论文:RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
arXiv: 2604.06870 (2026.04)
1. 研究动机

当前的图像生成模型(如 GPT-Image、Gemini、Qwen-Image 等)在全局构图上已经做得不错,但在局部细节上仍然经常翻车------文字扭曲、logo 变形、细线条断裂等问题非常常见。这类问题在电商产品图、广告、UI 设计等对细节敏感的场景中尤其致命。
现有的指令驱动编辑模型主要做的是粗粒度的语义编辑,面对局部细节修复存在三个核心问题:
- 区域可控性差:很难精确指定需要修复的区域
- 微细节恢复弱:细微缺陷(如断裂的文字笔画)往往修不好
- 背景漂移:修复目标区域时,非目标区域也会被意外改动
因此作者提出了一个专门的问题设定------区域特定图像精细化(Region-Specific Image Refinement):给定输入图像和用户指定的区域(涂鸦 mask 或 bounding box),恢复该区域的细粒度细节,同时严格保持背景不变。
2. 方法概览
2.1 整体架构
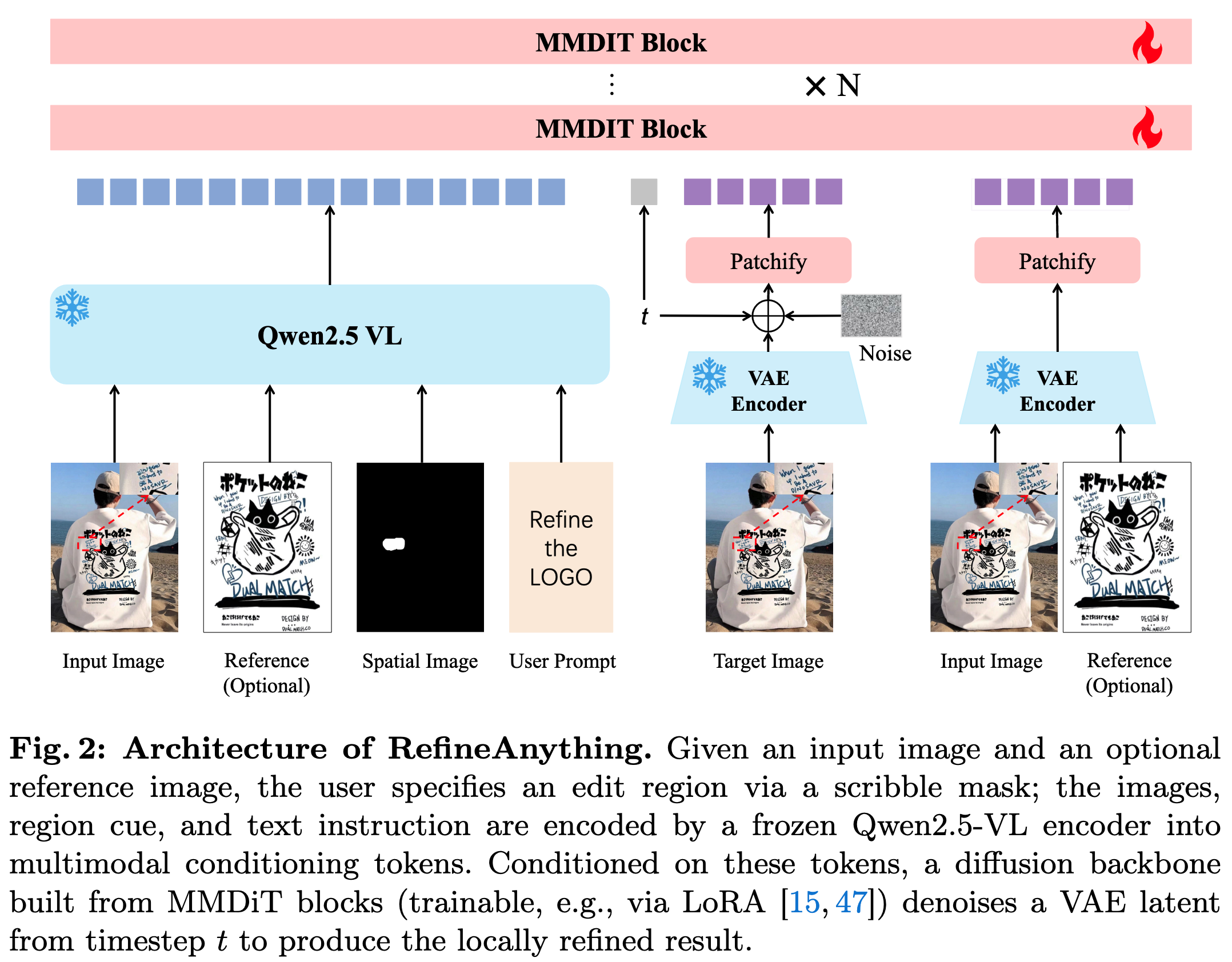
RefineAnything 基于 Qwen-Image 构建,包含三个核心组件:
- 冻结的多模态编码器(Qwen2.5-VL):将输入图像、可选的参考图像、区域标注和文本指令编码为多模态条件 token,提供高层语义引导
- VAE 编码器:将输入图和参考图编码为潜空间表示,提供低层细粒度视觉上下文
- MMDiT 去噪骨干网络 :在多模态 token 和 VAE latent 的双重条件下,对目标 latent 进行去噪
训练时只用 LoRA(rank=256)微调 MMDiT 中 attention 的投影层,效率很高。
2.2 Focus-and-Refine(核心创新)
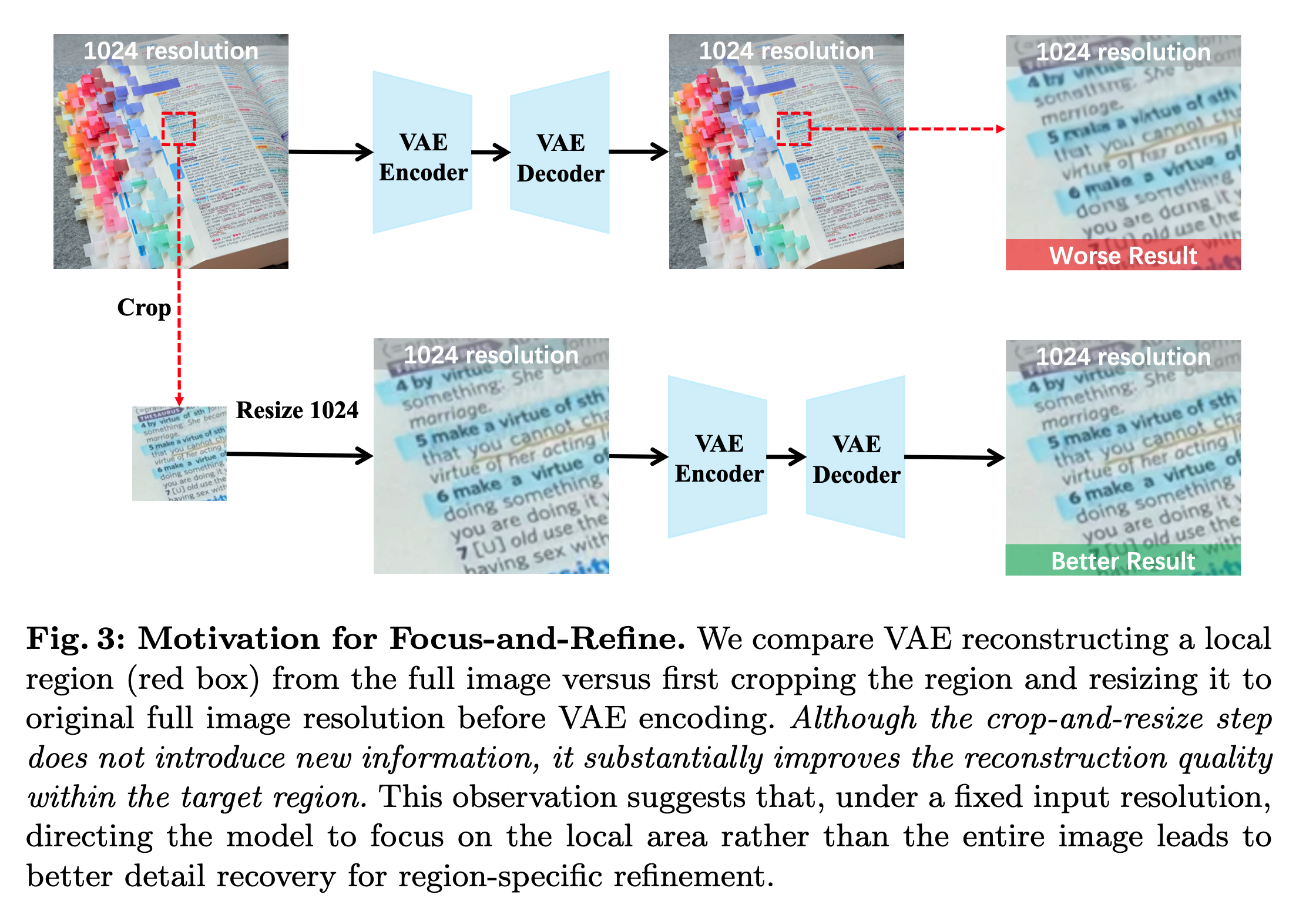
这是本文最关键的设计,源于一个反直觉的观察:
在固定输入分辨率(如 1024×1024)下,将目标区域裁剪出来并 resize 到全图分辨率后再做 VAE 编码-解码,虽然没有引入任何新信息,但重建质量却显著提升。
换句话说,限制局部修复质量的不是信息量不够,而是模型的固定分辨率容量没有被分配到正确的位置。
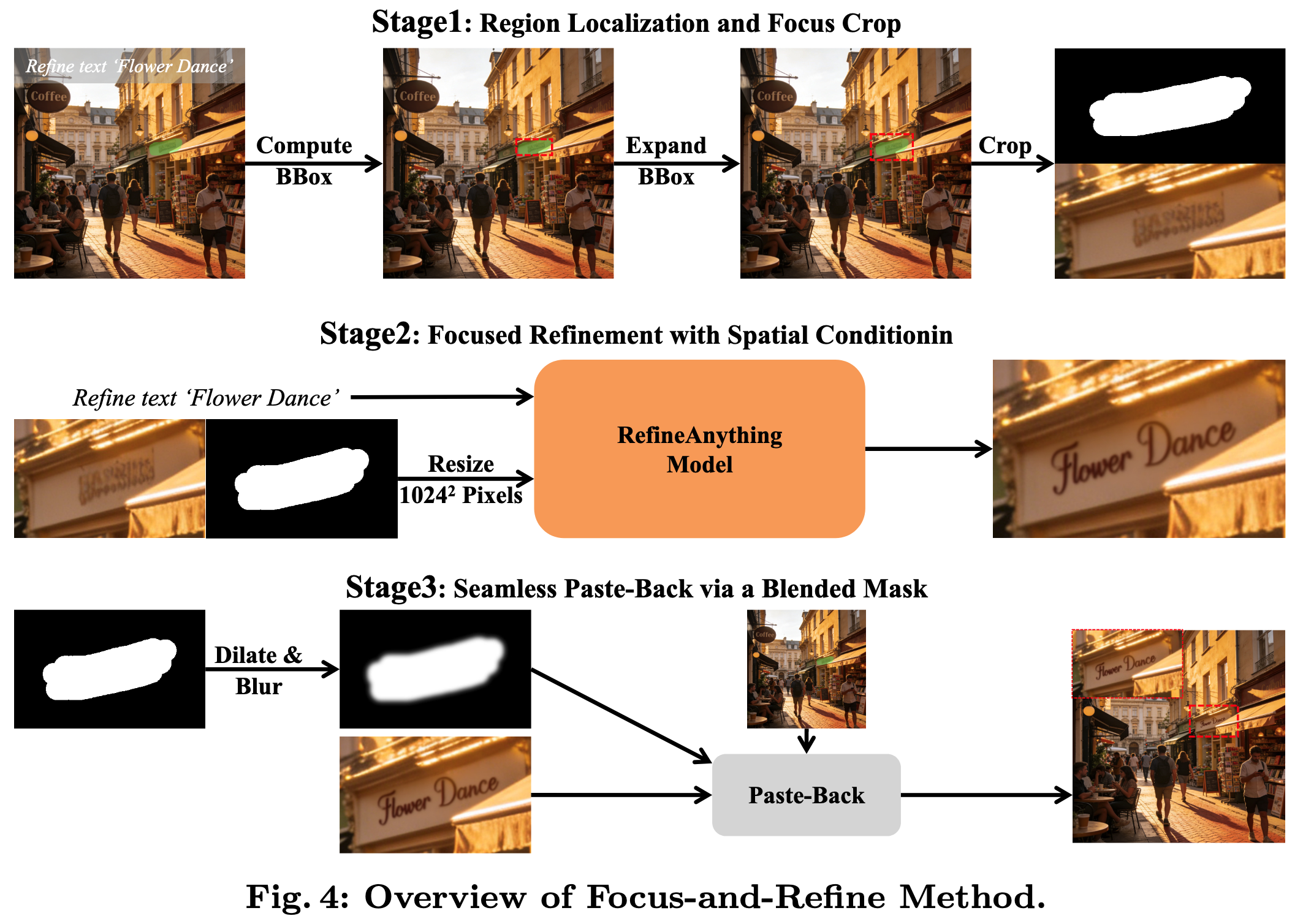
基于此观察,Focus-and-Refine 分三步走:
Step 1:区域定位与裁剪
- 根据用户提供的 mask/bbox 计算紧凑边界框
- 扩展一定 margin(m=64)提供局部上下文
- 裁剪并 resize 到模型输入分辨率
Step 2:聚焦式生成
- 在裁剪后的视图上,用裁剪后的 scribble mask 作为空间条件
- 结合可选的参考图和文本指令,进行条件生成
Step 3:无缝粘贴回原图
- 对 mask 做形态学膨胀 + 高斯模糊,得到 blended mask
- 用 blended mask 做 alpha 混合,将修复结果粘贴回原图
- 保证背景严格不变,同时消除拼接边缘伪影
2.3 Boundary Consistency Loss
为了进一步减少粘贴边界处的缝隙伪影,作者提出了边界一致性损失。核心思想是在编辑边界附近的区域加大训练监督权重:
- 定义一个边界带:对 mask 做膨胀减去腐蚀
- 在 flow-matching 去噪目标的基础上,对边界带区域的 loss 乘以权重 (1 + α),α=9
这使得模型在训练时特别关注边界区域的一致性。
3. 数据构建:Refine-30K
作者构建了 30K 样本的训练数据集,分为两个子集:
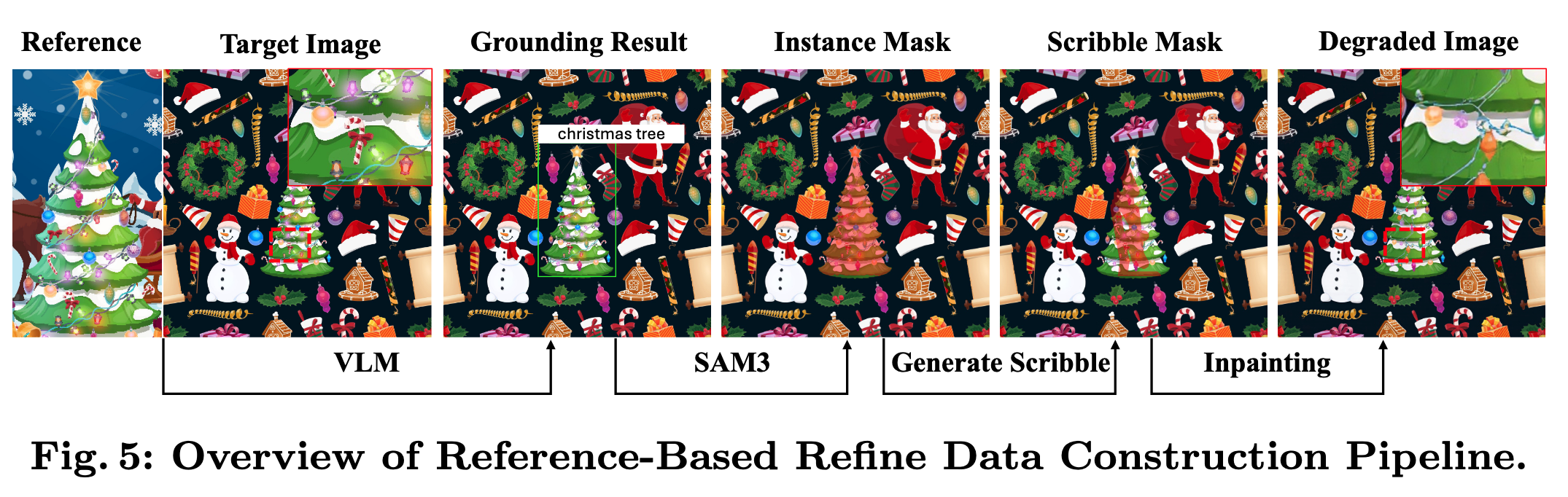
Reference-Based(20K 样本)
这个子集的核心场景是:用户手里有一张参考图(比如产品 logo 的标准图),希望把生成图中变形的对应区域修复成参考图的样子。训练数据的构建需要造出"退化-修复"的配对样本。
每个样本由一对图像 (I^ref, I*) 出发,其中 I^ref 是参考图,I* 是包含该参考物体的目标图(即 ground truth)。构建流程如下:
① 跨图 Grounding(VLM)
用 Gemini3 同时看参考图和目标图,找到参考图中最显著的主体(比如一双鞋、一个 logo),确认它也出现在目标图中,并在目标图上输出一个 bounding box。这一步做了严格的主体一致性校验,只保留 VLM 高置信度匹配的样本对。
② 精细分割(SAM3)
Bounding box 可能框进多余的背景。因此用 SAM3 在目标图上、以 VLM 给出的 bbox 和文本描述为条件做实例分割,得到精确的物体 mask M_obj。限制为单实例 mask,避免歧义。
③ 合成退化(Scribble + Inpainting)
在 M_obj 的膨胀区域内随机采样涂鸦笔画,得到 inpainting mask M。然后用 inpainting 模型对目标图 I* 的 mask 区域进行"破坏性重绘",生成退化图 I。再做一次轻度 paste-back blending,确保退化图和 GT 仅在 mask 区域内不同。这样就人工制造出了"局部细节崩坏"的输入。
④ 组装样本
最终每个样本存储为 (I, I^ref, I*, M, y),其中 y 是基于 VLM 描述生成的精细化指令(如 "Refine the logo on the shirt")。
简单来说:先找到参考图和目标图之间的对应物体 → 精确分割 → 人为把目标图的对应区域搞坏 → 搞坏的图就是训练输入,原图就是 GT。
Reference-Free(10K 样本)
这个子集对应的场景是:用户没有参考图,只给一句文本指令(如 "修复这个人的脸"),让模型自己判断该怎么修。数据从单张图像出发构建。
① 显著物体定位(VLM)
给定单张图像 I*,用 Gemini3 检测图中的显著物体,输出一组候选 bounding box 及文本描述。随机采样一个物体,保证训练数据覆盖不同类别和尺度。
② 分割与退化(SAM3 + Inpainting)
与 reference-based 子集的流程完全一致:SAM3 精细分割 → 涂鸦 mask → Inpainting 退化 → paste-back blending。
③ VLM 缺陷验证(关键步骤)
这是 reference-free 子集特有的质量控制环节。并不是所有合成退化都能产生有意义的修复任务------有些退化太轻微看不出来,有些退化在语义上不合理(比如把天空 inpaint 出奇怪纹理)。因此用 VLM 对退化图做二次审查,过滤掉两类无效样本:(a) 退化不明显、看不出缺陷的;(b) 退化结果语义不一致/不合理的。
④ 组装样本
最终存储为 (I, I*, M, y),其中 y 是纯文本指令(如 "Refine {object} in the masked region"),没有参考图。
简单来说:随机选一个物体搞坏它 → 用 VLM 检查搞坏的效果是否"够坏但合理" → 通过检查的才留下来当训练数据。
4. 评估体系:RefineEval
作者构建了 RefineEval benchmark,包含 67 个 case × 3 种退化方法 × 2 张图 = 402 个测试样本。
Reference-Based 评估指标
评估逻辑很直观:前景区域(编辑区域)和 GT 比,看修得像不像;背景区域和原输入图比,看有没有被改动。
前景指标(修复区域 vs GT):
| 指标 | 全称 | 衡量什么 | 直觉理解 | 方向 |
|---|---|---|---|---|
| MSE | Mean Squared Error | 像素级误差 | 逐像素算差值的平方再取均值,最原始的"图像差多少"度量 | ↓越小越好 |
| SSIM | Structural Similarity | 结构相似性 | 从亮度、对比度、结构三个维度衡量两张图的感知相似度,比 MSE 更符合人眼感知 | ↑越大越好 |
| LPIPS | Learned Perceptual Image Patch Similarity | 感知距离 | 用预训练网络(如 VGG/AlexNet)提特征,在特征空间算距离。两张图看起来越像,LPIPS 越小 | ↓越小越好 |
| VGG | VGG Perceptual Loss | 感知特征距离 | 和 LPIPS 类似,用 VGG 网络的中间层特征计算距离,关注纹理和风格层面的差异 | ↓越小越好 |
| DINO | DINOv2 Large Similarity | 高层语义相似度 | 用自监督视觉模型 DINOv2 提特征算余弦相似度,关注"是不是同一个物体/同一种语义" | ↑越大越好 |
| CLIP | CLIP ViT-L/14 Similarity | 跨模态语义相似度 | 用 CLIP 视觉编码器提特征算相似度,衡量图像在视觉-语言对齐空间中的语义一致性 | ↑越大越好 |
这些指标从不同层次衡量修复质量,可以粗略理解为一个从底层到高层的梯度:
这些指标从不同层次衡量修复质量,可以粗略理解为一个从底层到高层的梯度:
像素级精确度 感知相似度 语义一致性
MSE ← SSIM ← LPIPS/VGG ← DINO ← CLIP
(底层) (高层)MSE/SSIM 在像素空间直接算,关注的是"每个像素数值差多少";LPIPS/VGG 把图像过一遍预训练 CNN,在中间层特征上算距离,捕捉的是纹理、边缘、风格这些中层感知信息;DINO/CLIP 用的是更强的视觉基础模型提特征,关注的是高层语义------"是不是同一个东西"。
背景指标(非编辑区域 vs 原输入图):
| 指标 | 衡量什么 |
|---|---|
| MSE_bg | 背景像素级变化,理想值为 0(完全没动) |
| LPIPS_bg | 背景感知距离,理想值为 0 |
| SSIM_bg | 背景结构相似度,理想值为 1(完全一致) |
RefineAnything 在背景指标上拿到了接近完美的分数(MSE_bg=0.000, SSIM_bg=0.9997),这得益于 Focus-and-Refine 的 blended mask paste-back 机制------背景区域的像素是直接从原图复制的,根本不经过模型。
5. 实验结果
Reference-Based 精细化
| 方法 | MSE↓ | LPIPS↓ | DINO↑ | CLIP↑ | SSIM↑ | MSE_bg↓ | SSIM_bg↑ |
|---|---|---|---|---|---|---|---|
| Kontext | 0.040 | 0.264 | 0.685 | 0.785 | 0.538 | 0.011 | 0.9660 |
| Qwen-Edit | 0.049 | 0.287 | 0.675 | 0.807 | 0.436 | 0.454 | 0.7530 |
| Gemini3 | 0.031 | 0.178 | 0.771 | 0.855 | 0.510 | 0.029 | 0.9061 |
| Ours | 0.020 | 0.155 | 0.793 | 0.885 | 0.591 | 0.000 | 0.9997 |
核心结论:
- 相比最强开源 baseline(Kontext),MSE 降低 50%,LPIPS 降低 41%
- 背景保持几乎完美:MSE_bg ≈ 0,SSIM_bg ≈ 1
Reference-Free 评估指标
没有参考图就没有像素级 GT 可以对比,所以改用 VLM(Gemini2.5-Pro)做主观评分,五个维度各打 1-5 分:视觉质量(VQ)、自然度(Nat.)、美学(Aes.)、细节保真度(Det.)、指令忠实度(Faith.)。
消融实验
- 去掉 Focus-and-Refine → 前景指标明显下降,背景保持也变差
- 去掉 Boundary Consistency Loss → 前景指标下降,边界处出现可见缝隙和颜色不一致
6. 个人思考
亮点:
- Focus-and-Refine 的 motivation 非常 elegant:一个简单的 crop-resize 操作就能大幅提升局部重建质量,这个观察本身就很有价值
- 问题定义清晰,pipeline 实用性强,blended mask 保证了背景严格不变
- 数据构建流程设计合理,特别是 VLM-based defect validation 的引入
值得商榷的地方:
- "反直觉"这个说法有点过了。 论文把 crop-resize 提升局部重建质量称为 "counter-intuitive observation",但仔细想想其实挺符合直觉的:VAE 的 latent 空间容量是固定的,整张图编码时容量分摊给所有区域,裁剪放大后容量集中给了目标区域,重建质量自然更好。这更像是一个合理的工程思路,而非反直觉的发现。
- 实验对比存在不对等。 RefineAnything 的流程是"先裁剪局部 → 模型编辑 → 贴回原图",而所有 baseline(Kontext、Qwen-Edit、BAGEL 等)都是直接对整张图做编辑,没有经过 crop-paste-back 这一步。这导致两个不公平:一是背景指标上 RefineAnything 天然接近满分(背景像素直接从原图复制),二是前景指标上 RefineAnything 也占了把分辨率集中在局部的优势。一个更公平的消融应该是:给所有 baseline 也加上同样的 crop-resize + paste-back 流程,再比较前景修复效果。 论文的消融实验(Tab. 3)只对比了自己有无 Focus-and-Refine,没有把这个策略应用到其他 baseline 上,所以很难判断提升到底来自模型本身还是来自 crop-paste-back 这个trick。