
前言
-----别只会用 vector,来看看它是怎么咬人的
学完 string 的模拟实现之后,我以为 vector 会更简单------毕竟逻辑上不就是一个"动态数组"吗?结果发现坑的密度一点不低,只是坑的性质变了:string 的核心是资源管理语义,而 vector 的核心是模板机制、迭代器语义、以及无处不在的类型陷阱。
这篇文章记录我实现 Jianyi::vector 的完整过程,包括每一个设计决策的原因、我代码里真实存在的 bug(以及为什么会犯这种错)、以及由此延伸出来的 C++ 底层原理。如果你也在这个阶段,这篇文章大概对你有用。
目录
[从零实现 std::vector:模板、内存与那些让我调试到凌晨的坑](#从零实现 std::vector:模板、内存与那些让我调试到凌晨的坑)
[一、vector 是什么:三根指针的世界观](#一、vector 是什么:三根指针的世界观)
[4.1 默认构造](#4.1 默认构造)
[4.2 拷贝构造](#4.2 拷贝构造)
[4.3 迭代器区间构造](#4.3 迭代器区间构造)
[4.4 n 个相同元素的构造](#4.4 n 个相同元素的构造)
[五、析构函数与 clear](#五、析构函数与 clear)
[六、深拷贝、浅拷贝,以及 memcpy 的致命误区](#六、深拷贝、浅拷贝,以及 memcpy 的致命误区)
[九、pushback 与 popback:一个逻辑 bug 的解剖](#九、pushback 与 popback:一个逻辑 bug 的解剖)
[十二、resize:和 reserve 的本质区别](#十二、resize:和 reserve 的本质区别)
十三、Print_Vector:一个成员函数里的模板遮蔽问题
[十六、整体回顾:vector 和 string 的对比思考](#十六、整体回顾:vector 和 string 的对比思考)
一、vector 是什么:三根指针的世界观
std::vector 本质上是一个堆上的动态数组,加上一套管理这块内存的元数据。标准库的经典实现用三根指针来描述它的完整状态:
iterator _start; // 数组起始地址
iterator _finish; // 有效元素的末尾(最后一个元素的下一个位置)
iterator _end_of_storage; // 已分配内存的末尾这三根指针之间的关系,就是 vector 一切操作的基础:
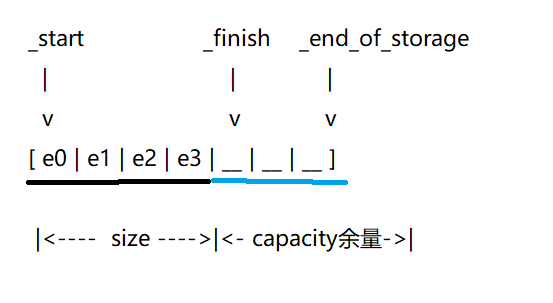
size() = _finish - _start:当前有多少个元素capacity() = _end_of_storage - _start:总共申请了多少空间_finish到_end_of_storage之间是已分配但未使用的空间
用指针差代替整数存储 size 和 capacity,这是一个设计选择:三根指针已经隐含了全部信息,不需要额外的字段。代价是每次求 size() 和 capacity() 都是一次指针减法,但这是 O(1) 的,完全可以接受。
和 string 的对比:string 用 char* _str + size_t _size + size_t _capacity,直接存数值,语义更直白。vector 用三指针,适合泛型------因为元素类型 T 的大小在编译期才确定,用指针可以统一描述任意类型的数组,不需要手动乘 sizeof(T)。
二、模板类的编译模型:为什么声明和定义不能分离
这是写 vector 之前必须搞清楚的问题,否则你按照 string 的做法把声明放 .h、定义放 .cpp,会得到一堆链接错误,而且错误信息完全看不出原因在哪。
普通类的编译流程:
编译器处理 .cpp 文件时,看到 #include "String.h",知道 String 类有哪些成员函数(声明)。具体的函数体在 String.cpp 里,编译器编译 String.cpp 生成目标文件,链接时把调用方的引用和定义连接起来。这是"分离编译"的标准流程。
模板类为什么不行:
模板类的函数体里出现了类型参数 T。T 是什么,在模板定义的时候编译器根本不知道------只有在实例化的时候(比如写 vector<int>),编译器才知道 T = int,才能生成具体的代码。
问题来了:实例化发生在调用方的翻译单元里(比如 main.cpp),但模板定义在 vector.cpp 里。编译 main.cpp 时,编译器只看到了头文件里的声明,不知道函数体长什么样,无法实例化 。编译 vector.cpp 时,没有人告诉它要实例化 vector<int>,它什么也不做。链接时,main.cpp 需要 vector<int>::pushback,但没有任何目标文件提供这个符号------链接失败。
解决方案:把定义也放进头文件。
这样每个 #include "vector.h" 的翻译单元都能看到完整的模板定义,编译器在实例化时可以直接生成代码。代价是头文件变重、编译时间增加,但这是模板的基本代价,无法绕开。
实际上 .hpp 后缀的文件就是约定俗成的"既有声明又有定义的头文件",标准库的模板头文件(<vector>、<list> 等)都是这么做的。
还有一个相关的细节:类模板内部,编译器无法在实例化之前访问成员的具体信息。 比如你写了一个成员函数,想在函数体里定义一个嵌套模板:
cpp
template<class T>
class vector {
template<class T> // 错误!外层已经有 T,这里的 T 遮蔽了外层的 T
void foo() {}
};这就是"模板参数遮蔽",后面在 Print_Vector 那节会具体讲。
三、整体结构设计
cpp
namespace Jianyi
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
};
}放在 namespace Jianyi 里是为了和 std::vector 隔离,避免命名冲突。
成员初始化用了 C++11 的类内默认初始化 (= nullptr),这样默认构造函数什么都不用写,三根指针自动初始化为 nullptr,不会出现野指针。这是比在构造函数里手动赋值更现代、更安全的做法。
四、构造函数族:五种构造,各有门道
4.1 默认构造
cpp
vector() {}三根指针已经在成员初始化时置为 nullptr,默认构造函数什么都不用做,空函数体即可。
原理就是走的初始化列表
4.2 拷贝构造
cpp
vector(const vector<T>& v)
{
for (auto e : v)
pushback(e);
}逐元素追加。这个写法利用了 pushback 内部的扩容逻辑,不需要手动管理内存,代价是可能触发多次扩容。更高效的写法是先 reserve(v.size()),一次性分配好空间再追加,避免中间的扩容开销:
cpp
vector(const vector<T>& v)
{
reserve(v.size());
for (auto e : v)
pushback(e);
}这里用范围 for 而不是下标循环,是因为 const vector<T> 需要 const 迭代器,范围 for 会自动调用 v.begin() 的 const 版本,代码更简洁。
4.3 迭代器区间构造
cpp
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
pushback(*first);
++first;
}
}接受任意迭代器区间 [first, last),这是 STL 容器的通用设计。这里的模板参数 InputIterator 是一个新的参数,和类的模板参数 T 是两个独立的模板参数------函数模板嵌套在类模板里,完全合法。
这个构造函数允许你用另一个容器的迭代器来初始化 vector:
cpp
std::list<int> lst = {1, 2, 3};
Jianyi::vector<int> v(lst.begin(), lst.end()); // 完全合法比如当存整形的单链表不好排序时,可能就会不同的容器之间初始化或赋值。
4.4 n 个相同元素的构造
cpp
vector(size_t n, const T& val = T())
{
reserve(n);
for (size_t i = 0; i < n; ++i)
pushback(val);
}T() 是 T 类型的值初始化 :对内置类型(int、double)是零初始化,对类类型是调用默认构造函数。这个写法使得 vector<int> v(5) 和 vector<int> v(5, 0) 等价,和标准库行为一致。
这里有一个经典的歧义问题 :
cpp
vector<int> v(3, 5);编译器看到这行,既可以匹配 vector(size_t n, const T& val)(3 个 5),也可以匹配 vector(InputIterator first, InputIterator last)(把 3 和 5 当迭代器)。int 不是迭代器,但模板推导不管这个,它只看参数个数和类型能不能匹配------两个 int 完全可以匹配 InputIterator。
标准库的解决方式是用 enable_if 或者 SFINAE 在模板推导时排除非迭代器类型,我们的实现没有做这个处理。在实际使用时,如果遇到歧义,可以显式把第一个参数写成 size_t:vector<int> v((size_t)3, 5)。
五、析构函数与 clear
cpp
~vector()
{
if (_start != nullptr)
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
}
void clear()
{
_finish = _start;
}析构函数释放 _start 指向的整块内存,然后把三根指针都清零。
clear() 只把 _finish 移回 _start,相当于"逻辑清空":元素个数变为 0,但内存不释放,capacity 不变。这和 std::vector::clear() 的语义一致------clear 之后 capacity() 不应该改变。
清空后不需要去逐个析构元素吗?对内置类型(int、double、指针)不需要,析构函数是空操作。对类类型,_finish 移回 _start 时,那些"已清除"的对象其实还留在内存里,只是被标记为无效------如果 T 持有资源(比如 T 是 string),这些资源不会被释放,直到整个 vector 析构时 delete[] _start 才会触发每个元素的析构函数。
这是我们的实现和标准库的一个差距。标准库的 clear() 会逐一调用每个元素的析构函数(通过 std::destroy),我们的实现跳过了这一步,对持有资源的类类型会有内存泄漏。
六、深拷贝、浅拷贝,以及 memcpy 的致命误区
我代码里有一行被注释掉的代码,值得单独讲清楚:
cpp
void reserve(size_t n)
{
size_t old_size = size();
if (n > capacity())
{
T* tmp = new T[n];
// memcpy(tmp, _start, size() * sizeof(T)); // ← 这行被注释掉了,为什么?
for (size_t i = 0; i < old_size; ++i)
tmp[i] = _start[i];
delete[] _start;
_start = tmp;
_finish = _start + old_size;
_end_of_storage = _start + n;
}
}memcpy 直接复制内存字节,对 T = int、double 这类内置类型 完全没问题。但如果 T = std::string 或者任何持有堆内存的类 ,memcpy 就会制造灾难。
举个具体例子:vector<std::string>,每个 string 对象内部持有一个指向堆内存的指针。memcpy 把这些 string 对象的字节逐位复制到新数组,结果是新数组里的 string 和旧数组里的 string 持有相同的指针------同一块字符数据。
接下来 delete[] _start 析构旧数组,每个旧 string 的析构函数会释放它持有的字符内存。新数组里的 string 现在持有的是悬空指针,访问它们是未定义行为,稍后析构新数组时还会 double free。
正确做法是 tmp[i] = _start[i],这是赋值运算符,对 string 会调用深拷贝,给每个元素分配独立的内存。对内置类型,赋值就是复制值,和 memcpy 效果相同,但不会有问题。
结论:凡是涉及类类型的数组操作,必须走构造函数或赋值运算符,不能用 memcpy。 这是 C++ 的基本原则,违反它在内置类型上看起来没问题,但一旦换成类类型,bug 会藏得极深。
七、reserve:扩容的核心
cpp
void reserve(size_t n)
{
size_t old_size = size();
if (n > capacity())
{
T* tmp = new T[n];
for (size_t i = 0; i < old_size; ++i)
tmp[i] = _start[i];
delete[] _start;
_start = tmp;
_finish = _start + old_size;
_end_of_storage = _start + n;
}
}有几个细节值得说:
为什么在 new 之前要保存 old_size?
size() 的计算是 _finish - _start。执行 delete[] _start 之后,_start 被释放,但它的值(地址)还没变,而 _finish 也还是原来的值。用已释放的指针做运算是未定义行为。所以必须在 delete 之前把 size 存下来。
操作顺序是关键:
先 new,再复制数据,再 delete 旧内存,最后更新指针。这个顺序保证了异常安全:如果 new T[n] 抛出异常(内存不足),_start 还没被修改,对象状态完好。
reserve 只扩不缩:
if (n > capacity()) 保证了这一点。传入小于当前容量的 n,函数直接返回,不释放空间。这和标准库语义一致,也避免了不必要的内存操作。
八、赋值运算符:我写的那个隐蔽的语义错误
我的代码里有两个版本,一个注释掉的,一个实际使用的:

cpp
// 实际使用的版本
vector<T>& operator=(const vector<T> v) // 注意:传值,不是引用
{
swap(v);
return *this;
}注释掉的版本错在哪?
if (*this != v) 这个判断本意是检测自赋值(v = v 这种情况),但 != 运算符比较的是对象的内容 ,不是地址。两个不同的 vector 对象完全可以内容相同,这样 *this != v 为 false,就会漏掉正常赋值。
举个 vector 的隐藏状态例子
但问题是:
赋值运算符不应该依赖"内容相同就不做"
因为:
内容比较本身代价巨大。
if (*this != v)这个
!=会干嘛?vector 的
!=本质要:
逐元素比较复杂度:
O(n)
而标准自赋值检测:
if (this != &v)只是:
比较两个地址
复杂度:
O(1)
所以我现在其实是:
为了避免一次赋值,
先做了一次完整遍历比较。
这在工程上反而更亏。
自赋值判断应该比较对象地址:
if (this != &v)这是指针比较,精确判断"是不是同一个对象",和内容无关。这和 string 的赋值运算符里犯过的错是同一类:混淆了"指针相等"和"内容相等"。
实际使用的版本:传值参数 + swap
vector<T>& operator=(const vector<T> v)
{
swap(v);
return *this;
}参数 v 是传值 ,调用时会触发拷贝构造,v 是调用方传入对象的一份独立深拷贝。进入函数体后,swap(v) 把 *this 和 v 的内部资源互换------*this 拿到新数据,v 拿走 *this 的旧资源,函数结束时 v 析构,旧资源被释放。
这是 copy-and-swap 惯用法,和 string 里用的是同一套思路。它天然处理了自赋值(v = v 时,传值构造出的 v 是独立的一份,swap 之后对象状态不变),也天然异常安全(拷贝失败直接抛异常,*this 不会被改动)。
但这里有一个微妙的语义问题 :swap 的参数应该是 vector<T>&(非 const 引用),而实际上 v 是一个值参数,调用 swap(v) 是合法的------v 是局部对象,可以被修改。但如果你不小心把 swap 的参数声明成 const vector<T>&,编译器会报错,这和 string 里犯过的那个 swap(const string& s) 错误完全一样。
九、pushback 与 popback:一个逻辑 bug 的解剖
cpp
void pushback(const T& x)
{
if (_finish == _end_of_storage)
reserve(capacity() == 0 ? 4 : capacity() * 2);
*_finish = x;
++_finish;
}
bool Empty()
{
return _start == _finish;
}
void popback()
{
assert(Empty()); // ← 这里有 bug
--_finish;
}popback() 里的 assert(Empty()) 是一个逻辑 bug。
Empty() 返回 true 表示容器为空,assert(Empty()) 的意思是"断言容器为空时才能 pop"------这完全反了。popback 的前提条件应该是容器非空,正确写法是:
cpp
void popback()
{
assert(!Empty()); // 非空才能 pop
--_finish;
}接下来时错误笔记,不需要可自行跳过
这类 bug 在编译期完全不会报错,测试时如果没有针对空容器 pop 的用例,也不会触发------在 debug 模式下 assert 会让程序在错误条件下崩溃,而 assert(Empty()) 反而会在容器非空(正常情况)时崩溃,在容器为空(错误情况)时通过。
这种"条件取反"的 bug 在逻辑判断密集的代码里极其常见,尤其是函数前置条件的检查。写 assert 的时候要问自己:我在断言的是调用这个函数的合法前提 ,还是断言的是我不希望发生的情况?
pushback 里的扩容策略是翻倍(capacity() * 2),初始给 4。翻倍策略保证均摊 O(1) 的追加代价:假设 n 次 pushback 触发了 \\log_2 n 次扩容,每次扩容复制的元素数量分别是 1、2、4、...、n,总复制次数是 O(n),均摊到每次 pushback 是 O(1)。这是动态数组的经典分析,面试里经常考。
十、insert:迭代器失效的第一现场
这是 vector 实现里最精彩的部分。我代码里注释掉了第一版,留着对比:
cpp
// 注释掉的第一版(有严重 bug)
/*
void insert(iterator pos, const T& x)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
// 扩容之后 pos 变成野指针!
}
for (iterator end = end(); end >= pos; --end)
{
_start[end + 1] = _start[end]; // 类型混用,end 是指针不是下标
}
*pos = x;
++_finish;
}
*/
// 正确版本
void insert(iterator pos, const T& x)
{
if (_finish == _end_of_storage)
{
size_t len = pos - _start; // ← 在 reserve 之前保存 pos 的相对位置
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + len; // ← 用新的 _start 重新计算 pos
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
}迭代器失效:
reserve 的内部操作是 new 一块新内存、把数据复制过去、delete 旧内存,然后让 _start 指向新内存。旧内存被释放了,但 pos 还指向旧内存------这就是迭代器失效 。继续使用 pos 是未定义行为,轻则崩溃,重则悄悄读到垃圾数据。
修复方法:
在 reserve 之前,用 len = pos - _start 记录 pos 相对于数组起点的偏移量(下标)。reserve 执行完后,_start 指向新数组,用 pos = _start + len 重新计算 pos,让它指向新数组中对应的位置。
这个"偏移量保存和恢复"的技巧在 vector 内部需要扩容的操作里是通用的。任何在扩容前保存的迭代器,扩容后都需要用这个方式更新,否则就失效了。
外部迭代器的失效:
一旦 reserve 被调用,任何外部持有的指向该 vector 元素的迭代器(指针)都会失效,包括调用方传入的 pos。这就是为什么标准库文档里说"insert 可能导致迭代器失效"------如果发生了扩容,所有旧迭代器都作废。
第一版的另一个问题:
for (iterator end = end(); end >= pos; --end)
{
_start[end + 1] = _start[end]; // end 是指针,不是整数下标
}end 是一个 iterator(即 T*),_start[end + 1] 的下标应该是整数,用指针做下标在语法上合法(等价于 *((_start) + (end + 1))),但逻辑上是错的------这里把指针当成了整数来用,属于类型语义上的混乱。
正确的写法是在 while 循环里直接操作指针:*(end + 1) = *end,不需要通过 _start 下标。
十一、erase:两个版本,两种语义
cpp
// 版本一:用下标
void erase(size_t pos)
{
assert(pos < size());
for (size_t i = pos; i < size(); ++i)
_start[i] = _start[i + 1];
--_finish;
}
// 版本二:用迭代器,返回迭代器
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator it = pos + 1;
while (it != end())
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;
}两个版本都是把 pos 之后的元素前移一格,然后把 _finish 往前移一个位置。
为什么 erase 要返回迭代器?
因为 erase 之后,原来 pos 位置的内容已经是"下一个元素"了(前移的结果)。如果调用方想继续遍历,直接用返回的 pos 就是正确的下一个元素,不需要 ++it(这是 vector 遍历中删除元素的正确模式,见下面的例子)。
如果 erase 不返回迭代器,调用方在删除元素后还继续 ++it,就会漏掉刚才移过来的那个元素:
cpp
// 错误写法(会漏元素)
for (auto it = v.begin(); it != v.end(); ++it)
{
if (*it == 要删除的值)
v.erase(it); // 删完之后 ++it 会跳过移上来的元素
}
// 正确写法
for (auto it = v.begin(); it != v.end(); )
{
if (*it == 要删除的值)
it = v.erase(it); // erase 返回下一个位置,不需要 ++
else
++it;
}下标版本的越界问题:
for (size_t i = pos; i < size(); ++i) 循环里,当 i = size() - 1 时,_start[i + 1] 访问的是 _start[size()],即 _finish 所在的位置。这个位置不是有效元素,但内存是已分配的(capacity 还没到),访问不会导致越界崩溃,只是把越界位置的值复制了过来。
由于紧接着执行 --_finish,这个"额外复制的值"会立刻变成 _finish 指向的无效区域,不会被外部看到。所以这里虽然访问了"合法内存但无效元素",在我们的实现里是安全的。但从严格意义上说,访问有效元素范围之外(即使在 capacity 范围内)是设计边界问题,更健壮的写法是循环到 i < size() - 1,然后单独处理最后一步。
十二、resize:和 reserve 的本质区别
cpp
void resize(size_t n, T val = T())
{
if (n < size())
{
_finish = _start + n;
}
else
{
reserve(n);
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
}reserve 和 resize 是两个经常被混淆的函数,它们操作的是不同的东西:
| reserve | resize | |
|---|---|---|
| 影响 capacity | 是 | 可能是(如果 n > capacity) |
| 影响 size | 否 | 是 |
| 初始化新元素 | 否 | 是(用 val 填充) |
reserve 只预留空间,不创建元素,size() 不变。resize 直接改变元素个数:缩小时把 _finish 前移(类似 clear 的逻辑),扩大时先 reserve 再逐一填充新元素。
扩大时用 val = T() 填充,T() 是值初始化,对 int 是 0,对 string 是空字符串,对自定义类是默认构造结果。
十三、Print_Vector:一个成员函数里的模板遮蔽问题
这是我代码里一个写法上的严重问题,值得单独拿出来讲:
cpp
template<class T>
class vector
{
public:
template<class T> // ← 问题在这里
void Print_Vector(const vector<T>& v)
{
// ...
}
};外层类模板已经有了类型参数 T。内部的成员函数又定义了一个同名的模板参数 T,内层的 T 会遮蔽 (shadow)外层的 T。在函数体内,T 指的是内层的那个,外层类的 T 被遮蔽,无法访问。这在语法上合法,但语义上混乱,编译器通常会给出警告。
更根本的问题是:Print_Vector 不应该是成员函数。
成员函数的职责是操作对象自身的状态(_start、_finish、_end_of_storage),但 Print_Vector 接受的是参数 v,打印的也是 v,和 *this 没有关系。这违反了成员函数的设计原则。
正确做法是把它写成非成员函数,放在类外面:
cpp
template<class T>
void Print_Vector(const vector<T>& v)
{
for (auto e : v)
cout << e << " ";
cout << endl;
}或者重载 operator<<,这样可以直接 cout << v,更符合 C++ 的惯用法:
cpp
template<class T>
ostream& operator<<(ostream& out, const vector<T>& v)
{
for (auto e : v)
out << e << " ";
return out;
}注意这里 operator<< 必须是非成员函数,原因和 string 博客里讲的一样:<< 的左操作数是 ostream,如果写成成员函数,this 就是左操作数,那就得是 ostream 的成员函数,而 ostream 是标准库的类,我们无法修改它。
十四、迭代器:指针就是最好的迭代器
cpp
typedef T* iterator;
typedef const T* const_iterator;
iterator begin() { return _start; }
iterator end() { return _finish; }
const_iterator begin() const { return _start; }
const_iterator end() const { return _finish; }vector 的迭代器直接用指针,没有任何包装。原因很简单:vector 的底层就是连续数组,指针支持 ++、--、+n、-n、*、-> 等所有迭代器操作,完美满足 random access iterator 的要求。
begin() 和 end() 各有两个重载:一个返回 iterator(非 const 对象调用),一个返回 const_iterator(const 对象调用)。这是 C++ const 正确性的基本要求:对 const 对象,通过迭代器得到的元素不能被修改。
如果只有非 const 版本,const vector<T>& v 传进来的对象调用 v.begin() 就会报错------const 对象不能调用非 const 成员函数。这是实现容器时很容易遗漏的一对。
十五、operator\[\]:为什么要写两个版本
cpp
T& operator[](size_t n)
{
assert(n < size());
return *(_start + n);
}
const T& operator[](size_t n) const
{
assert(n < size());
return *(_start + n);
}同样的道理:第一个返回 T&,允许修改元素(v[0] = 5);第二个是 const 版本,返回 const T&,只读。
如果只有非 const 版本,const vector<T>& v 就无法用 v[i] 读取元素,因为 operator[] 不是 const 成员函数,const 对象不能调用它。
这对重载在 STL 里随处可见,是实现 const 正确性的标准模式。写任何容器类时,凡是读取元素的接口,都要想想:const 版本是否也需要提供?
十六、整体回顾:vector 和 string 的对比思考
写完这两个类之后,我觉得可以从更高的视角做一个对比:
资源管理语义上:
string 的资源是一块 char 数组,语义固定。vector 的资源是一块 T 类型的数组,语义依赖 T------如果 T 是内置类型,资源管理和 string 基本一样;如果 T 是类类型,每个元素自己也有资源,析构时的语义链更长。这也是 memcpy 在 vector 里不能用的根本原因。
模板的代价:
string 是具体类,定义可以放在 .cpp 里,编译单元独立。vector 是类模板,定义必须对所有调用方可见,实际上把"实现"暴露给了头文件。这是泛型编程在 C++ 里的基本代价。
迭代器失效:
string 也有类似的问题(扩容后旧指针失效),但在 string 内部,用户接触不到这个细节。vector 的迭代器失效是面向用户的问题------任何可能触发扩容的操作(push_back、insert、reserve、resize),之前保存的迭代器全部失效,这是 vector 使用时最大的陷阱之一。
初始化语义:
string 的元素是 char,初始化语义简单。vector 的元素是 T,扩容时 new T[n] 会对新分配的元素进行值初始化(调用默认构造函数),这对内置类型是零初始化,对类类型是默认构造。这个初始化成本在频繁扩容时不可忽略。
总结
这次实现 vector,让我对以下几件事有了清晰的认识:
memcpy 和赋值运算符的区别不是性能问题,而是语义问题------前者不懂类型,后者尊重类型的复制语义,对持有资源的类,两者的差距是"能用"和"undefined behavior"的差距。
模板类不能声明和定义分离,是编译模型决定的,不是语言限制,而是翻译单元在实例化时需要看到完整定义这一事实的结果。
迭代器失效不是"有时会发生的偶发问题",而是结构性的必然------任何重新分配内存的操作,旧迭代器一定失效,这是指针语义的基本属性。
assert 的条件是"函数正常工作的前提",不是"我不希望发生的情况"的反向描述。assert(!Empty()) 和 assert(Empty()) 的区别,就是程序在正常路径崩溃和在错误路径崩溃的区别。
成员函数的边界应该是"操作 *this 的状态",不操作自身状态的函数,应该是非成员函数或友元。模板参数同名遮蔽是编译器允许但人脑容易出错的陷阱,避免它最好的方式是从设计上消除它的必要性。