<int>(k+1,-1));
for(int j=0;j<=n-1;j++){
// for(auto iter:cur[j]){
// if(j+1<=n-1){
// flag=grid[i][j],dc=flag?1:0,ds=flag;
// if(iter.first()+dc<=k){
// prev[j+1][iter.first()+dc]=ds+iter.second();
// }
// }
// if(i+1<=m-1){
// flag=grid[i][j],dc=flag?1:0,ds=flag;
// if(iter.first()+dc<=k){
// prev[j][iter.first()+dc]=ds+iter.second();
// }
// }
// }
// for(int c=0;c<=k;c++){
// if(cur[j][c]==-1){continue;}
// //cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
// if(j+1<=n-1){
// flag=grid[i][j+1],dc=flag?1:0,ds=flag;
// if(c+dc<=k){
// cur[j+1][c+dc]=max(ds+cur[j][c],cur[j+1][c+dc]);
// }
// }
// if(i+1<=m-1){
// flag=grid[i+1][j],dc=flag?1:0,ds=flag;
// if(c+dc<=k){
// next[j][c+dc]=max(next[j][c+dc],ds+cur[j][c]);
// }
// }
// }
for(auto iter:cur[j]){
if(j+1<=n-1){
flag=grid[i][j+1],dc=flag?1:0,ds=flag;
if(iter.first+dc<=k){
cur[j+1][iter.first+dc]=max(cur[j+1][iter.first+dc],iter.second+ds);
}
}
if(i+1<=m-1){
flag=grid[i+1][j],dc=flag?1:0,ds=flag;
if(iter.first+dc<=k){
next[j][iter.first+dc]=max(next[j][iter.first+dc],iter.second+ds);
}
}
}
}
// tmp=cur;
// cur=prev;
// prev=cur;
//prev=cur;
if(i!=m-1)cur=next;
}
// for(int i=1;i<m;i++){
// for(int j=1;j<n;j++){
// for(int c=0;c<=k;c++){
// if(dp[i][j][c]==-1){continue;}
// //cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
// if(i+1<=m-1){
// flag=grid[i+1][j],ds=flag,dc=flag?1:0;
// if(c+dc<=k){dp[i+1][j][c+dc]=max(dp[i+1][j][c+dc],dp[i][j][c]+ds);}
// }
// if(j+1<=n-1){
// flag=grid[i][j+1],ds=flag,dc=flag?1:0;
// if(c+dc<=k){dp[i][j+1][c+dc]=max(dp[i][j+1][c+dc],dp[i][j][c]+ds);}
// }
// }
// }
// }
int res=-1;
// for(int c=0;c<=k;c++){
// //cout<<"c: "<<c<<" dp: "<<dp[m-1][n-1][c]<<endl;
// //cout<<"c: "<<c<<" dp: "<<cur[n-1][c]<<endl;
// res=max(res,cur[n-1][c]);
// }
for(auto iter:cur[n-1]){
//cout<<"c: "<<c<<" dp: "<<cur[n-1][c]<<endl;
res=max(res,iter.second);
}
return res;
}
};实现了滚动数组DP,将三维数组优化到二维数组
在此基础上,进一步以哈希表优化了对C的访问;
但是哈希表取代vector后,性能非但没有更好,反而还超时了部分样例


即哈希表优化,适用于稀疏数组;但这个题目背景下,c的值限制在(0,min(m+n,k))中,很稠密,所以用哈希表反而会加重时间、空间复杂度

class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
vector<vector<int>>cur(n,vector<int>(k+1,-1));
cur[0][0]=0;
