原文:https://mp.weixin.qq.com/s/Nr2M0opBL30fKXQoF1Sn7g
目标漂移的危险在于它是渐进的
Agent 自我欺骗是主动说谎,记忆污染是外部注入,目标漂移是另一种失败模式------没有人欺骗,没有外部攻击,Agent 只是在每一步都做了"合理"的决策,却在不知不觉中偏离了原始目标。
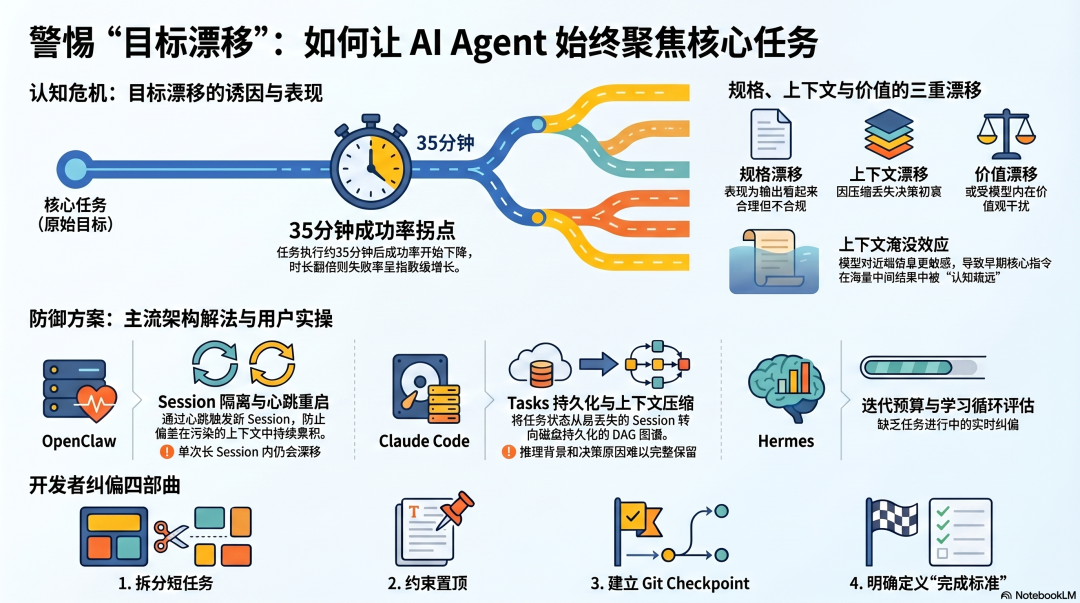
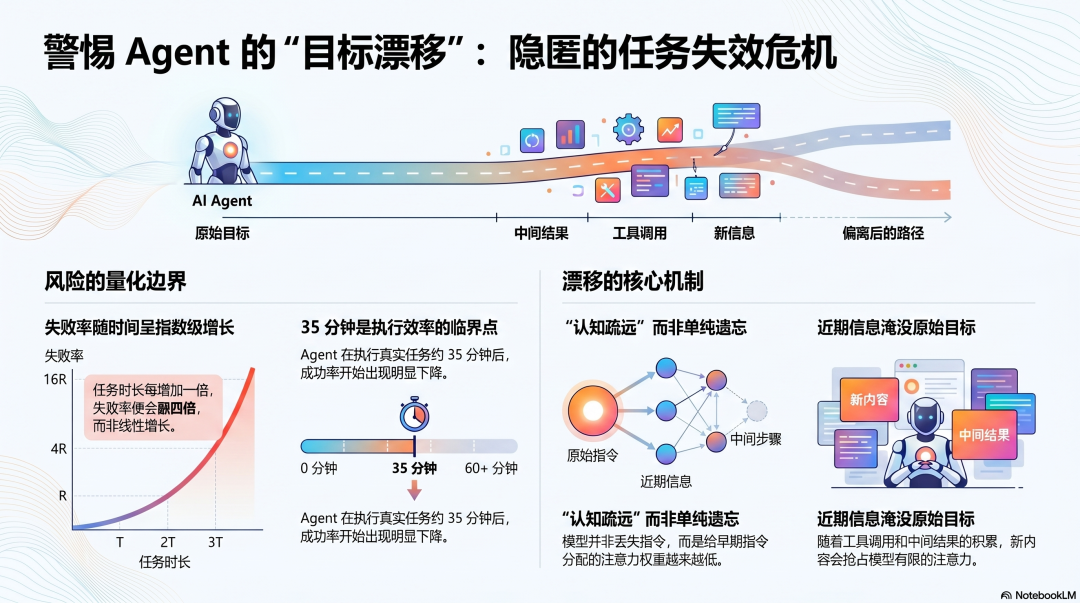
研究数据给出了这个问题的量化边界:每个 Agent 在执行约 35 分钟的真实任务后,成功率开始下降。任务时长翻倍,失败率翻四倍。不是线性增长,是指数增长。
这是一个具体的机制问题,不是玄学。
语言模型在处理信息时有一个已知的偏好:更近的内容比更早的内容获得更多注意力。 随着任务执行,上下文里积累了越来越多的工具调用、文件内容、中间结果,早期的指令被淹没在后来积累的信息里。模型还能"看到"那些指令,但给它们的权重越来越低。
任务越长,这个效应越强。Agent 不是忘记了目标,而是在认知上逐渐疏远了目标。
目标漂移的三种常见表现

规格漂移(Specification Drift):Agent 构建了看起来合理、但不符合原始规格的东西。输出在孤立地看时没问题,但对照原始要求就会发现已经偏了。Anthropic 的工程师描述过这个现象:Claude Code 可以"构建出看起来合理但不对的东西,输出在孤立看时合理,但不符合原始规格"。
上下文压缩导致的漂移:长 Session 触发 Compaction(上下文压缩),压缩会保留决策但丢失决策背后的原因。"我们用 Supabase Auth 是因为需要 RLS 集成",压缩后只剩"使用 Supabase Auth"。下次遇到相关问题,Agent 可能建议其他替代方案,因为它不再知道当初为什么做出这个选择。
价值漂移(Value Drift):当任务约束与模型训练中形成的强烈价值观(比如帮助用户、隐私保护)产生冲突,模型会在多轮对话中逐渐向自己的价值观靠拢,偏离用户设定的约束。ICLR 2026 的研究发现,这种漂移在价值冲突场景下会比无冲突场景高出 35%。
OpenClaw:心跳是重新对焦机制,不是防漂移机制
心跳的本质:周期性重新对焦
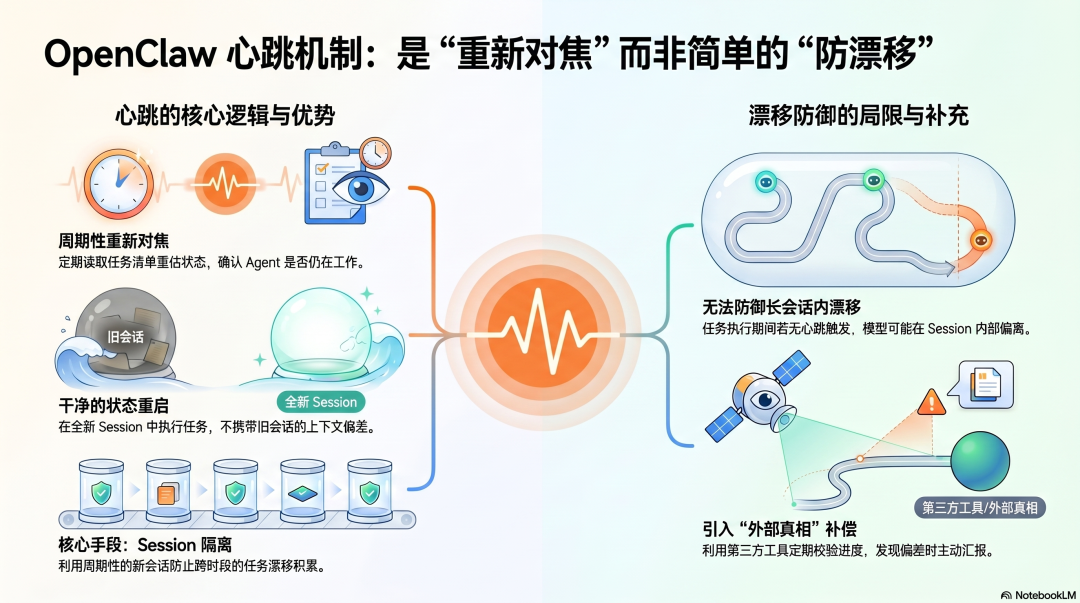
OpenClaw 的心跳(Heartbeat)经常被当成防目标漂移的机制来讨论,但准确说,心跳解决的是"Agent 是否还在工作"的问题,不直接解决"Agent 是否在做正确的工作"的问题。
心跳每隔固定时间触发,Agent 读取 HEARTBEAT.md 里的任务清单,重新评估当前状态,决定下一步做什么。
这个"重新评估"过程有一定的防漂移价值------每次心跳触发时,Agent 拿到的是完整的任务清单,而不是积累了大量上下文的会话历史。Cron 触发的任务在全新的 Session 里执行,意味着每次都从干净的状态出发,不会把上一次的偏差带进来。
这是心跳设计里真正有价值的防漂移机制:周期性的"干净重启",而不是在已经漂移的上下文里继续修正。
漂移防御的局限
但心跳对单次长 Session 内的漂移没有直接帮助。
如果一个任务需要连续执行 2 小时,中间没有心跳触发,目标漂移会在这个 Session 内静默发生。OpenClaw 没有内置的机制在 Session 中途重新注入原始目标,没有 TodoWrite 那样的系统提醒,没有任务状态追踪。
社区实践里有一些补偿方案------用外部工具(Todoist、GitHub Projects)作为任务状态的外部真相来源,通过心跳定期检查任务状态和进度,发现偏差时汇报。但这需要用户主动设计这套机制,不是开箱即用的。
