摘要: 在技术圈,我们每天都被 LLM、Agent、RAG、MCP 这些名词轰炸。它们看似孤立,实则是一场长达数年的"接力赛",每一项技术都是为了弥补前者的缺陷而生。本文将为你绘制一张大模型家族的"概念血缘图谱",用一条逻辑主线贯穿始终,让你看清这场 AI 浪潮背后唯一的真相:一切技术都在围绕"提示词"做文章。
引言:被概念轰炸前,先看清"万物之源"
如果你刚踏入大模型领域,很容易在层出不穷的新名词中迷失方向。但若让我们回到 2020 年,一切都没那么复杂。
当时的研究者发现了一件神奇的事:当语言模型的参数规模突破某个临界点(大致在数百亿到千亿级别),模型突然"开窍"了。它不再只是机械地模仿,而是展现出了逻辑推理、代码生成、甚至某种意义上的"举一反三"。为了与过去那些表现平平的"小模型"划清界限,我们给了它一个新身份------大语言模型(LLM, Large Language Model)。
但请透过现象看本质:LLM 的核心能力,剥离所有包装后,是一种极其朴素的本能------文字接龙。 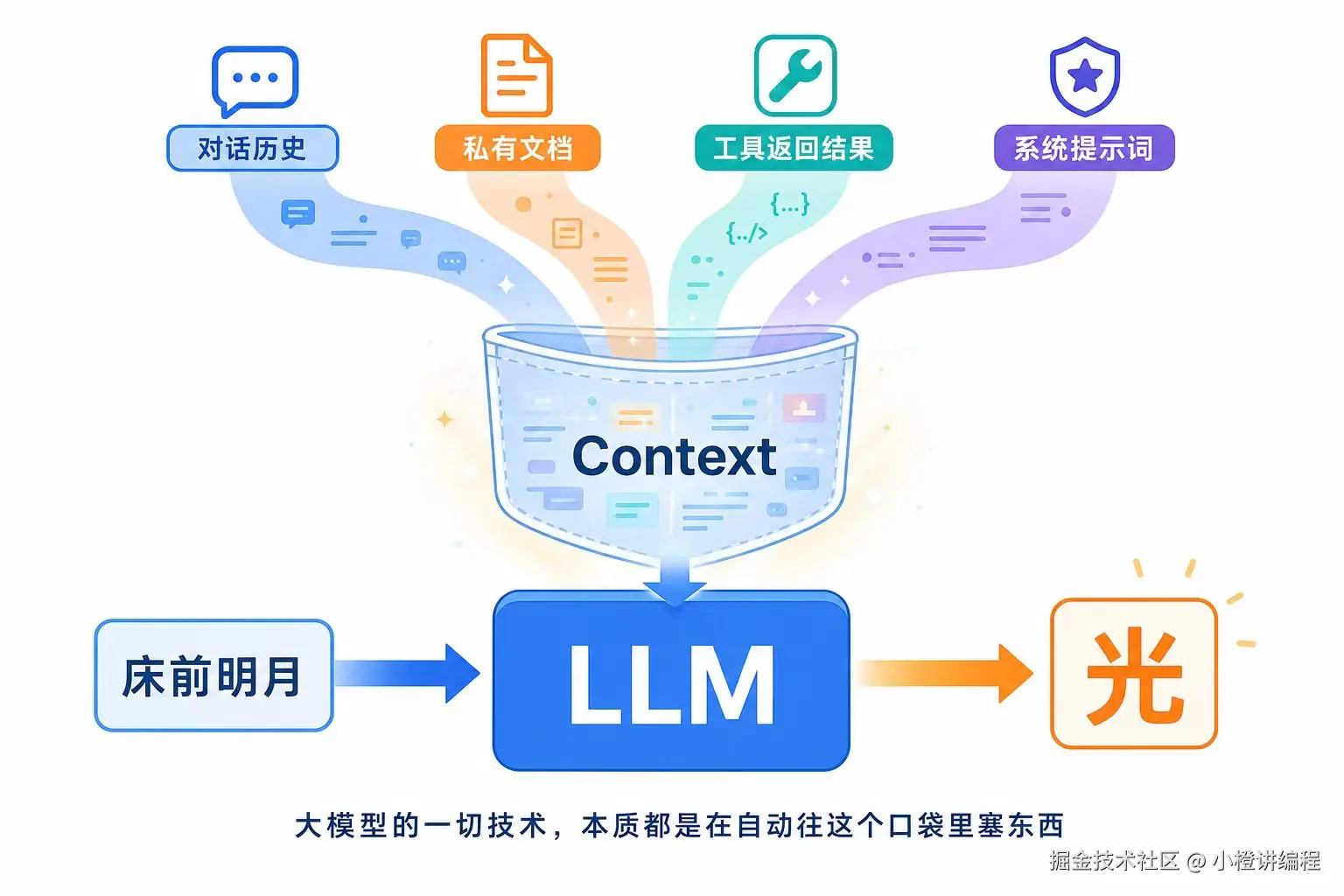
给定一串前文"床前明月",它只做一件事:计算下一个字是"光"的概率。它没有记忆,不知道今天几号,不能访问互联网,更没法操作你的本地文件。一个只会做"完形填空"的机器,为何能被包装成无所不能的助手?
