在数字经济浪潮下,数据已成为企业核心生产要素,被誉为"新时代的石油"。然而,原始数据往往杂乱无章------缺失的字段、错误的格式、重复的记录、逻辑矛盾的数据随处可见,这样的"劣质数据"不仅无法为决策提供支撑,反而可能误导企业方向,造成巨大损失。此时,ETL(抽取Extract、转换Transform、加载Load)作为数据处理的核心环节,就像数据治理的"净化器",全程守护数据质量,让数据从"(raw material)"蜕变为"高价值资产"。下面演示如何使用ETLCLoud高效的数据质量评估提示数据准确性。
一、数据源配置
来到平台首页,点击数据源管理模块。
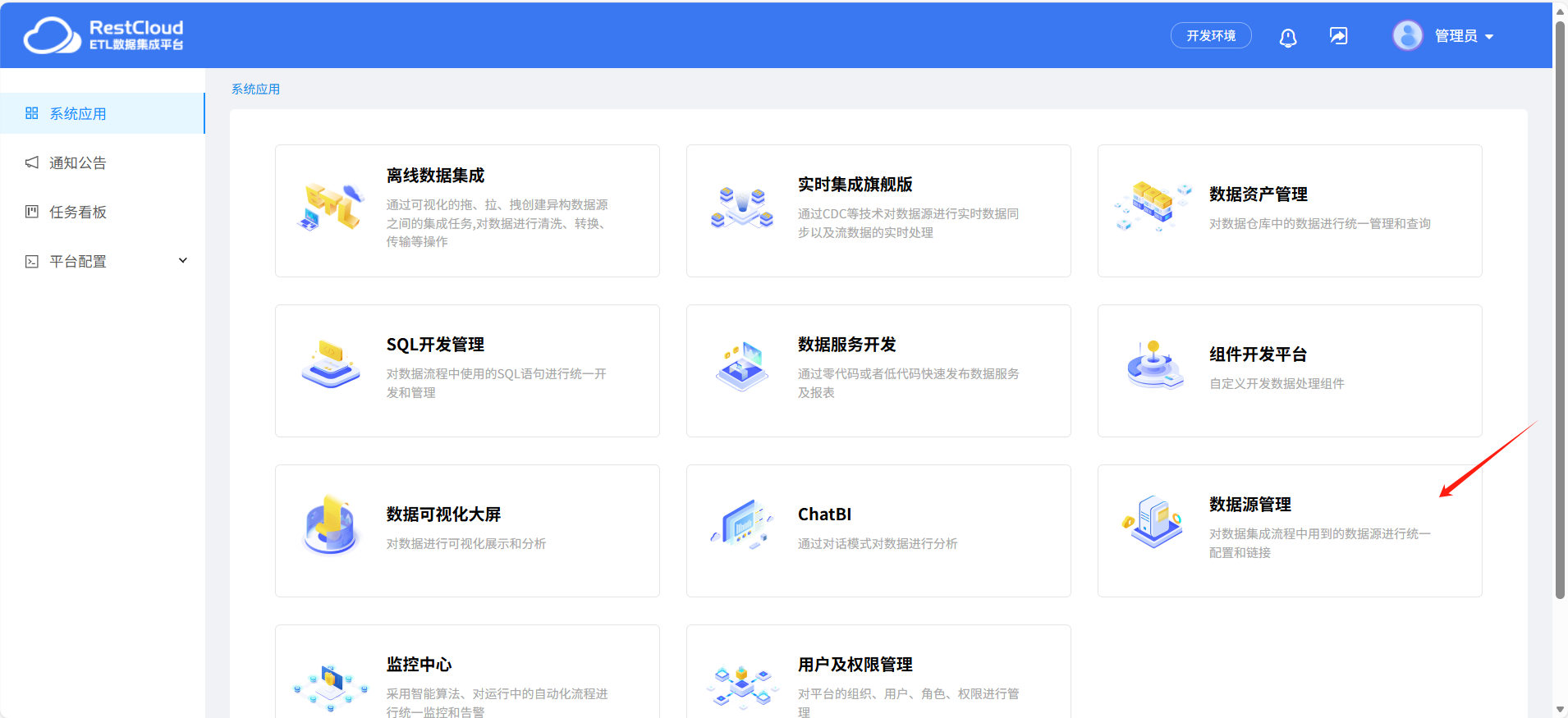
点击新建数据源并选择对应的数据源模板进行创建。
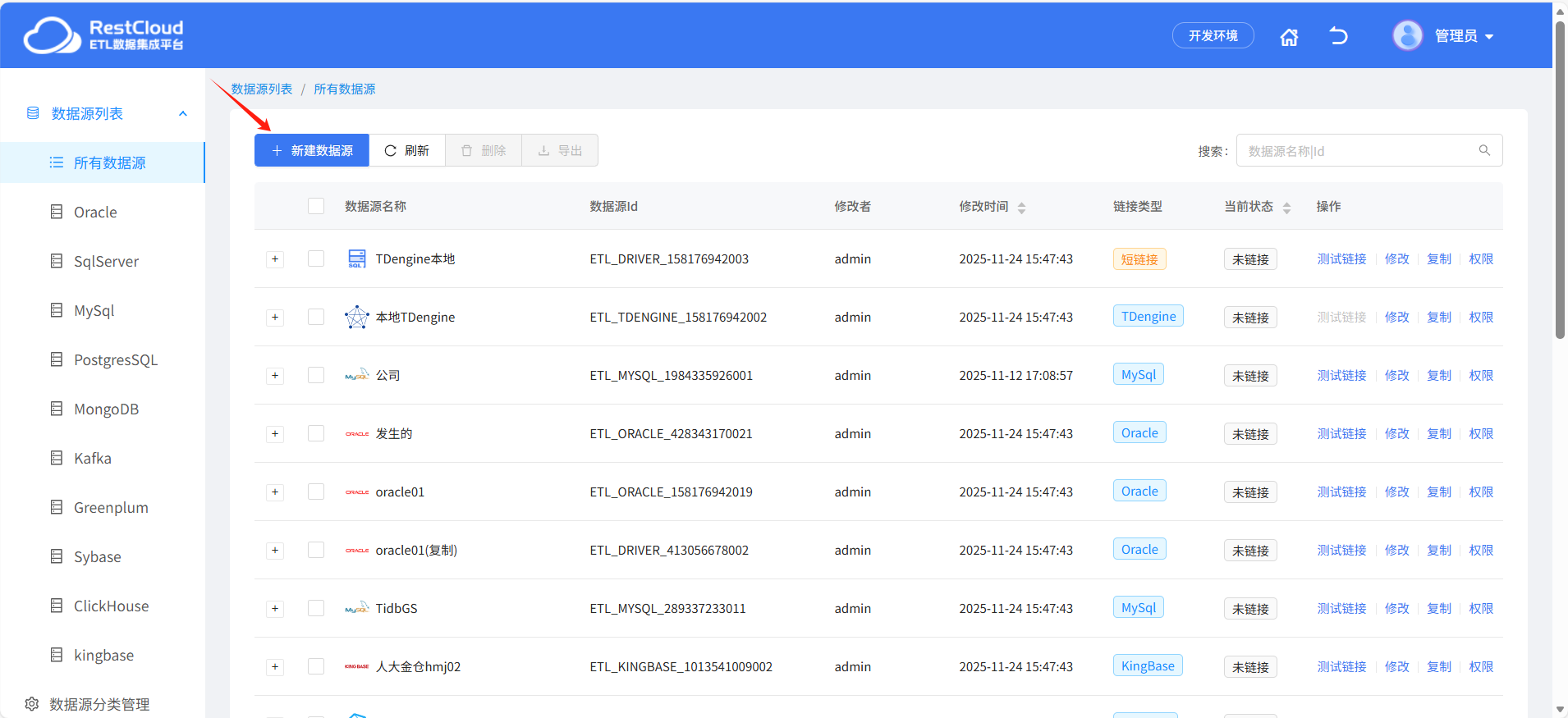
这里选择MySQL模板创建MySQL数据源

按照上面提示填写对应的配置,所属分类这里没有的可以在分类管理中进行创建。
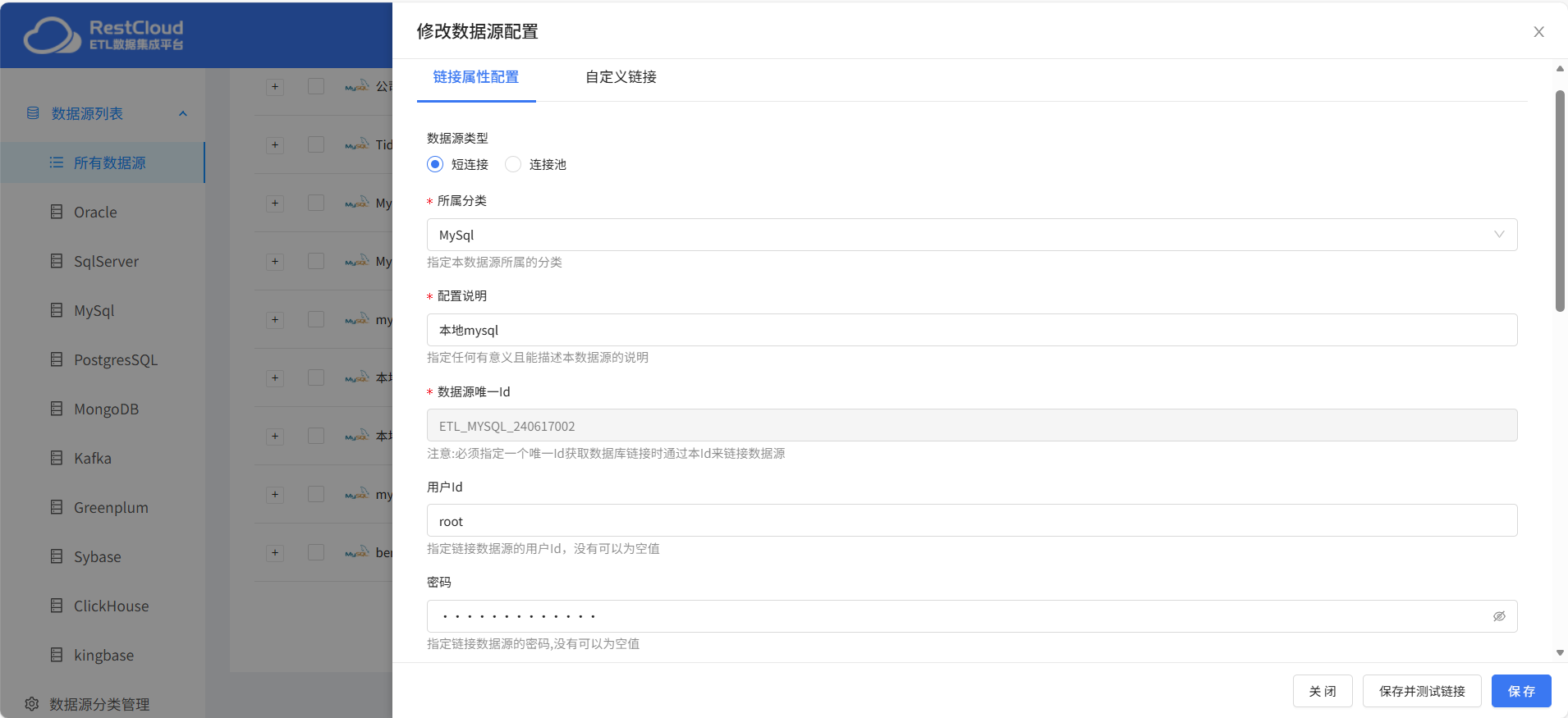
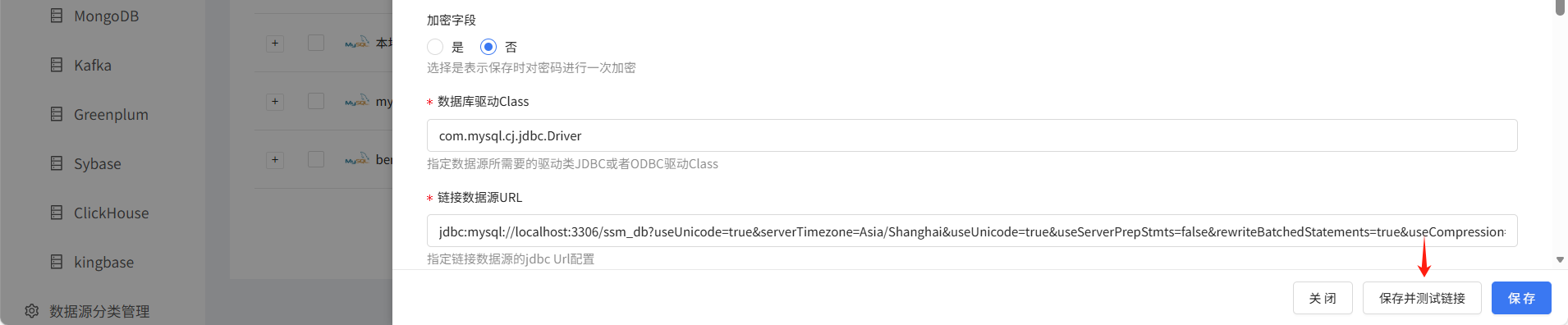
配置完成之后点击保存并测试,出现链接成功提示则数据源可以正常使用。
按照同样的步骤创建另一个MySQL数据源,这里一共创建了两个数据源

二、配置数据库质量检测
回到平台首页,进入离线数据集成模块
选择一个流程应用
进入流程应用之后,再左侧列表中点击数据质量,打开数据质量检测。
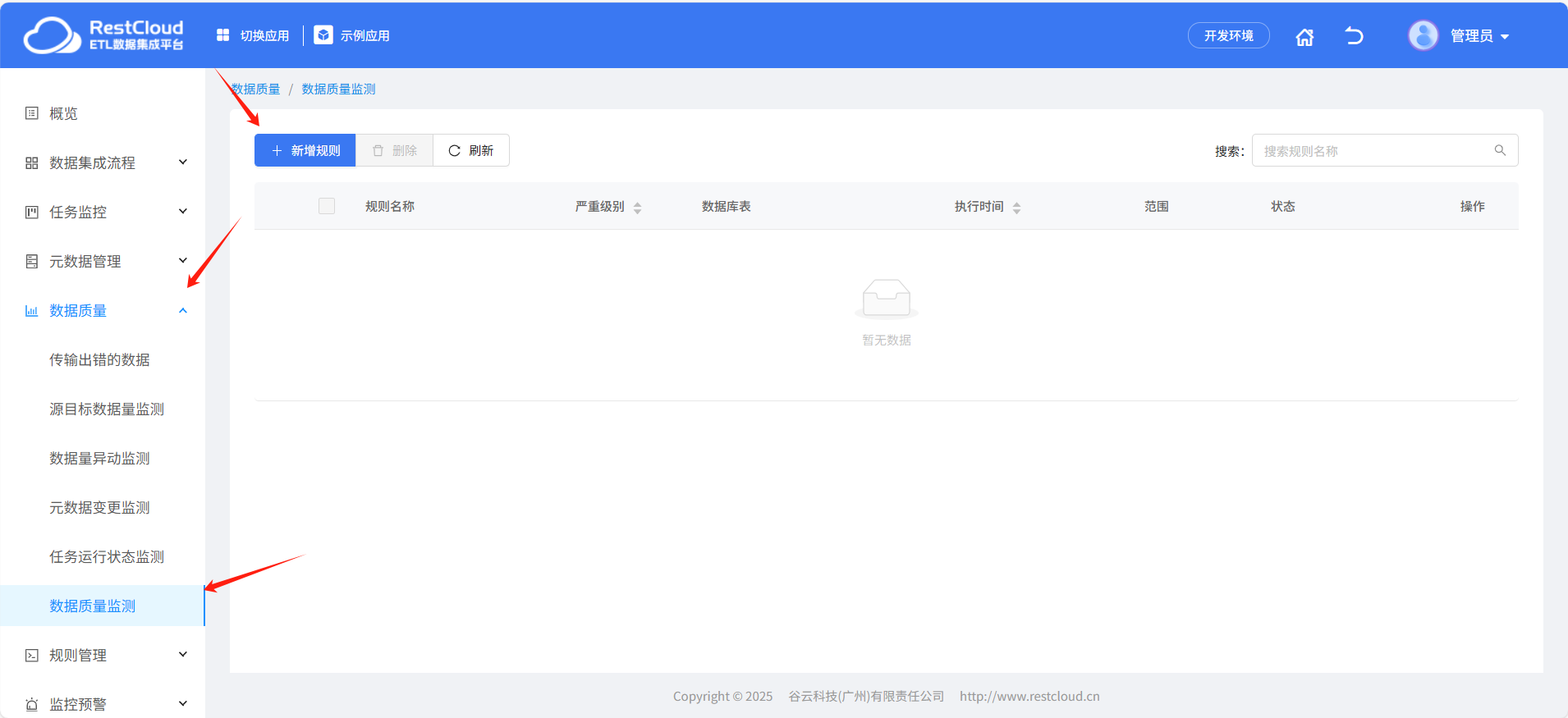
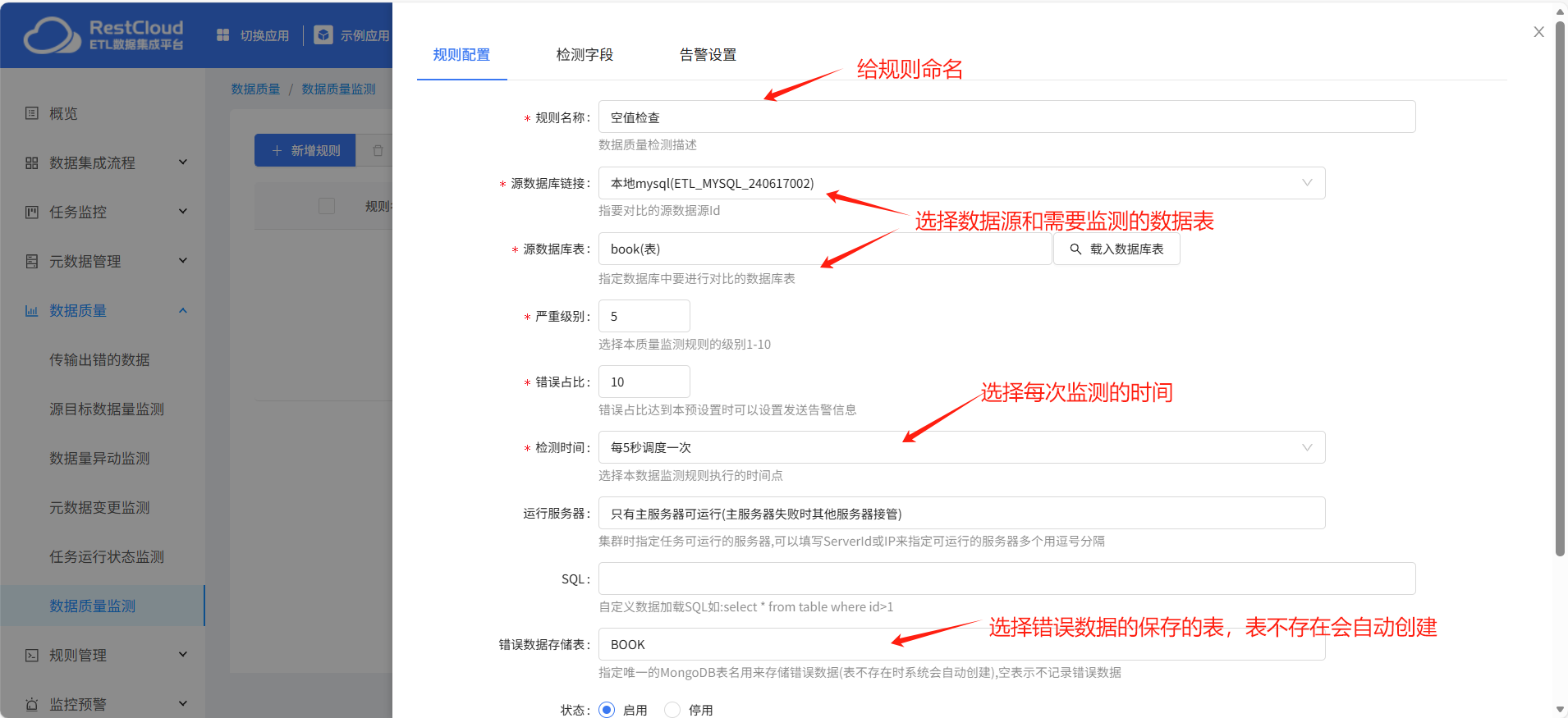
点击新建规则,填写对应配置
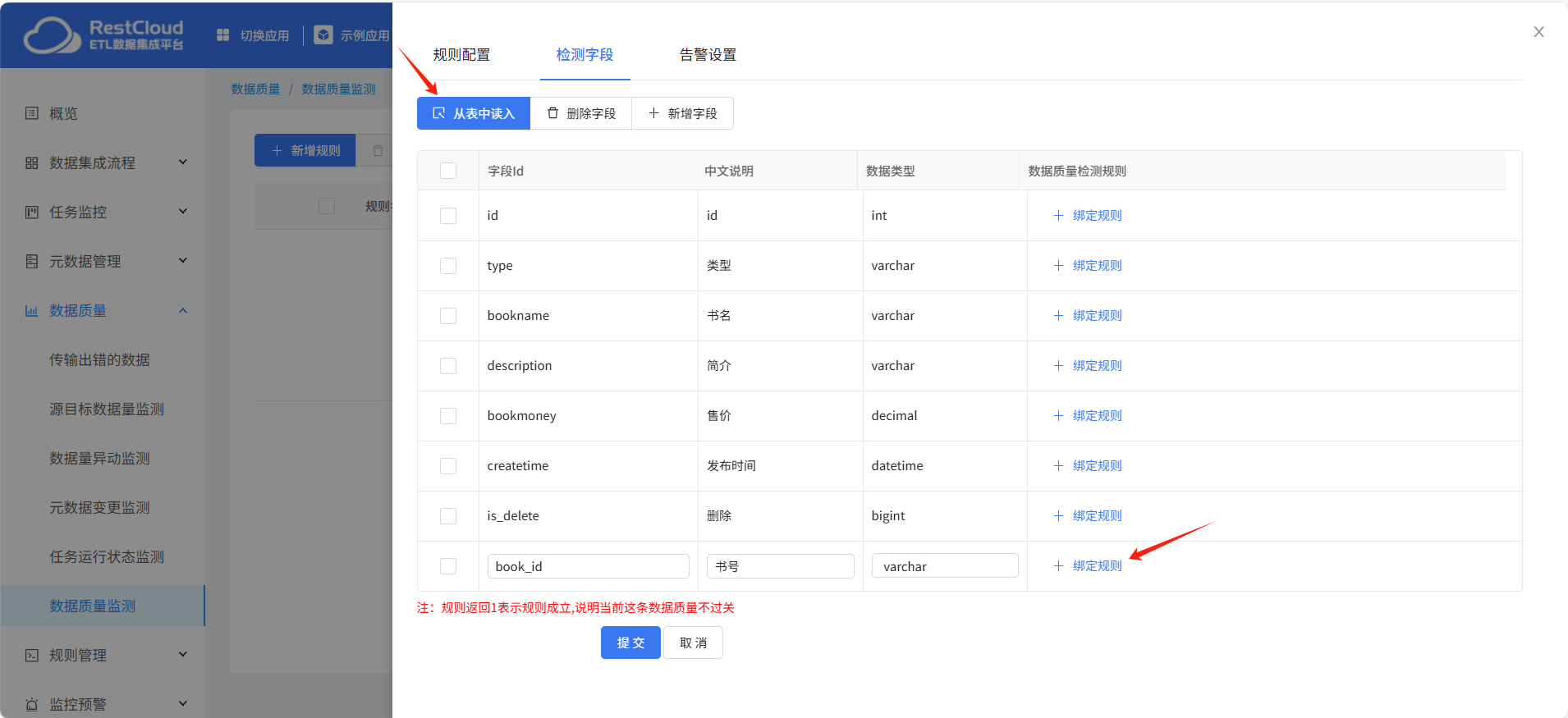
检查字段配置:
点击从表中读入,载入表字段信息,选择字段绑定数据质量规则。
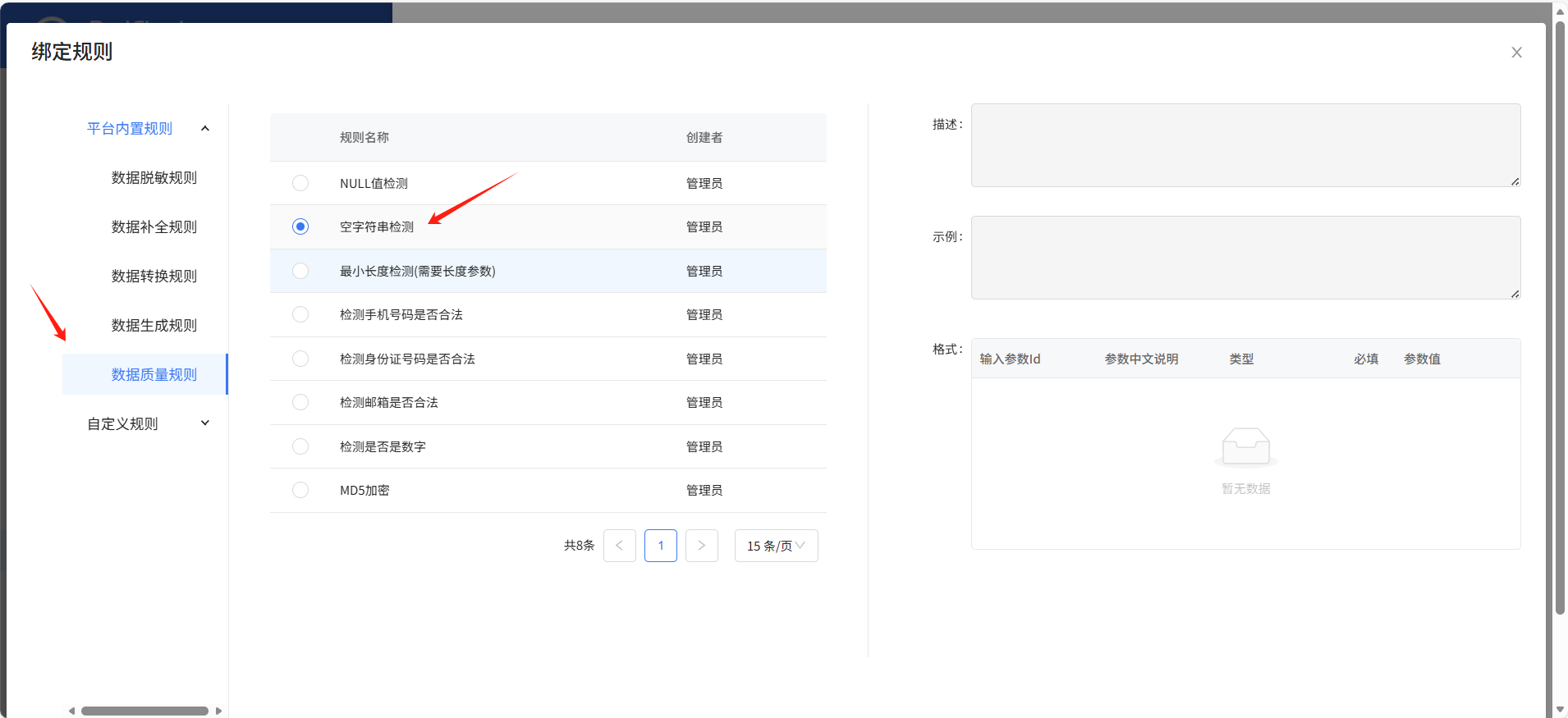
这里选择绑定空字符串检测
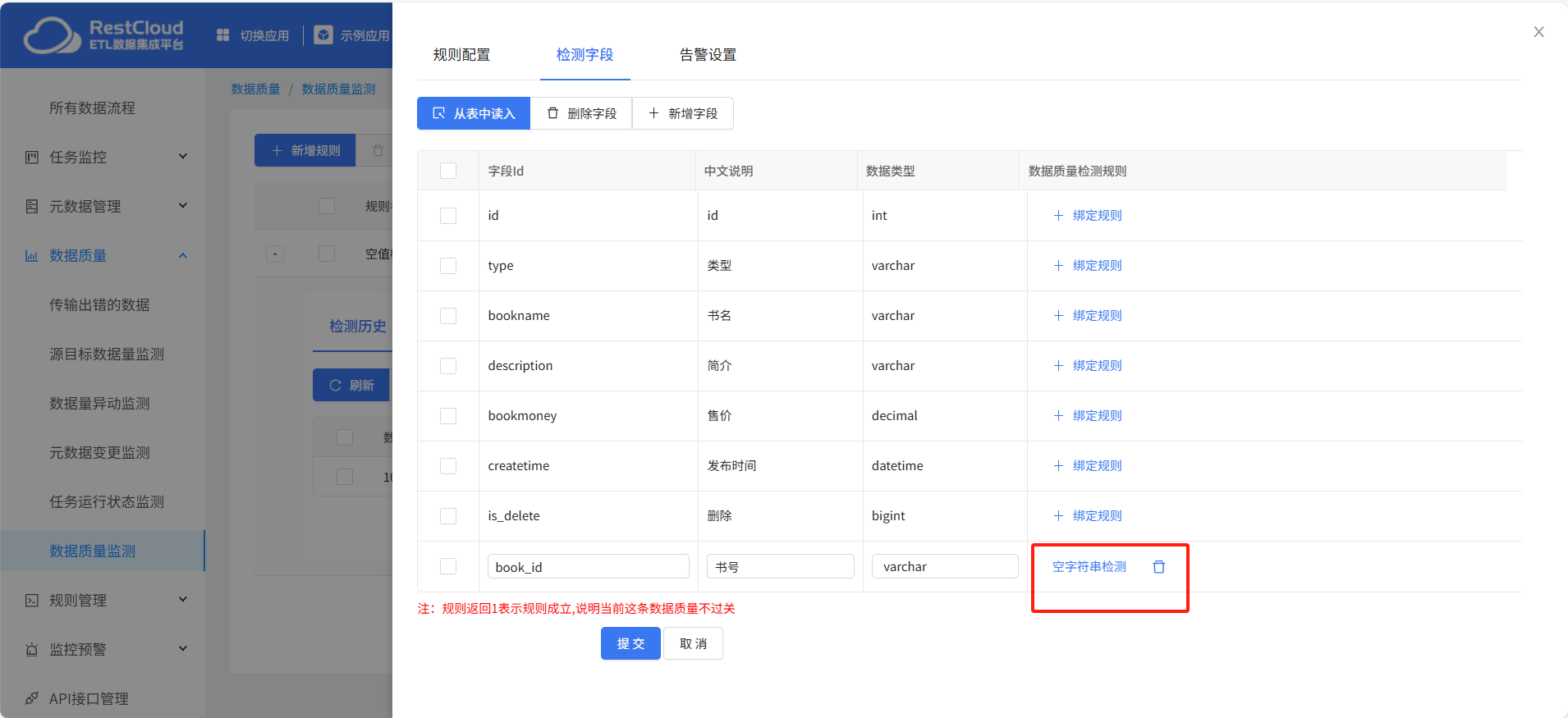
告警设置:
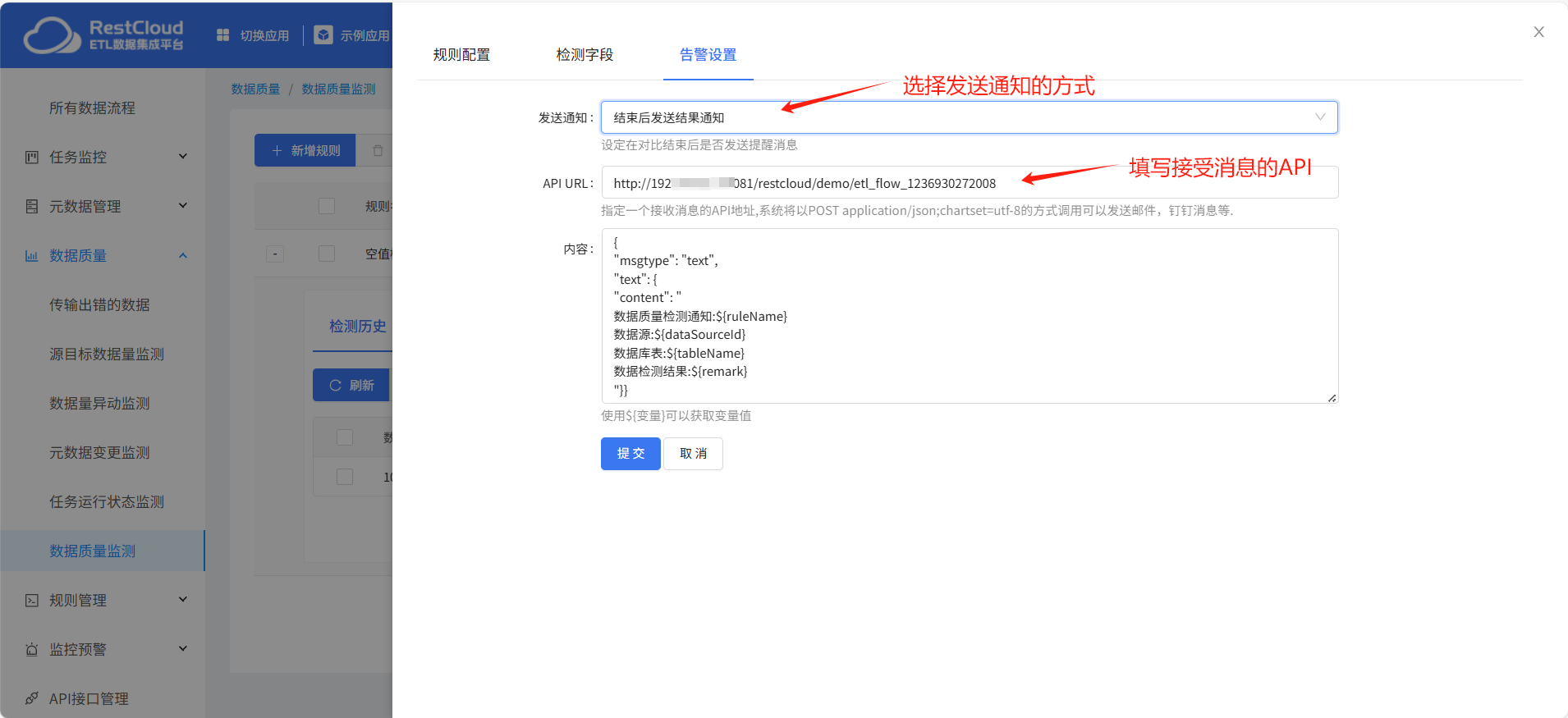
启动质量监测规则
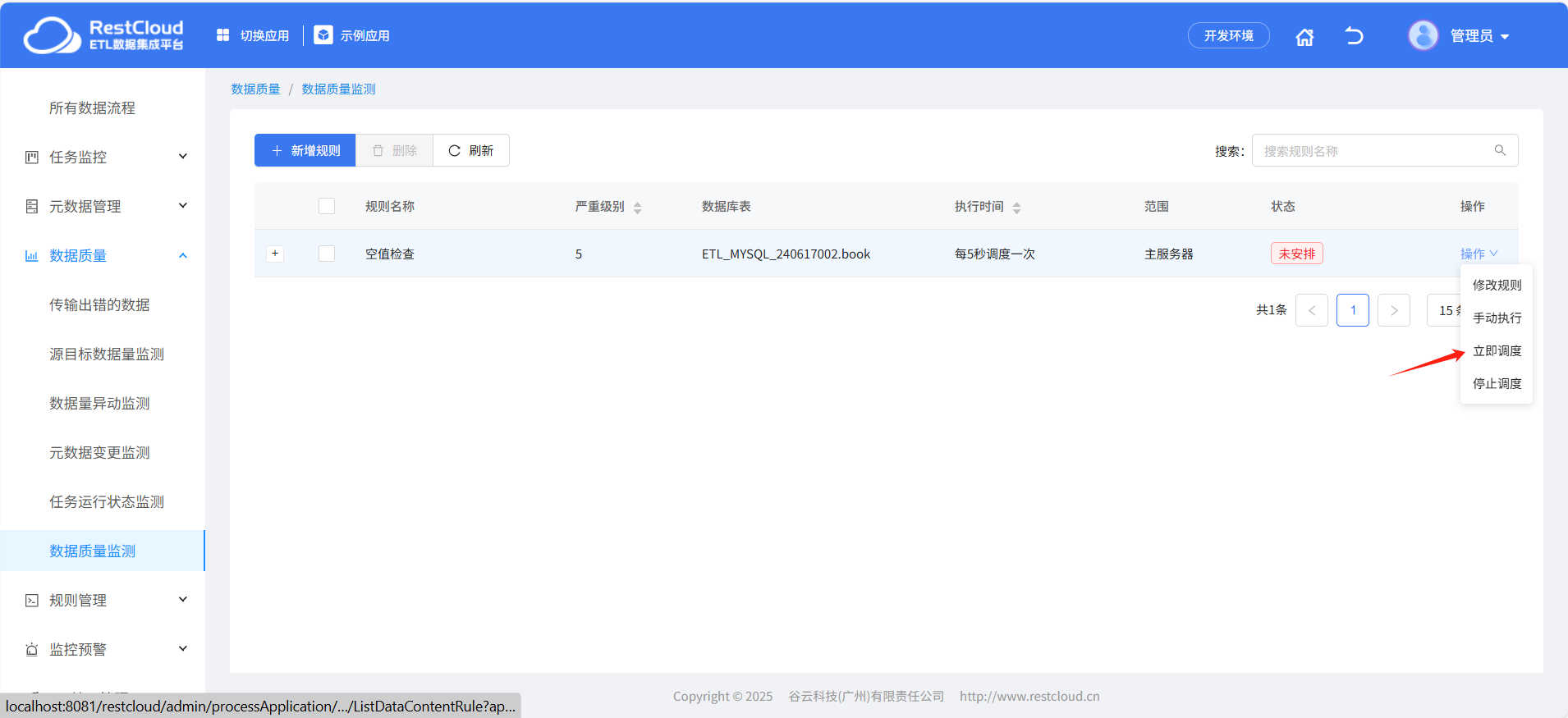
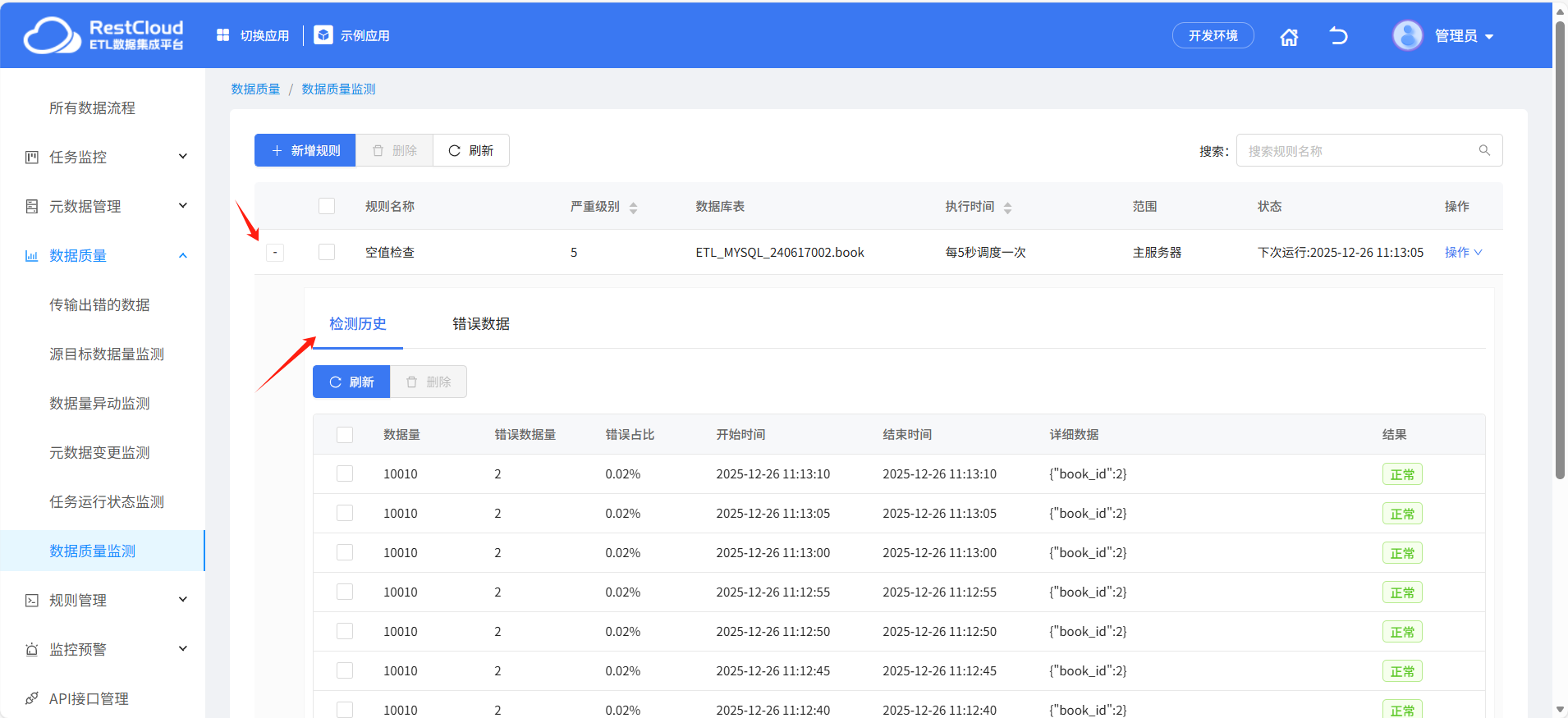
查看执行记录:
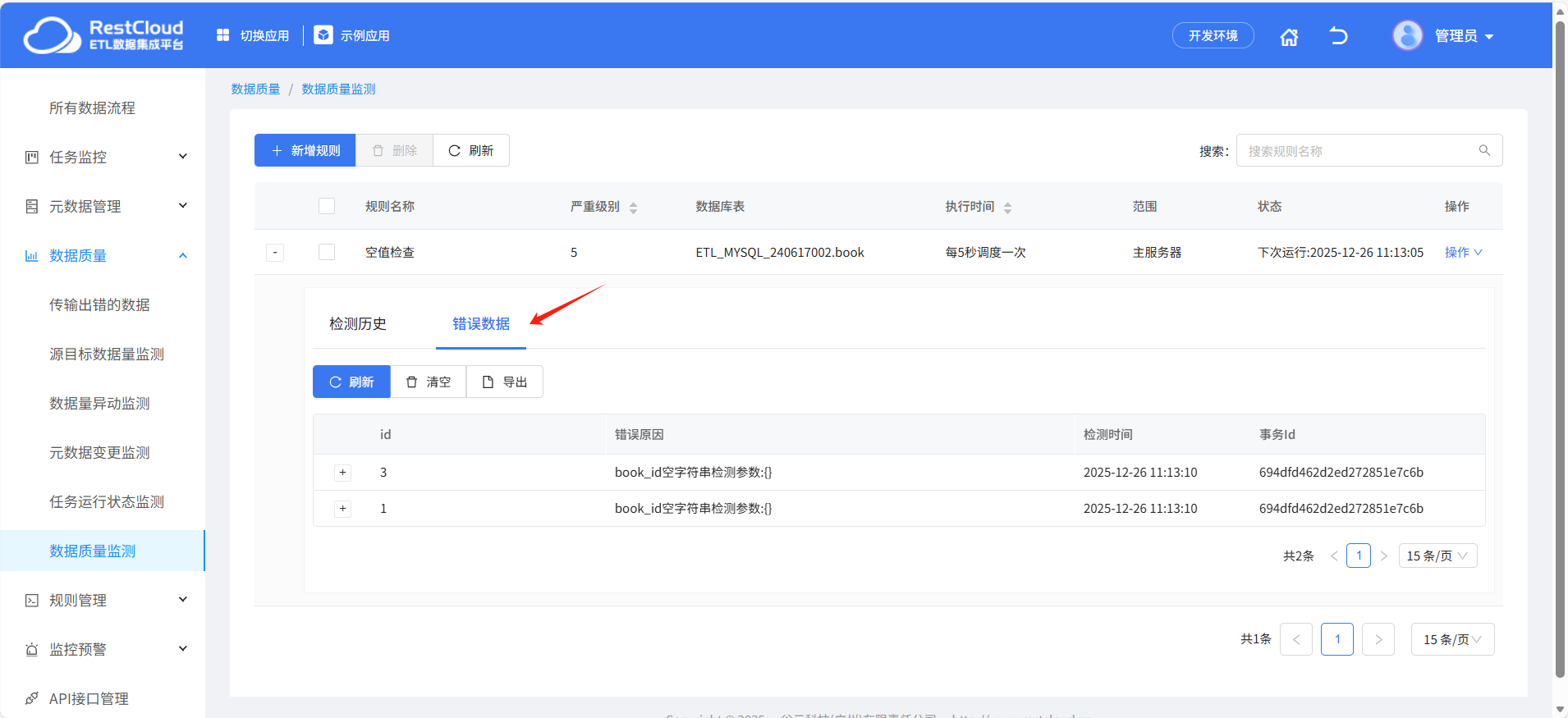
错误数据
监控消息:

三、总结
以上便是使用ETLCloud实现高效的数据质量评估与监控机制的具体过程,可以看到,我们使用ETLCloud工具链接数据库,每隔一段时间监测表的数据,对整张表的数据根据绑定的规则进行检测,然后配置具体的告警阈值,当错误数据占比达到阈值,将错误信息发送到流程。并且在流程将错误信息发送到接受消息的API中,实现高效的实时数据质量监控闭环。