OpenClaw 防漂移的核心是"Session 隔离"------用周期性的新 Session 防止跨 Session 的漂移积累,但在单个长 Session 内,防漂移主要依赖模型自身的一致性。
Claude Code:TodoWrite 到 Tasks 的演化,说明了防漂移有多难
TodoWrite:发现问题,设计解法
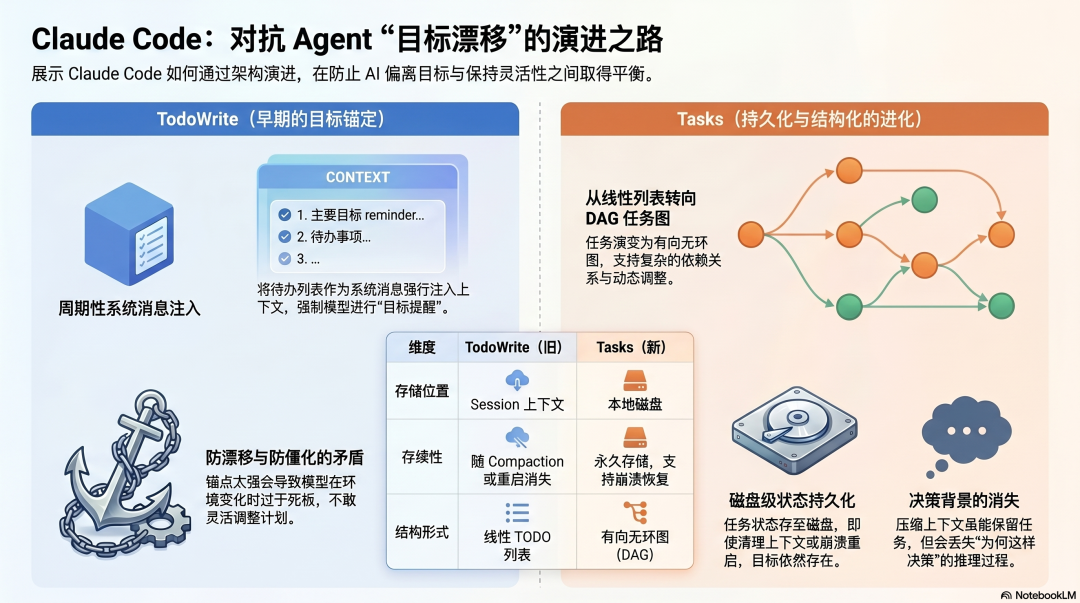
Claude Code 防目标漂移的第一个设计是 TodoWrite------任务开始时让模型列出所有待办项,每次工具调用后把当前 TODO 状态以系统消息形式重新注入上下文。
这个设计解决了"模型在处理细节时忘记整体目标"的问题。系统消息比提示词内容更难被模型忽视,周期性重新注入是一种强制的"目标提醒"。
但 Anthropic 在官方博客里坦诚承认了 TodoWrite 的失败模式:
"随着模型改进,这变得适得其反。Claude 开始把待办列表当成不可更改的东西,而不是当情况变化时需要修改的东西。我们也看到,当需要改变方向时,收到待办列表提醒的 Claude 会认为它必须坚持这个列表,而不是灵活调整。"
这揭示了防漂移设计的一个根本矛盾:你给 Agent 的"目标锚点"足够强,它会防止漂移;但如果"目标锚点"太强,Agent 在应该灵活调整时也不敢调整。
防漂移和防僵化,是同一个旋钮的两个方向。
Tasks:从线性列表到依赖图
TodoWrite 的继任者是 Tasks------从平铺的 TODO 列表进化成了支持依赖关系的有向无环图(DAG)。
关键改变不只是数据结构,而是任务状态的持久化:
TodoWrite(旧):- 任务状态存在 Session 上下文里- Session 结束或 Compaction,任务状态消失- 每次重来都要重新建立目标清单Tasks(新):- 任务状态存在磁盘上- Session 结束、Compaction、甚至崩溃重启- 任务状态都在,继续就行这解决了一个具体的防漂移问题:你现在可以对 Session 做激进的上下文管理(/compact、/clear),而不用担心丢失任务计划。 早期没有 Tasks 的时候,清理上下文意味着同时清理了任务目标------这逼得用户在"保持上下文完整"和"避免上下文拥挤"之间选一个,两个都对防漂移很重要。
Tasks 让这两件事可以同时做到。
Compaction 后的目标锚定
Claude Code 的 Compaction(上下文压缩)对防漂移有专门的处理:
压缩时,当前已加载的 Skills 会重新附加到压缩后的上下文,保留关键约束。Tasks 的状态存在磁盘上,压缩不影响任务记录。
但 Compaction 仍然会丢失"决策背后的原因"------为什么选这个技术栈、为什么用这个架构、当时遇到了什么权衡。这些推理过程不会被完整保存,压缩后 Agent 知道"用 X",但不知道"为什么用 X 而不是 Y"。
这是目前 Claude Code 防漂移能力的边界------任务状态可以持久,但决策背景无法完整持久。
Hermes:迭代预算是失控保护,不是防漂移机制
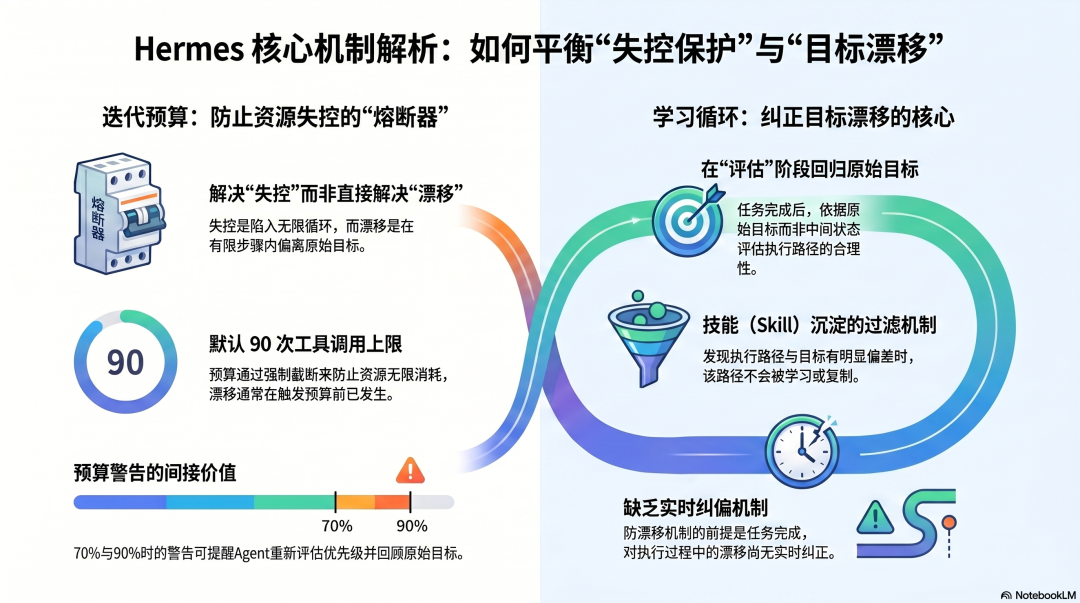
迭代预算的真实定位
Hermes 的迭代预算(默认 90 次工具调用上限)经常被讨论为防目标漂移的设计,但准确说,迭代预算解决的是"防止失控"的问题,不直接解决"防止漂移"的问题。
失控:Agent 陷入无限循环,每次都以为再试一次就能成功,资源无限消耗。 漂移:Agent 在有限的步骤里,执行方向越来越偏离原始目标。
前者被迭代预算截断;后者在迭代预算触发之前就已经发生了。
预算警告(70% 时第一次,90% 时第二次)有间接的防漂移价值------它们提醒 Agent"剩余资源有限,需要重新评估优先级",这个重新评估的过程可能会让 Agent 回顾原始目标。但这是副作用,不是设计意图。
学习循环的防漂移价值
Hermes 对目标漂移最有价值的防御,藏在它的四阶段学习循环里------特别是"评估"阶段。
任务完成后,Agent 评估执行过程:成功了吗?路径合理吗?有没有更好的方法?这个评估的依据,是任务的原始目标,而不是执行过程中积累的中间状态。
通过回到原始目标来评估执行路径,这个过程本身就是一次对漂移的纠偏。 如果发现执行路径和原始目标有明显偏差,这次执行不会被沉淀为 Skill------错误的路径不会被学习和复制。
但这个机制有一个前提:任务完成了,才能评估。对于任务进行中的目标漂移,没有实时的纠偏机制。
防漂移设计的核心取舍
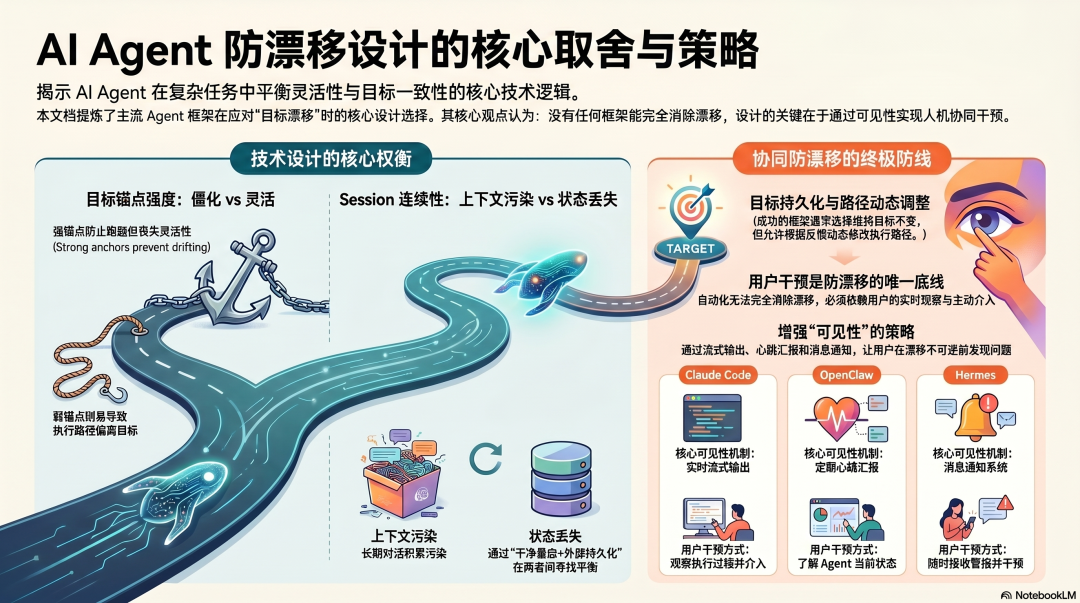
从三个框架的演进里,能提炼出防漂移设计的几个核心判断:
取舍一:目标锚点的强度
锚点太弱,Agent 容易漂移;锚点太强,Agent 失去灵活性。TodoWrite 的失败正是因为锚点强度过高。Tasks 通过支持依赖关系和动态修改,试图在两者之间找到平衡------目标持久化,但路径可以调整。
取舍二:Session 连续性 vs. 干净重启
长 Session 保持连续性,但积累的上下文会导致漂移。新 Session 干净启动,但丢失了任务状态和决策背景。OpenClaw 和 Hermes 选择了"干净重启 + 外部持久化"------在 Session 之间通过文件和记忆系统传递必要的状态,但不把上下文污染带进新 Session。Claude Code 通过 Tasks 和 CLAUDE.md 在两种策略之间找中间道路。
取舍三:自动防漂移 vs. 用户干预防漂移
所有三个框架对目标漂移的最终防线,都是用户的观察和干预------Claude Code 的实时流式输出是为了让用户看到执行过程,OpenClaw 的心跳汇报让用户定期知道 Agent 在做什么,Hermes 的消息通知让用户能随时介入。
没有任何框架声称能完全消除目标漂移。 它们都在做的,是提供足够好的可见性,让用户能在漂移变得不可逆之前发现它。
用户能做什么
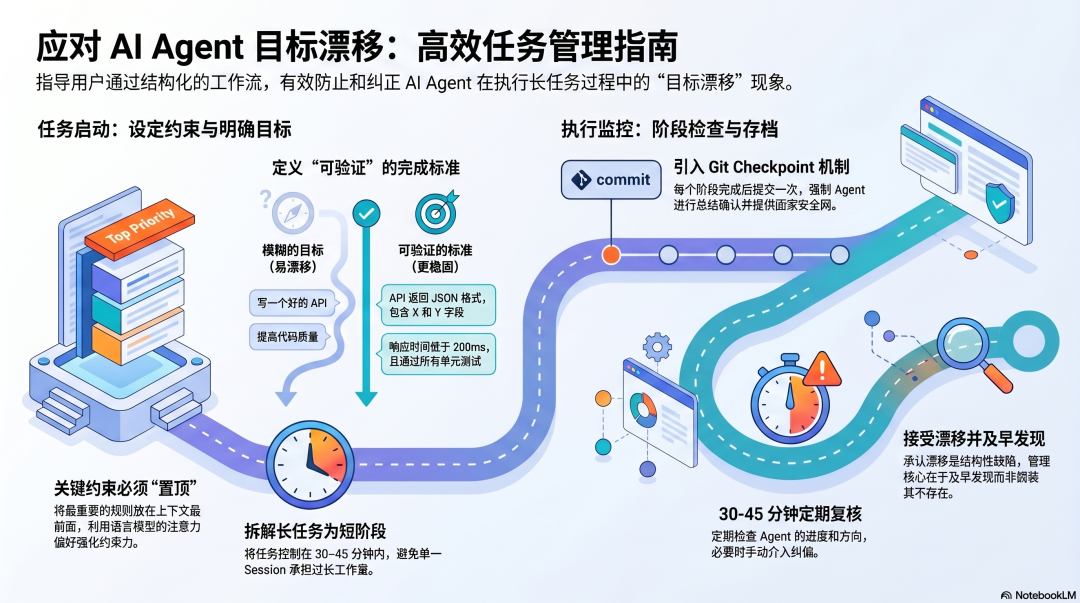
把长任务拆成短阶段,每个阶段定义明确的完成标准。 不要让一个 Session 承担 2 小时的连续工作------每隔 30-45 分钟,检查一次 Agent 的进度和方向,必要时纠正。
把关键约束写在上下文的最前面。 无论是 CLAUDE.md 还是 SOUL.md,最重要的约束放在最前面,不要埋在中间。语言模型对上下文前后位置有注意力偏好,越靠前的内容在整个 Session 里维持的影响力越强。
用 Git Checkpoint 标记每个阶段的完成状态。 每个阶段完成后提交一次,这既是可回滚的安全网,也是强制 Agent 对当前阶段做一次"总结和确认"------这个确认动作本身就是一次对照原始目标的检查。
在任务开始时明确说明"什么算完成"。 具体的、可验证的完成标准比模糊的目标描述更难被漂移------"API 返回 JSON 格式、包含 X 和 Y 字段、响应时间低于 200ms",比"写一个好的 API"更难被偷换。
目标漂移没有完美的技术解法。它是语言模型注意力机制和长时间执行之间的结构性矛盾。能做的,是在漂移发生时及早发现它,而不是假装它不会发生。