答案在于"上下文 (Context)"。
LLM 本身是一个孤立的函数,但它的输入通道------Context,是一个可以无限做文章的"魔法口袋"。我们今天看到的所有炫酷名词,从 Memory 到 Agent,从 RAG 到 Skill,本质无非都是在做两件事:
- 如何自动往 Context 口袋里塞入更多有用信息。
- 如何用最少次数的交互,拿到最准确的结果。
下面,让我们沿着这条"上下文增强"的主线,把散落的概念重组为一部进化史。
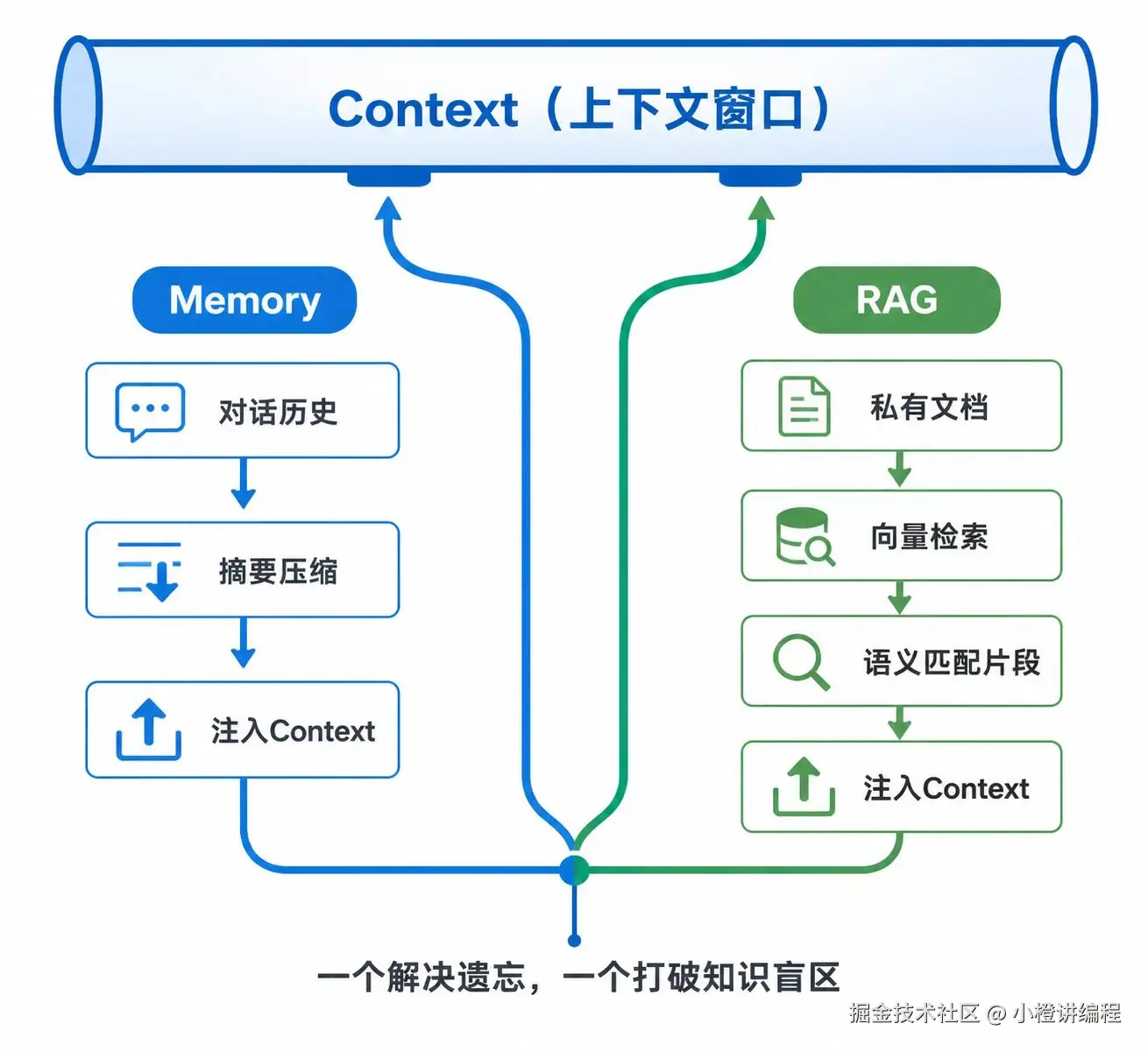
1. 记忆 (Memory):对抗"鱼的记忆"
LLM 的 API 调用是无状态的。每一轮对话,都是一个新的开始。你第一句话说"我叫李明",第二句话问"我叫什么?",它会一脸茫然。
为了让机器能像人一样连续对话,工程师想到了最直接的方案:把你们之前的聊天记录,原封不动地拷贝到新的请求里,放在当前提问的前面。
这部分"历史的聊天记录",就是大模型的 Memory(记忆)。
Memory 给了模型短期记忆的假象,但很快遇到了物理极限------Context 窗口装不下了。一顿午饭聊下来,Token 就溢出了。怎么办?技术在这里开始了第一次精巧的演化:压缩记忆。可以写一个函数,定期调用 LLM 对漫长的对话历史进行摘要,只把摘要后的关键信息作为 Memory 保留。
