过去两年,大模型的"记忆力竞赛"几乎成了一场军备竞赛。从4K到128K,从128K到1M,上下文窗口的数字越来越大,厂商的宣传越来越响亮。
但你有没有注意到一个尴尬的事实------窗口越大,模型越"健忘"?
Qwen2.5-Instruct-1M号称支持百万Token,但在实际测试中,当输入达到896K时准确率直接归零。DeepSeek-R1-Distill-Qwen-32B在56K之后性能断崖式下跌。QwenLong-L1-32B在超过训练长度60K后也迅速崩塌。下面这张图把问题展示得一目了然------
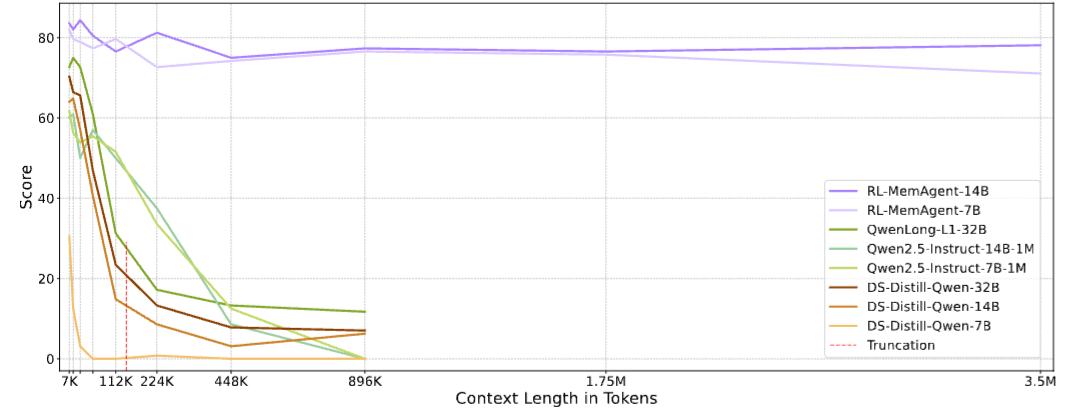
图1
图1:各模型在RULER-HotpotQA基准上的准确率随上下文长度变化曲线。RL-MemAgent-14B和7B在7K到3.5M范围内几乎保持水平,而所有基线模型都在某个长度后急剧下跌至接近零。
这些模型的上下文窗口是"名义上的"------就像一个号称能装100本书的书架,你真放上去,它就塌了。
问题的根源不在于模型不够大,而在于Transformer的注意力机制本身。全局注意力的计算复杂度是O(n²)------上下文长度翻一倍,计算量翻四倍。当文本从4K膨胀到百万级别,这个二次方的代价就从"可以忍受"变成了"不可承受"。
长文本处理的三条主流路线------位置编码外推、稀疏/线性注意力、上下文压缩------各有各的死穴。位置编码外推(如NTK、YaRN、DCA)修改位置嵌入来扩展窗口,但O(n²)的复杂度没变,越长越慢,而且外推时性能衰减严重。稀疏注意力和线性注意力(如Mamba、RWKV)虽然把复杂度降到了O(n),但通常需要从头训练,而且稀疏模式依赖人工设计,灵活性不足。上下文压缩方案(如LLMLingua、Titans)试图把信息浓缩到更少的Token里,但压缩过程本身会破坏标准生成流程,外推能力也很有限。
三条路都没有同时解决长文本处理的"不可能三角":无限长度、无损性能、线性复杂度。
就在这个节点上,清华大学AIR(智能产业研究院)与字节跳动Seed联合实验室SIA-Lab提出了MemAgent------一个用强化学习训练的记忆智能体,把任意长度的文本处理变成了一个"分段阅读+记忆覆写"的流式过程。
