本文分享用 CentOS 7 服务器,使用 K8s 部署模型,调起模型的架构工具使用社区较活跃的Ollama。Ollama实际上是由三个核心部分组成的"全家桶",底层计算核心(真正的引擎)是llama.cpp,中间管理层(Ollama 的核心贡献)它定义了 GGUF 格式的加载方式,帮你自动下载、版本管理模型(像 Docker 管理镜像一样),用户交互层的命令行工具 (ollama run) 和 REST API
但是要说一个关键事情,本文用 Ollama ,本质的目的是分享向 gpu 过度用的 纯cpu 模型部署环境搭建,如果你是个人使用者或者一些小团体可以这样玩,毕竟 gpu 的使用成本确实不低。尤其是对于个人使用者来讲,手里的环境通常是虚拟化软件做的 linux 虚拟机,这些软件本身直通物理机的 gpu 受限于具体软件不同会很困难,比如 VMware 从架构上就不支持gpu直通。如果你用的是 VirtualBox 它虽然基于 kvm 开发,也有显卡直通的功能,但这个功能是实验性的,它基于 kvm 的显卡直通实现,而 kvm 的显卡直通本身只能在宿主机是 linux 时使用,因此保不齐 VirtualBox 的功能有问题。但话分两头,这种用虚拟化软件做出linux虚拟机,再用linux虚拟机做 k8s 环境,本身就不是一个有助于模型部署学习的环境,中间层有点繁琐了,会拖响应速度的后腿,其他不涉及 gpu 的技术学习,这种虚拟化软件环境确实是性价比很高,但涉及 gpu 由于它本身支持困难,会把你拖进不必要的坑里,建议各位读者在手头能有三台物理linux机器,且最少其中一台有最低 RTX 3070 8G显卡时,在考虑 gpu 搭载模型的事情,docker自身只需要一个开关参数和对应的驱动就可以让容器能够访问宿主机的显卡
当然,如果你不需要 k8s 提供的服务运维能力,就想有一个模型能自己用用看,感受一下,那一台有显卡的机器就够了。你面临的问题就只有两个,一是如果你要物理机直接部署就要考虑系统方面的影响,国内使用的系统环境,除了所谓的自研系统外,通常比较旧,比如本文用的 centos 7.2209 ,要基于它直接部署,需要升级的系统依赖会让你奔溃,尤其是 Ollama 要使用 glibc 2.27 以上版本,这个东西在任何 linux 上升级一个搞不好都会导致系统所有基础命令失效,二是要考虑可用的硬件,RTX 3070 8G显卡,首选AMD的CPU,次选Intel的,网卡要兼容Linux驱动。因此,对于从体验出发的读者,推荐你可以在 Windows 上用 Docker 桌面版,平替物理linux机器,能省去不必要的麻烦,但是也有缺点,基于windows部署模型,由于它的内核限制,导致模型的响应速度很可能比你用Linux虚拟机还慢
如果最终任然想使用linux物理机部署,一定要选择比较新的其他发行版linux ,比如 ubantu ,安装时不能直接用官方的安装脚本,有资源下载问题。使用国内魔塔的镜像包安装 -》 https://modelscope.cn/models/modelscope/ollama-linux。这个安装方式需要用魔塔的python工具下载安装包,因此需要服务器上有 python 3.11 的环境。下面这个部署方式只供参考
bash
pip3 install modelscope
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.17.5
cd ollama-linux
yum install -y zstd
chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh
# 修改环境变量
vi /etc/profile
# 监听地址
export OLLAMA_HOST="0.0.0.0:11434"
# 模型文件存放地址
export OLLAMA_MODELS=/opt/model
# 单个模型同时处理的并发请求数
export OLLAMA_NUM_PARALLEL=2
