因为性能测试能帮你找到你代码里的锁。
我还在国内一家互联网大厂打工的时候,有次做完一轮性能测试,把报告交给leader审核。他瞄了一眼:
CPU才压到40%?
我很诧异,回了一句:并发数和环境都检查过了,已经是最优并发数了,接口的吞吐量确实也一直上不去。
leader只说了一句:你的代码里有锁,线程在CPU里干活的效率很低很低,CPU的利用率太低了。先去检查代码。
后来仔细检查代码,还真是有锁。
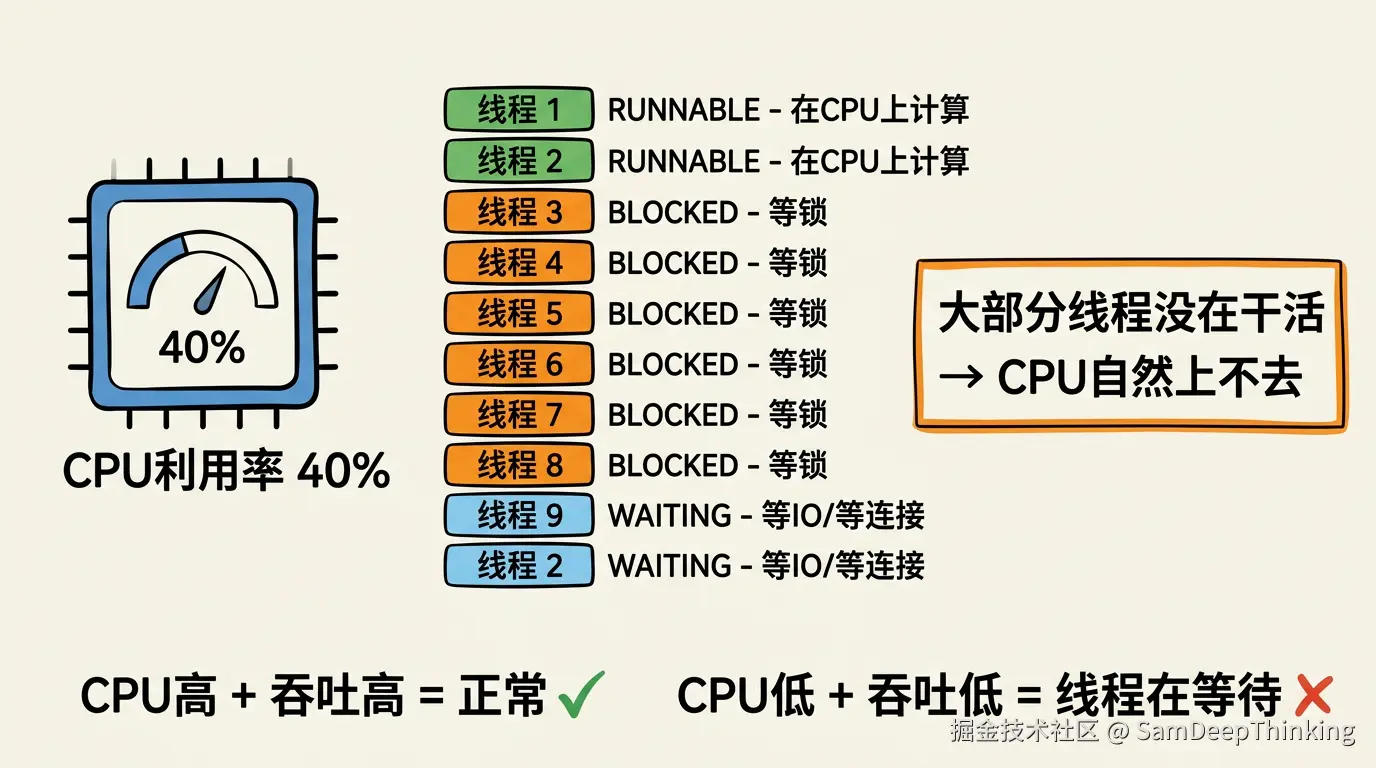
CPU利用率低意味着什么
线程在CPU上做的事情分两类。一类是真正消耗CPU的:数学计算、对象序列化、JSON解析、GC回收。另一类不消耗CPU:等锁、等数据库返回、等网络响应、等连接池分配连接。
CPU利用率反映的是线程在CPU上真正干活的时间占比。40%意味着大部分时间里,线程没在做计算,在等什么东西。
吞吐量上不去,说明请求处理的速度到了天花板。线程没在计算(CPU低),但也没在快速处理请求(吞吐低),那线程在干嘛?在等。
等什么?两种可能。一种是等外部依赖:数据库查询慢、下游服务响应慢。另一种是等锁:线程之间互相排队,同一时间只有少数线程能真正执行代码。
leader当时一眼判断是锁,是因为压测环境是独立的,数据库和下游服务的响应时间都很正常。排除了外部因素,剩下最大的可能就是代码里有锁。
这里整理了一张压测时常见异常现象的速查表,碰到类似情况可以直接对照排查:
| 压测现象 | 可能的原因 | 排查方向 | 常用工具 |
|---|---|---|---|
| CPU低+吞吐低 | 锁竞争、IO等待、连接池满 | 线程dump看BLOCKED/WAITING状态 | jstack、Arthas thread |
| CPU高+吞吐低 | 死循环、频繁GC、低效算法 | CPU火焰图、GC日志 | async-profiler、jstat |
| CPU高+吞吐高+响应慢 | 线程池不够、请求在排队 | 线程池监控、请求排队时间 | Micrometer、Prometheus |
| 吞吐随并发增加反而下降 | 锁竞争加剧、上下文切换过多 | vmstat看cs列、锁分析 | vmstat、perf |
| 前几分钟正常后来变慢 | 内存泄漏、连接泄漏、GC压力增大 | 堆内存趋势、连接池监控 | jmap、VisualVM |
| 错误率随并发数线性上升 | 超时配置不合理、下游扛不住 | 下游服务监控、超时配置检查 | SkyWalking等链路追踪 |
做过几次压测的人都知道,压测过程中最耗时的不是加压本身,而是看到异常数据之后不知道从哪里下手排查。这张表可以省不少时间。