int flag,dc,ds,i=0;
for(;i<m;i++){
vector<vector<int>>next(n,vector<int>(k+1,-1));
for(int j=0;j<=n-1;j++){
for(int c=0;c<=k;c++){
if(cur[j][c]==-1){continue;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
if(j+1<=n-1){
flag=grid[i][j+1],dc=flag?1:0,ds=flag;
if(c+dc<=k){
cur[j+1][c+dc]=max(ds+cur[j][c],cur[j+1][c+dc]);
}
}
if(i+1<=m-1){
flag=grid[i+1][j],dc=flag?1:0,ds=flag;
if(c+dc<=k){
next[j][c+dc]=max(next[j][c+dc],ds+cur[j][c]);
}
}
}
}
if(i!=m-1)cur=next;
}
int res=-1;
for(int c=0;c<=k;c++){
res=max(res,cur[n-1][c]);
}
return res;
}
};细节小优化
在滚动数组的基础上继续优化

这个就是说,每个状态既然都由其上方和左方确定
然后又一直用一维数组来表示,那么按从左到右的顺序遍历时,每个状态被遍历完时,其下面状态的一个来源就被确定了,至于另一个来源,则在下一行时被确定,在那时取max;然后回到此时遍历的状态,其右侧的状态,就在此时也被补足了,用max;那么此时的状态也没用了,就可以被直接覆盖掉了,所以可以直接在这里进行覆盖
而不是等这一行都遍历完后再统一覆盖,也就是说,是遍历一个状态就覆盖一个状态,将这个方法的优化做到了极致
class Solution {
public:
int maxPathScore(vector<vector<int>>& grid, int k) {
int m=grid.size(),n=grid[0].size();
vector<vector<int>>cur(n,vector<int>(k+1,-1));
cur[0][0]=0;
int flag,dc,ds,i=0;
for(;i<m;i++){
//vector<vector<int>>next(n,vector<int>(k+1,-1));
for(int j=0;j<=n-1;j++){
vector<int>next_cur_tmp(k+1,-1);
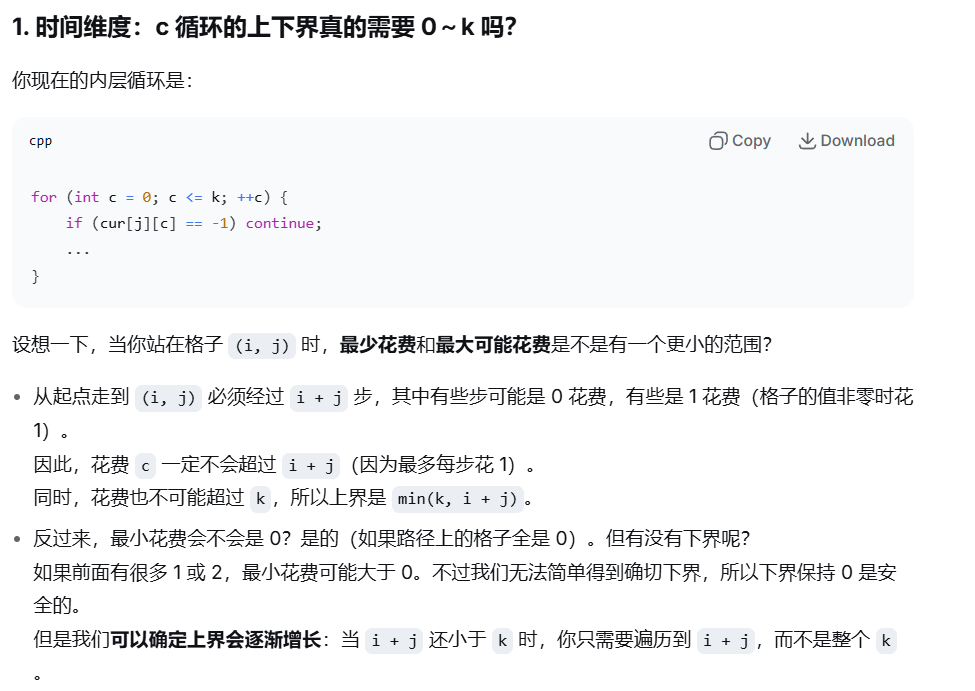
for(int c=0;c<=min(k,i+j);c++){
if(cur[j][c]==-1){continue;}
//cout<<"i: "<<i<<" j: "<<j<<" c: "<<c<<endl;
if(j+1<=n-1){
flag=grid[i][j+1],dc=flag?1:0,ds=flag;
if(c+dc<=k){
cur[j+1][c+dc]=max(ds+cur[j][c],cur[j+1][c+dc]);
}
}
if(i+1<=m-1){
flag=grid[i+1][j],dc=flag?1:0,ds=flag;
if(c+dc<=k){
next_cur_tmp[c+dc]=ds+cur[j][c];
}
}
}
if(i!=m-1)cur[j]=next_cur_tmp;
}
//if(i!=m-1)cur=next;
}
int res=-1;
for(int c=0;c<=k;c++){
res=max(res,cur[n-1][c]);
}
return res;
}
};优化c的遍历上界

3387
最直接的应该是遍历;但是不限制转换次数
对于第一天,假设有N种可行的转换次数,第二天有M种
那么直接遍历就是O(N*M)的复杂度
问题一就是如何知道有多少种可行的转换次数
如果在pairs当中,就说明两个节点之间是可连通的,就是可达的;
由此构建并查集,如果在同一个并查集下就说明他们之间是可以相互转换的;如果不在就说明不能;
最后应该是选取初始货币所在的那个并查集,以及进行完路径压缩后,有多少个节点,就是初始货币能转换到多少个最终状态,第一天的,加上边权,就意味着转换时的倍率;
第二天同理,但是第一天有N种可能的最后状态,如果第一天都不可达的并查集,在第二天更不可达,所以用的并查集和第一天是一样的;不对,第二天更新了pairs,所以构建的并查集和第一天不一样,对于每种状态,在其所在的并查集上,假设有X个元素,就有N*X的可能,
设根节点为基准,子节点到父节点的权值表示,子节点转到父节点的倍率,即子/父=边权,那么同一并查集下任意两个节点之间的转换公式(由a转到c,ac均接到父节点上)为da/dc
1.对第一天,先根据pairs和rates构建第一天的并查集和权值数组
2.应当知道和初始货币类型同在一个并查集下的所有元素,假设结果为N
如何知道?
3.然后进行N次循环,表示在第一天后转到这N种货币,这里是外循环,并以tmp表示转换后的数量,tmp由转换公式得到
4.对第二天,根据pairs和rates构建第二天的并查集和权值数组
5.同样,应该知道第一天结束后的Ni货币所在并查集下的所有元素,结果为X
6.执行X次内循环,结果为res,由tmp和转换公式得到,取max(res)
最终max(res)为结果
class Solution {
public:
// unorderd_map<string>node;
//vector<string>node;
set<string>node;
unordered_map<string,string>p1;
unordered_map<string,double>d1;
unordered_map<string,string>p2;
unordered_map<string,double>d2;
string find(string a,unordered_map<string,string>&p,unordered_map<string,double>&d){
if(p[a]==a){
return a;
}
string origin=p[a];
p[a]=find(p[a],p,d);
d[a]*=d[origin];
return p[a];
}
void unite(string a,string b,double v,unordered_map<string,string>&p,unordered_map<string,double>&d){
string ra=find(a,p,d),rb=find(b,p,d);
if(ra==rb){return;}
p[ra]=rb;
d[ra]=v*d[b]/d[a];
}
double maxAmount(string initialCurrency, vector<vector<string>>& pairs1, vector<double>& rates1, vector<vector<string>>& pairs2, vector<double>& rates2) {
for(int i=0;i<pairs1.size();i++){
string a=pairs1[i][0],b=pairs1[i][1];
if(p1.find(a)==p1.end()){
p1[a]=a;
//node.push_back(a);
node.insert(a);
d1[a]=1.0;
}
if(p1.find(b)==p1.end()){
p1[b]=b;
node.insert(b);
//node.push_back(b);
d1[b]=1.0;
}
unite(a,b,rates1[i],p1,d1);
}
for(int i=0;i<pairs2.size();i++){
string a=pairs2[i][0],b=pairs2[i][1];
if(p2.find(a)==p2.end()){
p2[a]=a;
//node.push_back(a);
node.insert(a);
d2[a]=1.0;
}
if(p2.find(b)==p2.end()){
p2[b]=b;
//node.push_back(b);
node.insert(b);
d2[b]=1.0;
}
unite(a,b,rates2[i],p2,d2);
}
double res=1.0;
//for(int i=0;i<node.size();i++){
for(const string&cur:node){
// if(node[i]==initialCurrency){continue;}
// if(find(node[i],p1,d1)!=find(initialCurrency,p1,d1)){continue;}
// if(find(node[i],p2,d2)!=find(initialCurrency,p2,d2)){continue;}
// double tmp=d1[initialCurrency]/d1[node[i]];
// res=max(res,d2[node[i]]/d2[initialCurrency]*tmp);
if(cur==initialCurrency){continue;}
if(find(cur,p1,d1)!=find(initialCurrency,p1,d1)){continue;}
if(find(cur,p2,d2)!=find(initialCurrency,p2,d2)){continue;}
double tmp=d1[initialCurrency]/d1[cur];
res=max(res,d2[cur]/d2[initialCurrency]*tmp);
}
return res;
}
};
class Solution {
public:
// unorderd_map<string>node;
//vector<string>node;
unordered_map<string,int>m;
//set<string>node;
int cnt=0;
// unordered_map<string,string>p1;
// unordered_map<string,double>d1;
// unordered_map<string,string>p2;
// unordered_map<string,double>d2;
vector<int>p1,p2;
vector<double>d1,d2;
// unordered_map<string,double>d1;
// unordered_map<string,string>p2;
// unordered_map<string,double>d2;
// string find(string a,unordered_map<string,string>&p,unordered_map<string,double>&d){
// if(p[a]==a){
// return a;
// }
// string origin=p[a];
// p[a]=find(p[a],p,d);
// d[a]*=d[origin];
// return p[a];
// }
int find(int a,vector<int>&p,vector<double>&d){
if(p[a]==a){
return a;
}
int origin=p[a];
p[a]=find(p[a],p,d);
d[a]*=d[origin];
return p[a];
}
// void unite(string a,string b,double v,unordered_map<string,string>&p,unordered_map<string,double>&d){
// string ra=find(a,p,d),rb=find(b,p,d);
// if(ra==rb){return;}
// p[ra]=rb;
// d[ra]=v*d[b]/d[a];
// }
void unite(int a,int b,double v,vector<int>&p,vector<double>&d){
int ra=find(a,p,d),rb=find(b,p,d);
if(ra==rb){return;}
p[ra]=rb;
d[ra]=v*d[b]/d[a];
}
double maxAmount(string initialCurrency, vector<vector<string>>& pairs1, vector<double>& rates1, vector<vector<string>>& pairs2, vector<double>& rates2) {
//m[initialCurrency]=cnt++;
//cout<<"test1"<<endl;
for(int i=0;i<pairs1.size();i++){
string a=pairs1[i][0],b=pairs1[i][1];
if(m.find(a)==m.end()){
cout<<a<<endl;
p1.push_back(cnt);
d1.push_back(1.0);
p2.push_back(cnt);
d2.push_back(1.0);
// p1[cnt]=cnt;
// d1[cnt]=1.0;
m[a]=cnt++;
//node.push_back(a);
//node.insert(a);
}
if(m.find(b)==m.end()){
cout<<b<<endl;
//p1[cnt]=cnt;
//node.insert(b);
//node.push_back(b);
//d1[cnt]=1.0;
p1.push_back(cnt);
d1.push_back(1.0);
p2.push_back(cnt);
d2.push_back(1.0);
m[b]=cnt++;
}
cout<<"test3,a:"<<m[a]<<" b:"<<m[b]<<endl;
unite(m[a],m[b],rates1[i],p1,d1);
}
//cout<<"test4,a"<<endl;
for(int i=0;i<pairs2.size();i++){
string a=pairs2[i][0],b=pairs2[i][1];
if(m.find(a)==m.end()){
p2.push_back(cnt);
d2.push_back(1.0);
m[a]=cnt++;
}
if(m.find(b)==m.end()){
p2.push_back(cnt);
d2.push_back(1.0);
m[b]=cnt++;
}
unite(m[a],m[b],rates2[i],p2,d2);
}
cout<<"test2,并查集1: "<<p1.size()<<" 2:"<<p2.size()<<endl;
double res=1.0;
//for(int i=0;i<node.size();i++){
// for(const string&cur:node){
for(int i=0;i<p2.size();i++){
// if(node[i]==initialCurrency){continue;}
// if(find(node[i],p1,d1)!=find(initialCurrency,p1,d1)){continue;}
// if(find(node[i],p2,d2)!=find(initialCurrency,p2,d2)){continue;}
// double tmp=d1[initialCurrency]/d1[node[i]];
// res=max(res,d2[node[i]]/d2[initialCurrency]*tmp);
//if(cur==initialCurrency){continue;}
if(i<p1.size()&&(find(i,p1,d1)!=find(m[initialCurrency],p1,d1))){continue;}
//if((find(i,p1,d1)!=find(0,p1,d1))){continue;}
if(find(i,p2,d2)!=find(m[initialCurrency],p2,d2)){continue;}
//if(i==m[initialCurrency]){continue;}
//cout<<i<<endl;
double tmp=1.0;
if(i<p1.size()){tmp=d1[m[initialCurrency]]/d1[i];}
res=max(res,d2[i]/d2[m[initialCurrency]]*tmp);
}
return res;
}
};
class Solution {
public:
unordered_map<string,int>m;
int cnt=0;
vector<int>p1,p2;
vector<double>d1,d2;
int find(int a,vector<int>&p,vector<double>&d){
if(p[a]==a){
return a;
}
int origin=p[a];
p[a]=find(p[a],p,d);
d[a]*=d[origin];
return p[a];
}
void unite(int a,int b,double v,vector<int>&p,vector<double>&d){
int ra=find(a,p,d),rb=find(b,p,d);
if(ra==rb){return;}
p[ra]=rb;
d[ra]=v*d[b]/d[a];
}
double maxAmount(string initialCurrency, vector<vector<string>>& pairs1, vector<double>& rates1, vector<vector<string>>& pairs2, vector<double>& rates2) {
for(int i=0;i<pairs1.size();i++){
string a=pairs1[i][0],b=pairs1[i][1];
if(m.find(a)==m.end()){m[a]=cnt++;}
if(m.find(b)==m.end()){m[b]=cnt++;}
}
for(int i=0;i<pairs2.size();i++){
string a=pairs2[i][0],b=pairs2[i][1];
if(m.find(a)==m.end()){m[a]=cnt++;}
if(m.find(b)==m.end()){m[b]=cnt++;}
}
p1.resize(cnt),p2.resize(cnt),d1.resize(cnt),d2.resize(cnt);
for(int i=0;i<cnt;i++){
p1[i]=i,p2[i]=i;
d1[i]=1.0,d2[i]=1.0;
}
for(int i=0;i<pairs1.size();i++){
string a=pairs1[i][0],b=pairs1[i][1];
unite(m[a],m[b],rates1[i],p1,d1);
}
for(int i=0;i<pairs2.size();i++){
string a=pairs2[i][0],b=pairs2[i][1];
unite(m[a],m[b],rates2[i],p2,d2);
}
double res=1.0;
for(int i=0;i<cnt;i++){
if((find(i,p1,d1)!=find(m[initialCurrency],p1,d1))){continue;}
if(find(i,p2,d2)!=find(m[initialCurrency],p2,d2)){continue;}
double tmp=d1[m[initialCurrency]]/d1[i];;
res=max(res,d2[i]/d2[m[initialCurrency]]*tmp);
}
return res;
}
};并查集


假设以A为基点,就是root;
399
1.遍历对数组equations,让被除数作为父亲,即A/B=C时,PA=B;这样有i个元素的equtions,遍历完后有i个root
2.尝试合并这些节点
但是如何保证一遍遍历确实是不遗漏的?
合并的标准的是什么?就是给出A和B,C和D的关系后,那么他们之间就一定要合并吗?应该是至少有关联的元素才能合并,但是在一开始时都没合并时,没法判断是否真的有关系(因为这个关系可能在后面),以及如果真的有关系,又怎么判断出来?比如a->b,b->c,在接到第二个关系时,此时只要两个root,即b和c,那么只判断根是无法断定他们直接有关系的,即find没用,那怎么知道什么时候该合并,什么时候不合并?
如果知道要合并,那该怎么合并,随机选一个为新的根节点,将边权信息记录在没被选为根节点的那个旧根节点当中;后续遍历到的时候再进行路径压缩,边权更新关系为da=da*dp\[a]
3.对于解题,c与d,首先findc和findd是不是相等,如果不相等就说明他们之间没关系,直接返回-1;不然c/d=dc/dd
这是以c和d都直接挂载到根节点为例的,应该需要判断一下c和d是不是真的挂载在根节点,即pc=find(c),如果不是,需要再while一下去更新数值;
不应当不在同一集合就直接合并,比如A->B,C->D,此时该如何合并?AB和CD都没关系,怎么合并?
对于合并的标准,就是等式两侧的变量(设为A/B=C),如何其属于的根节点不同,就该合并;此时根据二者是否为各自的根节点,又该进行讨论;
如果AB均是自己的根节点,那么PA=B,da=c
如果其中一个是,一个不是,以A是为例,应当找到B的根节点,设为D,即D=find(B),然后再PA=D,da=c*db(即b是a到新根节点d上的一个节点)
如果都不是,都找到,记E=find(A),那么PE=D,de=c*da*db
如何记录数据结构?
每个节点要记录自己的名字string,和到父节点的权值int,以及自己的父节点
首先要知道有几个节点,假设有n个;
用int数组d记录权值关系;
如何记录连接关系?就用string数组p
但是如何知道一共有多少个节点?有没有什么好方法?
使用哈希表
对于a->b和b->c的情况,如果就
对于a->b和a->c的情况,如果使用数组去建模并查集,都会造成覆盖情况,该怎么处理?
现在代码存在问题,即默认将equtions当中的每个元素都作为初始的并查集去建立节点关系,这样容易造成覆盖问题
先判断分子分母是否已经有父亲了,如果有了,直接执行合并,不然就执行构建