Memory 技术,是人类帮 LLM 对抗其"无状态"原罪打下的第一块补丁。
2. 检索增强生成 (RAG):打破"知识的诅咒"
即便解决了记忆,模型仍有"知识盲区"。它的知识截止于训练完成的那一天,且对未公开的私有文档一无所知。
如果 LLM 是一个闭卷考试的考生,那 RAG(检索增强生成) 就是给他开了"开卷考试"的特权。
流程是这样设计的:
- 离线阶段: 将你所有的私有文档(产品手册、技术文档、最新新闻)切成片段,通过嵌入模型(Embedding Model)转译成向量,存入向量数据库。
- 在线阶段: 用户提问时,把问题也向量化,在数据库里做"语义相似度"匹配,找出最相关的几个原文片段。
- 注入: 把这些片段直接拼接到当前的 Context 中,然后告诉模型:"请基于我给你的参考资料,回答以下问题。"
RAG 的实质,是外挂知识库的实时注入技术。它让 LLM 的回答从"拍脑袋"变成了"有理有据",极大地压制了幻觉。
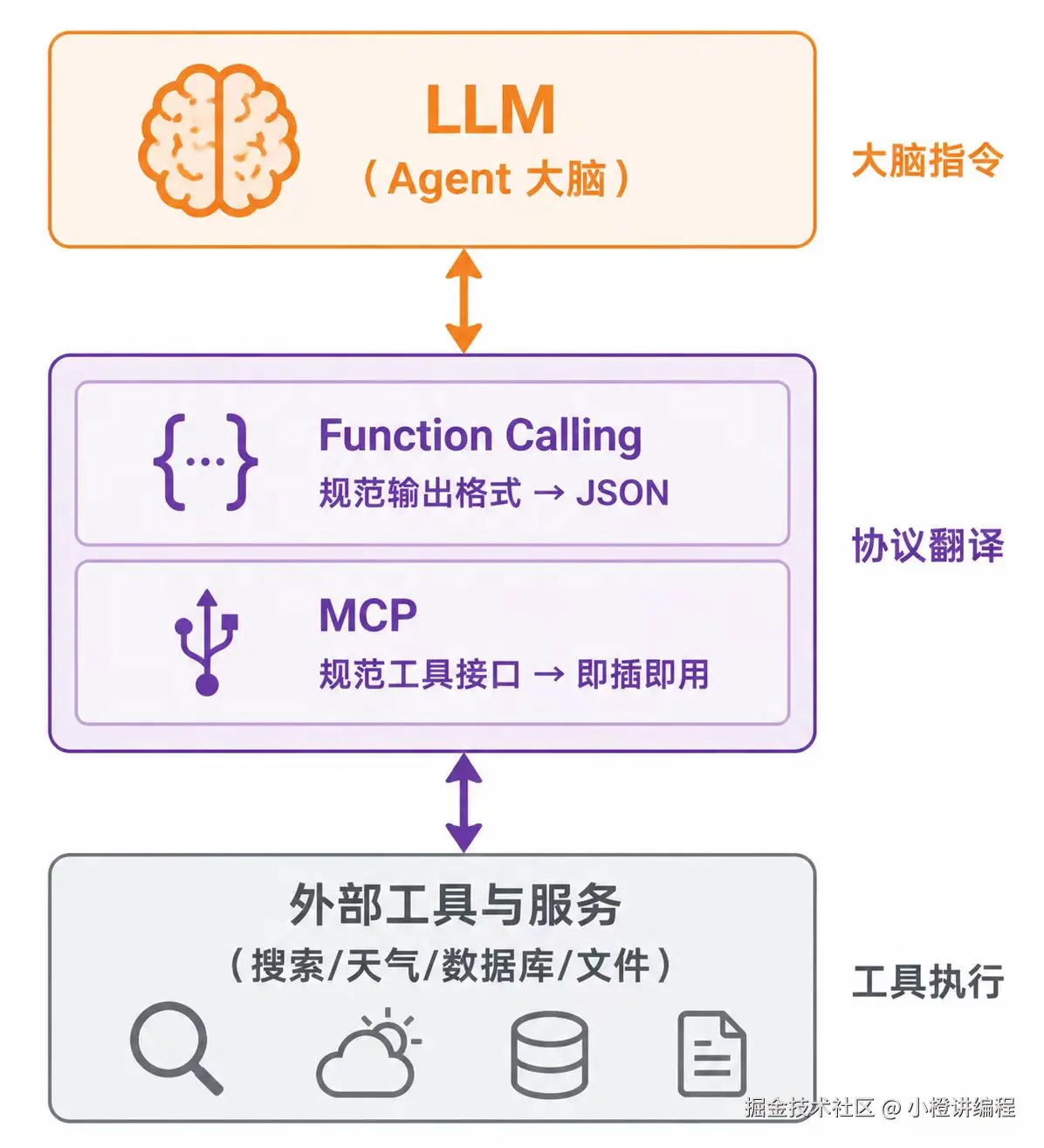
3. 函数调用 (Function Calling):统一内部的"摩斯密码"
当模型需要查天气、订机票时,只靠文字输入就不够了。它得能"驱动"外部工具。但 LLM 输出的是自然语言,程序无法稳定解析"帮我搜一下天气"这句话到底是想调哪个 API。
于是,Function Calling 作为一套交互规范被定了下来。
它强迫 LLM 在需要工具时,不以自然语言输出,而是生成一个结构化的 JSON 字符串:
json
{
"tool_name": "weather_api",
"parameters": {
"city": "Beijing",
"date": "2025-05-20"
}
}对于 Agent 程序而言,解析这段 JSON 就变得极其可靠。
Function Calling 的本质,是 Agent 大脑(LLM)与 Agent 四肢(执行程序)之间达成的通信协议。这让散乱的指令变成了可被代码精确捕获的动作。
4. 模型上下文协议 (MCP):解耦外部的"万能插座"
Function Calling 统一了程序去理解模型的语言,但没解决程序去对接不同工具的麻烦。今天对接谷歌搜索,明天换必应,代码得重写,格式各不相同。
MCP(模型上下文协议) 的出现,是为了给工具侧定一个统一标准。
如果把 Agent 主程序看作一台电脑的主机,那么 MCP 就是 USB 协议。管你是 U 盘、键盘还是鼠标,只要遵循 USB 协议,就能即插即用。MCP 规定,所有工具服务都必须暴露 tool/list 和 tool/call 这类统一接口。这让工具服务与 Agent 主程序完成了解耦,整个生态开始有了分工。
5. 智能体 (Agent):从"大脑"到"生物体"的觉醒
有了 Memory、RAG 和工具调用协议,一个完整的"数字生物"终于拼图完成。这就是 Agent(智能体)。
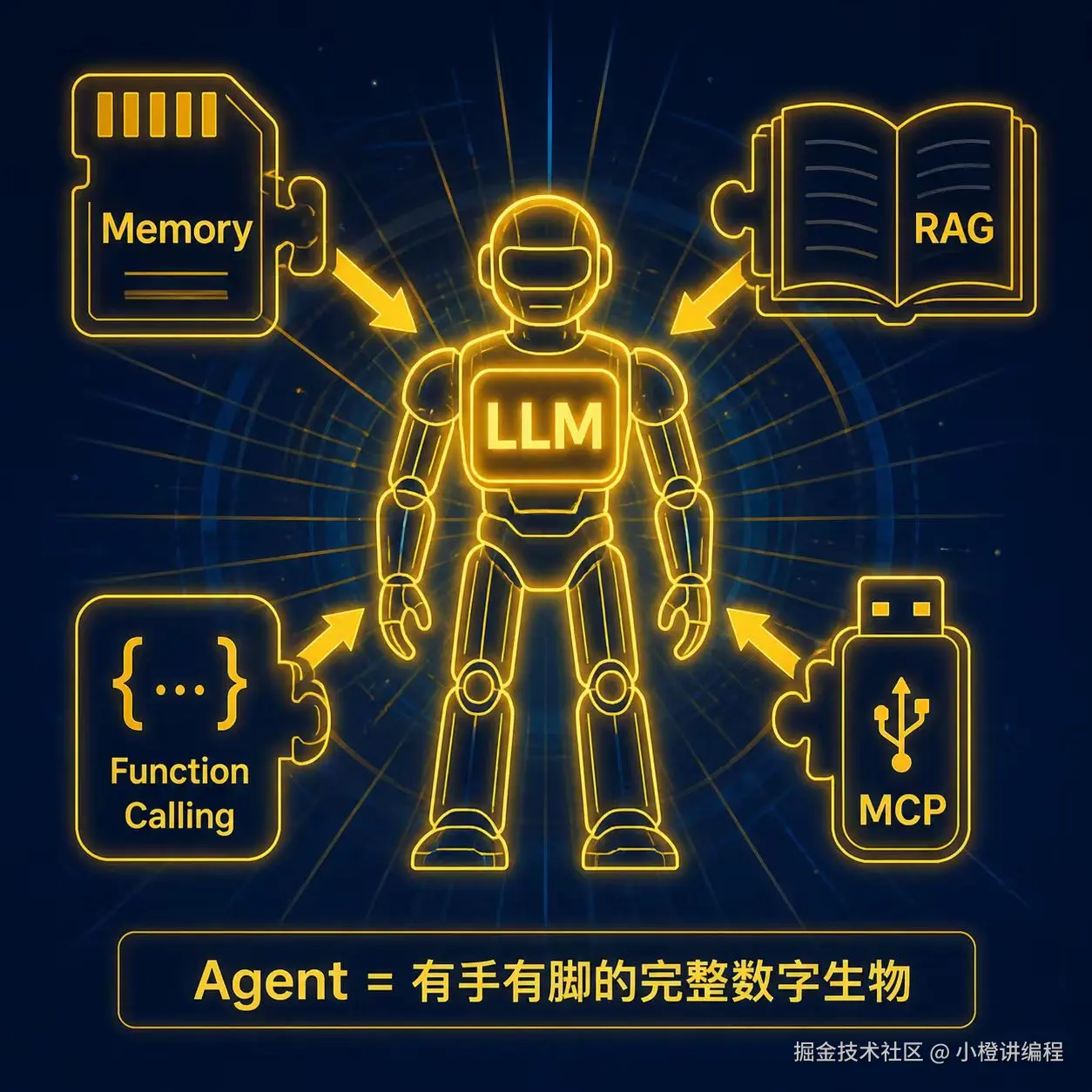
不要被早期那些仅仅靠 Prompt 伪装出来的"伪智能体"迷惑。真正的 Agent 是一个自主运行的程序,承担着规划者与执行者的角色。它在一个循环里工作:
- 思考: 接收任务,通过 LLM 制定计划。
- 决策: 如果计划暗示需要工具,生成 Function Calling 格式的指令。
- 行动: 主程序解析指令,通过 MCP 协议调度外部工具。
- 观察: 将工具返回的结果塞回 Context,引导 LLM 进行下一轮思考。
Agent 是大模型脱虚向实的关键一跃。它让 LLM 长出了手脚,从只会上网的"缸中之脑",变成了能对物理世界或数字世界施加影响的"智能体"。
6. 链式与工作流:进化中的"自动化本能"
单个 Agent 的调用是行动,多个调用的串联才是任务。
比如要进行一次深度调研:"调研 A 公司 -> 分析 B 市场 -> 写对比报告",这显然需要把多个步骤像糖葫芦一样串起来。于是,业界分化出两种固化流程的手段:
- LangChain 流(硬编码): 用 Python 代码将上述步骤串联。优点是稳如老狗,逻辑严密;缺点是改起来麻烦。
- Workflow 流(低代码): 通过拖拽画布来编程。优点是上手快,业务人员就能玩;缺点是不擅长应对极其复杂的逻辑分支。
它们都在做编排 (Orchestration),殊途同归,为的都是让 Agent 能够自动化地处理长链路任务。
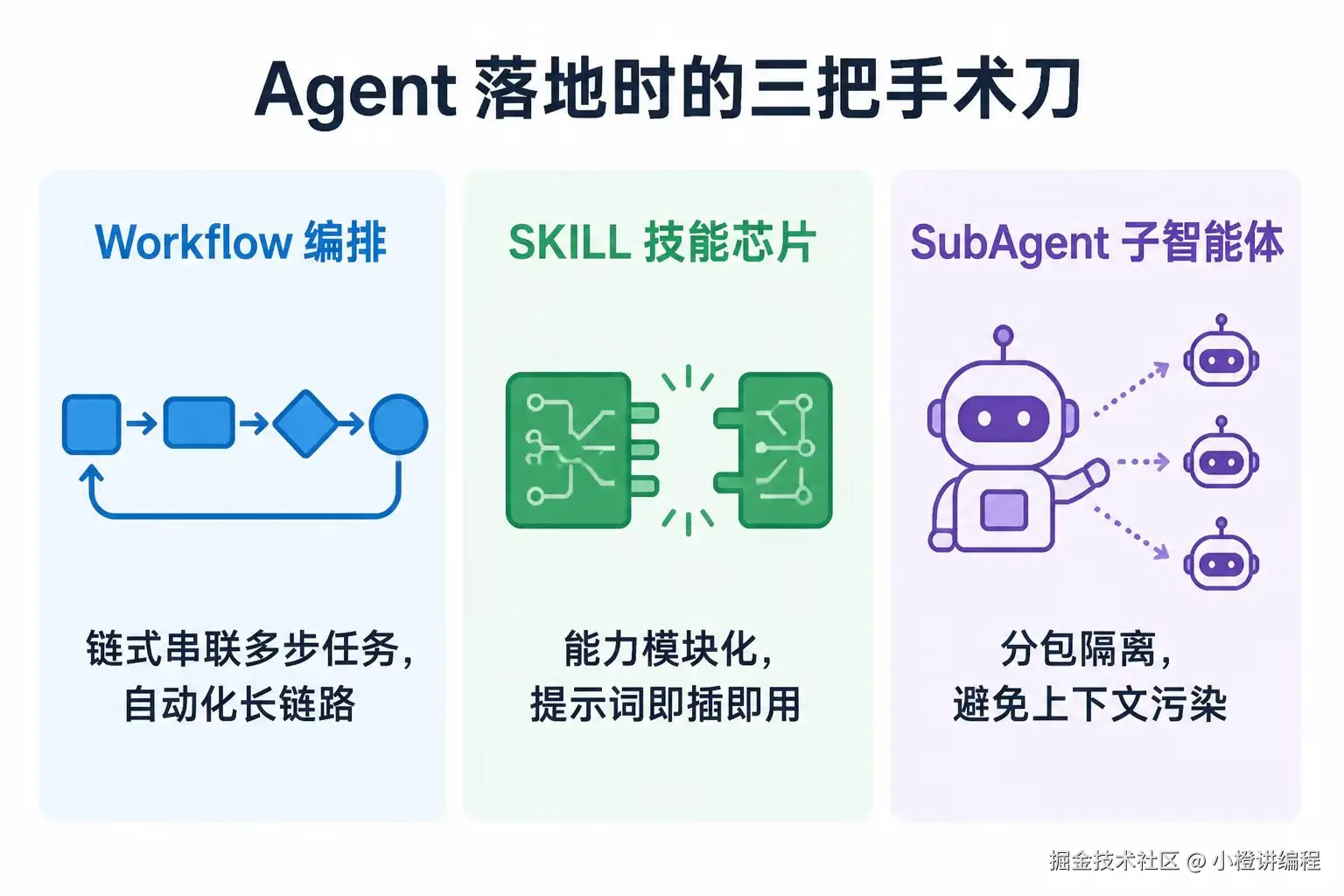
7. 进阶设计:SKILL 与子智能体 (SubAgent)
在上述基础架构之上,工程师们遇到了场景落地时更精细的问题:
问题一:提示词管理混乱。 一个高级 Agent 有几十种提示词模板,如何复用?
解法:SKILL。 将特定能力的 Prompt 固化成 SKILL.md 文件,Agent 在需要时动态加载。这就像是给 Agent 安装了"技能芯片",随时插拔。它让提示词工程从手工作坊进入了资产管理的阶段。
问题二:复杂任务导致的上下文污染。 当一个主智能体同时处理多个子任务时,这些子任务产生的巨量中间推理过程,会迅速把主 Context 撑爆。
解法:SubAgent (子智能体)。 将子任务分包给一个完全独立的 Agent,在一个"隔离"的上下文环境中执行,最后只将干净的结果返回主 Agent。这实现了上下文的微观隔离,保证了系统在处理庞大复杂任务时的整洁与健壮。
终章:超级智能体------必然的归一
行文至此,你会发现一幅清晰的血缘图谱:
LLM 是内核,Context 是灵魂通道,Memory、RAG 是往通道里自动递纸条的机制,Agent 是给内核装上了躯干,而 MCP、Function Calling、Workflow 等都是为了让这具躯干行动得更稳定、更流畅。
展望未来,所有的技术名词都会走向内化与消失。
未来属于 超级智能体 (Super Agent) ------一个将搜索、存储、压缩、工具调度、技能加载全部封装进底层操作系统的存在。届时,用户不再需要了解什么是 RAG 或 MCP,只需下达一个指令:"帮我把这件事办了。"它会自己规划、自己纠错、自己交付。

这场进化的终点,是名词的消融,与体验的涌现。而贯穿始终的,永远是那个最朴素的真理:自动丰富上下文,减少沟通成本,追求极致的便利。
如果你也对这张不断扩展的"概念图谱"着迷,欢迎在评论区留下你的见解。我们一起见证,下一个被创造出来的,又会是笔下的哪个名词。