ConcurrentHashMap里的隐藏锁
那次具体的代码问题年代久远,细节记不清了。在这里我举一个demo例子来说明问题。
一个商品查询接口,为了减少数据库访问,开发者在Service层做了一个本地缓存:
Java
@Service
public class ProductService {
private final ConcurrentHashMap<Long, Product> localCache = new ConcurrentHashMap<>();
@Autowired
private ProductMapper productMapper;
public Product getProduct(Long productId) {
// 从缓存获取,没有就查数据库并放入缓存
return localCache.computeIfAbsent(productId, id -> productMapper.selectById(id));
}
}代码review的时候,看这段代码找不出任何毛病。ConcurrentHashMap是线程安全的,computeIfAbsent保证原子性:key不存在就执行mapping函数加载数据,存在就直接返回。用法规范,逻辑清晰,没有任何一行代码里出现synchronized关键字。
当你压测的时候,会发现吞吐量死活上不去。抓线程dump一下后,发现大量线程处于BLOCKED状态,阻塞点在ConcurrentHashMap.computeIfAbsent。
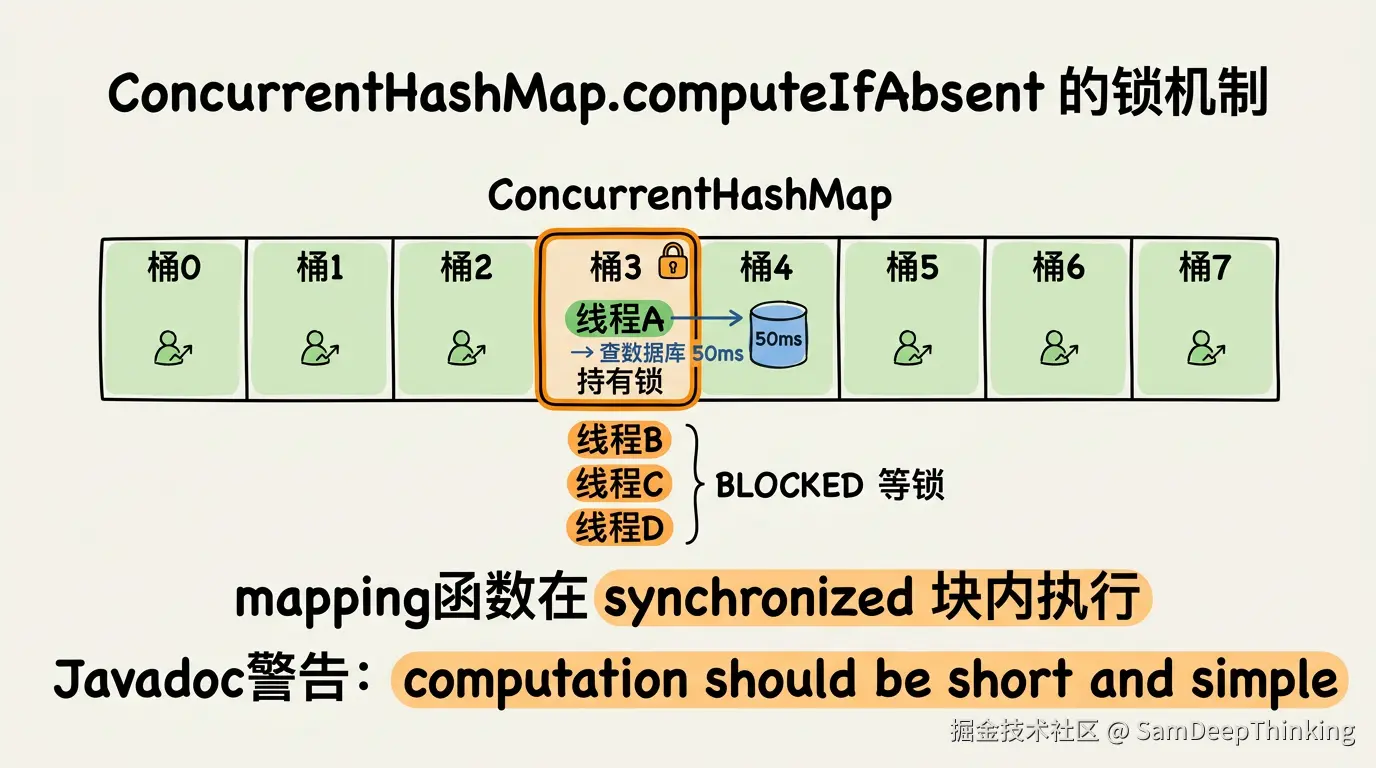
翻ConcurrentHashMap的源码,computeIfAbsent的实现里有一段关键逻辑:当key落到某个hash桶时,它会对这个桶的头节点加synchronized锁,然后在锁持有期间执行mapping函数。
productMapper.selectById(id)这个数据库查询,是在synchronized块里面执行的。
一次MySQL查询假设耗时50ms。ConcurrentHashMap默认16个桶,当你用200个并发线程散落在16个桶上,平均每个桶有12到13个线程在排队。每个桶同一时间只有一个线程能执行数据库查询,其余全部BLOCKED。同一时刻最多只有16个线程在真正干活,剩下184个都在等锁。
16除以200,8%的线程在工作。CPU上不去,完全说得通。
ConcurrentHashMap的Javadoc里写了一句警告:computation should be short and simple。说的就是mapping函数里不要放慢操作。只不过很少有人去读computeIfAbsent的Javadoc。