研究团队由清华AIR的周浩、王明轩领衔,核心成员包括余弘立、陈廷弘、冯江涛、陈江杰等,横跨字节跳动Seed和清华AIR两大机构。清华AIR在大模型训练和强化学习领域有深厚积累,字节跳动Seed则在工程化落地方面经验丰富。这支团队的组合,恰好覆盖了MemAgent所需的"算法创新+工程实现"两条腿。
1. 人类读长文的方式,才是正确答案
MemAgent的核心直觉来自一个朴素的观察:人类从来不会试图"记住"一本书的每一个字。
你读一本500页的小说,不会把每个句子都刻在脑子里。你会做笔记,记下关键情节、重要人物、核心转折------然后在需要的时候翻看笔记,而不是重读整本书。你的"记忆"是一个不断更新的摘要,旧的不重要的信息会被新的关键信息覆盖。
MemAgent做的事情完全一样。它把一篇超长文档切成固定大小的片段(chunk),每读完一个片段,就用一段固定长度的"记忆"(memory)来记录到目前为止最重要的信息。读下一个片段时,模型看到的只有两样东西:当前片段 + 之前的记忆。读完后,记忆被覆写为新版本。
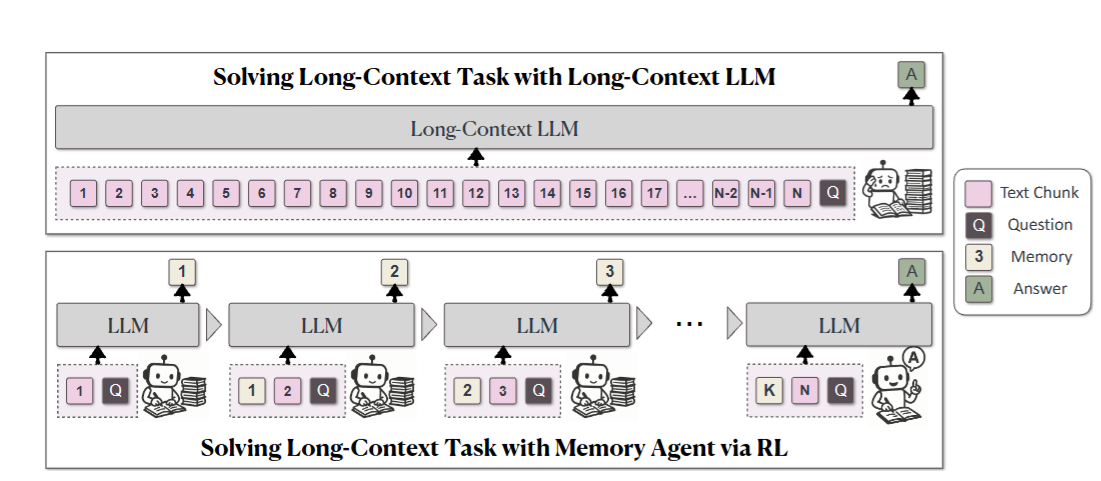
图2
图2:MemAgent工作流示意图。上半部分是传统长文本LLM的处理方式(一次性读取全部内容),下半部分是MemAgent的分段处理流程------将文档切分为N个chunk,逐个读取并更新固定长度的记忆,最后基于记忆生成答案。
这个设计看起来几乎"过于简单"------但正是这种简单,让它能够无限扩展。
因为记忆长度是固定的(1024个Token),每处理一个片段的计算量是恒定的O(1)。整个文档的处理复杂度严格线性于片段数量,即O(N)。不管你的文档是10万Token还是350万Token,每一步的计算开销完全相同。
2. 覆写策略:为什么"忘记"比"记住"更重要
MemAgent的记忆更新采用的是覆写策略(overwrite strategy)------每读完一个新片段,旧记忆被完全替换为新记忆。
这听起来很激进。为什么不是追加?为什么不是选择性更新?
答案藏在"固定长度"这个约束里。如果记忆可以无限增长,那它本质上就退化成了"把所有内容都存下来",和直接扩大上下文窗口没有区别。覆写策略强制模型做一件事:在有限的1024个Token里,决定什么值得保留,什么应该丢弃。
这就像你的笔记本只有一页纸。每读完一章,你必须重新写这一页------你可以保留之前的关键信息,也可以用新发现的更重要的信息替换掉旧内容。这个"取舍"的能力,才是长文本理解的核心。
更关键的是,这个取舍不是靠规则定义的,而是靠强化学习训练出来的。模型通过大量试错,学会了哪些信息对最终回答有用、哪些是干扰项。保留有用信息的记忆会得到奖励,保留无用信息的记忆会被惩罚。
这意味着什么?意味着MemAgent的"记忆力"不是工程师手动设计的压缩规则,而是模型自己学会的信息筛选能力。
3. 两阶段工作流:读与答的分离
MemAgent的推理过程被自然地分解为两个模块。
第一个是上下文处理模块(Context-Processing),如表1中上半部分。模型逐个读取文档片段,每读完一个片段就更新记忆。提示模板很直接:

表1
第二个是答案生成模块(Answer-Generation),如表1的下半部分。当所有片段都读完后,模型只看问题和最终记忆来生成答案:
它不再接触原始文档的任何内容------所有需要的信息都应该已经被浓缩在记忆里了。
这种"读写分离"的设计有一个被低估的优势:位置编码从头到尾都不需要修改。每一轮对话的上下文窗口大小是固定的(8K),模型用的是完全标准的Transformer解码器,没有任何架构改动。这意味着MemAgent可以直接套用在任何现有的LLM上,不需要从头训练,不需要特殊的注意力核,不需要额外的模块。
翻译成人话------MemAgent把一个"需要超长上下文窗口的难题"变成了"多轮短对话的简单任务"。
4. Multi-Conv DAPO:如何训练一个跨对话的智能体
MemAgent的训练是整篇论文最有技术含量的部分。
传统的RLVR(基于可验证奖励的强化学习)训练流程很直接:给模型一个问题,模型生成一个回答,用规则验证回答是否正确,然后用奖励信号更新模型。但MemAgent的情况完全不同------一个问题会产生多轮对话(多次记忆更新 + 最终回答),而且这些对话之间的上下文是独立的。
为什么上下文是独立的?因为每轮对话的输入是"当前片段 + 当前记忆",而不是"所有历史对话的拼接"。模型在第3轮看不到第1轮的原始输入,只能通过记忆间接获取之前的信息。
这给训练带来了一个根本性的挑战:现有的多轮对话RL方法(如Search-R1、Agent-R1)都是把工具调用和模型回复交替拼接成一个长序列来优化的。但MemAgent的多轮对话不能简单拼接------它们的上下文是独立的。
团队的解决方案是Multi-Conv DAPO(多对话DAPO算法)。核心思想是:把每轮对话视为独立的优化目标,但共享同一个奖励信号。
具体来说,对于一个问题,模型生成一组rollout,每个rollout包含多轮对话(记忆更新)和一个最终回答。奖励只由最终回答的正确性决定------用规则验证器检查答案是否匹配标准答案。然后,这个奖励信号被均匀分配到该rollout的所有对话上。
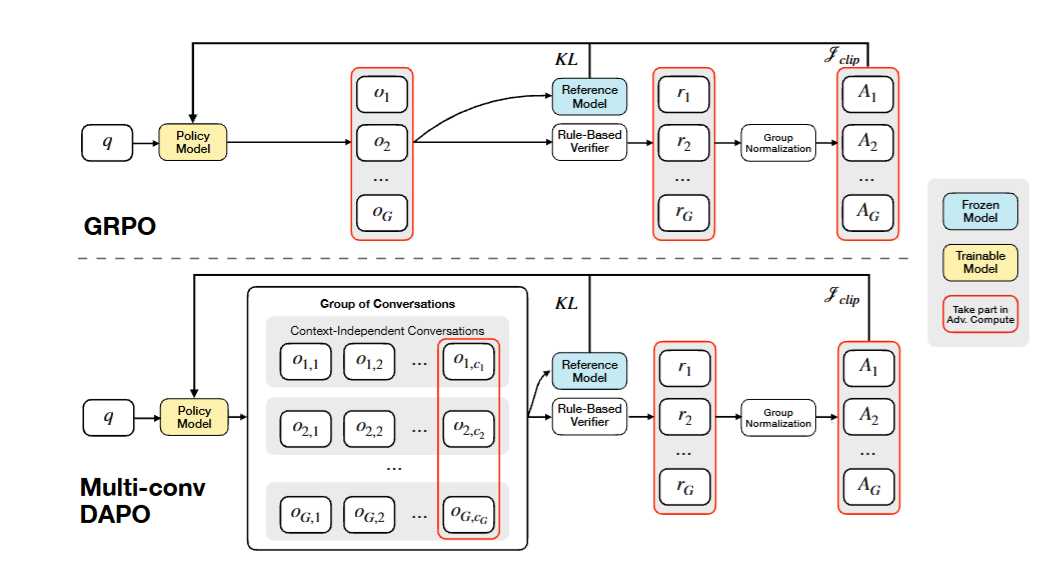
图3
图3:Multi-Conv DAPO与标准GRPO的训练流程对比。左侧是标准GRPO(每个query生成一个output),右侧是Multi-Conv DAPO(每个query生成多轮独立对话o₁,₁、o₁,₂...o₁,c₁,最终对话的奖励r₁反向传播到所有对话)。关键区别在于优化目标从单一对话扩展到了多轮独立上下文对话。
传统GRPO的优化维度是(组,Token),Multi-Conv DAPO把它扩展到了(组,对话,Token)三个维度。这不是简单的维度增加------它意味着模型不仅要学会"怎么回答问题",还要学会"怎么在中间步骤记录有用信息"。
这是一个关键的设计选择。因为记忆Token是隐变量------它们没有直接的监督信号(没有人告诉模型"好的记忆长什么样"),只有最终答案的对错作为间接反馈。Multi-Conv DAPO通过把最终奖励传播到所有中间步骤,让模型自己发现"什么样的记忆能导向正确答案"。
5. 从自回归建模的视角重新理解MemAgent
论文提供了一个优雅的理论视角来理解MemAgent的本质。
标准的自回归语言模型把序列的联合概率分解为:
这个分解隐含地要求所有历史Token(或至少它们的隐藏状态)都必须留在活跃上下文中。这正是二次方注意力成为长文本瓶颈的根源。
MemAgent引入了一个固定长度的隐变量记忆m,把原始的似然函数分解为:
其中 是"读"路径------基于当前记忆理解新片段; 是"写"路径------基于新片段和旧记忆生成新记忆。
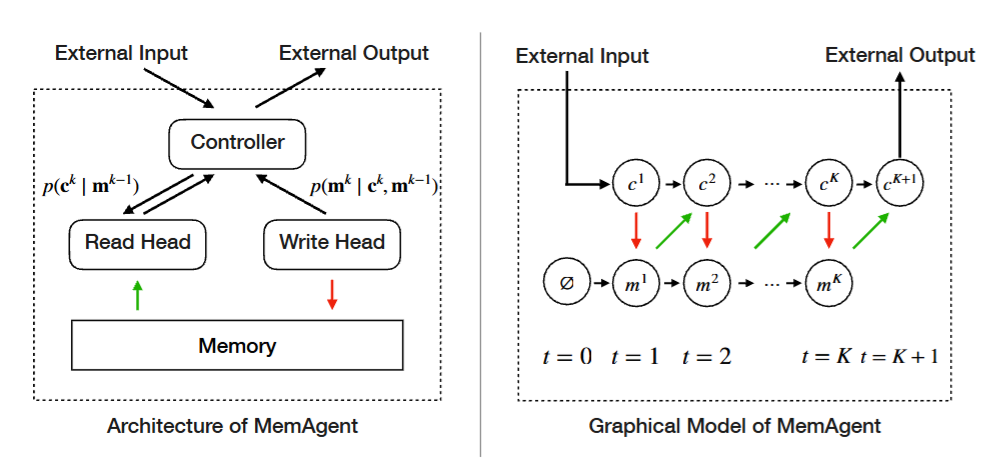
图4
图4:MemAgent的架构图和概率图模型。左侧展示了Controller(控制器)、Read Head(读头)、Write Head(写头)和Memory(记忆)的交互关系;右侧是对应的概率图模型,展示了从t=0到t=K+1的记忆状态转移过程,每一步都包含p(cₖ|mₖ₋₁)的读操作和p(mₖ|cₖ,mₖ₋₁)的写操作。
一句大白话总结------MemAgent本质上把Transformer变成了一个循环网络,但状态大小是用户可控的。
这个视角揭示了MemAgent和其他长文本方案的本质区别。线性注意力模型(如Mamba)也在做上下文压缩,但它们的压缩发生在特征空间------隐藏状态是不透明的向量,人类无法理解也无法干预。MemAgent的压缩发生在Token空间------每一步的记忆都是人类可读的文本,你可以检查它、编辑它、甚至用它来调试模型的行为。
这不是一个小区别。这是"黑箱压缩"和"白箱压缩"的分水岭。
6. 实验:8K训练,350万外推,性能几乎不掉
实验设置值得仔细看。
训练数据:从HotpotQA训练集中合成了32768个样本,每个样本约28K Token。团队做了一个聪明的数据清洗------过滤掉了模型不需要上下文就能回答的问题(这些问题的答案已经被模型"记住"了,用它们训练没有意义)。
训练窗口:仅8K Token。其中1024给问题,5000给文档片段,1024给记忆,1024给输出。模型通常需要5-7轮对话来处理完整个上下文。
基线模型:DeepSeek-R1-Distill-Qwen系列(7B/14B/32B)、Qwen2.5-Instruct-1M系列(7B/14B)、QwenLong-L1-32B。
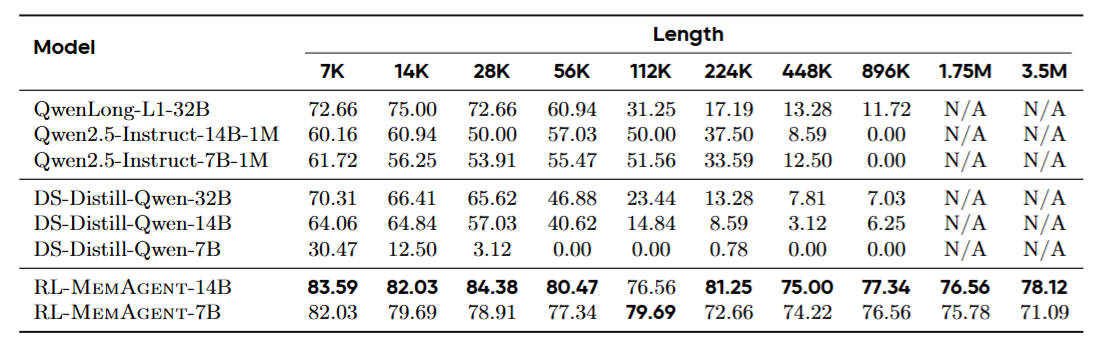
表2
表2:主实验结果对比表。展示了各模型在7K、14K、28K、56K、112K、224K、448K、896K、1.75M、3.5M十个长度档位上的准确率。RL-MemAgent-14B在整个范围内准确率稳定在75%-84%之间,而所有基线模型都在某个长度后出现断崖式下跌------Qwen2.5-Instruct-14B-1M在896K时归零,DS-Distill-Qwen-32B在112K后跌破25%,QwenLong-L1-32B在224K后跌至17.19%。
几个关键数字:
-
RL-MemAgent-14B在3.5M Token时的准确率是78.12%,而它在7K时是83.59%。性能损失仅5.47个百分点。
-
RL-MemAgent-7B在3.5M时是71.09%,7K时是82.03%。一个7B模型,用8K窗口训练,在350万Token的任务上仍然保持71%的准确率。
-
作为对比,QwenLong-L1-32B------一个32B的模型------在224K时就只剩17.19%了。
这说明什么?说明"窗口大"和"用得好"是两回事。MemAgent用一个8K的小窗口,通过学会"记什么、忘什么",碾压了窗口大几十倍的模型。
7. 消融实验:没有RL,记忆机制只是个空壳
消融实验回答了一个关键问题:记忆机制本身有多大贡献?RL训练又贡献了多少?
去掉RL训练,只保留记忆机制(MemAgent w/o RL)→ 模型在短文本上表现尚可,但随着长度增加,性能持续下滑。32B版本在896K时只有约40分。
去掉记忆机制,只用原始模型(Qwen2.5-Instruct)→ 超过上下文窗口后输入被截断,性能直接崩塌。
加上RL训练的完整MemAgent → 7B和14B模型在整个长度范围内保持稳定高性能。
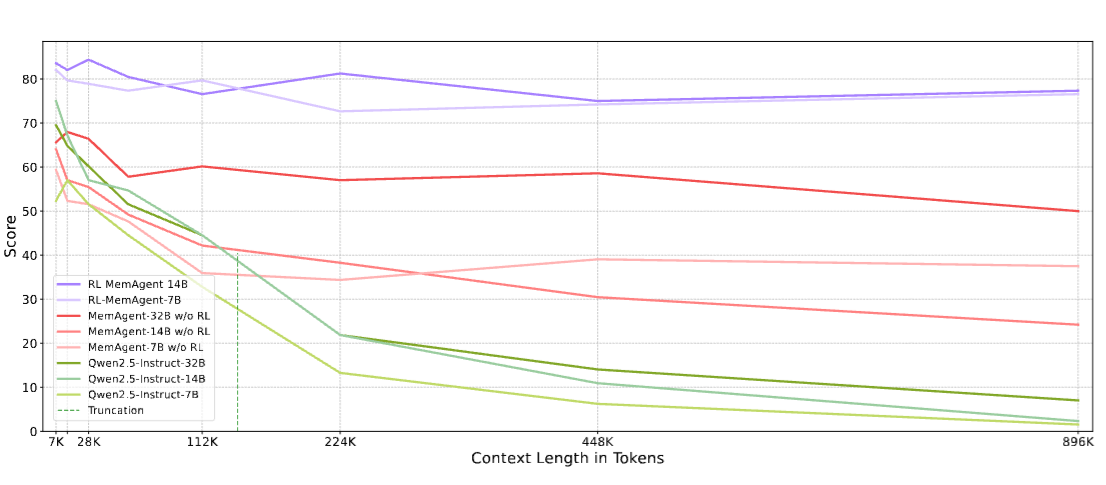
图5
图5:消融实验曲线对比。横轴是上下文长度(7K-896K),纵轴是准确率。三组曲线清晰分离:原始Qwen2.5-Instruct模型(蓝色系)在112K截断点后断崖下跌;MemAgent w/o RL(橙色系)虽然能处理超长文本但性能持续下滑;RL-MemAgent(绿色系)在整个范围内几乎保持水平。
这说明记忆机制提供了结构性支撑------让模型有能力处理超长文本。但光有结构不够,RL训练才是教会模型"如何有效使用记忆"的关键。没有RL的记忆机制,就像给你一个笔记本但不教你怎么做笔记------工具在那里,但你不会用。
更值得关注的是OOD(分布外)任务的表现。MemAgent只在HotpotQA上训练,但在RULER基准的10个不同任务上都表现出色------包括大海捞针(NIAH)、变量追踪(VT)、高频词提取(FWE)和SQuAD问答。
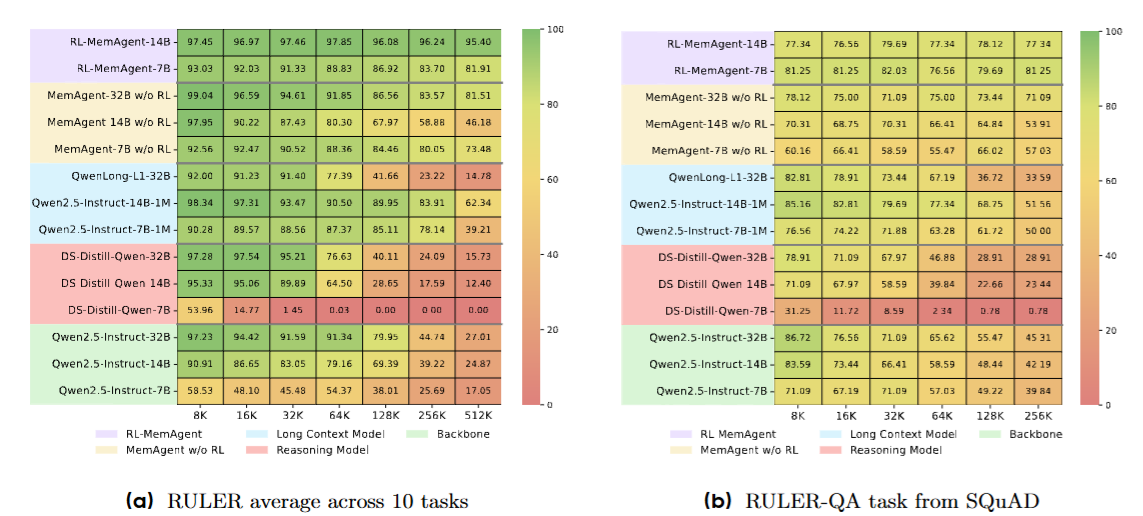
图6
图6:RULER基准任务热力图。左图是10个任务的平均分,右图是SQuAD-QA任务的单独表现。RL-MemAgent-14B在8K到512K范围内保持95%以上的平均准确率(深绿色),而基线模型在128K后普遍跌至60%以下(黄色到红色)。这证明记忆能力成功泛化到了训练集之外的任务类型。
这不是过拟合。这是真正学会了"记忆"这个能力。
8. 案例分析:看MemAgent如何"做笔记"
论文给出了一个具体的推理轨迹,展示MemAgent处理一个2跳问题的全过程。
问题是:"浪漫喜剧《Big Stone Gap》的导演住在纽约的哪个城市?"回答这个问题需要两步:先找到导演是谁(Adriana Trigiani),再找到她住在哪里(Greenwich Village, New York City)。
第1轮:模型读到一个叫Ghost的制作团队,总部在纽约。虽然和问题不直接相关,但模型判断"纽约"这个关键词可能有用,于是把它记了下来。这是预判性记忆------模型在没有确切答案时,先存储可能相关的线索。
第2轮:没有相关内容。模型保持记忆不变,没有被无关信息干扰。这是抗干扰能力。
第3轮:两个关键条目同时出现------《Big Stone Gap》的导演是Adriana Trigiani,而Adriana Trigiani住在Greenwich Village。模型立即更新记忆,记录下完整的推理链,并得出正确答案。
这个案例揭示了MemAgent学到的三个核心能力:预判性存储(在不确定时保留潜在线索)、抗干扰(面对无关信息时保持稳定)、即时整合(发现关键信息时立即更新并推理)。
更重要的是------这些能力不是通过注意力机制的架构设计实现的,而是作为文本生成能力通过RL训练涌现出来的。
9. 线性复杂度:不只是理论,是实打实的计算节省
论文给出了详细的FLOP计算对比。
基线模型处理一个长度为c的文档,需要的计算量与(q+c+o)²成正比------这是标准Transformer的O(n²)复杂度。当c从8K增长到4M,计算量增长了约250000倍。
MemAgent的计算量由三部分组成:初始化阶段(处理q+200+o个Token)、记忆更新阶段(重复⌈c/5000⌉次,每次处理q+200+5000+o个Token)、最终回答阶段(处理q+100+o个Token)。总计算量与c线性相关。
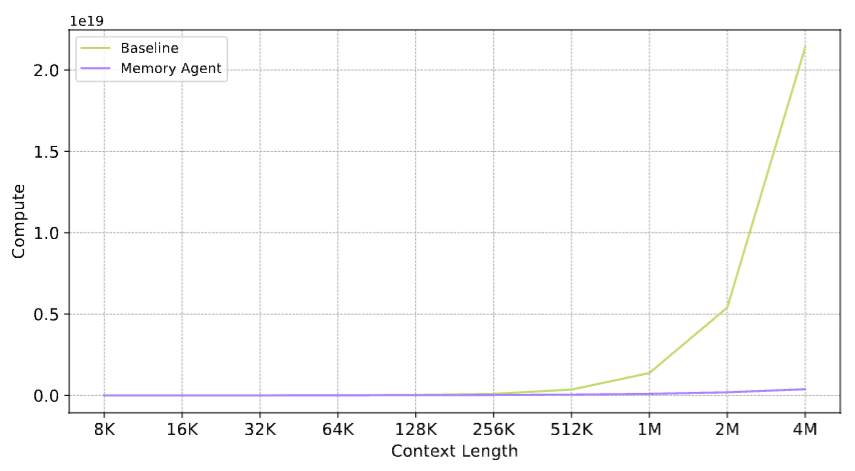
图7
图7:浮点运算量(FLOP)对比曲线。横轴是上下文长度(8K-4M),纵轴是计算量(单位:10¹⁹次浮点运算)。基线模型(蓝色)呈现陡峭的抛物线增长(O(n²)),而MemAgent(橙色)几乎是一条直线(O(n))。在4M Token时,基线模型需要约2×10¹⁹次运算,MemAgent仅需约0.15×10¹⁹次------差距超过13倍。
翻译成人话------处理一本400万Token的书,传统方法需要的算力够训练一个小模型了,MemAgent只需要传统方法在处理几十万Token时的算力。
10. 长文本处理的范式转移
把MemAgent放在更大的版图中看,它代表的不只是一个新方法,而是一种思路的转变。
过去的长文本方案,不管是扩大窗口、稀疏注意力还是上下文压缩,本质上都在试图让模型"一次性看完所有内容"。区别只是看的方式不同------有的全看,有的跳着看,有的看压缩版。
MemAgent的思路完全不同:不要一次性看完,而是像人一样分段阅读、持续记录。模型不需要"记住"所有内容,只需要学会"记住重要的内容"。这个"学会"的过程,由强化学习来完成。
这个思路打开了几个值得关注的方向:
第一,记忆长度的可控性。MemAgent的记忆是1024个Token,但这个数字是可调的。更长的记忆意味着更多的信息保留,但也意味着更大的计算开销。这给了用户一个清晰的"精度-效率"旋钮。
第二,记忆的可解释性。因为记忆是普通文本,你可以直接阅读模型在每一步"记了什么"。这在调试、审计和安全审查场景中价值巨大------你不需要猜测模型"看到了什么",直接看它的笔记就行。
第三,Multi-Conv DAPO的通用性。这个训练算法不仅适用于记忆智能体,理论上可以用于任何需要跨多个独立上下文进行优化的智能体工作流。这可能是比MemAgent本身更有长期价值的贡献。
MemAgent不是长文本问题的终极答案。它的记忆覆写策略在某些需要精确回忆早期细节的任务上可能存在信息丢失。它目前只在QA任务上验证过,在摘要、翻译等其他长文本任务上的表现还有待检验。
但它证明了一件事:你不需要一个巨大的上下文窗口来处理巨大的文档。你需要的是一个聪明的记忆系统------而强化学习可以训练出这样的系统。
如果说过去的长文本方案是在"扩大仓库",MemAgent展示的是另一条路------训练一个更聪明的"仓库管理员"。仓库大小有限,但管理员知道什么该放在最显眼的位置,什么可以扔掉。
这可能才是长文本处理真正的未来。