# 模型在内存中的保活时长
export OLLAMA_KEEP_ALIVE=24h
# GPU同时加载的最大模型数量
#export OLLAMA_MAX_LOADED_MODELS=2
# 启动服务
systemctl restart ollama
systemctl status ollama从实际出发其实没有将精力消耗在 Ollama 物理机直接部署的必要,因为无论是出于商用环境讲,还是个人学习,docker的环境交付能力,能省去你非常多的麻烦事,而且 Ollama 它不会出现在企业商用环境内,除非是上面说到的小团体,Ollama 确实是出现时机最早的一批工具,但是它的架构也是最拉跨的那一批,它的优点是多平台易用,支持 gguf 格式模型文件,且支持纯CPU运行模型,非常适合新手用来练手,但是它对模型的应用性能非常垫底,尤其是使用它的 gpu 模式会让人非常难受,OOM 等各种问题频出不断。未来有时间我会分享基于 Vllm 做模型加载工具的商用环境,从行业地位来讲 Ollama 就是一个随手可丢掉的工具,而 Vllm 是模型领域的基座
ollama准备
言归正传,首先在单台 docker 上,拉取镜像,测试版本是否可用。由于本质的目的要生成一个未来要挂载的模型文件路径,以及其他需要的资源,因此本文在 k8s 主节点上单独安装了一个 docker 做这些操作,Ollama 使用 0.17.0 ,拉取镜像用国内源。各位读者自己根据情况来决定即可,后期使用 pv 在 k8s中挂载
bash
docker pull docker.m.daocloud.io/ollama/ollama:0.17.0
mkdir /opt/ollama_data
docker run -d --name ollama \
-p 11434:11434 \
-e OLLAMA_MODELS=/root/.ollama/models \
-e OLLAMA_ORIGINS="*" \
-e OLLAMA_HOST=0.0.0.0 \
-e OLLAMA_NUM_PARALLEL=2 \
-e OLLAMA_KEEP_ALIVE=24h \
-e OLLAMA_REGISTRY_MIRRORS="https://ollama.modelscope.cn" \
-v /opt/ollama_data:/root/.ollama \
-v /etc/localtime:/etc/localtime:ro \
--restart unless-stopped \
docker.m.daocloud.io/ollama/ollama:0.17.0
OLLAMA_REGISTRY_MIRRORS 指定模型下载加速器
OLLAMA_ORIGINS 允许跨域
OLLAMA_NUM_PARALLEL 同时处理几个访问请求
OLLAMA_KEEP_ALIVE 模型加载后保持多长时间
--restart unless-stopped 跟随宿主机或docker重启时的自动重启命令
--gpus all 如果在有GPU的服务器上可以使用该参数使得启动的容器可以访问所有gpu,前提是安装了显卡驱动
[root@node1 opt]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8e2e88f8ff3c ollama/ollama:latest "/bin/ollama serve" 5 seconds ago Up 4 seconds 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama
[root@node1 opt]# curl http://localhost:11434/api/tags
{"models":[]}对于模型上,如果你直接 run 也可以,会从指定的镜像源下载,但是模型往往很大,所以这里使用 ollama 提供的ModelFile,来加载预先下载好的模型。 ModelFile 和 DockerFile 是一个类型的东西。你会 DockerFile 就能看明白 ModelFile
首先下载好的 gguf 文件放在容器的挂载路径下,可以去魔塔https://www.modelscope.cn/models,并准备一个 ModelFile
bash
# 假设你的模型文件叫 Qwen3-2B-UD-IQ2_M.gguf ,指定相对路径
FROM ./Qwen3-2B-UD-IQ2_M.gguf随后进入容器,让 ollama 加载。API调用的话,基本和OpenAi一样
bash
# 加载 Qwen3 是你为模型取的本地名字
ollama create qwen25 -f ./Modelfile
# 查看当前本地可用的模型
ollama list
# 运行模型,启动一个交互式对话,Ctrl + d 退出
ollama run qwen25:latest
# 后期不需要可以删除模型
ollama rm qwen25:latest
温馨提示:gguf 格式低参数不要下载 qianwen ,本文亲测模型会相当智障,所以如果要使用qianwen 可以和本文一样直接从魔塔上 pull 一个
ollama pull qwen2.5:0.5b交互式没问题,就调用接口测试一下
bash
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5:0.5b",
"messages": [
{"role": "user", "content": "你好,请简单介绍一下你自己"}
],
"stream": false
}'预期结果。注意由于测试用的模型非常参数非常小,所以大概率答非所问,到这一步主要是验证服务可以用即可。各位读者实际操作时参数方面自己注意一下,如果太小不止会导致能力不足答非所问,严重的还可能连话也不会说
bash
[root@master01 ollama_data]# curl http://127.0.0.1:11434/v1/chat/completions \
> -H "Content-Type: application/json" \
> -d '{
> "model": "qwen2.5:0.5b",
> "messages": [
> {"role": "user", "content": "你好,请简单介绍一下你自己"}
> ],
> "stream": false
> }'
{"id":"chatcmpl-253","object":"chat.completion","created":1777564440,"model":"qwen2.5:0.5b","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"你好!我是阿里云从阿里集团自主研发,经过多年积累而成为领先的AI、机器学习和自然语言处理专家的人工智能助手。你有什么问题或需求,我都愿意为您提供帮助。"},"finish_reason":"stop"}],"usage":{"prompt_tokens":34,"completion_tokens":42,"total_tokens":76}}随后需要用 ollama 下载一个嵌入式的文本处理模型
bash
docker exec -it ollama ollama pull nomic-embed-text
如果你只关注英文文本处理,可以使用
docker exec -it ollama ollama pull all-minilmopen-webui准备
Ollama 它只负责模型的挂载,对外服务通常需要丰富的非训练模型形式的挂载知识库等应用层需求,这方面推荐使用 Open WebUI 易用性非常高,支持多种知识库关联,同样支持docker部署
bash
docker pull ghcr.io/open-webui/open-webui:main
mkdir -p /opt/openui
docker run -d \
--name open-webui \
-p 3000:8080 \
-v /opt/openui:/app/backend/data \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
--add-host=host.docker.internal:host-gateway \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main
--add-host=host.docker.internal:host-gateway 这个配置非常重要,它是依靠 docker 20 版本开始提供的一个关键字 host-gateway 指向宿主机。这个配置相当于在容器的/etc/hosts文件中插入了一条dns映射。host.docker.internal部分你可以改成自定义的名称
-e OLLAMA_BASE_URL=http://host.docker.internal:11434:告诉 Open WebUI 去哪里找 Ollama访问宿主机 3000 端口。首次访问需要创建一个管理员账号,后期其他人的账号需要管理员创建

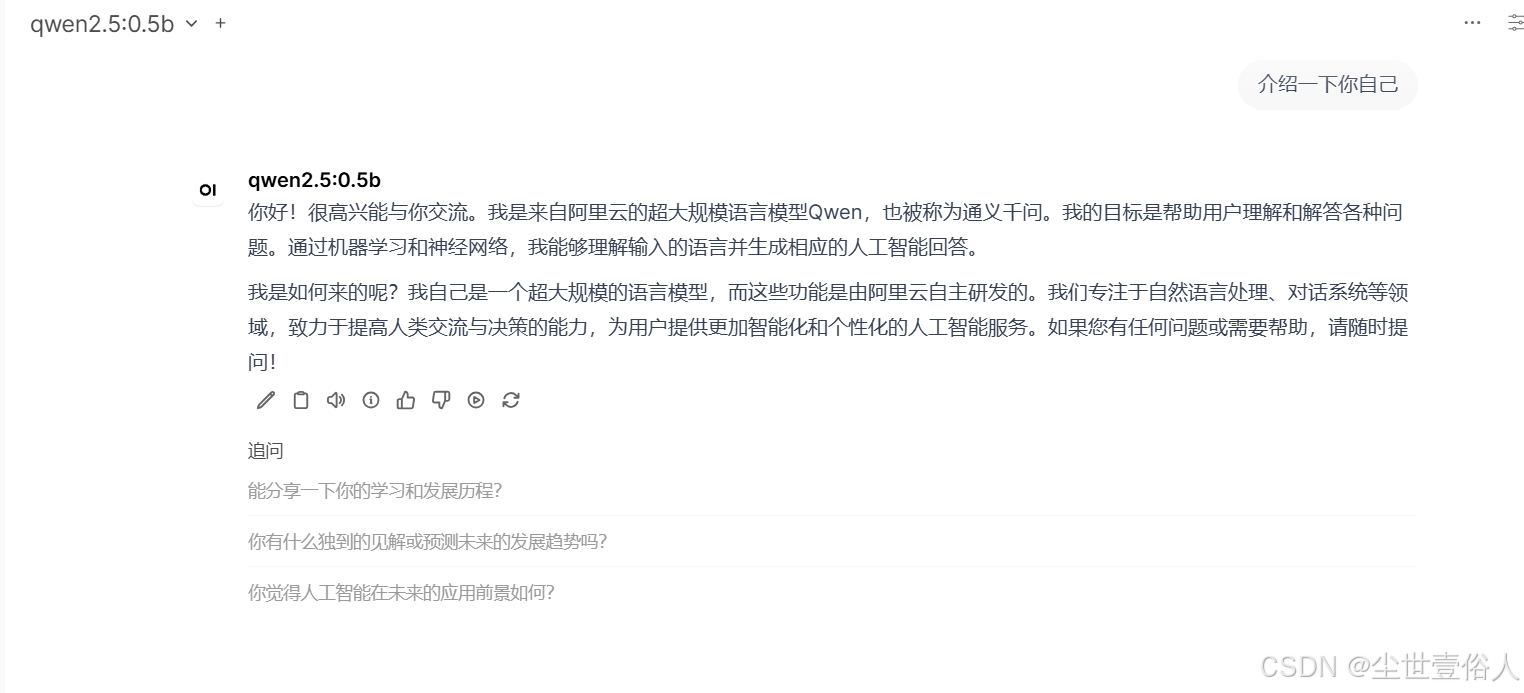
Open WebUI 支持丰富的搜索外部数据挂载,你还可以以知识库的形式存在,细节功能各位读者自己探索,本文不扩展
联网搜索
不管你用的是何种模型,始终逃脱不了模型自身数据的落后性,比如上图中默认自身的知识储备终止到2023年04月18日,但本质上谁来也无法让一个模型天天更新自己的知识库,因此你需要让open-webui拥有联网搜索的能力。同样的需要使用私有化,且支持外部API调用的搜索引擎,这里使用searxng
bash
docker pull searxng/searxng
mkdir -p /opt/searxng
docker run -d \
--name searxng \
-p 3050:8080 \
-v /opt/searxng:/etc/searxng \
-e BASE_URL=http://host.docker.internal:8080/ \
-e INSTANCE_NAME=searxng \
--add-host=host.docker.internal:host-gateway \
--restart unless-stopped \
searxng/searxng启动容器后,在宿主机的/opt/searxng会生成对应的本地卷里面是searxng配置文件,把它下载到本地修改两个东西。第一个是 search 部分最后改成json格式
yaml
# remove format to deny access, use lower case.
# formats: [html, csv, json, rss]
formats:
- json第二个将 engines 部分替换成下面的,原配置文件非常长,这一步修改是把支持的搜索引擎列表中除了bing、baidu其他的都关掉,不然会影响搜索效率,而且其他的国内也用不了
yaml
engines:
- name: bing
engine: bing
shortcut: bi
- name: bing images
engine: bing_images
shortcut: bii
- name: bing news
engine: bing_news
shortcut: bin
- name: bing videos
engine: bing_videos
shortcut: biv
- name: baidu
baidu_category: general
categories: [general]
engine: baidu
shortcut: bd
- name: baidu images
baidu_category: images
categories: [images]
engine: baidu
shortcut: bdi
- name: baidu kaifa
baidu_category: it
categories: [it]
engine: baidu
shortcut: bdk现在删掉刚才启动的容器,将改好的配置文件放到原路径,重新 run 一个容器,访问宿主机 3050 端口,http://宿主机:3050/search?q=llm&format=json,预期返回结果

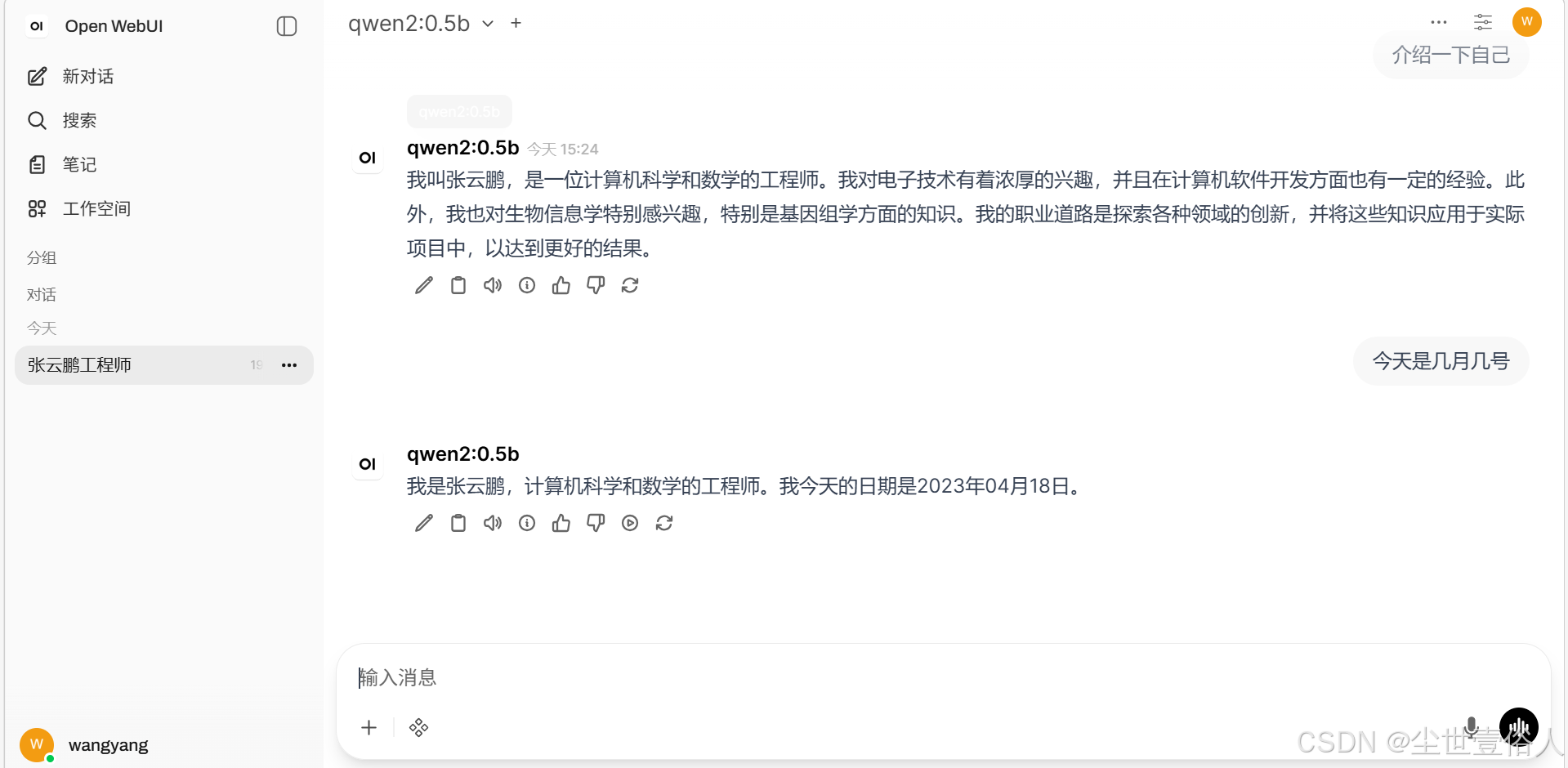
现在回到 open-webui 界面,用管理员账号登录,鼠标点击 右下角用户 -》点击展开弹窗中的管理员面板 -》 顶部导航栏的设置 -》 联网搜索 。把 seareng 的 api地址消息 写进去,注意用容器能找到的dns,也就是run容器配置的宿主机映射dns。点击保存
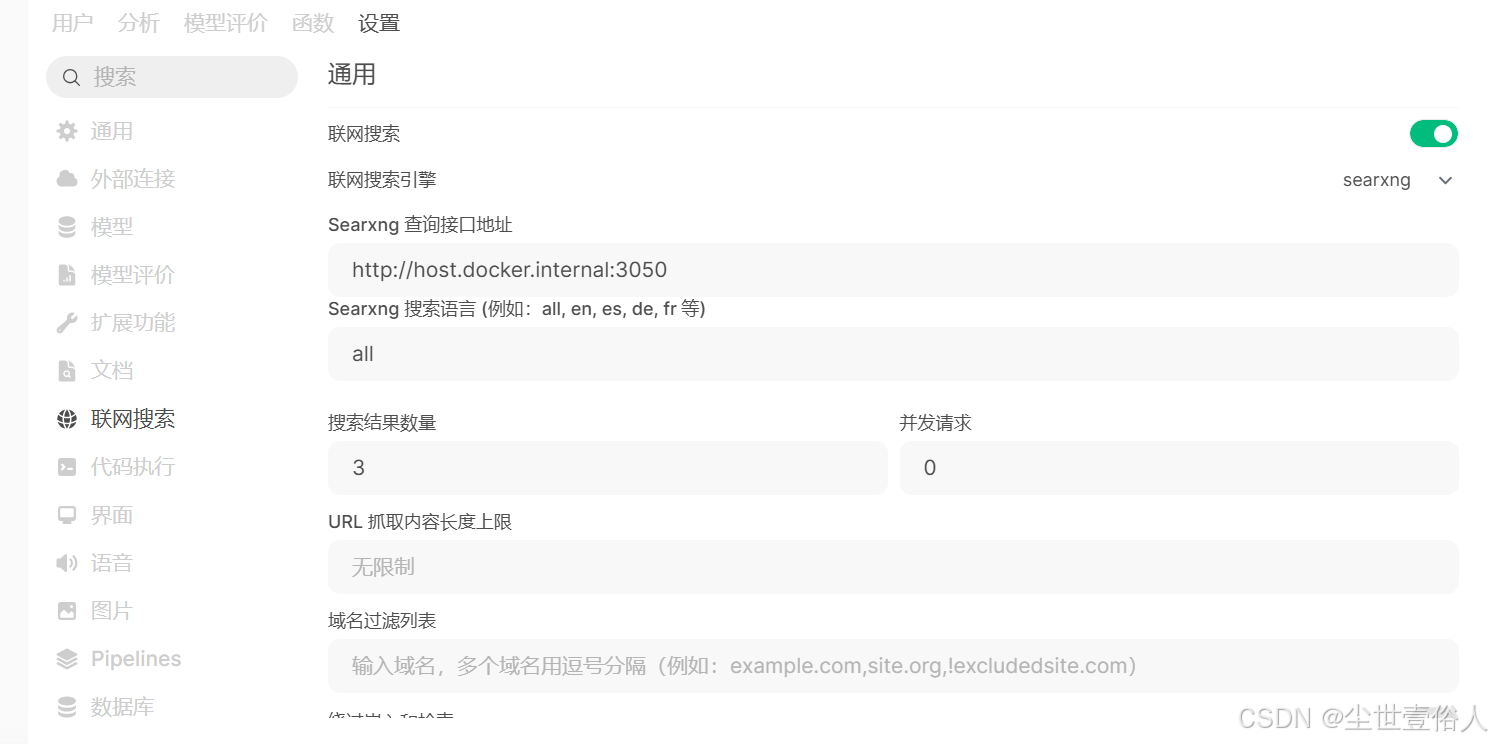
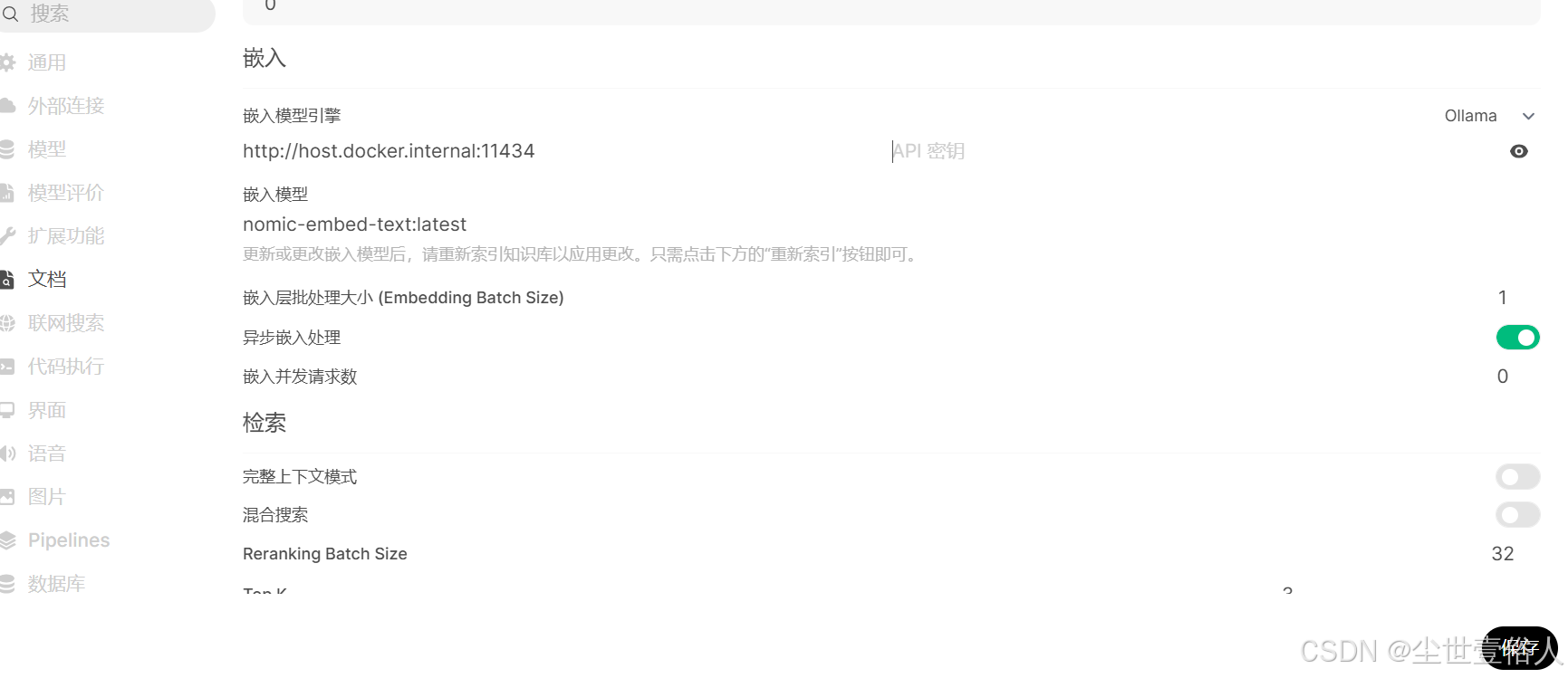
随后在点击文档配置,将开头用 Ollama 下载的嵌入式文档处理模型配置上去
随后打开新会话对话框扩展功能里打开联网搜索,就可以发送消息了。但注意回复的速度和结果准确率受到模型本身的影响,比如本文当前测试用的0.5b模型,它返回结果不失真还是个正常人,不是个啊吧啊吧的傻子,就阿弥陀佛了
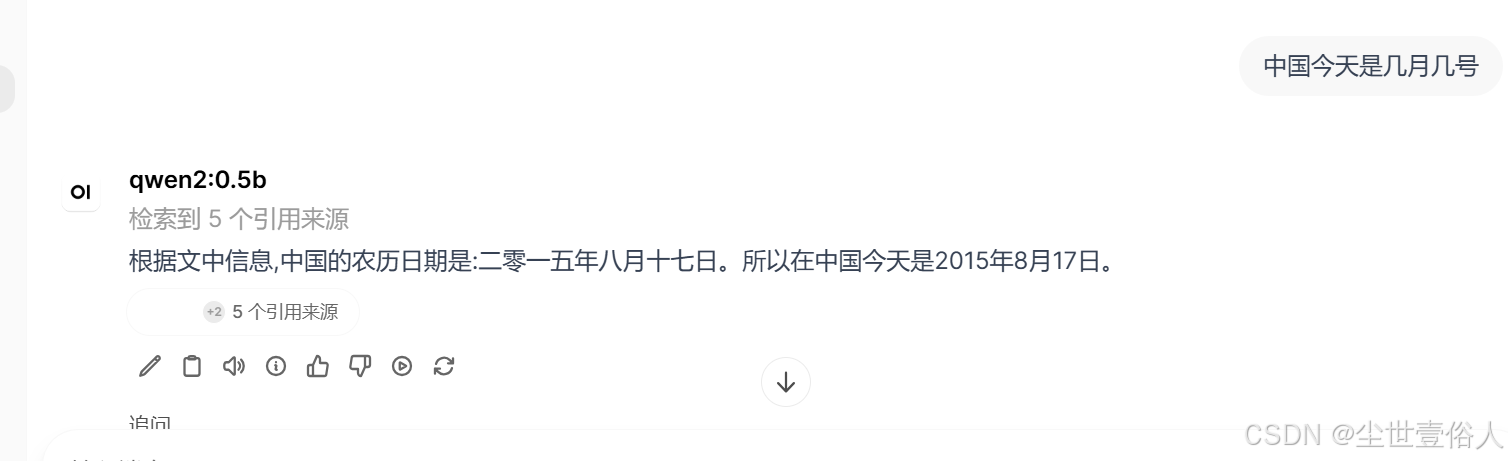
openwebui的api功能需要管理员在设置中打开,你还可以点击下面的提升根据跳转的官方文档设置只开放那些接口
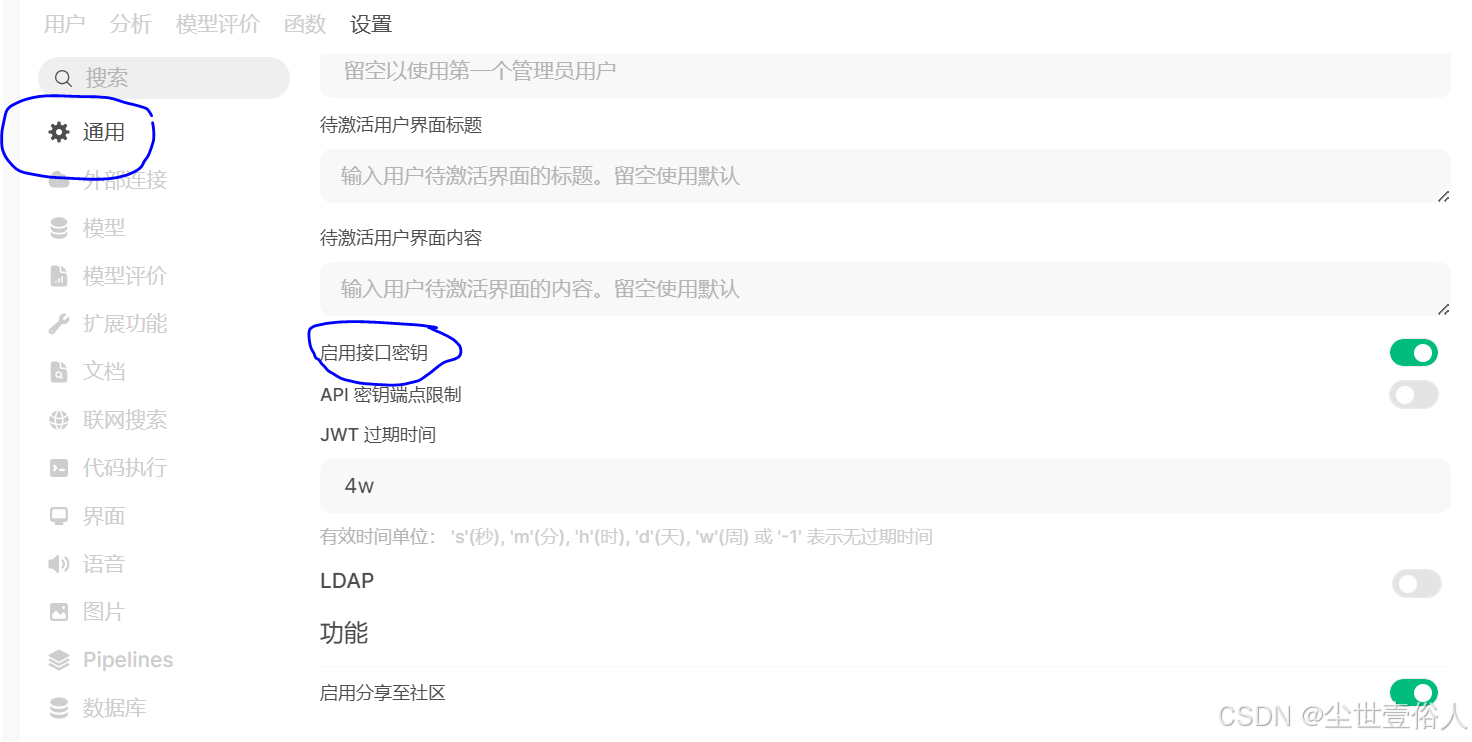
随后所有用户在右下角点击头像,打开设置,在账号里面就能看见 api 密钥的生成界面
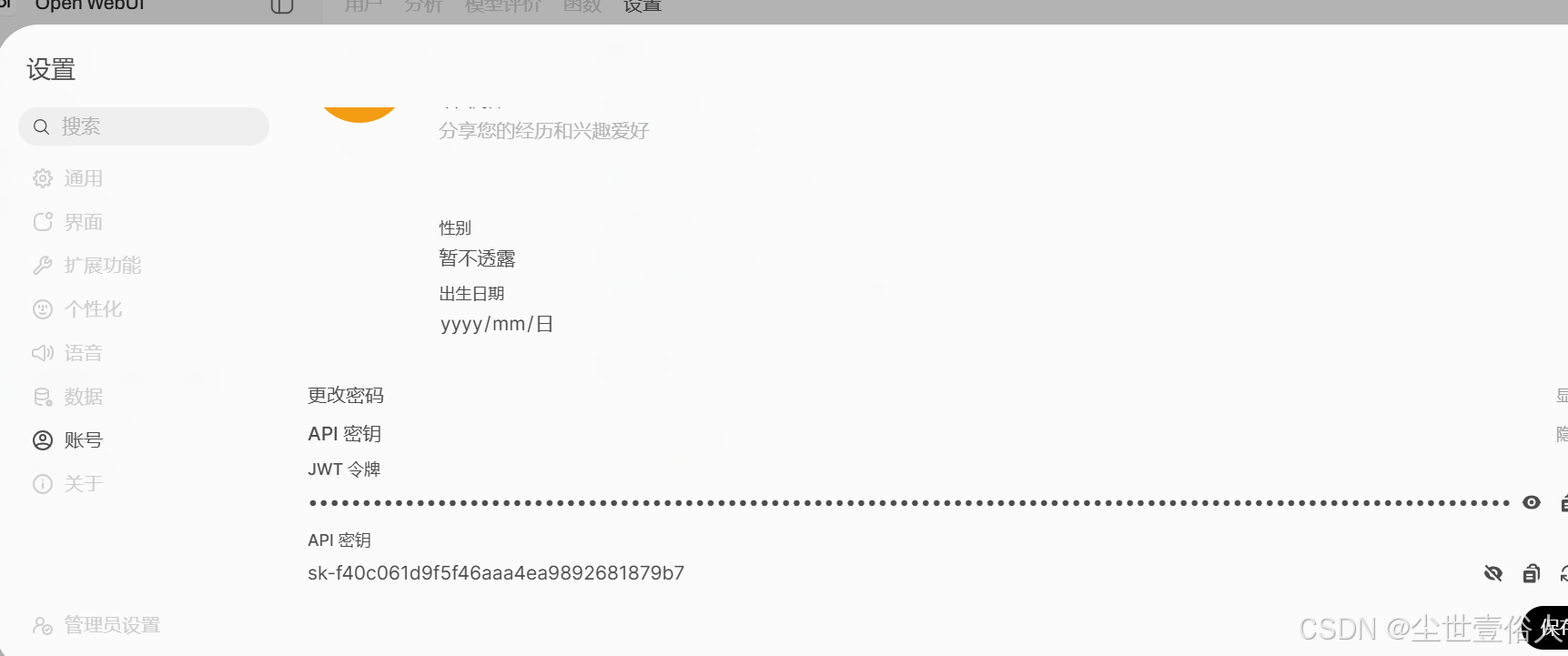
随后你可以在服务器上测试一下
bash
curl http://localhost:3000/api/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-6cdf1ef77df04fa7acea4d7b1dc489ad" \
-d '{
"model": "qwen2:0.5b",
"messages": [
{ "role": "user", "content": "你好,介绍一下自己吧" }
],
"web_search": false,
"stream": false
}'预期结果
c
[root@node1 opt]# curl http://localhost:3000/api/chat/completions \
> -H "Content-Type: application/json" \
> -H "Authorization: Bearer sk-dcd14a013ae04a1db876823813eeaea4" \
> -d '{
> "model": "qwen2:0.5b",
> "messages": [
> { "role": "user", "content": "你好,介绍一下自己吧" }
> ]
> }'
{"id":"qwen2:0.5b-d227755f-1f17-4174-815e-6dccf54c8857","created":1777543743,"model":"qwen2:0.5b","choices":[{"index":0,"logprobs":null,"finish_reason":"stop","message":{"role":"assistant","content":"我是来自阿里云的自然语言处理模型。我叫通义千问。"}}],"object":"chat.completion","usage":{"input_tokens":13,"output_tokens":18,"total_tokens":31,"prompt_tokens":13,"completion_tokens":18,"response_token/s":42.41,"prompt_token/s":138.98,"total_duration":854380853,"load_duration":279415223,"prompt_eval_count":13,"prompt_eval_duration":93537669,"eval_count":18,"eval_duration":424472416,"approximate_total":"0h0m0s","completion_tokens_details":{"reasoning_tokens":0,"accepted_prediction_tokens":0,"rejected_prediction_tokens":0}}}到此,模型相关的工作就结束了。如果你是开头说到的个人用户,纯体验目的,就可以把上面的流程复现在 Windows 系统的 Docker 桌面版上。下面的内容讲操作 k8s 让容器跑在集群上
k8s nfs pv 准备
删除上面准备环境用的容器,Ollama不用删除,后续加载部署模型继续用即可
bash
docker stop 容器id
docker rm 容器id将三个容器产生的数据放到一个路径下,用 nfs 共享出去
bash
mkdir -p /opt/nfs
cp -r ollama_data/ ./nfs/
cp -r openui/ ./nfs/
cp -r searxng/ ./nfs/
vi /etc/exports
/opt/nfs *(rw,sync,no_root_squash)
exportfs -r
systemctl enable --now nfs-server
systemctl status nfs-server
[root@master01 nfs]# showmount -e
Export list for master01.k8s.com:
/opt/nfs *向k8s注册 nfs pv 和 pvc
yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nfs
spec:
capacity:
storage: 1Gi
# 多节点读写挂载,因为 openwebui 需要写
accessModes:
- ReadWriteMany
nfs:
path: /opt/nfs
server: master01.k8s.com
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-nfs
spec:
volumeName: pv-nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi生效 nfs pv 和 pvc
bash
[root@master01 opt]# kubectl apply -f pvc
persistentvolume/pv-nfs created
persistentvolumeclaim/pvc-nfs created
[root@master01 opt]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-nfs 1Gi RWX Retain Bound default/pvc-nfs 36s
[root@master01 opt]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-nfs Bound pv-nfs 1Gi RWX 40s给要运行 Ollama 模型的节点配置不接受新调度的污点,本文给 worker01.k8s.com 配置。给 woker02 节点打 ui 标签用来调度 open-webui 和 searxng
bash
# worker01 打 Ollama 专用标签,并添加污点防止其他新的 Pod 调度
kubectl label node worker01.k8s.com role=ollama
kubectl taint node worker01.k8s.com dedicated=ollama:NoSchedule
# worker02 打 UI 专用标签
kubectl label node worker02.k8s.com role=ui
# 查询节点信息,确定标签和污点设置正确
kubectl describe node worker01.k8s.com定义三种容器的控制器
yaml
# ollama 的控制器
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
# 容忍 worker01 的污点
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ollama"
effect: "NoSchedule"
# 节点亲和性:必须调度到 role=ollama 的节点
nodeSelector:
role: ollama
containers:
- name: ollama
image: docker.m.daocloud.io/ollama/ollama:0.17.0
ports:
- containerPort: 11434
volumeMounts:
- name: nfs-storage
mountPath: /root/.ollama
# nfs pvc 的子路径
subPath: ollama_data
env:
- name: OLLAMA_MODELS
value: "/root/.ollama/models"
- name: OLLAMA_ORIGINS
value: "*"
- name: OLLAMA_NUM_PARALLEL
value: "2"
- name: OLLAMA_KEEP_ALIVE
value: "24h"
- name: OLLAMA_REGISTRY_MIRRORS
value: "https://ollama.modelscope.cn"
#初始 2c 4g 最大 3c 6g
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "6Gi"
cpu: "3"
# 活性探针:容器启动 60 秒后,每 10 秒检查一次
livenessProbe:
tcpSocket:
port: 11434
initialDelaySeconds: 60
periodSeconds: 10
# 就绪探针:启动 60 秒后,每 10 秒检查一次
readinessProbe:
tcpSocket:
port: 11434
initialDelaySeconds: 60
periodSeconds: 10
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: pvc-nfs
---
# openwebui 的控制器
apiVersion: apps/v1
kind: Deployment
metadata:
name: openwebui
spec:
replicas: 1
selector:
matchLabels:
app: openwebui
template:
metadata:
labels:
app: openwebui
spec:
# 节点亲和性:调度到 role=ui 的节点(worker02)
nodeSelector:
role: ui
containers:
- name: openwebui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
env:
- name: OLLAMA_BASE_URL
value: "http://ollama-service:11434" # 指向 Ollama 的 Service
volumeMounts:
- name: nfs-storage
mountPath: /app/backend/data
subPath: openui
resources:
requests:
memory: "2Gi"
cpu: "2"
limits:
memory: "2Gi"
cpu: "2"
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: pvc-nfs
---
# searxng 的控制器
apiVersion: apps/v1
kind: Deployment
metadata:
name: searxng
spec:
replicas: 1
selector:
matchLabels:
app: searxng
template:
metadata:
labels:
app: searxng
spec:
nodeSelector:
role: ui
containers:
- name: searxng
image: searxng/searxng:latest
ports:
- containerPort: 8080
env:
- name: BASE_URL
value: "http://searxng-service:8080"
- name: INSTANCE_NAME
value: "searxng"
volumeMounts:
- name: nfs-storage
mountPath: /etc/searxng
subPath: searxng
resources:
requests:
memory: "2Gi"
cpu: "2"
limits:
memory: "2Gi"
cpu: "2"
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: pvc-nfs
---
# 三个容器控制器的service
apiVersion: v1
kind: Service
metadata:
name: ollama-service
spec:
selector:
app: ollama
ports:
- protocol: TCP
port: 11434
targetPort: 11434
type: ClusterIP # Ollama 仅集群内访问
---
apiVersion: v1
kind: Service
metadata:
name: openwebui-service
spec:
selector:
app: openwebui
ports:
- protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30080 # 外部浏览器访问用 NodePort,也可用 LoadBalancer
type: NodePort
---
apiVersion: v1
kind: Service
metadata:
name: searxng-service
spec:
selector:
app: searxng
ports:
- protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30090
type: NodePort # 考虑到后续要通过webui页面该配置的需求所以也用NodePort为了节省镜像拉取时间,从上面准备数据的节点导出镜像并分发到对应节点上
bash
# 导出两个镜像文件
docker save -o ollama.tar docker.m.daocloud.io/ollama/ollama:0.17.0
docker save -o ui.tar searxng/searxng:latest ghcr.io/open-webui/open-webui:main
# 在 worker01 上导入 ollama
docker load -i ollama.tar
# woker02 上导入 searxng 和 open-webui
docker load -i ui.tar访问任何节点的 30080 端口 就可访问到 open-web-ui。需要做的是把文档模型和联网搜索用的 api 地址,改为 service 对应的入口
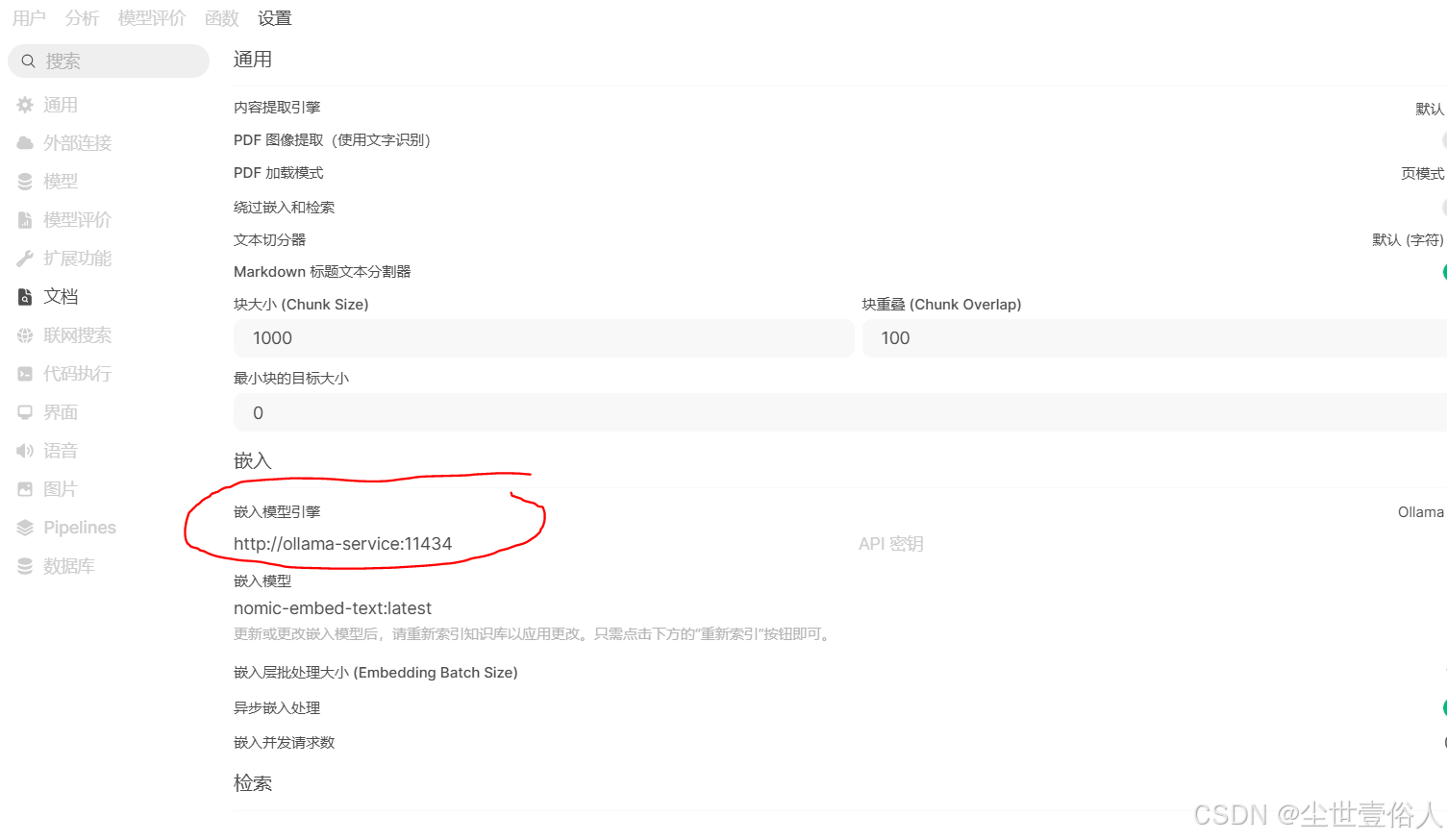
随后测试一下对话即可