修复方式是把数据库查询从computeIfAbsent里拆出来:
Java
public Product getProduct(Long productId) {
// 先查缓存
Product product = localCache.get(productId);
if (product != null) {
return product;
}
// 缓存没命中,在锁外面查数据库
product = productMapper.selectById(productId);
if (product != null) {
// putIfAbsent保证并发安全,返回已有的值
Product existing = localCache.putIfAbsent(productId, product);
return existing != null ? existing : product;
}
return null;
}代价是同一个key缓存没命中的时候,可能有几个线程同时去查了数据库。大多数场景下这是可以接受的,缓存填充只发生一次,之后所有请求都走缓存。如果对重复查询也不能容忍,可以换用Caffeine的LoadingCache,它的加载机制不会阻塞其他key的读取。
类似的隐藏锁场景
ConcurrentHashMap.computeIfAbsent不是唯一的例子,类似的隐藏锁还有不少。
UUID.randomUUID()内部共享了一个SecureRandom实例。SecureRandom的nextBytes方法,在部分安全提供者实现下是synchronized的(可以看SecureRandom类的nextBytes方法,里面有一个threadSafe标志位的判断)。每个请求生成一个UUID做链路追踪ID,高并发下所有线程可能在这一行排队。
SimpleDateFormat不是线程安全的,有些旧代码会把它作为静态变量,外面包一层synchronized。功能上没问题,性能上每个请求都在排队等这把锁。
Logback的同步文件Appender,每写一条日志都要拿锁。日志量大的接口,这个锁会成为瓶颈。
这些问题有个共同特征:锁藏在你平时不会怀疑的组件里。
代码review发现不了这类问题。只有在性能测试中,通过线程dump看到大量BLOCKED线程,才能定位到锁的位置。
性能测试帮你定限流参数
做性能测试还有一个非常实际的用途:确定限流参数。尤其是在应付公司大促活动的时候,这是绕不过去的事。
大促之前,运维和开发一定会被问:系统能扛多少并发?限流阈值设多少?
这两个数字不是拍脑袋定的,是压测出来的。
通过性能压测,逐步增加并发数,同时观察系统各项指标。在某个并发数下,CPU、内存、数据库负载、响应时间、错误率都保持稳定,再往上加并发就开始出问题。这个临界点对应的并发数,就是系统在当前配置下的实际承载能力。
那这个「稳定」的标准怎么定?
CPU到90%不是最优并发数
很多人有个误解:把CPU压到90%对应的并发数就是系统的极限能力。
绝对是错的。
CPU不是你应用独占的资源。操作系统自身要做线程调度、网络包收发、文件IO。JVM的GC也需要CPU。监控采集、日志写入同样消耗CPU。如果应用把CPU用到90%,留给这些基础工作的余量不到10%。
一旦有任何波动,比如一次Full GC、一个突发的网络重传、一小波比平时大一点的流量,系统就绷不住了。响应时间飙升,错误率上来,甚至直接不可用。
经验值是应用CPU保持在65%到70%之间比较健康,留出30%左右的余量给操作系统、GC和突发情况。这不是一个精确的数字,不同的应用类型、不同的GC策略会有差异,70%是一个比较安全的参考上限。
有人会觉得70%太保守了,浪费了30%的CPU。
这不是浪费,是留给意外情况的缓冲区。线上环境不像压测环境那么干净,各种毛刺和波动是常态。留够余量,系统才能在波动面前保持稳定。
要看整条请求链路的资源
CPU保持在70%就够了吗?也不够。
一个HTTP请求从进来到返回,经过的不只是CPU。Tomcat的线程池、数据库连接池、MySQL的CPU和磁盘IO、Redis的连接数和响应延迟、下游服务的响应时间,任何一个环节到了瓶颈,系统都会变得不稳定。
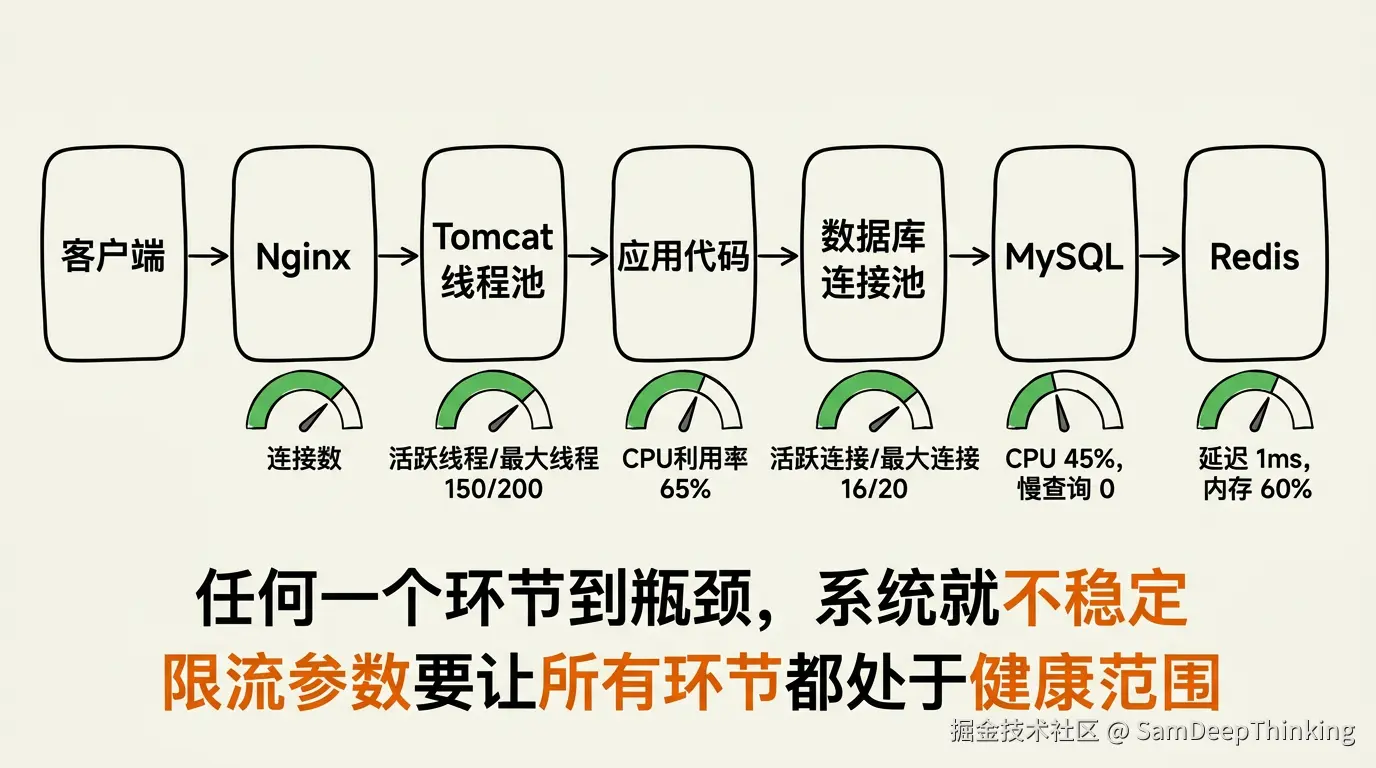
应用CPU才50%,看起来还有余量,但数据库连接池已经满了,大量请求在等连接分配。或者Redis的响应延迟从1ms飙到50ms,虽然应用CPU正常,但接口的P99响应时间已经超过了业务要求。
确定最优并发数的标准不是单看CPU,而是整条请求链路上所有资源都处于稳定状态。
通过调整并发数,找到一个让所有资源负载都在安全范围内的值。这个值才是系统真实的承载能力。
用压测数据设限流参数
找到了最大稳定并发数之后,就可以设限流参数了。
限流阈值不要直接等于压测出的最大稳定并发数,还要留余量,通常取最大稳定值的80%左右。
设好限流之后,再跑一轮验证压测:给系统远超限流阈值的请求量,比如10倍甚至100倍。观察限流是否正确生效,超出阈值的请求是否被拒绝或降级返回,系统内部的各项资源指标是否保持在健康范围内。
验证通过,意味着即使大促流量远超预期,系统也是稳定的。超出的部分被限流挡在外面,不会影响已经进来的请求的正常处理。
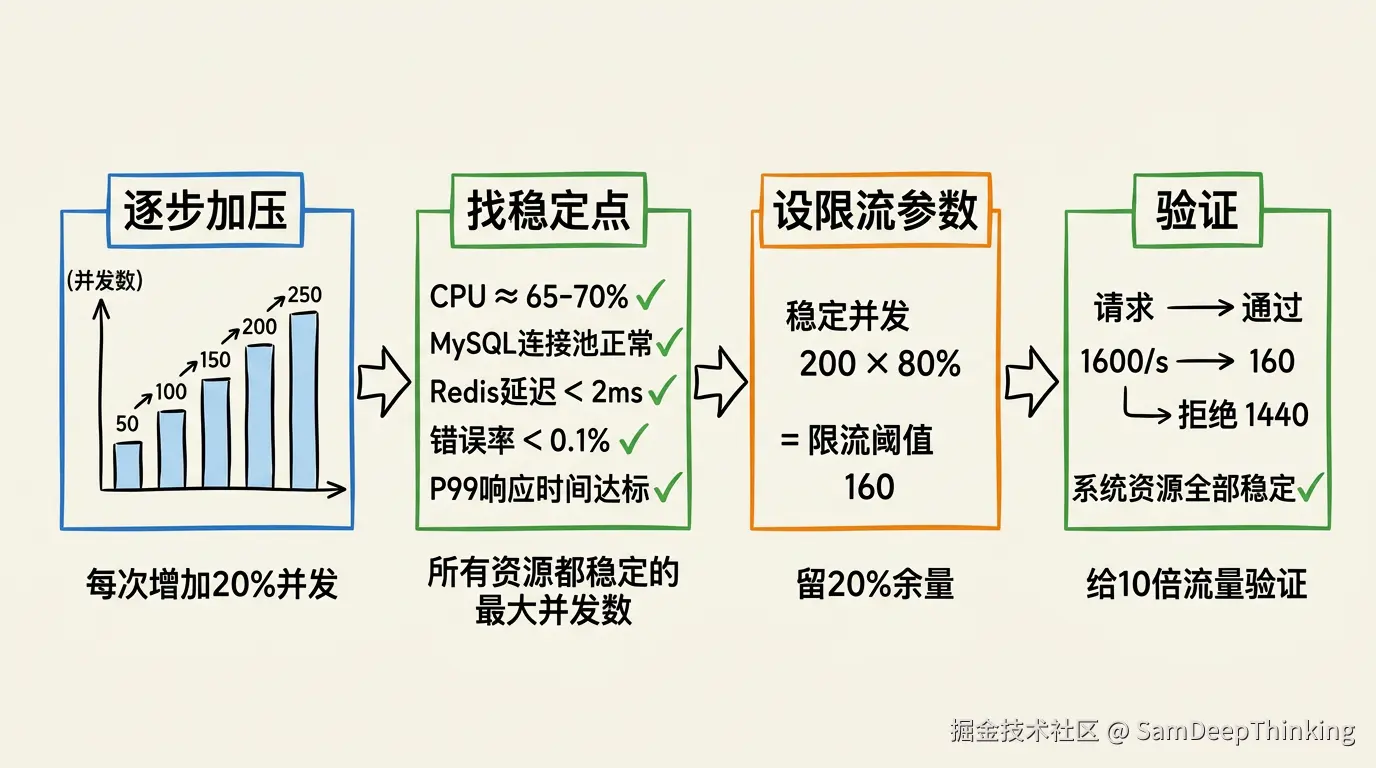
整理一下压测定限流参数的操作步骤:
- 用梯度加压,每次增加20%并发数,每个梯度持续观察5分钟以上,等指标稳定
- 同时监控这些指标:应用CPU、JVM堆内存、Tomcat线程池使用率、数据库连接池使用率、MySQL的CPU和慢查询数、Redis响应延迟、接口P99响应时间、错误率
- 找到所有指标都稳定的最大并发数。判断标准:应用CPU不超过70%、数据库连接池使用率不超过80%、P99响应时间不超过业务要求的上限、错误率低于0.1%
- 限流阈值 = 最大稳定并发数 × 80%
- 设好限流后,给10倍以上流量再压一轮,验证限流生效后系统内部资源全部在健康范围内
这5步做完,大促期间心里是有底的。不管流量来多大,系统最多就是把超出的请求限流掉,不会出现整个系统被打崩的情况。
不压测发现不了的问题
除了找锁和定限流,性能测试还能帮你发现一些日常开发中完全看不到的问题。
你的代码可能没毛病,但你依赖的下游服务扛不住。一个内部服务的HTTP连接池默认10个连接,日常流量下绰绰有余,压测一上量全部排满,你的线程卡在等下游响应上,连带着你自己的线程池也满了,本来跟这个下游没关系的接口也开始超时。日常流量下这种问题根本不会出现。
中间件的配置也是一样。Redis连接池大小、消息队列的消费线程数、数据库连接池的最大连接数,框架的默认值在低流量下都够用。压测上量之后,连接不够用了、消费速度跟不上开始堆积了、连接池开始排队了,各种配置问题才浮出水面。不压测,你根本不知道哪个默认值需要调。
还有一类问题更隐蔽:只在高并发持续运行一段时间后才出现的内存泄漏。ThreadLocal用完没清理,Tomcat线程池复用线程时上一个请求的数据还留着。某个本地缓存没有淘汰策略,数据只进不出。低流量时泄漏速度慢,GC扛得住,监控上看不出异常。压测跑半小时,堆内存曲线一路上升不回落,问题就暴露了。
最值得警惕的是超时配置的连锁反应。A服务调B,B调C,C的响应变慢了。如果B没有配合理的超时和熔断,B的线程池会被C拖住。A调B也变慢了,A的线程池又被B拖住。一个下游的问题沿着调用链往上蔓延,整条链路上所有服务都被拖慢。不做全链路压测,你不知道某个下游变慢会不会引发雪崩,也不知道你配的超时和熔断参数在真实压力下够不够用。
小结
代码review能发现逻辑错误,单元测试能验证功能正确,集成测试能检查模块之间的对接。这些手段各有各的价值,但有一类问题它们都发现不了:并发条件下的锁竞争、资源瓶颈、配置缺陷。这些问题在低并发环境下完全隐形,只有真实的压力才能把它们逼出来。
性能测试的收获不只是报告里的TPS和响应时间数字。更值钱的是,通过压测过程中对线程dump、资源监控、链路追踪数据的分析,你对自己系统的运行状态建立了一个真实的认知。哪个接口有锁竞争、哪个连接池配小了、哪个下游服务是薄弱环节、限流阈值该设多少,这些认知不是读文档能获得的,是在压测过程中一轮一轮摸出来的。
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking