AutoFlow: Automated Workflow Generation for Large Language Model Agents
AutoFlow:大型语言模型代理的自动化工作流生成

摘要
近年来,大语言模型(LLM)的进步在理解复杂自然语言方面取得了显著进展。LLM的一个重要应用是基于LLM的人工智能代理,它利用LLM的能力以及外部工具来解决复杂任务。为确保LLM代理遵循有效且可靠的流程解决给定任务,通常采用人工设计的工作流来指导代理的工作机制。然而,人工设计工作流需要大量精力和领域知识,使得大规模开发和部署代理变得困难。为解决这些问题,我们提出了AutoFlow,这是一个旨在为代理自动生成工作流以解决复杂任务的框架。AutoFlow以自然语言程序作为代理工作流的格式,并采用工作流优化程序迭代优化工作流质量。此外,本研究提供了两种工作流生成方法:基于微调的方法和基于上下文的方法,使AutoFlow框架适用于开源和闭源LLM。实验结果表明,我们的框架能够生成稳健且可靠的代理工作流。我们相信,自动生成和解释自然语言工作流是解决复杂任务的一种有前景的范式,尤其是在LLM快速发展的背景下。
1.引言
近年来,大型语言模型(LLMs)的最新进展在理解和处理复杂自然语言方面展现了显著进步。这些发展催生了广泛的应用,其中基于LLM的人工智能智能体尤为突出。这些智能体结合LLM的能力与外部工具,以处理从数据分析7、软件开发23, 35、科学研究2、旅行规划46到各领域众多决策过程等复杂任务。
确保基于LLM的AI智能体有效且可靠运行的关键方面之一是设计指导其任务解决流程的工作流。例如,用于虚假新闻检测的基于LLM的智能体可能按照以下由信息和传播专家24:1)检查URL,2)检查语言,3)常识评估,4)立场评估,5)总结发现,6)分类。代理逐步执行工作流程,每一步都可能调用LLM或外部工具来收集有用信息以进行最终的总结和分类。
传统上,这些工作流是手动构建的,需要大量精力和深厚的领域知识。这种手动过程对AI智能体的大规模开发和部署构成了重大障碍,因为它既耗时又耗费资源。
为了解决人工工作流设计面临的挑战,本文提出了AutoFlow,一种新颖的框架,旨在为AI代理自动生成工作流以解决复杂任务。AutoFlow以自然语言程序的形式表示工作流47,便于理解和交互。AutoFlow的核心是一个工作流优化过程,该过程迭代地改进生成的工作流的质量,确保其鲁棒性和可靠性。
从技术角度而言,AutoFlow引入了两种创新的工作流生成方法:基于微调的方法和基于上下文的方法。基于微调的方法通过调整大语言模型的参数,为特定任务和领域定制工作流生成过程。相比之下,基于上下文的方法利用语境信息来引导生成过程,无需进行大量微调,因此适用于开源和闭源大语言模型。更具体地说,如图1所示,用户将提供工作流生成查询来描述任务类型。基于该查询,生成器大语言模型生成工作流,而冻结的解释器大语言模型在数据集上执行生成的工作流,并将性能评估作为奖励。随后,AutoFlow使用强化学习根据该奖励更新生成器大语言模型。此过程可视为一次训练迭代,而生成器大语言模型在经过多次迭代后有望学习如何生成有效且最优的工作流。
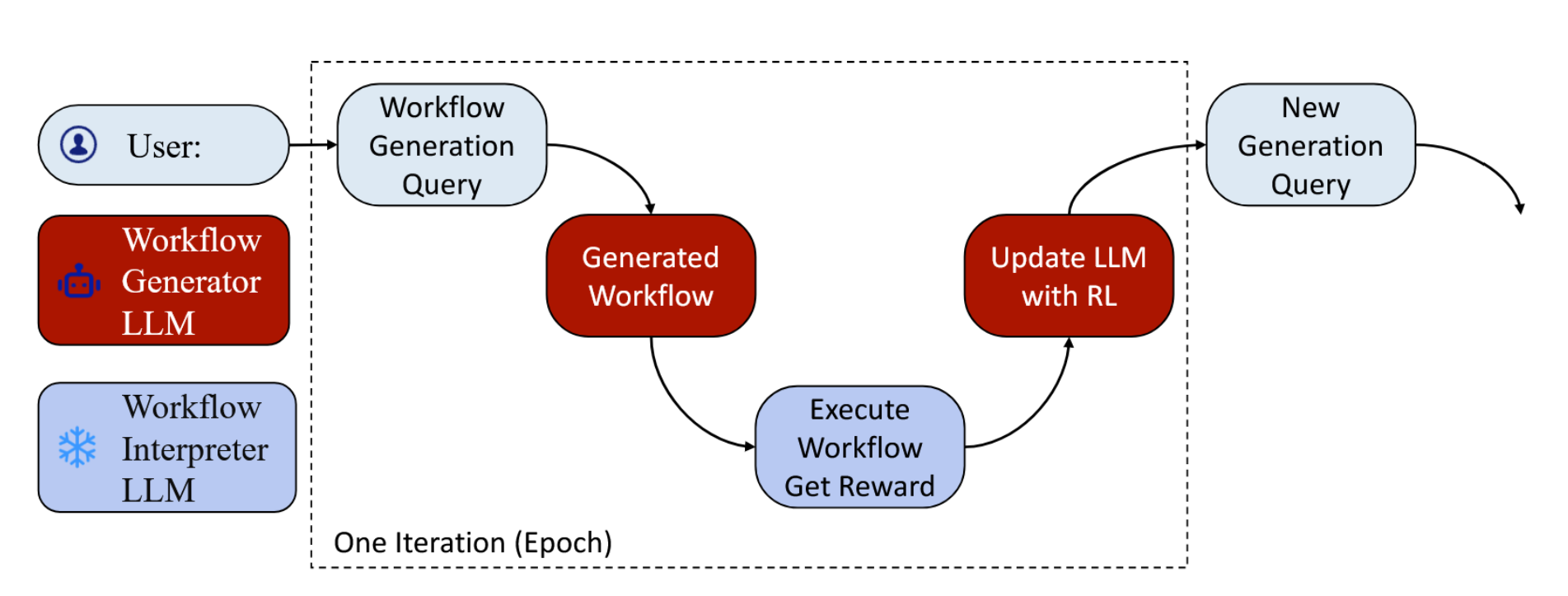
图1:利用强化学习奖励进行大语言模型(LLMs)的AutoFlow整体生成流程
