Ollama作为开源大模型本地化部署的核心工具,凭借轻量、易用、高效的特性,成为开发者实现大模型本地运行的首选方案。近日,Ollama正式发布v0.22.1版本,此次更新堪称一次全方位的功能升级与体验优化,涵盖新增Poolside集成、完善模型推荐机制、优化量化策略、适配多模型架构、修复核心Bug等多个维度,涉及代码修改文件数十个,新增代码数千行,进一步提升了Ollama的兼容性、实用性和性能表现。
一、版本核心更新概述
Ollama v0.22.1版本的更新核心围绕"兼容性拓展、体验优化、性能提升"三大目标展开,涉及多个模块的代码重构与功能新增。具体来看,此次更新主要包含以下几大方向:
-
新增Poolside集成:支持Poolside CLI的运行与管理,完善相关测试用例,实现跨平台适配(Windows系统暂不支持)。
-
完善模型推荐机制:新增模型推荐接口、缓存管理,优化推荐模型的排序与展示逻辑,支持从服务端获取动态推荐列表。
-
优化量化策略:新增Laguna模型专属量化逻辑,支持FP8张量源的量化适配,调整不同模型的量化类型优先级,提升量化模型的性能与精度。
-
多模型架构适配:新增Laguna、Nemotron-H系列模型的适配支持,完善模型渲染器、解析器的自动配置逻辑。
-
推理性能优化:优化日志概率(Logprobs)的输出逻辑,修复内置解析器场景下的日志概率丢失问题,完善缓存机制提升推理速度。
-
Bug修复与细节优化:修复多个测试用例的异常问题,优化命令行交互体验,完善集成注册与管理逻辑,提升版本稳定性。
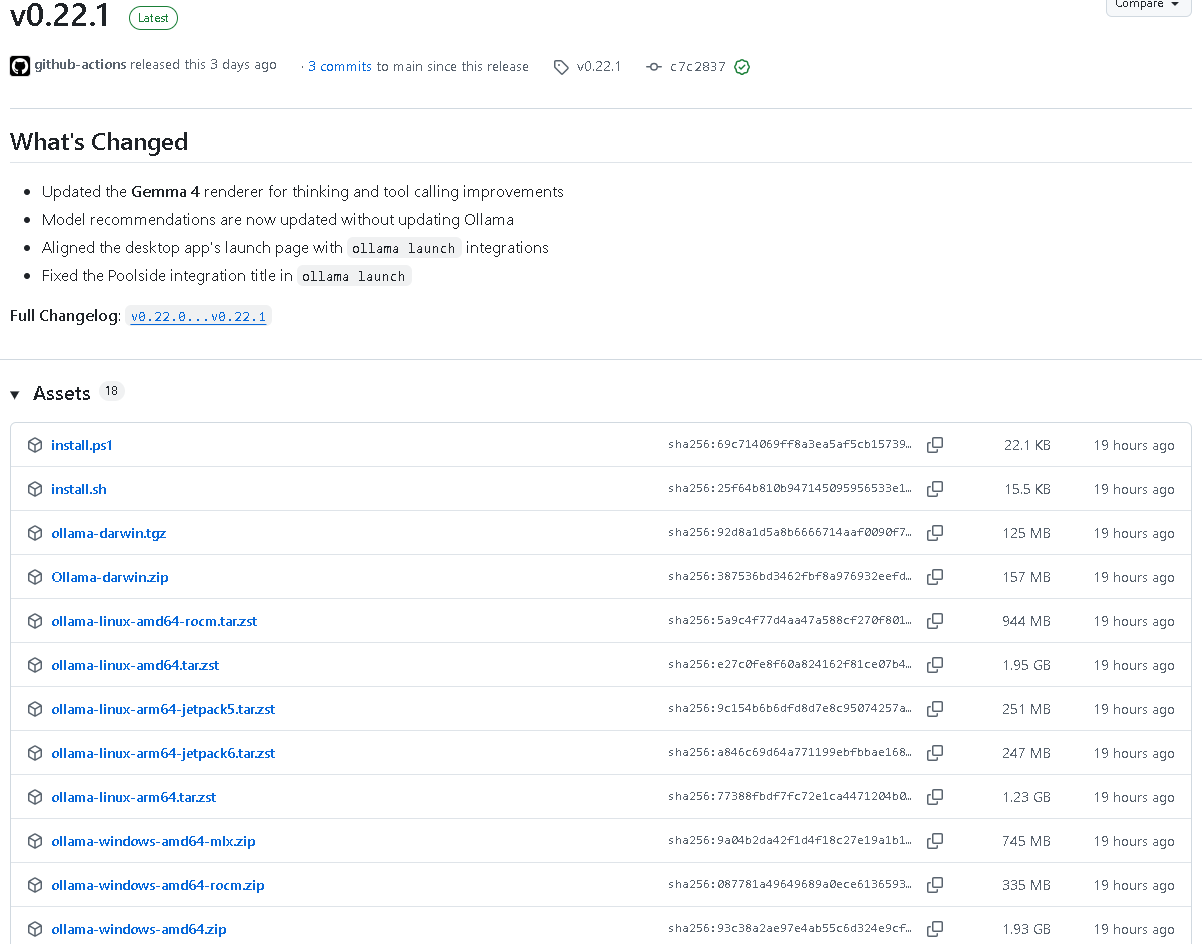
此次更新覆盖了Ollama的核心模块,包括launch命令模块、server服务模块、模型量化模块、模型适配模块等,涉及代码文件近50个,新增代码超3000行,修改代码超2000行,是一次规模较大的版本升级。接下来,我们将逐一拆解每个模块的具体更新内容。
二、核心功能更新详解
2.1 新增Poolside集成:拓展外部工具适配能力
此次更新最引人注目的功能之一,便是新增了Poolside集成支持。Poolside作为一款轻量的大模型运行工具,与Ollama的集成的,进一步拓展了Ollama的外部工具适配范围,为开发者提供了更多的运行选择。此次集成涉及多个文件的新增与修改,具体实现细节如下:
2.1.1 Poolside核心实现(cmd/launch/poolside.go)
新增poolside.go文件,实现了Poolside的Runner接口,用于处理Poolside CLI的运行逻辑。核心功能包括:
-
定义Poolside结构体,实现String()方法,返回集成名称"Pool",用于在命令行中展示。
-
实现args()方法,用于构建Poolside的运行参数,支持传入模型名称和额外参数,参数格式为"-m 模型名 额外参数"。
-
实现Run()方法,核心逻辑的是:检查当前系统是否为Windows(Windows暂不支持Poolside),若为Windows则返回不支持错误;查找Poolside的可执行文件"pool",若未找到则返回安装提示;构建运行命令,设置环境变量(POOLSIDE_STANDALONE_BASE_URL和POOLSIDE_API_KEY),并执行命令,将标准输入、输出、错误流与当前进程关联。
-
定义poolsideUnsupportedError()方法,返回Windows系统不支持Poolside的错误提示信息。
其中,环境变量的设置是关键,POOLSIDE_STANDALONE_BASE_URL设置为Ollama的基础地址(加上/v1后缀),POOLSIDE_API_KEY设置为"ollama",确保Poolside能够与Ollama正常通信。
2.1.2 Poolside测试用例(cmd/launch/poolside_test.go)
新增poolside_test.go文件,为Poolside集成提供了完善的测试用例,覆盖参数构建、运行逻辑、跨平台适配等场景,确保集成功能的稳定性。具体测试场景包括:
-
TestPoolsideArgs:测试参数构建逻辑,验证带模型、不带模型、带额外参数等场景下,参数是否正确生成。
-
TestPoolsideRunSetsOllamaEnv:测试Run()方法是否正确设置环境变量,确保Poolside能够正确关联Ollama的服务地址和API密钥。
-
TestPoolsideRunWindowsUnsupported:测试Windows系统下的不支持逻辑,验证是否能够正确返回错误提示。
测试用例中通过模拟不同系统环境、不同参数输入,验证了Poolside集成的核心功能,确保在非Windows系统下能够正常运行,Windows系统下能够给出明确的不支持提示。
2.1.3 集成注册与管理(cmd/launch/registry.go、cmd/launch/launch_test.go等)
为了让Ollama能够识别并管理Poolside集成,此次更新对集成注册相关代码进行了修改:
-
在registry.go中,更新launcherIntegrationOrder列表,将"pool"添加到集成顺序中,确保Poolside能够被正确加载和展示。
-
在launch_test.go的多个测试用例中,新增"/api/experimental/model-recommendations"接口的模拟响应,返回空推荐列表,避免因新增模型推荐机制导致测试用例失败,同时确保Poolside集成的测试环境正常。
-
在launch.go的Supported integrations说明中,新增"pool Pool",用于在命令行帮助信息中展示Poolside集成的说明。
2.1.4 Poolside相关测试补充(cmd/launch/integration_test.go)
在integration_test.go中,补充了Poolside集成的相关测试,包括:
-
在TestIntegrationLookup中,新增Poolside的集成查找测试,确保能够正确查找到Poolside集成。
-
在TestIntegrationRegistry中,更新expectedIntegrations列表,添加"pool",验证集成注册是否成功。
-
在TestIntegration_InstallHint中,新增Poolside的安装提示测试,确保当Poolside未安装时,能够返回正确的安装地址(https://github.com/poolsideai/pool)。
-
新增TestListIntegrationInfos_HidesPoolsideOnWindows测试,验证Windows系统下是否会隐藏Poolside集成,避免用户在不支持的系统中看到该集成。
-
新增TestEnsureIntegrationInstalled_PoolsideUnsupportedOnWindows测试,验证Windows系统下调用EnsureIntegrationInstalled方法时,是否会返回正确的不支持错误。
通过以上测试用例的补充,确保了Poolside集成在不同场景下的稳定性和正确性,为开发者使用Poolside集成提供了可靠保障。
2.2 完善模型推荐机制:实现动态推荐与缓存管理
Ollama v0.22.1版本对模型推荐机制进行了全面优化,新增了模型推荐接口、缓存管理逻辑,优化了推荐模型的排序与展示,支持从服务端获取动态推荐列表,提升了用户选择模型的体验。此次更新涉及cmd/launch/launch.go、cmd/launch/models.go、server/model_recommendations.go等多个文件,具体细节如下:
2.2.1 模型推荐核心逻辑(cmd/launch/launch.go)
在launch.go中,新增了模型推荐相关的核心逻辑,包括推荐列表的获取、缓存、 fallback机制等:
-
新增recommendations()方法,用于获取模型推荐列表。核心逻辑的是:调用requestRecommendations()方法从服务端获取动态推荐列表;若获取失败或推荐列表为空,则 fallback到内置的推荐模型列表(recommendedModels);同时设置动态云模型限制(setDynamicCloudModelLimits),确保推荐模型的参数正确。
-
新增requestRecommendations()方法,用于向服务端发送模型推荐请求(调用apiClient.ModelRecommendationsExperimental方法),解析响应结果,过滤无效推荐(如空模型名、重复模型、缺少上下文长度或最大输出令牌的云模型),生成推荐列表。
-
修改loadSelectableModels()方法,将原来的buildModelList()调用替换为buildModelListWithRecommendations(),传入获取到的推荐列表,实现推荐模型与现有模型的融合展示。
其中,requestRecommendations()方法中添加了日志记录,当云模型推荐缺少上下文长度或最大输出令牌时,会输出警告日志,便于开发者排查问题;同时通过seen map避免重复推荐,确保推荐列表的唯一性。
2.2.2 模型推荐辅助逻辑(cmd/launch/models.go)
在models.go中,对模型推荐相关的辅助逻辑进行了优化,包括推荐模型参数调整、云模型限制管理等:
-
更新recommendedModels列表,为每个推荐模型补充了ContextLength、MaxOutputTokens、VRAMBytes等参数,其中云模型补充上下文长度和最大输出令牌,本地模型补充VRAM需求,提升用户选择模型的参考价值。例如,kimi-k2.6:cloud的ContextLength设置为262144,MaxOutputTokens设置为262144;qwen3.5的VRAMBytes设置为14*format.GigaByte。
-
新增displayVRAM()方法,用于将VRAM字节数转换为易读的格式(如~14GB),当VRAMBytes为0时返回空字符串,确保模型描述的简洁性。
-
新增cloudModelLimitsFromRecommendations()方法,用于从推荐列表中提取云模型的上下文长度和最大输出令牌,生成云模型限制映射。
-
新增mergeCloudModelLimits()方法,用于合并基础云模型限制和额外云模型限制,确保云模型限制的完整性。
-
优化lookupCloudModelLimit()方法,优先从动态云模型限制(dynamicCloudModelLimits)中查找,再从基础云模型限制(cloudModelLimits)中查找,支持动态更新云模型限制。
-
新增setDynamicCloudModelLimits()方法,用于设置动态云模型限制,通过互斥锁保证并发安全。
-
新增buildModelListWithRecommendations()方法,将推荐列表与现有模型列表融合,实现推荐模型的优先展示,同时保留现有模型的展示逻辑。
此外,还删除了原来的recommendedVRAM映射,改用displayVRAM()方法动态生成VRAM提示,提升了代码的灵活性和可维护性。
2.2.3 模型推荐接口与缓存(server/model_recommendations.go、server/routes.go)
在server模块中,新增了模型推荐接口和缓存管理逻辑,支持服务端返回动态推荐列表,并通过缓存提升响应速度:
-
新增model_recommendations.go文件,实现了模型推荐的缓存管理,包括缓存的初始化、获取、更新等逻辑。通过SWR(Stale-While-Revalidate)策略,实现缓存的高效更新,确保推荐列表的时效性。
-
在routes.go中,新增"/api/experimental/model-recommendations"接口,用于返回模型推荐列表。接口逻辑的是:优先从缓存中获取推荐列表,若缓存未命中或过期,则从服务端获取最新推荐列表,更新缓存后返回;同时输出日志,记录推荐列表的来源(缓存或默认)和数量。
-
在Server结构体中,新增modelRecommendations字段,用于管理模型推荐缓存;在Serve()方法中,初始化模型推荐缓存并启动缓存更新机制。
2.2.4 模型推荐测试用例(server/model_recommendations_test.go)
新增model_recommendations_test.go文件,为模型推荐机制提供了完善的测试用例,覆盖缓存逻辑、接口响应、推荐列表过滤等场景,确保模型推荐功能的稳定性和正确性。测试用例包括缓存命中、缓存过期、推荐列表过滤、服务端请求失败等场景,全面验证了模型推荐机制的核心逻辑。
2.3 优化量化策略:适配多模型架构,提升量化性能
量化是大模型本地化部署的关键技术,能够有效降低模型的内存占用,提升运行速度。Ollama v0.22.1版本对量化策略进行了全面优化,新增Laguna模型专属量化逻辑,支持FP8张量源的量化适配,调整不同模型的量化类型优先级,进一步提升了量化模型的性能与精度。此次更新涉及server/quantization.go、server/laguna_quantization_test.go、server/create.go等多个文件,具体细节如下:
2.3.1 量化核心逻辑优化(server/quantization.go)
在quantization.go中,对量化核心逻辑进行了多处优化,新增了架构专属量化逻辑和FP8张量源适配:
-
新增quantizeState结构体字段,包括preserveSourceFP8ToQ8(是否保留FP8源张量到Q8量化)、preserveSourceQ4(是否保留FP8源张量到Q4量化)、sourceFP8Tensors(FP8源张量名称集合),用于适配FP8张量源的量化逻辑。
-
新增hasSourceFP8Tensors()方法,用于判断模型是否包含FP8源张量(通过kv.String("source_quantization") == "hf_fp8"且kv.Strings("source_fp8_tensors")非空判断)。
-
新增sourceFP8TensorSet()方法,用于将FP8源张量名称转换为集合,便于快速查询。
-
优化quantize()方法,初始化quantizeState时,设置sourceFP8Tensors、preserveSourceFP8ToQ8、preserveSourceQ4等字段,根据模型的FP8源张量配置,调整量化策略。
-
优化newType()方法,在量化过程中,根据FP8源张量配置,保留指定张量的量化类型;同时新增Laguna模型的专属量化逻辑,对不同类型的张量采用不同的量化策略。
-
新增isLagunaGGUFRoutedExpertWeight()方法,用于判断张量是否为Laguna模型的路由专家权重(如ffn_gate_exps.weight、ffn_up_exps.weight、ffn_down_exps.weight)。
-
新增lagunaGGUFBlockIndex()方法,用于提取Laguna模型张量的块索引,为不同块的量化策略调整提供依据。
-
新增lagunaGGUFQuantization()方法,实现Laguna模型的专属量化逻辑:非路由专家权重保留原始类型,不进行量化;路由专家权重根据块索引、量化类型、块数量,调整量化类型(如Q4_K_M类型下,部分块提升为Q6_K类型)。
-
优化getTensorNewType()方法,调整量化类型的优先级,新增对Laguna模型的支持,同时优化Qwen3系列模型的量化逻辑。
此次量化策略优化的核心亮点,是实现了FP8张量源的精准适配和Laguna模型的专属量化,既能保证量化模型的性能,又能避免量化导致的精度损失,提升了大模型本地化运行的体验。
2.3.2 Laguna量化测试用例(server/laguna_quantization_test.go)
新增laguna_quantization_test.go文件,为Laguna模型的量化逻辑提供了专门的测试用例,覆盖不同张量类型、不同量化类型、不同块数量的场景,验证Laguna量化逻辑的正确性。具体测试场景包括:
-
非路由权重的量化保留:验证非路由专家权重(如blk.1.attn_q.weight)在量化过程中是否保留原始类型,不进行量化。
-
共享专家权重的量化保留:验证共享专家权重(如blk.1.ffn_gate_shexp.weight)在量化过程中是否保留原始类型。
-
路由门权重的量化:验证路由门权重(如blk.1.ffn_gate_exps.weight)在不同量化类型下的量化结果是否符合预期。
-
路由下采样权重的量化:验证路由下采样权重(如blk.1.ffn_down_exps.weight)在不同量化类型、不同块数量下的量化类型提升是否符合预期。
通过这些测试用例,确保了Laguna模型量化逻辑的正确性,为Laguna模型的本地化部署提供了可靠保障。
2.3.3 量化相关逻辑调整(server/create.go)
在create.go中,对模型创建过程中的量化逻辑进行了调整,适配FP8张量源和Laguna模型:
-
修改createModel()方法,在量化逻辑中,新增对BF16模型的支持,将原来的"quantization is only supported for F16 and F32 models"提示修改为"quantization is only supported for F16, BF16 and F32 models",支持更多类型的模型量化。
-
新增hasSourceFP8Tensors()方法的调用,当模型包含FP8源张量且未指定量化类型时,自动设置量化类型为Q8_0,确保FP8源张量的量化适配。
2.3.4 量化测试用例补充(server/quantization_test.go)
在quantization_test.go中,补充了FP8源张量量化的相关测试用例,包括:
-
source_fp8_q8_preserves_bf16_tensors:测试FP8源张量在Q8_0量化时,是否只量化指定的FP8张量,保留其他BF16张量。
-
source_fp8_q4_promotes_bf16_tensors_to_q8:测试FP8源张量在Q4_K_M量化时,是否将非FP8张量提升为Q8_0量化,确保量化精度。
这些测试用例的补充,进一步验证了FP8源张量量化逻辑的正确性,确保量化策略的稳定性。
2.4 多模型架构适配:新增Laguna、Nemotron-H系列模型支持
Ollama v0.22.1版本进一步拓展了模型架构的适配范围,新增了Laguna、Nemotron-H系列模型的支持,完善了模型渲染器、解析器的自动配置逻辑,确保这些模型能够在Ollama中正常运行。此次更新涉及server/create.go、server/routes_create_test.go、x/models/laguna等多个文件,具体细节如下:
2.4.1 Laguna模型适配(x/models/laguna/laguna.go、x/models/laguna/laguna_test.go)
新增Laguna模型的适配代码,包括模型的核心实现和测试用例,确保Laguna模型能够正常加载和运行:
-
新增laguna.go文件,实现了Laguna模型的核心逻辑,包括模型的初始化、前向传播、注意力机制等。Laguna模型采用了路由专家架构,适配了动态专家选择机制,能够有效提升模型的推理性能。
-
新增laguna_test.go文件,为Laguna模型提供了完善的测试用例,覆盖模型初始化、前向传播、注意力计算等场景,验证模型实现的正确性。
2.4.2 Nemotron-H系列模型适配(server/create.go、server/routes_create_test.go)
在create.go中,新增了Nemotron-H系列模型的适配逻辑,包括nemotron_h、nemotron_h_moe、nemotron_h_omni三种模型:
-
当模型架构为Nemotron-H系列时,自动设置渲染器(Renderer)和解析器(Parser)为"nemotron-3-nano",确保模型的输入输出格式正确。
-
如果用户手动指定了渲染器和解析器,则保留用户的设置,不进行自动覆盖,提升灵活性。
在routes_create_test.go中,新增了Nemotron-H系列模型的测试用例,包括:
-
TestCreateNemotronHDefaultsRendererParser:测试Nemotron-H系列模型在未指定渲染器和解析器时,是否会自动设置为"nemotron-3-nano"。
-
TestCreateNemotronHDefaultsKeepExplicitRendererParser:测试Nemotron-H系列模型在手动指定渲染器和解析器时,是否会保留用户的设置。
2.4.3 模型架构相关补充(server/sched.go、x/create/laguna.go等)
在sched.go中,更新了不支持并行请求的模型架构列表,将"nemotron_h_omni"添加到列表中,确保该模型在运行时不会启用并行请求,避免出现运行异常。
在x/create/laguna.go中,新增了Laguna模型的创建逻辑,支持Laguna模型的快速创建和配置,适配Laguna模型的专属参数和结构。
2.5 推理性能优化:完善日志概率输出与缓存机制
此次更新对Ollama的推理性能进行了多方面优化,重点完善了日志概率(Logprobs)的输出逻辑,优化了缓存机制,提升了推理速度和响应效率。具体更新内容如下:
2.5.1 日志概率输出优化(server/routes.go、server/routes_generate_test.go)
日志概率是大模型推理过程中的重要指标,用于衡量模型输出结果的置信度。此次更新优化了日志概率的输出逻辑,修复了内置解析器场景下的日志概率丢失问题:
-
在routes.go的GenerateHandler()方法中,修改了日志概率的输出判断条件,将原来的"res.Response != "" || res.Thinking != "" || res.Done || len(res.ToolCalls) > 0"修改为"res.Response != "" || res.Thinking != "" || res.Done || len(res.ToolCalls) > 0 || len(res.Logprobs) > 0",确保即使解析器仍在缓冲可见内容,只要存在日志概率,就会输出相关结果,避免日志概率丢失。
-
在routes_generate_test.go中,新增TestGenerateLogprobsWithBuiltinParser测试用例,验证内置解析器场景下,日志概率是否能够正常输出,确保优化后的逻辑正确。
2.5.2 缓存机制优化(x/mlxrunner/cache/*)
在mlxrunner的缓存模块中,对缓存机制进行了全面优化,提升了推理过程中的缓存利用率,减少重复计算,从而提升推理速度:
-
优化cache.go中的缓存管理逻辑,调整缓存的存储和读取策略,提升缓存命中率。
-
完善recurrent.go中的循环缓存逻辑,优化循环注意力的缓存处理,减少内存占用,提升推理效率。
-
新增rotating_attention_test.go文件,为旋转注意力缓存提供专门的测试用例,验证缓存逻辑的正确性。
-
优化recurrent_test.go中的测试用例,覆盖更多缓存场景,确保缓存机制的稳定性。
2.6 其他重要更新:Bug修复与细节优化
除了上述核心功能更新外,Ollama v0.22.1版本还进行了大量的Bug修复和细节优化,覆盖测试用例、命令行交互、模型配置等多个方面,提升了版本的稳定性和易用性。
2.6.1 测试用例修复与补充
此次更新修复了多个测试用例的异常问题,补充了大量缺失的测试用例,确保版本的稳定性:
-
在cmd/launch/launch_test.go中,为所有测试用例新增了"/api/experimental/model-recommendations"接口的模拟响应,避免因新增模型推荐机制导致测试用例失败。
-
在server/routes_create_test.go中,新增TestCreateLagunaDetectsRendererParser测试用例,验证Laguna模型是否能够自动检测并设置正确的渲染器和解析器。
-
修复了quantization_test.go中的部分测试用例,确保量化逻辑的测试覆盖全面。
2.6.2 模型配置优化
在server/create.go中,优化了模型创建过程中的配置逻辑,新增了Laguna模型的渲染器和解析器自动配置,确保模型能够正常运行。
2.6.3 命令行交互优化
在cmd/launch/launch.go中,更新了Supported integrations说明,新增Poolside集成的说明,便于用户了解和使用该集成;同时优化了命令行参数的解析逻辑,提升交互体验。
2.6.4 其他细节优化
-
在x/tokenizer/tokenizer_load.go中,新增了tokenizer的加载逻辑,完善了tokenizer的管理,提升了模型的分词效率。
-
在x/models/nn/目录下,新增了recurrent.go、sdpa.go等文件,实现了循环神经网络和缩放点积注意力的核心逻辑,为多模型架构提供支持。
-
优化了多个模型的实现代码(如gemma4、qwen3_5等),修复了潜在的Bug,提升了模型的运行稳定性。
三、版本更新总结与应用建议
3.1 版本更新总结
Ollama v0.22.1版本是一次全方位的功能升级,此次更新的核心价值在于:
-
拓展了外部工具适配能力:新增Poolside集成,为开发者提供了更多的大模型运行选择,丰富了Ollama的生态。
-
提升了用户体验:完善模型推荐机制,实现动态推荐与缓存管理,帮助用户快速选择合适的模型;优化日志概率输出,为开发者提供更精准的推理指标。
-
增强了模型兼容性:新增Laguna、Nemotron-H系列模型的适配,拓展了Ollama支持的模型架构范围;优化量化策略,适配FP8张量源,提升了量化模型的性能与精度。
-
提升了版本稳定性:修复了多个Bug,补充了大量测试用例,优化了核心逻辑,确保Ollama在不同场景下的稳定运行。
此次更新涉及的代码修改范围广、内容多,充分体现了Ollama团队对用户需求的关注和对产品质量的追求,进一步巩固了Ollama在大模型本地化部署领域的优势地位。
3.2 应用建议
针对Ollama v0.22.1版本的更新内容,结合实际应用场景,为开发者提供以下应用建议:
-
对于需要使用Poolside工具的开发者,可在非Windows系统(如Linux、macOS)中升级至v0.22.1版本,体验Poolside与Ollama的集成功能,注意需先安装Poolside CLI(可通过https://github.com/poolsideai/pool获取)。
-
对于使用Laguna、Nemotron-H系列模型的开发者,升级后无需手动配置渲染器和解析器,Ollama会自动适配,可直接加载模型运行,同时建议使用优化后的量化策略,提升模型运行性能。
-
对于关注模型推荐和日志概率的开发者,可充分利用新增的模型推荐接口和优化后的日志概率输出逻辑,提升模型选择效率和推理结果分析能力。
-
对于追求推理性能的开发者,可关注缓存机制的优化,合理配置模型参数,充分利用量化策略,降低模型内存占用,提升推理速度。
-
Windows系统用户需注意,此次更新中的Poolside集成暂不支持Windows系统,后续可关注Ollama的版本更新,等待Windows系统的支持。
3.3 后续展望
Ollama v0.22.1版本的更新,为大模型本地化部署提供了更强大的功能和更优的体验。结合此次更新的方向,后续Ollama可能会继续推进以下方面的发展:
-
完善Poolside集成的Windows系统支持,实现跨平台的全面适配。
-
拓展更多模型架构的适配,支持更多主流大模型的本地化部署。
-
进一步优化量化策略和缓存机制,提升大模型的推理性能和运行效率。
-
丰富模型推荐机制,结合用户的使用场景和硬件配置,提供更精准的模型推荐。
四、总结
Ollama v0.22.1版本的更新,是一次兼顾功能拓展、体验优化和性能提升的重大升级,涵盖了Poolside集成、模型推荐、量化策略、模型适配等多个核心模块,为开发者提供了更强大、更易用、更稳定的大模型本地化部署工具。