焦糖玛奇朵的魔法工具使用说明
焦糖玛奇朵的魔法工具,实现了从视频到高质量数据的半自动流水生产线工程。
其开发初衷是为了高效清洗数据集以快速迭代模型。
如果使用中发现有任何可以改进的地方欢迎留言或私信我。
小白如果需要可以找我要打包的exe,有自己环境的可以参考前文代码一键运行。
目前主要适配YOLO框架。
本文档说明3 个数据集工具的用途、启动方式、使用流程、依赖环境和常见问题。
工具概览
| 工具 | 入口脚本 | 推荐启动方式 | 用途 |
|---|---|---|---|
| VideoToYolo | video_to_yolo_tool.py |
run_video_to_yolo_yolov8.bat |
视频抽帧、ONNX 自动标注、生成 YOLO 数据集、类别统计与数据平衡 |
| DatasetCleaner | dataset_clean_tool.py |
run_dataset_cleaner_yolov8.bat |
逐目标查看裁剪图,快速修正类别、移动脏图、移出需重标图片 |
| QuickModelViewer | quick_model_viewer.py |
run_quick_model_viewer_yolov8.bat |
快速加载 ONNX 模型和图片,直接可视化检测框 |
推荐使用桌面快捷方式启动:
VideoToYoloDatasetCleaner-yolov8QuickModelViewer
如果快捷方式失效,可以直接双击项目目录中的 .bat 文件。
依赖环境
当前最稳定的启动方式是使用已有 conda 环境:
text
C:\Users\zhang\.conda\envs\yolov8主要依赖:
text
python
opencv-python
numpy
Pillow
PyYAML
onnxruntime / onnxruntime-gpu
tkinter启动脚本会先激活 yolov8 环境,再补充 ONNX Runtime、CUDA、torch 相关 DLL 搜索路径。
不要直接双击 .py 文件,尤其是涉及 ONNX 推理的工具。直接双击可能会用到系统默认 Python,导致动态链接库加载失败。
1. VideoToYolo
用途
VideoToYolo 是数据集前置工具,用于把视频转换成 YOLO 检测数据集。
它可以完成:
- 选择视频目录
- 按固定帧间隔抽帧
- 生成
images - 整理/保留
videos - 使用 ONNX 模型自动标注
- 生成
labels - 生成
dataset.yaml - 把模型没有检出任何目标的图片移到
empty_images - 统计各类别数量
- 随机移出某一类的纯类别图片,用于数据平衡
输出目录结构
选择一个数据集目录后,工具会生成或使用:
text
dataset_root/
videos/
images/
labels/
empty_images/
class_balance_removed/
dataset.yaml说明:
videos:原始视频目录。images:抽帧后、参与训练的图片。labels:YOLO txt 标签。empty_images:模型没有检出任何目标的图片,会从images移到这里,不生成 txt。class_balance_removed:类别平衡时被移出的图片和标签,不会物理删除。dataset.yaml:YOLO 训练配置。
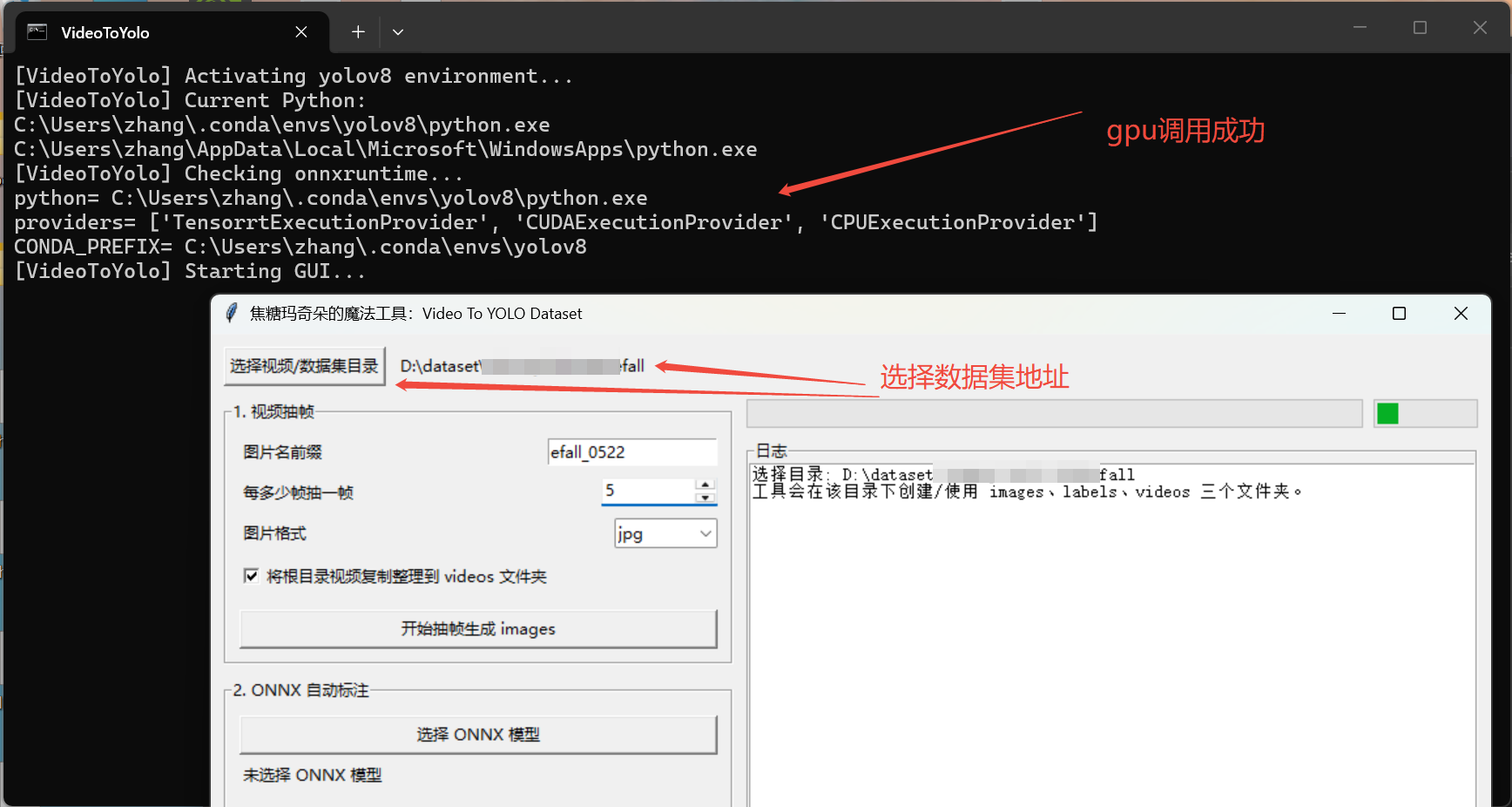
视频抽帧
- 点击
选择视频/数据集目录。 - 设置
图片名前缀。 - 设置
每多少帧抽一帧。 - 选择图片格式,一般用
jpg。 - 点击
开始抽帧生成 images。
抽帧命名规则:
text
图片名前缀_视频序号_帧序号.jpg示例:
text
efall_0520_3_24.jpg注意:图片名会避免中文和特殊字符,尽量保证训练和跨平台迁移稳定。
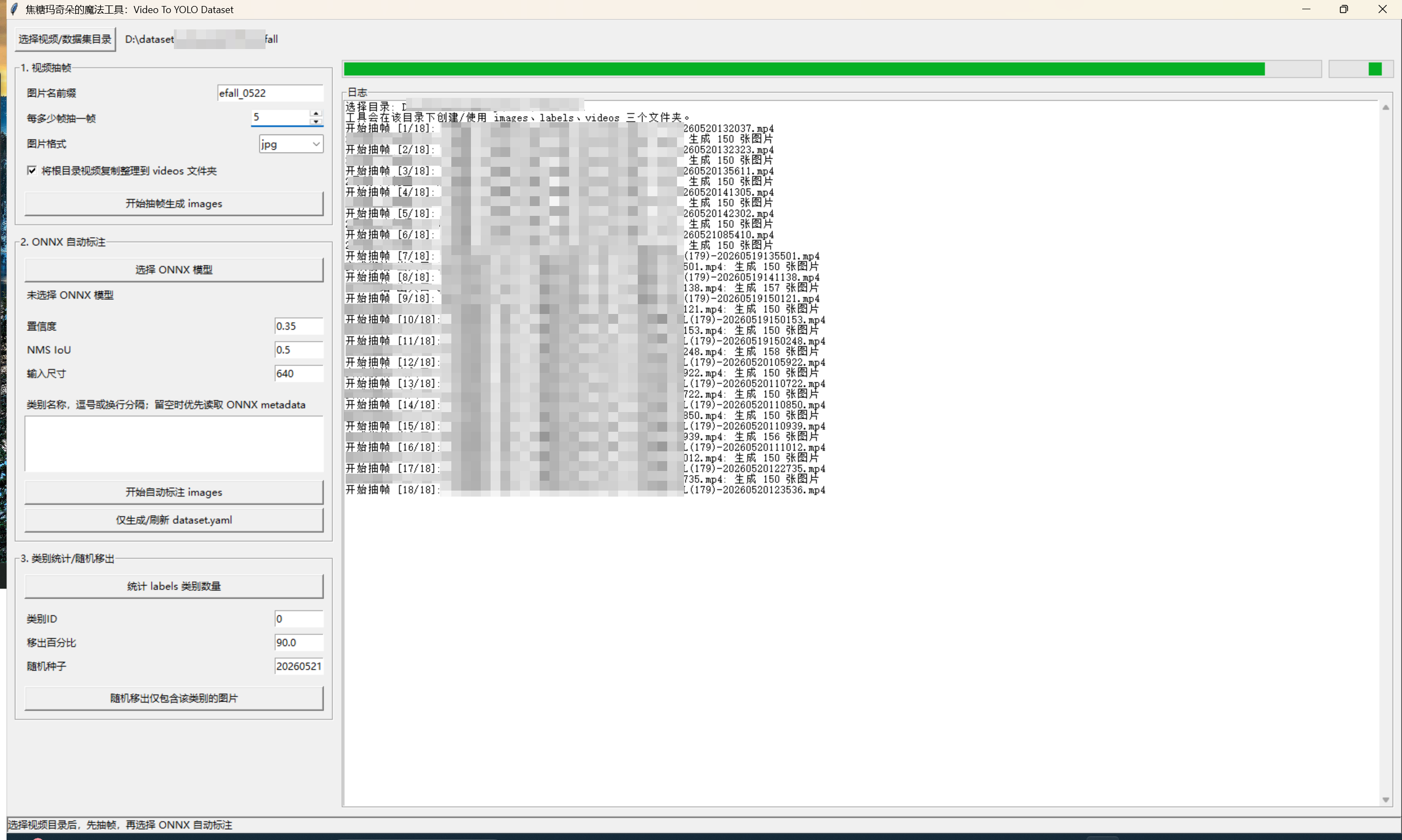
自动标注
- 点击
选择 ONNX 模型。 - 设置
置信度、NMS IoU、输入尺寸。 - 如果模型没有类别 metadata,在类别框中手动填写类别名。
- 点击
开始自动标注 images。
类别名可以写成:
text
standing
fall
bending也可以用逗号分隔:
text
standing,fall,bending自动标注完成后:
- 有目标的图片保留在
images,生成对应 txt 到labels。 - 没有目标的图片移到
empty_images。 - 自动生成或刷新
dataset.yaml。 - 日志中会输出类别统计。
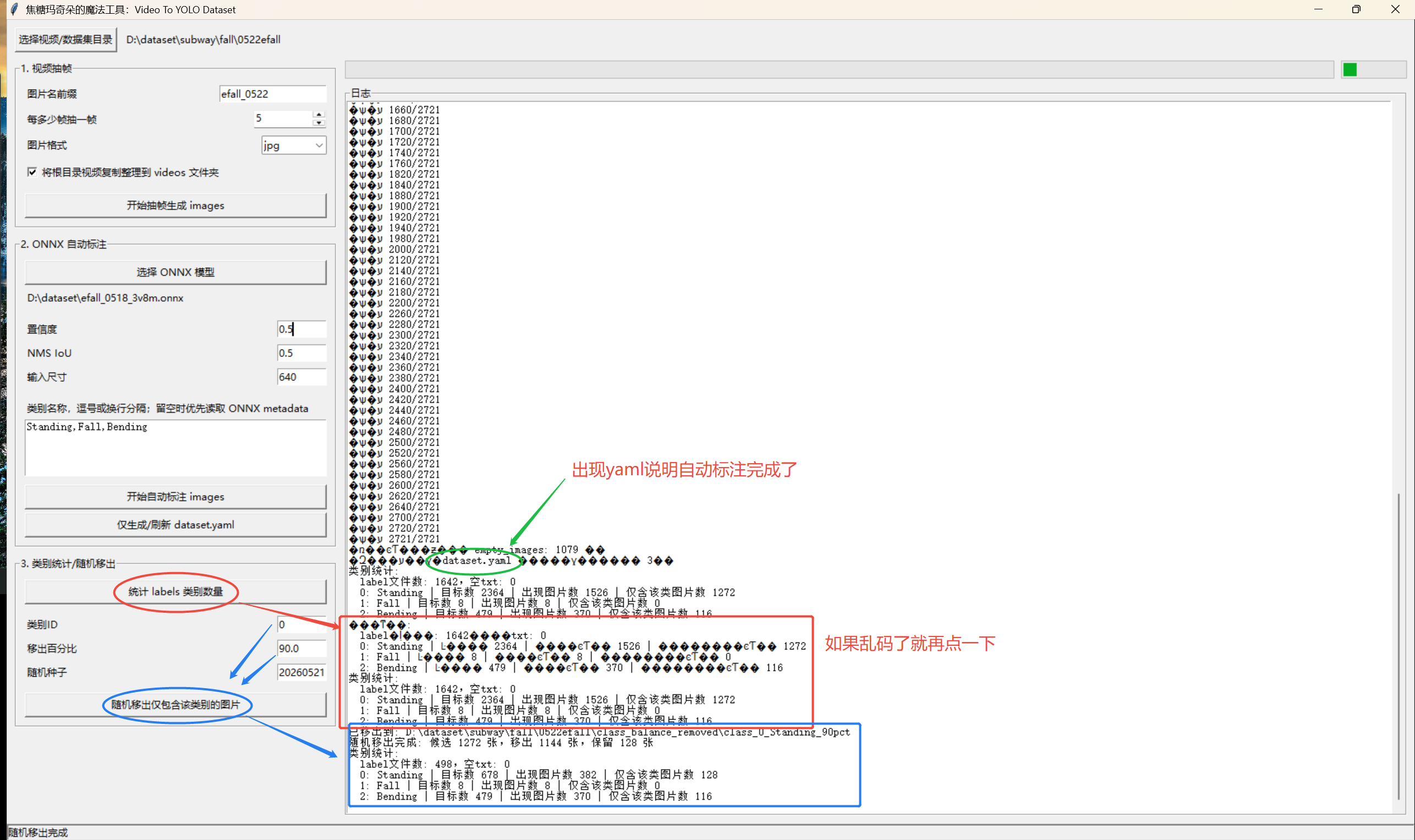
类别统计
点击 统计 labels 类别数量 后,日志会显示:
text
类别统计:
label文件数: 145,空txt: 0
0: standing | 目标数 220 | 出现图片数 121 | 仅含该类图片数 43
1: fall | 目标数 3 | 出现图片数 3
2: bending | 目标数 141 | 出现图片数 102含义:
目标数:该类别框的总数量。出现图片数:有该类别的图片数量。仅含该类图片数:整张图只包含该类别,不包含其他类别。
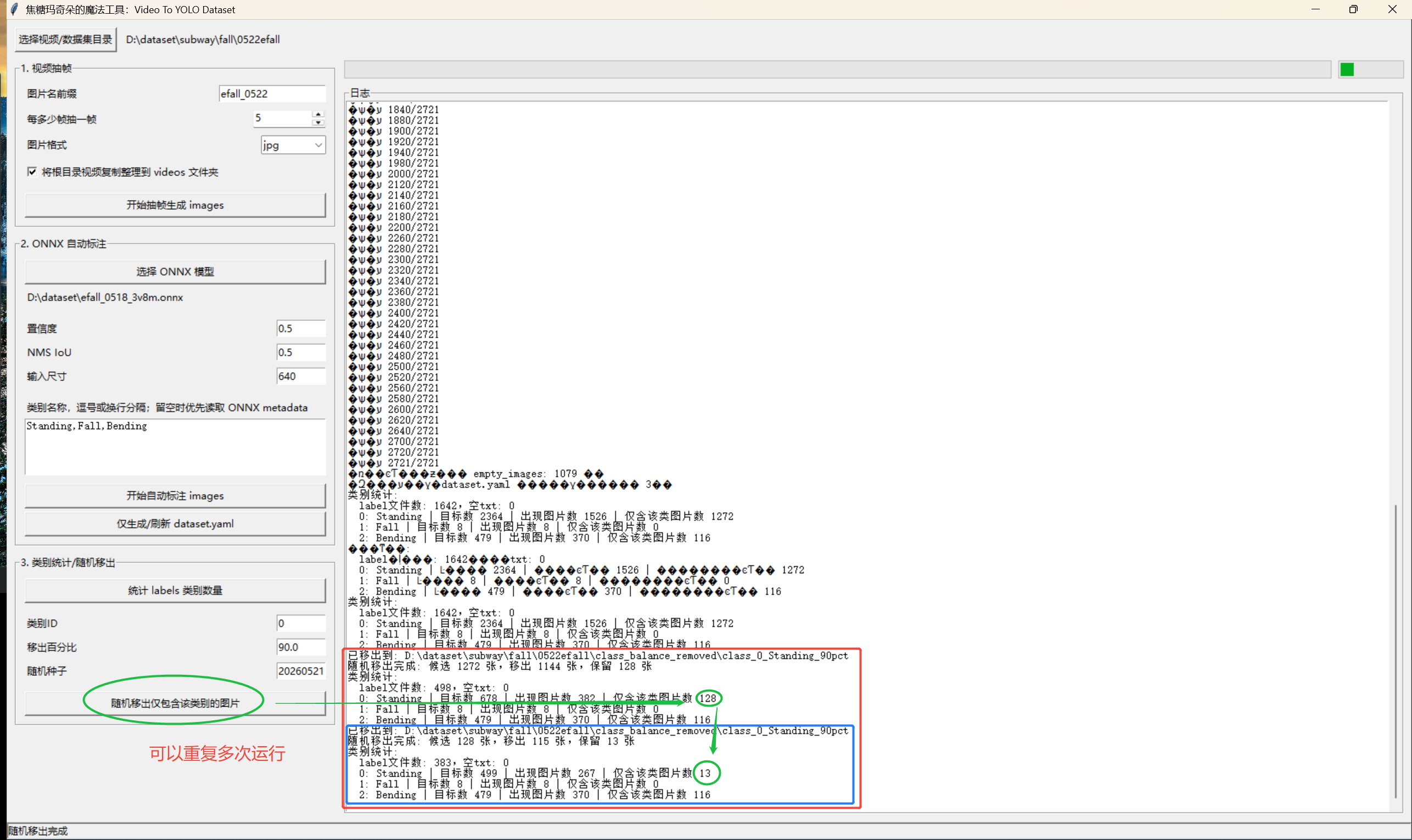
随机移出单类别图片
用于处理某个类别严重过多的问题。
例如 Standing 太多,希望随机移出 90% 的"仅包含 Standing 的图片":
类别ID填0。移出百分比填90。随机种子可保持默认。- 点击
随机移出仅包含该类别的图片。
工具只会移出"标签中全部目标都是该类别"的图片。只要图片包含其他类别,就会保留。
移出的数据会放到:
text
class_balance_removed/class_0_standing_90pct/
images/
labels/
manifest.csv这不是物理删除,可以手动恢复。
效果图区域
VideoToYolo 主界面
抽帧与自动标注日志
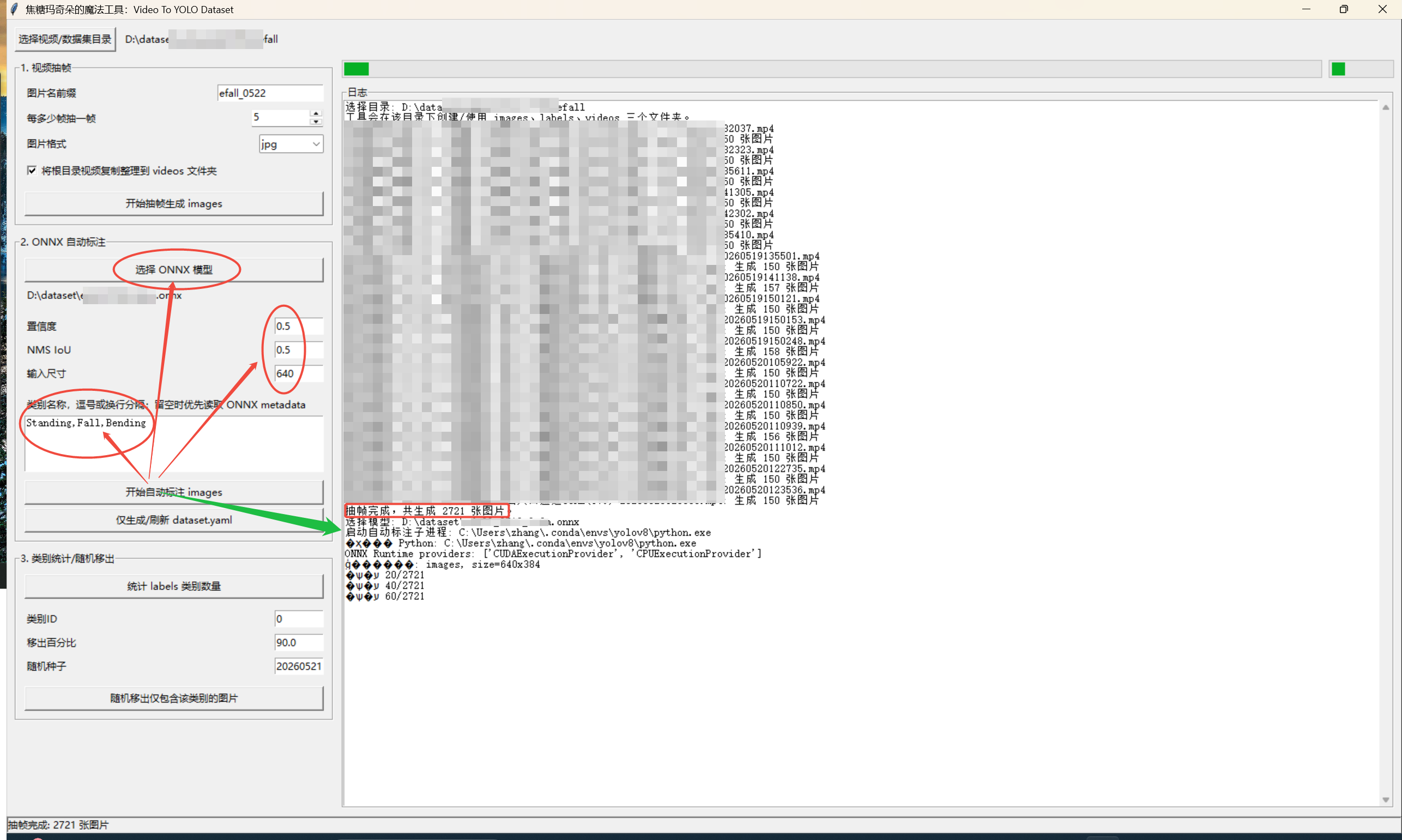
类别统计与随机移出
2. DatasetCleaner
用途
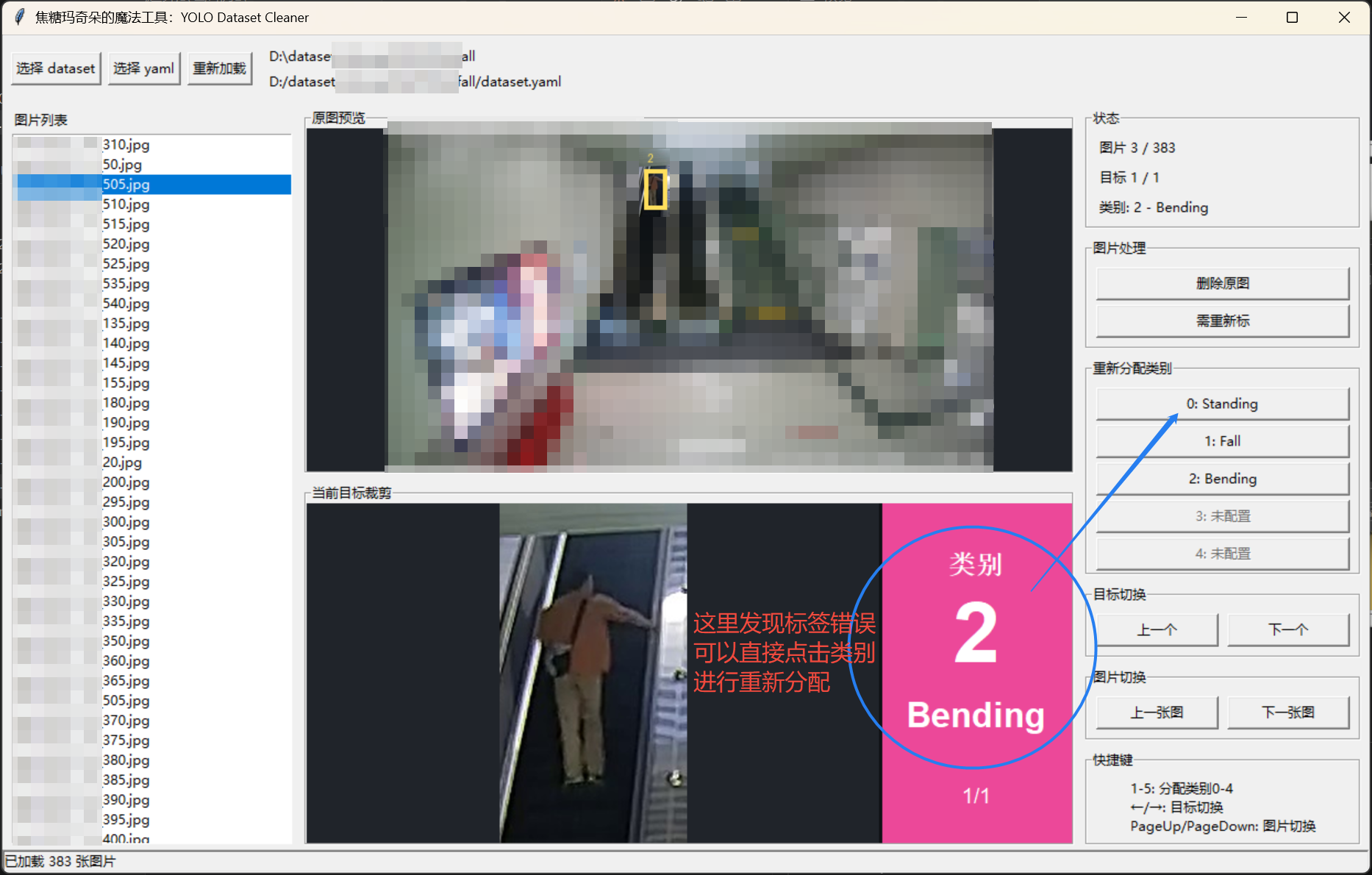
DatasetCleaner 是人工快速清洗工具,用于逐个查看 YOLO 标注目标。
它可以完成:
- 加载 YOLO 数据集
- 加载训练 yaml 中的类别名
- 显示原图场景
- 显示当前目标 20% 扩框裁剪图
- 在裁剪图右侧用大色块显示类别号和类别名
- 快速修改当前目标类别
- 把脏图移到
_delete_ - 把缺漏标图片移到
relabel - 跨图片连续切换目标
输入数据结构
默认读取:
text
dataset/
images/
train/
val/
test/
labels/
train/
val/
test/
dataset.yaml也支持没有 train/val/test 的简单结构:
text
dataset/
images/
labels/
dataset.yaml图片和标签按相对路径对应:
text
images/a.jpg -> labels/a.txt
images/train/a.jpg -> labels/train/a.txt使用流程
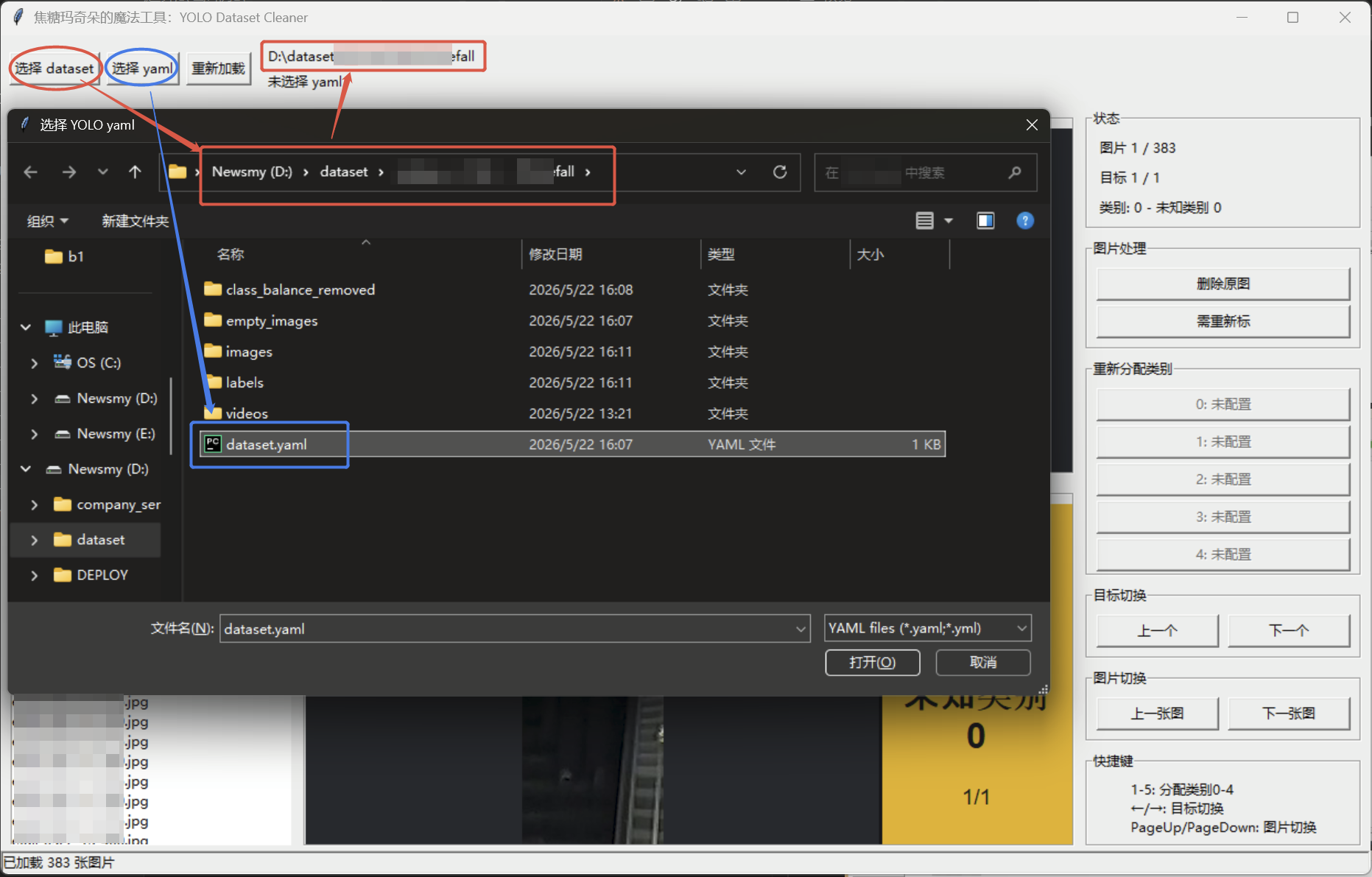
- 点击
选择 dataset。 - 点击
选择 yaml。 - 左侧选择图片,或用上一张/下一张切换。
- 查看原图场景和当前目标裁剪图。
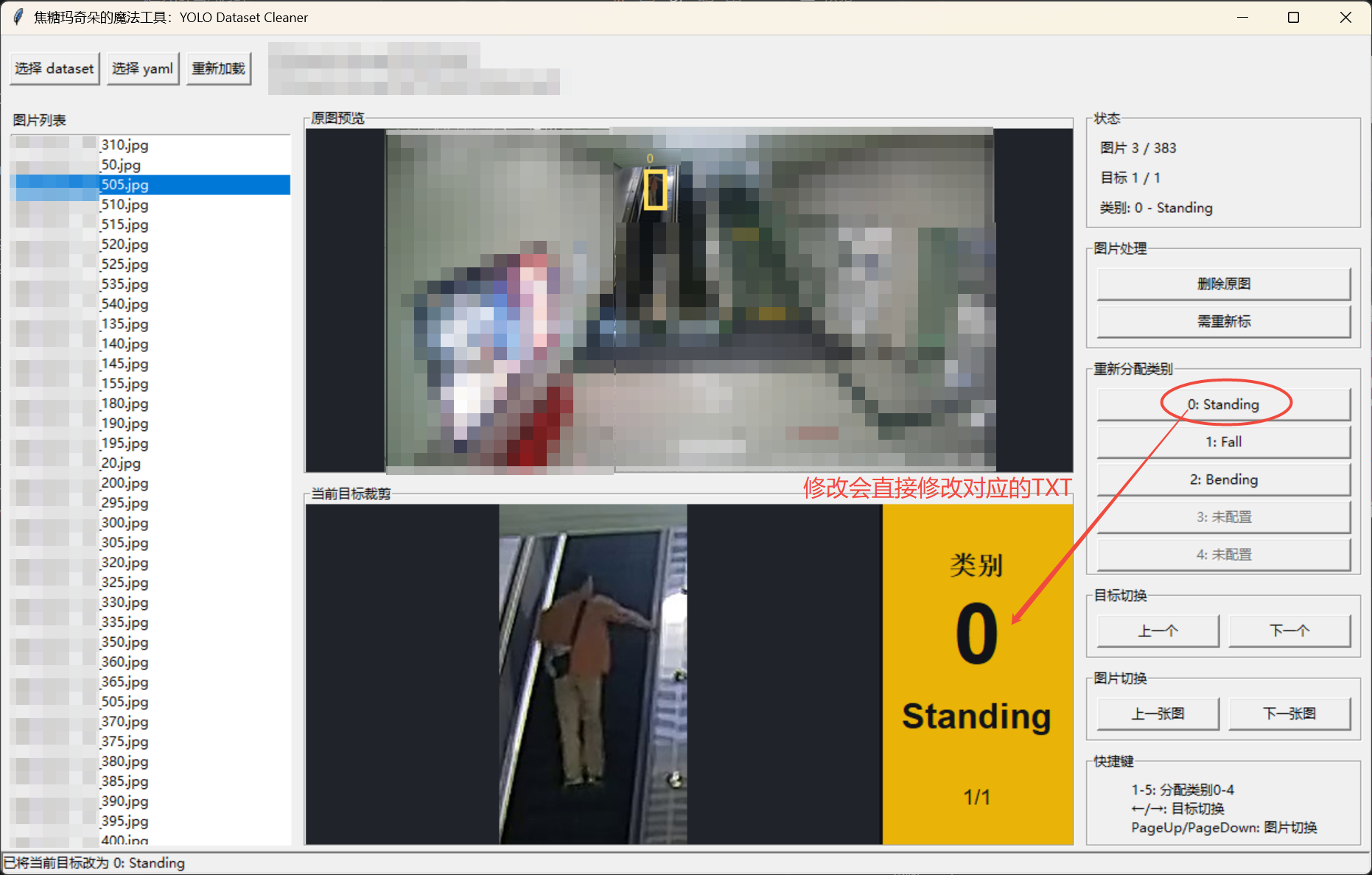
- 如果类别错误,点击右侧类别按钮。
- 如果整张图不适合训练,点击
删除原图。 - 如果图片目标有漏标,点击
需重新标。
类别修正
类别按钮显示真实 YOLO 类别号:
text
0: standing
1: fall
2: bending点击后会立即修改当前图片对应的 .txt 文件。
修改的是当前目标所在行的第一个字段,也就是 class id。bbox 坐标不变。
图片移动规则
删除原图 不是真的删除,会移动到:
text
dataset/_delete_/images/
dataset/_delete_/labels/需重新标 会移动到:
text
dataset/relabel/images/
dataset/relabel/labels/目录层级会尽量保持原来的相对路径。
目标切换逻辑
- 当前图最后一个目标点
下一个:跳到下一张图第一个目标。 - 当前图第一个目标点
上一个:跳到上一张图最后一个目标。 - 当前图没有目标时:上一个/下一个会直接切图。
快捷键:
text
1-5: 分配类别 0-4
Left / Right: 切换目标
PageUp / PageDown: 切换图片效果图区域
DatasetCleaner 主界面
目标裁剪与类别色块
3. QuickModelViewer
用途
QuickModelViewer 是快速验证 ONNX 模型效果的小工具。
它可以完成:
- 选择 ONNX 模型
- 选择单张图片
- 选择图片文件夹
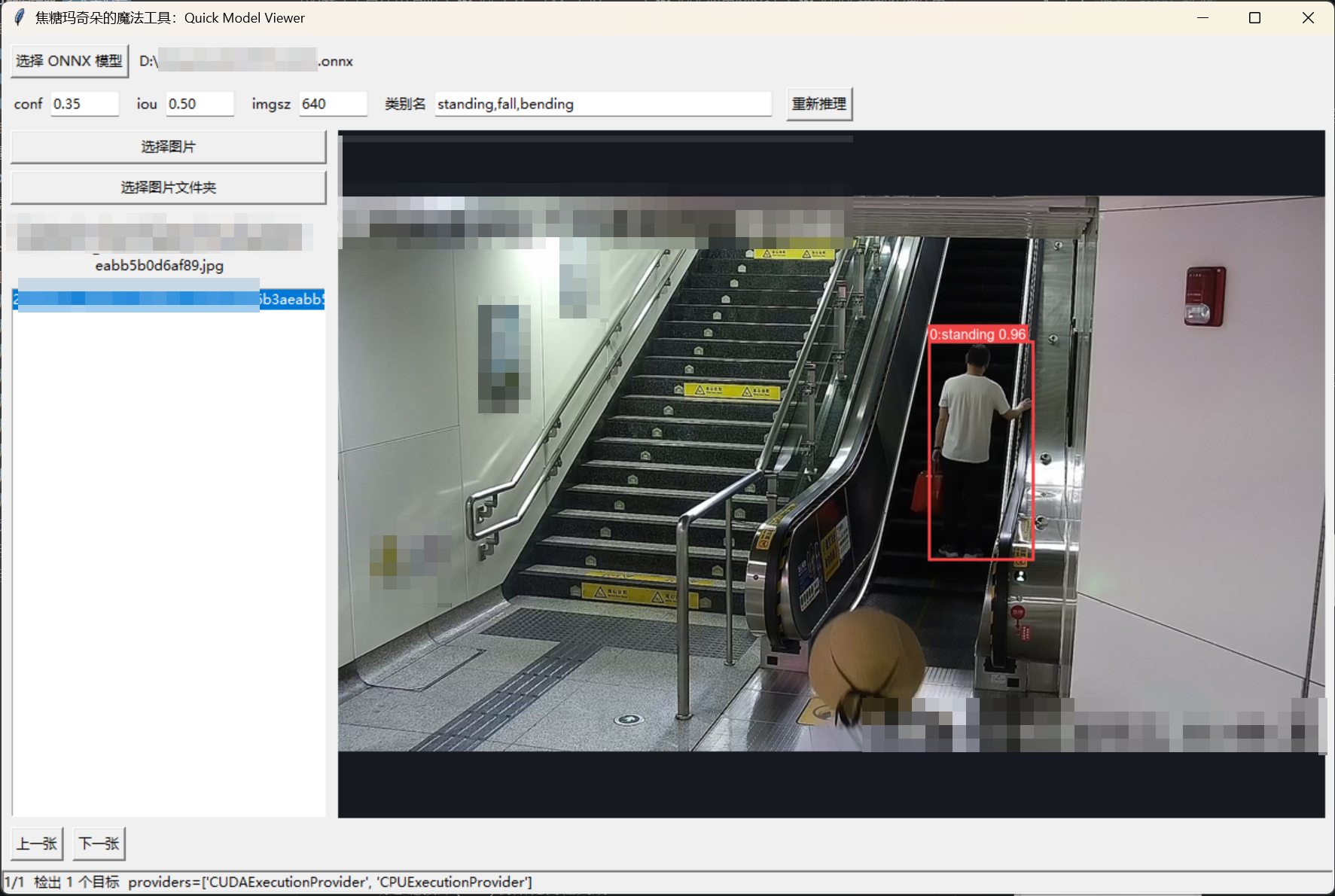
- 快速推理并画框
- 显示类别号、类别名、置信度
- 调整 conf、iou、imgsz
- 上一张/下一张快速浏览
使用流程
- 点击
选择 ONNX 模型。 - 点击
选择图片或选择图片文件夹。 - 设置
conf、iou、imgsz。 - 点击
重新推理或切换图片查看效果。
如果 ONNX 模型带有类别 metadata,工具会自动读取类别名。
如果没读到,可以手动填写:
text
standing,fall,bending推理方式
QuickModelViewer 的界面进程只负责显示。
真正的 ONNX 推理会通过独立子进程执行,这样可以绕开 onnxruntime-gpu 在 Tkinter 进程中偶发的 DLL 初始化问题。
效果图区域
QuickModelViewer 主界面
模型推理结果
常见问题与注意事项
1. onnxruntime 动态链接库初始化失败
常见报错:
text
DLL load failed while importing onnxruntime_pybind11_state
动态链接库(DLL)初始化例程失败建议:
- 不要直接双击
.py。 - 使用对应
.bat或桌面快捷方式启动。 - 确认启动窗口中 Python 是:
text
C:\Users\zhang\.conda\envs\yolov8\python.exeVideoToYolo 和 QuickModelViewer 已经采用子进程推理方式,正常情况下可以绕过这个问题。
2. 打开的是旧窗口
如果刚修改过工具,但效果没有变化,很可能旧窗口还开着。
建议:
- 关闭所有旧工具窗口。
- 重新双击桌面快捷方式。
- 再测试新功能。
3. 图片名不要包含中文
视频原名经常包含中文、括号、空格等字符。
训练集图片建议使用 ASCII 命名,例如:
text
efall_0521_1_0.jpg
efall_0521_1_15.jpgVideoToYolo 抽帧时已经默认使用:
text
图片名前缀_视频序号_帧序号.jpg4. 空图片是否参与训练
当前策略是不参与。
自动标注时,如果模型没有检出任何目标,图片会移动到:
text
empty_images/并且不会生成空 txt。
5. 随机移出不是物理删除
类别平衡时移出的数据会保存在:
text
class_balance_removed/可以手动恢复。
6. DatasetCleaner 修改类别是立即写入
点击类别按钮后,.txt 会立即被改写。
如果误点,可以再次点正确类别改回来。
7. dataset.yaml 的 train/val
VideoToYolo 默认生成:
yaml
train: images
val: images这是为了快速验证和小数据集制作方便。
正式训练前,如果需要 train/val/test 拆分,可以后续再拆目录并修改 yaml。
8. ONNX 输出格式兼容性
当前自动标注和快速验证主要兼容常见 YOLOv8 ONNX 输出:
text
[1, 4 + num_classes, N]也兼容部分已带 NMS 的输出:
text
[x1, y1, x2, y2, score, class]如果某个模型可加载但结果明显不对,优先检查:
- 输入尺寸是否正确。
- 类别名数量是否正确。
- 模型是否是 YOLO 检测模型。
- 导出 ONNX 时是否带了特殊后处理。
推荐工作流
从视频到训练集
- 使用 VideoToYolo 抽帧。
- 使用 VideoToYolo 自动标注。
- 使用 VideoToYolo 统计类别。
- 必要时随机移出过多类别。
- 使用 QuickModelViewer 抽查模型标注效果。
- 使用 DatasetCleaner 人工清洗类别和脏图。
- 训练 YOLO 模型。
快速验证模型
- 使用 QuickModelViewer 选择模型。
- 选择几张典型图片。
- 调整 conf/iou。
- 判断模型是否适合作为自动标注模型。