我们的实验结果验证了AutoFlow框架的有效性,表明由AutoFlow生成的工作流在保持可读性的同时优于人工设计的工作流,并展示了其生成高质量工作流的能力,使人工智能代理能够以高可靠性执行复杂任务。以自然语言自动生成和解释工作流不仅简化了开发过程,而且代表了一种解决复杂问题的有前景的范式,尤其是在大语言模型技术快速演进的背景下。总之,本文做出了以下贡献:
• 我们介绍了AutoFlow,这是一个能够以自然语言自动生成工作流的框架,使得工作流可以被大语言模型精确解释,同时减少人工投入。
• 我们提出了两种方法,即微调方法和上下文学习方法,以将强化学习融入开源和闭源大语言模型的工作流生成过程。
• 我们通过基准任务进行实验以验证AutoFlow框架,在保持生成的天然语言工作流对人类可读的同时,提高了有效计划率和整体性能。
在下文部分,我们首先在第二节回顾相关工作。在第三节中,我们介绍如何用自然语言表示工作流及我们的动机。在第四节中,我们展示AutoFlow框架的详细设计,包括两种学习方法:微调方法和上下文学习方法。我们在第五节提供并分析了基准数据集上的实验结果,最后在第六节总结我们的工作并提出未来研究的潜在方向。
2.相关工作
2.1 LLM代理与工作流
AI agent(人工智能代理)是一种能够自主决策并在特定环境中执行操作,以有效处理各种复杂任务的实体30, 8, 38, 45。近年来,随着大型语言模型(LLMs)的快速发展,基于LLM的AI代理已成为解决复杂任务(如推理、规划与编码)的重要代理类型7, 23, 35。
推理:大语言模型通常将复杂任务分解为一系列步骤,构成推理链40。常用方法包括思维链及其衍生产物40, 21(如树结构49和图结构1)。自一致性方法39通过对多条推理路径进行采样,并通过投票选取最一致的结果。
规划:规划任务要求大型语言模型生成一系列动作以实现特定目标9。近期研究设计了测试平台,用于评估大型语言模型在专家模型集成7、旅行任务规划46和工具使用52等领域的规划能力。然而,一个已知问题是大型语言模型可能生成不可执行、无效或语法错误的方案,例如将文本片段作为图像处理工具的输入。为解决这一问题,部分研究7, 52采用后处理方法从生成的文本中提取工具链,即利用大型语言模型本身作为解析器对生成文本进行后处理。此外,近期尝试将有限状态机集成到大型语言模型中,以增强人类对大型语言模型规划过程的可控性25, 44。ReAct方法50还通过引入搜索引擎等外部工具来改进大型语言模型的规划能力。本研究基于上述思路,旨在提升生成框架的可执行性。
编码:大语言模型可以生成代码以解决复杂任务,从而减少手动编程的需求29, 47, 15, 27, 5, 34, 31, 3。然而,生成的代码可能包含错误或无法满足用户需求。为缓解这些问题,基于工作流的方法被提出,包括手动设计和自动生成的工作流16, 43, 53。另一个研究方向是利用大语言模型进行自然语言编程,发挥其强大的自然语言理解能力。一个显著的例子是CoRE语言47,它将自然语言编程、伪代码编程和工作流编程统一在同一框架下,以大语言模型作为解释器。我们的工作遵循自然语言编程中的工作流概念,并开发了一个自动化工作流生成框架以减少人力劳动。
2.2 自动化机器学习
自动化机器学习(AutoML)旨在减少设计和部署机器学习技术中的人力劳动,简化机器学习在现实问题中的应用。AutoML技术主要有三种类型48, 26:
自动模型选择:诸如Auto-sklearn 6和Auto-WEKA 22等工具能够从模型库和超参数设置中自动选择最佳机器学习模型。
自动特征工程:由于特征工程在许多应用中对模型性能有显著影响,Data Science Machine 17、ExploreKit 18和VEST 4等工具无需人工干预即可生成或选择有用特征。
神经架构搜索(NAS):ENAS 33、DARTS 28、NASH 37、GNAS 12和AmoebaNet-A 36等方法能够针对特定任务自动发现有效的神经网络架构,无需人工设计。实验表明,通过NAS生成的网络在各种任务中可以媲美甚至超越人工设计的架构。
AutoML系统通常包含两个训练核心组件:控制器(一个负责采样模型选择的机器学习模型)和子模型(包含待创建并用于当前任务的机器学习模型参数)。在本工作中,我们遵循这一训练范式,以工作流生成大语言模型作为控制器,以生成的工作流及工作流解释大语言模型作为子模型。所提出技术的更多细节将在第4节中介绍。
3.初步与背景
3.1 自然语言程序作为工作流
在本节中,我们介绍如何将自然语言程序用作工作流的表示。具体而言,我们将以代码表示与执行(CoRE)系统47为例,展示如何将工作流构建为自然语言程序,以及LLM智能体如何通过执行自然语言程序来遵循工作流。
3.1.1 CoRE 语言语法
CoRE语言定义了四个组件,用于将工作流组织为自然语言指令。
• 步骤名称(Step Name)用于唯一标识工作流的每个步骤。
• 步骤类型(Step Type)定义了每个步骤的指令类型。共有三种不同类型的步骤:
-- 处理(Process):处理步骤在执行当前步骤后,转换到下一个指定的步骤。
-- 决策(Decision):类似于条件语句(例如"if-else"),决策步骤用于根据评估的条件分支程序流程。
-- 终止(Terminal):终止步骤表示程序的结束。
• 步骤指令(Step Instruction)是将在该步骤中执行的自然语言指令。
• 步骤连接(Step Connection)指向下一个步骤,从而建立程序执行流程。
以下是在OpenAGI基准测试中用于图像-文本处理的一个示例工作流:
步骤1::: 过程::: 根据目标确定输入数据类型。:::next::步骤2
步骤2::: 过程::: 根据目标确定输出数据类型。:::next::步骤3
步骤3::: 过程::: 从提供的工具列表中选择工具以生成计划。:::next::步骤4
步骤4::: 决策::: 检查计划中的每个工具是否都在提供的工具列表中。:::是::步骤5:::否::步骤3
步骤5::: 决策::: 检查前一个工具的输出数据类型是否为后一个工具的输入数据类型。:::是::步骤6:::否::步骤3
步骤6::: 终点::: 通过列出工具名称输出计划。在本论文中,我们使用':::'来区分每一步中的上述四个组成部分。
3.1.2 大语言模型作为工作流执行的解释器
为了处理和执行CoRE语言中的工作流,系统使用大型语言模型(LLM)作为解释器。LLM解释器逐步执行指令。具体而言,在CoRE系统中,一个步骤的执行可分为四个过程。❶ 首先,LLM决定执行当前步骤可能需要从记忆中获取哪些信息,并从记忆中检索相关信息。❷ 获取相关信息后,系统将这些信息与该步骤的指令整合为一个结构化提示,LLM处理该提示以生成响应。❸ 为扩展LLM的能力,系统可能使用外部工具分析每个步骤的初始响应。根据当前步骤的初始响应,LLM决定是否需要外部工具。若确认使用工具,LLM将决定工具名称和工具参数,然后执行外部工具,最后将结果整合到记忆中。❹ 当前步骤执行完毕后,LLM将根据当前步骤的输出决定下一步要执行的步骤。
3.2 动机
CoRE系统使用户能够以自然语言编写工作流,从而统一了自然语言编程、伪代码编程和工作流编程。尽管其入门门槛低于编程语言,但用自然语言构建工作流仍需要大量人力和领域专业知识。受自动化机器学习(AutoML)13的启发,我们希望基于给定任务和训练数据自动学习最佳工作流。考虑到CoRE语言中的指令以自然语言编写,且大语言模型(LLM)具有较强的自然语言理解能力,我们也使用LLM作为工作流生成器。为了与3.1节中提到的解释器LLM区分,我们将学习生成工作流的LLM称为工作流生成器LLM,并将解释和执行工作流的LLM称为工作流解释器LLM,与图1一致。这样,用户只需提供任务的高级描述和相应的数据集,生成器LLM即可生成CoRE语言中的最优工作流,供解释器LLM在给定任务上执行。此过程旨在最小化人力投入,并自动为LLM追求最优工作流,无论用户对工作流设计的知识水平如何。
4.AutoFlow框架
在本节中,我们介绍了将AutoFlow框架应用于工作流生成器LLM的两种方法,即针对开源LLM的微调方法和针对闭源LLM的上下文学习方法。
4.1 使用开源大语言模型的工作流生成微调方法
我们使用LoRA适配器11对开源大型语言模型进行微调,作为工作流生成器。训练过程如图2a所示。
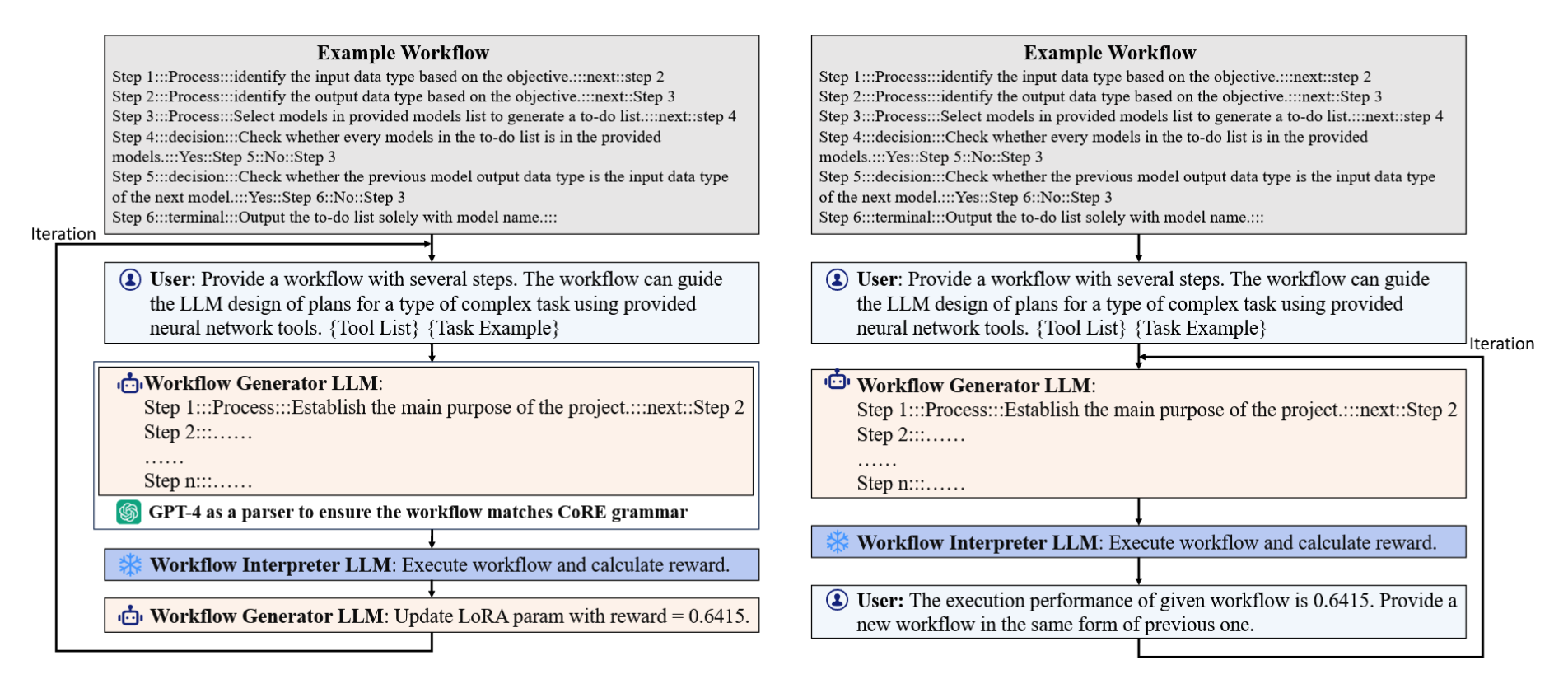
(a) 用于开源大语言模型的基于强化学习奖励微调方法的AutoFlow生成过程。
(b) 基于上下文学习与RL奖励的闭源大语言模型AutoFlow生成过程
图2:使用AutoFlow生成工作流的概览,以OpenAGI 7任务为例
首先,工作流生成器LLM接收用户提供的少量示例工作流和任务描述作为输入查询。尽管CoRE语言的语法要求极简,且指令以自然语言编写,能够被LLM很好地学习和生成,但示例工作流有助于工作流生成器LLM更深入地理解CoRE语言的语法。任务的自然语言描述旨在帮助生成器LLM理解待生成工作流的应用场景。以OpenAGI基准测试7中的文本与图像处理任务为例,任务描述可以是:"提供一个包含多个步骤的工作流。该工作流可引导LLM利用提供的工具,为涉及文本与图像处理的复杂任务设计方案"。
其次,下一步是根据输入查询生成可执行的工作流。对于闭源大语言模型(如GPT-4),在给出少样本示例的情况下,该模型可以直接生成语法有效的工作流。然而,开源大语言模型(如Mixtral-8x7B)即使提供了少样本示例工作流,也无法持续生成语法有效的工作流。为解决该问题,我们遵循先前工作7, 52中的后处理策略,使用GPT-4作为解析器将输出的工作流修正为语法有效的形式。
第三,生成的工作流将由解释器大语言模型执行,以获取其在验证数据集上的性能。随后,基于工作流在验证数据集上的表现更新生成器大语言模型。具体而言,我们采用强化学习(RL)更新生成器大语言模型的LoRA适配器参数,并将验证数据集上所有数据实例的平均指标作为奖励。
这三个步骤共同构成微调过程的一次迭代。当满足终止条件时,即连续两次迭代之间的奖励差异小于一个阈值,微调过程将终止,并生成最终的工作流。经过迭代优化过程后,工作流生成器大语言模型基于执行反馈为任务生成最优工作流。
4.2 面向闭源大语言模型的工作流生成的上下文学习方法
针对GPT-4等闭源大语言模型,我们采用上下文学习以避免微调参数。如图2b所示,AutoFlow框架还需要一个示例工作流和任务描述,并将它们作为输入查询提供给工作流生成器大语言模型。GPT-4生成工作流后,我们不使用解析器来修正流程,因为GPT-4能够很好地遵循示例工作流所展示的CoRE语法。随后,解释器大语言模型执行该工作流,并在验证数据集上评估其性能作为奖励,这与微调方法的过程相同。不同之处在于,下一步中,AutoFlow框架直接将奖励值包含在查询中,并提示生成器大语言模型根据先前生成的工作流的性能来生成新的工作流,例如"先前工作流的执行性能为0.6415。请提供一个能够获得更好性能的新工作流"。整个过程如图2b所示。我们将在实验中证明,GPT-4等闭源大语言模型能够有效利用提示中的奖励值来优化工作流,并最终通过上下文学习方法获得最优工作流。
5.实验
5.1 骨干大型语言模型 (LLM)
我们在闭源和开源大语言模型(LLM)上进行了实验:
• GPT-4 32(闭源)是OpenAI的生成式预训练Transformer。本研究中使用的是GPT-4-1106-preview版本。
• Mixtral-8x7B 14(开源)是一个预训练的生成式稀疏混合专家模型,参数量为467亿。
在我们的实验中,我们将这两类LLM分别用作工作流生成器LLM和解释器LLM,因此总共产生了四种组合。
5.2 大语言模型的规划模式
我们采用以下基于LLM的智能体规划方案:
• 零样本学习(Zero)直接将查询输入LLM。
• 思维链(CoT)40引导LLM生成连贯的语言序列,作为连接输入查询与输出答案的有意义中间步骤。
• 少样本学习(Few)在提示中提供一组高质量示例,每个示例包含目标任务上的输入和期望输出。
• CoRE 47使用手动设计的工作流,并将LLM作为解释器。
• AutoFlow是我们提出的框架,能够自动生成工作流。
5.3 基准数据集
我们在基准数据集OpenAGI 7上进行实验。OpenAGI基准任务根据其输出类型和真实标签类型(任务1、2和3)进行分类。然后,基于针对不同的任务类型,采用不同的指标来评估性能:CLIP Score 10 用于评估文本与图像之间的相似度,应用于文本到图像任务(任务1);BERT Score 54 利用BERT评估文本生成质量,应用于数据标签和预期输出均为文本的任务(任务2);ViT Score 42 用于评估图像标签与图像输出之间的相似度(任务3)。
5.4 实现细节
我们的框架及所有基线均基于开源库PyTorch实现。我们遵循OpenAGI平台7在零样本和少样本学习中的实现设置。利用DSPy框架19, 20将思维链(CoT)策略应用于OpenAGI平台。我们还在OpenAGI平台上尝试了思维程序(Program-of-Thought)5和ReAct51策略。然而,ReAct策略需要文本观测,这不适用于我们的OpenAGI任务,因为部分观测为图像格式,而思维程序无法生成可执行代码。因此,我们未将其纳入基线。在AutoFlow框架的超参数设置中,我们将工作流生成器大语言模型(LLM)的迭代次数设为30。对于作为生成器LLM的开源模型Mixtral,我们采用REINFORCE41作为核心强化学习(RL)算法,并以训练数据集上的平均得分作为奖励。RL优化器使用Adam,学习率设为0.001。此外,我们对Mixtral应用了秩为8的低秩自适应(LoRA)11,以实现高效微调。
5.5 实验分析
我们在OpenAGI 7基准数据集上进行了实验。为确保公平比较,我们使用相同的工作流解释器LLM将结果以表格形式呈现。具体而言,使用开源LLM Mixtral作为LLM解释器的结果如表1所示;使用闭源LLM GPT-4作为LLM解释器的结果如表2所示。每一行代表一类任务,每一列代表一个LLM解释器的规划方案。从这两个表格可以看出,应用我们的AutoFlow框架后,任务平均得分显著优于基线方法。与最佳基线方法CoRE相比,当使用Mixtral作为LLM解释器时,AutoFlow提升了超过40%;当使用GPT-4作为解释器LLM时,提升了超过5%。对于每类任务的得分,我们的AutoFlow也达到了最高值。因此,实验结果验证了AutoFlow的有效性,且能够生成性能优于人工设计的工作流。

表1:使用开源LLM Mixtral作为所有任务和学习模式的LLM解释器时在OpenAGI上的表现。Zero代表零样本学习,Few代表少样本学习。粗体数字表示在相同LLM下每个任务类型的最高得分。

表2:在以闭源大语言模型GPT-4作为所有任务与学习方案的LLM解释器时,OpenAGI的性能表现。其中Zero指零样本学习,Few指少样本学习。加粗数字表示在相同LLM下各任务类型中的最高得分。
一个有趣的观察是,当使用Mixtral作为LLM解释器时,最佳平均分数由使用GPT-4作为工作流生成器的AutoFlow取得;而当使用GPT-4作为LLM解释器时,最佳平均分数则由使用Mixtral作为工作流生成器的AutoFlow取得。这一观察表明,将不同系统(Mixtral与GPT-4)分别用于LLM解释器和工作流生成器,可能会产生某种协同效应,即一个系统的优势弥补了另一个系统的不足,从而有助于更好地解决复杂的多步骤任务。
6 结论与未来工作
在本研究中,我们提出了AutoFlow框架,利用大型语言模型自动生成代理的有效工作流。我们为AutoFlow设计了两种学习方法:当使用开源LLM作为工作流生成器时的微调方法,以及当使用闭源LLM作为工作流生成器时的上下文学习方法。与人工设计的工作流相比,自动生成的工作流能够实现更优的性能,并显著减少人工劳动,从而提高自动化程度。尽管AutoFlow展示了令人鼓舞的结果,但仍存在改进空间。例如,工作流生成LLM的学习过程采用强化学习,与基于梯度的方法或少样本学习方法相比可能并非最高效。未来研究可尝试评估其他学习方法的有效性。再如,在AutoFlow框架中,工作流生成器与解释器LLM通过协作学习范式协同工作。相反,我们也可以尝试其他学习范式,如师生范式或对抗学习范式。
引用文献
- 1 Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17682--17690.
- 2 Daniil A. Boiko, Robert MacKnight, and Gabe Gomes. 2023. Emergent autonomous scientific research capabilities of large language models. arXiv:2304.05332 physics.chem-ph
- 3 Yuzhe Cai, Shaoguang Mao, Wenshan Wu, Zehua Wang, Yaobo Liang, Tao Ge, Chenfei Wu, Wang You, Ting Song, Yan Xia, Jonathan Tien, Nan Duan, and Furu Wei. 2024. Low-code LLM: Graphical User Interface over Large Language Models. arXiv:2304.08103 cs.CL
- 4 Vitor Cerqueira, Nuno Moniz, and Carlos Soares. 2021. Vest: Automatic feature engineering for forecasting. Machine Learning (2021), 1--23.
- 5 Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. Transactions on Machine Learning Research (2023).
- 6 Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. 2015. Efficient and Robust Automated Machine Learning. In Advances in Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett (Eds.), Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2015/ file/11d0e6287202fced83f79975ec59a3a6-Paper.pdf
- 7 Yingqiang Ge, Wenyue Hua, Kai Mei, Jianchao Ji, Juntao Tan, Shuyuan Xu, Zelong Li, and Yongfeng Zhang. 2023. OpenAGI: When LLM Meets Domain Experts. In Advances in Neural Information Processing Systems (NeurIPS) (2023).
- 8 Yingqiang Ge, Yujie Ren, Wenyue Hua, Shuyuan Xu, Juntao Tan, and Yongfeng Zhang. 2023. LLM as OS, Agents as Apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem. arXiv e-prints (2023), arXiv--2312.
- 9 Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992 (2023).
- 10 Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. CLIPScore: A Reference-free Evaluation Metric for Image Captioning.
- 11 Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 cs.CL
- 12 Siyu Huang, Xi Li, Zhi-Qi Cheng, Zhongfei Zhang, and Alexander Hauptmann. 2018. Gnas: A greedy neural architecture search method for multi-attribute learning. In Proceedings of the 26th ACM international conference on Multimedia. 2049--2057.
- 13 Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren. 2019. Automated machine learning: methods, systems, challenges. Springer Nature.
- 14 Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. 2024. Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024).
- 15 Ana Jojic, Zhen Wang, and Nebojsa Jojic. 2023. Gpt is becoming a turing machine: Here are some ways to program it. arXiv preprint arXiv:2303.14310 (2023).
- 16 Martin Josifoski, Lars Klein, Maxime Peyrard, Yifei Li, Saibo Geng, Julian Paul Schnitzler, Yuxing Yao, Jiheng Wei, Debjit Paul, and Robert West. 2023. Flows: Building Blocks of Reasoning and Collaborating AI. arXiv:2308.01285 cs.AI
- 17 James Max Kanter and Kalyan Veeramachaneni. 2015. Deep feature synthesis: Towards automating data science endeavors. In 2015 IEEE international conference on data science and advanced analytics (DSAA). IEEE, 1--10.
- 18 Gilad Katz, Eui Chul Richard Shin, and Dawn Song. 2016. Explorekit: Automatic feature generation and selection. In 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 979--984.
- 19 Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive NLP. arXiv preprint arXiv:2212.14024 (2022).
- 20 Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv preprint arXiv:2310.03714 (2023).
- 21 Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35 (2022), 22199--22213.
- 22 Lars Kotthoff, Chris Thornton, Holger H Hoos, Frank Hutter, and Kevin Leyton-Brown. 2019. Auto-WEKA: Automatic model selection and hyperparameter optimization in WEKA. In Automated Machine Learning. Springer, Cham, 81--95.
- 23 Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society. In Thirty-seventh Conference on Neural Information Processing Systems.
- 24 Xinyi Li, Yongfeng Zhang, and Edward C Malthouse. 2024. Large Language Model Agent for Fake News Detection. arXiv preprint arXiv:2405.01593 (2024).
- 25 Zelong Li, Wenyue Hua, Hao Wang, He Zhu, and Yongfeng Zhang. 2024. Formal-LLM: Integrating Formal Language and Natural Language for Controllable LLM-based Agents. arXiv:2402.00798 (2024).
- 26 Zelong Li, Jianchao Ji, Yingqiang Ge, and Yongfeng Zhang. 2022. AutoLossGen: Automatic Loss Function Generation for Recommender Systems. SIGIR (2022).
- 27 Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. 2023. Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477 (2023).
- 28 Hanxiao Liu, Karen Simonyan, and Yiming Yang. 2019. DARTS: Differentiable Architecture Search. In International Conference on Learning Representations. https://openreview. net/forum?id=S1eYHoC5FX
- 29 Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. Faithful chain-of-thought reasoning. arXiv preprint arXiv:2301.13379 (2023).
- 30 Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. 2024. AIOS: LLM Agent Operating System. arXiv (2024).
- 31 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474 (2022).
- 32 Josh et al OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 cs.CL
- 33 Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, and Jeff Dean. 2018. Efficient neural architecture search via parameters sharing. In International Conference on Machine Learning. PMLR, 4095--4104.
- 34 Gabriel Poesia, Oleksandr Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gulwani. 2022. Synchromesh: Reliable code generation from pre-trained language models. arXiv preprint arXiv:2201.11227 (2022).
- 35 Chen Qian, Xin Cong, Wei Liu, Cheng Yang, Weize Chen, Yusheng Su, Yufan Dang, Jiahao Li, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. Communicative Agents for Software Development. arXiv:2307.07924 cs.SE
- 36 Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. 2019. Regularized Evolution for Image Classifier Architecture Search. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (Jul. 2019), 4780--4789. https://doi.org/10.1609/aaai.v33i01. 33014780
- 37 Frank Hutter Thomas Elsken, Jan Hendrik Metzen. 2018. Simple and efficient architecture search for Convolutional Neural Networks. https://openreview.net/forum?id= SySaJ0xCZ
- 38 Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. 2023. A Survey on Large Language Model based Autonomous Agents. arXiv:2308.11432 cs.AI
- 39 Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022).
- 40 Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824--24837.
- 41 Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning 8 (1992), 229--256.
- 42 Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Zhicheng Yan, Masayoshi Tomizuka, Joseph Gonzalez, Kurt Keutzer, and Peter Vajda. 2020. Visual Transformers: Tokenbased Image Representation and Processing for Computer Vision. arXiv:2006.03677 cs.CV
- 43 Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155 cs.AI
- 44 Yiran Wu, Tianwei Yue, Shaokun Zhang, Chi Wang, and Qingyun Wu. 2024. StateFlow: Enhancing LLM Task-Solving through State-Driven Workflows. arXiv:2403.11322 cs.CL
- 45 Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, and Tao Gui. 2023. The Rise and Potential of Large Language Model Based Agents: A Survey. arXiv:2309.07864 cs.AI
- 46 Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. 2024. Travelplanner: A benchmark for real-world planning with language agents. arXiv preprint arXiv:2402.01622 (2024).
- 47 Shuyuan Xu, Zelong Li, Kai Mei, and Yongfeng Zhang. 2024. CoRE: LLM as Interpreter for Natural Language Programming, Pseudo-Code Programming, and Flow Programming of AI Agents. arXiv:2405.06907 cs.CL
- 48 Quanming Yao, Mengshuo Wang, Yuqiang Chen, Wenyuan Dai, Yu-Feng Li, Wei-Wei Tu, Qiang Yang, and Yang Yu. 2018. Taking human out of learning applications: A survey on automated machine learning. arXiv preprint arXiv:1810.13306 (2018).
- 49 Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems 36 (2024).
- 50 Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022).
- 51 Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. In International Conference on Learning Representations (ICLR).
- 52 Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Ren Kan, Dongsheng Li, and Deqing Yang. 2024. EASYTOOL: Enhancing LLM-based Agents with Concise Tool Instruction. arXiv preprint arXiv:2401.06201 (2024).
- 53 Zhen Zeng, William Watson, Nicole Cho, Saba Rahimi, Shayleen Reynolds, Tucker Balch, and Manuela Veloso. 2024. FlowMind: Automatic Workflow Generation with LLMs. arXiv:2404.13050 cs.CL
- 54 Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT.